摘要
我们推出了 LongCat-Flash,一个拥有 5600 亿参数的专家混合 (Mixture-of-Experts, MoE) 语言模型,旨在兼顾计算效率与先进的智能体 (Agentic) 能力。为满足可扩展效率的需求,LongCat-Flash 采用了两项新颖设计:
a) 零计算专家 (Zero-computation Experts):此机制能够实现动态计算预算分配,根据上下文需求为每个词元(token)激活 186 亿至 313 亿(平均 270 亿)不等的参数,从而优化资源利用。
b) 快捷连接 MoE (Shortcut-connected MoE):此设计扩大了计算与通信的重叠窗口,与同等规模的模型相比,在推理效率和吞吐量方面展现出显著的提升。
我们为大模型开发了一个全面的扩展框架,该框架结合了超参数迁移 (hyperparameter transfer)、模型增长初始化 (model-growth initialization)、多管齐下的稳定性套件以及确定性计算 (deterministic computation),以实现稳定且可复现的训练。值得注意的是,通过利用可扩展架构设计与基础设施工程的协同效应,我们在 30 天内完成了超过 20 万亿词元的模型训练。在推理方面,我们实现了超过每秒 100 词元 (TPS) 的速度,而每百万输出词元的成本仅为 0.70 美元。
为了培养 LongCat-Flash 的智能体能力,我们首先在优化的数据混合上进行了大规模预训练,随后针对推理、代码和指令进行了目标明确的中期和后期训练,并通过合成数据及工具使用任务进一步增强其能力。全面的评估表明,作为一个非思维(non-thinking)基础模型,LongCat-Flash 在与其他领先模型的竞争中表现出极高的竞争力,并在智能体任务中展现出卓越的实力。LongCat-Flash 的模型权重已开源,以促进社区研究。
- LongCat Chat: https://longcat.ai
- Hugging Face: https://huggingface.co/meituan-longcat
- GitHub: https://github.com/meituan-longcat
1. 引言
以 DeepSeek-V3、Qwen3 和 Kimi-K2 为代表的大型语言模型(LLMs)的飞速发展,已证明了通过扩展模型尺寸和计算资源来提升性能的有效性。尽管近期有研究对扩展定律的持续性提出疑虑,但我们坚信,算法设计、底层系统优化和数据策略在推动可扩展智能的前沿中扮演着同等关键的角色。这要求我们在模型架构和训练策略上不断创新,以提升规模化的成本效益,并制定系统性的数据策略,以增强模型解决真实世界任务的能力。
在本项目中,我们介绍了 LongCat-Flash,一个高效且强大的专家混合(MoE)语言模型,其设计旨在从两个协同的方向推进语言模型的边界:计算效率和智能体能力。通过在数万个加速器上进行训练,LongCat-Flash 将架构创新与一套复杂的多阶段训练方法论相结合,旨在构建可扩展的智能模型。我们的主要贡献涵盖以下方面:
为计算效率设计的可扩展架构
LongCat-Flash 的设计与优化遵循两大核心原则:高效的计算资源利用以及高效的训练与推理。具体来说:
- 鉴于并非所有词元的重要性都相同,我们在 MoE 模块中引入了零计算专家机制。该机制能够根据词元的上下文重要性动态分配计算预算,按需激活 186 亿到 313 亿不等的参数(总参数量为 5600 亿)。为了确保计算负载的稳定性,我们采用了一个由 PID 控制器调节的专家偏置(expert bias),使得每个词元平均激活约 270 亿参数。
