
内容基本按照:这篇文章要解决什么问题?解决思路与和现有路线的不同,创新点的直觉 & 如何解决,实现/落地层面的要点与坑,潜在价值等内容组织,希望对读者有启发。
Neural MP: A Generalist Neural Motion Planner
https://arxiv.org/pdf/2409.05864
这篇文章要解决什么问题?
传统运动规划(采样、搜索、轨迹优化)基本上每个新场景都要从零规划,复杂/拥挤场景常常需要几十秒到分钟级;而人类可以依赖“经验”快速在闭环里反应与避障。作者要把这种“经验”蒸馏成一个通用神经策略,让同一套策略在大量、风格各异的场景里快速出解,并通过轻量的测试时优化保证真实世界安全可执行。

简述:他们先在仿真里大规模生成复杂场景,用传统专家规划器收集轨迹,再拟合成一个反应式通用策略(如下图);部署时再叠加轻量的测试时优化来挑选无碰路径。同时论文主页/摘要将方法概括为“三步”:大规模程序化场景→多模态序列建模拟合专家→轻量测试时优化。

解决思路与和现有路线的不同
方法三要素:
数据: 程序化生成 + 真实感网格(Objaverse)组合出大规模多样场景;并给出生成细节/算法(Alg.1,如下伪码;同时,参考下下图左)。作者指出常见基准数据集(如 MotionBenchMaker)在真实感和多样性上不足,以致泛化弱。

模型: 把状态/目标/环境表示输入到序列模型(论文最终选 LSTM,),动作头用 GMM (Gaussian Mixture Model)建模多模态分布;作者做了系统消融对比 MLP/Transformer/ACT 与不同损失,结论是 LSTM + GMM 对多模态和推理时延最均衡(如下图中)。
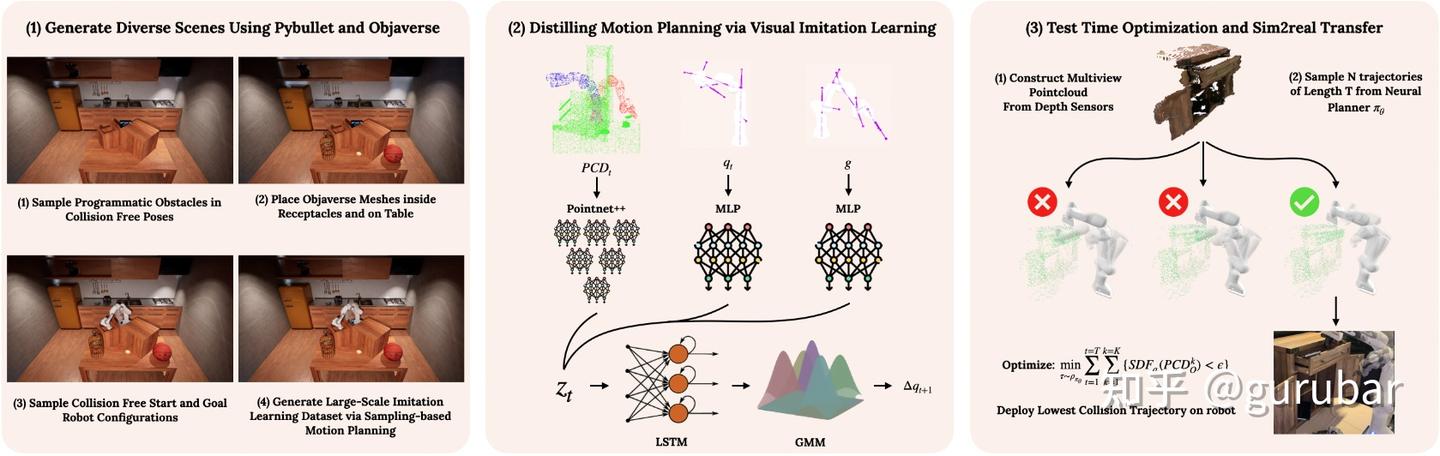
测试时优化(轻量): 从策略采样多条轨迹,用机器人-场景 SDF ( Signed Distance Function)交并度估计碰撞风险,只选择不碰撞(或最近似)轨迹执行(如上图右;
整个方法先用仿真+真实感网格生成“杂乱场景里的专家演示”大数据,再把传统“采样式规划器”[用经典的采样式运动规划算法(如 PRM、RRT/RRT*、BIT*、FMT* 等)在已知几何的仿真环境里,为给定起点与目标求一条无碰撞路径/轨迹] 的能力蒸馏进一个点云→关节增量的时序神经策略;
上线时不盲信单次输出,而是从分布采样多条轨迹并用几何(SDF)打分择优,从而在真实世界里获得更快、更稳、更安全的避障运动规划);文中观测到约 25% 的策略采样无需碰撞,直接筛选即可显著提高成功率。
和已有路线的不同:
相比采样型(如 AIT*,arxiv)与并行优化(如 cuRobo,arxiv),Neural MP 不是在测试时“从零”搜索/多种子优化,而是先把“经验”蒸馏到策略里,再用非常薄的测试时筛选确保安全性,因此在真实世界实现了更高成功率且更稳定。
相比端到端学习(MPNet、MπNets、EDMP等),Neural MP 在数据构造与损失设计(程序化 + 真实感网格、GMM 多模态)与轻量筛选上更注重“实用与落地的可靠性”,并在作者复现实验里显著超越这些学习基线。
| 方法 | 核心思路/类型 | 训练需求 | 典型推理/规划 | 论文中报告的成功率* | 主要优点 | 主要短板/风险 |
|---|---|---|---|---|---|---|
| AIT* | 采样 + 自适应启发式,渐近最优 | 无 | 10–80s 级(文中两设定) | 45.83%(10s)/72.92%(80s) | 有理论保证,广泛适用 | 对窄通道/高维慢,需调启发式 |
| cuRobo | GPU 并行多种子轨迹优化 | 无/少量 | 20–50ms 级(论文) | 79.17% | 极快、工程化强 | 多种子也可能卡住窄通道/视觉碰撞误判 |
| MPNet | 点云→端到端路径(早期) | 需要 | <1s(作者原文) | —(本文未复现实验表) | 端到端快 | 泛化/安全性受数据与损失限制 |
| MπNets | 单深度相机→反应式策略 | 需要 | 毫秒级策略前向 | 16.67%(真实任务,本文复现)/作者称快且鲁棒 | 反应快、端到端 | 本文指出损失与数据偏置致泛化差 |
| EDMP | 扩散模型 + 成本集合引导 | 需要 | 100ms–秒级(典型扩散) | 82.37–88.72%(仿真复现实验) | 结合学习与代价引导,性能强 | 推理较重,落地需工程化 |
| Neural MP(本文) | 大规模蒸馏的通用策略 + 轻量测试时优化(SDF筛选) | 需要(程序化 + Objaverse) | 策略前向 + 采样筛选(~1–3s) | 95.83%(真实)、90.13%(仿真) | 泛化强、成功率高、落地考虑充分 | 数据/标定质量敏感,仍需轻量筛选 |
创新点的直觉 & 如何解决
把“从零搜索”换成“先学经验再小修正”:人类靠经验快速动,偶有擦碰就微调;Neural MP 先把大量专家规划“蒸馏”成可泛化的多模态策略,在测试时采样多条轨迹,用SDF 快速估碰撞,挑最安全的那条执行——既保留“反应式速度”,又通过极薄的后处理把回归误差引起的“轻微擦碰”过滤掉。
数据即能⼒的上限:大量程序化场景 + 真实感网格(Objaverse)解决了以往学习型方法“数据窄/几何单一→泛化差”的瓶颈;验证了不同数据源训练的泛化差异(Neural MP 数据 > MπNets/MotionBenchMaker)。
设计细节服务于“可落地”:消融显示 GMM 损失 > L1/L2/点匹配;LSTM 与 Transformer性能相近但LSTM 延迟更低;历史长度过长反而伤性能。整体配置就是为了高成功率 + 低时延的最佳点。
实现/落地层面的要点与坑
传感与标定:SDF/点云质量直接影响“碰撞筛选”的可靠性;作者也观察到视觉碰撞检查在窄通道容易误判,从而影响 AIT*/cuRobo 与策略筛选效果。
数据生成:程序化资产与 Objaverse 混合是关键,但也要控制几何分布/尺度/材质的多样性,避免数据与真实分布错位(文中也在 in-hand 的 OOD 物体上出现退化)。
推理延迟预算:作者在真实实验里用 ~1s 基础策略 + ~3s 采样筛选即可达到 SOTA 成功率;若要更严格的“最远离障选择”还可继续优化但可能增加延迟。
架构与损失:若改用 ACT/点匹配等损失,多模态/姿态歧义会显著拉低成功率(如端位姿 0°/180°不可辨);GMM 更适合“多解”的规划分布。
与已有系统集成:Neural MP 的输出是安全轨迹,可作为 cuRobo/优化器的warm-start或与采样法混合(文中也测了 Global/Hybrid 专家配置),工程上易于渐进替换。
潜在价值
真实世界的“通用规划器”雏形:同一策略跨多环境/多任务/带物体与动态障碍,论文报告对采样、优化与学习基线分别提升 23%、17%、79% 的成功率。
从“离线经验”到“在线稳健”的实用范式:把大规模离线蒸馏与在线极薄筛选结合,给“学习型规划”提供了一条可落地、可控风险的路径(尤其适合工厂/仓储里“多变但同类”的任务)。
数据引擎可持续扩展:程序化资产 + 开放 3D 资源(Objaverse/Objaverse-XL)意味着可以持续扩容经验覆盖面,提升 OOD 稳健性。
与经典/系统化方案互补:在需要极限时延时,可把策略作为并行优化/采样的先验;在需要最强成功率时,则采用“策略 + 轻量筛选”组合,形成速度-成功率可调的工程拨盘。
Interactive Navigation for Legged Manipulators with Learned Arm-Pushing Controller
https://arxiv.org/pdf/2503.01474
文章要解决什么问题?
传统移动/足式机器人在“可移动障碍物”的场景里,常因机体宽度受限或空间狭窄而无法用机体去挤/顶开障碍;而现有“交互式导航”多数依赖机体推挤或仅做可通行性评估,缺少可在狭窄空间中精确、稳定地重定位障碍的手段。
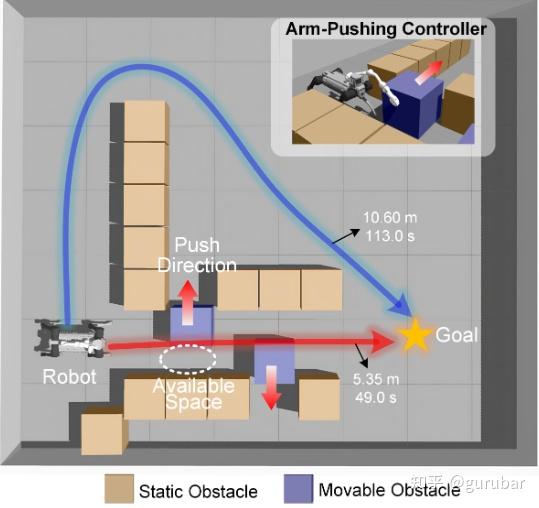
本文目标是:在已知地图、已知“哪些障碍可移动”的前提下,让带机械臂的足式机器人通过主动手臂推挤清障,从而显著缩短路径与时间,实现更高效的到达。文中在仿真与真实机器人(Unitree B2 + Z1 Pro,On-board Jetson Orin)上验证了相较“非交互导航/机体推挤”的路径更短、耗时更少。
解决思路 & 与典型工作对比
总体框架(如文中 Fig.2):
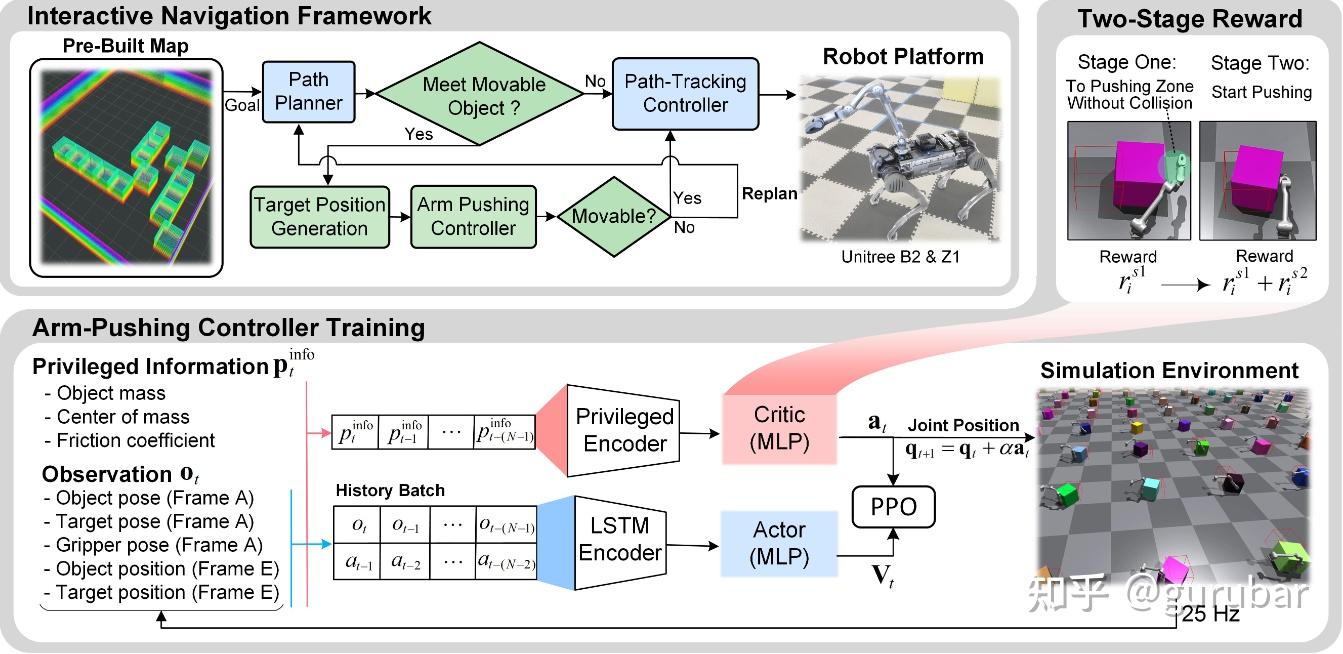
(1) 全局用 Hybrid-A* 规划粗路径,并以“需要推挤的时间成本”修正代价;随后用 QP(OSQP)在可行域内平滑;
(2) 当检测到路径与“可移动障碍”相交且进入交互半径时,采样目标位姿并选择最近的可行“目标推位”;
(3) 触发基于RL的手臂推挤控制器实现物体位移;若发现不可移动则回退为“将其视作静态”的重规划。
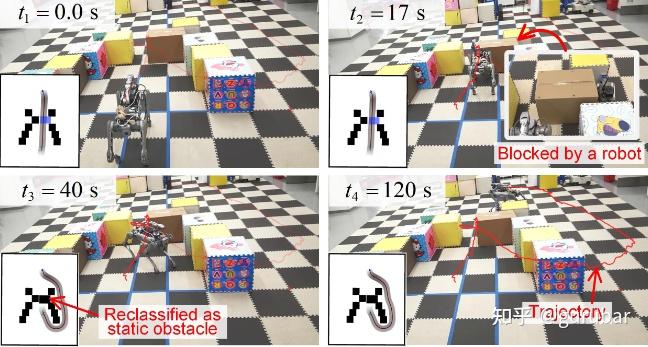
推挤策略在 Isaac Gym 中以 PPO + 1024并行体训练,并提出两阶段奖励:先引导末端进入“推挤区”(几何可行/避免碰撞)→再激活任务级奖励(稳定/防倾倒/朝目标推进),显著改善收敛与长期性能;并通过参数随机化+WBC(全身控制)做 sim-to-real。
| 方法 | 核心思路 | 交互对象 | 规划/控制 | 适用空间 | 文章要点/结论 |
|---|---|---|---|---|---|
| NAMO(Stilman & Kuffner, 2005) | 把“移动障碍”纳入规划搜索 | 障碍整体位姿 | 分辨率完备的可移动障碍规划 | 一般室内 | 奠基性理论框架,但对窄空间下的稳定接触/防倾倒未细化。 |
| IN-Sight(IROS’24) | 视觉自监督“可通行性/可互动性”评分用于路径 | 被动/轻度互动 | 端到端感知-规划 | ANYmal实机,较开阔 | 强化“看见-能过”的长程规划,但不做大物体稳定推挤控制。 |
| RL-Pushable-Objects(IROS’24,Yao et al.) | 机体/底盘与物体交互的RL本地规划 | 机体顶推为主 | A2C 多智能体 | 相对宽裕 | 能在仿真与实机推进障碍,但精细接触/窄道能力有限。 |
| Adaptive Non-prehensile Mobile Manipulation(2024) | 学习SE(2)物体动力学+MPPI | 机体/末端非抓取推挤 | 学习动力学+采样控制 | 一般室内 | 对未知物体动力学适应强,实机验证;未专攻狭窄处的稳定多接触。 |
| Planar Pushing RL(Multimodal Exploration)(IROS’23) | 桌面2D推挤,多模态探索 | 小型物体 | RL分类探索 | 桌面2D | 强调接触模态多样性,但与大物体/3D稳定推挤有分布差异。 |
| Dynamic Object Goal Pushing(CRL)(2025) | 约束RL实现目标位姿推挤 | 移动操作臂 | 约束RL | 一般室内 | 在四足+臂上实机≥80%成功率,注重防倾倒与不确定性鲁棒。 |
| 本文:Legged Manipulator + Arm-Pushing(2025) | 两阶段奖励RL + 目标推位采样 + 轻量重规划 | 大尺寸物体 | PPO策略+WBC | 狭窄&拥挤 | 真实实验:较“无互动导航”路径更短、时间更少;“机体推挤”易卡死。 |
创新点的直觉 & 机制
“先站好位,再稳推进”:大物体推挤的难点在于可行接触几何与防倾倒。两阶段奖励的直觉是把“到达良好接触区”的几何可行性与“稳定推进到目标”的任务可行性解耦;只有进入“推挤区”后才激活任务级奖励,避免早期就被稀疏任务奖励误导,显著提升探索效率与收敛。
“策略+轻量规划/筛选”的组合:用Hybrid-A*给出全局意图,局部用RL策略在闭环里细致地贴边/换接触面,必要时重规划回退,从而在狭窄处维持稳-准-快。
面向落地的训练与迁移:PPO + 1024并行actors(parallel actors)、课程学习(逐级目标点)、参数随机化(质量/摩擦/观测噪声)、WBC(whole-body controlle)扩展工作空间等组合,使策略对尺寸/质量/摩擦/形状具鲁棒泛化,并成功 sim-to-real。

