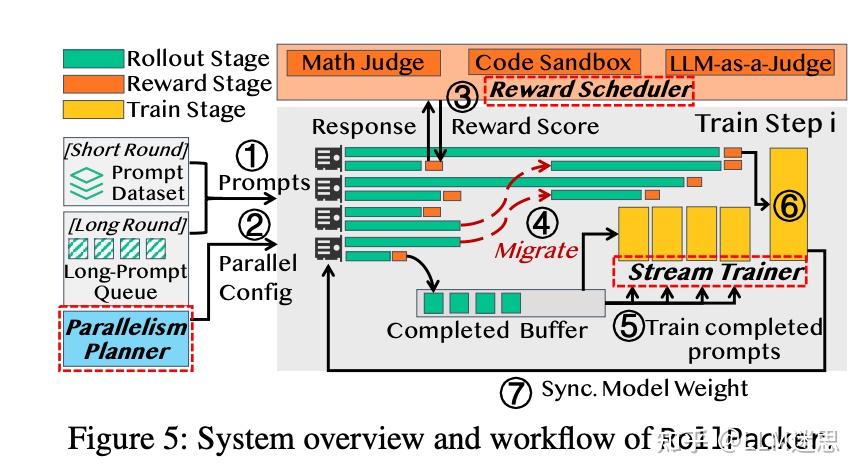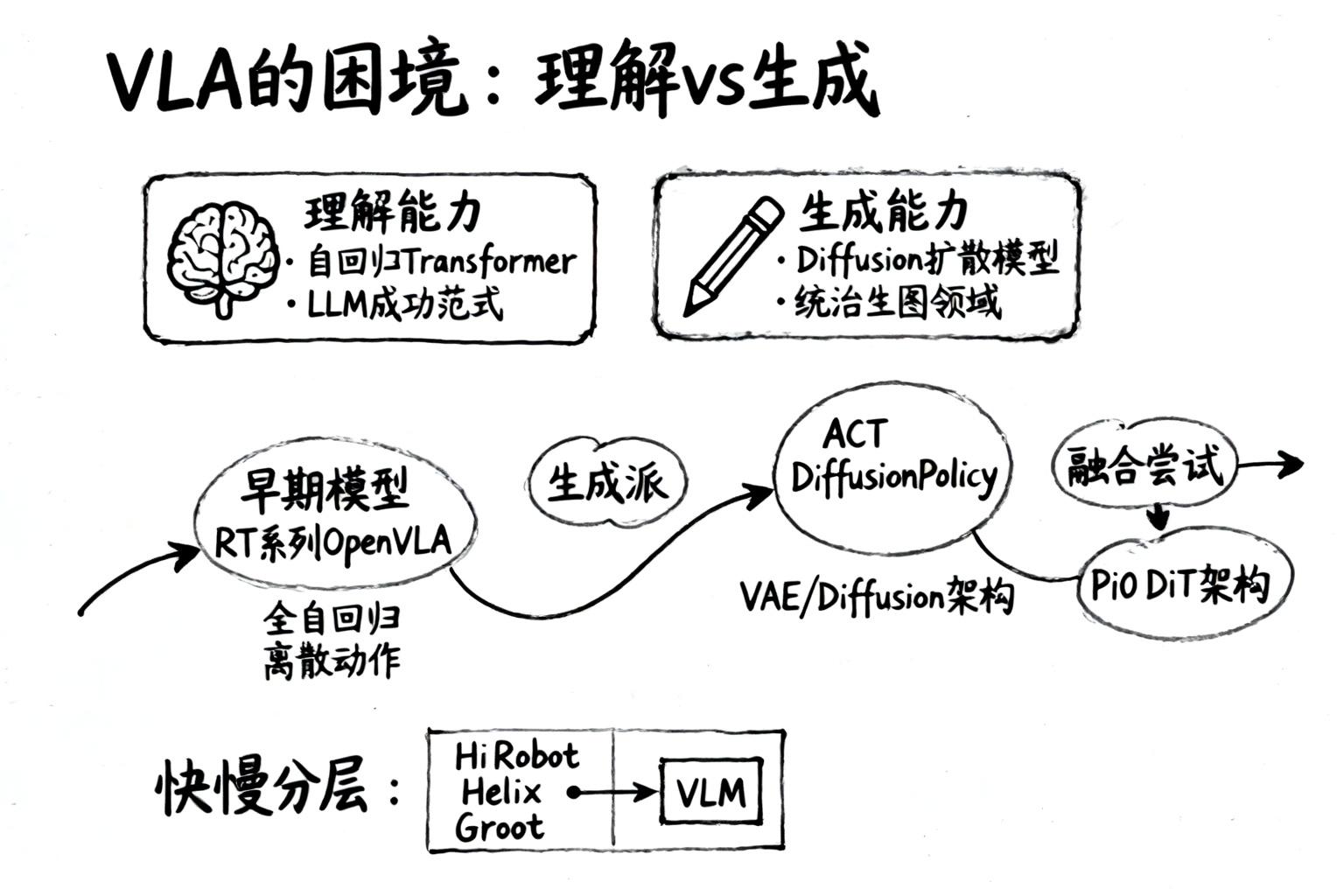