- 由于通信开销是 MoE 模型规模化过程中的主要瓶颈,我们整合了快捷连接 MoE (ScMoE) 架构。该设计通过扩大计算与通信的重叠窗口,结合定制化的基础设施优化,使我们能够在数万个加速器上进行大规模训练,并实现高吞吐量、低延迟的推理。
有效的模型扩展策略
高效地扩展模型尺寸是策略设计中的一个核心挑战。为此,我们开发了一个全面的"稳定性与扩展性"框架,用于稳健地训练大规模模型:
- 我们成功地将超参数迁移策略应用于如此庞大的模型,通过利用小型代理模型并结合理论保证,来预测最优的超参数配置。
- 我们采用基于一个精炼的半尺寸模型检查点的模型增长机制来初始化模型,与传统的随机初始化方法相比,性能得到了显著提升。
- 我们设计了一套多管齐下的稳定性保障方案,包括原则性的路由梯度平衡、抑制隐层大规模激活的 z-loss,以及精细调优的优化器配置。
- 为了增强大规模集群训练的可靠性,我们引入了确定性计算,这保证了实验结果的精确可复现性,并能在训练过程中检测到静默数据损坏(Silent Data Corruption, SDC)。这些措施确保了 LongCat-Flash 的训练过程稳定,未出现任何无法恢复的损失尖峰。
为智能体能力设计的多阶段训练流程
通过精心设计的训练流程,LongCat-Flash 具备了先进的智能体行为能力。我们首先构建了一个更适合智能体任务后训练的基础模型,其中设计了两阶段预训练数据融合策略,以集中训练推理密集型领域的知识。在中间训练阶段,我们增强了模型的推理和编码能力,同时将上下文长度扩展至 128k,以满足智能体后训练的需求。在此基础上,我们进行了多阶段的后训练。考虑到智能体任务的高质量、高难度训练数据稀缺,我们设计了一个多智能体合成框架,该框架从信息处理、工具集复杂性和用户交互三个维度定义任务难度,并使用专门的控制器生成需要迭代推理和环境交互的复杂任务。
综合来看,得益于我们在可扩展架构设计、训练策略和基础设施工程方面的协同努力,LongCat-Flash 实现了高训练吞吐量和低推理延迟。我们在 30 天内完成了对 5600 亿参数模型超过 20 万亿词元的预训练,并在无需人工干预故障排查的情况下,实现了 98.48% 的有效训练时长。在推理部署上,该模型在 H800 GPU 上实现了超过 100 TPS 的效率,每百万输出词元的成本仅为 0.7 美元,与同规模模型相比表现出卓越的性能。
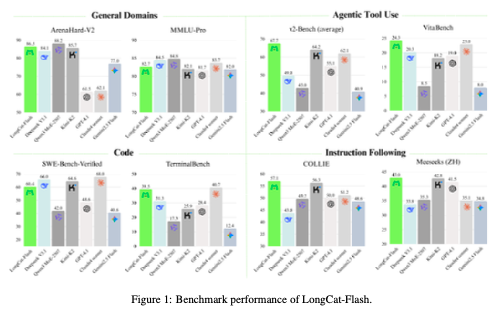
我们对 LongCat-Flash 的基础模型和指令微调模型在多个基准上进行了评估。作为一个非思维模型,LongCat-Flash 取得了与业界顶尖非思维模型(如 DeepSeek-V3.1 和 Kimi-K2)相当的性能,同时使用了更少的激活参数并提供了更快的推理速度。具体而言,LongCat-Flash 在 ArenaHard-V2 上得分 86.5,在 TerminalBench 上得分 39.5,在 τ²-Bench 上得分 67.7,展现了其在通用领域、编码和智能体工具使用方面的强大能力。为减少现有开源基准可能带来的数据污染并增强评估的可信度,我们还构建了两个新的基准:Meeseeks 和 VitaBench。Meeseeks 通过迭代反馈框架模拟真实的人机交互,评估模型的多轮指令遵循能力,LongCat-Flash 在此基准上取得了与前沿模型相当的分数。VitaBench 则利用真实业务场景评估模型处理复杂现实任务的熟练度,LongCat-Flash 在此表现优于其他大语言模型。
2. 架构设计
LongCat-Flash 采用了一种新颖的 MoE 架构,其核心在于两项关键创新。
2.1. 零计算专家 (Zero-Computation Experts)
在语言模型中,对下一个词元的预测任务天然存在计算异质性。复杂的词元可能需要更多的计算资源才能准确预测,而简单的词元则几乎不需要计算。这一现象在推测解码 (Speculative Decoding) 中也得到了经验证实:一个小型草稿模型就能可靠地预测大型模型在处理多数简单词元时的输出。
