作者:zhuobai
https://zhuanlan.zhihu.com/p/1935370284921263679
今天跟大家分享下前段时间阅读的来自新国立 showlab 的一篇综述:
Discrete Diffusion in Large Language and Multimodal Models: A Survey
https://arxiv.org/abs/2506.13759v1
最近这两个月都在做 diffusion 的相关工作,感觉这篇很适合想入门 diffusion model 的同学来学习。
这篇文章整体逻辑梳理的很清楚,我将文中部分内容做了简化与提炼,保留了对理解最关键的信息。希望大家读完能有所收获!
I. Introduction
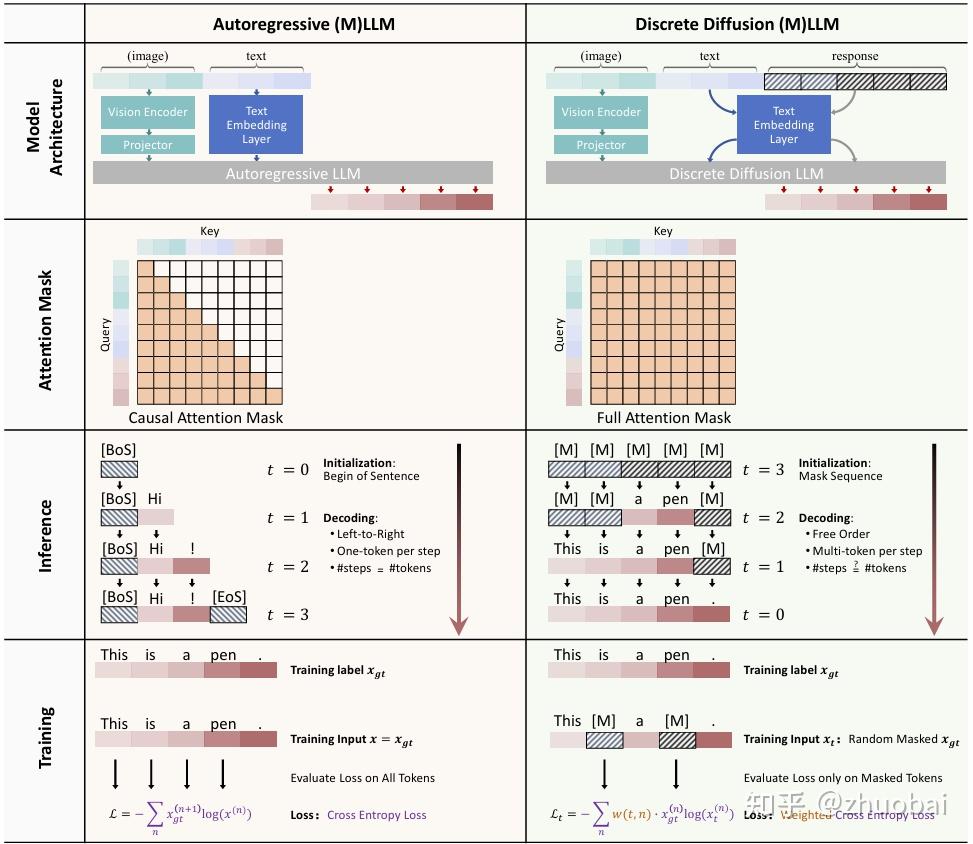
迄今为止,LLMs 和 MLLMs 的主导范式一直是 Autoregression(AR)模型。尽管此前取得了成功,但这些以从左到右顺序生成输出的 AR 模型仍存在一些固有局限性:
- token-by-token 的解码策略天然限制了推理过程中的并行化,在效率提升方面存在瓶颈
- 由于缺乏内建机制来施加 structural constraints(例如指定输出长度或特定格式),AR难以有效地控制输出结构
- 由于 causal attention,AR 只能一次性、静态地感知输入的 visual 和 text。限制了模型的 selective attention,使得模型难以根据任务动态地感知信息,除非借助代价高昂的 CoT 推理或需要外部工具配合的多轮处理方式
Discrete Diffusion Large Language Models (dLLMs) 和 Discrete Diffusion Multimodal Large Language Models (dMLLMs) 近期成为比较火的研究方向。与 AR 不同,dLLMs 将生成过程视为对 token 的迭代去噪过程。该范式具有以下优势:
- Parallel Decoding:dLLMs 在每一次去噪步骤中可以同时生成多个 token,显著加快推理速度
- Better Controllability:dLLMs 将生成过程视为 denoising 或 infilling 任务,这种建模方式允许精确控制输出属性(response length, format,reasoning structure),可通过预定义的模板进行条件生成
- Dynamic Perception:由于 bidirectional attention 机制,dLLMs 能在生成过程中持续修正对视觉与语言上下文的感知,能支持自适应理解能力,克服 AR 静态、单遍处理输入的局限
diffusion models 最初是为图像生成等 continuous domains 提出的,近年来被成功扩展到 discrete spaces。早期研究中学者们建立了相关的基础数学公式,引入了专门为 categorical data 设计的 token corruption schemes,验证了基于扩散的方法在多种 data 上的可行性。
这一初始阶段,模型主要集中在 1B parameters。通过 simplifications 和 reparameterizations 以及结合实际的工程优化实践,the absorbing-state discrete diffusion formulation 逐渐成为开源模型所采用的主流数学框架。