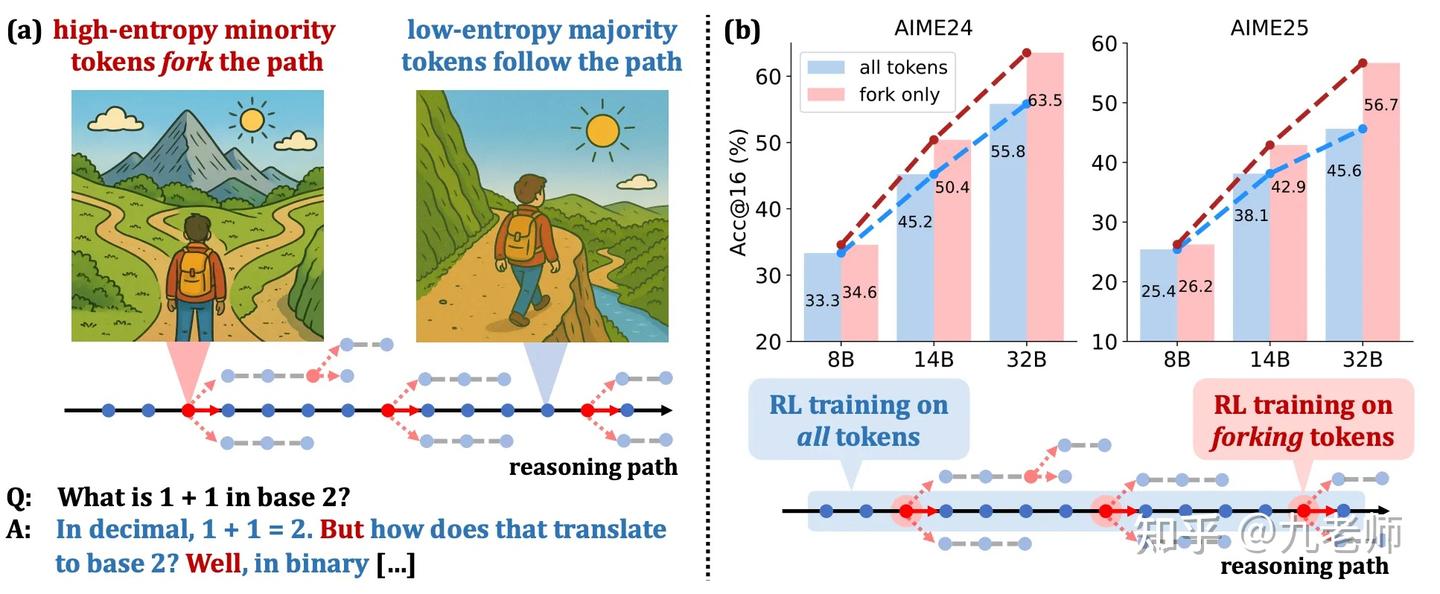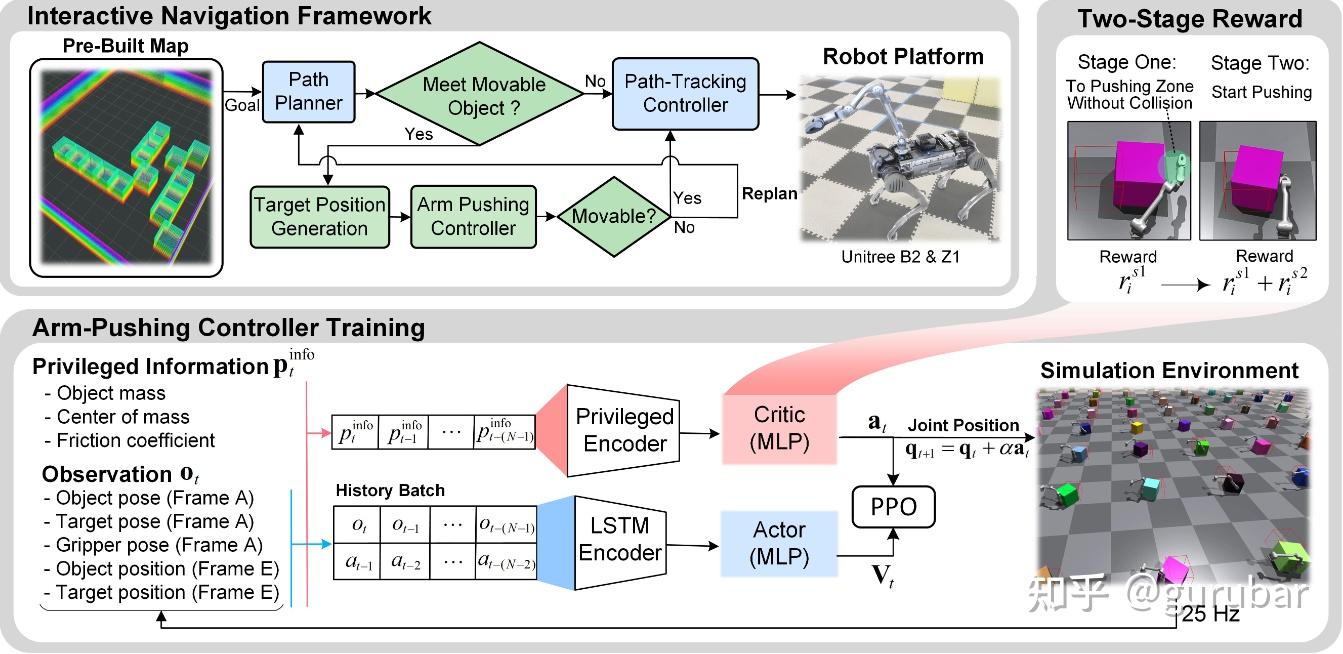
·
精选文章
Qwen用假信号也能拿高分?虚假的RLVR如何激活隐藏记忆回路?