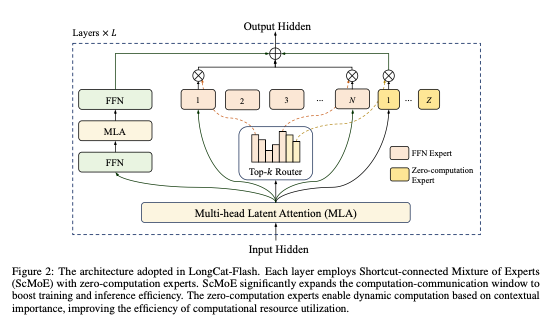
受此启发,LongCat-Flash 通过零计算专家机制,为每个词元激活数量可变的 FFN 专家,从而实现动态的计算资源分配。这使得模型能够根据上下文的重要性,更合理地调配计算资源。具体来说,LongCat-Flash 在其标准的 N 个 FFN 专家之外,额外扩展了 Z 个零计算专家。这些零计算专家极为高效,它们仅将输入 x_t 原样返回,不产生任何额外计算开销。其 MoE 模块的数学形式如下:
\text{MoE}(x_t) = \sum_{i=1}^{N+Z} g_i E_i(x_t)
其中,路由权重 g_i 和专家函数 E_i(x_t) 定义为:
g_i = \begin{cases} \text{Softmax}(\text{Router}(x_t) + b_i)_{\text{TopK}}, & \text{if expert } i \text{ is in Top-K} \\ 0, & \text{otherwise} \end{cases}
E_i(x_t) = \begin{cases} \text{FFN}_i(x_t), & \text{if } 1 \le i \le N \\ x_t, & \text{if } N < i \le N+Z \end{cases}
2.1.1. 计算预算控制
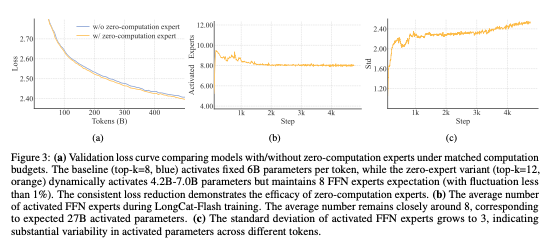
为了激励模型学习依赖上下文的计算分配,对零计算专家的平均选择率进行精细控制至关重要。若无明确约束,模型倾向于较少使用零计算专家,导致资源利用效率低下。
我们通过改进一种无辅助损失 (aux-loss-free) 策略中的专家偏置机制来解决此问题。我们引入了一个专家特定的偏置项 b_i,它根据近期的专家利用率动态调整路由分数,同时与语言模型本身的训练目标解耦。b_i 的更新增量计算如下:
\Delta b_i = \begin{cases} \mu \left( \frac{K_e}{K \cdot N} - \frac{T_i}{T_{\text{all}}} \right), & \text{if } 1 \le i \le N \\ 0, & \text{if } N < i \le N+Z \end{cases}
其中,\mu 是偏置适应率,T_{\text{all}} 是全局批次中的词元总数,T_i 是路由到第 i 个专家的词元数,K_e 是期望激活的 FFN 专家数量(K_e < K)。
2.1.2. 负载均衡控制
高效的 MoE 训练需要专家之间稳健的负载均衡。虽然上述的计算预算控制在语料库级别上强制了均衡,我们还引入了一种设备级负载均衡损失,以进一步防止在专家并行(EP)组之间出现极端的序列级不平衡。
L_{LB} = \alpha \sum_{j=1}^{D+1} f_j P_j
2.2. 快捷连接 MoE (Shortcut-Connected MoE)
我们最初的架构采用了 MoE 和密集 FFN 模块交错的拓扑结构。然而,大规模 MoE 模型的效率在很大程度上受到通信开销的制约。在传统执行模式中,专家并行化带来了一个串行工作流:必须先通过一次全局通信操作(All-to-All)将词元路由到指定的专家,然后才能开始计算。
为了克服这一限制,我们采用了 Shortcut-connected MoE (ScMoE) 架构。ScMoE 引入了一个跨层快捷连接,它重排了执行流程。这一关键创新使得前一模块的密集 FFN 计算可以与当前 MoE 层的路由通信(dispatch/combine)并行执行。
