作者:gurubar
原文:https://zhuanlan.zhihu.com/p/1974055240048345546
为什么World Model 在Robotics领域中非常重要?
从理论与认知科学角度,Schmidhuber 等人长期主张“智能 = 学会一个可压缩、可预测的世界”;Ha & Schmidhuber 2018 的 World Models 实验证明:仅靠学习到的生成式世界模型,就能在“梦境”中训练策略并成功迁回真实环境,说明内在模拟器本身足以支撑决策。

在强化学习与控制领域,Hafner 的 Dreamer 系列(V1–V4)通过“在世界模型里做 RL”系统性地展示:在 Atari、连续控制乃至跨 150+ 复杂任务上,基于世界模型的 agent 同时取得更高样本效率和更强泛化,最新 Nature 2025工作已超过大量专门算法。

对真实机器人而言,DayDreamer等工作已经在机械臂和移动平台上实证:世界模型可以大幅减少真实交互次数,通过“在模型中想象未来”规避昂贵甚至危险的试错,这是任何要落地的机器人系统都绕不过的安全与成本约束。
新一代专为机器人设计的世界模型(如 ICLR 2025 的 HuWo、DREMA)将机器人–环境的物理接触、组合技能和“数字孪生”统一到一个可学习模型中,使同一世界表征可复用于行走、操作、模仿学习等多种能力。
从研究版图看,ICLR 2025 专门设立 “World Models: Understanding, Modelling and Scaling” 与 “Generative Models for Robot Learning” 等工作坊,聚焦 embodied AI、视频世界模型与机器人控制,表明“世界建模”已被视为通往通用机器人与 AGI 的主线之一,而非边缘话题。
同时,在更广泛的 AI 社区,LeCun、Fei-Fei Li 等一线学者及工业界不断强调 world model 是突破纯文本 LLM 局限的关键方向,媒体对 DeepMind Genie 等系统的报道也在强化一个共识:如果没有可靠世界模型,很难获得可信且可行动的智能。

综上,对于追求高样本效率、可解释性、安全性与通用性的机器人系统而言,系统性研究 world model 不再是“锦上添花”,而几乎等价于:这套机器人体系是否具备可扩展的智能潜力。
World Model × Robotics最新论文解读
World model 的核心想法,是让机器人先在“脑内模拟器”里预测未来观测与结果,再据此做决策或评估策略——即用一个可微的“环境”取代昂贵、难以建模的真实世界或传统仿真器。最近,这条线出现了几个显著变化:
- 从小模型到视频级生成器:基于 Conditional Diffusion Transformer / Flow Matching 的视频世界模型成为主流,可以在高分辨率视觉上做条件生成与规划,如 Navigation World Models (NWM)、Genie、Vid2World等。
- 从 task-specific 到 foundation-style:如 Unified World Models (UWM)、Humanoid World Models (HWM)、1X World Model,把“大量机器人数据 + 互联网视频”统一进一个 world model 平台,为多任务、多机器人提供基座。
- 更紧地和 RL / VLA 策略耦合:Robotic World Model、GPC、FLARE、RLVR-World等把 world model 看成 RL 的“动态模型 + rollout 引擎 + evaluator”,逐渐实现“训练策略前先炼一个世界”的范式。
已有两篇 最新的survey 对整体格局有系统梳理,非常值得作为背景阅读:
论文:A Comprehensive Survey on World Models for Embodied AI
链接:https://arxiv.org/pdf/2510.16732v1
以及聚焦操作任务的
论文:A Step Toward World Models: A Survey on Robotic Manipulation
链接:https://www.arxiv.org/pdf/2511.02097
下面按四个主题,把代表性论文和发展脉络串起来:
- 平台 / Foundation World Models for Robotics;
- Manipulation;
- Locomotion / Navigation;
- RL & Policy Adaptation。
文章选取举个最新代表性的文章,采样“一段话一个图”的简易解析方式,便于快速浏览或阅读。
平台:World-Model-as-a-Platform & Robot Foundation World Models
这一方向关注的是:能不能有一个通用世界模型当“仿真云”,机器人任务只是在上面做微调 / 规划 / 评估?
通用世界模型与机器人数据的融合
Genie / Genie Envisioner