在这种框架下,推理过程表现为 iterative masked token prediction,训练过程则等价于 masked language modeling,loss 可以简化为 weighted 交叉熵损失。
这些简化显著降低了模型在训练和推理阶段的复杂度,同时提升了其稳定性,为 large-scale diffusion language models 的发展奠定了基础。
在工业界,一个重要 scalability 和 effectiveness 的突破 来自 Inception Labs 和 Google 推出的 discrete diffusion-based large language models,分别是 Mercury 和 Gemini Diffusion。在 code 和 math benchmark 中表现出与 AR 相当的性能,在解码速度上提升了10倍,每秒约生成 1000 个 token。
同时科研界也在不断的推进新的工作。dLLMs 和 dMLLMs 的发展路径类似于 AR 的演进:
首先是基于大型语料训练的dLLMs(LLaDA 和 Dream),随后,利用公开可用的 dLLM 作为 backbone,发展出 dMLLMs(Dimple、LaViDa 和 LLaDA-V),通过 multimodal alignment, instruction tuning, preference learning, reasoning enhancement 进行优化。
实验证明这些 dLLMs 和 dMLLMs 在相同的 scale 和 data size 下,能够媲美甚至接近同级别的AR。通过加速技术,推理速度相比 AR 有显著优势。
由于其使用 full attention masks,每一步的计算成本偏高。若不加以优化,实际推理速度无法超越 AR。因此大量研究致力于将原本为 AR 设计的推理加速算法适配至 dLLMs,提升推理效率。
II. Mathematical Formulations
这一节整理了一些具有代表性的 discrete diffusion model 的数学公式,内容比较长,感兴趣的可以去看下原文。
III. Large Discrete Diffusion Language And Multimodal Models
本节主要从 high-level 的角度回顾了一些具有代表性的工作,总共分为四类。
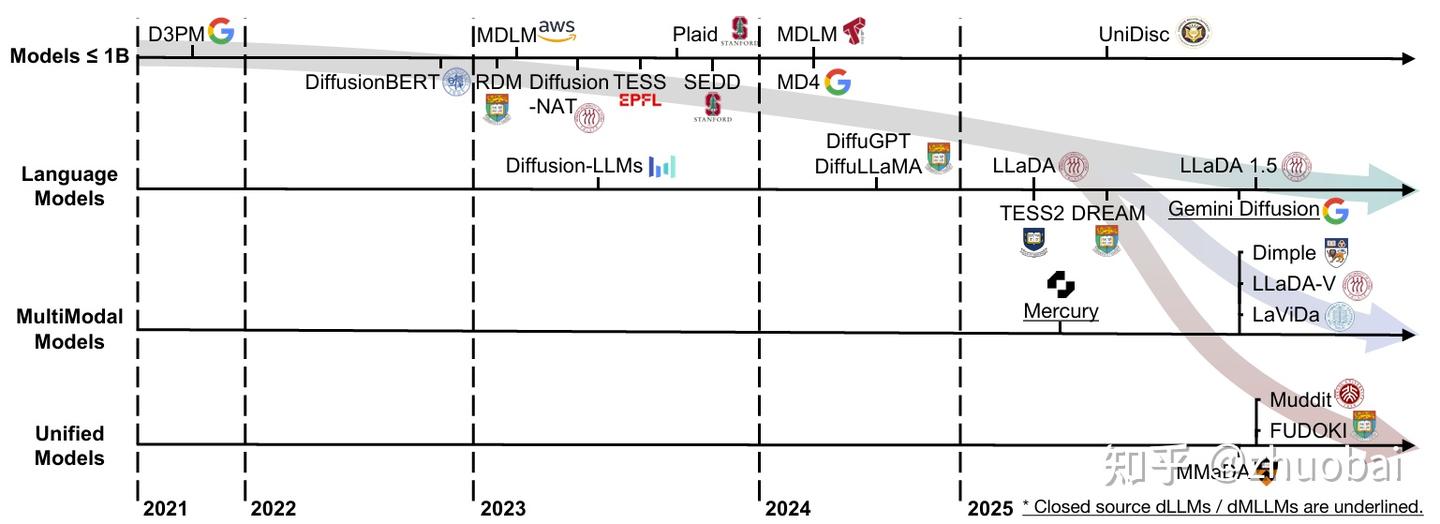
A. Discrete Diffusion Models around 1B
1.D3PM:提出了一类更灵活的 noising schedule 族,将离散扩散扩展到了更广泛的离散空间
2.DiffusionBERT: 探索训练 BERT 来逆向一个具有吸收态的离散扩散过程,引入了与 token 相关的前向噪声调度策略,以及将时间步信息嵌入 BERT 的方法
3.RDMs:L. Zheng 等人从离散扩散采样过程推导出一种等价的形式,并提出了一类新的模型 Reparameterized Discrete Diffusion Models。将 D3PM 的反向扩散过程重新表述为一个两阶段采样过程,从而大大简化了训练目标,并使文本生成过程中拥有更加灵活的解码算法
B. Large Diffusion Language Models
1.LLaDA:首个基于 discrete diffusion、可替代 AR LLM 的方案。对 masked text 逐步去噪生成文本:在前向过程中,随机 mask input token;在反向过程中,利用 Transformer 预测 masked token。