实现层面的要点与潜在坑
前提与感知:默认已知地图并预先标注“哪些障碍可移动”;真实实验用动捕获取位姿→工程上应替换为稳健的在线感知与可移动性判定(语义/交互感知),否则对布置依赖较强。
几何与参数选择:推挤区半径/高度、激活距离 d_push、采样半径 r_push、路径代价中“推挤时间成本” c_t 等都影响触发时机与效率;需要与机器人尺寸/臂展匹配并经现场标定。
稳定接触/防倾倒:对高重心或易滚动物体,若末端入射角/力方向不当易致倾倒或反弹;虽然奖励中显式加入“防倾倒/对齐目标方向”项,但仍依赖接触估计与控制频率(文中策略25 Hz)。
窄空间的感知碰撞误判:狭窄夹缝中,视觉/几何误差会放大,可能导致错误的“可推/不可推”判断或路径碰撞判定,需要更稳健的距离场/占据估计。
系统集成:Hybrid-A*(全局)+ QP(平滑)+ PID(跟踪)+ WBC(全身执行)层次较多,接口与延迟预算要清晰(文中规划≈200 ms,策略+执行实时闭环)。
可能的价值
狭窄/拥挤环境的“可执行”交互式导航范式:相比“只绕行”或“机体硬挤”,用手臂稳定推挤显著缩短路径、降低通行时间,真实实验对比如图6/表IV所示(无互动导航约 113 s/10.7 m,本方法约 58 s/5.4 m;机体推挤易失败)。


与NAMO/自监督互动导航互补:本文把“能不能推、怎么推”落到了可学策略+几何先验的组合,能作为 NAMO 类全局搜索或 IN-Sight 类视觉互动导航的可执行后端。
可扩展的数据-能力闭环:两阶段奖励 + 课程学习易扩展到更多形状/材质/障碍布置;结合近期“移动操控推挤”工作(如约束RL防倾倒)可进一步提升鲁棒性。
行业场景:仓储理货、医院走廊、商场临时堆放等“可移动但随机摆放”的场所,部署价值直接;亦可作为通用导航栈的“交互模块”。
Autonomous Hiking Trail Navigation via Semantic Segmentation and Geometric Analysis
https://arxiv.org/pdf/2409.15671
文章要解决什么问题(Problem)
在森林徒步小径(hiking trails)等非结构化、强动态自然环境中,传统仅几何(LiDAR/高程)或仅语义(相机/分割)的方法各有盲区: 纯几何易把草/灌木误作障碍,或无法表达“哪块是小径”; 纯语义受光照/季节/遮挡影响,难以可靠估计真实可通行性。

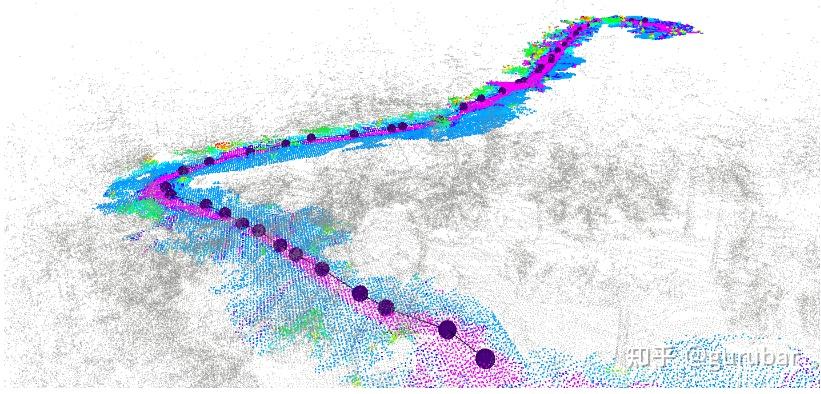
本文目标是:在坚持走小径、必要时离径绕障/抄近路与总体安全之间寻找平衡,提出一套语义+几何融合的可通行性(traversability)分析 + 基于可通行分布采样的RRT*(Rapidly exploring Random Tree Star)导航方法,并在仿真与实地(WVU Arboretum,如下图)验证语义与几何权重对“在径率/路径长度/时间”的权衡。
解决思路与与已有路线的不同(Approach & Comparison)
系统两大模块(见文中系统图):
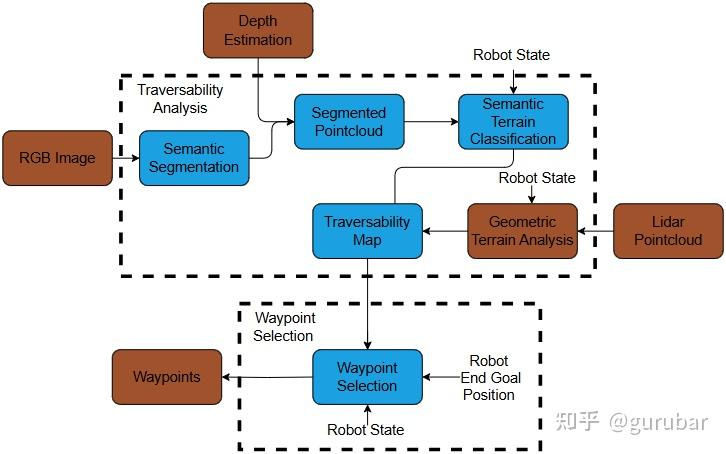
Traversability Analysis:YOLOv8 语义分割(自建 8 类徒步语义数据集,mAP≈75.8%,其中“trail” mAP≈96.7%,如下图)→ 与深度/点云配准为语义点云 → 与 LiDAR 高程/坡度等几何可通行度用加权代价融合,构建全球可通行度点云地图(例如下图,West Virginia University)。数据关联用双 kd-tree邻近查询,地图配准用ICP(iterative closest point),并做体素/统计离群过滤以满足实时性。


