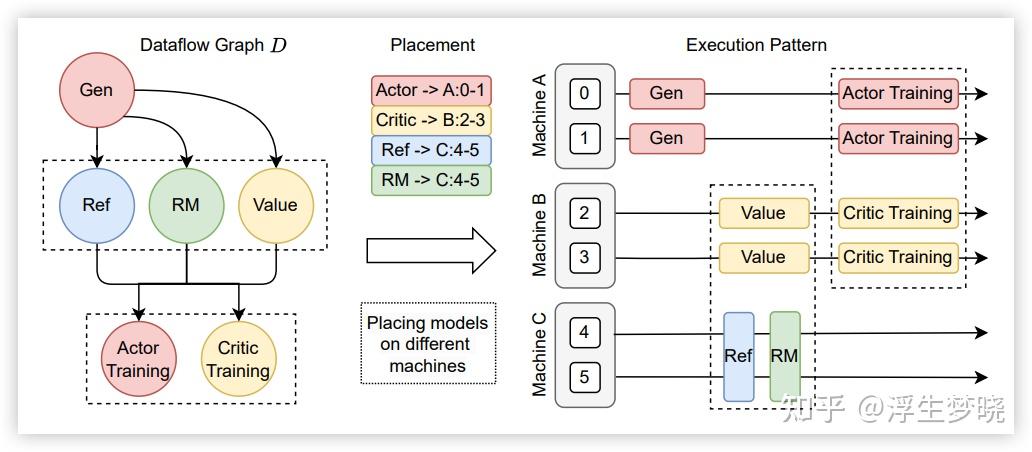
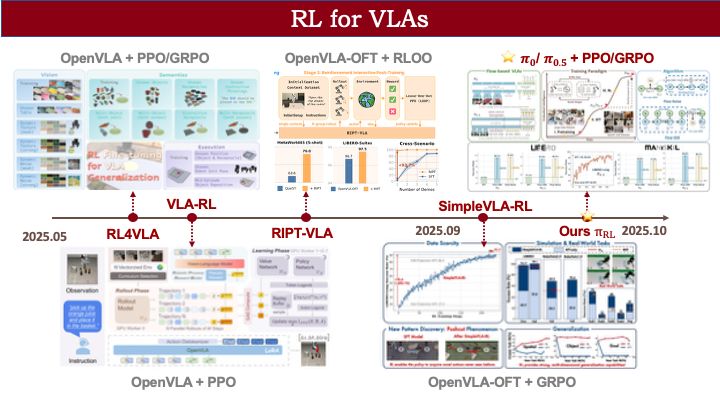
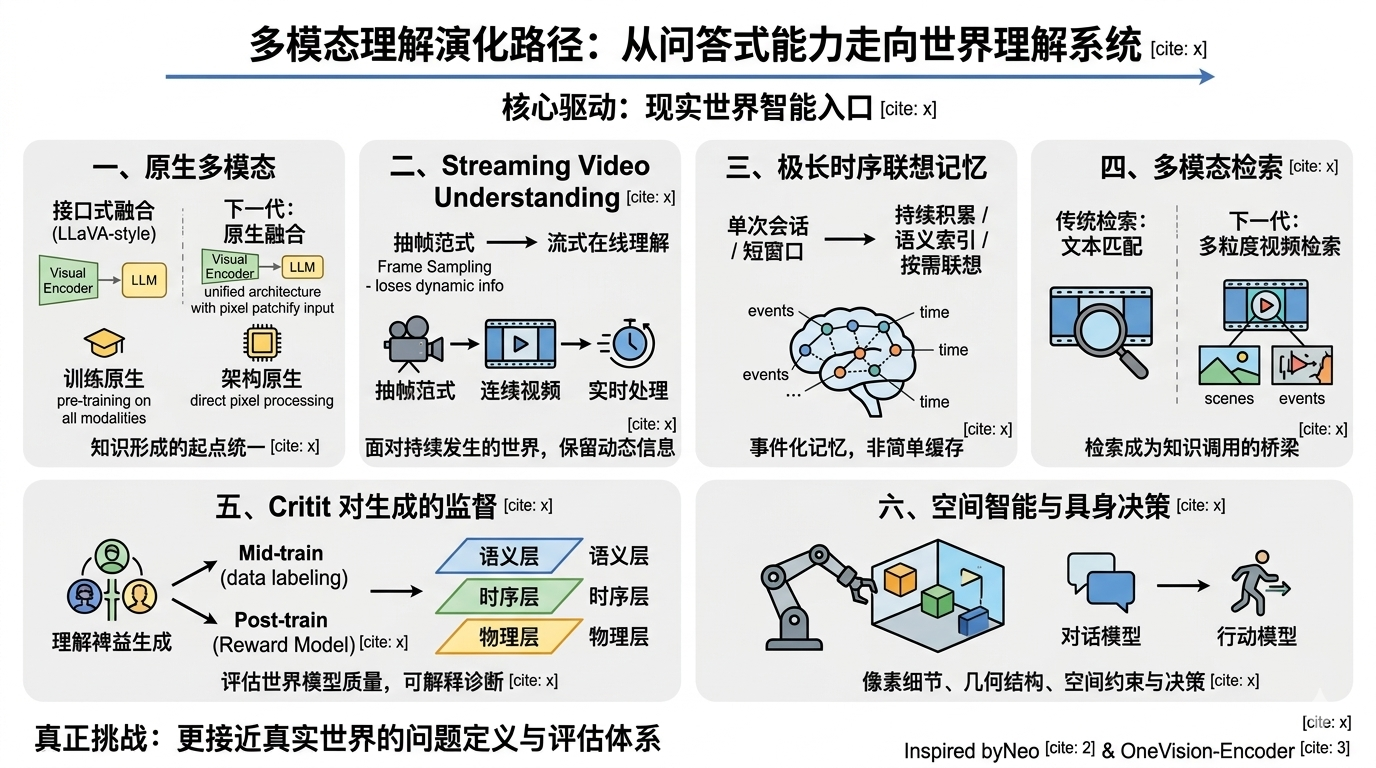
·
精选文章
Vibe Coding & Agent Evolved Meetup
当顶尖极客遇上 AI,代码从此有了“感觉” Stop Writing Code. Start Designing Vibe. 