作者:假如给我一只AI
https://zhuanlan.zhihu.com/p/1890132185966682238
前言:最近在学习LLM的分布式训练,看到Attention计算相关加速方法是其中重要的一环,虽然之前也碎片化学习过,但已然模糊了,本次系统总结下。本文第一章节讲解FlashAttention,思路为:safe-Softmax->3pass-Softmax->2pass-Softmax->1pass-Attention->FlashAttentionV1->FlashAttentionV2,尽量以图解的方式结合理论和代码进行解释。然后,在第二章节讲解PageAttention,在第三章讲解RadixAttention。
本文用电脑食用效果更佳
一、FlashAttention
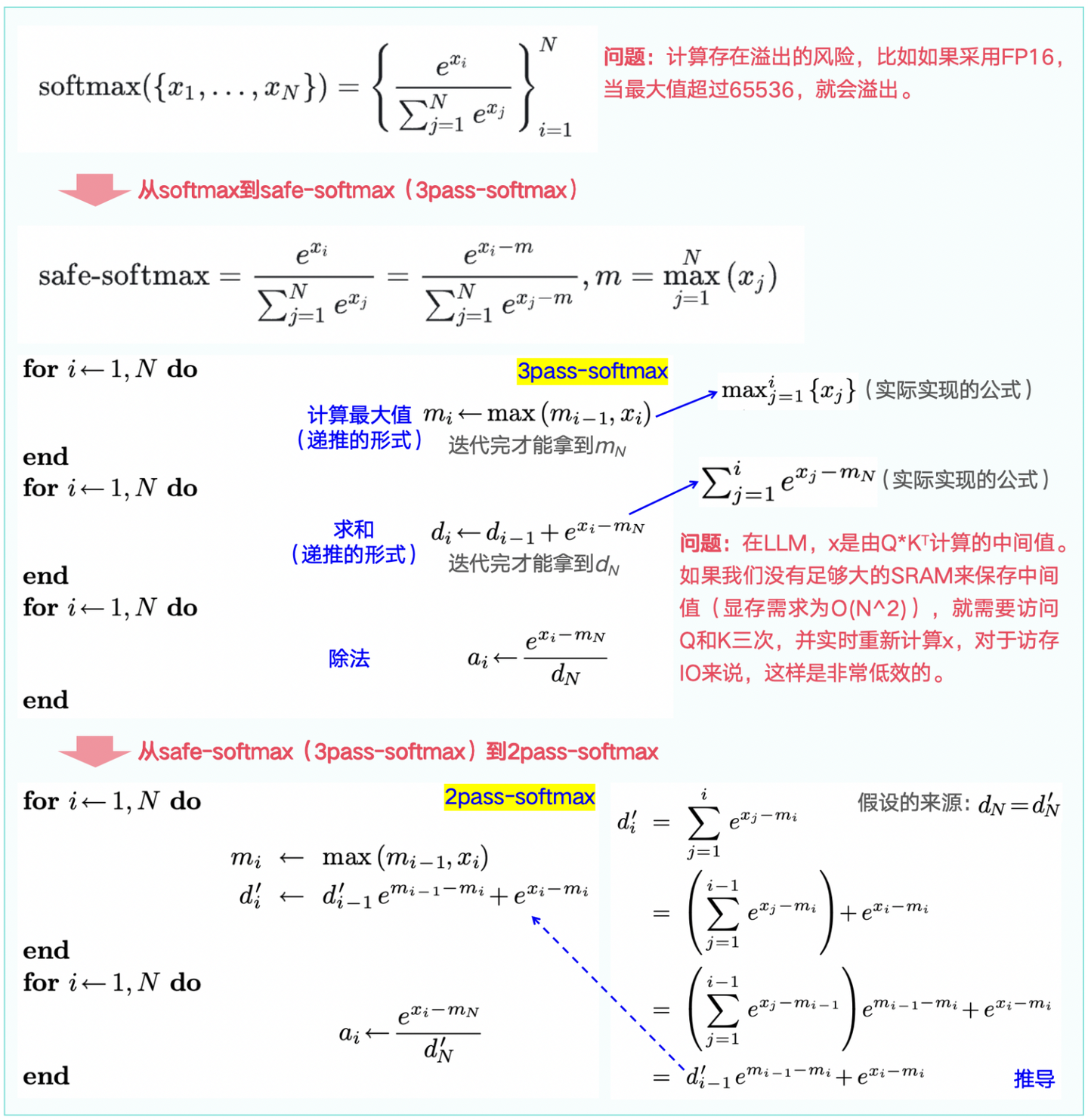
前提1:在LLM常规的Attention计算中,softmax必不可少,但一般的计算存在数值溢出的风险。比如假设采用FP16,当最大值超过65536,就会溢出,因此计算时通常采用safe-softmax的做法(公式见图1-2顶部)。
前提2:通过文章假如给我一只AI:LLM分布式训练方法汇总-图解,可以看到GPU中,SRAM的计算速度惊人,但空间很小。因此,在计算时,可以将位于HBM的矩阵拆分并逐块Load(载入)到SRAM中,将计算结果再Write(写入)回HBM。然而,如果只有一部分矩阵,会导致safe-softmax无法计算,如下图1-1。
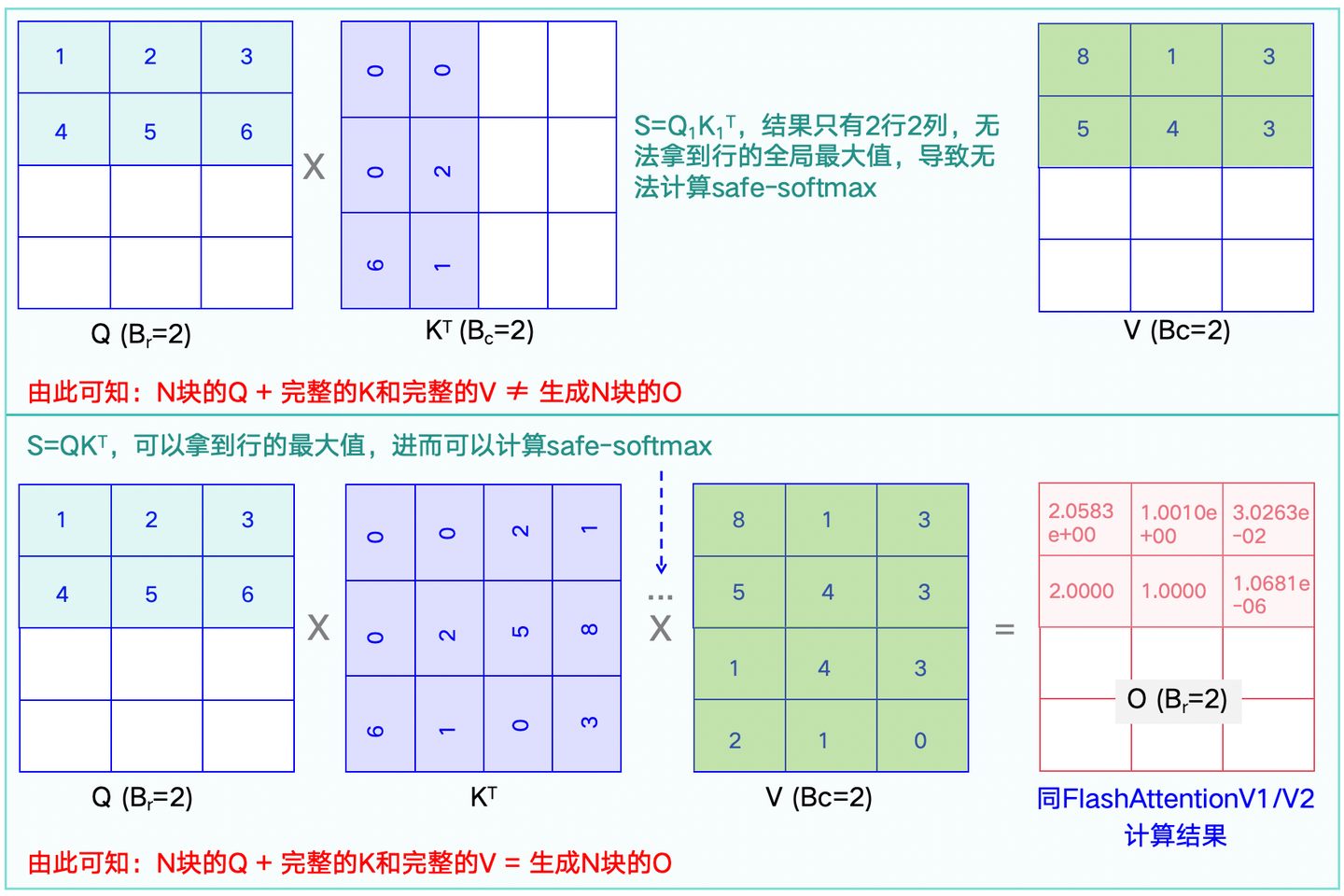
前提3:在safe-softmax计算过程中,通常需要三步计算:最大值、求和、除法。然而,三步过程产生的中间结果我们没有足够的SRAM来保存,虽然可以通过将中间结果放到HBM中存储,但这会增加访存IO的次数,影响效率。
1.1 从safe-Softmax -> 3pass-Softmax -> 2pass-Softmax
1.2 从2pass-Softmax -> 2pass-Attention
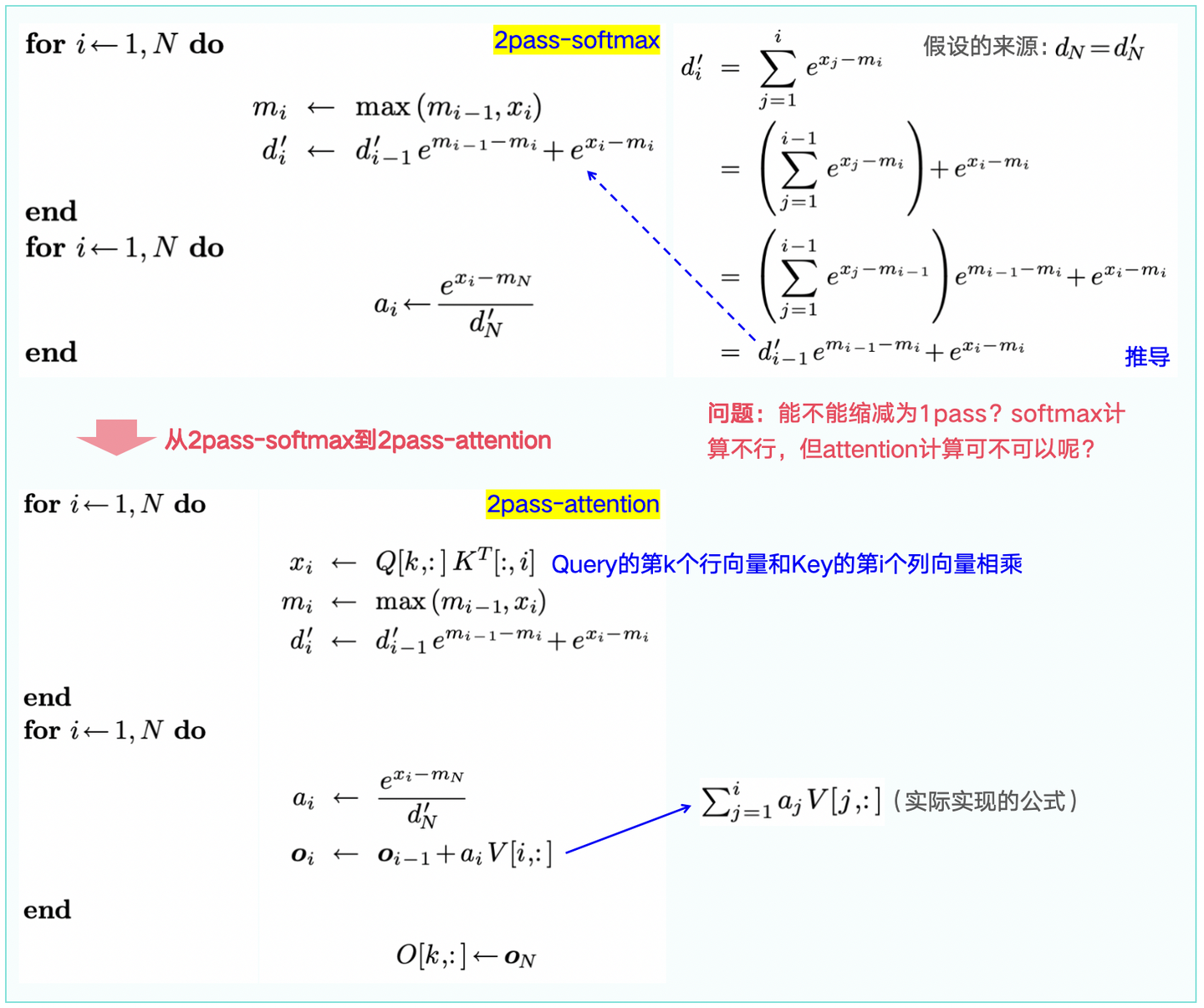
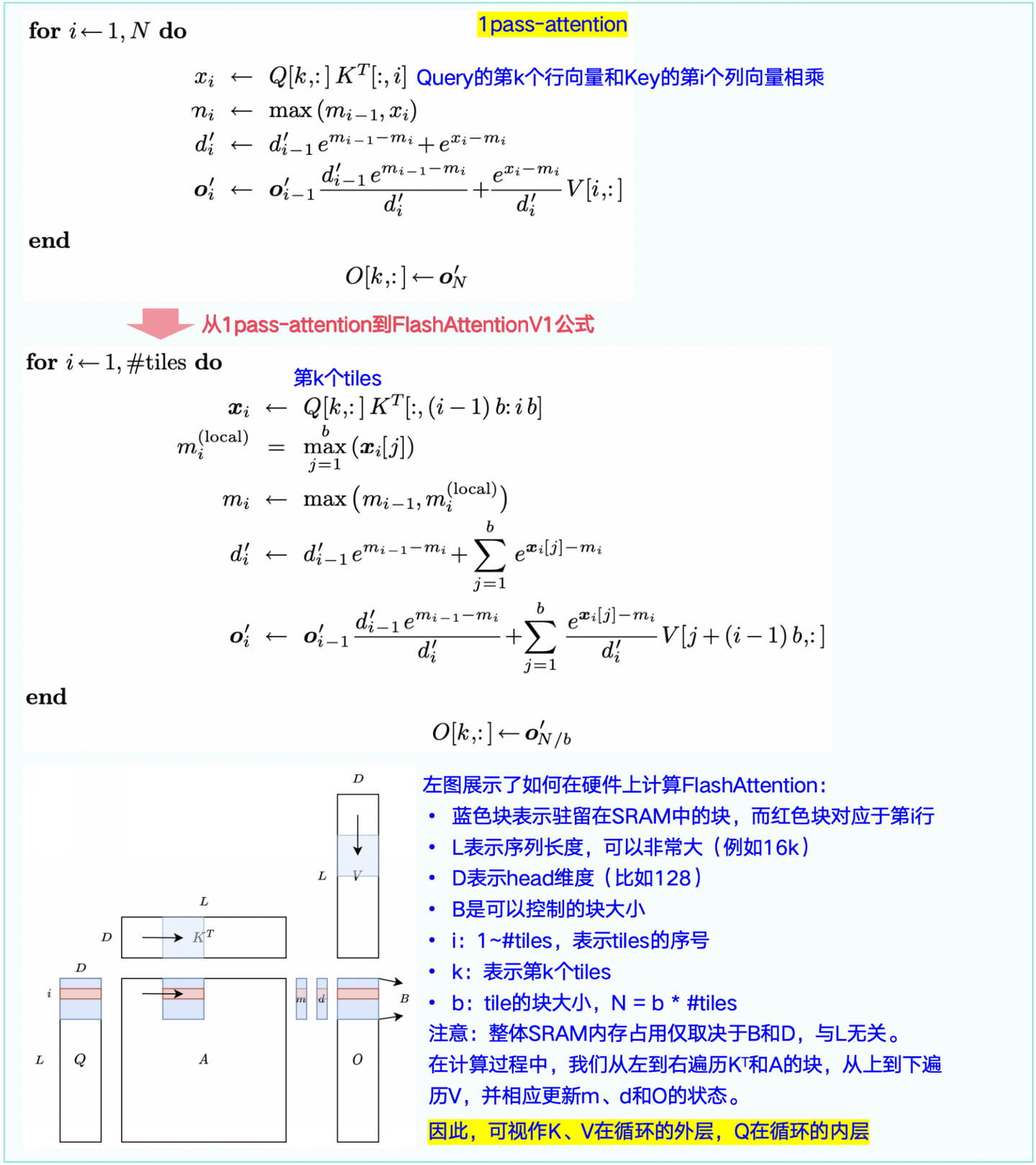
1.3 从2pass-Attention -> 1pass-Attention

1.4 从1pass-Attention -> FlashAttentionV1

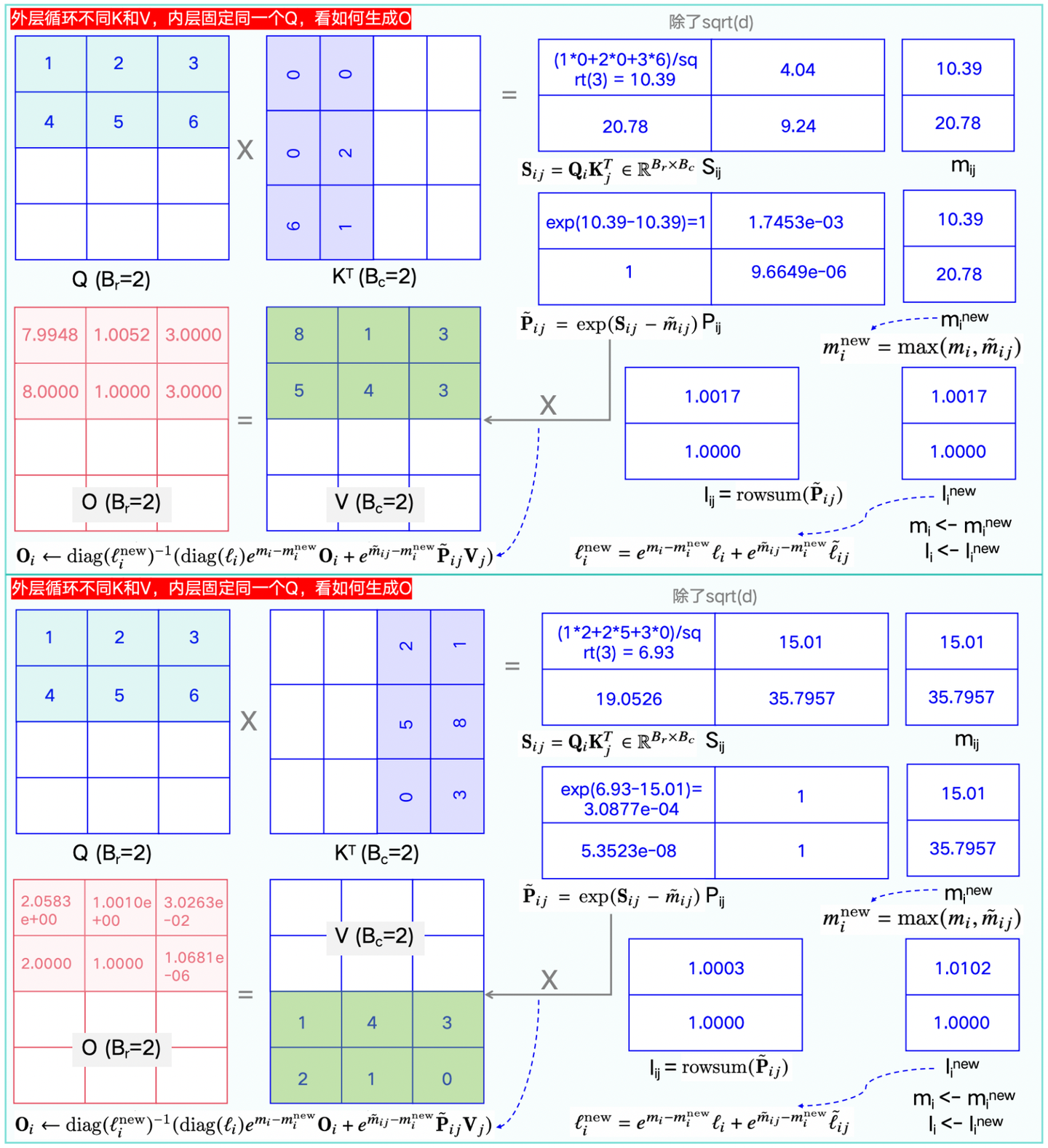
看完公式推导和官方算法,为了更好的理解,这里举一个实际的例子,见下图1-7。