Waypoint/Path Planning:以可通行度分布作为采样分布的 RRT* 生成分段 waypoint(而非均匀随机采样),代价函数同时考虑距离与可通行惩罚;局部跟踪用 FALCO(库轨迹 + 似然避碰)。实测/仿真评估语义-几何权重 w 对“在径率、距离、时间”的影响,并给出w≈0.75 的实地示范。
| 方法 | 关键信息 | 表现/应用侧重点 | 主要局限/差异 |
|---|---|---|---|
| 本文 (2025) | 语义(相机) + 几何(LiDAR) 融合的可通行度点云;以可通行分布采样的RRT*;仿真与实测权衡语义权重w | 实地在 WVU 小径验证;w↑ ⇒ 在径率↑但距离/时间↑,示例 w=0.75 | 依赖分割质量与跨季节泛化;外参/深度误差会影响投影与融合。 |
| OFFSEG (CASE’21) | 离线图像语义分割:把场景分为 traversable/obstacle 等,并细分草/碎石/水坑 | 强化对可通行类别的像素级理解 | 仅视觉,天气/光照敏感;不显式度量坡度/粗糙度。 |
| Maturana+ (FSR’18) | 实时语义地图(2.5D 网格,融合语义类与高度)用于越野导航 | 语义 + 高度编码,ATV 场景验证 | 2.5D 单层表示对悬垂/多层结构易失真;未显式建可通行代价。 |
| Leung+ (ICARA’22) | 混合可通行:语义分割 + 几何(坡度/粗糙度)融成代价栅格 | 机器人中心成本图→规划器可直接用 | 仍多为栅格/2.5D表达;对复杂植被上/下层分离有限。 |
| ForestTrav (2023–24) | 3D LiDAR-only 概率体素可通行估计,面向密林 | 对植被穿行鲁棒,开源实现 | 无语义,难表达“哪块是小径”;对软障/低矮植被易过保守。 |
| Waibel+ (T-ITS’22) | LiDAR 构建连续可通行代价,联动局部+全局规划 | 几何一致、规划闭环清晰 | 无语义,对“绕障抄近路 vs. 走小径”的语义偏好缺失。 |
| Thoresen+ (RA-L’21) | Traversability Hybrid A*:在 Hybrid A* 中显式引入可通行成本 | 适配UGV 山地/坡度 | 采样/扩展仍与语义分布无耦合,与本文“分布采样”不同。 |
| TrailNet/Deep Trail Following (’16+) | 端到端视觉沿径(学习“路在何方”) | 低成本视觉、轻量跟踪 | 不看几何,对泥泞/坡度/坍塌等物理通行风险无感。 |
小结:本文与“语义+几何混合”(Leung+)同属融合路线,但表达载体从2.5D/栅格拓展为点云层面的加权可通行图,并把分布采样直接灌入 RRT*;与“仅几何”或“仅语义”相比,能在“走小径 vs 安全快捷”之间显式旋钮式权衡(权重 w)。
创新点的直觉 & 机制(Intuition & How it works)
直觉A:把“能不能走”变成“走的概率/代价”,让采样更聪明。 与其在空间里均匀撒点(经典RRT*),不如在“更可能好走”的区域按可通行分布采样,既提升找到好路的概率,也减少无效扩展;代价项再惩罚低可通行区域,实现“走小径/抄近路/避险”的连续权衡。
直觉B:语义与几何互补。语义告诉你哪儿是“trail/grass/rock/roots/树干/结构/粗糙径”,几何告诉你坡陡/崎岖/台阶。二者做点云级对齐并以权重 w 融合,天然抗单一模态的失败模式。实测与仿真表明:w↑ 使在径率↑,但路径/时间可能变长(绕开危险或坚持回到小径)。
直觉C:工程可落地的细节。使用YOLOv8(自建 1250 张标注、8 类、mAP≈75.8%/trail≈96.7%)、ZED2i 合理深度门限(0.5–6 m)、双 kd-tree 近邻、ICP 细配准、体素/统计滤波降采样与去噪,配合LIO-SAM建图与FALCO局部避障,形成完整、可实时的系统。
实现层面的关键点与潜在坑(Implementation Notes)
跨模态外参 & 时间同步:语义掩膜→点云投影对外参/时间戳极敏感;ZED 深度在边缘/植被处易跳变,需配合距离/高度门限、体素/统计滤波(文中已有)与ICP 紧配准。
权重 w 的现场标定:仿真表(w=0∼1)显示:仅几何(w=0)在径率最低;w=0.5∼1 在径率上升但可能距离/时间变长;实地示范使用 w=0.75。部署时可按生态/效率制定策略:保护区取高 w,应急搜救取中等 w以兼顾捷径。
3D 表达 vs 2.5D/栅格:本文点云级融合能更好处理悬垂植被/多层结构,但内存/计算相对更高;需根据平台算力(如 Husky A200 + 激光 + 立体相机)做体素分辨率权衡。
局部规划与全局一致性:RRT* 分布采样生成 waypoint,局部跟踪用 FALCO(似然避碰);应注意重规划频率与地图更新延迟,避免“语义回滚/几何突变”造成抖振。
季节/光照域移位:语义分割对四季/雨雪/逆光敏感,建议扩充四季数据与数据增强;必要时引入伪标签自训练/域自适应来稳健化 OFF-road 视觉。
可能的价值(Impact)
面向真实自然场景的“可调拨盘”式导航范式:一套可在“走小径 vs 安全/效率”之间连续可调的融合导航栈,适于巡检、步道维护、科考、搜救等多目标权衡任务。
工程落地友好:依赖常见传感器(立体相机+LiDAR)、可复现组件(LIO-SAM、FALCO),并附数据/仿真环境与演示视频,利于二次开发与对比评测。
与现有两类主线形成互补:相对仅几何(Waibel/ForestTrav)或仅语义(OFFSEG/TrailNet),本文提供了可通行表达与采样机制的一体化接口;对以可通行代价驱动的规划(如 Traversability Hybrid A*)也可作为上游概率先验接入。
FruitNeRF++: A Generalized Multi-Fruit Counting Method Utilizing Contrastive Learning and Neural Radiance Fields
https://arxiv.org/pdf/2505.19863
文章在解决什么问题?
多果种(苹果/李子/柠檬/梨/桃/芒果)统一计数长期受限于: 多数方法只适配单一果种或依赖果形模板/尺度先验,迁移困难; 2D 掩膜跨视角不一致,直接 3D 聚类易“重复计数/漏计”; 果实小、密集、被叶/枝遮挡时,2D 实例常被分裂成多个片段,3D 聚类更难。
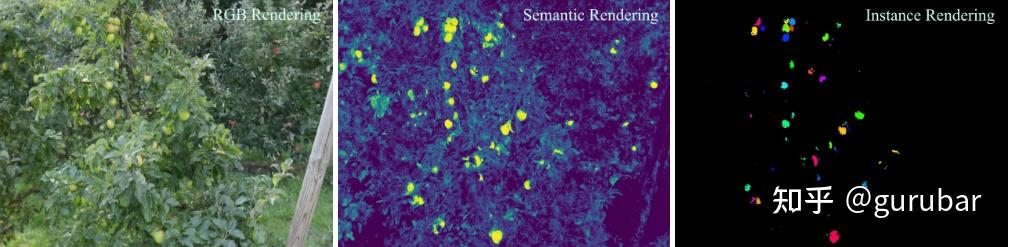
FruitNeRF++ 要做的是:在无结构的多视角照片下,构建形状无关(shape-agnostic)的 3D 实例表示与聚类管线,实现跨果种泛化的计数,而不再为每种果实设计模板或调超参。
思路与和已有路线的不同
完整管线(图 2):
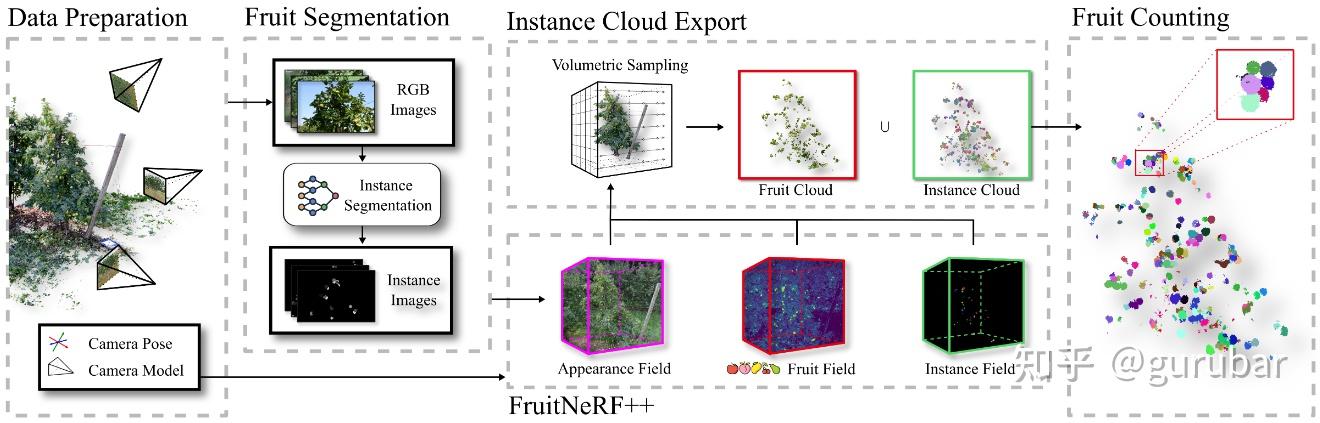
由 Grounded-SAM/Detic 生成多果种 2D 语义与实例掩膜;
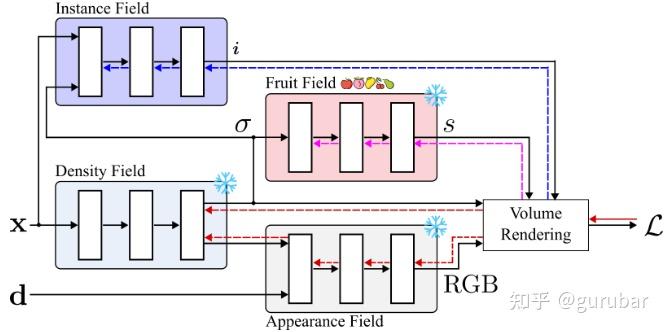
训练含 密度/外观/语义/实例 四个场的 NeRF;实例场用对比学习使同一果实体素的嵌入彼此接近、不同果实分离——采用原型化 InfoNCE与局部难负样本(近邻果实)采样,并用分级训练先收敛几何与语义,再冻结训练实例场;
体素采样导出仅果实点云 + 实例嵌入;
先 k-means 分片降规模,再在每片上用 HDBSCAN 做多模态聚类(距离 = 实例嵌入余弦 + 3D 欧式的加权和),输出实例数即为果数。
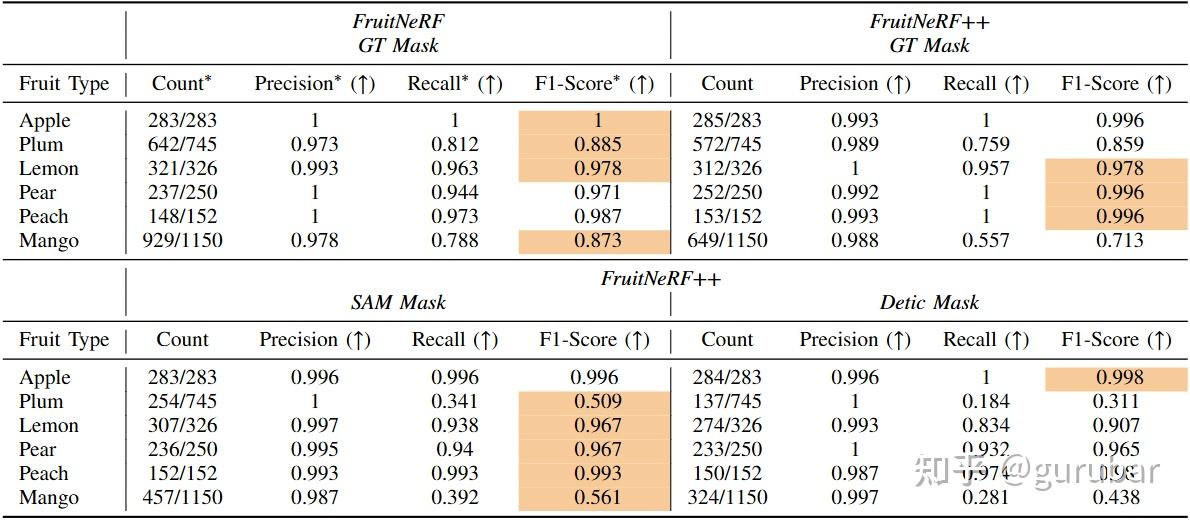
该方案去除了 FruitNeRF 的果种模板/级联聚类超参依赖,天然多果种泛化;在合成数据上用 GT 掩膜的平均 F1=0.925,用 Grounded-SAM/Detic 掩膜分别 0.832/0.776;在 FUJI 实拍苹果上 F1≈0.765。
| 方法 | 关键思路/输入 | 是否需果形/果种先验 | 多果泛化 | 主要差异/局限 |
|---|---|---|---|---|
| FruitNeRF++(本文) | 基于 NeRF 的语义+实例场;原型化 InfoNCE + 局部难负采样;HDBSCAN(嵌入+欧式) | 否 | 是 | 去模板、形状无关;对 2D 掩膜/位姿质量较敏感;训练耗时。 |
| FruitNeRF (2024) | 语义 NeRF → 果点云 → 级联聚类+果形模板 | 是 | 部分 | 需果种模板与尺度调参,跨果种迁移成本高。 |
| Gené-Mola 2020 | 实例分割 + SfM 3D 定位→聚类计数 | 轻 | 一般 | 受遮挡与两侧配准影响;单果种较多。 |
| Liu 等 2018/2019 | 分割+多帧跟踪+SfM 的序列计数 | 否 | 一般 | 依赖时序/轨迹,夜间可控光;跨果种需重训。 |
| Häni 等 2019(JFR) | U-Net 分割→投影 3D → 聚类计数,系统对比 | 轻 | 一般 | 2D/3D 管线清晰,但对密集遮挡/跨视角一致性弱。 |
| Contrastive Lift (NeurIPS’23) | 对比学习训练 3D 实例场(慢/快教师) | 否 | 场景泛化 | 通用 3D 实例分割思路;非农业专向。本文借鉴其对比学习提升 3D 一致性。 |
| Panoptic Lifting (CVPR’23) | 2D panoptic → 3D panoptic 场 | 否 | 场景泛化 | 统一 3D 语义+实例表示;未面向果实小目标/计数细节。 |
小结:FruitNeRF++ 的关键不同在于把“可数的实例性”内化到 3D 场里,而非在果点云上依赖形状模板做二次启发式切割;这使它对果种/生长期尺度变化更稳健。
创新点的直觉 & 机制如何落地
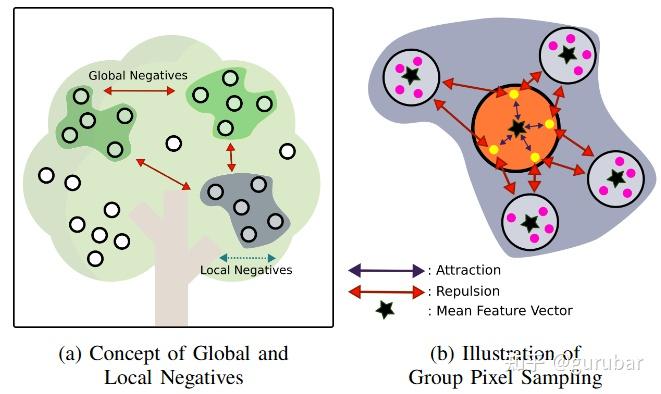
直觉 1|把“同一颗果”的 3D 体素拉到同一嵌入原型附近: 用原型化 InfoNCE(每颗果的像素→聚合成原型向量,与其它果原型做对比)代替像素两两对比,稳定且省算,还能聚焦小目标(局部难负采样、近邻果优先分离)。
直觉 2|先学稳几何,再学实例: 分级训练:先收敛密度/外观(NeRF 几何可靠),再加入语义,最后冻结几何/语义只训实例场,避免“实例像素采样”让几何遗忘。
直觉 3|聚类即融合“位置+语义实例”: 聚类距离 d=λc⋅dcos(嵌入)+λe⋅dE(3D);实例嵌入分开“贴得近的不同果”,欧式距离抑制“远处同类误合”,二者互补。论文扫参显示 τ≈0.2、D∈[16,32]、λe≈5区间效果较稳。
实现要点与“坑”
位姿/配准敏感:FUJI 数据集的位姿噪声/两侧手工配准会把同果的体素“拉散”,致实例场被污染→计数下降(FUJI F1≈0.765)。优先用高质量 SfM/SLAM 或加上时序束调。
2D 掩膜质量瓶颈:Grounded-SAM/Detic 在遮挡时常把一颗果切成两个实例,训练把同一果的嵌入拉远→过分割;论文给出合成集 IoU:SAM≈0.561、Detic≈0.49。可通过掩膜后处理/时序一致性缓解。
算力与时长:大场景训练约 8h/A5000(24GB),实例场收敛占大头;推断时需体素采样(论文示例采样 60 万点、分 40 片聚类)。工程上可考虑稀疏体素/哈希网格加速或改用 Gaussian Splatting/PAg-NeRF 以提速。
超参与内存:嵌入维 D 太小会同果/异果不易分,太大内存增;λe 过小仅靠嵌入会错合近邻果,过大又退化为几何聚类——论文给出扫参曲线可作首选区间。
数据覆盖:树体遮挡重、视角覆盖不足会令实例场局部塌缩;采集上建议半球多视角、统一曝光,并混合不同生长期/光照以提升泛化。
潜在价值
真正“形状无关”的多果种计数范式:同一模型可在多果型/多生长期下工作,减少果种切换的系统重构与标注成本;在合成数据 + GT 掩膜上 F1≈0.925,说明上限受 2D 掩膜/位姿质量而非方法本身制约。
从“模板/启发式”迈向“3D 学习型实例场”:借鉴 3D 实例/全景场(Contrastive Lift、Panoptic Lifting)的思想,但面向小目标/密集遮挡做了实例采样与损失设计的工程化调整,具有领域可迁移性(论文还在“Messy Rooms”做了泛物体试验)。
与 2D 零样本计数的互补:2D 的 Zero-Shot Counting仅靠类名就能计数,但缺少多视角一致与遮挡消歧;FruitNeRF++ 的 3D 实例场可作为三维扩展路径。
产业落地:对产量预测/采收计划/包装与冷链等具直接价值;统一的多果计数可减少多品类果园的部署碎片化。
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
https://arxiv.org/pdf/2503.06669
文章要解决什么问题
现实世界操控想要“通用化”,瓶颈不是模型容量,而是数据与平台:现有数据集多为短时程、单臂、受控实验室采集,硬件异构、标注不统一,难以支撑长时程、多模态(视觉+触觉)、双臂/协作等复杂任务的可泛化学习;现成通用策略(VLA/扩散/流模型)也因此在泛化与灵巧操作上受限。
本文要解决的是:如何通过规模化、标准化、带“人-在-环”质检的真实数据与统一硬件生态,系统性提升通用策略的上限;并提出能把网页/人类视频知识迁移到机器人控制的模型范式(GO-1)。
背景对照:OXE 以聚合方式统一多源数据但质量/异构度高;DROID面向“野外”多场景但总规模和质量控制有限;RT-1 等早期模型多在短时程与少场景上训练。
解决思路 & 与典型工作对比
平台 + 数据 + 模型,一体化路线:
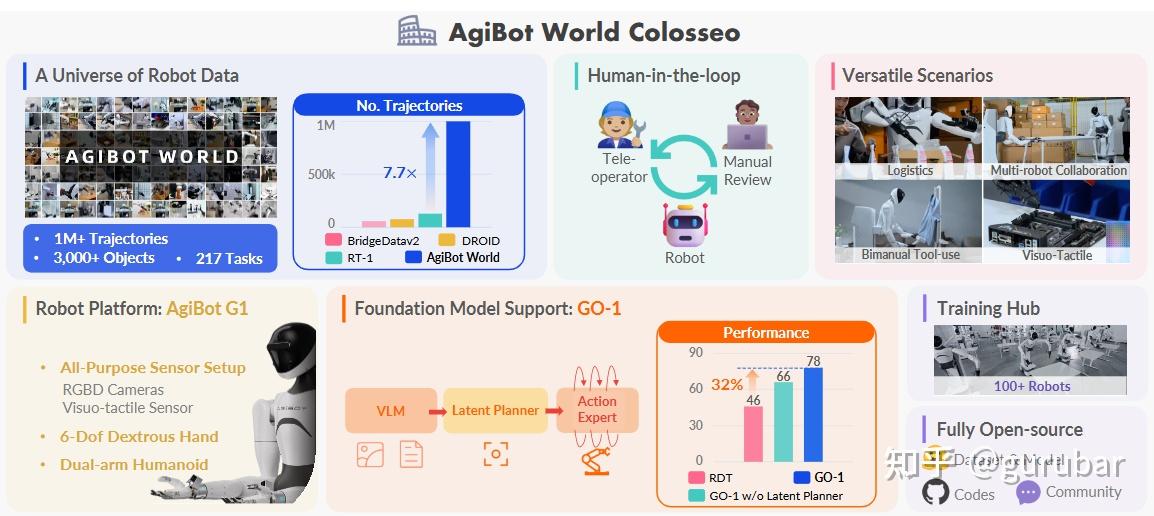
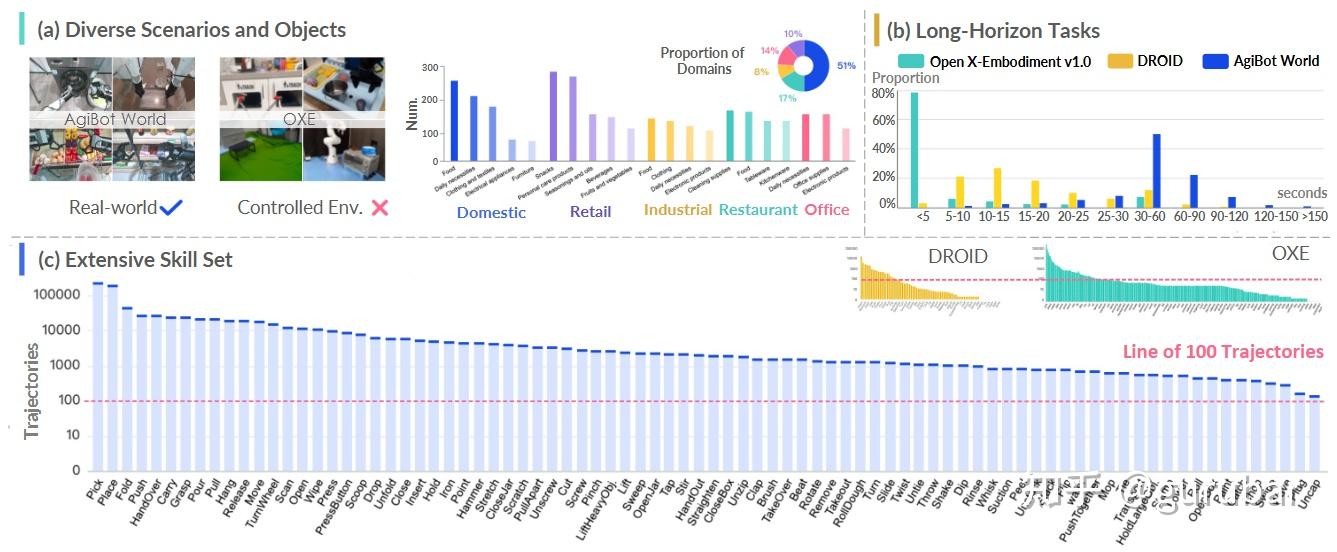
平台/数据:在 4000 ㎡真实设施中,覆盖家庭/零售/工业/餐饮/办公五大域,统一硬件(移动双臂+灵巧手+视触觉),100+ 机器人采集 100 万+ 轨迹、217 任务、87 技能、106 场景、3000+ 物体;全流程“人-在-环”质检、失败恢复轨迹保留与标注。