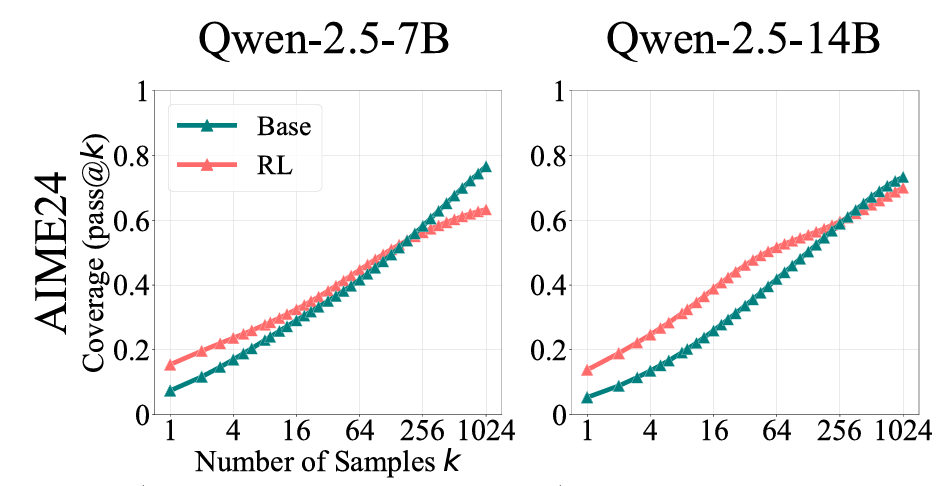
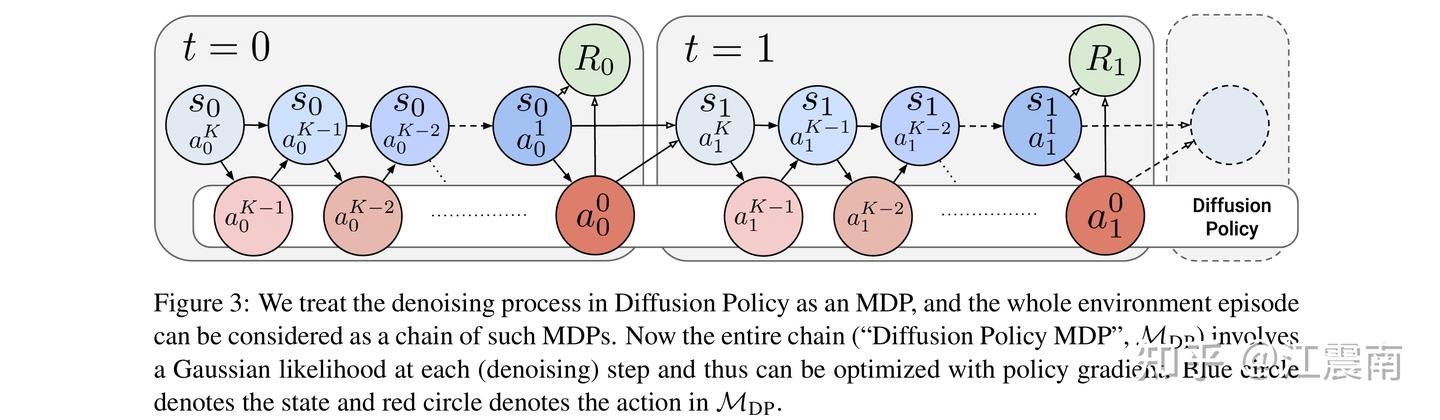
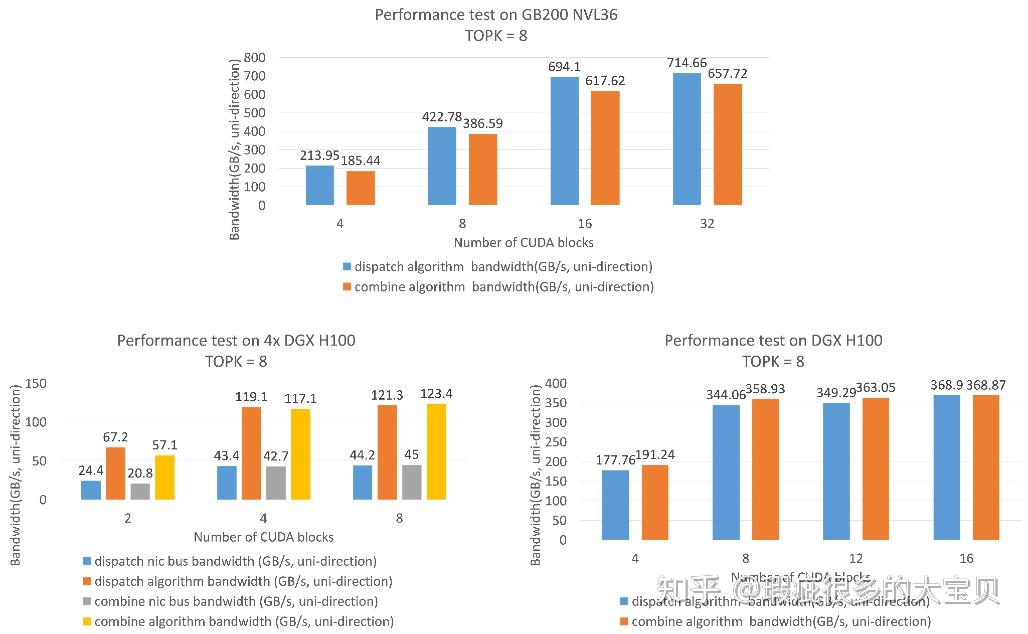