注意:Q(蓝色)、K(紫色)、V(绿色)、O矩阵(粉红色),且例子只展示了半个block的Q如何生成对应的O矩阵,且O矩阵更新了2次:
1)在K、V前半block和Q计算时,更新了1次(第一步的值会参与第二步的计算);
2)在K、V后半block和Q计算时,更新了第2次。
FlashAttentionV1核心代码如下,其计算过程完全和图1-7一样。
"""
输入示例:
Q = torch.tensor([[[[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12]]]], dtype=torch.float32, requires_grad=True).to(device='cuda')
K = torch.tensor([[[[0, 0, 6],
[0, 2, 1],
[2, 5, 0],
[1, 8, 3]]]], dtype=torch.float32, requires_grad=True).to(device='cuda')
V = torch.tensor([[[[8, 1, 3],
[5, 4, 3],
[1, 4, 3],
[2, 1, 0]]]], dtype=torch.float32, requires_grad=True).to(device='cuda')
mask = torch.randint(1, 2, (1, 4)).to(device='cuda')
"""
def flash_attention_forward(Q, K, V, mask=None):
O = torch.zeros_like(Q, requires_grad=True)
l = torch.zeros(Q.shape[:-1])[...,None]
m = torch.ones(Q.shape[:-1])[...,None] * NEG_INF
O = O.to(device='cuda')
l = l.to(device='cuda')
m = m.to(device='cuda')
Q_BLOCK_SIZE = min(BLOCK_SIZE, Q.shape[-1])
KV_BLOCK_SIZE = BLOCK_SIZE
Q_BLOCKS = torch.split(Q, Q_BLOCK_SIZE, dim=2)
K_BLOCKS = torch.split(K, KV_BLOCK_SIZE, dim=2)
V_BLOCKS = torch.split(V, KV_BLOCK_SIZE, dim=2)
mask_BLOCKS = list(torch.split(mask, KV_BLOCK_SIZE, dim=1))
Tr = len(Q_BLOCKS)