模型(GO-1):提出 ViLLA 三阶段架构:
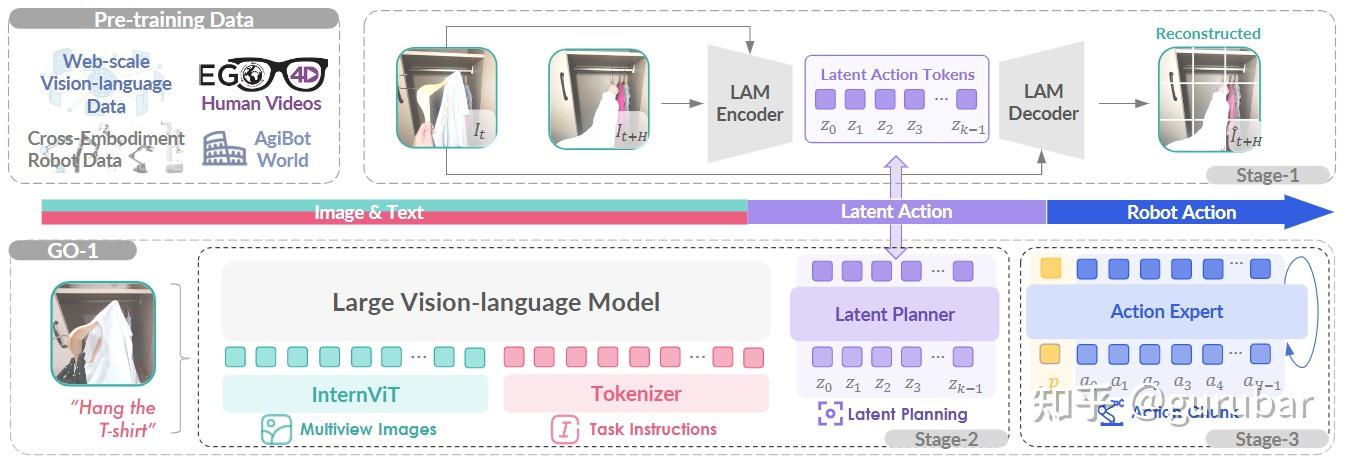
- 潜在动作模型(LAM)在网页/人类视频上学“逆动力学”并量化为离散潜在动作 token(VQ 码本);
- 潜在规划器(基于 InternVL2.5-2B 的 VLM)在潜在动作空间做长时程推理;
- 动作专家用扩散目标回归低层连续控制;三者层级条件化,连接“网页语义→潜在动作→控制信号”。
效果:在文中选取的真实任务上,GO-1 平均显著优于 RDT 和无潜在规划版本;用 AgiBot World 预训练优于用 OXE 预训练,且随数据量呈幂律可扩展(r≈0.97);在仅用 OXE 时长 1/10 的数据下仍带来泛化提升。
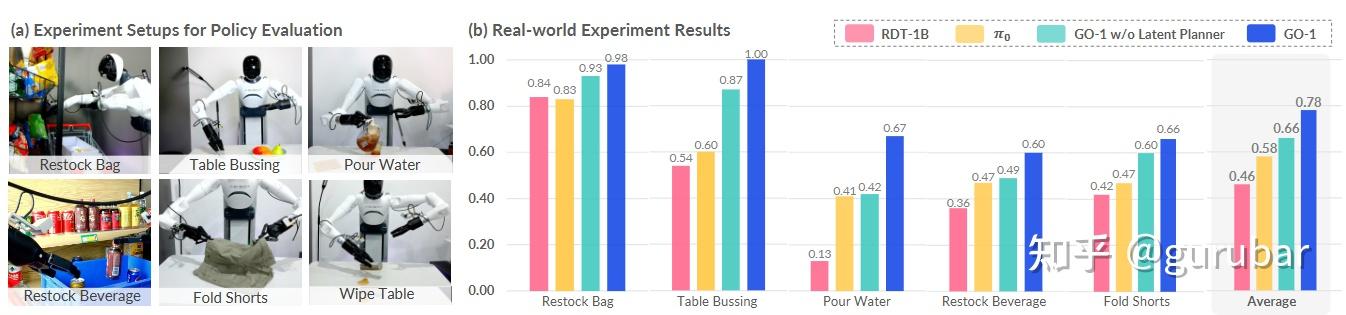
| 工作 | 类型/目标 | 规模/多样性(示例) | 主要方法 | 优点 | 相对本文的局限 |
|---|---|---|---|---|---|
| AgiBot World + GO-1(本文) | 平台+数据+通用策略 | 100万+ 轨迹,五大域,双臂+灵巧手+视触觉;人-在-环质检 | ViLLA:VLM→潜在动作→扩散动作专家;长时程 | 质控+长时程+灵巧,与网页/人类视频对齐 | 训练/硬件成本高;仿真环境仍在完善 |
| Open X-Embodiment (OXE) | 数据聚合 | ~100万+ 轨迹,跨 22+ 机体 | 统一格式+RT-X | 广覆盖、易用 | 异构/质量不均,长时程少,出域泛化受限。 |
| DROID | “在野”多场景数据 | 7.6 万 轨迹 / 350h,564 场景/86 任务 | 众包遥操作 | 场景多样、真实 | 规模与质控不及本文;多为单臂。 |
| RT-1 | 端到端策略 | 13 万 轨迹;少数场景 | Transformer 策略 | 率先展示“数据×容量”效应 | 短时程/单臂为主,任务域窄。 |
| Octo | 开源通用策略 | 预训练 80 万 OXE 轨迹 | Transformer-扩散,易微调 | 好适配,多机器人即插即用 | 仍依赖 OXE 质量/短时程偏好。 |
| OpenVLA | 7B VLA | 97 万 机器人演示 | VLM+动作头,参数高效微调 | SOTA 通用策略之一 | 主要用 OXE/聚合数据;触觉/双臂覆盖有限。 |
| RDT-1B | 双臂扩散基座 | 预训练多源+>6k 双臂微调 | 扩散 Transformer | 双臂复杂动作强 | 未结合网页/人类视频潜在动作对齐。 |
| BridgeData v2 | 跨域数据 | 6.0 万 轨迹/24 环境 | 低成本平台、多方法评测 | 跨域泛化佳 | 规模/长时程/双臂不足。 |
创新点的直觉 & 如何落地
把“网页/人类视频”的动作知识压到可控的“潜在动作 token”里:直接学低层控制会被机体差异吞没;先学“视觉→潜在动作”的逆/正动力学(VQ 量化),再让规划器在离散潜在空间做长时程推理,最后由扩散动作专家解码到具体机体,实现跨机体、跨场景迁移。
数据即能力上限,但“质量×结构化”同样关键:同等甚至更少时长的 AgiBot World 预训练,相比 OXE 预训练在见域/出域都更强,说明统一硬件、全流程质检、失败恢复标注能显著提高“每小时数据”的有效性;曲线显示幂律可扩展(r≈0.97)。
端到端≠一次性:ViLLA 的分层训练(先几何/视频潜在动作,再潜在规划,再动作专家)把学习难度拆解,既保留 VLM 的语义/常识,又维持控制的高频/稳定。
实现层面的要点与潜在坑
工程门槛:多相机(头部/腕部/后向)标定与时间同步、触觉/灵巧手采样频率、30 Hz 控制回放的丢帧/漂移处理,都是重保真训练的关键;轻微时序错位会破坏“潜在动作”对齐。
算力与时长:三阶段预训练 + 大规模数据清洗/标注需要集群支持;若只做下游微调,可先用公开权重并少量任务演示适配(论文也采用“预训练后再按任务微调”范式)。
出域评测方法学:文中采用分场景/干扰物/语言变体三类变更,评分按部分成功加权;落地时建议复用此 rubric,避免“二元成功率”的信息损失。
可复现性与许可:数据与模型按 CC BY-NC-SA 4.0/开源发布,商业化需关注许可边界与第三方素材(网页视频)来源合规。
仿真缺口:当前评测以实机为主,同构仿真环境在完善中;若你需要大规模超参搜索或策略安全验证,需自建近真仿真或等待官方发布。
可能的价值
把“数据规模”与“任务难度”一起拉升:从“桌面短时程”迈向“长时程/工具使用/双臂协作/视触融合”,为通用操控提供现实分布上的训练与评测基线。
验证“高质量、结构化数据”优先级:同等甚至更少时长,AgiBot World 预训练即可在见域/出域上显著超过 OXE 预训练;人-在-环质检比“更大但未筛选”的数据更有效。
方法论外溢:潜在动作作为“跨模态桥”可移植到 Octo/OpenVLA/RDT/π0 等框架,以降低跨机体/跨数据源学习的摩擦。
产业落地:五大域的 1:1 场景(零售补货、餐饮清理、工业工位协作等)直接对接商用流程;失败恢复标注适合做偏好/反思对齐与安全策略研究。
DiFuse-Net: RGB and Dual-Pixel Depth Estimation using Window Bi-directional Parallax Attention and Cross-modal Transfer Learning
https://arxiv.org/pdf/2506.14709
这篇文章要解决什么问题?
手机等相机的双像素(Dual-Pixel, DP)传感器能在一次曝光里产出“左右半像素”图像,蕴含极细微的散焦位移线索,可辅助单相机深度估计。