这个 Transformer 与标准 LLM 相似,但取消了 causal masking,因此在预测时可以看到完整的上下文。LLaDA 证明了 dLLM 可以达到与同规模自回归 LLM 相竞争的性能
2.DIFFUSION-LLMs:利用 multi-stage(大规模预训练 → diffusive adaptation 转换为扩散生成 → instruction-tuning)构建 dLLMs。证明了 dLLMs 可作为通用语言模型的可行方案,并凸显了 scale 和 instruction-tuning 的重要性
3.DiffuGPT 与 DiffuLLaMA:将已有的 AR Transformer 转换为 dLLM,避免从零开始训练大模型的高昂成本。将参数规模从 127M 到 7B 的 AR 转换为扩散模型。提出了AR 模型的 next-token prediction 和 diffusion denoising objective 的理论关联,使两种范式在适配过程中能够对齐。
在训练中仅需不到 2000 亿个 token 的 data,大幅降低训练成本。展示了通过适配方式扩展 dLLMs 的现实可行路径,有效利用已有的 AR 模型知识构建高性能的 dLLMs
4.DREAM:DREAM 7B 是目前最强大的 dLLM 之一。专为复杂推理任务而设计,同时保持了良好的效率与可扩展性。其在多个 benchmark 中表现与同规模的 AR 相当甚至更优(LLaMA3 8B 和 Qwen 2.5-7B )。
DREAM 在 1B 规模的模型上系统探索了设计选项,并识别出两个尤为关键的组件:AR weight initialization;context adaptive noise scheduling
5.LLaDA 1.5:针对 dLLMs 的 RLHF,提出了 Variance-Reduced Preference Optimization, VRPO。证明了类似 RLHF 的对齐方法同样适用于 dLLMs,并指出解决 ELBO 估计的方差问题是实现高质量对齐的核心关键。
6.TESS 2:large scale,instruction-following and general-purpose 的 dLLM。整合了以往多个工作的核心思想。
C. Large Diffusion Multimodal Models
1.Dimple:是最早提出的 dMLLM 之一。其 vision encoder + Transformer LLM 的架构与现有的 Qwen-VL、LLaVA 相似。关键创新在于 two stage hybrid training。
- 第一阶段:初始化 Dream 权重,在 vision-language instruction data 上 autoregressive fine-tuned;
- 第二阶段:在 discrete diffusion objective 继续训练。
实验发现,纯扩散训练往往不稳定,会导致 length bias 及性能下降。而通过前期的 AR 训练 warming up,训练更稳定
2.LaViDa:由一个 vision encoder 和一个 discrete diffusion Transformer 组成。image 的 context 通过一个 MLP 将这些 image embedding project 到语言模型的 space。
