作者:绝密伏击
https://zhuanlan.zhihu.com/p/1954613742634504507
技术报告:LongCat-Flash-Thinking Technical Report
链接:https://github.com/meituan-longcat/LongCat-Flash-Thinking/blob/main/tech_report.pdf
前几天刚不久,美团发布了 LongCat-Flash-Chat,将大模型的“卷”带到了新高度。
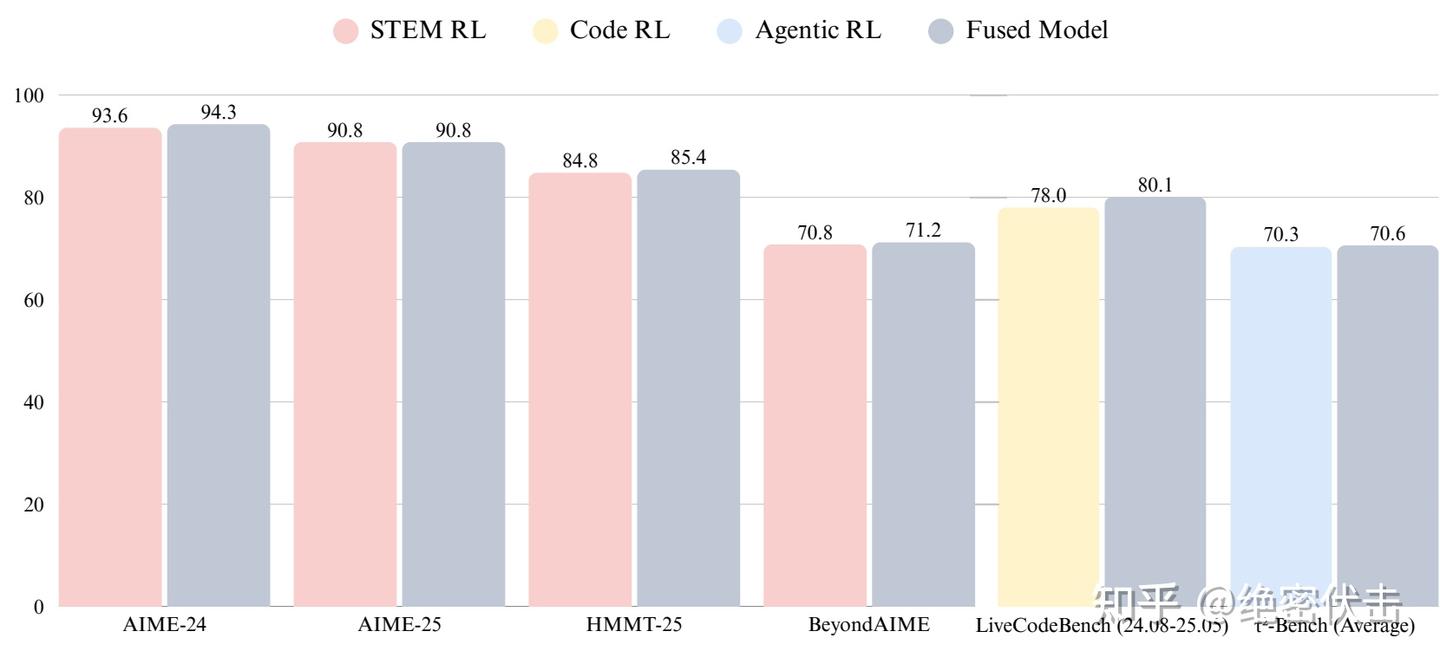
而就在这两天,美团就发布了对应的推理模型 LongCat-Flash-Thinking。在保持了 LongCat-Flash-Chat 极致速度的同时,全新发布的 LongCat-Flash-Thinking 更强大、更专业。综合评估显示,LongCat-Flash-Thinking 在逻辑、数学、代码、智能体等多个领域的推理任务中,取得了不错的效果。
1. 训练细节
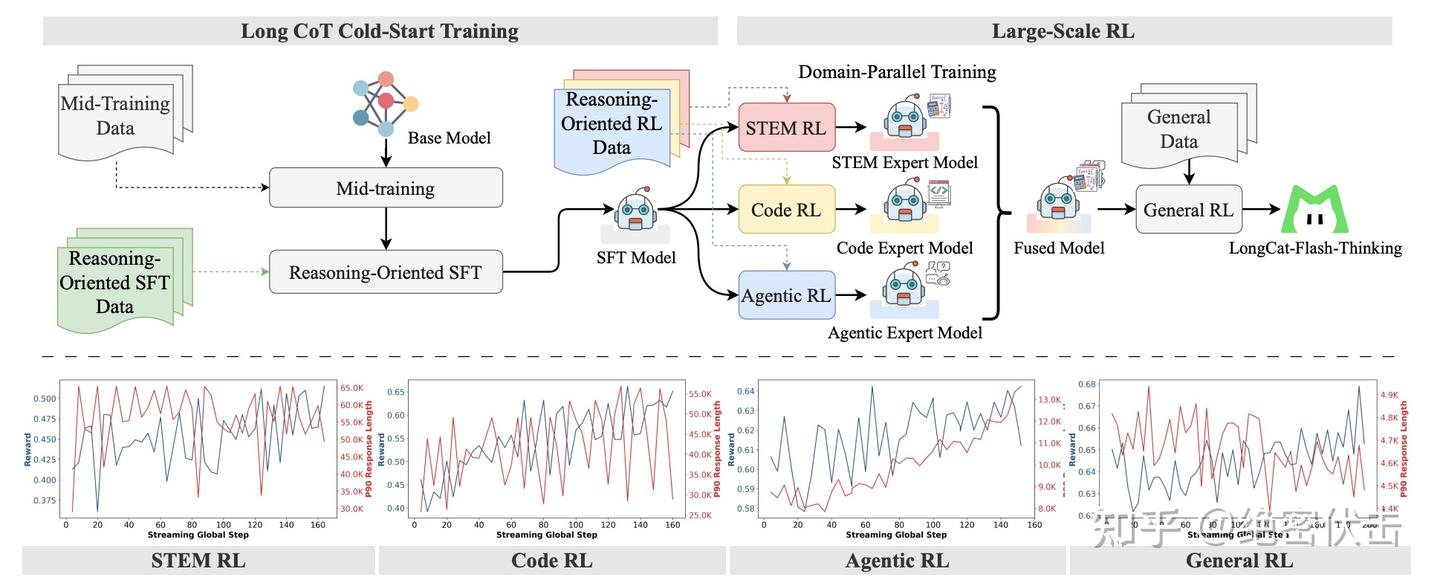
LongCat-Flash-Thinking 的训练流程与 GLM-4.5 十分相似。主要区别在于,GLM-4.5 在分领域强化学习之后,会直接对各个专家模型进行蒸馏,并最终统一到一次 SFT;而 LongCat-Flash-Thinking 则选择先对专家模型进行 Model Fusion,得到 Fused Model,再进入 General RL。下图展示了 GLM-4.5 与 LongCat-Flash-Thinking 的差异:
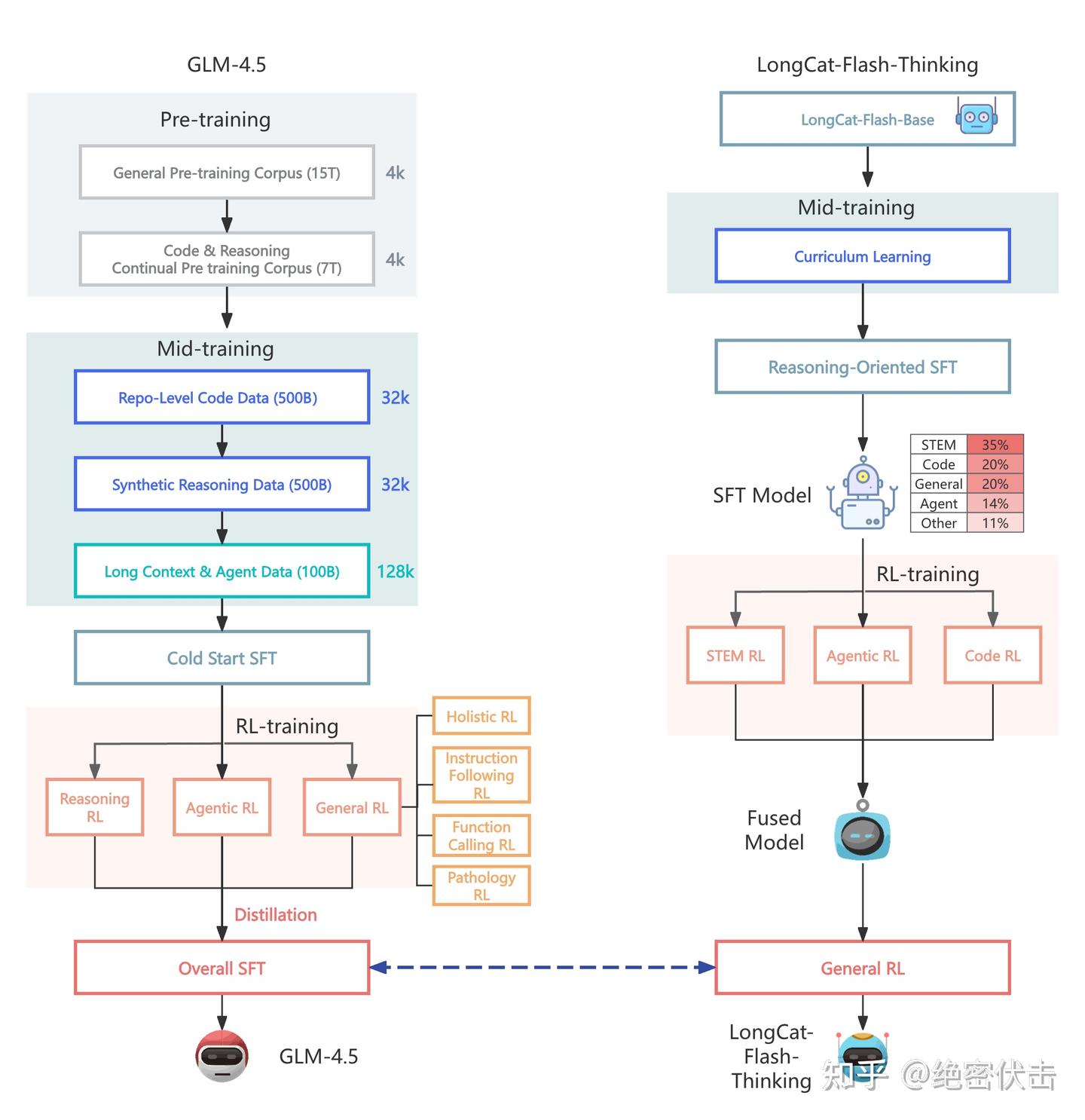