停止机械地敲击键盘,开始设计你的创意流。 你是否还在为 Rust 的所有权机制头秃? 你是否觉得构建一个行业级 Agent 需要组建一支专家团队? 你是否相信,一个周末足以重
阅读更多
73
-OwCS.png)
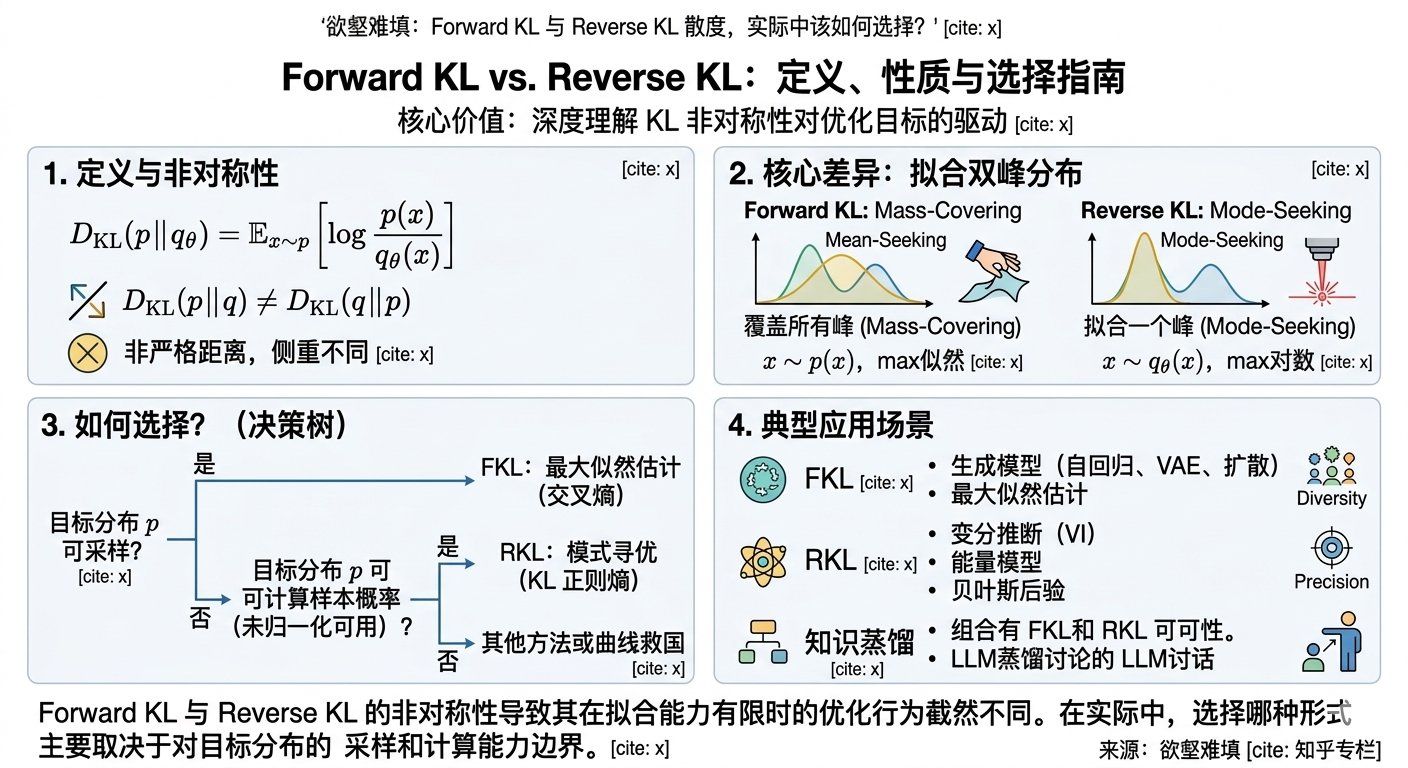
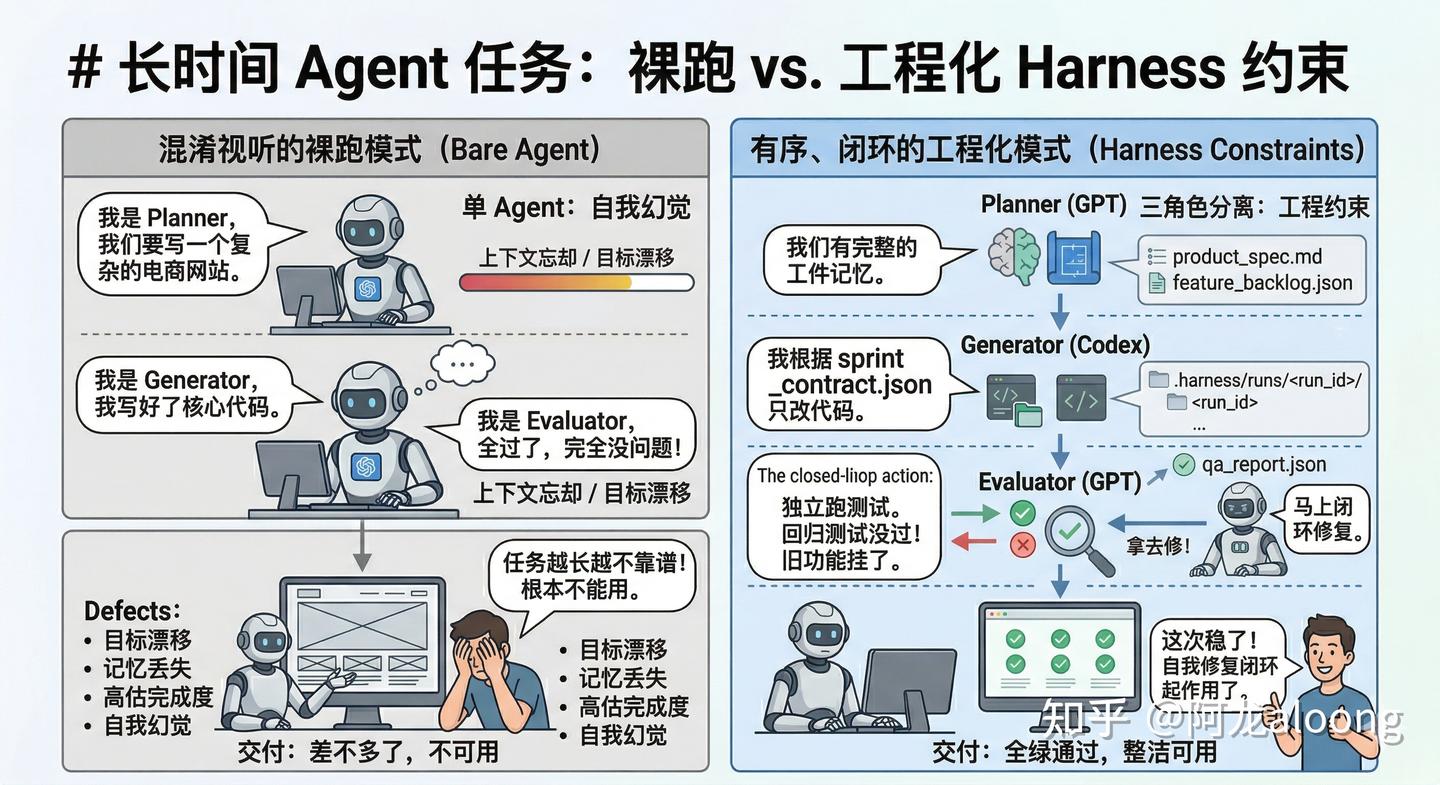