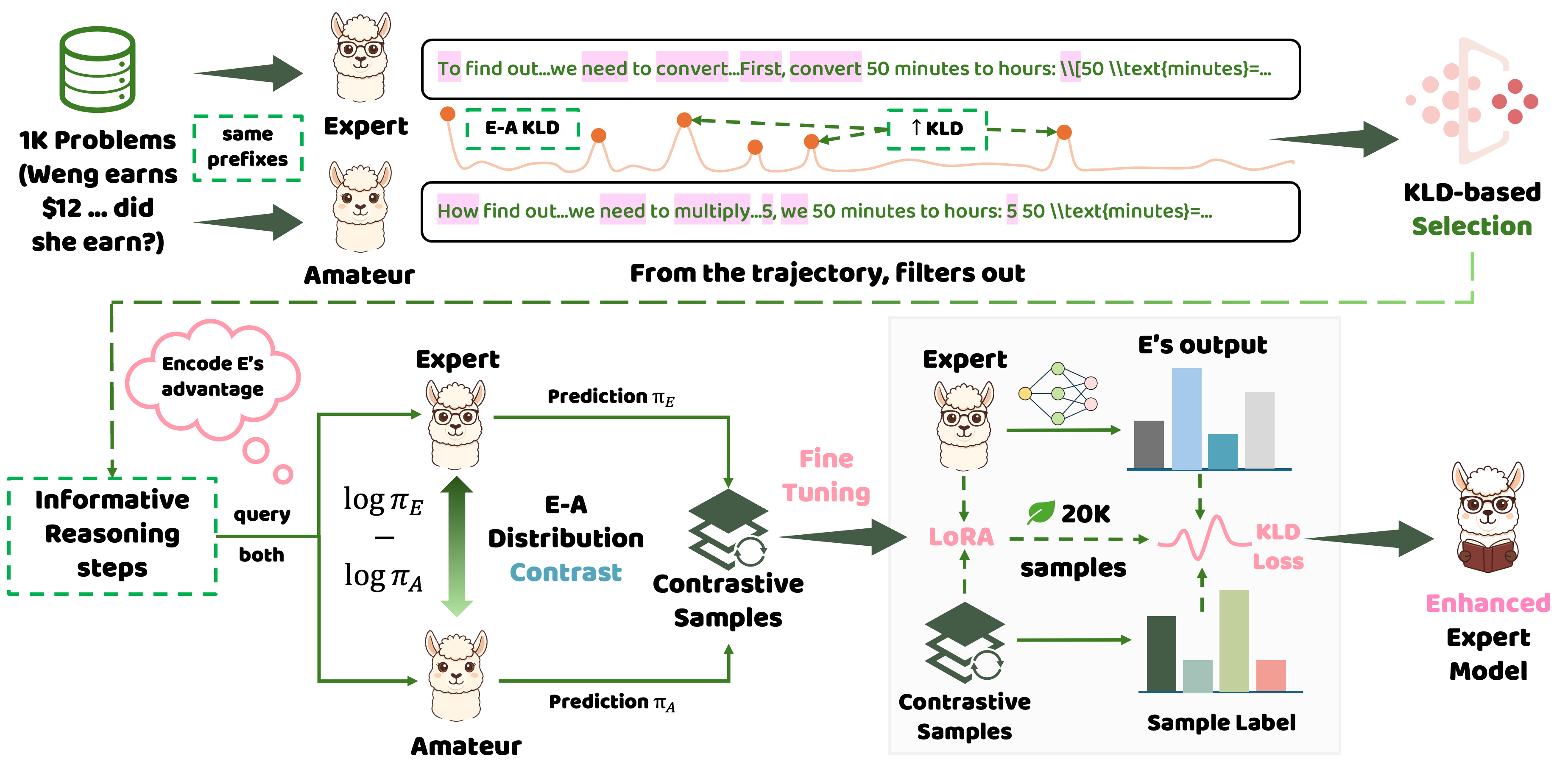
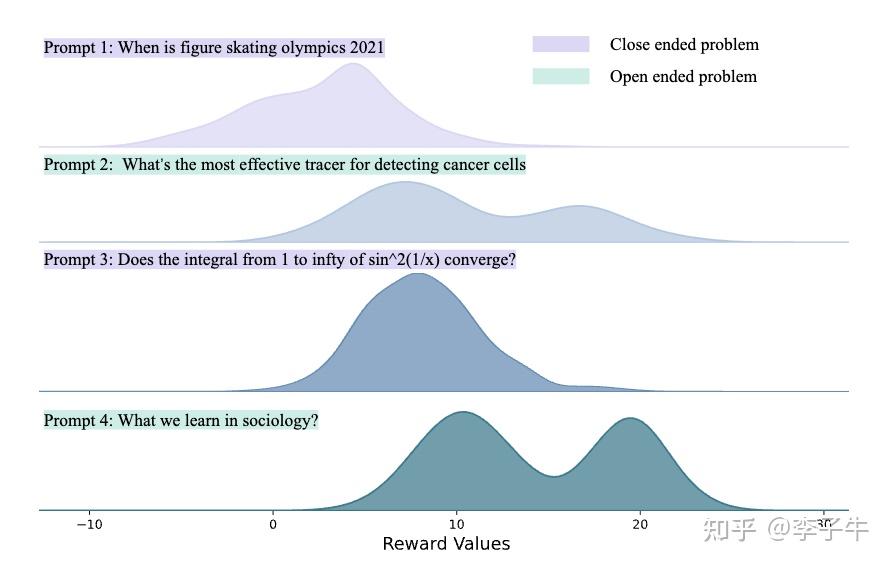
无需真实奖励,哪怕用随机、错误的信号进行训练,大模型准确率也能大幅提升? 此前,学术界已经发现了一个令人困惑的现象:像 Qwen2.5 这样的模型,即使在 