Tc = len(K_BLOCKS)
# print("Tr: ", Tr)
# print("Tc: ", Tc)
O_BLOCKS = list(torch.split(O, Q_BLOCK_SIZE, dim=2))
l_BLOCKS = list(torch.split(l, Q_BLOCK_SIZE, dim=2))
m_BLOCKS = list(torch.split(m, Q_BLOCK_SIZE, dim=2))
# 外层K、V遍历,内层Q遍历
for j in range(Tc):
Kj = K_BLOCKS[j]
Vj = V_BLOCKS[j]
# print("Kj: ", Kj)
# print("Vj: ", Vj)
maskj = mask_BLOCKS[j]
for i in range(Tr):
# print("****"*10)
Qi = Q_BLOCKS[i]
# print("Qi: ", Qi)
Oi = O_BLOCKS[i]
# print("Oi: ", Oi)
li = l_BLOCKS[i]
mi = m_BLOCKS[i]
scale = 1 / np.sqrt(Q.shape[-1])
Qi_scaled = Qi * scale
S_ij = torch.einsum('... i d, ... j d -> ... i j', Qi_scaled, Kj)
# print("S_ij: ", S_ij)
# Masking
maskj_temp = rearrange(maskj, 'b j -> b 1 1 j')
S_ij = torch.where(maskj_temp > 0, S_ij, NEG_INF)
m_block_ij, _ = torch.max(S_ij, dim=-1, keepdims=True)
# print("m_block_ij: ", m_block_ij)
P_ij = torch.exp(S_ij - m_block_ij)
# Masking
P_ij = torch.where(maskj_temp > 0, P_ij, 0.)
# print("P_ij: ", P_ij)
l_block_ij = torch.sum(P_ij, dim=-1, keepdims=True) + EPSILON
# print("l_block_ij: ", l_block_ij)
P_ij_Vj = torch.einsum('... i j, ... j d -> ... i d', P_ij, Vj)
mi_new = torch.maximum(m_block_ij, mi)