语言模型是 LLaDA-8B 或 Dream-7B。该模型在 masked-denoising framework 中将 image token 与 text token 一致处理
3.LLaDA-V:基于 LLaDA 构建的 purely dMLLM。它集成了一个 vision encoder 以及一个 MLP connector,将视觉特征映射到 language embedding space,帮助 dLLM 同时处理 image,text。
在使用相同多模态训练数据的条件下,LLaDA-V 的表现可以媲美 LLaMA3-V,并逐步缩小与 Qwen2.5-VL 之间的差距
D. Large Unified Model
1.MMaDA:采用了一种统一的扩散架构,通过 shared probabilistic formulation实现跨模态。使用单一的基于扩散的 Transformer 架构来处理所有数据类型,而非为每种模态配备独立 encoder。支持三种任务:text generation、multimodal understanding、image generation
2.LaViDa:一个基于 Discrete Flow Matching 构建的统一多模态模型
3.Muddit:使用 pure discrete diffusion 同时处理 text 与 image 的统一模型。图像通过预训练的 VQ-VAE 编码;文本通过 CLIP text encoder 处理。在训练与推理过程中,MM-DiT 会在这个联合 token 空间中对被 mask 的 token 进行预测
IV. Training Techniques
A. Challenges
1.Low Corpus Utilization:AR 的每一个答案序列中的 token 都能为学习提供信号,而 diffusion 训练在每个 time step 只对该步的 mask token 进行监督计算损失。不是所有 token 都在训练中被有效利用
2.Random Sampling of Time Index:训练中每个样本仅被监督一个生成步骤,在推理阶段,decoding 通常包含多个时间步的迭代。这种不一致会引入 coverage gap:尽管 decoding 需要跨多个步骤逐步优化,训练却仅为其中一个步骤提供梯度信号
3.Length Bias:生成序列长度是预先设定的,缺乏像 AR 中 [EOS] 这样的自然停止机制。因此,在仅使用扩散目标进行训练时,模型对目标输出长度较为敏感。所以当生成长度变化时,模型性能会出现显著波动,被称为 length bias,难以在不同输出长度之间泛化
B. Initialization Technique
针对 dLLMs 训练中的低效性和不稳定性问题,多项研究采用了先进的 initialization 策略,将完整的扩散训练过程转化为微调任务。
1.BERT Initialization:扩散生成过程可以被视为一种 multi-step masked language modeling 过程。Diffusionbert 即通过从预训练的 BERT 模型初始化扩散模型来进行建模
2.Autoregressive Model Initialization:Dream 7b 探索了从 AR LMs 直接迁移的方法,通过对齐两种范式的训练目标实现扩散模型的适配,借此扩散模型便可以使用 AR 的预训练权重进行初始化
3.Autoregressive-then-Diffusion Training:Dimple 提出了一个先 AR,后 diffusion 的方案,其训练流程分为两个阶段。