从上图可以看出,两者的核心区别在于对三个专家模型的处理方式。GLM-4.5 选择直接蒸馏三个专家模型,并在此基础上统一进行 SFT;而 LongCat-Flash-Thinking 则先将三个专家模型融合为一个 Fused Model,再进入通用强化。
除此之外,虽然在一些细节上可能存在差异,但整体方向大体一致。接下来,我们将重点介绍美团在模型融合上的具体做法。
2. Model Fusion
在 Large-Scale RL 阶段,得到了三个 领域专家模型:
- STEM Expert Model(擅长数学和科学推理)
- Code Expert Model(擅长代码生成与程序推理)
- Agentic Expert Model(擅长工具调用和交互式任务)
问题在于:
- 直接将不同领域的模型混合,会产生 参数干扰(interference)。
- 有的参数更新可能互相冲突,甚至导致某些领域性能下降。
因此,需要一种 稳定的模型融合方法,将多个专家模型合并为一个 统一的 Fused Model,并尽可能保留各自优势。
2.1 Normalization(归一化任务向量)
每个领域的更新量定义为:
即 RL 之后的参数减去 SFT 基线参数
- 不同领域的 \tau_i 可能尺度差异很大。
- 解决方法:对它们做 归一化处理,保证每个领域在融合时权重相对均衡。
比如 L2 Norm 归一化 对每个任务向量 \tau_i 做:
这样每个领域的更新方向保留,但幅度被压到同一尺度。归一化后的向量再加权合并:
其中 w_i 可以是:
- 等权重 (uniform):所有领域一样重要。
- 性能加权 (performance-based):某领域在验证集表现更好,就赋予更大权重
2.2 Dropout(丢弃冗余参数)
在领域并行 RL 后,我们有三个专家模型:STEM、Code、Agentic。
- 这些模型的参数更新( \tau_i = \theta_i^{RL} - \theta^{SFT} )往往存在 重叠的部分。