但现实存在两大痛点:
- DP 位移极小(手机小光圈导致仅数像素量级),常规立体匹配或简单拼接 RGB+DP 的端到端网络都吃不准;
- 缺乏大规模高质量 RGB-DP-D 数据集,公开 Google DP 数据集的真值稀疏、噪声较高,限制训练与评测。
本文旨在:把“语义上下文”(RGB)与“DP 位移细节”(DP)解耦学习、再自适应融合,并通过跨模态迁移训练(CmTL)充分利用海量 RGB-D 数据,同时提出DCDP高质量数据采集方案,从而显著提升 DP 深度估计的精度与可泛化性。

解决思路 & 与典型工作
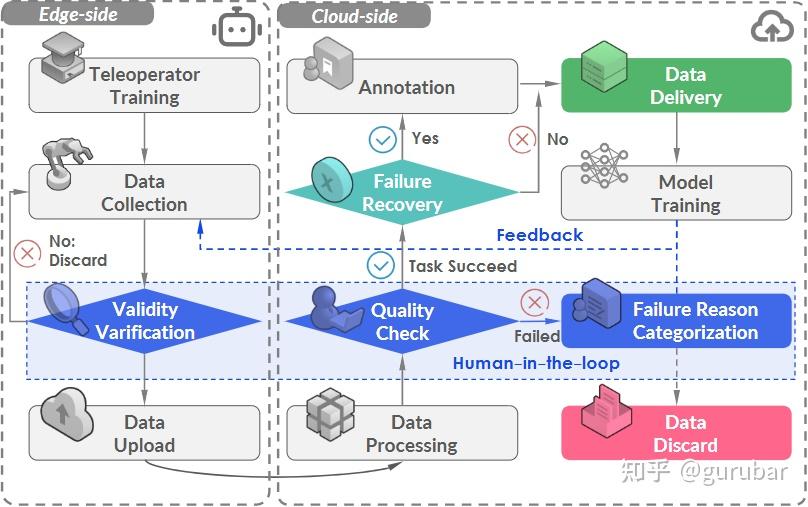
方法总览(DiFuse-Net):
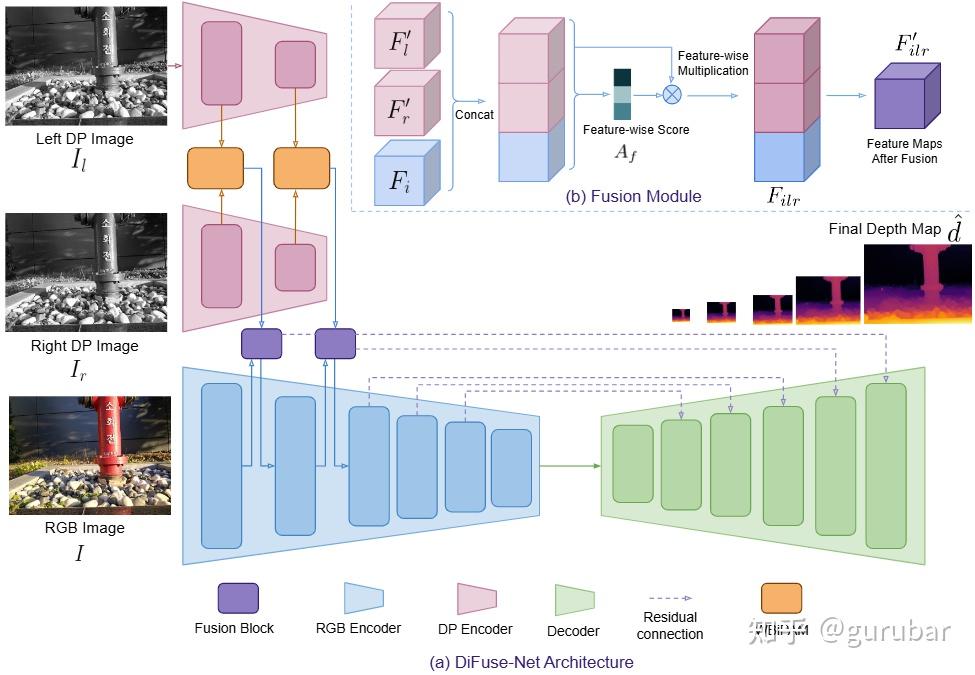
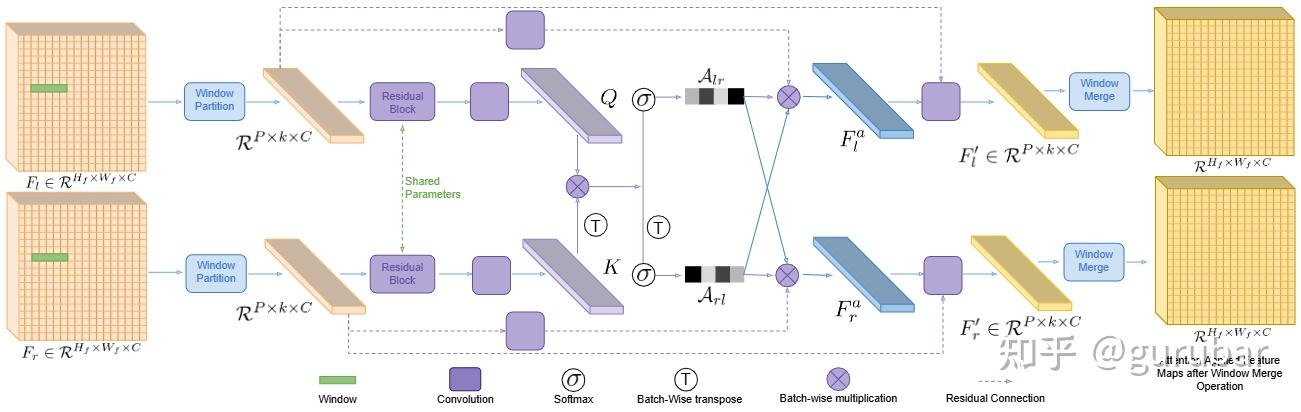
双分支编码器:RGB 编码器提取全局上下文;DP 孪生编码器内置 WBiPAM 窗口化双向视差注意力,只在 DP 视差的局部窗口内做左右交互,专门捕捉“极小位移”;
特征级自适应融合:对齐后对 RGB/DP 特征做逐特征权重估计与融合,避免纹理贫乏区被 DP 误导;
三阶段 CmTL:先用少量 RGB-DP-D 训练 DP 分支,再用大规模 RGB-D 提升 RGB 分支,最后联合微调;
DCDP 数据:用两部手机构成对称立体+AI 立体视差生成稠密高质深度真值,提供 5,000/700(train/test)样本。