RLVR(带验证奖励的强化学习)过程中给予虚假奖励(Spurious Rewards),它在对应测试集上的准确率依然能神奇地大幅提升,并通过一系
阅读更多
63



-ftxt.png)

-AXSE.PNG)

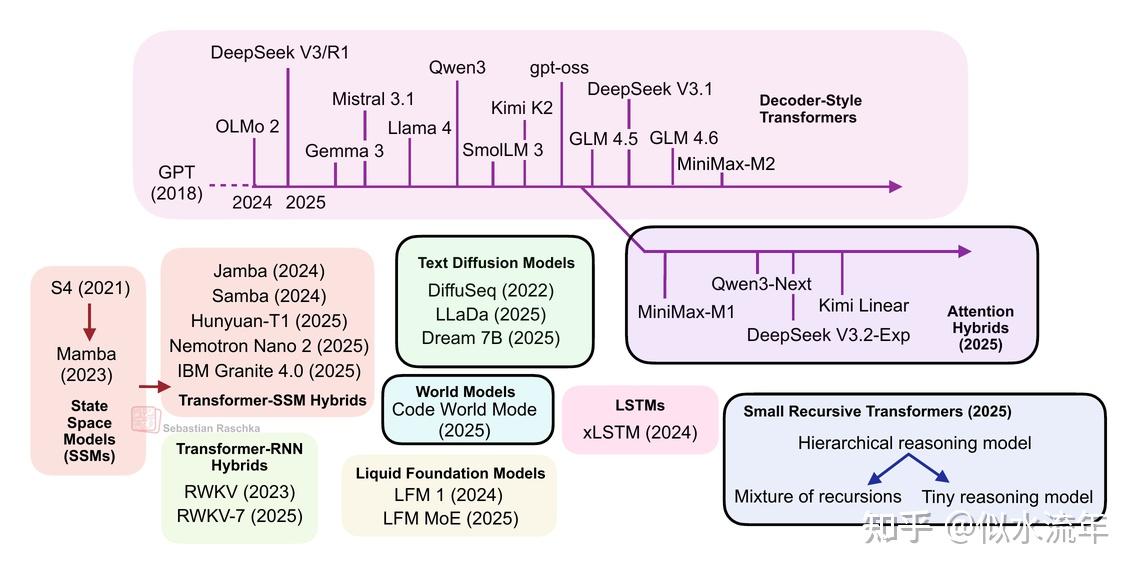