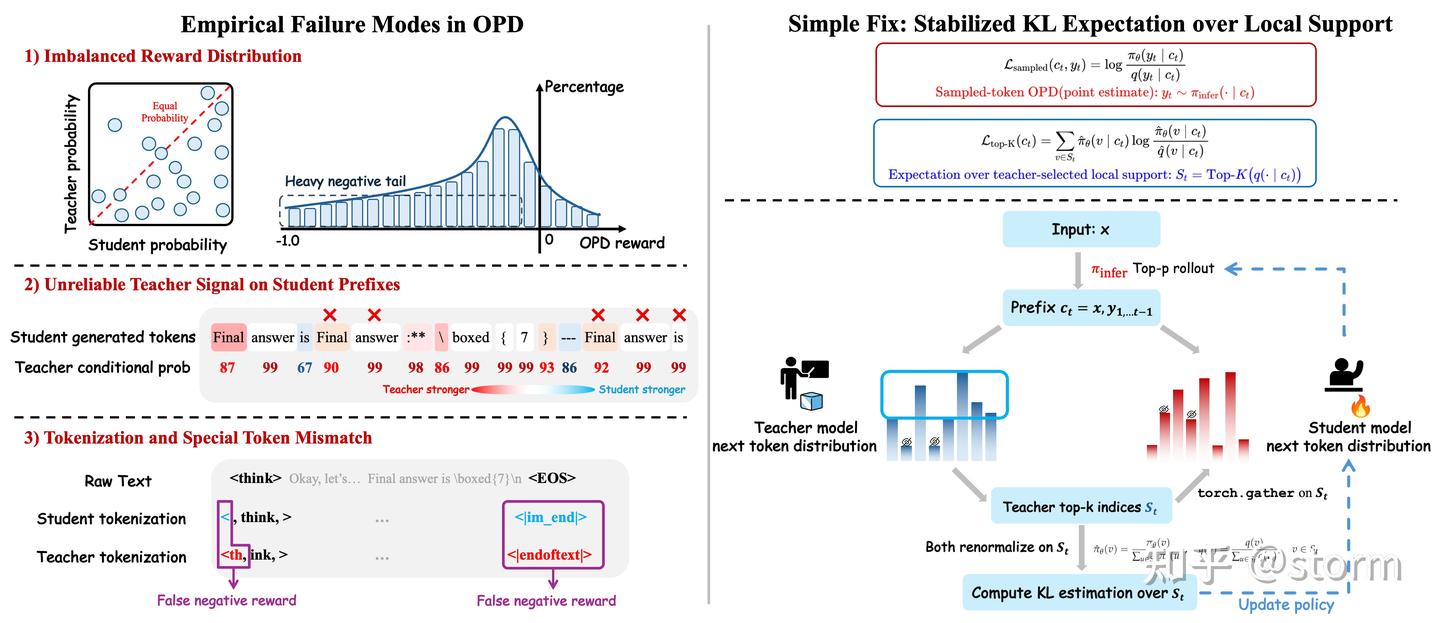
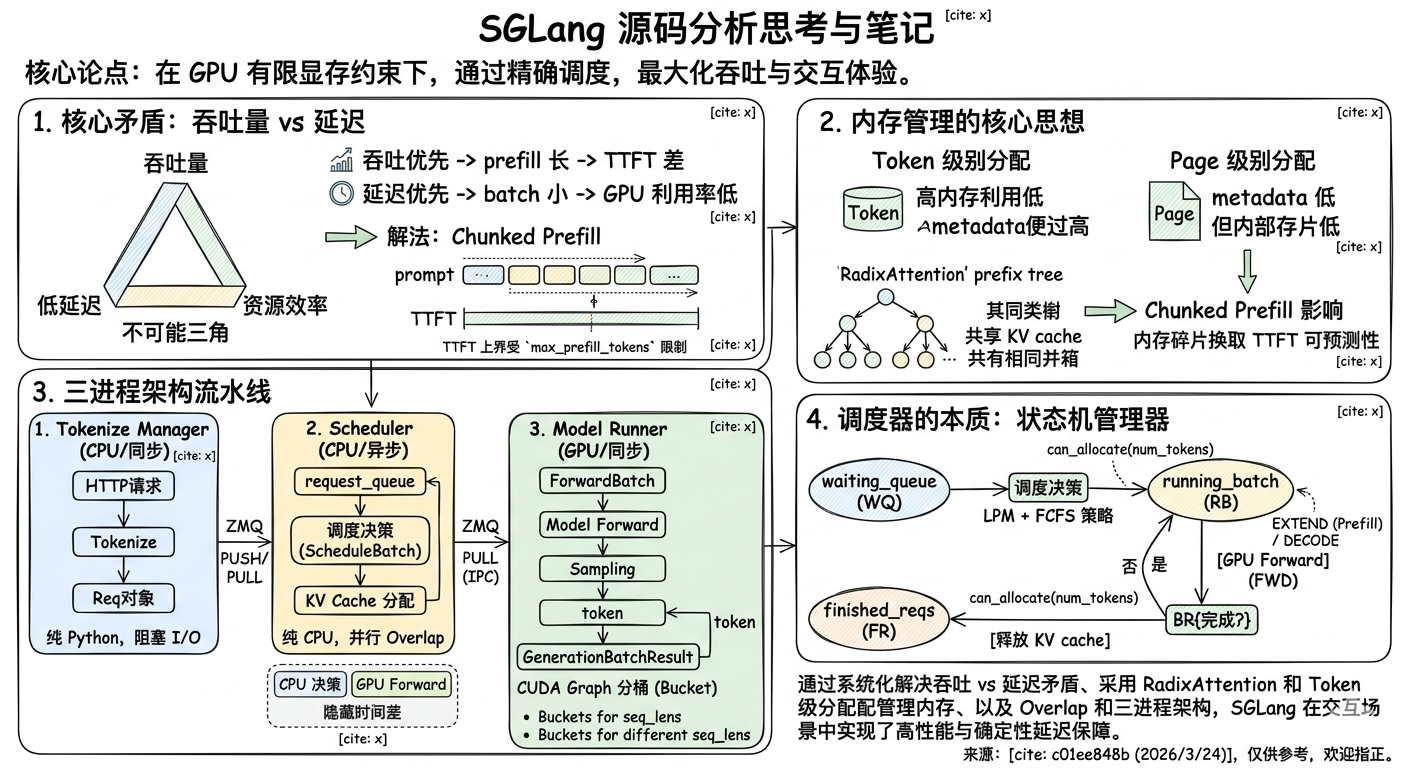
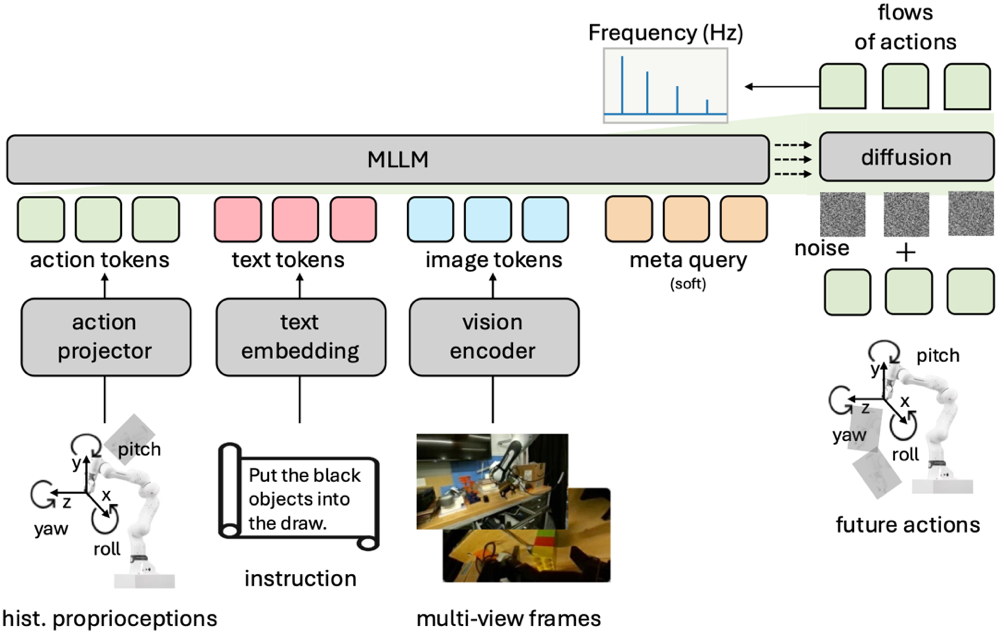


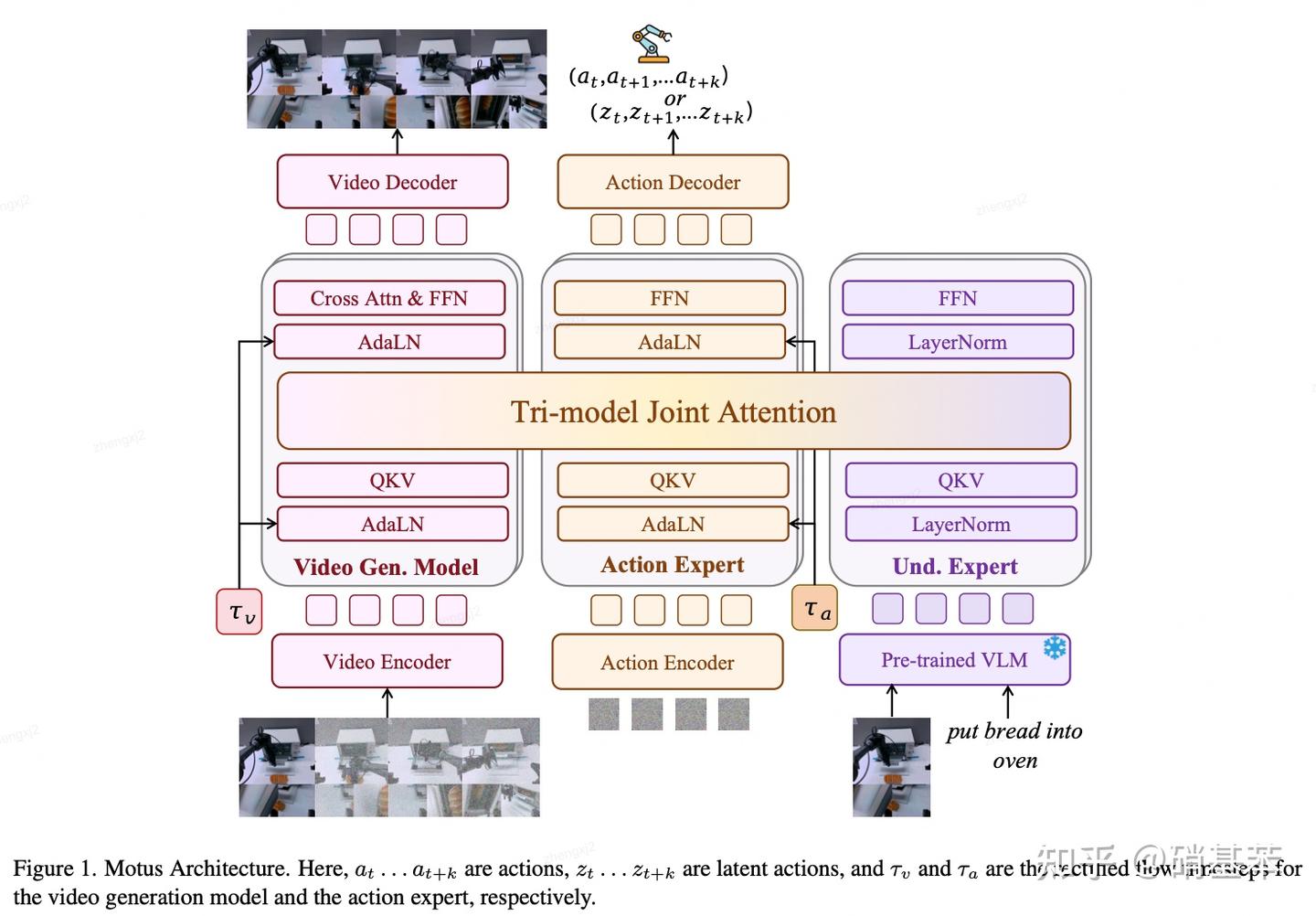
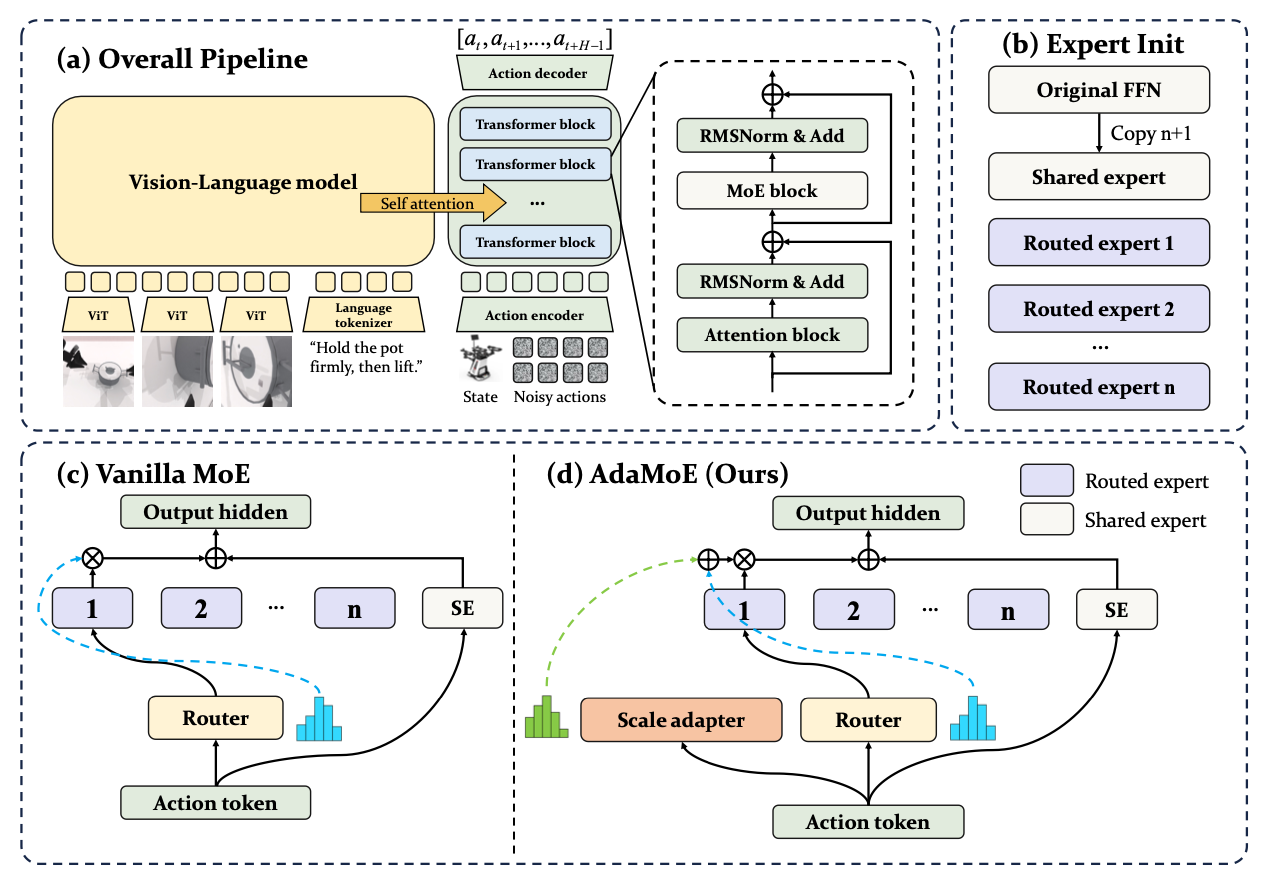