- 举例:STEM 和 Code 都会更新某些 “通用推理” 参数,比如 attention 层的权重,方向差不多。
- 如果直接把所有更新叠加,会导致 重复贡献 → 参数过大偏移 → 训练不稳定。
因此,需要一种方法来 削减冗余,这就是 Dropout。
- 借鉴了 DARE (Domain-Aware Redundancy Erasing) 思路。
- 对“重复更新”的参数,不是全部保留,而是 随机丢弃一部分,减少累积放大的效应。
举个例子,假设我们融合三个专家在某一参数 W 上的更新:
- STEM:+0.10
- Code:+0.12
- Agentic:+0.11
这三个更新方向几乎一致,说明是 高度冗余。 如果直接相加:
→ 更新量过大,可能破坏训练稳定性。
引入 Dropout:
- 假设 Dropout rate = 0.33
- 随机丢弃其中一个更新,比如丢掉 STEM 的贡献:
- 这样仍然保留了方向(正向增强),但避免了三者累加过大。
2.3 Erase(擦除冲突更新)
- 借鉴 SCE (Selective Conflict Erasing) 的思路。
- 如果某个参数在不同专家模型中的更新方向冲突严重,且有一方属于“少数派”,则擦除掉少数派的更新。
例子:
- STEM 模型:参数 W 增加 +0.2
- Code 模型:参数 W 增加 +0.25
- Agentic 模型:参数 W 减少 -0.8
- 融合时发现:STEM 和 Code 一致,而 Agentic 方向相反且幅度大。
- 采用 Erase:删除 Agentic 在该参数上的更新,只保留 STEM + Code 的共识更新。
通过 Normalization + Dropout + Erase,最终得到一个 统一的 Fused Model。