# print("mi_new: ", mi_new)
li_new = torch.exp(mi - mi_new) * li + torch.exp(m_block_ij - mi_new) * l_block_ij
# print("li_new: ", li_new)
O_BLOCKS[i] = (li/li_new) * torch.exp(mi - mi_new) * Oi + (torch.exp(m_block_ij - mi_new) / li_new) * P_ij_Vj
print("O_BLOCKS: ", O_BLOCKS)
l_BLOCKS[i] = li_new
m_BLOCKS[i] = mi_new
# print("l_BLOCKS: ", l_BLOCKS)
# print("m_BLOCKS: ", m_BLOCKS)
O = torch.cat(O_BLOCKS, dim=2)
l = torch.cat(l_BLOCKS, dim=2)
m = torch.cat(m_BLOCKS, dim=2)
return O, l, m
1.5 从FlashAttentionV1 -> FlashAttentionV2
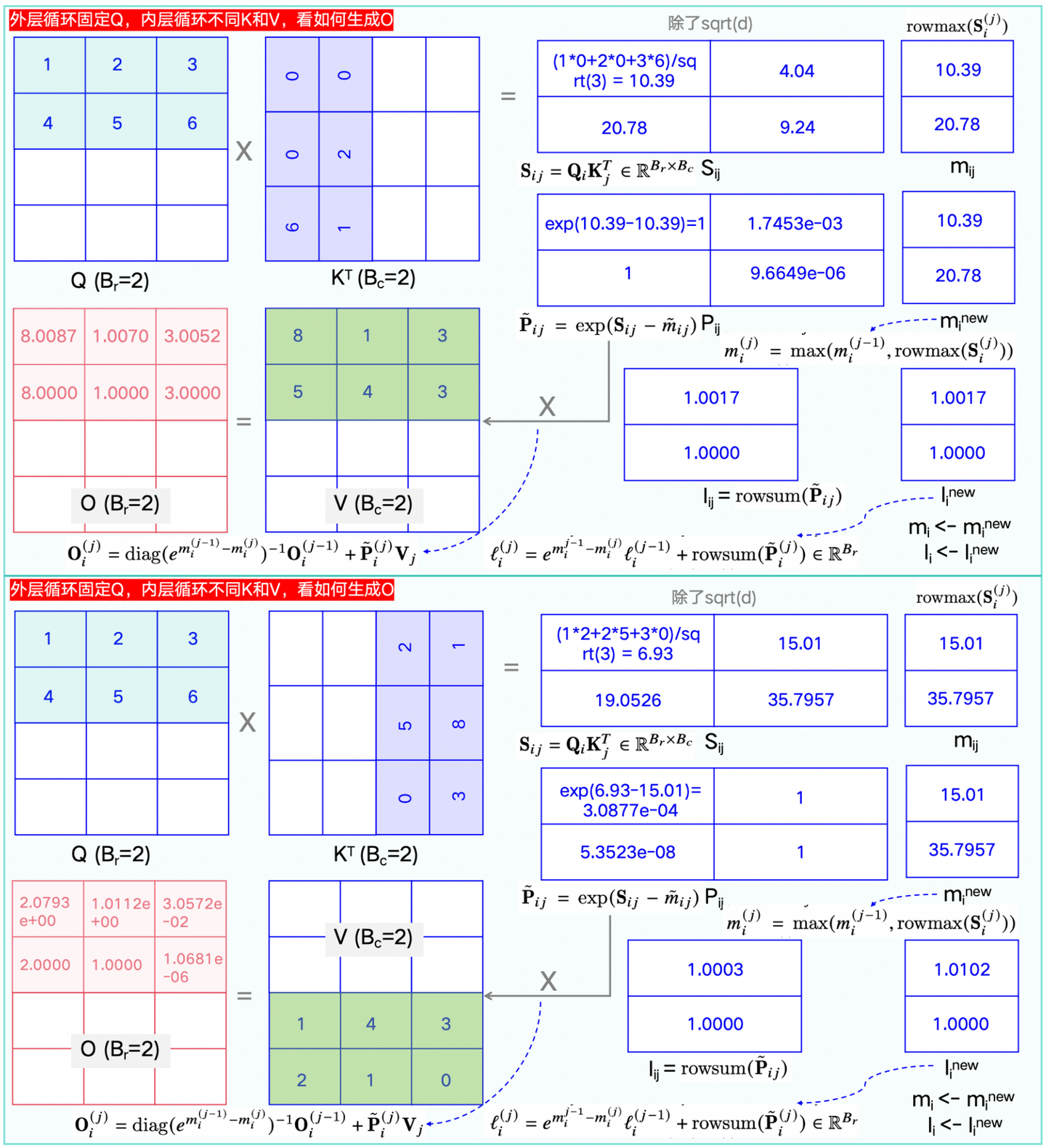
理解了V1,来看V2就容易很多,直接看下图1-8的对比即可。

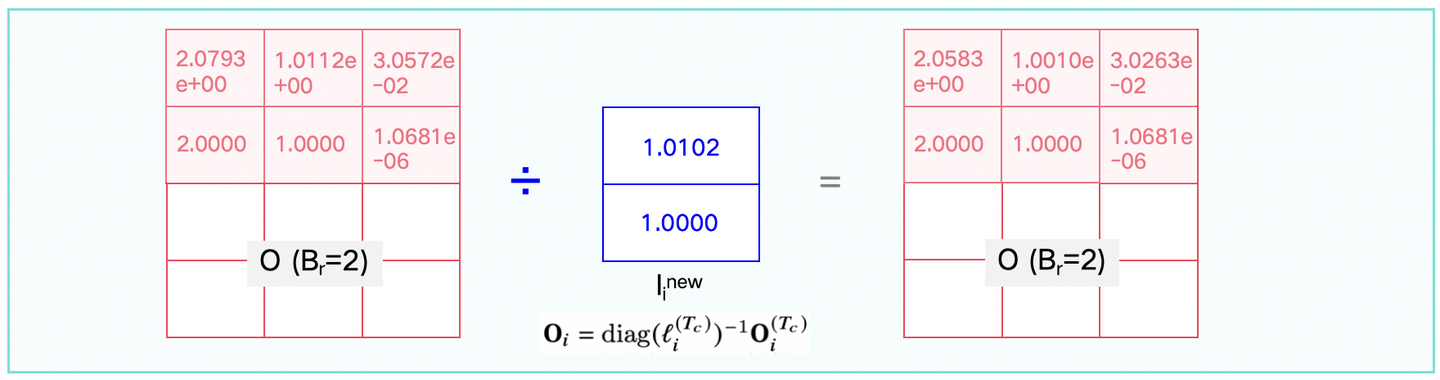
算法公式对比之后,可以看下图1-9(及其图1-9续图)给出的一个实际运行案例。
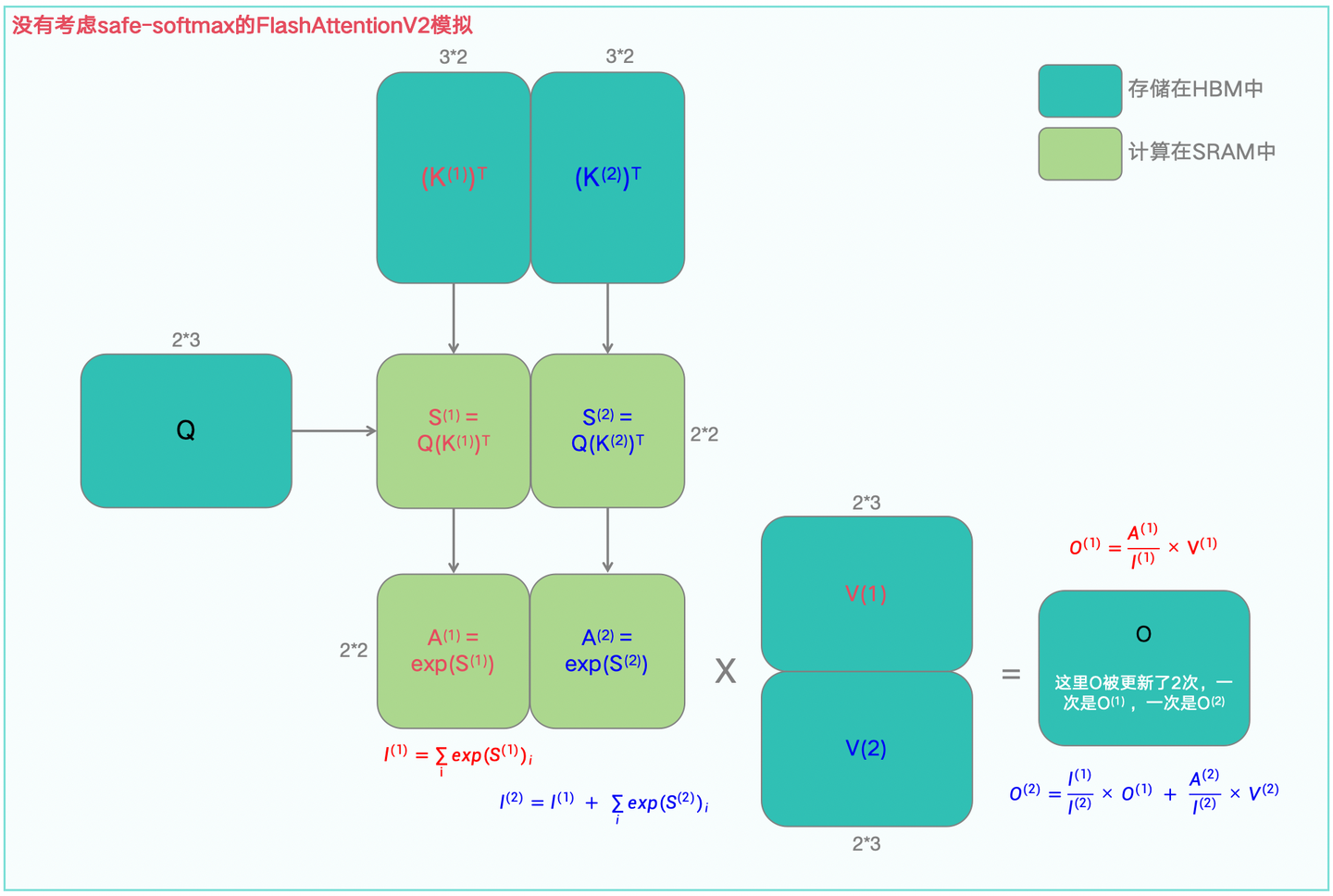
如果还是不好理解,可以看下面的图1-10,即去掉Safe-Softmax下FlashAttentionV2的前向传播示意图。
同样还是show code,在上述FlashAttentionV1核心代码的基础上(输入输出不变),修改了一版V2的代码,如下:
def flash_attentionv2_forward(Q, K, V, mask=None):
O = torch.zeros_like(Q, requires_grad=True)
l = torch.zeros(Q.shape[:-1])[...,None]
m = torch.ones(Q.shape[:-1])[...,None] * NEG_INF
O = O.to(device='cuda')
l = l.to(device='cuda')
m = m.to(device='cuda')
Q_BLOCK_SIZE = min(BLOCK_SIZE, Q.shape[-1])
KV_BLOCK_SIZE = BLOCK_SIZE