.png)

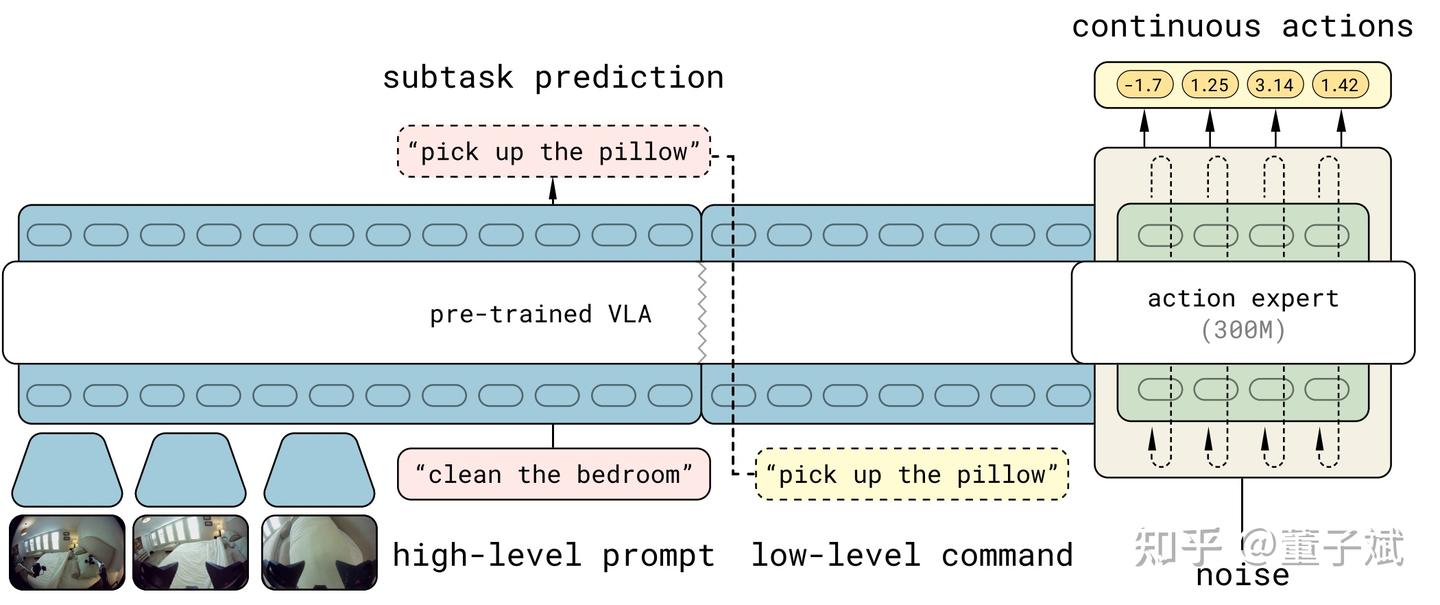
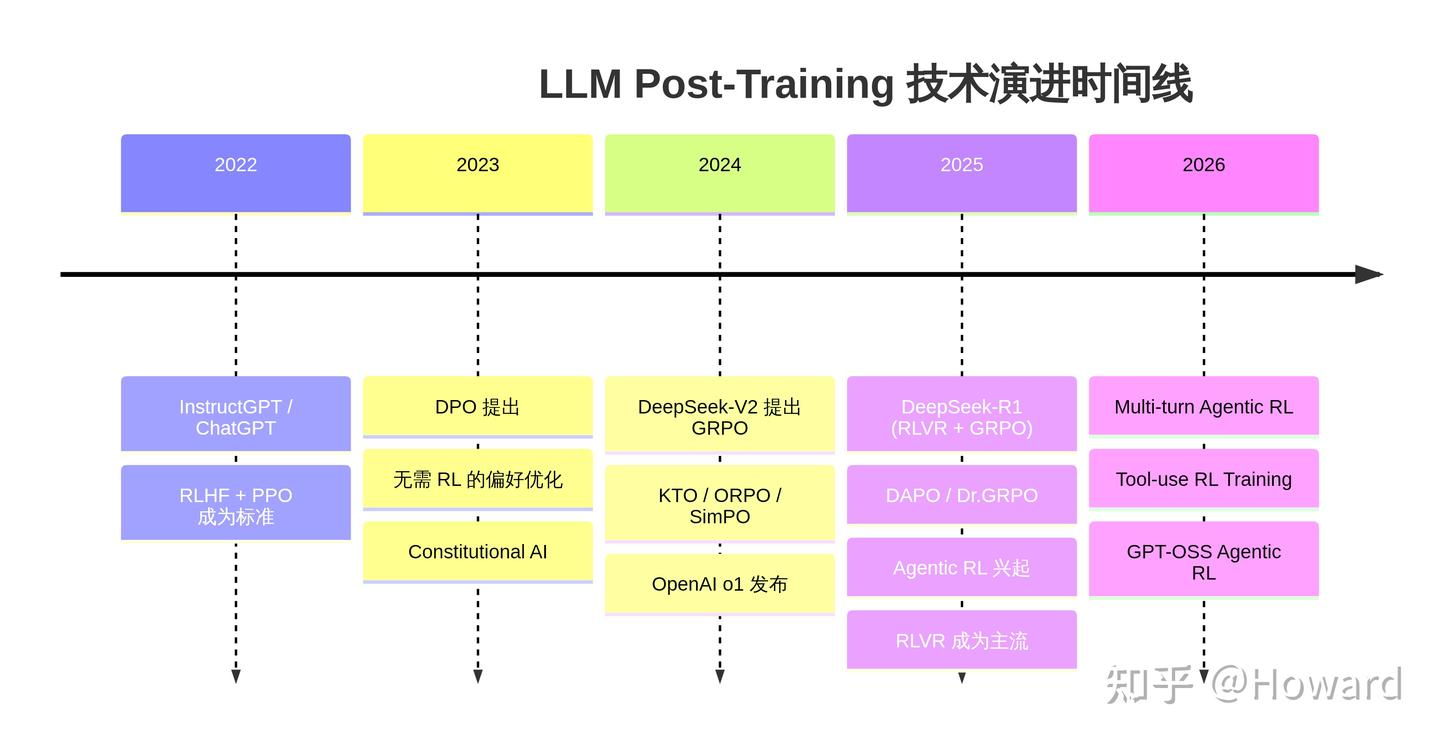
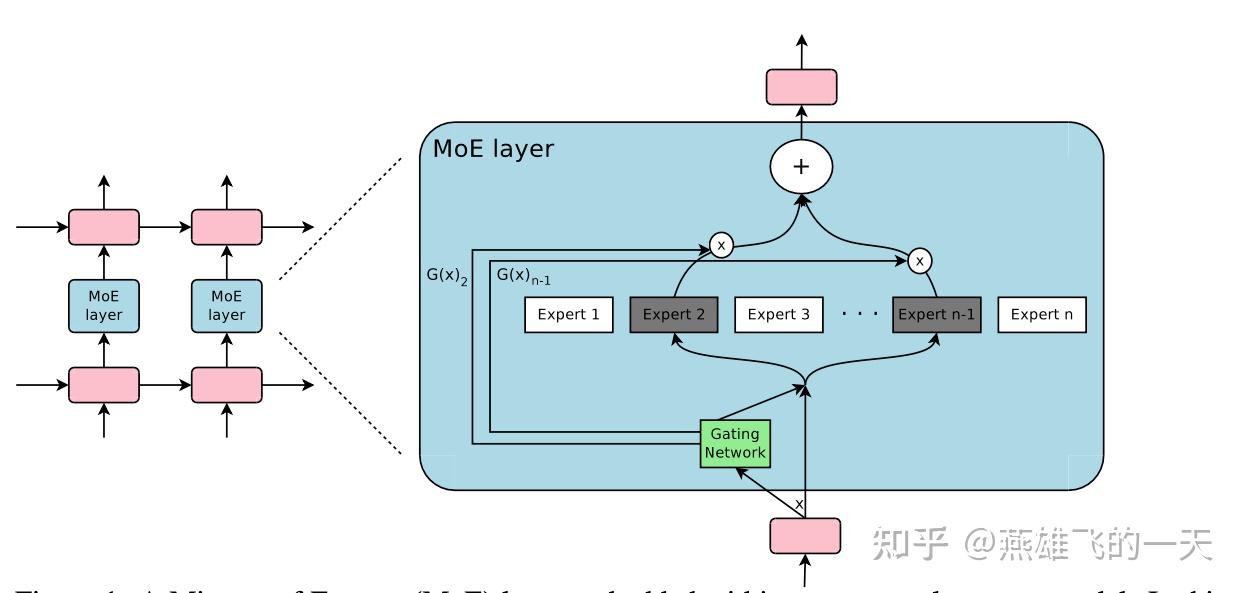
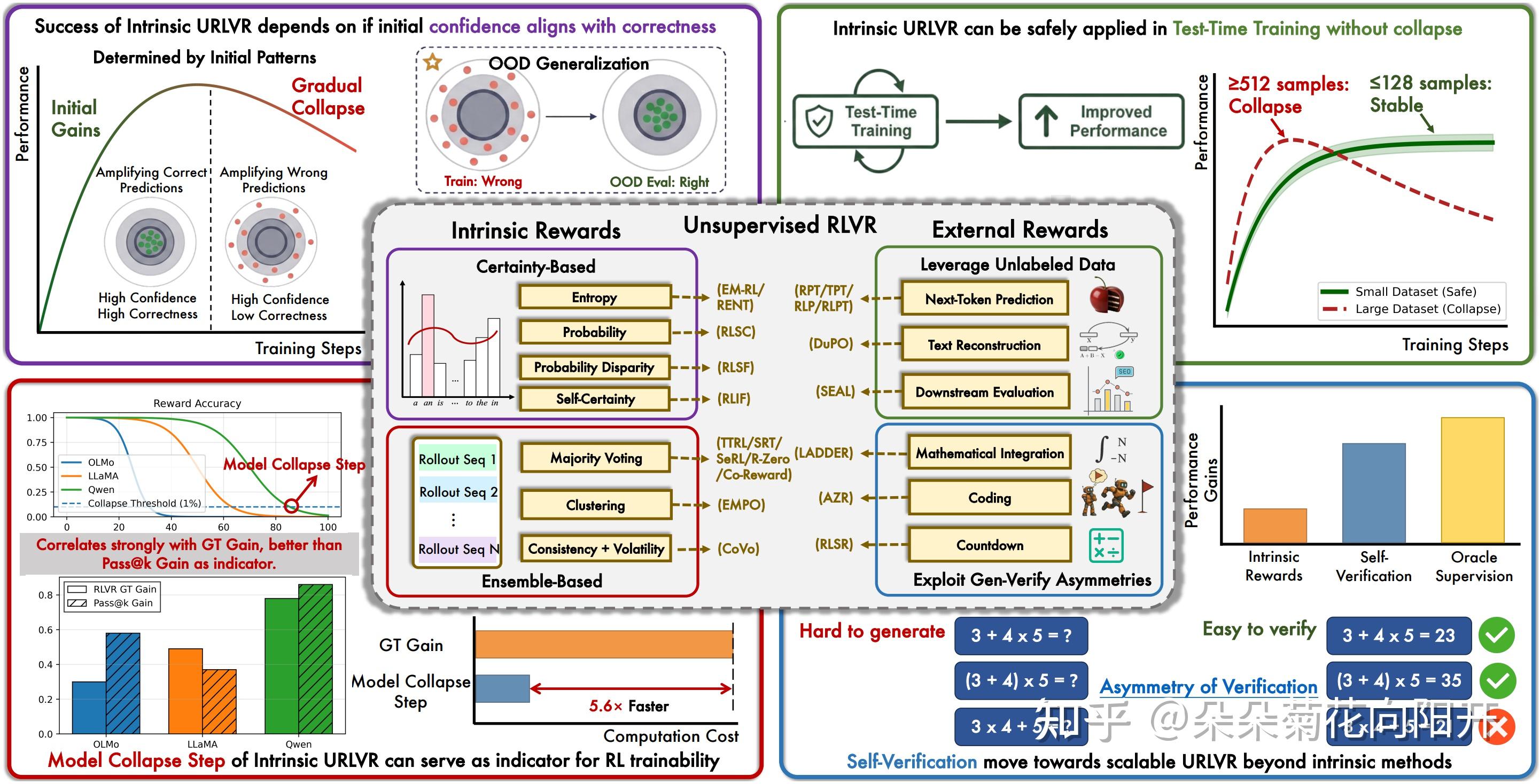
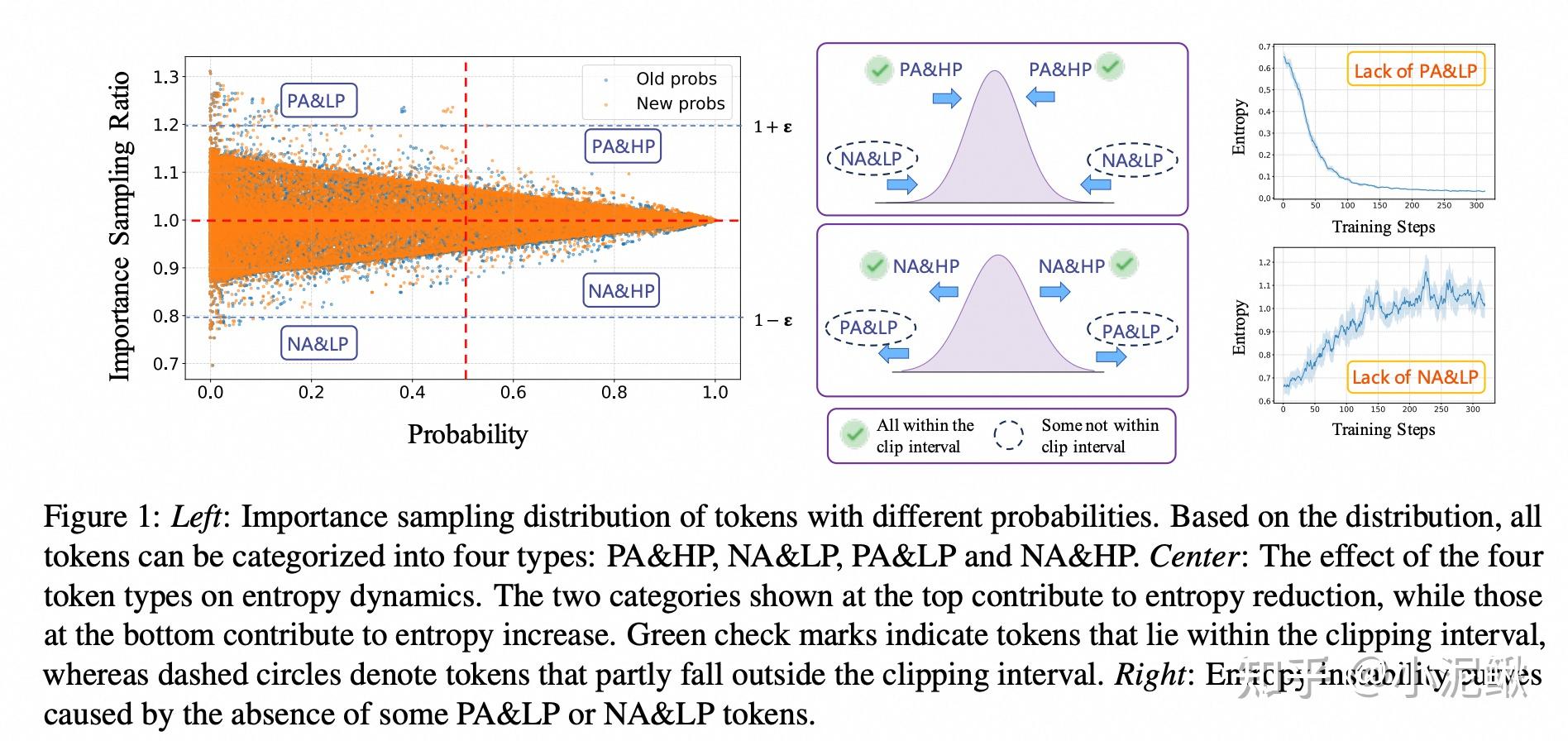