该架构选择基于以下关键发现:
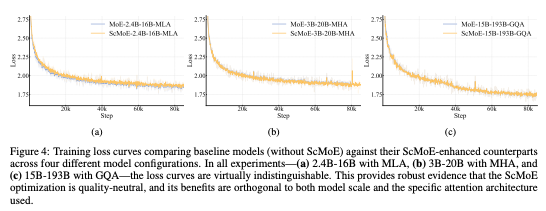
- ScMoE 架构不牺牲模型质量:采用 ScMoE 的模型与基线模型的训练损失曲线几乎完全重合。这一结果在多种模型配置下都保持一致,有力证明了 ScMoE 是一项质量中立 (quality-neutral) 的优化。
- ScMoE 架构带来显著的系统效率增益:
- 对于大规模训练:通过将操作沿词元维度切分为细粒度块,扩展的重叠窗口允许前一模块的计算与 MoE 层的通信阶段完全并行。
- 对于高效推理:ScMoE 实现了一个单批次重叠 (Single Batch Overlap) 流水线,理论上的每输出词元时间 (TPOT) 降低了近 50%。
2.3. 为可扩展性设计的方差对齐
在小规模上表现优异的架构设计在模型规模扩大时可能变得次优。通过广泛实验和理论分析,我们发现特定模块中的方差错位 (variance misalignment) 是导致这种性能差异的关键因素。
2.3.1. MLA 的尺度校正
LongCat-Flash 采用了改进的多头潜在注意力 (MLA) 机制,该机制引入了尺度校正因子 \alpha_q 和 \alpha_{kv},以解决非对称低秩分解中固有的方差不平衡问题。
缩放因子定义为:
\alpha_q = \sqrt{\frac{d_{\text{model}}}{d_q}} \quad \text{and} \quad \alpha_{kv} = \sqrt{\frac{d_{\text{model}}}{d_{kv}}}
2.3.2. 专家初始化方差补偿
LongCat-Flash 采用了细粒度专家 (fine-grained expert) 策略,即将每个逻辑专家进一步分割为 m 个更小的物理专家。我们提出了一种方差补偿机制,对专家的聚合输出应用一个缩放因子 \gamma = m:
\text{MoE}(x_t) = \gamma \left( \sum_{i=1}^{mN} g_i \cdot E_i(x_t) \right)
2.4. 模型信息
| 参数 | 值 | 描述 |
|---|---|---|
| 总参数量 | 560 B | 模型所有参数的总和 |
| 激活参数量 | 27 B (平均) | 每个词元平均激活的参数量 |
| 模型隐藏层维度 | 6144 | Transformer 层的隐藏状态维度 |
| 层数 | 80 | Transformer 层的数量 |
| 注意力头数 | 48 | 注意力机制中的头数量 |
| 上下文长度 | 128k | 模型支持的最大序列长度 |
| FFN 专家总数 (N) | 144 | 标准计算专家的数量 |
| 零计算专家总数 (Z) | 48 | 零开销的恒等变换专家数量 |
| Top-K | 12 | 路由器为每个词元选择的专家总数 |
| 期望激活 FFN 专家数 | 8 | 目标平均激活的 FFN 专家数量 |
| 词汇表大小 | 150,528 | 模型使用的词汇表大小 |
3. 预训练
LongCat-Flash 的预训练过程旨在构建一个强大的基础模型,为后续的智能体能力培养奠定坚实基础。
3.1. 训练策略
为了高效且稳定地训练这个 5600 亿参数的庞大模型,我们制定了一套综合性的训练策略。
3.1.1. 超参数迁移
为大型模型寻找最优超参数(如学习率、批次大小)通常成本高昂。我们采用了超参数迁移技术,通过在多个小型代理模型(例如 1B、3B、7B 参数)上进行实验,来预测大规模模型的最优配置。我们发现,在固定计算预算下,最优学习率与模型参数量成反比。基于这一规律,我们成功地为 LongCat-Flash 预测了接近最优的学习率。
3.1.2. 模型增长初始化