https://arxiv.org/pdf/2508.05635
DeepMind 的 Genie 3 系列把大规模视频世界模型做成“环境引擎”;其上的 Genie Envisioner 更进一步,用 action-conditioned video generation 做机器人操作任务的世界模型,并展示了可作为统一基座支撑多种 manipulation 场景。
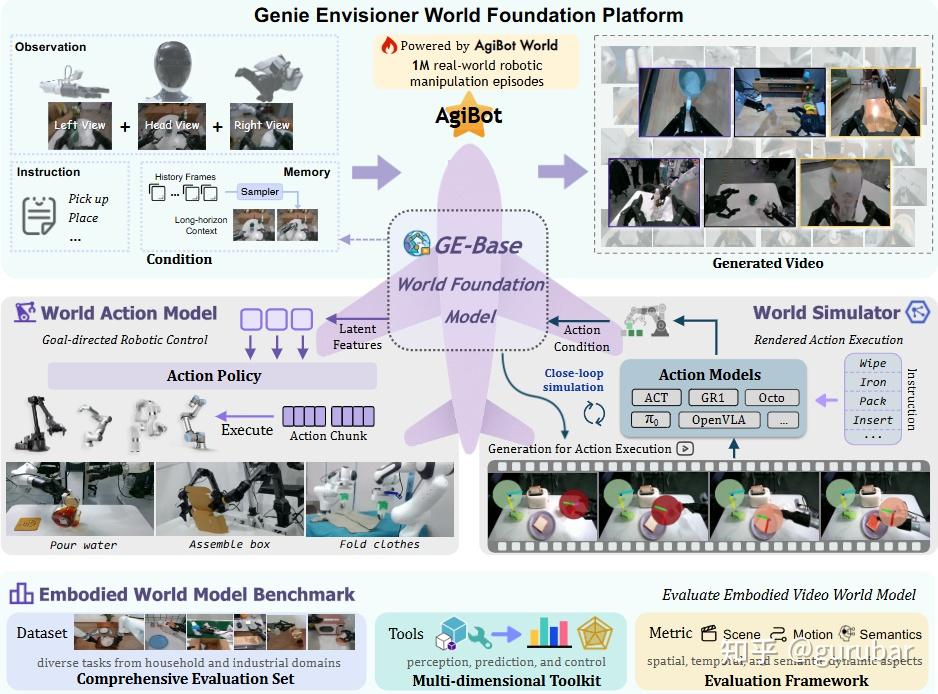
如上图所示,围绕 GE(Genie Envisioner )-Base 世界模型,搭了一个同时支持“想象世界(生成视频)+ 决策行动(控制机器人)+ 标准评测”的完整平台:输入 & GE-Base 世界模型: 多视角相机观察(左/头/右视角)+ 文字指令 + 历史记忆 → 作为条件输入。
这些数据来自 AgiBot World 的 100 万条真实机器人操作轨迹。中间的 GE-Base World Foundation Model 根据这些条件生成未来的视频(右上),相当于在“脑海里”想象接下来会发生什么。
两条主线——行动模型 & 世界模拟器: 从 GE-Base 提取的“latent features”生成具体的 Action Policy / Action Chunk,直接控制各种机器人执行任务(倒水、装箱、叠衣服等)。
World Simulator(右中): 用 GE-Base 预测出的世界状态,驱动一个视频级仿真器,渲染机器人执行动作的画面。 这里可以接入不同风格的已有动作模型(ACT、GR1、Octo、OpenVLA 等),形成闭环仿真和执行。
Embodied World Model Benchmark(基准评测): 提供一个包含多种家庭 / 工业操作任务的数据集。提供感知、预测、控制等工具,和场景 / 运动 / 语义多维度指标,用来系统评估各种 embodied world model 的效果。
Vid2World:从视频扩散到交互 world model
https://arxiv.org/pdf/2505.14357
Vid2World 提出一个通用框架,把预训练视频扩散模型“因果化 + 注入动作”,变成可自回归 rollout 的交互式 world model,在机器人操作、游戏、开放场景中统一测试。它解决了两个核心 gap:因果生成和动作对视频生成的精细控制。

如上图,Vid2World 先用海量“没有动作标注”的互联网视频训练视频扩散模型,再用少量跨域和同域的交互数据做适配,把这个模型变成一个可条件在动作上的世界模型,能用于机器人操作、游戏仿真和开放环境导航等多种交互任务。
Unified World Models (UWM)
https://arxiv.org/pdf/2504.02792
UWM把“视频扩散 + 动作扩散”统一在一个 transformer 里,通过分别控制两种 diffusion timestep 来实现:既能当 policy、forward/inverse dynamics,又能做 video generator,并且可以用有动作的机器人轨迹 + 无动作的互联网视频一起预训练,大幅提高下游策略泛化。
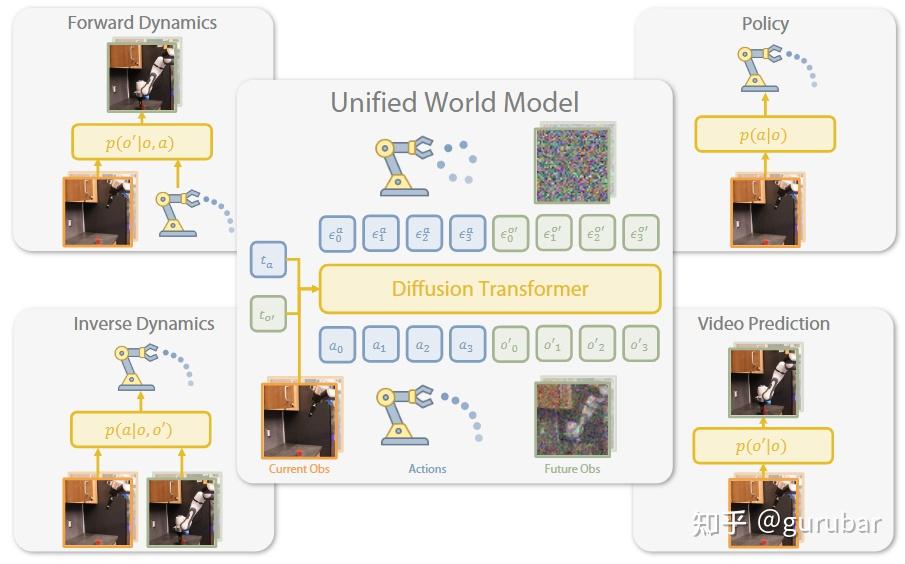
如上图,作者用一个“Diffusion Transformer 世界模型”,通过模态专属的 diffusion 时间步,把forward dynamics/inverse dynamics、策略学习、视频预测这四种任务统一起来 —— 训练一次,就能在测试时按需切换不同推理方式,从而让模仿学习更稳、更能泛化。
面向人形 / 通用机器人的世界基础模型
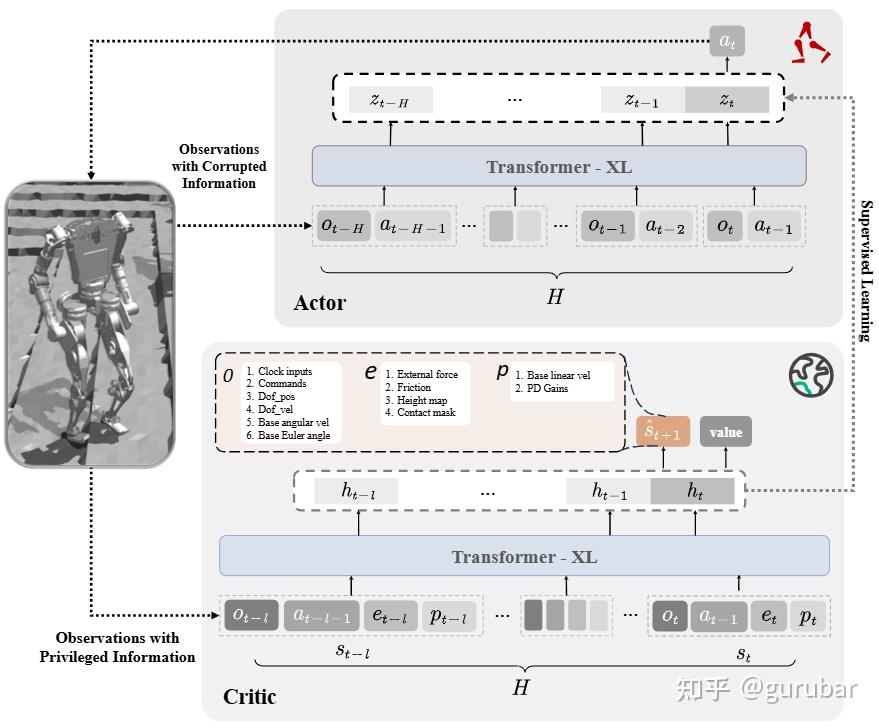
Humanoid World Models (HWM)
https://arxiv.org/pdf/2506.01182
HWM面向人形机器人,基于 100 小时人形视角的视频 + 控制 token,训练轻量级、开放源代码的动作条件视频世界模型,支持在 1–2 张 GPU 上训练与部署,强调“学界可承受的 world model 基座”。
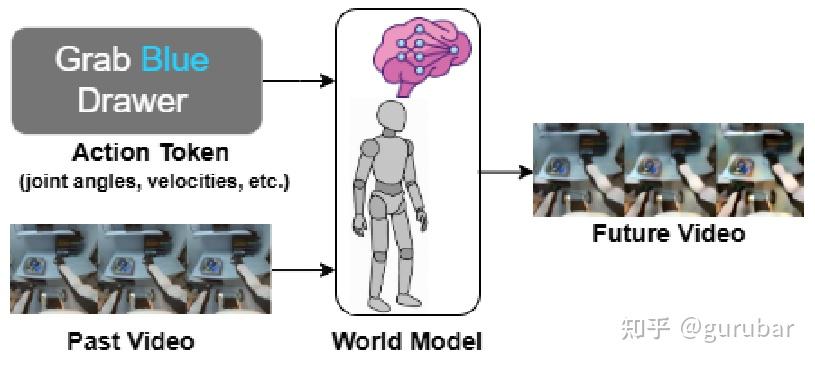
如上图,HWM 把“过去看到的东西”和“类人机器人的控制指令”一起编码,利用世界模型生成“未来会看到的视频”,从而在脑中为 humanoid 搭建一个可用于预测和规划的视觉世界。
1X World Model & 1X Challenge
https://opendrivelab.github.io/challenge2025/WM_Duke.pdf
1X 提出“Evaluating bits, not atoms”的口号,通过 world model challenge 推动对人形机器人世界模型的标准化评测。Duke 团队的技术报告展示了如何在 1X 数据集上做长时预测 + 有效状态压缩,探索 Diffusion Forcing Transformer 等架构(前端用动作条件的 3D 扩散 Transformer 做长时视频预测。