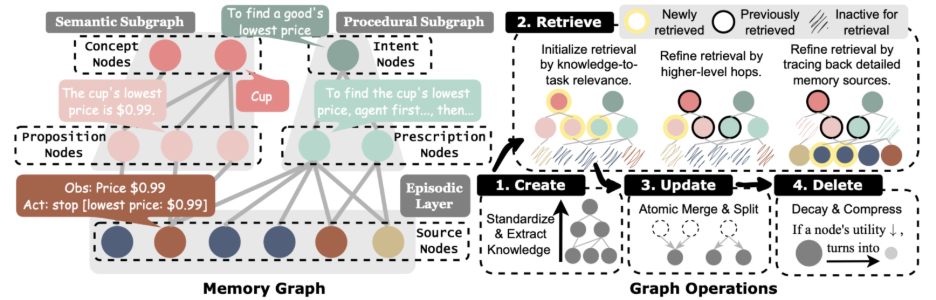
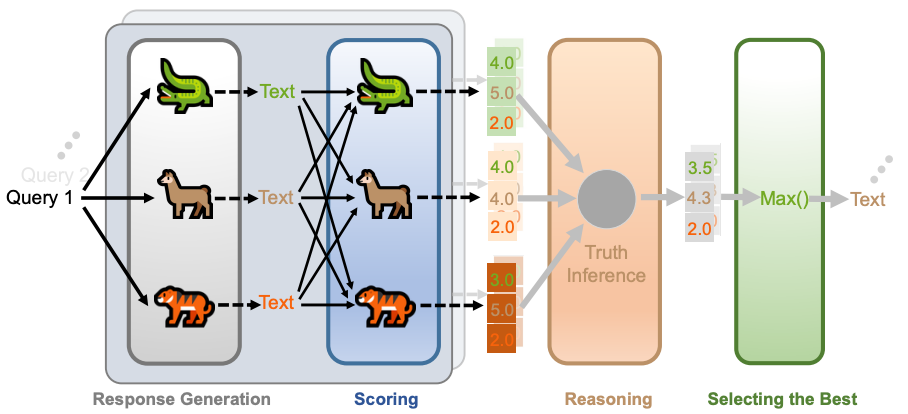
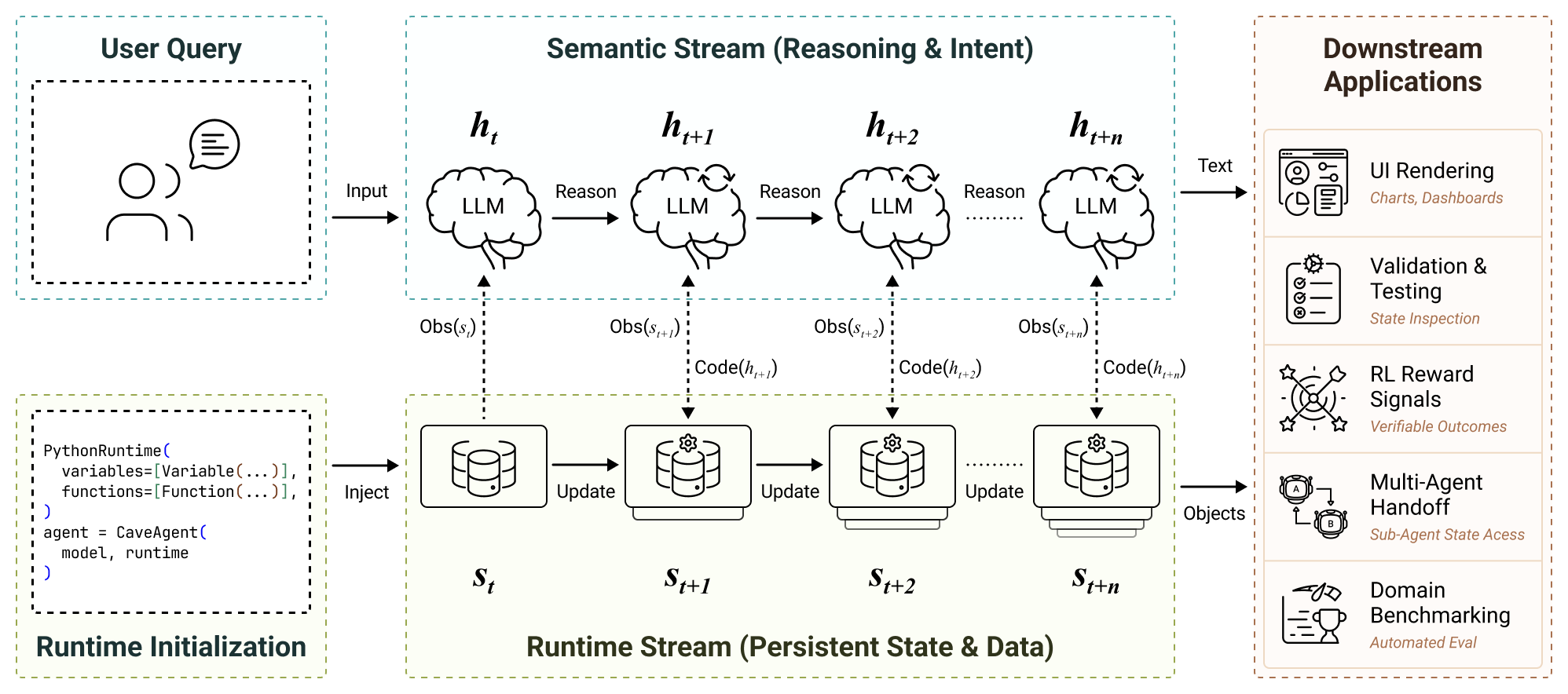
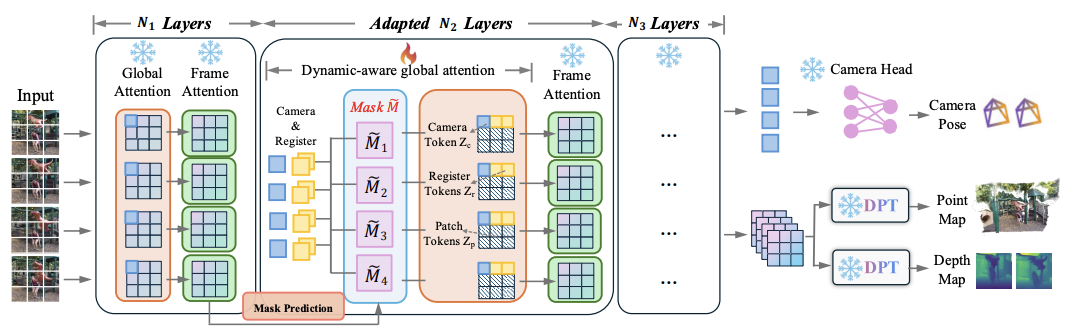
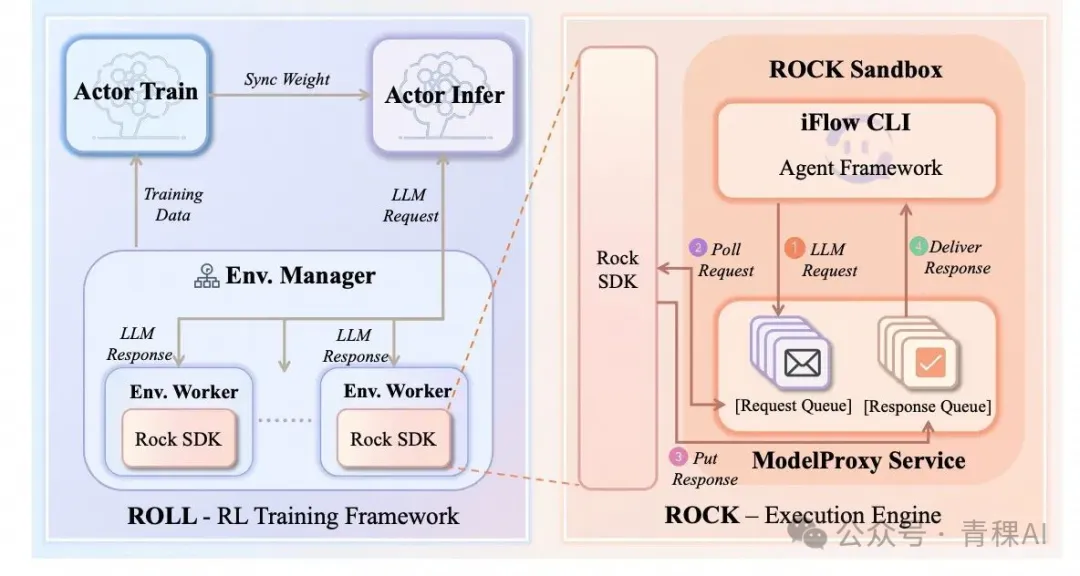