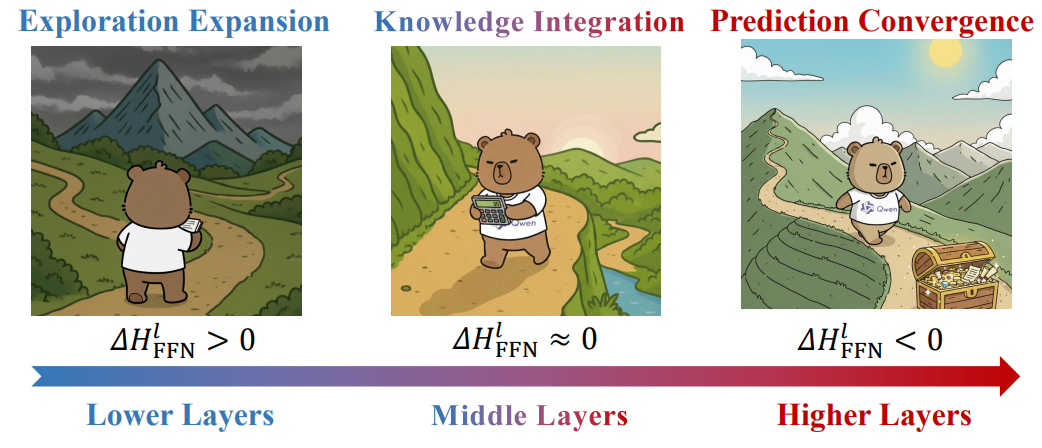
.png)
-obJS.png)
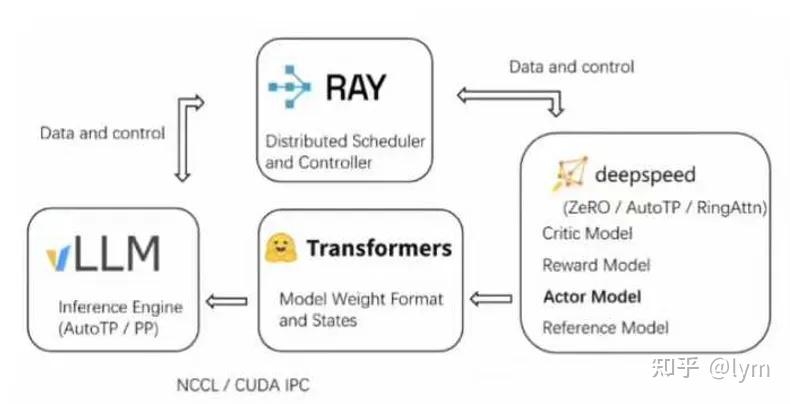
.png)
-KKeY.png)
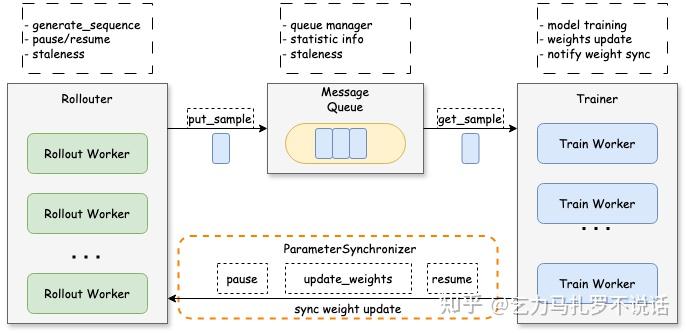
