
最近半年,VLA 在机器人策略学习上的惊艳表现,让“用规模推动智能”再次成为可能,也被视为通往通用智能的重要路径。强化学习被普遍认为能进一步释放 VLA 的潜力。但现实却很骨感:缺少成熟的 RL 框架、难以复用的代码结构、高昂的显卡开销,都让新算法的开发门槛居高不下。
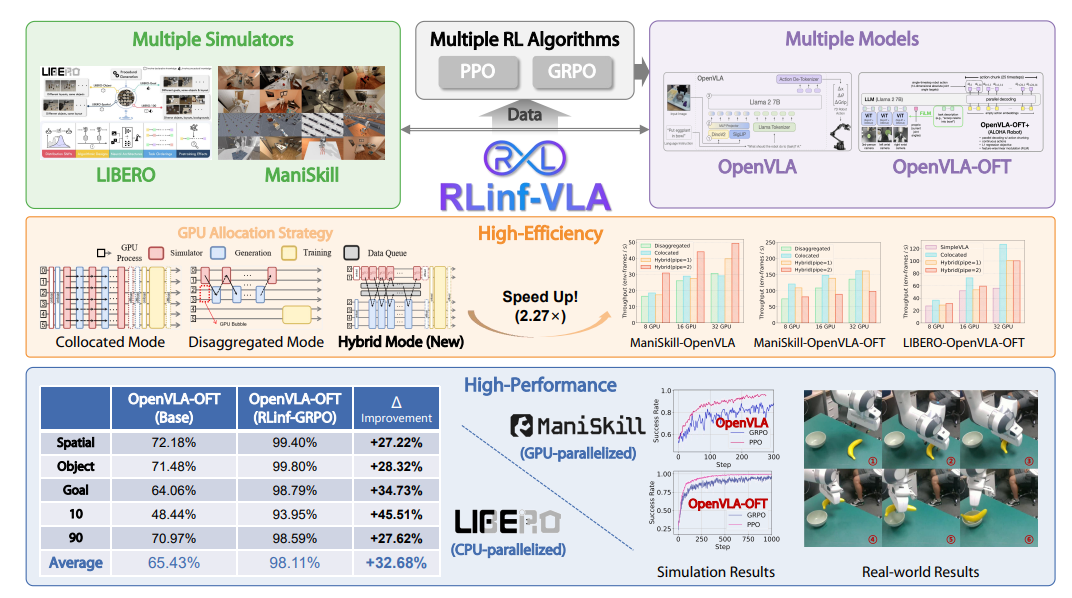
为了解决这些痛点,我们打造了 RLinf-VLA ——一个统一、高效、可扩展的 VLA 强化学习框架,让你能专注于算法本身,而不是在工程复杂度里挣扎。它不仅优化了训练与推理的资源利用,还在架构上为多种仿真器、VLA模型和 RL 算法支持。
https://arxiv.org/pdf/2510.06710
12月2日(周二)晚8点,青稞Talk 第94期,RLinf 强化学习框架 VLA 部分的核心开发人员之一、清华大学交叉信息研究院本科生臧宏之,将直播分享《RLinf-VLA 实践:从零上手 VLA(OpenVLA )强化学习》。
在本次直播中,我们将深入讲解 RLinf-VLA 的设计思路、系统结构与实际性能。
分享嘉宾
臧宏之,清华大学交叉信息研究院本科生,研究兴趣在强化学习与机器人学习。RLinf 强化学习框架 VLA 部分的核心开发人员之一。
主题提纲
RLinf-VLA 实践:从零上手 VLA(OpenVLA )强化学习
1、RLinf-VLA 的设计思路与系统架构
2、关于 VLA+RL 的算法技术设计: PPO / GRPO 等
3、OpenVLA 的微调实践
4、AMA (Ask Me Anything)环节
直播时间
12月2日20:00 - 21:00