-tmMQ.png)

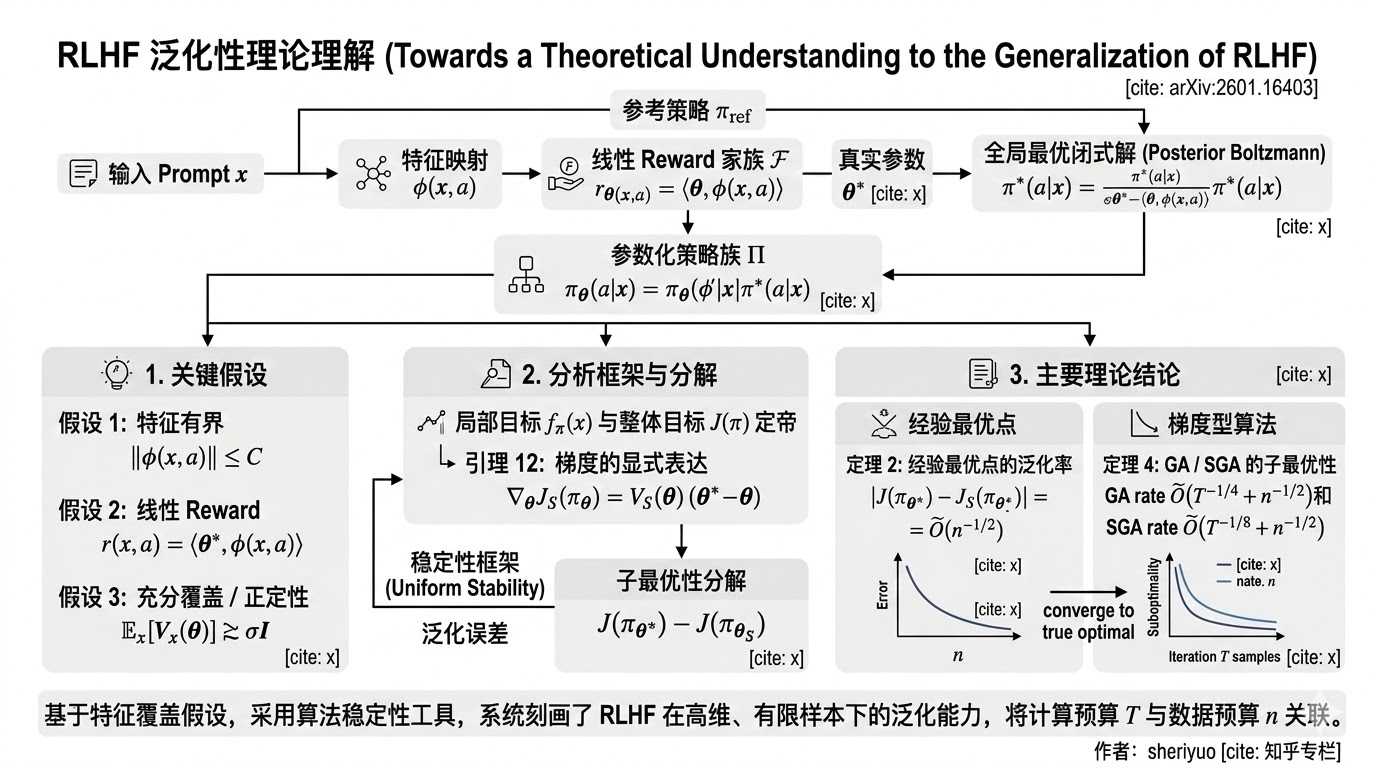
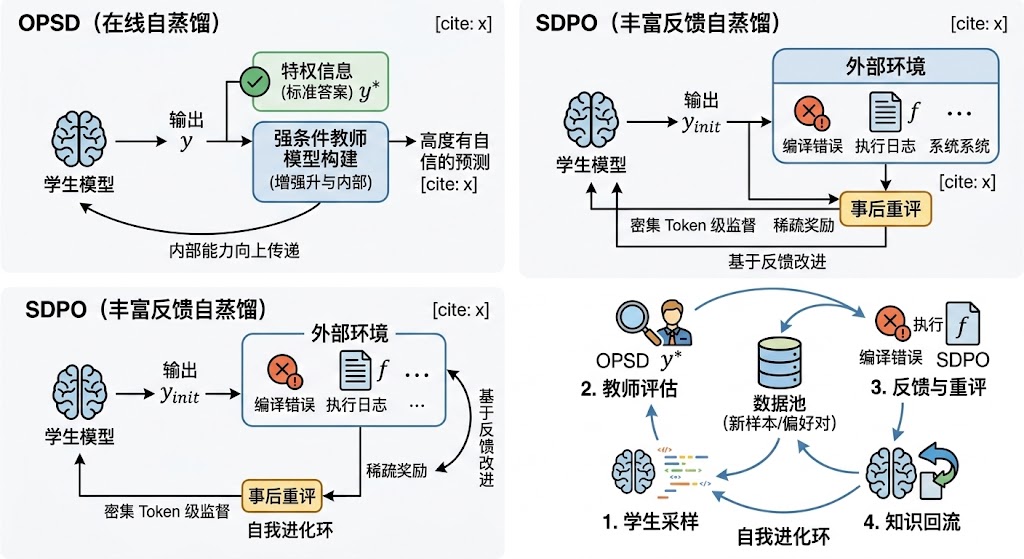
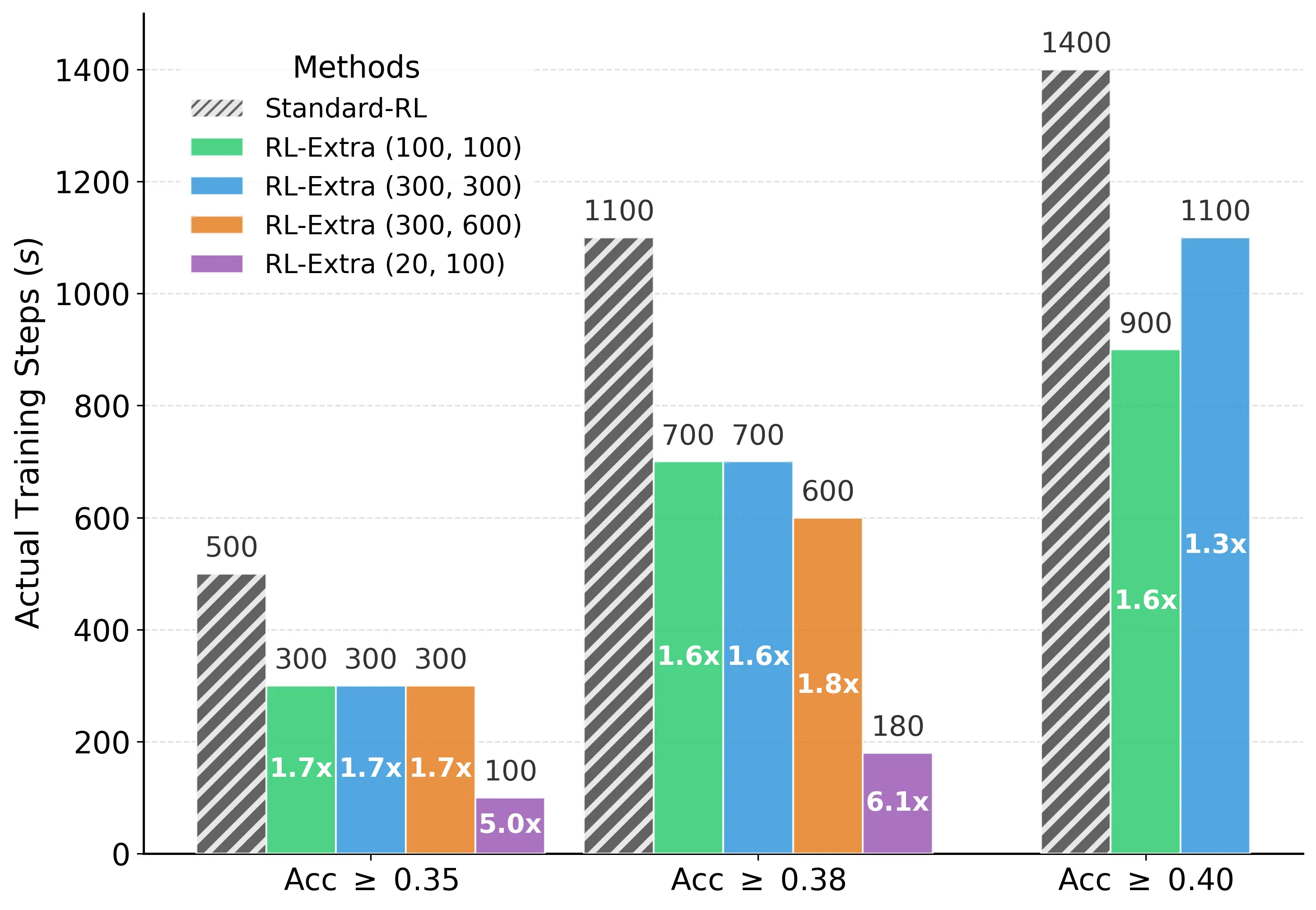
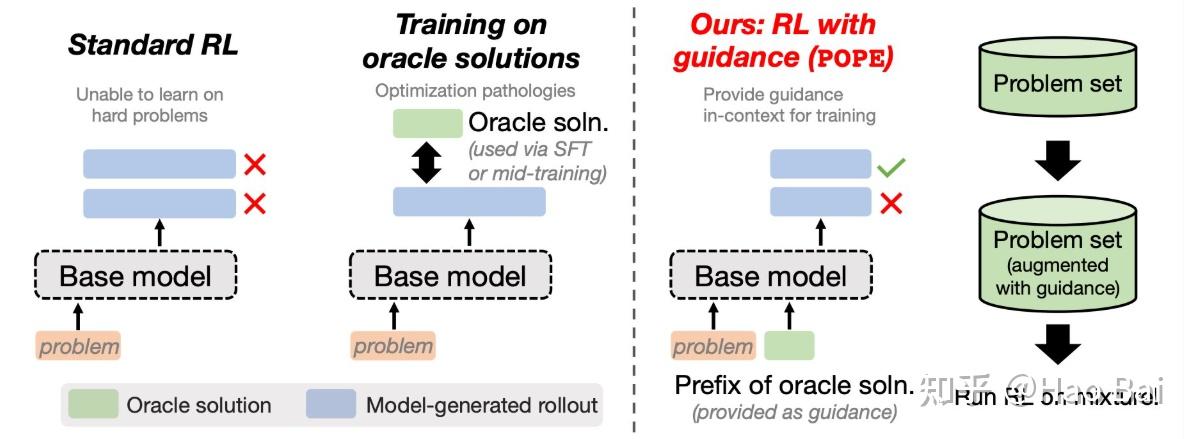
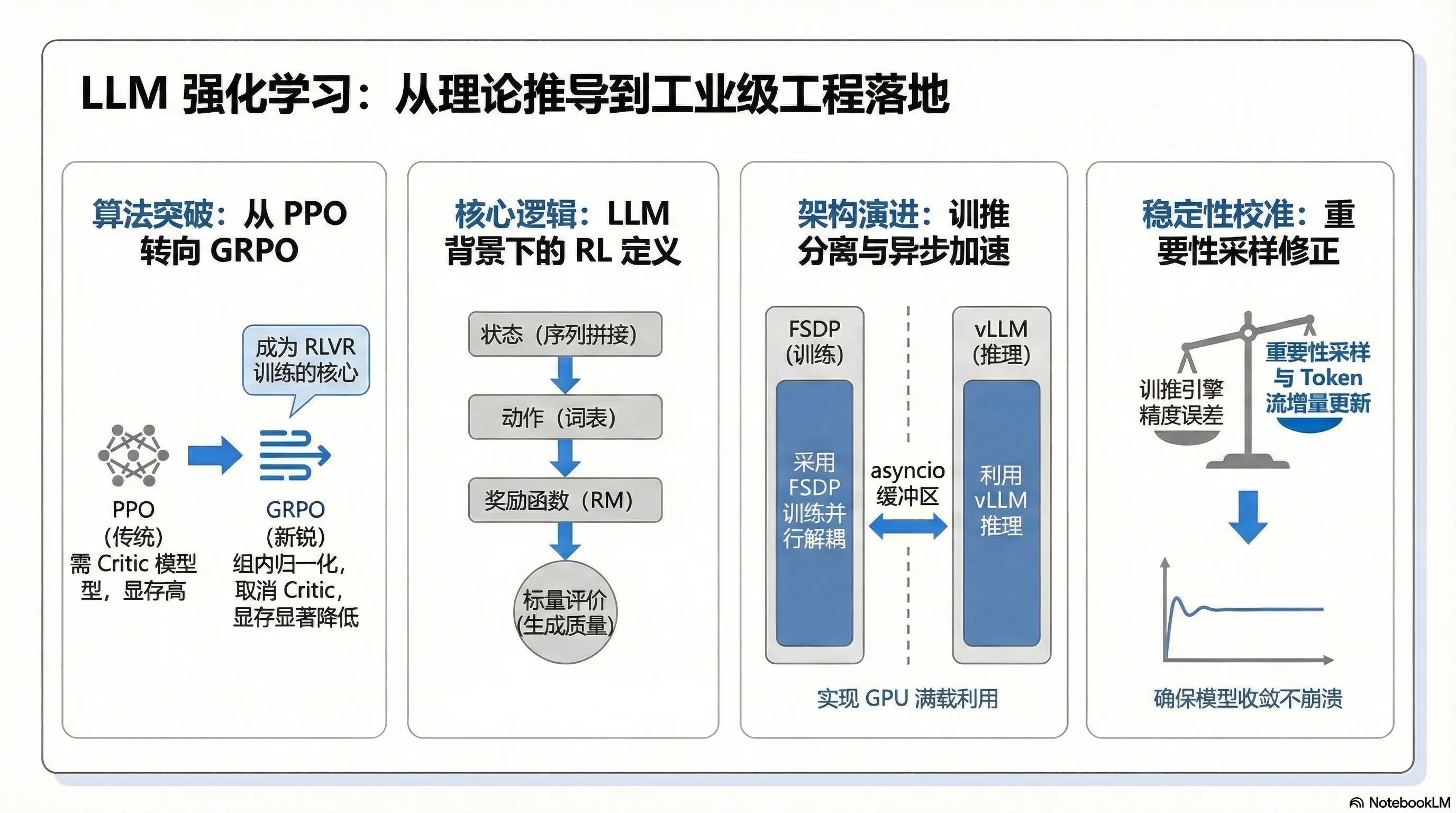