- Phase I:Autoregressive Training:Dimple 被当作一个标准 AR 来训练,采用 causal attention mask and next-token prediction loss;
- Phase II:Diffusion Fine-tuning:在完成 AR 训练后,模型进入 discrete diffusion 训练阶段,full attention 和 timestep-dependent masked language modeling losses。
通过引入 AR 的先验能力,Dimple 在训练中表现出更强的指令对齐能力、更好的微调效果,并对输出长度变化更具鲁棒性。
C. Complementary Masking Technique
为确保所有的 token 都在训练中被 mask 并 optimize,LaViDa 使用 complementary masking 对不同的输入序列的 masked version 进行互补。

D. Masking Scheduling Technique
Mask schedule 控制前向扩散过程中的扰动方式。具体来说,schedule 定义了每个时间步 t 的扰动强度 a_t,决定了训练过程中 masked 的 token 比例。一个有效的 schedule 能够通过控制各时间步的signal-to-noise ratio,在学习稳定性与生成质量之间取得平衡。
1.Uniform Masking Scheduling。总共包括:、
- Linear Schedule:mask 比例随时间 t 线性增长。在初始阶段保留更多 token,后期 mask 比例线性上升
- Geometric Schedule:mask 比例随时间 t 指数增长(非常快),初期几乎不加噪,后期迅速mask 大多数 token
- Cosine Schedule:mask 比例一开始变化缓慢,中间变化较快,最后趋于平稳,是一种平滑非线性曲线;被认为在视觉/语言扩散模型中最稳定、有效
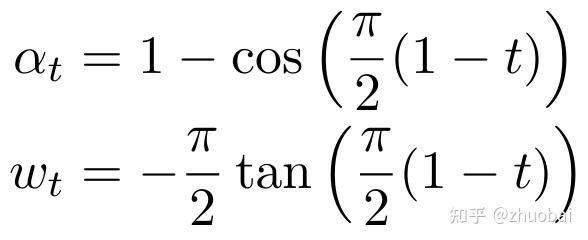
2.Token-wise Masking Scheduling
Uniform masking scheduling 对所有 token 使用相同的调度策略,这忽略了不同 token 之间在信息量上的固有差异。例如,不同的 token 所携带的信息量是不同的,通常可以通过 entropy 来衡量;
而 LLMs 在生成时表现出easy-first 的解码行为 —— 即常见的、低熵的 token 更容易被提前预测出来。diffusionbert 引入了一种基于 token 的 token-wise masking schedule,是比较早的技术了。
V. Inference Techniques
A. Unmasking Techniques
在 dLLMs 和 dMLLMs 中,模型在 iterative unmasking process 的过程中面临的两个核心挑战是 (i)每次迭代中应 mask 掉哪些 token(ii)每次迭代应 mask 掉多少 token。

1.Discrete-Time Unmasking
Random Unmasking:最简单的策略是随机选择当前 step 中的 s_t 个masked token 进行 unmask。 s_t 的取值可以在各步骤中固定,也可以通过 cosine scheduling 控制。