| 方法 | 关键思路/输入 | 是否专门处理 DP 细微位移 | 数据与训练 | 代表结论/特点 |
|---|---|---|---|---|
| DiFuse-Net(本文) | RGB/DP 解耦 → WBiPAM(窗口双向**视差注意)→ 特征级融合;三阶段 CmTL | 是(局部窗口、双向) | 自建 DCDP + 公开 Google DP;利用大规模 RGB-D 做 CmTL | 在 Google DP 上 全面优于 DPNet/立体基线;DP 编码器两层最优;融合以“逐特征权重”最佳。 |
| DPNet (ICCV’19) | 直接拼接 RGB+DP,端到端回归相对深度 | 否 | 自采 5×Pixel 相机多视角,真值 稀疏 | 开创 DP 深度估计任务,但没专项建模DP 视差形成与细微位移。 |
| Du²Net (ECCV’20) | 双摄+DP 正交基线信息融合,缓解遮挡与边缘误差 | 部分(强调与双摄互补) | 自建双摄+DP 数据 | 证明“DP+双摄”互补有效,定位于摄影/三维照片等应用。 |
| DP Exploration / DDDNet (CVPR’21) | 建立DP 成像物理模型,联合去模糊+深度 | 是(从成像物理出发) | DP 仿真器 + 少量实拍 | 物理建模+重模糊损失提升鲁棒性,但非专为手机极小位移设计。 |
| Modeling DP Defocus-Disparity (ICCP’20) | 参数化 PSF建模 DP 散焦位移,优化估计 | 是(优化式) | DSLR/实验室场景 | 指出 DSLR 与手机 DP 差异显著,直接迁移存在问题。 |
| RAFT-Stereo (3DV’21) | 最强立体匹配之一,递归场变换 | 否(非 DP 专项) | Middlebury/ETH3D 等 | 立体 SOTA,但对手机 DP 像素级微视差并非最优解。 |
| MiDaS / ZoeDepth | 纯 RGB-D 单目(混合多数据/零样本泛化;Zoe 做相对→度量) | 否 | 海量 RGB-D | 对 DP 线索不可用,本文实测也弱于 DiFuse-Net 于 DP 任务。 |
小结:本文与 DPNet/DDDNet 的最大差异在于把“DP 细微视差”作为一等公民来建模(WBiPAM:窗口化+双向注意),并通过 CmTL 充分吃下 RGB-D 的泛化能力——既不依赖双摄硬件,也避免仅靠 RGB 的固有限制。
创新点的直觉 & 机制如何落地
直觉 A:DP 是“极窄带”线索,要在“局部+双向”里精算。
传统 cost-volume/全局注意力在手机 DP 的±几像素位移上既费算又易被噪声淹没。WBiPAM把注意力限制在沿对极线的小窗口,并左右双向计算匹配相关性,显著提升“微位移”分辨力与稳健性。
直觉 B:谁擅长什么就做什么——模态解耦再融合。
RGB 分支负责全局上下文/语义先验,DP 分支负责局部视差;在特征空间里用逐特征权重自适应融合,纹理贫乏处更依赖 RGB,细节边界处强化 DP。消融表明该融合优于像素/信道级校准。
直觉 C:数据稀缺用“跨模态迁移”补。
用 三阶段 CmTL 把大规模 RGB-D 的“形状/场景先验”迁入 RGB 编码器,再与 DP 编码器联合;实验显示 CmTL 明显降低 AIWE/提升 SRCC。
直觉 D:真值要“密、准、对齐”。
DCDP 用对称双机+AI 立体(如 RAFT-Stereo 级别)生成稠密、边界锐利的深度,并设计逐次标定与反投影对齐流程,保证与 DP 图像像素级对齐。
实现层面的要点与潜在坑
外参/时序与几何对齐:DP 与 RGB 的时间戳与标定必须稳定;DCDP 采用每次采集都重标定+反投影回原像平面,并裁边减小残差影响(<3 像素)。
DP 编码器深度:消融显示 两层最好,再深会破坏细微位移;这与“手机 DP 视差极小”特性一致。

融合粒度选择:逐特征权重在“DP 细节 vs RGB 上下文”的权衡上优于像素/信道级;若场景纹理极弱,需关注 RGB 分支是否被过拟合先验牵引。
训练与算力:采用 Pytorch/Adam,多尺度深监督;实例场景(Google DP)上 DiFuse-Net 参数量≈9.9M,推理和训练成本适中,但 CmTL 需要预先在大规模 RGB-D 上训练。

数据依赖:整体上对 2D 掩膜/位姿质量不敏感(因不依赖 2D 实例),但对DP 图像质量与对齐仍敏感;若改变手机型号/光圈,需适配 WBiPAM 的窗口与融合阈值。
实验结论与潜在价值
更好的精度与可泛化性:在 Google DP 基准上,DiFuse-Net 相比 DPNet/立体基线/增强基线在 SRCC 与 AIWE 上全面更优;
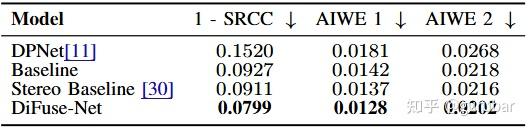
与 MiDaS/ZoeDepth 这类纯 RGB-D 单目基座相比,也取得更好 DP-任务表现(参数更小)。

工程范式的迁移性:不依赖双摄硬件;当有RGB-D 海量数据时,用 CmTL 即可迁移到DP 传感任务;当有双摄时,还可把 RAFT-Stereo 一类视差结果作为“教师”生成更优真值。
应用场景:移动端 AR/三维照片、低成本机器人避障/重建、无人机/穿戴设备的低功耗深度;对弱纹理/边界锐度/薄结构尤其友好。
研究促进:DCDP 提供了目前少见的高质量 RGB-DP-D,可作为后续 DP 物理建模、联合去模糊-深度、多设备域自适应等方向的统一评测基线。
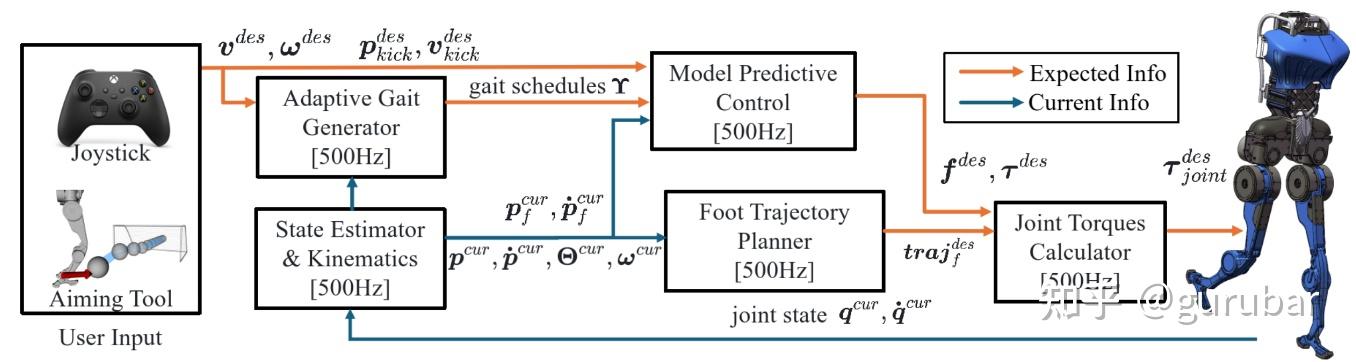
Like Playing a Video Game: Spatial-Temporal Optimization of Foot Trajectories for Controlled Football Kicking in Bipedal Robots
https://arxiv.org/pdf/2510.01843
文章要解决什么问题(Problem)
在类人足球中,要既稳又准地完成传射很难: 需要在激烈踢球时保持整体稳定(接触力/力矩约束、摆动腿时序与身体平衡耦合); 要把球打到目标位姿/方向/速度(可控落点与出球速度/角度),而不仅是“踢出去”; 现有做法要么是预定义动作/差值轨迹(摆腿只靠 Bézier/插值,几乎不管时序与动态约束),要么是端到端 RL(强但黑箱、对机器人与环境特定、难以解释与调参)。
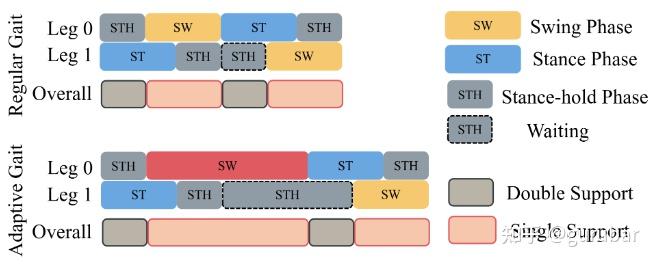
本文聚焦“摆动脚”的时空联合规划:把无人机上成熟的MINCO类时空形变优化迁移到双足摆脚,同时解出轨迹形状与摆动时长,并与SRB-MPC(质心动力学)闭环配合,实现人样的回摆(backswing)与可控的触球速度/方向。在仿真与 40 kg/1.5 m 实机(PEARL)上,给出<1 ms 规划时延与–90°…90° 角域近 100% 的射门成功率等结果。

解决思路 & 与典型工作对比(Approach & Comparison)
系统管线(图 2):视觉检测与可视化瞄准 → 状态估计 → SRB-MPC 求解支撑脚 GRF/GRT → STOFT(Spatial-Temporal Optimization of Foot Trajectory)为摆动脚在 A→B→C(三点边界)之间作5 阶多项式两段时空优化;同时自适应步态 FSM插入“双支撑/等待”以在加长摆动期时维持稳定;触球采用冲量-恢复系数模型反推所需足端撞击速度。
约束包含:速度/加速度上限、ESDF 自碰约束(另一条腿视作障碍)、髋球形工作空间、时长上界等;优化用 MINCO 参数化 + L-BFGS 显式梯度,单次规划 <1 ms。此外,针对正面“趾尖踢”与侧向“脚内侧踢”给出不同末端姿态插值与可行性处理;实机测试显示角域一致高成功率。
| 方法 | 核心思路 | 控制/优化对象 | 典型平台 | 优点 | 与本文差异/局限 |
|---|---|---|---|---|---|
| 本文 STOFT + SRB-MPC | MINCO 时空联合摆脚轨迹 + 自碰/运动学/时长约束;与 SRB-MPC闭环耦合;两种踢法 | 触球位姿/速度 + 摆动时长 + 步态FSM | PEARL 双足 | <1 ms、近100% 成功率(–90°…90°)、可解释 | 需球动力学参数(恢复系数 α≈0.65)与良好状态估计;以 SRB 近似忽略腿质量耦合。 |
| Deep RL 1v1 足球(Science Robotics’24) | 端到端 Deep RL 习得走/转/起身/踢等复合技能 | 隐式学到踢球策略 | Mini humanoid | 强鲁棒、策略丰富 | 黑箱、对可控触球速度/落点弱、跨机体/场景可解释性差。 |
| DribbleBot(ICRA’23) | 四足 RL 野外带球/运球操控 | 机体-球交互策略 | 四足 | 野外鲁棒、端到端 | 非双足,不强调摆脚时序/撞击速度精控。 |
| VH-MPC 摆脚动力学(RA-L’21) | 可变时域 MPC:上层决定落脚与时长,下层纳入摆脚动力学 | 落脚位置与着地时序 | BOLT 双足 | 抗扰稳步行 | 指向落脚稳定,非“可控射门”;未做自碰/回摆与撞击速度匹配。 |
| Convex SRB-MPC(MIT Cheetah 3, IROS’18) | SRB + 凸 MPC 规划 GRF | 质心与接触力 | 四足 快、工程化成熟 | 对摆脚常用简单插值;无物体撞击/传射任务。 | |
| 感知-非线性 NMPC(T-RO’23) | 感知+全身 NMPC 实时优化 | 全身轨迹+接触 | 四足 | 感知-控制一体 | 计算重、非专为踢球的时空摆脚与撞击控制。 |
| Contact-Implicit MPC(IJRR’24/25) | 接触隐式 DDP/MPC 同时决定接触模式与动作 | 多接触序列 | 四足 | 可自动发现场景接触 | 计算与建模复杂,非聚焦精准触球速度/角度。 |
注:本文把无人机的 MINCO 时空形变迁入双足摆脚这一研究环节,区别于“只在 SRB-MPC 上做力/落脚”的常规范式。
创新点的直觉 & 机制(Intuition → Mechanism)
直觉 A|“踢得远/快”靠回摆 + 时长自由度:人踢远球会回摆拉长加速路程与时间。于是把时间也作为决策量(Tswing)与空间一起优化,确保在中间点 B达到所需撞击速度/方向,末端再回到落脚 C;自然出现人样回摆。→ 机制:两段 5 阶多项式,MINCO 统一参数化 q,T,代价含三阶导平滑 + 时长罚;边界在 A/B/C 约束位姿/速度;梯度闭式、L-BFGS <1 ms。

直觉 B|“摆脚安全区”= 运动学球体 ∩ 自碰 ESDF:摆脚必须避开另一条腿与机构极限。→ 机制:以髋为球心的半径约束 + 动态 ESDF(另一腿作障碍)写成积分罚项,随轨迹采样点评估,优化中自保可行性。
直觉 C|踢球是一次“可解算的碰撞”:根据球的恢复系数 α 与期望出球速度v_out,直接反解足端所需撞击速度 v_des,把高层“想把球打到哪儿/多快”落到可跟踪的足端速度。