Q_BLOCKS = torch.split(Q, Q_BLOCK_SIZE, dim=2)
K_BLOCKS = torch.split(K, KV_BLOCK_SIZE, dim=2)
V_BLOCKS = torch.split(V, KV_BLOCK_SIZE, dim=2)
mask_BLOCKS = list(torch.split(mask, KV_BLOCK_SIZE, dim=1))
Tr = len(Q_BLOCKS)
Tc = len(K_BLOCKS)
# print("Tr: ", Tr)
# print("Tc: ", Tc)
O_BLOCKS = list(torch.split(O, Q_BLOCK_SIZE, dim=2))
l_BLOCKS = list(torch.split(l, Q_BLOCK_SIZE, dim=2))
m_BLOCKS = list(torch.split(m, Q_BLOCK_SIZE, dim=2))
for i in range(Tr):
Qij_1 = Q_BLOCKS[i]
oij_1 = O_BLOCKS[i]
lij_1 = l_BLOCKS[i]
mij_1 = m_BLOCKS[i]
for j in range(Tc):
# print("++++"*20)
Kj = K_BLOCKS[j]
Vj = V_BLOCKS[j]
# maskj = mask_BLOCKS[j]
scale = 1 / np.sqrt(Q.shape[-1])
Qi_scaled = Qij_1 * scale
S_ij = torch.einsum('... i d, ... j d -> ... i j', Qi_scaled, Kj)
# print("V2-S_ij: ", S_ij)
# print("V2-mij_1: ", mij_1)
max_values, _ = torch.max(S_ij, dim=-1, keepdim=True)
# Use torch.maximum with the max values
mij = torch.maximum(mij_1, max_values)
# print("V2-m_block_ij: ", mij)
P_ij = torch.exp(S_ij - mij)
# print("V2-P_ij: ", P_ij)
lij = torch.exp(mij_1 - mij) * lij_1 + torch.sum(P_ij, dim=-1, keepdims=True)