后端在 Cosmos token 空间用条件 CNN 做概率建模 来压缩视频状态,两者都充分利用“机器人姿态”作为条件信号,因此在 1X World Model Challenge 的“采样”和“压缩”两个赛道都拿到了第一)。
PAN:长时可交互模拟 world model
https://arxiv.org/pdf/2511.09057
PAN 作为一个通用途径,用统一的视频 world model 支持长时交互仿真,面向包括机器人在内的多种 embodied agents。
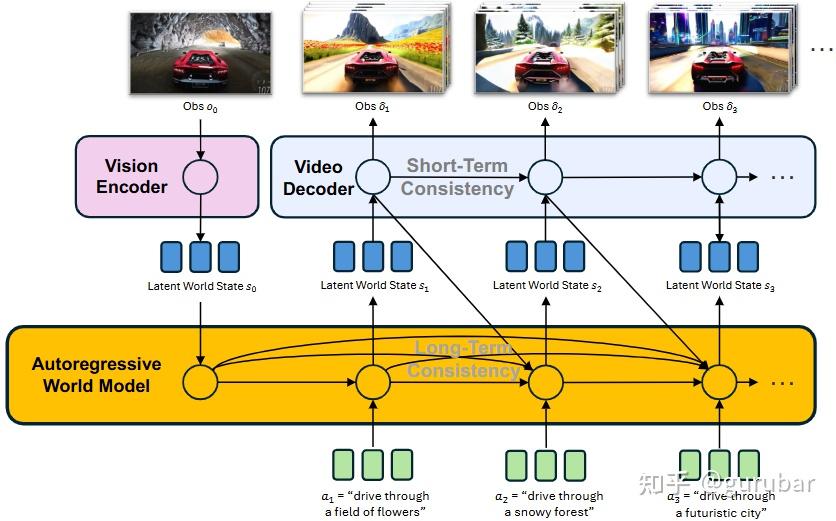
如上图,底层 world model:在抽象 latent 空间里,对“世界怎么随动作变化”做长期建模(负责剧情和物理逻辑,一致性是 long-term 的)。
上层 video decoder:把每个 latent 世界状态渲染成高保真视频,并保证相邻片段的短时平滑。动作是自然语言:a1, a2, a3 这样的文本指令,告诉模型接下来要发生什么(开到花田、雪地、未来城市),世界状态随之演化,相应的视频也跟着变化。
总而言之,PAN 用一个自回归 latent 世界模型 + 一个视频扩散解码器,把“长时间的世界逻辑”与“短时间的视频质量”分开建模,从而在自然语言动作驱动下,生成长时间、一致且可交互的世界视频。
Manipulation:
从像素世界到物体中心世界
在操作任务里,world model 往往要处理接触、遮挡、多物体交互,难度比导航大不少。最近的趋势大致有几类: 高保真视频 world model + policy / planner:Genie Envisioner、Ctrl-World、World4RL; 物体中心 / 高斯场景表示:GWM、FOCUS 等,把场景分解成对象或高斯元,便于长时预测和编辑;与 diffusion-based policy / VLA 的深度耦合:GPC、FLARE、DEMO³ 等,把 world model 变成“policy 的前瞻模块”。
高保真 generative world models
Genie Envisioner(参考如上论述)
https://arxiv.org/pdf/2508.05635
利用了 Genie 的视频世界模型能力,针对机器人操作数据做条件训练,实现“给定当前观测 + 动作序列 → 预测未来多步视频”,用于评估和改进 manipulation 策略。
Ctrl-World:A Controllable Generative World Model for Robot Policies
https://arxiv.org/pdf/2510.10125
使用 action-conditioned diffusion video 模型,对 robotic manipulation 的 action 做高精度控制,强调“可控性”和长期稳定预测,并在文中直接对比不同控制接口下的规划与策略性能。

如上图,图按列是时间 T=0,1,2,3,4 秒,按行是不同的世界模型变体:
- 第一(3行)行(Ctrl-World 完整版):每一秒给模型一个动作 chunk(用自然语言标出来,比如 “Z axis -6cm”, “X axis +6cm”, “Rotate 15°”,其实对应的是 7 维笛卡尔位姿增量)。 Wrist-view 预测画面里可以看到机械臂按指令在桌面上精细平移、上下移动、夹爪闭合,位置差异只有几厘米,预测轨迹和控制命令高度对齐。时间往后推到 4s,画面仍然清晰、物体位置一致,说明长时预测没有明显漂移。
- 第二行(w/o memory):去掉 pose-conditioned memory retrieval,只用最近上下文。同样的动作序列下,预测在 2–4s 逐渐变糊、姿态模糊,说明缺少记忆时,长期预测会发散,视觉质量和几何一致性变差。
- 第三行(w/o frame-level pose conditioning):仍然有记忆,但不做“逐帧” pose 条件,只在更粗层面给动作。可以看到:虽然大致方向对,但手的位置、夹爪状态经常对不上命令(比如该往 +X 走 6cm,画面里偏差很大),体现出控制精度显著下降。
World4RL
https://arxiv.org/pdf/2509.19080
World4RL 把 diffusion world model 看成 RL 的“dynamics + reward surrogate”,在 manipulation 与导航任务上展示了基于世界模型的 policy 优化与安全规划。

如上图,左边的 Diffusion Transition Model 学“动作之后画面怎么变”, Reward Classifier 学“看到什么算成功”,一起组成一个“虚拟环境”。右半部分:之后策略不再和真实机器人交互,而是把动作丢进世界模型,让模型“在脑内滚一条轨迹”、给出下一个画面和奖励。强化学习算法(比如 PPO)只在这个虚拟环境里反复尝试和更新策略,从而在不增加真实风险的前提下,提升 manipulation 任务中的性能与安全性。