.webp)

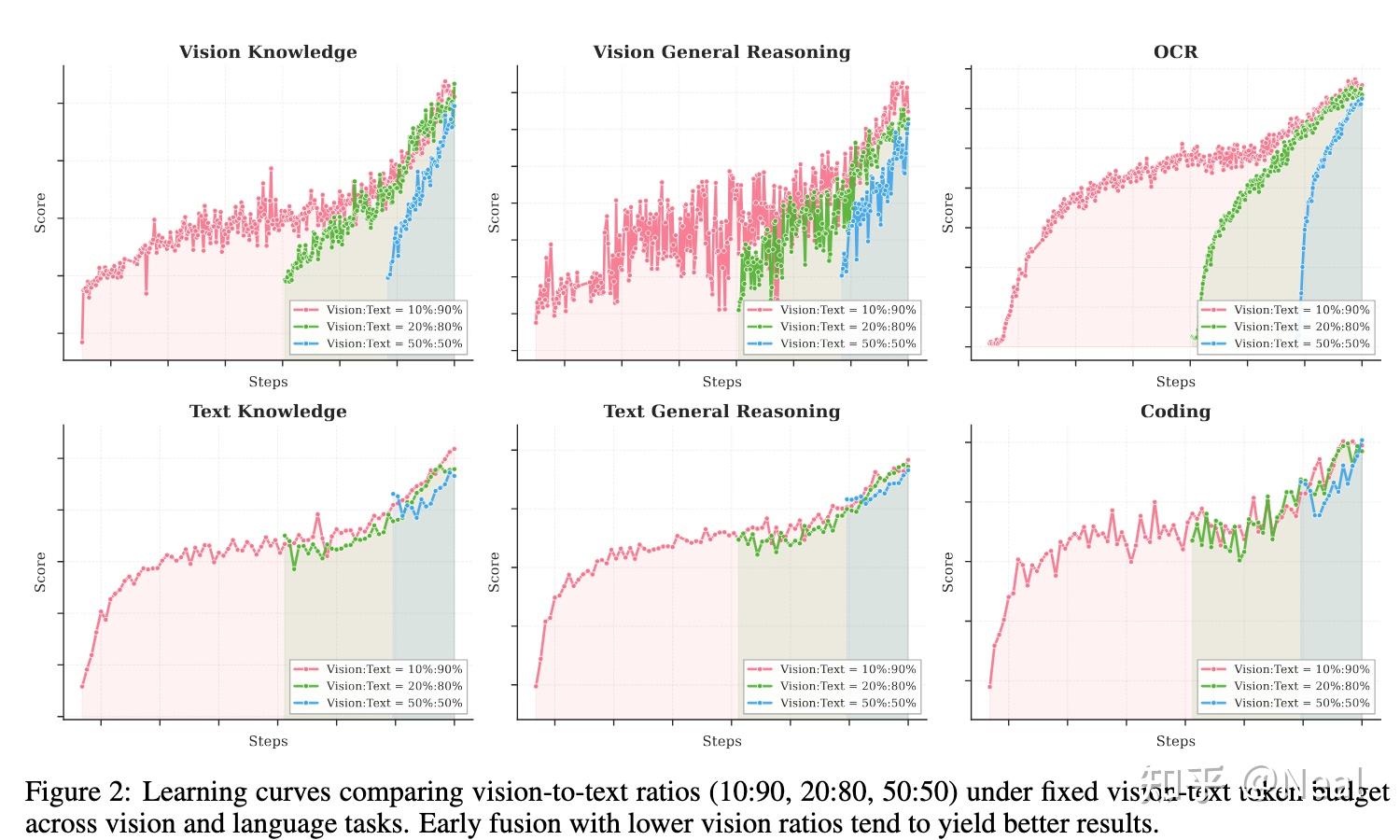

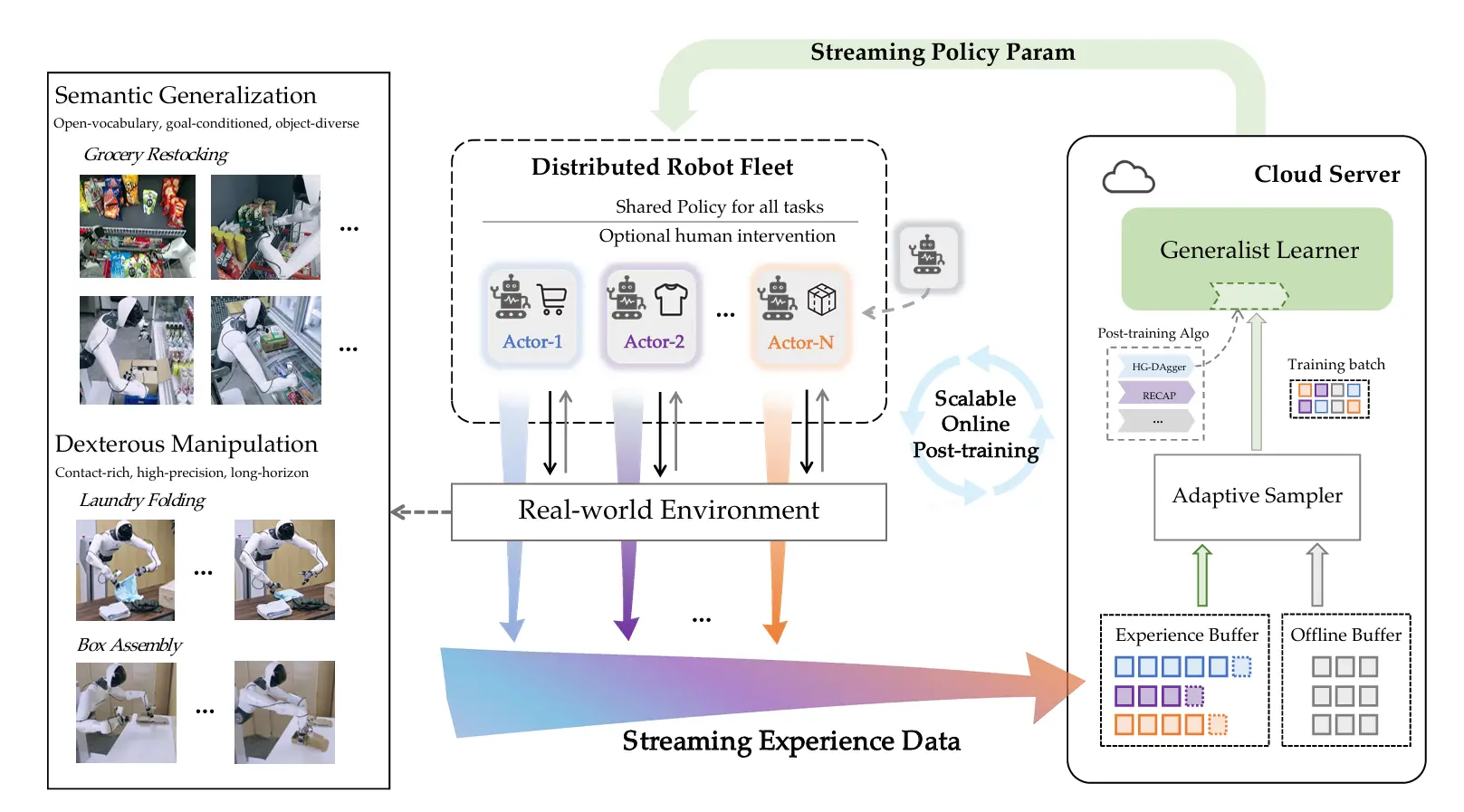




-ftxt.png)

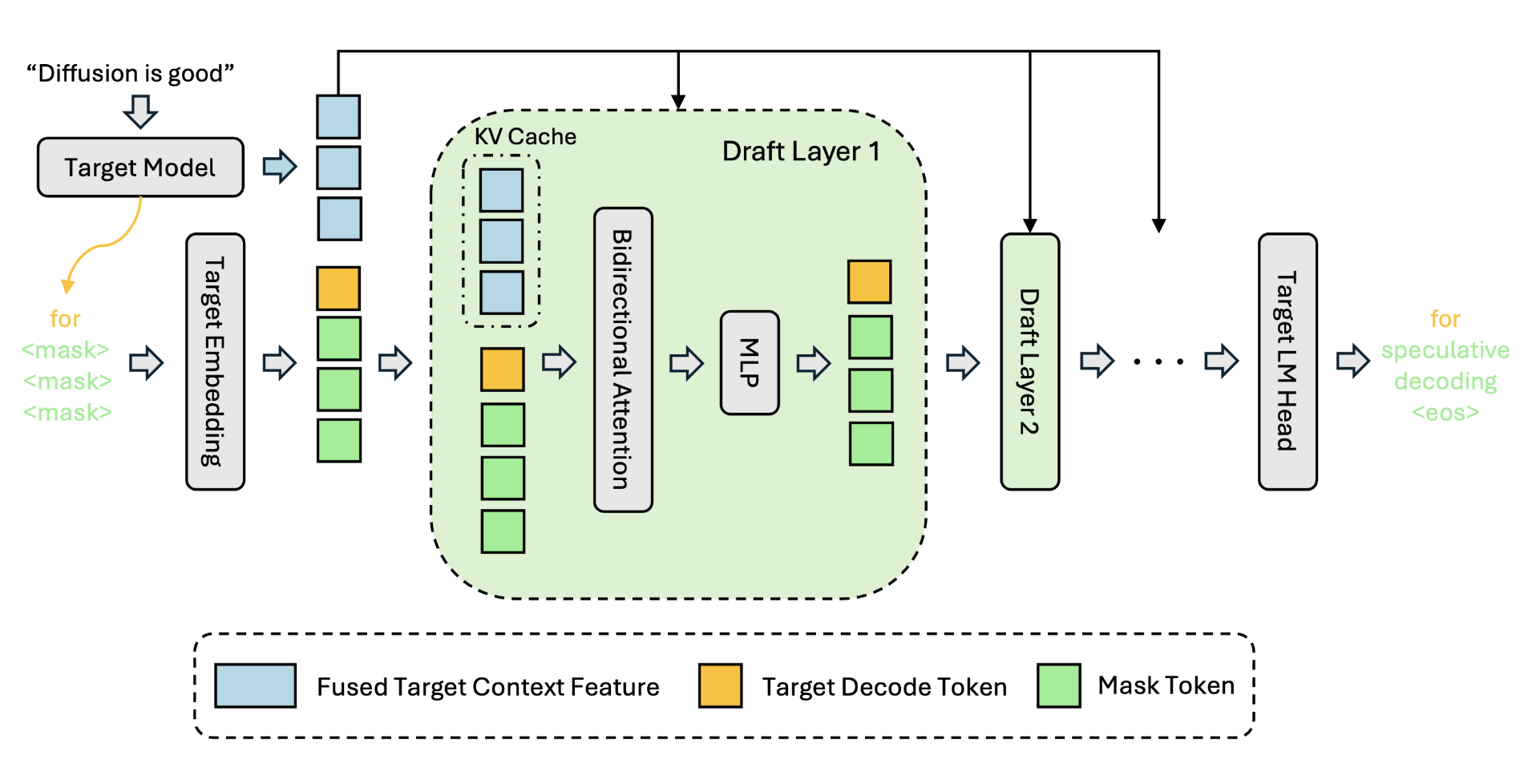
-AXSE.PNG)

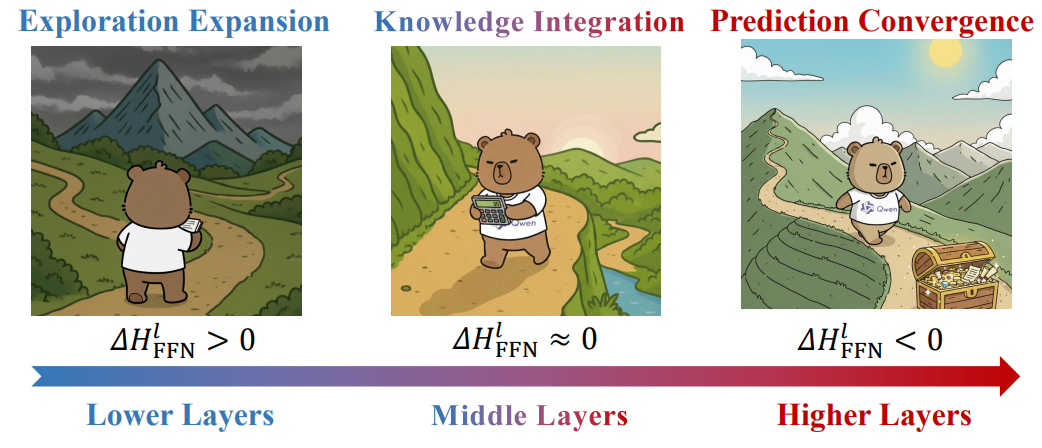