直觉 D|稳态靠步态自适应:踢球会加长摆动期,另一腿需“顶住”。→ 机制:FSM 引入 STANCE_HOLD 与双支撑等待,按阈值与“对侧是否在摆动”触发,避免拖脚/错步。
实现层面的要点与潜在坑(Implementation Notes)
参数/标定敏感:球-足碰撞的恢复系数 α(文中线下标定约 0.65)、摩擦系数、力/力矩上界会显著影响可达速度与稳定裕度。
模型近似:采用 SRB 忽略腿质量与摆动-质心耦合,可极大简化并利于 MPC 实时性,但对超激烈动作可能需更高保真度(如质心-关节耦合校正)。
姿态控制的自由度:实测中脚滚转不可控、主要调偏航完成“脚内侧踢”;需要在机构与控制器上明确可控姿态轴以免过度约束。
时序与感知闭环:STOFT 输出的 Tswing 与 FSM/质心 MPC 必须同步;视觉定位与 RViz 瞄准若延迟/漂移,会使 B 点速度目标错位。
可能的价值(Impact)
把“会踢”升级为“踢得准、可解释、可调”:对比 RoboCup 冠军队常用的“正面直线踢”,本文在侧向球位时通过“脚内侧踢”保持 100% 成功率,角域覆盖 –90°…90°;且触球速度可控,有利于战术传球/定点射门。 同时,可与 RoboCup 竞赛系统(如 UCLA ARTEMIS)形成互补:其系统层面强、本文给出可插拔的底层摆脚-撞击模块。
方法论外溢:把 MINCO时空形变成功迁入肢体末端任务,为开门/击打/工具使用等“末端撞击/快速接触”任务提供了通用模板(目标状态可解析 → 末端时空优化 → 与全身 MPC 耦合)。
工程落地友好:优化器 <1 ms、显式梯度、代价/约束可解释;在现有 SRB-MPC 步态栈上低侵入集成;对比赛/产品中的“可控踢/推/打”都具现实意义。
与 RL 互补:上层可用 RL/行为树做策略(站位、何时踢/传),底层用 STOFT 做可控物理执行,避免端到端策略在触球细节上的不可控与迁移难题。
Resilient Multi-Robot Target Tracking with Sensing and Communication Danger Zones
https://arxiv.org/pdf/2409.11230
文章面对的是什么问题
现实世界的多机器人多目标跟踪常会遭遇感知/通信“危险区”(danger zones):在这些空间区域里,机器人进入后会以一定概率发生传感器失效或通信受阻/欺骗。多数已有方法要么预知危险区并做保守规避,要么只在攻击发生前进行风险权衡,缺少在未知环境中一边探索一边恢复/重协同的机制。
本文在未知危险区下,提出一种具备恢复与再协同能力的协调框架,使机器人在遭遇临时性失败后能逃离危险区、共享危险区位置、并在风险—性能间自适应取舍。
 ""+represents a sensing attack, and the blue one represents a communication attack" />
""+represents a sensing attack, and the blue one represents a communication attack" />
文章的解决思路是什么?和已有思路有何不同
总体思路
建模:将多机器人/多目标跟踪在未知危险区中表述为部分集中式的非线性优化;把危险区位置当作高斯不确定的风险场,并引入软机会约束(soft chance constraints)与松弛变量,允许在必要时“可控触险”以赢得更好的跟踪质量。对感知攻击与通信攻击分别给出攻击与恢复模型(进入区内按概率受攻击;逃离并低于阈值概率后恢复)。
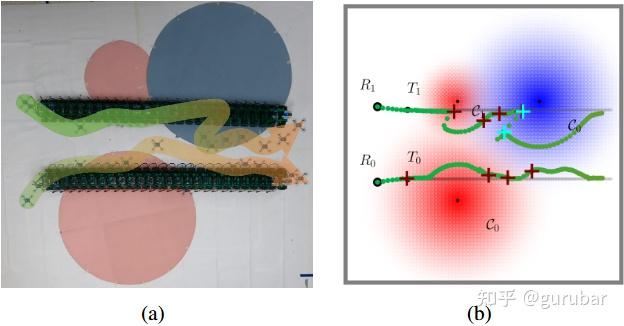
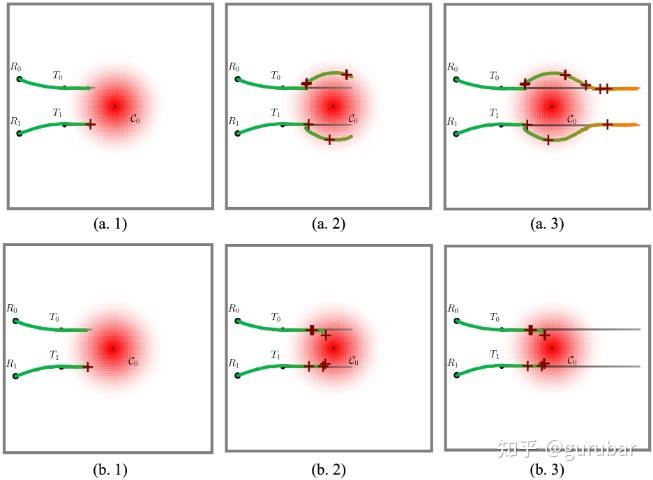
分场景协同: (如下图,展示了在同一感知危险区下,韧性跟踪能在受攻后识别—共享—规避—恢复并维持任务;普通跟踪则在两机都失去测量时瘫痪。)
- 有通信时(形成通信组):集中共享新发现的危险区,群体解一个带风险松弛的跟踪优化(松弛权重调节“保守 vs. 进取”)。
- 被干扰失联者:单机规划,一边用本机观测继续跟踪,一边规划最快逃离危险区;恢复通信后把估计的危险区信息广播给队友。估计融合采用协方差交集(CI) 合并通信分裂期间的两套 EKF。
验证:仿真展示在单/多重攻击下,对比“无韧性基线”,该框架能把MSE 与协方差迹维持在低水平;硬件用 Crazyflie 无人机跟踪地面移动目标,演示了感知区与通信区下的发现-逃离-共享-再协同流程;代码与演示视频公开(左图展示“感知失效但可通信→两机同时绕行”,右图展示“通信失效→先单机脱险、再共享信息、再绕行”的差异,这正是论文要验证的两类危险区与对应韧性策略)。

| 方法 | 场景/假设 | 关键机制 | 通信攻击 | 在线学习/恢复 | 与本文的主要差异 |
|---|---|---|---|---|---|
| 本文(2024–25) | 未知感知/通信危险区;攻击临时可恢复 | 部分集中式优化;软机会约束+松弛;失联单机逃离;恢复后共享;EKF+CI合并 | ✅ | ✅(边探索边揭示危险区) | 兼顾可控触险与恢复/再协同,实机验证。 |
| Zhou & Kumar, T-RO’23 | 已知/可界定的感知/通信攻击 | 风险/稳健跟踪规划,抗最坏情形失败 | ✅ | 部分 | 侧重稳健规避与最坏情形保障,未强调未知区的在线发现+恢复。 |
| Mayya et al., RA-L’22 | 敌对目标诱发传感失败风险(随距离变化) | 风险-性能自适应队形与任务分配 | ❌(不显式建模干扰) | 部分 | 关注风险权衡但不处理通信受阻及未知区揭示与共享。 |
| Zhou et al., RA-L’19 | 最坏情形α 个机器人失败 | 韧性子模优化近似算法 | ❌ | ❌ | 抗最坏移除的组合优化;不含危险区概率/恢复与通信威胁。 |
| Schlotfeldt et al., IROS’18 | 信息采集在对抗/失败下 | 韧性信息采集近似保证 | 间接 | ❌ | 面向信息获取的通用韧性,非专门的危险区(感知/通信)建模。 |
| Ramachandran et al., T-ASE’23 | 多机器人多目标在失败/重构下 | 网络重构保持跟踪 | 部分 | 部分 | 侧重连通性/重构;未建风险场/机会约束与未知区的共享策略。 |
| Zhou et al., ICRA’20 | 攻击鲁棒的分布式规划 | 分布式鲁棒子模优化 | 间接 | ❌ | 抗 DoS/移除的分布式近似;不含通信干扰区与恢复共享。 |
| Schwager et al., ISRR’17 | 未知危险下的信息获取 | 策略在探索中避险/收集 | ❌ | 部分 | 讨论未知危险但未涉及通信干扰与跟踪-风险联合优化。 |
创新点的直觉是什么?如何解决
把“安全”做成可调的概率约束:不是一味避险,而是用软机会约束+松弛让机器人在可控风险下靠近目标获取信息;当风险收益比高时允许“触险”,但配合逃离-恢复-共享链路,把一次失败变成共享知识,减少后续团队的风险暴露(如下图,“在多重红/蓝危险区里发现—共享—绕行—恢复”的时间序列可视化。
具体地,上排 (a) Resilient tracking):展示所提协同韧性跟踪随时间的演化(从左到右)。 机器人在任务中逐步碰到并识别未知危险区(红/蓝团),把“碰撞点” (+)(+)(+) 当作边界证据,并共享给队友; 团队基于共享信息重规划绕行,尽量让至少一台机器保持对两个目标的可观测/可通信;
整个过程中即使多次遭遇不同类型的攻击(先感知后通信),系统仍能恢复并继续稳定跟踪,同时不断“轮廓化”各危险区。 下排 (b) Vanilla tracking):普通策略没有韧性与共享机制。两个机器人在推进中反复踏入红/蓝区而失效,难以及时绕行与恢复,表现为被动、滞后、易失效。)。
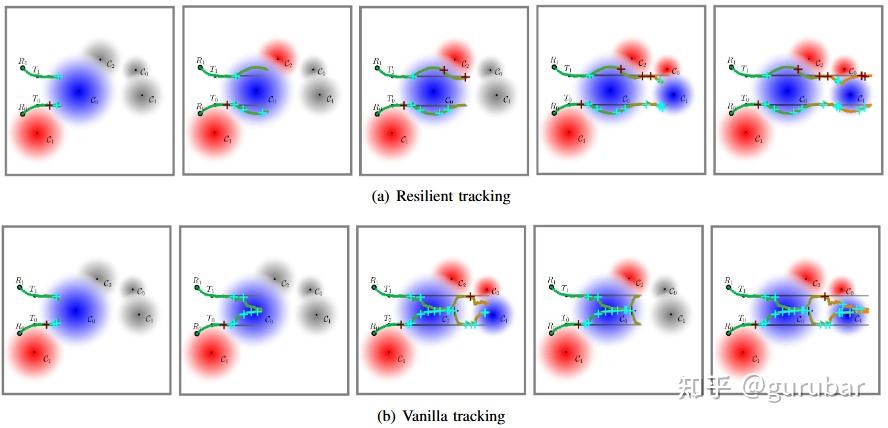
分裂-合流的估计与规划:通信被干扰时,受害机器人单机 EKF继续跟踪并最优逃离;恢复后通过协方差交集(CI)与队友的估计无偏合并,再回到集中式优化,完成估计与规划层面的“闭环合流”。
从“已知危险区的保守稳健”到“未知危险区的韧性协同”:与以往已知风险场或最坏移除的稳健方法相比,本文把危险区当作未知的随机场,在运行中逐步揭示并共享,使“稳健”从离线约束升级为在线可适配的团队行为。其效果如下图,韧性跟踪在遭遇“感知/通信危险区”时,能通过识别—共享—绕行—恢复把误差与不确定性都压在较低且稳定的水平;而 vanilla 跟踪会在干扰期丢失目标并发散,表现为 MSE 飙升、协方差迹显著增大与波动。