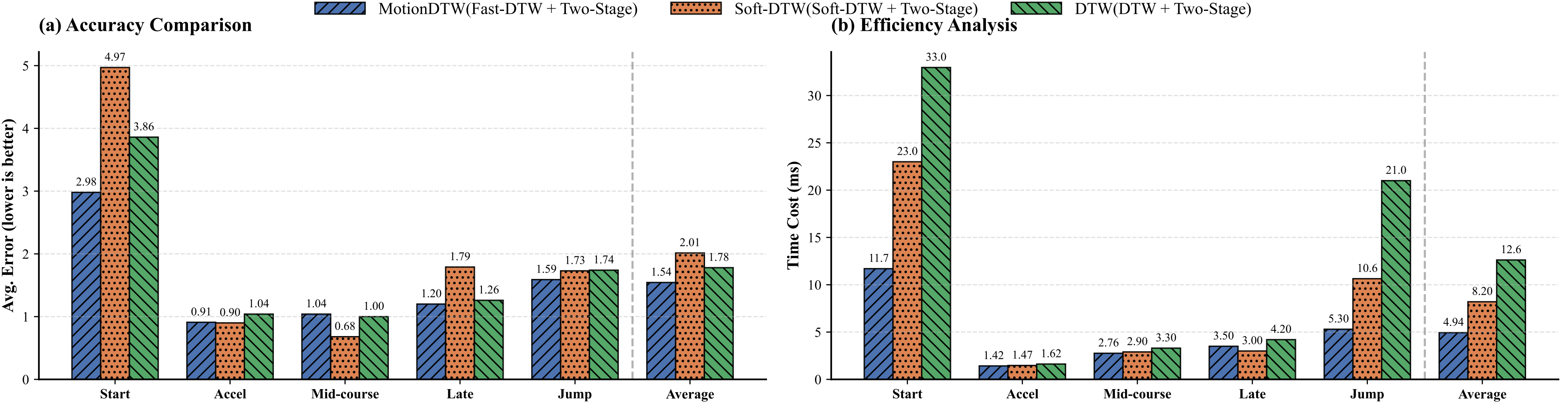
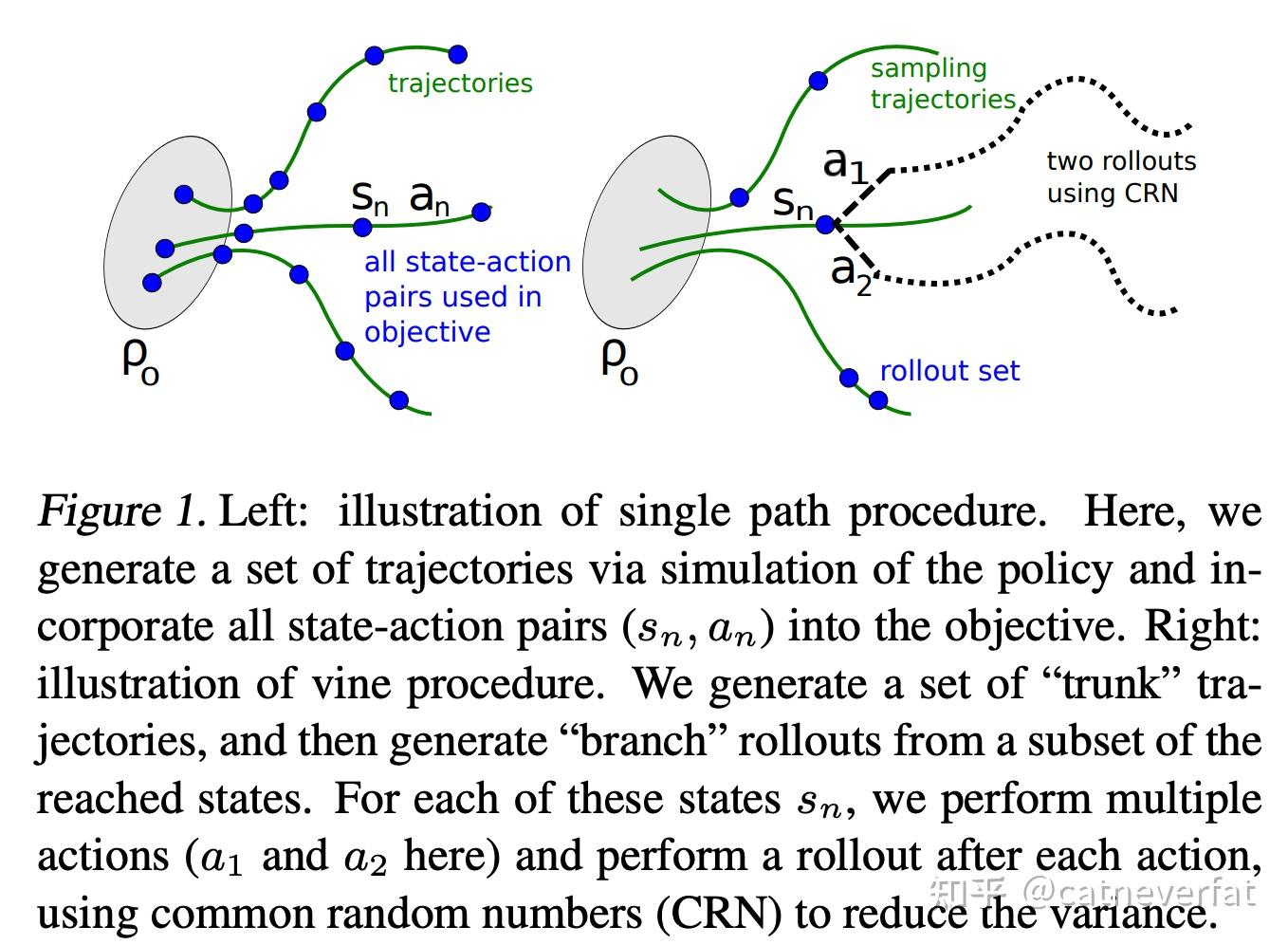
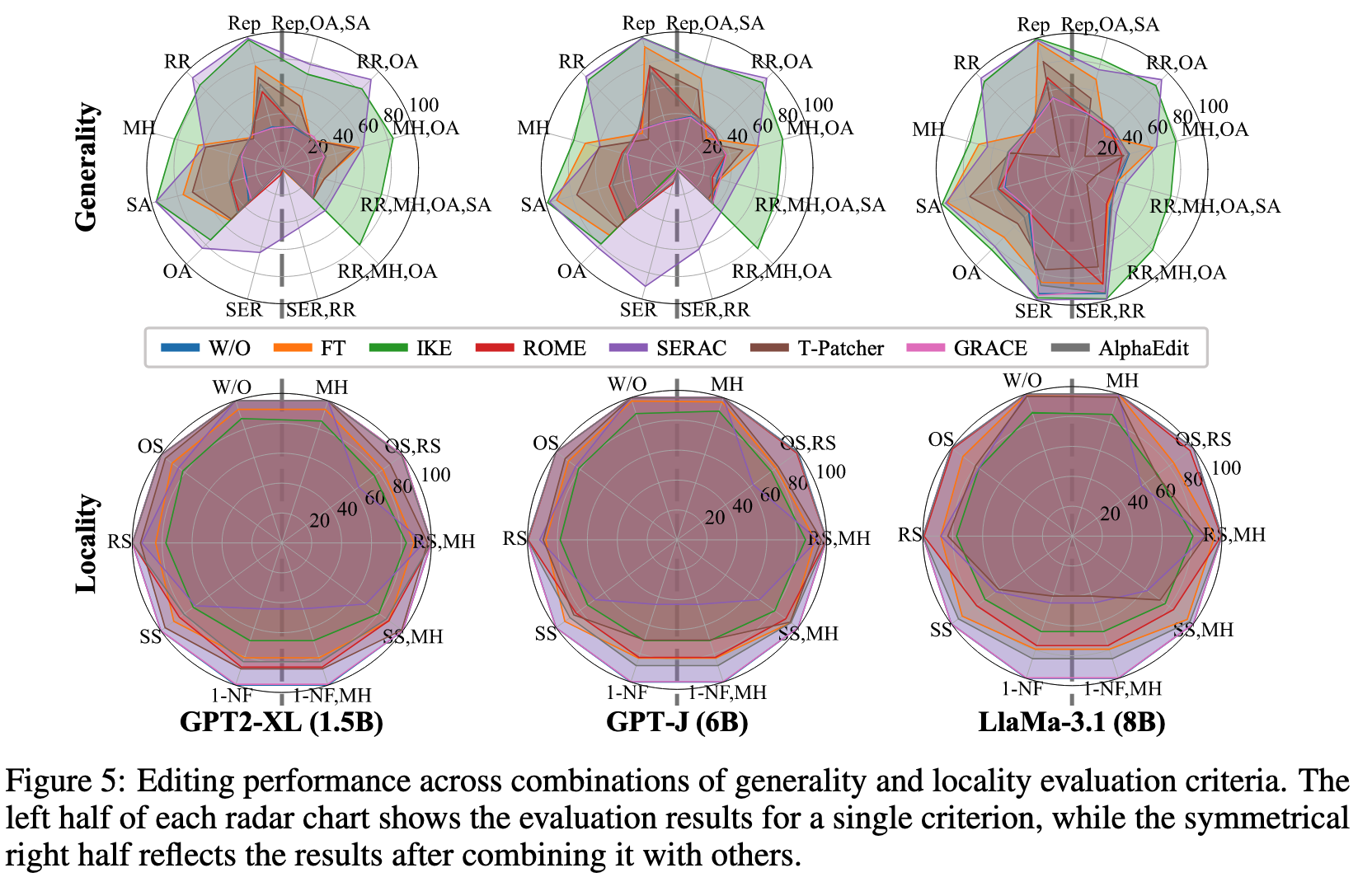
.png)