从头开始训练超大规模模型通常会经历一个较长的"热身"阶段。为了加速收敛,我们采用了模型增长初始化策略。我们首先训练了一个性能优越的半尺寸(约 280B 参数)模型,然后通过参数复制和微小的随机扰动将其"生长"为全尺寸的 LongCat-Flash 模型。
3.1.3. 训练稳定性
维持大规模 MoE 模型的训练稳定性是一大挑战。我们实施了一套多管齐下的稳定性保障方案:
- 路由梯度平衡:我们对路由器的梯度应用裁剪(clipping),防止因梯度过大导致的路由策略崩溃。
- 隐藏层 Z-Loss:我们引入一个辅助损失项(z-loss),对路由器输出的 logit 值进行 L2 正则化。
- 优化器微调:我们对 AdamW 优化器的参数进行了精细调整,并采用了 BF16 混合精度训练。
- 确定性计算:我们通过优化和替换非确定性的 CUDA 内核,实现了完全可复现的训练过程。
3.2. 通用预训练
预训练数据是模型能力的基础。我们从一个包含超过 100 万亿原始词元的庞大数据湖出发,经过精细的清洗、去重和质量过滤流程,构建了一个高质量的训练数据集。数据来源涵盖网页、书籍、代码、科学文献等。
3.3. 推理和编码能力增强
为了强化模型的推理和编码能力,我们设计了两阶段数据融合策略。在预训练的后期阶段,我们显著增加了代码和数学相关数据在训练批次中的比例。
3.4. 长上下文扩展
为了支持智能体应用中常见的长篇信息处理需求,我们将 LongCat-Flash 的上下文长度从初始的 4k 扩展到了 128k。我们采用了高效的位置编码方法(如 RoPE)和注意力机制(如 Flash Attention 2)。
3.5. 去污染处理
为了保证评估结果的公正性,我们对所有预训练数据进行了严格的去污染 (Decontamination) 处理。我们收集了常见基准测试的验证集和测试集,并使用 n-gram 重叠方法从我们的训练数据中移除了所有与这些基准内容高度相似的片段。
3.6. 评估
我们在多个学术基准上对预训练后的 LongCat-Flash 基础模型进行了评估,并与业界领先的开源模型进行了比较。
| 模型 | MMLU (5-shot) | GSM8K (8-shot) | HumanEval (0-shot) | MATH (4-shot) | BBH (3-shot) |
|---|---|---|---|---|---|
| Llama3-70B | 82.0 | 94.1 | 81.7 | 50.3 | 84.6 |
| Qwen2-72B | 79.2 | 87.3 | 85.9 | 53.0 | 83.1 |
| DeepSeek-V2 | 78.6 | 91.9 | 89.2 | 52.1 | 84.8 |
| LongCat-Flash-Base | 79.5 | 92.5 | 87.5 | 52.8 | 84.9 |
4. 后训练
后训练阶段的目标是将强大的基础模型转化为一个能够遵循指令、具备复杂推理和工具使用能力的智能体。
4.1. 推理和编码微调
我们利用高质量的指令数据对模型进行微调,重点增强其思维链 (Chain-of-Thought, CoT) 推理和代码生成能力。我们发现,在 SFT 阶段继续混合一定比例的预训练数据,有助于防止模型在通用能力上的遗忘。
4.2. 智能体工具使用
培养模型的工具使用能力是构建高级智能体的关键。由于高质量、高难度的工具使用训练数据非常稀缺,我们设计了一个多智能体合成数据框架。该框架包含以下角色:
- 任务控制器:根据预设的难度维度生成任务
- 规划智能体:将复杂任务分解为一系列需要使用工具的子步骤
- 执行智能体:调用指定的工具并获取结果
- 评估智能体:判断任务是否成功完成,并提供反馈
4.3. 通用能力微调