物体中心与高斯世界模型
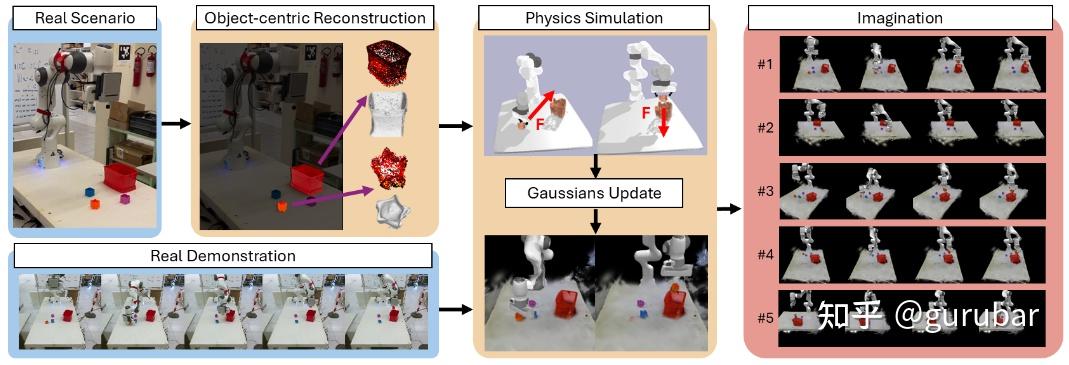
GWM:Towards Scalable Gaussian World Models for Robotic Manipulation
https://arxiv.org/pdf/2508.17600
使用 3D Gaussian splatting 风格的隐式场表示,把场景编码成可编辑的高斯云,world model 预测的是高斯参数随时间的演化,相比像素级预测更稳定,也更适合与 3D perception / grasping 模块协同。
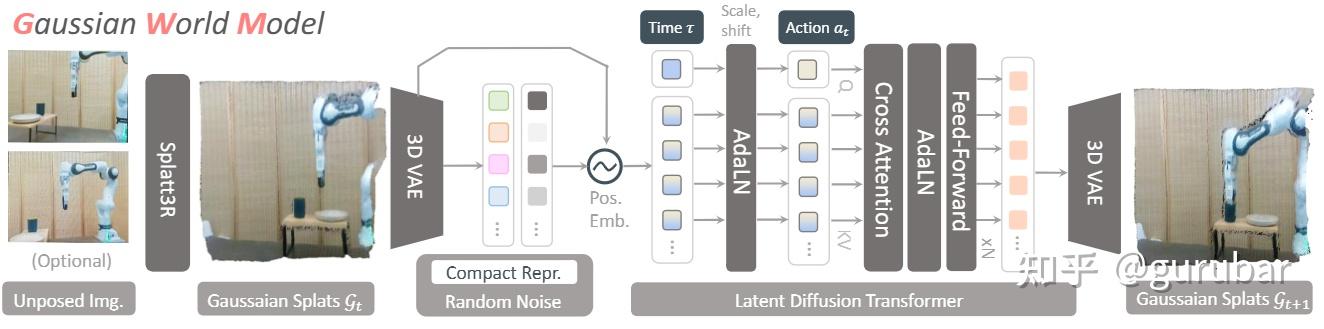
如上图,GWM 不再在像素上做 world model,而是先把场景变成 3D Gaussian 隐式场,再让 diffusion transformer 预测“高斯云随动作如何演化”,这样既避免像素级预测的抖动和模糊,又天然和 3D perception / grasping 说同一种“3D 几何语言”。
FOCUS: Object-Centric World Models for Robotic Manipulation
https://www.frontiersin.org/journals/neurorobotics/articles/10.3389/fnbot.2025.1585386/full
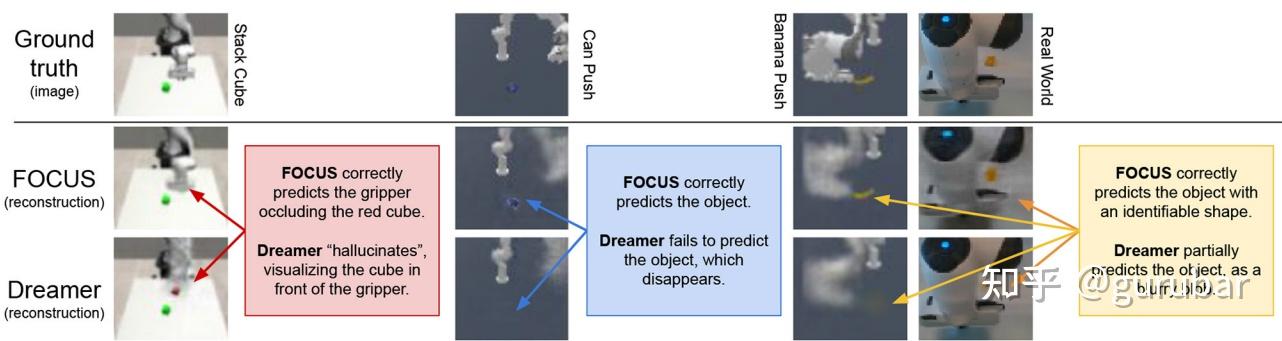
从视频中学习 object-centric slot 表示,world model 在对象级别做动力学预测,便于长时交互建模;在多物体堆叠、遮挡场景中表现优于纯像素模型。如下图,DreamerV2 往往把小物体、颜色接近背景的物体“糊成一团”,在堆叠、遮挡时容易丢失物体形状和位置,只剩下模糊的“云雾感”。
FOCUS 的重建则能清晰保留每个物体的轮廓、位置甚至部分纹理;即使物体很小、颜色不突出,或者被机械臂部分遮挡,也能被较好地“还原出来”。
FOCUS是先通过 object-centric 模块把视频分解成多个对象 slot,再让世界模型在这些对象 latent 上建模动力学;正因为在 对象级别 做表示与预测,模型不会把容量浪费在背景纹理,而是把注意力集中在可交互的物体上,所以在多物体堆叠、遮挡的 manipulation 场景中,重建明显优于纯像素模型 DreamerV2,也更适合作为后续 3D 感知、抓取和长时交互建模的基础。
iMoWM: Interactive Multi-Modal World Model for Robotic Manipulation
https://arxiv.org/pdf/2510.09036
支持多视角图像 + 力觉等多模态输入,把 manipulation 过程中接触信息也纳入 world model 中,提高对接触失败的预测能力。
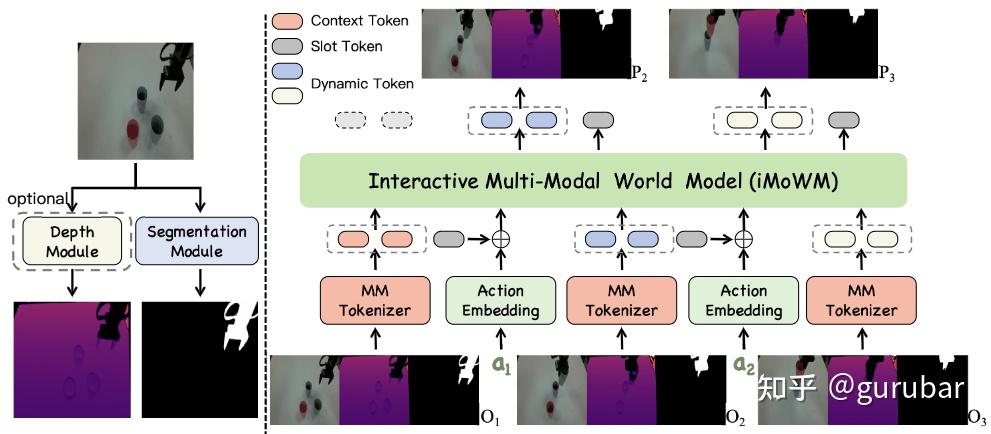
如上图,多模态观测:左侧输入的是彩色图像 + 深度图 + 机械臂 mask,组合成一个多模态观测。 深度图提供几何 / 距离信息,机械臂 mask 明确标出接触发生在哪些像素区域,相当于把“交互/接触区域”显式编码进观测里。
把多模态统一成 token:MMTokenizer 把 RGB、Depth、Mask 统一压成一串离散 token,既嵌入了几何结构,也保留了机械臂与物体接触区域的动态变化。这样 world model 看到的不是纯像素,而是“带几何与接触语义”的紧凑表示,更适合建模“什么时候会顶到了”“什么时候夹空了”这类失败模式。
右上方是 slot token + action conditioning:每个时间步在 token 序列中插入一个带动作信息的 [Sₜ],动作包括末端位姿、夹爪开合等。
自回归 Transformer 在这些多模态 token + action slot 上滚动预测未来 token,相当于在“几何+接触感知”的 latent 空间里做 dynamics 预测——世界模型不仅看画面,还显式对“机械臂怎么动、在哪儿接触”建模。
输出端:把预测的 token 解码回 未来的彩色图像 + 深度图 + 机械臂 mask。对 RL / imitation 来说,这就相当于一个“带几何与接触线索的模拟器”:一旦接触动作异常(比如深度突变、mask 相对目标物体位置不对),模型就更容易在预测中显现“失败征兆”。
与策略学习深度耦合
GPC:Strengthening Generative Robot Policies through Predictive World Modeling
https://arxiv.org/pdf/2502.00622
提出 Generative Predictive Control:先用 diffusion policy 拟合专家,再训练 world model,最后用 world model 对 policy 的多种 action chunk 进行“向前 roll-out + 打分”,做在线规划与优化,在推挤、折衣等任务上显著优于单纯 BC。