实现问题/工程要点
阈值与权重调参:感知/通信恢复阈值 ϵl,0,ϵk,0与约束松弛权重 w3,w4 共同决定“风险偏好”(保守 vs. 进取)。过小会频繁触发恢复/绕行,过大则可能累积失败。
未知区定位的偏差:危险区用高斯中心+半径/距离比建模;受攻击频率、进入轨迹与传感噪声影响,早期估计可能偏移/过宽,需要在共享后持续修正。
通信受阻的“失联策略”:单机阶段只有本机观测与风险场估计,易保守;逃离路径规划与恢复判据(概率低于阈值)要与机动性约束协调,避免在边界徘徊。
估计合并的细节:CI 的权重 ω 需根据方差或指标优化;若存在未建模相关性,CI 是安全但偏保守的合并,可能牺牲部分收敛速度。
实验假设与落地差距:文中默认不同高度避免机器人互撞、通信无距离上限且即时共享;落地到大尺度户外需考虑通信时延/丢包与碰撞/编队约束的扩展。
可能的价值在哪里
更一致的长期任务质量:仿真显示相较“无韧性”基线,本方法在多次攻击序列下仍能把跟踪 MSE 与协方差迹控制在低水平,避免误差爆炸;即使个别机器人失效,也能逃离-恢复-再协同维持团队性能。
从“避险”到“韧性协同”的范式转变:把失败当作收集环境风险信息的机会,通过共享危险区减少队友重复“踩雷”;适合安防巡检、灾情评估、野外监测等对抗/不确定环境。
开源可复现:作者公开了代码与演示视频,便于在其他平台上快速对比与移植(如将通信半径/延迟、移动平台动力学、更多估计器替换进去)。
DRACo-SLAM2: Distributed Robust Acoustic Communication-efficient SLAM for Imaging Sonar Equipped Underwater Robot Teams with Object Graph Matching
https://arxiv.org/pdf/2507.23629
文章面对的是什么问题
在成队水下机器人 + 成像声呐的场景里,多机器人 SLAM 同时受制于: 极低带宽声学通信( HS 模块短距典型仅 62.5 kbps),难以交换高维特征/点云; 声呐图像低分辨/噪声大/易“感知同形”(perceptual aliasing),跨机器人回环(inter-robot loop closure)匹配容易误配; 既有多机器人声呐 SLAM(如 DRACo-SLAM)能做分布式协作,但跨机器人回环依赖Go-ICP 全局配准,算力开销大;而经典 PCM 仅做两两一致性,当“同一片区域有多组近似误差的回环”时易保留异常。
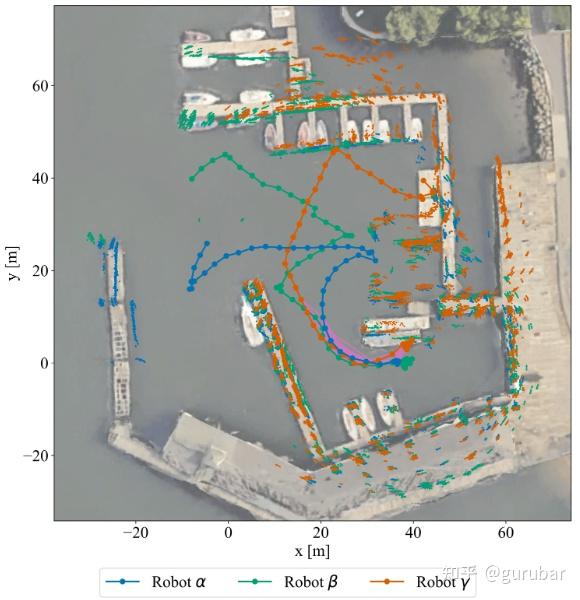
本文要解决:在低带宽与声呐可视性差的水下环境中,怎样以更“通信节俭 + 计算高效 + 抗混淆”的方式完成团队级回环关联与图优化。如下图,本文提出的DRACo-SLAM2 能把三台机器人的声呐观测在分布式、低带宽通信下融合成一张与卫星图匹配的全局地图的并通过跨机回环约束获得一致的轨迹与地图。
文章的解决思路;与典型路线的差异
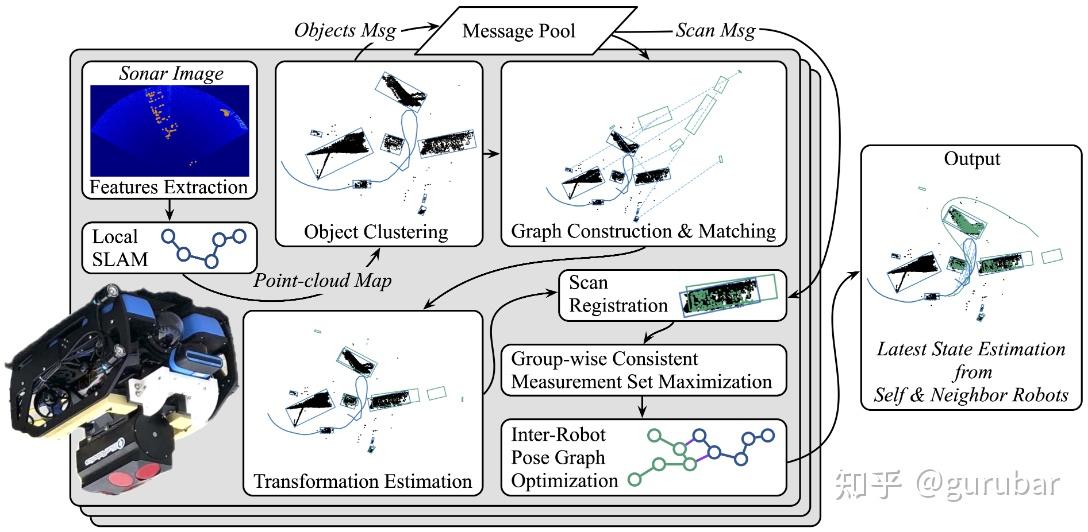
总体管线(图2):单机基于 Bruce-SLAM 的本地声呐 SLAM→从最新局部点云 DBSCAN 出对象地图(矩形框:中心 + 长宽)→只广播对象图(低比特)→对象图匹配(QAP 光谱解)得到跨机器人初始位姿→只按匹配对象请求少量相关点云,以此初值做 ICP 精化配准→用GCM(Group-wise Consistent Maximization)替代 PCM 做回环内点筛选→两步式 PGO(先本地+相关邻居,后按邻居分组局部全局化)加速收敛。关键结果:ICP 模块平均提速 ≈20×;整个跨机回环模块单位时步执行次数↑(≈122 次/步)且总耗时≈1/10;对象图消息量 ≈1–2 kbit,远低于 62.5 kbps 限制。
| 方法 | 输入/表征与交换 | 回环/配准策略 | 抗混淆/鲁棒 | 带宽/算力侧 | 与本文差异 |
|---|---|---|---|---|---|
| DRACo-SLAM2(本文) | 交换对象图(矩形中心与尺寸),必要时再拉取少量点云 | 对象图匹配(QAP) → ICP(滑窗);GCM 群一致性筛选;两步式 PGO | 以群一致性应对“同域相似误差”;回环更密更稳 | ICP 平均快 ~20×;回环模块时步耗时 ~1/10 | 首次把对象图匹配用于水下跨机回环;系统/代码开放。 |
| DRACo-SLAM(IROS’22) | 交换紧凑环形描述子 + 点云 | 环形描述子召回 → Go-ICP 精配准 | 用 PCM 两两一致性 | Go-ICP 重;频率受限 | 本文以对象图初值 + 标准 ICP替代 Go-ICP,显著提速。 |
| PCM(ICRA’18) | — | Pairwise 一致性最大化 | 抗少量粗错 | 面对多对相似误差易失效 | 本文扩展为GCM(群一致性)。 |
| SemanticLoop(RAL’22) | 3D 语义对象图 | 语义图匹配做回环 | 语义稳定、抗外观变 | 需语义检测 | 本文不依赖语义标签,只用几何+拓扑对象图匹配。 |
| SONAR-Context(ICRA’23) | 极坐标全局声呐描述子 | 描述子召回 → 初值 → ICP | 高效、无需学习 | 别名环境仍有误召回 | 本文以子图(对象图)级匹配降低别名。 |
| MAM3SLAM(Ocean Eng. ’24) | 多机视觉集中式 | 视觉特征 + 回环 | 多场景评测强 | 受水体可视性 | 本文面向声呐与低带宽,且分布式。 |
| 显式多会话/分布式配准(GMRBnB 等) | 各自建图后集中/离线配准 | 全局/组合配准 | 适合测深制图 | 不利实时决策 | 本文强调在线跨机回环与实时两步 PGO。 |
创新点的直觉 & 机制
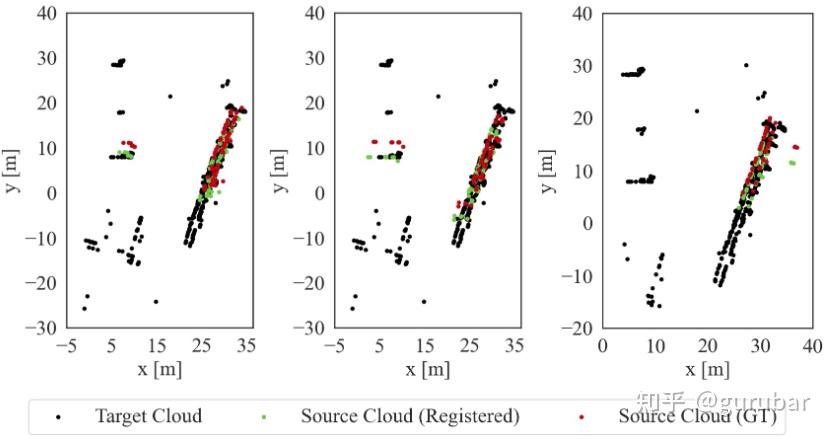
直觉 A|“把点云→对象图”,先对齐结构再精配准:声呐图细节差但布局可辨。先把局部点云聚类成对象(中心/长宽 + 互距构成完全图),用 QAP 光谱法求跨机对象图匹配 → 得到粗位姿初值 → 只拉取重叠对象的点云再做 ICP,大幅减算力与通信且更抗Aliasing(如下图,左图:橙色是源点云,黑色是目标点云。先用“对象图匹配”估计到一个粗位姿 T_init,把源点云大致变换到目标坐标系,两团点已经大致对上但仍有偏差。 右图:在 T_init 上运行 ICP(滑动窗口大小为 3,只用最近 3 帧,提高鲁棒性),得到精配准后的源点云(绿色),与黑色目标云紧密重合。)。

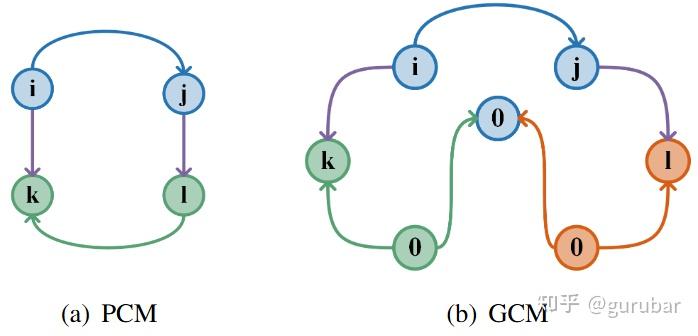
直觉 B|“别用成对看错—改用群体一致性”:同一片区域的多组跨机回环可能呈现相似的错误变换(声呐配准噪声/重合度影响),PCM 的 pairwise 容易一起放行。GCM 用“三机(或多机)闭环一致性”来裁剪这类群体相似错配(如下图, 展示“很多回环在同一区域产生相似错配”这一现实困境; 说明 GCM 用“多条回环构成闭环的一致性”来识别并剔除这类“成群出错”的回环,而PCM的成对检验容易失手。)。
直觉 C|“分两步优化,更快收敛、抑制串扰”:先以本机+相关邻居做局部 PGO,再对相关邻居做小范围全局化,避免一次性全图优化的收敛慢与误差传染。
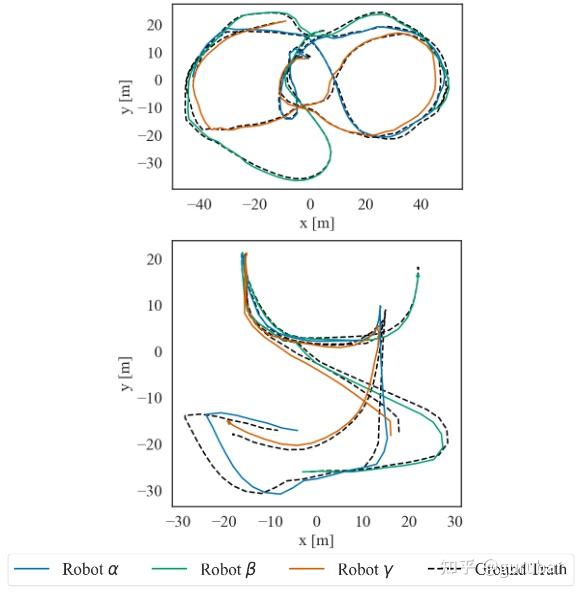
如下图,上图(仿真)中三机轨迹几乎与真值重合,说明在充分回环的条件下,DRACo-SLAM2 能把多机轨迹对齐到接近真值。 下图(真实海港)仍能基本贴合,但因声呐噪声、遮挡与回环稀疏,个别段落存在偏差;整体仍保持多机一致且全局对齐。
直觉 D|“通信只发该发的”:常发对象图(kbit 量级),命中后再按需拉取少量点云;配合滑窗 ICP与重叠率阈值(文中取 0.9),回环数↑且精度稳。
实现问题/工程要点
对象图质量:DBSCAN 的 n_min , d_min 影响“物体 vs 噪声”分割;对象尺寸/间距作为匹配权重的尺度鲁棒性需在不同场景重定标(文中 μ=4)。
QAP 光谱解→LAP:先光谱近似,再 JV(Jonker-Volgenant)解线性指派,速度快但对噪声/稀疏对象要结合 RANSAC 过滤。
配准细节:对象图估计的刚体变换作为 ICP 初值,并用滑窗(=3) 目标点云提升重叠,仍需重叠率门限与鲁棒核(Cauchy in GTSAM)。
GCM 参数:相较 PCM,群一致性涉及更多相对位姿组合,需缓存/查询历史跨机变换(文式(12)(13));实现上注意数值稳定与边界条件(回环稀疏时退化到 pairwise)。
通信策略:对象图消息 ≈1–2.25 kbit;点云仍占大头(与 DRACo1 近似),应仅在图匹配命中后拉取,且按显著更新再广播历史状态,贴合 ≤62.5 kbps 的声学链路。
适用假设:实验中各机器人等深度(3DoF 位姿),海况/流速、时延/丢包未深入建模;户外实航需加入时延鲁棒 PGO/通信重传与6DoF 扩展。
可能的价值
把“跨机回环”做成既省带宽又高频的常规能力:对象图先对齐 + 少量点云精配准,回环更密、优化更稳,支撑主动探索/协同建图的实时闭环。
面向真实水域的“韧性”方案:相比依赖视觉的多机 SLAM,声呐-优先的设计在浑浊/低光下更可靠;对港区/近海工程/水下安检等多机长航任务直接受益。
开源生态 + 可复现实验:提供代码与HoloOcean 仿真复现实验,并给出真实 USMMA 数据流程,便于你在本队平台快速对比/迁移。