除了专业能力,我们还使用了涵盖广泛领域的指令数据对模型进行微调,以提升其在通用对话、知识问答、文本创作等方面的表现。
4.4. 评估
我们对经过后训练的 LongCat-Flash-Chat 模型进行了全面的评估:
| 模型 | ArenaHard-V2 | Meeseeks | TerminalBench | τ²-Bench | VitaBench |
|---|---|---|---|---|---|
| GPT-4o-2024-05-13 | 92.2 | 8.87 | 45.9 | 75.0 | 79.5 |
| DeepSeek-V2-Chat | 88.9 | 8.78 | 41.5 | 68.3 | 74.2 |
| Qwen2-72B-Instruct | 85.1 | 8.52 | 34.6 | 62.1 | 71.8 |
| LongCat-Flash-Chat | 86.5 | 8.81 | 39.5 | 67.7 | 78.3 |
5. 训练基础设施
训练像 LongCat-Flash 这样的超大规模模型,对基础设施的性能、稳定性和可靠性提出了极高的要求。
5.1. 分布式训练策略
我们采用了3D 并行策略来组织数万个加速器进行协同训练:
- 专家并行 (EP):将 MoE 层中的专家分配到不同的设备上
- 张量并行 (TP):在节点内部对模型的权重矩阵进行切分
- 数据并行 (DP):将训练数据批次分发到不同的计算单元上
5.2. 性能与确定性优化
- 内核优化:我们对关键的计算内核进行了深度优化和融合
- 确定性保证:我们识别并替换了框架中所有非确定性的 CUDA 内核
5.3. 可靠性与可观测性
在数万个加速器上进行长达一个月的训练,硬件故障是常态而非例外。我们建立了一套强大的系统:
- 自动化故障检测与恢复:系统能够实时监控硬件状态,自动检测故障节点
- 全方位可观测性:我们构建了覆盖训练全链路的监控系统
得益于此,LongCat-Flash 的训练实现了 98.48% 的有效时间利用率。
6. 推理与部署
高效的推理是大型模型能否在实际应用中落地的关键。
6.1. 模型特定推理优化
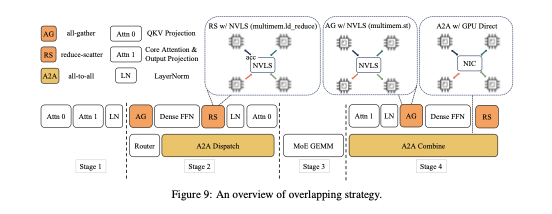
- 计算与通信编排:利用 ScMoE 架构的优势,我们设计了一个高效的单批次重叠流水线
- 推测解码:我们为 LongCat-Flash 训练了一个小型的草稿模型
- KV 缓存优化:我们采用了潜在注意力 (MLA),它将 KV 缓存的大小与序列长度解耦
6.2. 系统级推理技术
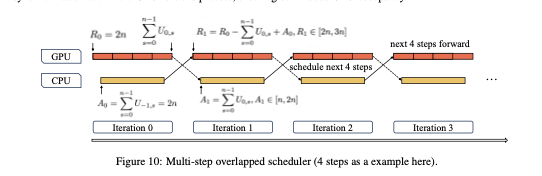
- 自定义内核与量化:我们使用了优化的推理内核
- 连续批处理:我们采用先进的批处理技术
6.3. 性能表现
结合上述优化,LongCat-Flash 在单个 H800 8-GPU 服务器上的推理性能如下:
| 场景 | 吞吐量 (tokens/sec/user) |
|---|---|
| 短上下文 (2k) | > 200 |
| 长上下文 (128k) | > 100 |
这一性能使得 LongCat-Flash 成为一个极具成本效益的解决方案,其每百万输出词元的成本仅为 $0.70。
7. 结论
我们介绍了 LongCat-Flash,一个 5600 亿参数的高效 MoE 语言模型。通过在架构、训练策略和基础设施层面的协同创新,我们成功地解决了大规模 MoE 模型在训练和推理上面临的核心挑战。LongCat-Flash 不仅在计算效率上达到了业界顶尖水平,还在通用能力、推理、编码和智能体任务中展现出卓越的性能。
我们相信,LongCat-Flash 的设计理念和技术实践为未来构建更强大、更高效、更智能的大型语言模型提供了有价值的参考。我们已将模型开源,希望能为社区的研究和应用贡献一份力量。