如下图,
- a) GPC-RANK 里,扩散策略在当前观测下同时生成多条候选 action chunk(多行“Multiple Action Proposals”)。世界模型对每条候选进行向前 rollout,预测未来的视频序列并给出对应奖励分数。控制器按奖励大小对候选排序,选出最高分的一条作为最终执行的 Single Action Proposal。
- b) GPC-OPT 里,先从扩散策略取一条 action chunk 作为 “warm start”。然后利用可微世界模型对这条序列做梯度上升优化:反复 roll-out、根据奖励梯度调整动作,使预测回报不断提升。最终得到一条经过优化的动作序列,用于在线替换原始 BC 输出,实现更强的规划能力。

FLARE:Robot Learning with Implicit World Modeling
https://arxiv.org/pdf/2505.15659
把世界建模做成 latent 对齐任务:policy 在预测动作的同时预测未来观测的 latent embedding,既不需要重建像素,又能让策略“看到未来”。在多任务模仿学习基准上取得 SoTA,并能利用无动作标签的 egocentric 视频进行联合训练。
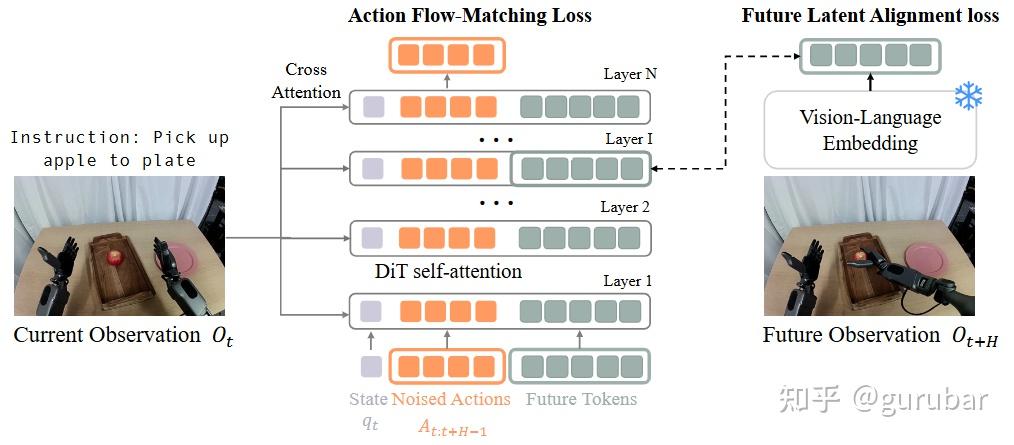
如上图,图左边显示当前观测经过 VLM 编成一个 vision-language embedding,同时把“加噪后的动作序列”和机器人状态也各自编码成 token,再加上若干 future tokens 一起送入 DiT。 DiT 一方面在整串 token 上做自注意力、通过 cross-attention 读取当前观测 embedding,用 action flow-matching loss 去拟合专家动作——也就是正常的扩散/flow policy 学习。
另一方面,在中间某一层把对应 future tokens 的隐状态 抽出来,用一个小 MLP 投影后去对齐“未来观测的 embedding”,用 future latent alignment loss(余弦相似度)来训练。这样,世界建模完全发生在 latent 对齐 上:policy 不生成未来像素,只要在内部学会“未来会长什么样的嵌入”,就等于在预测动作的同时“顺带看见未来”。
图中也强调这种设计只是在标准 VLA / DiT 上多塞了几类 token 和一个附加损失,因此可以在多任务模仿学习基准上稳定提性能,并且在没有动作标签的人类 egocentric 视频上,仍然可以只用对齐损失继续联合训练这一隐式 world model。
DEMO³:Multi-Stage Manipulation with Demonstration-Augmented Reward, Policy, and World Model Learning
https://arxiv.org/pdf/2503.01837
把 world model 作为 multi-stage manipulation 里的“中层模块”,同时学习 reward、policy 和 world model,支持复杂分阶段操作任务。
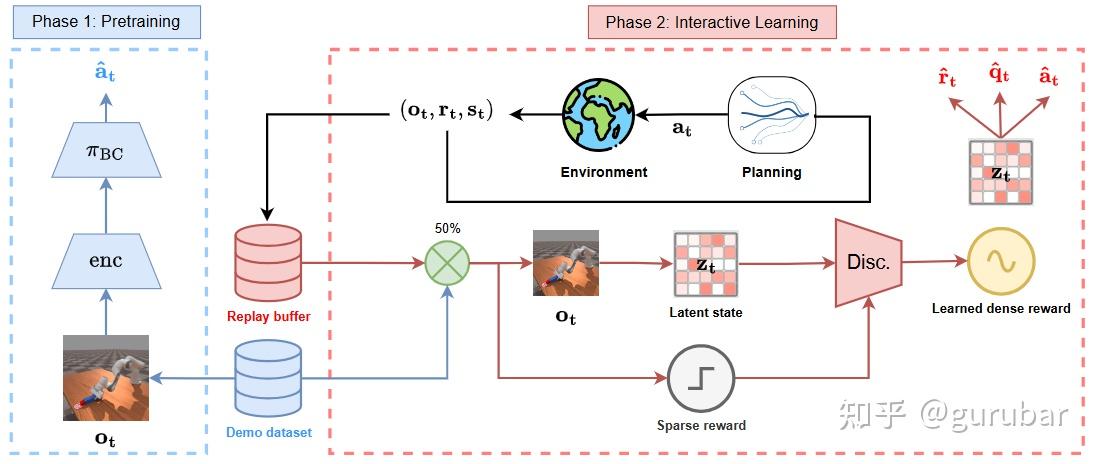
如上图,Phase 1:只用少量 demonstrations 做行为克隆,先训练一个视觉编码器和初始策略,相当于给后面的 world model 和规划打一个“中层”初始基础。Phase 2:环境交互产生的轨迹 + demos 一起进 replay buffer,encoder + dynamics 组成的 latent world model 在中间滚动,用来给 TD-MPC2 做规划(Planning 模块)。
同时,每个阶段有对应的 stage discriminator,在 latent state 上判断“能不能推进到下一阶段”,把原来的稀疏 stage reward 转成 learned dense reward,直接喂给 world model 和 planner。
整个图里可以看到:reward(判别器)、policy(TD-MPC2/BC)、world model(latent dynamics)是一起在线更新的,world model 作为连接视觉观测和多阶段规划的“中层模块”,支持复杂 multi-stage manipulation 的分阶段探索与决策。
Locomotion / Navigation:
从感知-预测融合到 Driving World Models
这一块 world model 的作用从“仅做视觉预测”逐渐扩展到: 为腿足 / humanoid 提供视觉前端 + 动力学先验;
作为 navigation planner,直接在像素或 latent 空间中搜索轨迹;在自动驾驶中统一生成 RGB+语义+深度+occupancy+reward 的综合世界。