推理阶段所采用的 mask 调度策略不一定要与训练阶段保持一致。在实践中被当作一个 tunable hyperparameter,根据不同任务进行变化
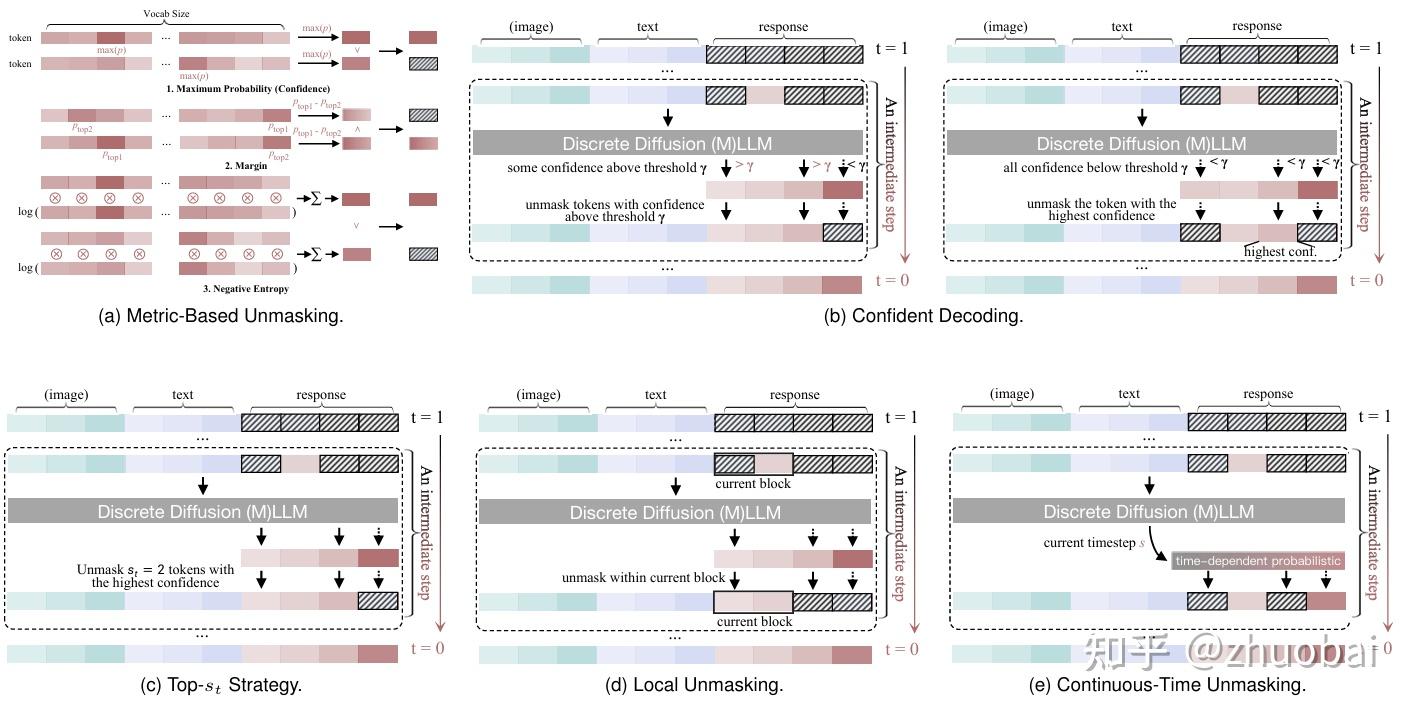
Metric-Based Unmasking:为每个 token 预测分配一个 metric,并依据该 metric 来选择要 mask 的 token。设 p \in \mathbb{R}^K 表示该 token 在 vocabulary 的预测概率分布,其中 K 是 vocabulary size。
- Maximum Probability (Confidence):模型对 the most likely token 的置信程度
- Margin: c = p_{top1} - p_{top2}, p_{top1}和 p_{top2}分别为最高和次高预测概率,衡量最优预测的主导程度
- Negative Entropy: c = -\sum_{i=1}^{K} p_i \log(p_i + \epsilon) ,使用一个很小的常数 ϵ 来保持数值稳定性,反映预测分布的尖锐程度,越尖锐说明模型越有信心。
Selection Policies:在计算出每个 token 的 metric 后,扩散模型会依据不同的策略进行 unmask token 的选择。
- Top-s_t Strategy:选择 highest confidence scores 的 s_t个 token 进行 unmask。s_t的值同样可以遵循 scheduling principles
- Confident Decoding:由 Dimple 提出,基于 fixed confidence threshold,动态选择 unmask 的 token 数量。Motivation:decoding 应适应文本的语义结构,某些步骤中模型可能对很多 token 进行高置信预测,而其他步骤则需要更谨慎。因此,每一步应自适应地调整 decoded token 的数量
- Local Unmasking:上述策略大多属于 global unmasking strategies,即所有 token 的 metric value 会聚合排序以决定选择顺序。然而,unmasking process 也可以是 local 的:所有 token 可以被划分为多个 subgroup,每个 subgroup 内独立进行排序和选择。
一个典型示例是Semi-Autoregressive Decoding。该方法将完整的 response 划分为多个 block,类似于 block diffusion。在每次前向传播中,模型会对所有 block 同时进行预测,但 token 的 unmask 按照从左到右、逐 block 的顺序进行。只有当前 block 中所有 token 被 unmask 后,才允许下一个 block 中的 token unmask
上述所有方法遵循一个共通模式:
(1)为每个 masked position 计算 confidence score;
(2)根据某种规则(threshold, top-k, decaying ratio, block order)选择一个子集 unmask;
(3)重复该过程,直到 no mask。
这样的 metric-based schedules 优先 unmask “容易” 的 token,从而减少错误传播,并支持高度并行化的生成过程。
2.Continuous-Time Unmasking (Flow Matching)