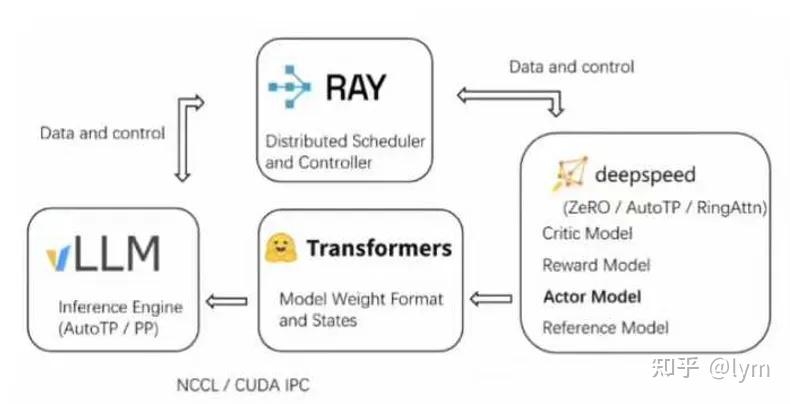
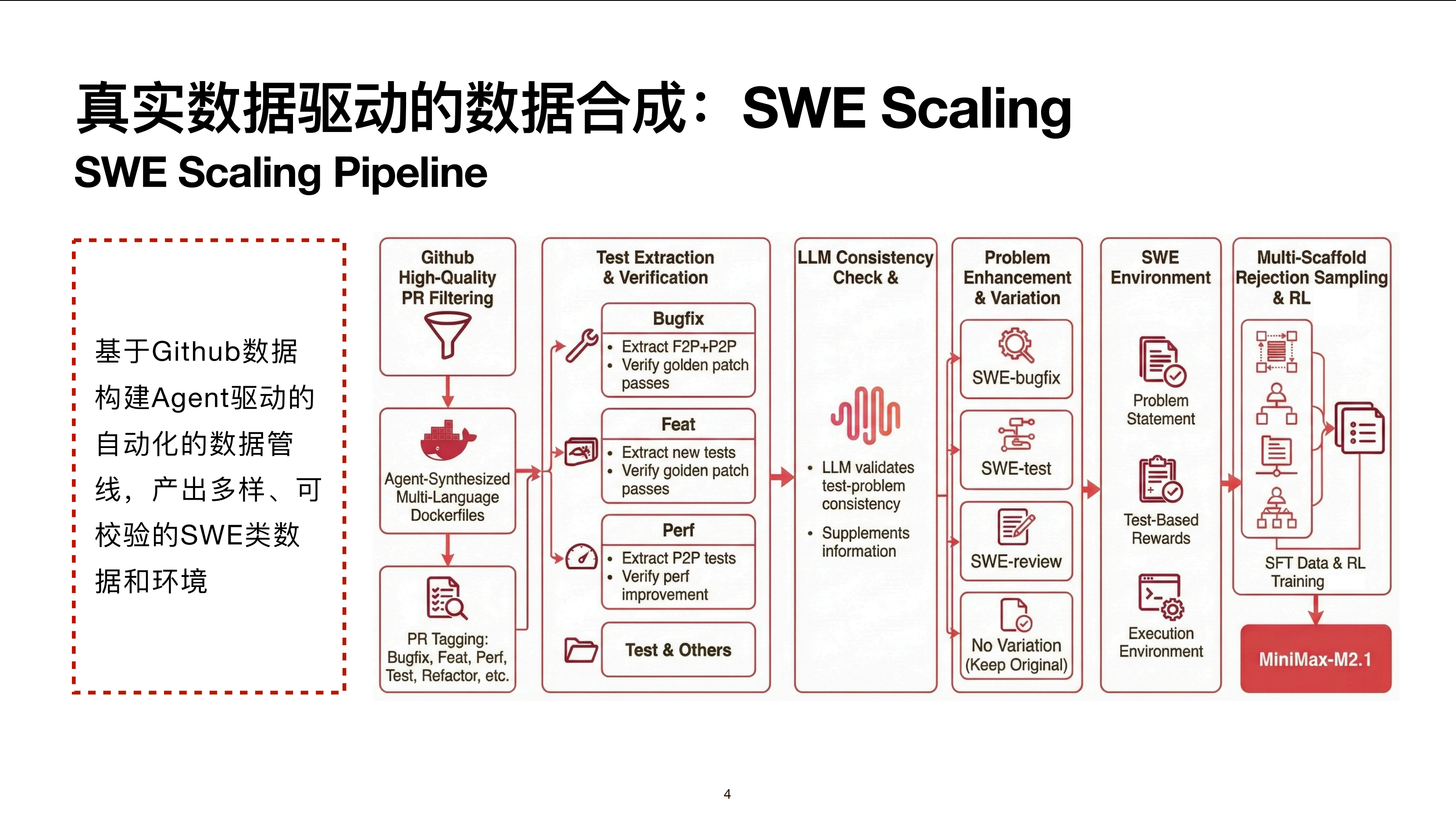
.png)
-obJS.png)
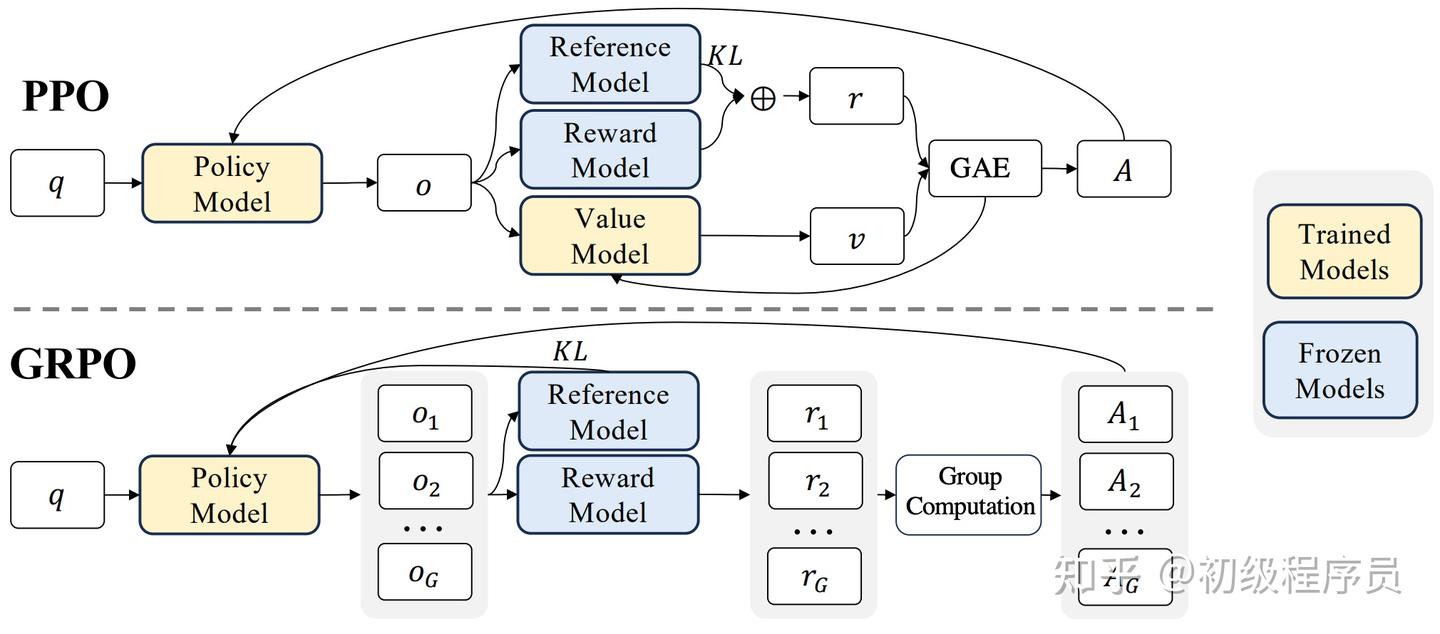
.png)
-KKeY.png)
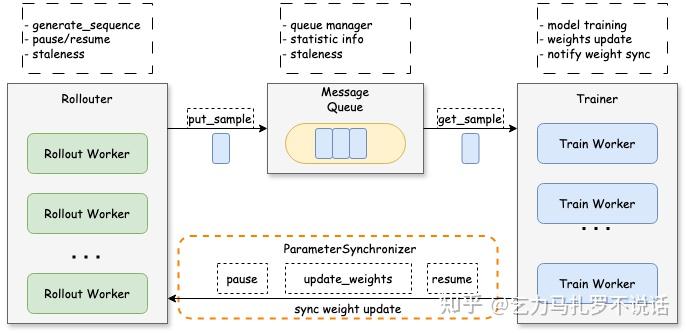
.png)
.png)