# print("V2-lij: ", lij)
print("torch.exp(mij_1 - mij): ", torch.exp(mij_1 - mij))
oij = torch.exp(mij_1 - mij) * oij_1 + torch.einsum('... i j, ... j d -> ... i d', P_ij, Vj)
# print("V2-oij: ", oij)
mij_1 = mij
lij_1 = lij
oij_1 = oij
m_BLOCKS[i] = mij_1
O_BLOCKS[i] = oij_1
l_BLOCKS[i] = lij_1
# print("V2-m_BLOCKS: ", m_BLOCKS)
# print("V2-O_BLOCKS: ", O_BLOCKS)
# print("V2-l_BLOCKS: ", l_BLOCKS)
# print("error-lij_1: ", lij_1)
tmp = O_BLOCKS[i] / lij_1
O_BLOCKS[i] = tmp
print(f"{i}-O_BLOCKS[i]: {O_BLOCKS[i]}")
O = torch.cat(O_BLOCKS, dim=2)
l = torch.cat(l_BLOCKS, dim=2)
m = torch.cat(m_BLOCKS, dim=2)
return O, l, m
二、PageAttention
2.1 PageAttentionV1
PageAttention(分页注意力)算法可以通过一个示例直观的观察其做法,如下图1-11所示:

从图11可知,PagedAttention 通过其Block Table自然地实现了内存共享。类似于进程共享物理页,该算法中不同的序列可以通过将其逻辑块(logical block)映射到同一物理块(physical block)来共享这些块。
Q:为什么说共享了?
A:在操作系统中,进程有虚拟地址空间,通过Page Table(页表)映射到物理内存页。多个进程可以共享同一个物理页,比如共享库或公共数据。类似地,PagedAttention使用Block Table来管理注意力计算中的内存块。每个请求(或序列)有自己的Block Table,记录哪些逻辑块映射到物理块。如果两个请求需要访问相同的数据,它们的Block Table可以指向同一个物理块,这样内存就被共享了。
Q:那这里的Block Table具体是怎么工作的呢?
A:假设在注意力计算中,键和值被分成固定大小的块。当处理新的请求时,系统会查看是否已经有相同的块存在。如果有,就直接引用现有的块,而不是创建新的。这类似于多个进程的页表项指向同一个物理页,从而节省内存。
Q:怎么理解连续逻辑地址和非连续物理地址?