Flow Matching 这块的知识欠缺,没有细读。
B. Remasking Techniques
对于基于 absorbing states 的 discrete diffusion models,在推理过程中,一旦某个 token unmasked,它在后续步骤中将保持不变。这种静态行为限制了模型对先前预测结果进行修改或优化的能力。
为了解决这一问题,remasking 被引入:该技术会在之前 unmasked positions 重新引入 mask,从而使模型能够对生成的输出进行迭代式的优化。
通过 remasking,decoding step 的总次数可以超过目标响应的长度,这就使得模型能够对响应内容进行多次更新与调整。这种机制被视为一种推理阶段 test-time scaling,通过逐步修正的方式提高最终生成结果的质量。
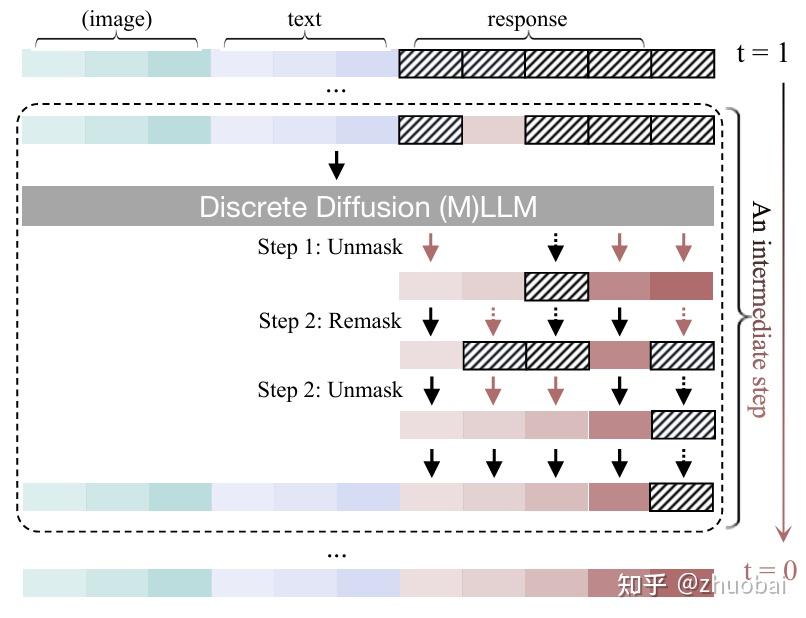
C. Prefilling and Caching Techniques
Prefilling 和 KV-Cache 是当前 AR 推理加速中广泛采用的标准技术。直观来说,Prefilling 和 KV-Cache 通过缓存前一解码步骤得到的 key 和 value 表征,避免重复计算,使模型能够在新的时间步复用这些表示。
在 AR 中,由于使用了 causal attention mask,缓存操作在理论上不会带来损失。这归因于注意力的单向性质,即每个 token 只能关注它之前的 token,因此之前计算得到的 key 和 value 表征在生成过程中始终保持有效且不变。
同样地,在诸如 block-wise decoding 等半自回归生成范式中,也可以在不同 block 之间应用缓存,而不会引入近似误差。
相比之下,dLLMs 和 dMLLMs 采用的是全注意力(双向)机制,其中每个 token 都可以关注序列中的所有其他位置,而不受掩码状态的限制。
因此,即使是已经解码完成并被取消掩码的 token,其对应的 key 和 value 表征也可能受到后续扩散迭代中其他 token 更新的影响。尽管存在这样的理论局限性,实验研究仍然持续验证了在 dLLMs 和 dMLLMs 中引入 Prefilling 与 KV-Cache 技术的有效性。
- Prefilling:多模态模型中,视觉输入的加入会显著增加 prompt token 的数量,往往即使不进行推理,其长度也超过生成回复的长度。对 prompt 进行 Prefilling 能够大幅提升推理效率。Dimple 与 LaViDa 是最早将 Prefilling 技术应用于 dMLLMs 的工作之一。Dimple 的实验结果表明,在大多数视觉语言基准上使用 Prefilling 所造成的性能下降可以忽略不计。引入 Prefilling 在推理效率上取得了显著提升,加速比范围为 2×–7×
- KV cache:由于采用 full attention,dLLMs 和 dMLLMs 中缓存的 KV pairs、注意力输出以及其他值都不是静态不变的。相应的缓存策略通常包括三个组成部分:caching、reuse 和 update。dKV-Cache 与 dLLM-Cache 是最早将缓存技术引入 dLLMs 的工作之一
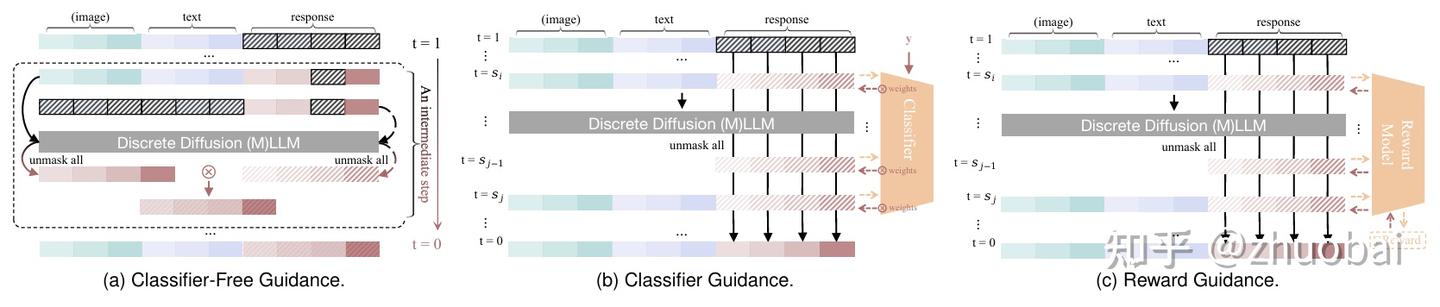
D. Guidance Techniques