视觉腿足 Locomotion:感知即 world model
World Model-based Perception for Visual Legged Locomotion (ICRA 2025)
https://arxiv.org/pdf/2409.16784
把 world model 当作感知模块的一部分,即预测未来的视觉观测与高度图,辅助 legged robot 在复杂地形(石块、楼梯等)上进行稳健行走。相比传统“静态高度图 + 局部规划”,world model 能在预见未来地形变化时提前调整步态。

如上图,这张图按列展示不同复杂地形(Gap、Climb、Tilt、Crawl),每个地形都有一行 Model(世界模型预测的深度图)和一行 Real(真实相机深度图)作对比。
世界模型只看到初始观测和后续动作序列,就能在“闭环”之外 向前滚动预测多步深度图,预测中的坑、台阶、低矮横梁等关键几何结构与真实观测在位置和姿态上高度对齐。尤其在 Crawl 场景里,虽然真实障碍物形状和仿真里不同,但模型预测出的“可钻过的狭缝”位置和角度与真实情况一致,说明它学到的是 可通行空间的未来几何。
从视角上看,深度图本质上就是在线估计的“局部高度/距离图”,世界模型对其进行 时间上的预测扩展,等价于在感知层就预见未来几步将要面对的台阶、空隙和障碍。
因此,这个图直观地体现了:world model 被嵌入到视觉感知管线中,负责预测未来视觉/高度信息,让腿足机器人在地形发生变化之前就调整步态,而不是像传统方法那样只依赖当前静态高度图 + 局部规划。
World Models as Reference Trajectories for Rapid Motor Adaptation (ICLR 2025)
https://arxiv.org/pdf/2505.15589
提出用 world model 生成“参考轨迹”,再用 RL / policy adaptation 快速调整到新地形或载荷,实验在 quadruped locomotion 上展示了能在 O(几次试错) 内适配奖励与动力学变化。如下图:
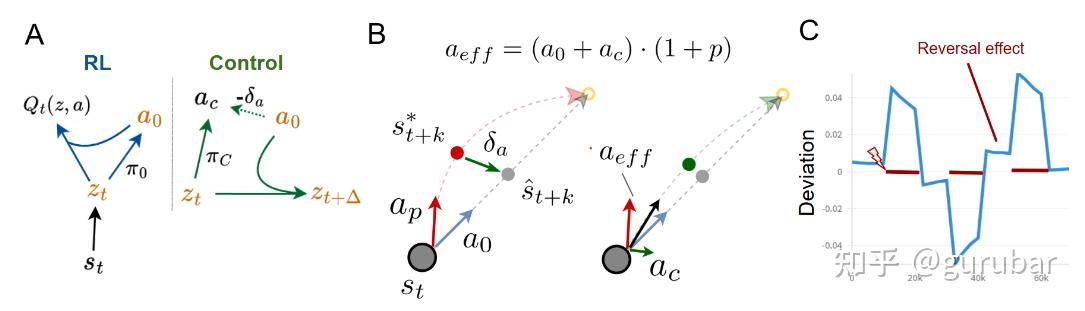
图 (a) 画出 RWM 的整体结构:RL 学到的 base policy 通过 world model F 预测出未来 latent 状态 z^t+1,这些预测轨迹被当成“参考轨迹”,自适应控制器 π_c 在此基础上对动作做快速修正。蓝色部分是慢时间尺度的 RL 策略(负责长期 reward 优化),绿色部分是快时间尺度的 adaptive controller(负责在参考轨迹周围纠偏),橙色是两者之间传递的 latent 状态和参考预测。
图(b) 的 2D 点质量示例里,黑线是真实轨迹,虚线是 world model 在 base policy 下预测的未来位置;当执行器被扰动时,轨迹偏离预测,控制器根据预测–观测误差立即产生校正动作,把真实轨迹拉回参考轨迹附近。
图(c) 展示了在交替方向扰动下,控制器仍能围绕参考轨迹稳定跟踪,并在扰动消失后出现典型的“后效”现象,说明系统确实在用世界模型生成的轨迹作为内在参考来做快速适应。
这套“world model 给参考轨迹 + RL/适应控制器做快速调整”的机制,就被直接套到 Walker/Humanoid 等 locomotion 任务上,实现对动力学变化在少量试错内的快速适配。
Navigation World Models & Latent Navigation
Navigation World Models (NWM, CVPR 2025 Oral, Best Paper HM)
ttps://openaccess.thecvf.com/content/CVPR2025/papers/Bar_Navigation_World_Models_CVPR_2025_paper.pdf
用 Conditional Diffusion Transformer 训练一个高容量的导航世界模型,从 egocentric 视频 + 动作预测未来视频,并用它来评估或直接搜索导航轨迹。相比传统 supervised policy,NWM 能在规划时动态引入约束(安全、舒适度等),并在未知环境中从单张图像“想象”可达路径。

如上图,图 (a) 说明 NWM 的训练:从机器人 / 人类采集的 egocentric 视频 + 导航动作 中,用 Conditional Diffusion Transformer 学一个高容量的视频世界模型,给定过去图像和动作预测未来图像。
图 (b) 展示在已知环境中,NWM 如何通过“模拟一条候选轨迹的视频 → 看是否接近目标”来评估或直接搜索导航轨迹,相当于把世界模型当作可微的“虚拟环境 +打分器”。
相比传统一次成型的 supervised policy,NWM 在规划时可以把“不能左转”“保持一定距离”等约束写进能量函数,在搜索动作序列时动态地满足这些安全 / 舒适度约束。