.png)

.jpg)
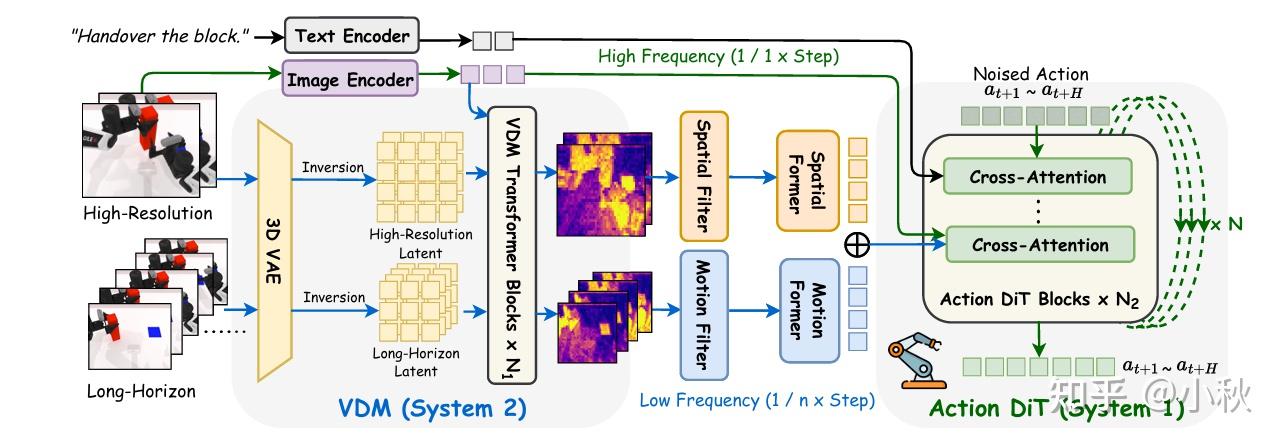


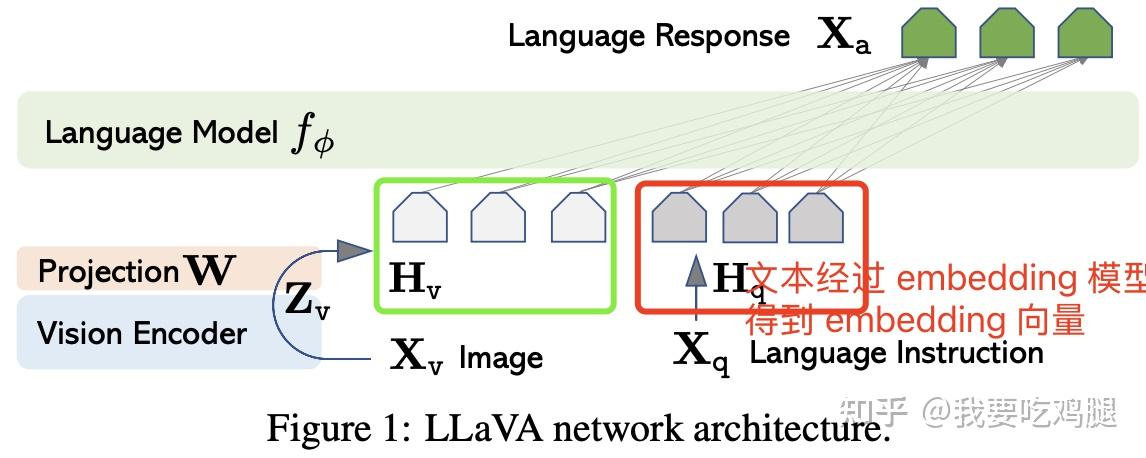
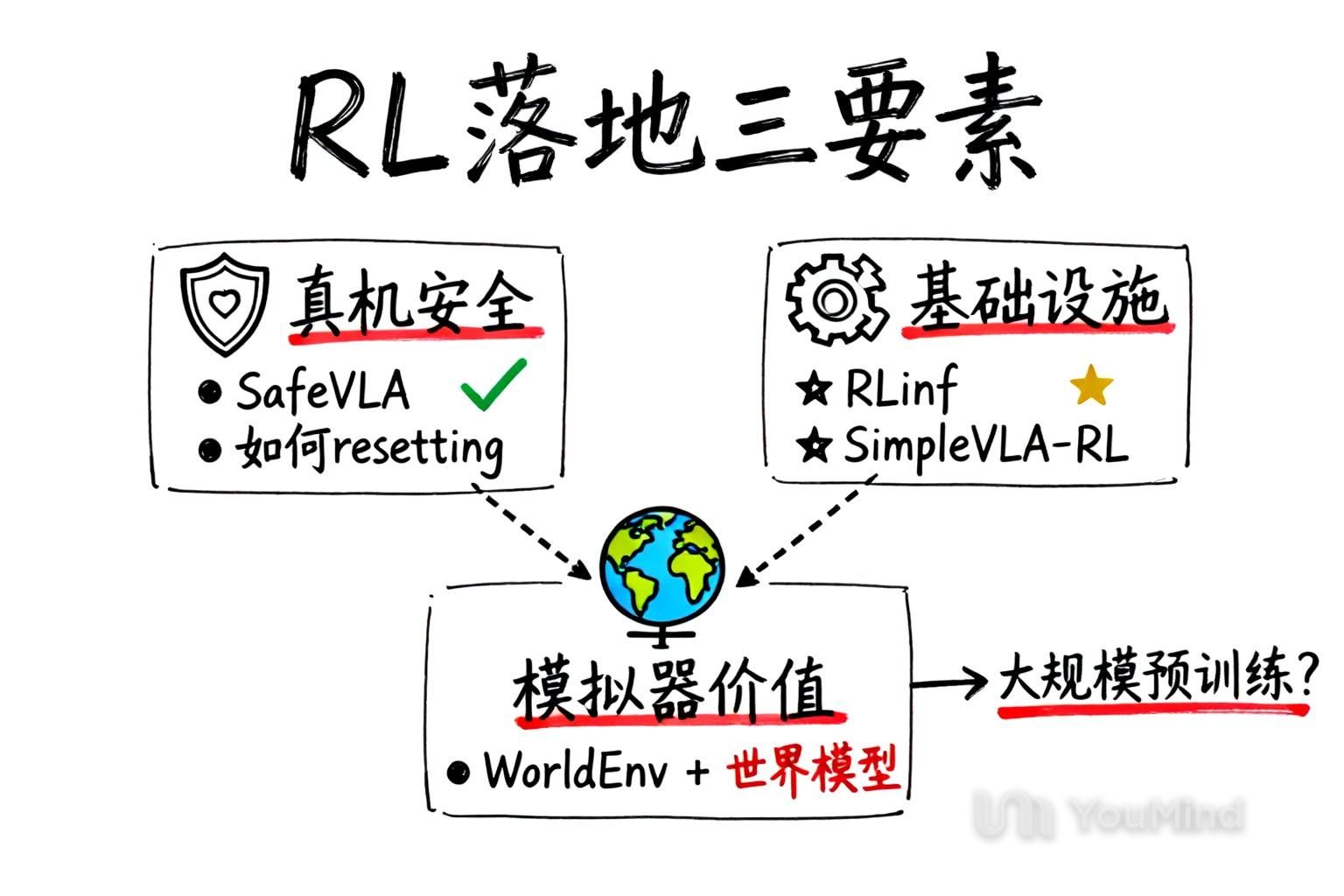
.png)