在 dLLMs 和 dMLLMs 中,对预测的 logits 或 sampling probabilities 进行 post-processing 的过程通常被称为 guidance,借用了图像扩散模型中的说法。guidance 被用于在生成过程中施加影响,以引导结果朝着期望的特性发展,例如提升 diversity 或者 controllability。主要包括:
- (1)Classifier-Free Guidance
- (2)Classifier Guidance
- (3)Reward Guidance。
技术细节就不详细说明了。
VI. Applications
主要有六个方向:Text Generation and Style Control、Text Editing and Summarization、Sentiment Analysis and Data Augmentation、Knowledge and Reasoning、Vision and Multimodal 和 Biological and Drug Discovery。
VII. Future Directions
A. Training and Infrastructure
目前,dMLLMs 主要沿用了 AR 的架构设计。这类模型通常使用一个 autoregressive LLM(如 Transformer)作为 text encoder,并搭配一个独立的 vision encoder 来提取图像特征。
然后通过一个轻量级的 projector or connector module(通常是一个简单的 MLP)将 vision tokens 和 textual representations 对齐。
尽管这种架构便于工程实现且能够复用已有的预训练组件,但本质上,它是出于工程便利性而非扩散建模需求所做出的迁移。
事实上,diffusion 与 AR 在建模方式上有根本性的不同:前者通过迭代去噪步骤建模联合数据分布,而后者则是通过序列化的条件概率建模。随着模型规模的扩大,这种差异愈加显著。
此外,相较于 AR,dMLLMs 的基础设施仍相对薄弱。在 AR 领域,社区已经拥有成熟的开源模型、标准化的训练框架以及可复现的训练流程,这些都极大地促进了大规模的快速迭代与部署。
因此,建立标准化、模块化且可扩展的训练框架,以及开源预训练模型,将是社区未来发展的关键方向。构建健全的基础设施不仅有助于公平比较与加速创新,还将推动其在实际应用中的落地部署。
B. Inference Efficiency
尽管 dLLMs 近期在各类任务上取得了一定成果,但在推理效率与系统可扩展性方面仍面临显著挑战。未来的研究可以从多个关键方向着手,以提升其实用性与性能:
- 架构层面:引入更高效的注意力机制(如 FlashAttention 以及多尺度 token 表示,可有效降低推理阶段的计算负担
- 去噪过程方面:发展更快的采样技术(如 progressive distillation 与 adaptive timestep scheduling),有望在不牺牲生成质量的前提下加快生成速度
- 模型空间方面:将扩散过程迁移到 latent space,正如潜空间扩散模型所展示的那样,是实现建模能力与推理效率平衡的有前景方法
- 系统部署方面:结合量化推理(如 INT8 或 INT4),可实现高吞吐、低延迟的生成流程
- 多模态场景中:探索更深层次的视觉-语言耦合机制,例如在扩散过程中引入跨模态交互模块或设计模态感知的去噪网络,有望增强模型跨模态推理的能力
总而言之,从模型架构优化、采样加速、表示压缩到部署层级优化的整体融合,构成了推进 dLLMs 向高效、实用的真实世界应用发展的潜在路线图。