图 (c) 则展示了在 未知环境 中,只给一张起始图像,NWM 就能从这张图出发,结合假设的动作序列“想象”下一连串可达视角,用于在从未见过的场景中探索潜在可行路径。 用 Conditional Diffusion Transformer 训练一个导航世界模型,然后用它来“看见”未来、评估轨迹并在约束下做规划,还能在 OOD 场景里从单帧出发进行想象式导航。
LS-NWM: Latent-Space Autoregressive World Model for Efficient Image-Goal Navigation
https://arxiv.org/pdf/2511.11011
观察到对导航来说“高质量像素预测不必要”,提出只在 latent 空间做多步 autoregressive 预测,大幅降低训练和规划开销(planning 时间减少约 400×),同时在 SR / SPL 上优于像素级基线。
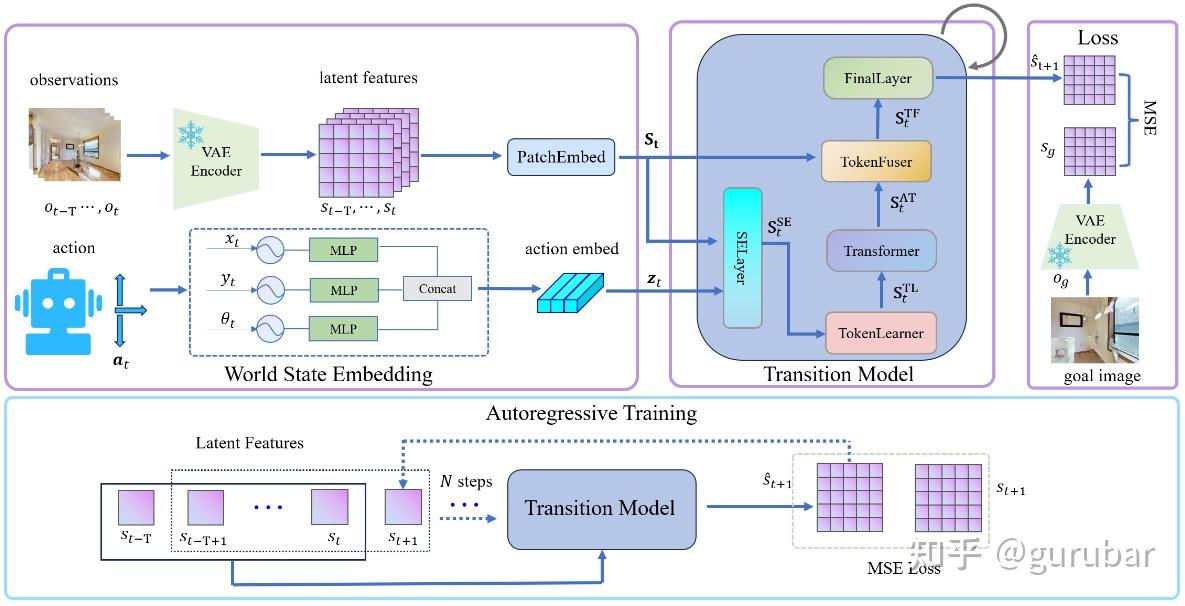
如上图,图左边“World State Embedding”把相机图像先送入 VAE 得到视觉 latent,再把动作编码成 action latent,然后拼成一个紧凑的世界状态表征 s_t , z_t,完全不再回到像素空间。 “Transition Model” 用 SE + TokenLearner/TokenFuser 等模块,把“历史 latent 图像 + 动作”融合后,直接预测下一步的 latent state s^t+1,整个预测过程都发生在 latent 空间。
箭头表示 多步 autoregressive 训练:模型的预测 latent 会被反复喂回作为下一步输入,连续滚动好几步,用统一的 MSE 监督长时序结构。因为既不重建视频,也不在像素上做规划,CEM 只需在这个低维 latent 上滚动和打分,大幅降低训练和规划开销(文中实测训练约快 3.2×、planning 时间约快 447×,同时在 SR / SPL 上优于像素级 NWM)。
整个体现了作者的核心主张:“导航不需要高质量像素预测,只要在 latent 空间做多步世界建模 + 规划,就能更省算力又更稳。”
Trajectory World Models (TWM, ICML 2025)
https://arxiv.org/pdf/2502.01366
面向“异质环境”,在轨迹空间学习 world model(预测未来轨迹分布),可以被视作对多种 locomotion / navigation 环境的一种统一建模方式。
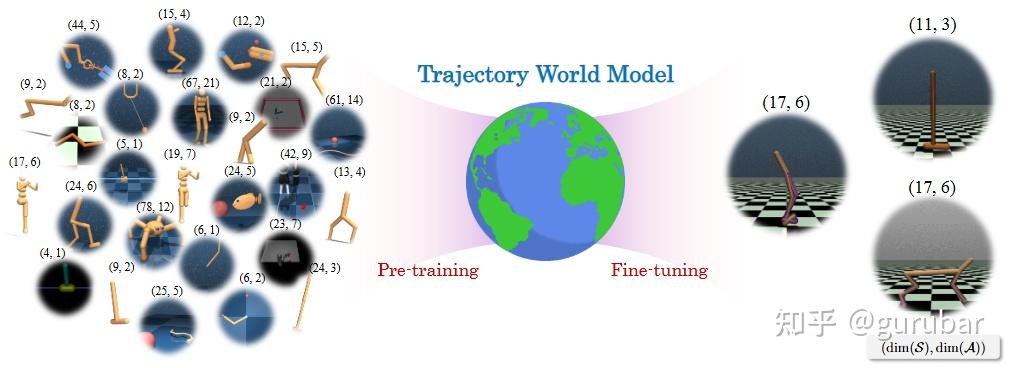
如上图,图中左右散布的是大量不同的环境,每个小方块旁边标着形如 (dim(S), dim(A)) 的数字,表示状态维度和动作维度都各不相同,体现“异质环境”。中间那块是统一的 Trajectory World Model,它不是为每个环境单独建模,而是把所有环境的轨迹一起用于预训练,相当于在“轨迹空间”里学习通用的动态分布。
“Pre-training” 阶段表示用 UniTraj 中来自各种 locomotion / navigation 等控制任务的大量轨迹,把共享的动力学规律学出来;“Fine-tuning” 则说明同一个模型可以再适配到某个新环境。因为不再依赖固定的状态/动作维度,而是在统一的轨迹表示上建模,这个 Trajectory World Model 就成了对多种异质环境的一种“统一世界模型”框架。
自动驾驶与全景导航世界模型
DriVerse: Navigation World Model for Driving Simulation via Multimodal Trajectory Prompting and Motion Alignment
https://arxiv.org/pdf/2504.18576
从单张图像 + 未来轨迹出发生成驾驶场景视频,通过“轨迹 token + 2D motion prior”强化控制能力,用 Motion Alignment 优化动态物体的一致性,用于评估自动驾驶算法。
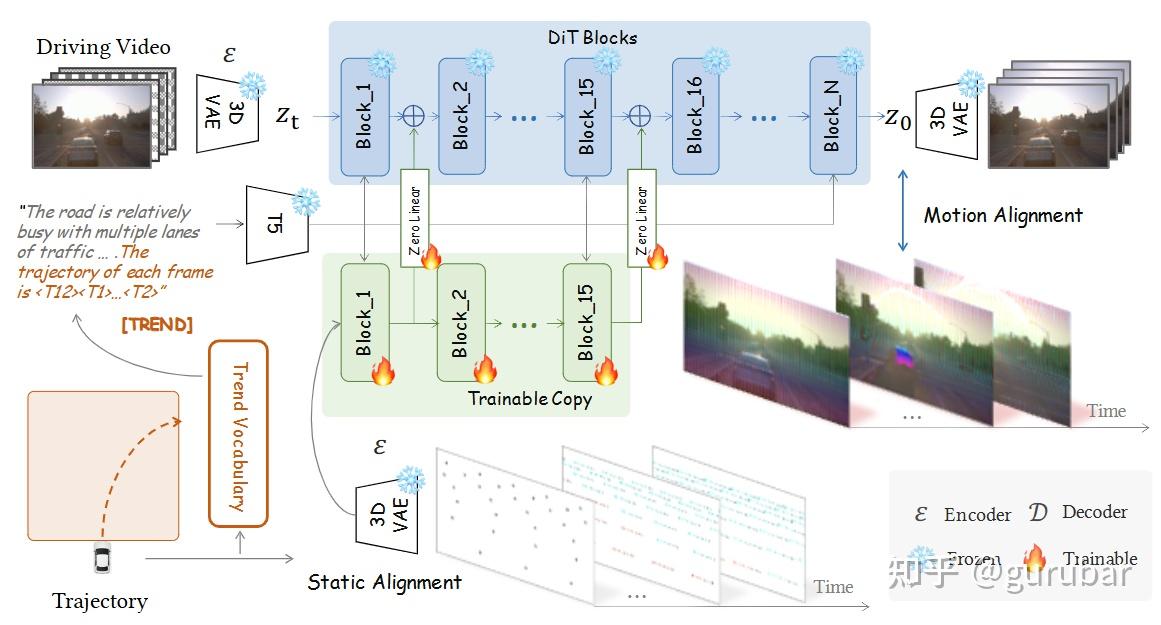
如上图,图左边展示:输入是一张场景图像和一条未来 3D 轨迹,图像先经过 3D VAE 编成视频 latent,轨迹一方面被离散成 trend vocabulary 写进文本 prompt(轨迹 token),另一方面通过 Trajectory-Guided Spatial Anchors 投影成随时间移动的 2D 点云,作为 spatial motion prior。
中间的 DiT Blocks 上方是冻结的主干,下方是“Trainable Copy+Zero Linear”,把这些 2D motion prior 注入到扩散 Transformer 中,实现“图像生成受轨迹强约束”的 静态对齐(Static Alignment/MTP)。