A:连续的逻辑地址空间:从程序的角度来看,逻辑地址空间是一个线性、连续的空间,程序员在编写代码时无需关心底层物理内存的布局;非连续的物理地址空间:操作系统通过页表将逻辑地址映射到物理地址,由于页表可以将任意的虚拟页映射到任意的物理页帧,因此物理内存的分配可以是非连续的。这种灵活的映射机制允许操作系统更高效地利用物理内存,支持内存保护和进程隔离(每个进程拥有独立的页表,其虚拟地址到物理地址的映射彼此不可见,即进程无法通过虚拟地址直接访问其他进程或内核的内存)。
此外,为了确保安全共享,PagedAttention 会记录物理块的引用计数并实现Copy-to-Wite机制,如下图1-12所示。
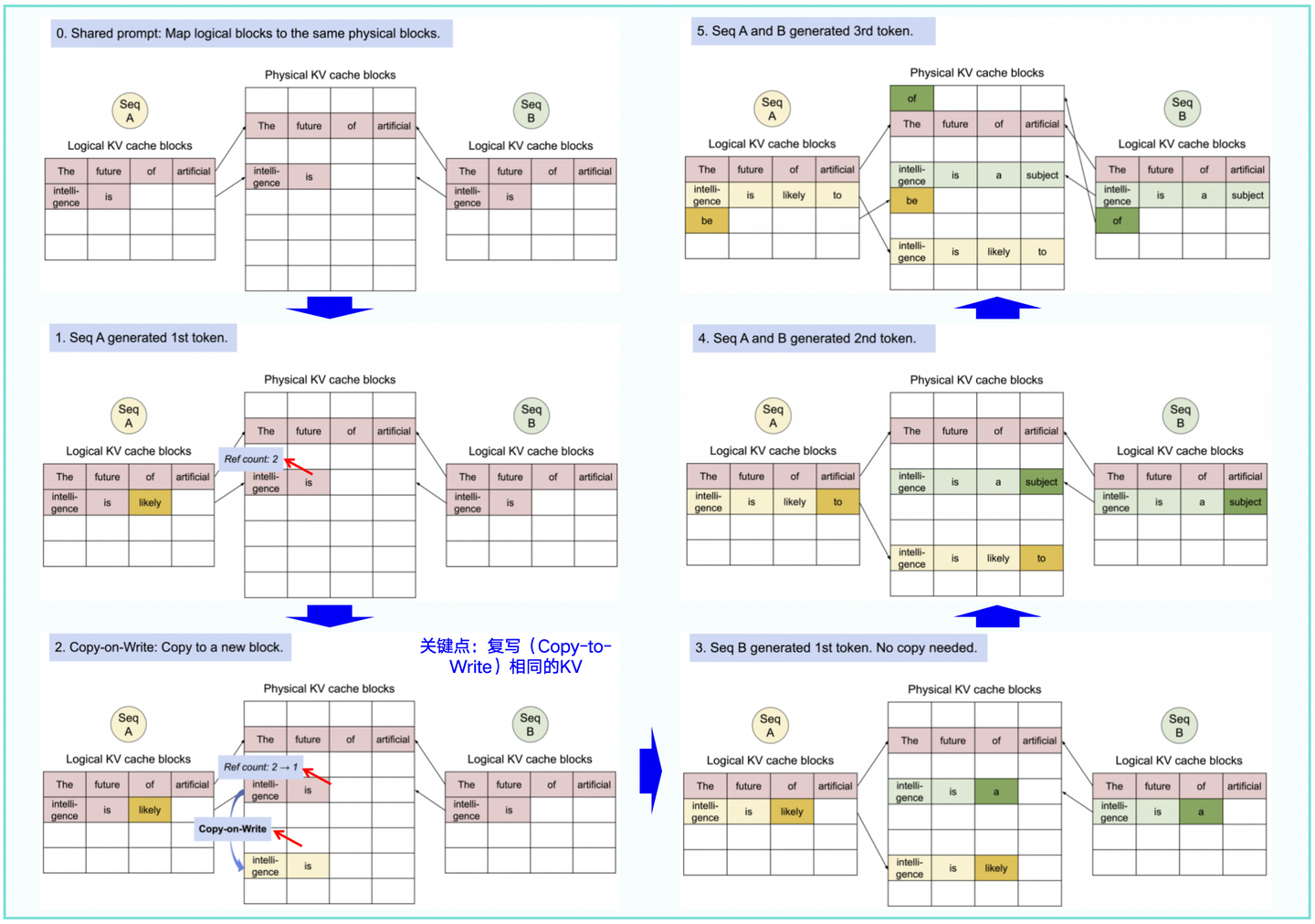
代码参考:PageAttention代码走读(采用cuda编程)
2.2 PageAttentionV2
有关V2网上资料较少,参考文章的说法:
相比于V1,在sequence序列维也做了并行处理,一个block处理一个序列的分块。所以这里也涉及到reduce_kernel的修改。
对应reduce_kernel的修改解释见另一篇文章。因此,在长序列中,通常才会考虑V2。
三、RadixAttention
RadixAttention始于2024年,是大模型推理加速架构SGLang的优化点之一。它的思想是在运行时自动地重用KV cache(这与现有系统在生成完成后丢弃KV缓存不同),其基本方案如下:
- 将Prompt(提示词)和completion(生成结果)的缓存保留在Radix树中,从而实现高效的前缀搜索、重用、插入和驱逐;
- 设计了LRU(最近最少使用)驱逐策略和缓存感知调度策略,以提高缓存命中率;
- RadixAttention可以兼容"Continuous Batching(连续批处理)、PageAttention、TP(张量并行)"等技术。
3.1 Radix Tree(基数树)
这里需要首先了解Radix树(基数树):它是一种用于高效字符串存储和查找的数据结构。它的核心思想是合并前缀。在Radix Tree中,每个节点存储的不再是一个字符,而是字符串的前缀,当插入/删除节点时,会通过合并/分裂前缀的方式,来尽可能的压缩树的高度,操作案例如下图2-1所示。
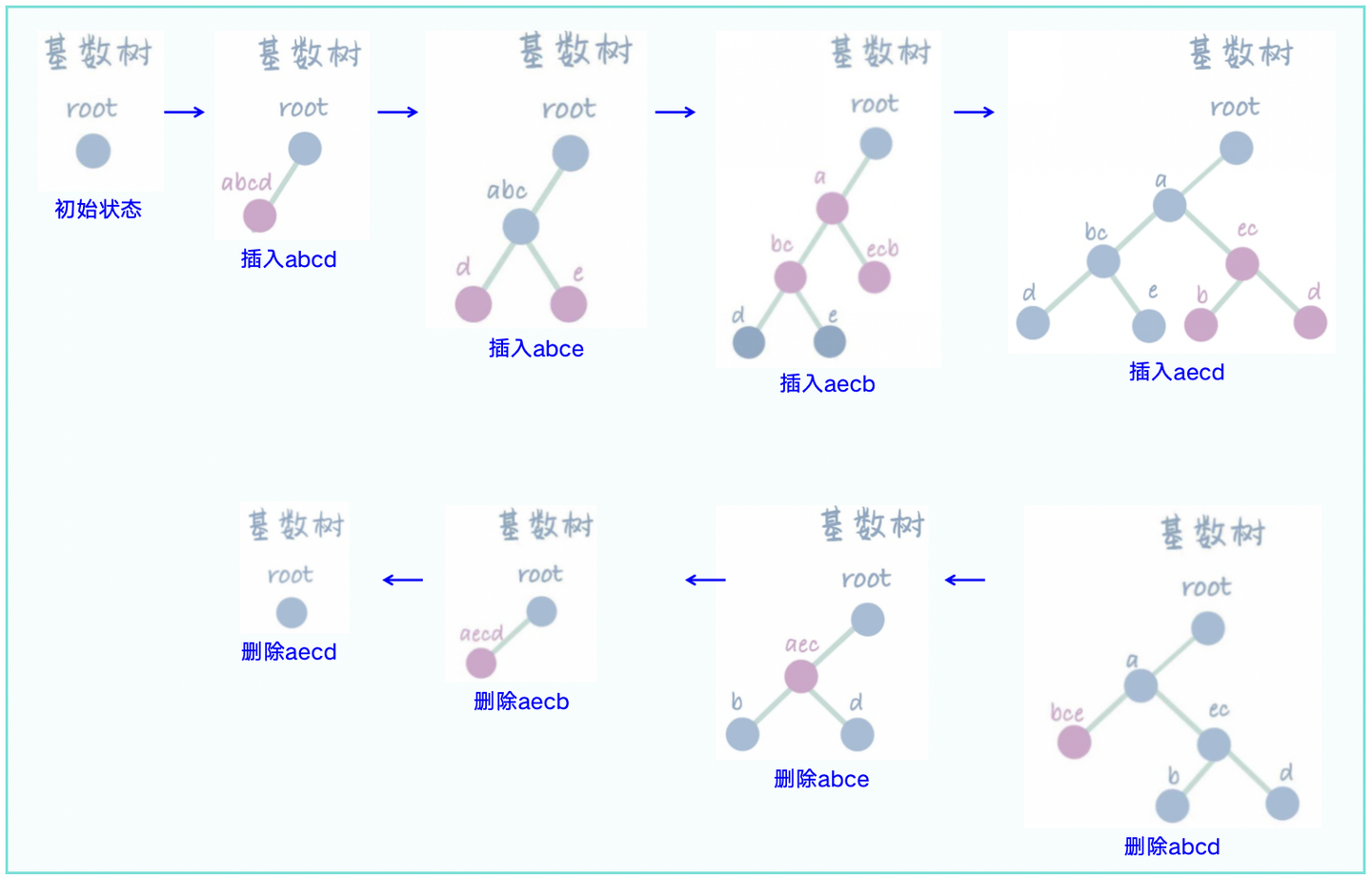
3.2 RadixAttention
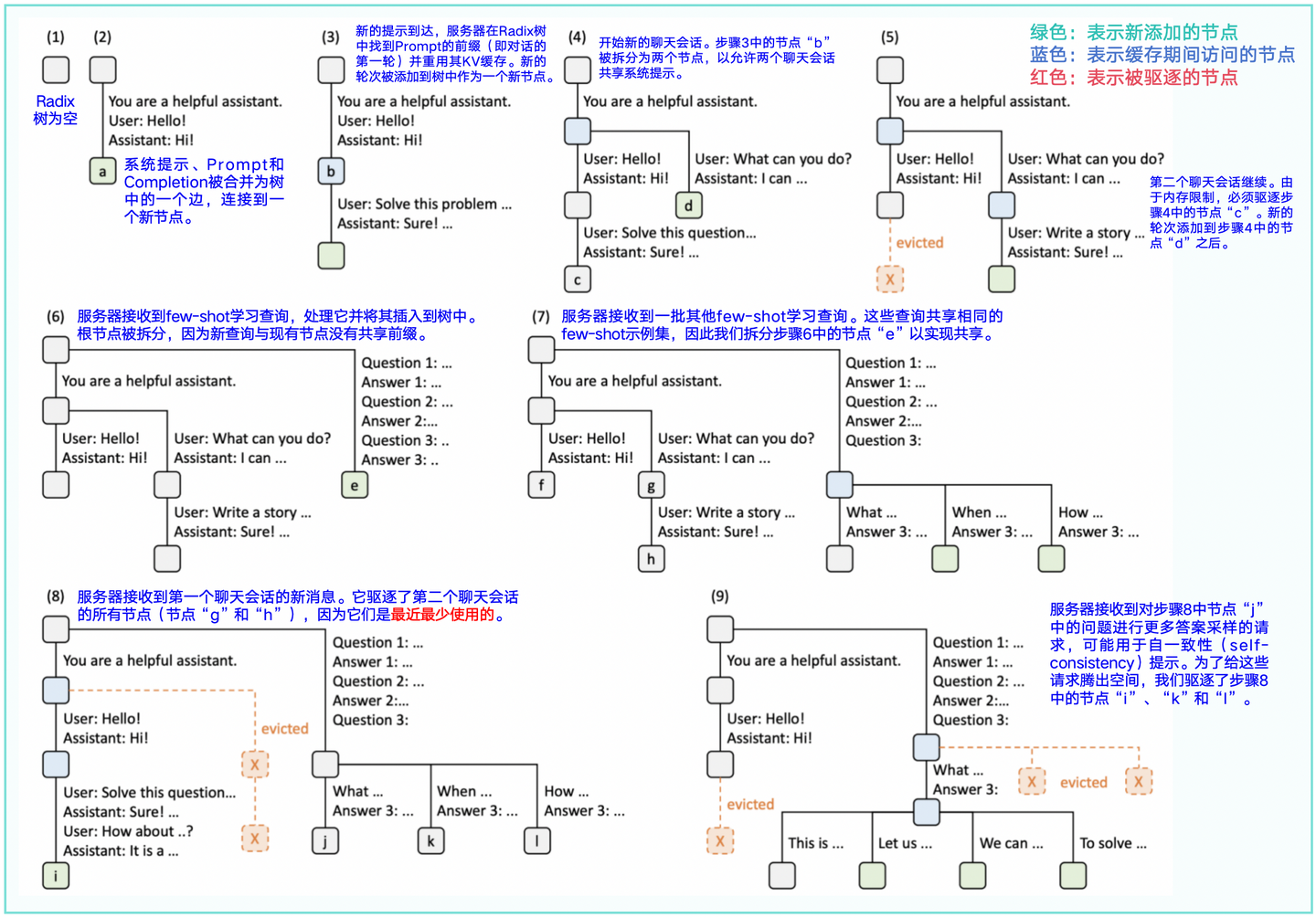
接下来直观理解RadixAttention,基于LRU淘汰策略的操作示例见图2-2。
四、参考文献
1.https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
2.DefTruth:[Attention优化][2w字] 原理篇: 从Online-Softmax到FlashAttention V1/V2/V3
https://zhuanlan.zhihu.com/p/668888063
3.FlashAtentionV1:http://arxiv.org/pdf/2205.14135
4.FlashAtentionV2:https://arxiv.org/pdf/2307.08691
5.PageAtention:vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
https://blog.vllm.ai/2023/06/20/vllm.html
6.RadixAttention:https://arxiv.org/pdf/2312.07104【SGLang论文】
7.Radix树原理介绍:https://blog.csdn.net/qq_354231