右侧的 Motion Alignment(LMA) 分支,用 3D VAE 把生成视频和真实视频都映射到 latent 空间,根据离线跟踪到的动态像素轨迹,对动态区域的 latent 做一致性约束,从而提升车辆和行人等动态物体的时序连贯性。整个图说明:DriVerse 从单张图像 + 未来轨迹出发生成驾驶视频,靠“轨迹 token + 2D motion prior”增强对导航轨迹的可控性,再用 Motion Alignment 保证动态物体行为合理,可作为评估自动驾驶算法的高保真导航世界模型。
OmniNWM: Omniscient Driving Navigation World Models
https://arxiv.org/pdf/2510.18313
把自动驾驶 world model 的 state–action–reward 三个维度统一起来:state 端同时生成全景 RGB、语义、metric depth 和 3D occupancy;action 端提出 panoramic Plücker ray-map 表示轨迹;reward 端直接从 occupancy 定义规则化稠密奖励,用于“在 world model 内闭环评估车辆行为”。

如上图,图 (a) “State” 部分展示:给定一张参考图像和车轨迹,OmniNWM 一次性生成全景 RGB、语义分割、metric depth 以及 3D 语义 occupancy 四种模态的视频,实现统一的多模态状态建模。
图 (b) “Action” 部分展示:不同输入轨迹先被编码为 normalized panoramic Plücker ray-map,以像素级“射线图”的形式注入扩散模型,从而精确控制全景相机轨迹与视角变化。
图(c) “Reward” 部分展示:规划轨迹驱动 world model 生成未来多模态场景,同时从生成的 3D occupancy 中直接计算碰撞、出界、速度等规则化稠密奖励,对每条轨迹进行打分。三个子图连在一起,直观地把自动驾驶 world model 的 state–action–reward 三个维度统一到同一个框架,并通过 occupancy-grounded dense reward 在 world model 内实现闭环导航评估与规划。
Learned Perceptive Forward Dynamics Model for Safe and Platform-Aware Robotic Navigation (RSS 2025)
https://arxiv.org/pdf/2504.19322
将“可学习 FDM(Forward Dynamics Model ) + 安全约束”结合,在实际机器人平台上做安全导航,属于 world-model-style 的前向动力学模型,与上面的视频世界模型形成互补。
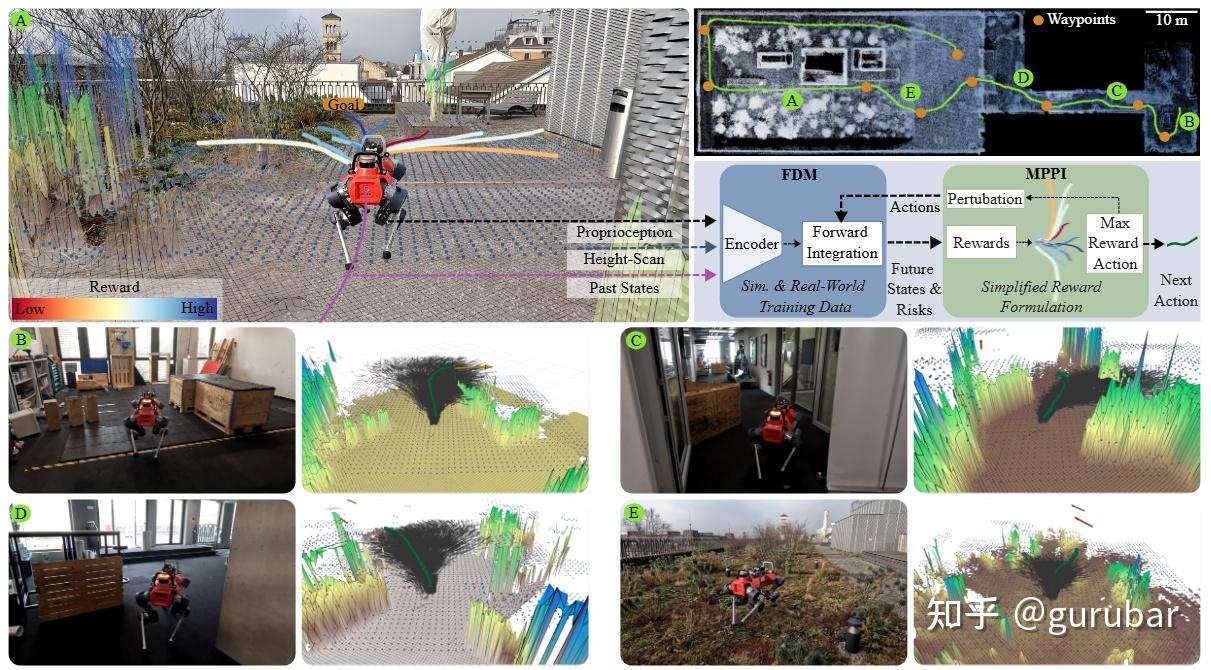
如上图,图右侧管线里, FDM 接收高度扫描(height scan)、历史位姿和本体传感(proprioception),对一整段速度指令序列进行多步前向积分,预测未来位姿和“失败风险”。
其后方的 MPPI 采样规划器随机扰动动作、调用 FDM 做 roll-out,并用“到目标的距离 + 失败风险”构成的简化 reward 为每条轨迹打分,从而在动作空间里做安全优化。
图左上大图和 A–E 子图里,多条候选路径以颜色编码 reward,红色高风险、绿色最优轨迹,最终选择的是既接近目标又避开台阶和坑洼等危险区域的绿色路径,展示了“可学习 FDM + 安全约束”在真实 ANYmal 平台上的安全导航效果。
这类 FDM 只在状态空间中预测未来轨迹和风险,而不生成像素视频,本质上是一个 world-model-style 的前向动力学模型;与上面那些视频世界模型互补——它为真实机器人提供可解释、带安全评估的动力学预测。
RL & Policy Adaptation:
世界模型作为“训练场”和“评委”
这一主题的核心问题是:有了一个比较靠谱的 world model,如何更高效地训练 / 评估策略?
大致可以分成几类:
- world model 作为高保真模拟器 + model-based RL 环境;
- world model 作为policy evaluator / critic;
- world model 与 VLA / diffusion policy 的联合训练;
- 用 RL 反过来训练 world model 自身(如 RLVR-World)。
Robotic World Model 与 model-based RL
Robotic World Model: A Neural Network Simulator for Robust Policy Optimization in Robotics
https://arxiv.org/pdf/2501.10100
训练一个神经网络模拟器(state-based 或视觉版),在其中做 model-based RL,并在 quadruped locomotion + manipulation 上展示了 sim-to-real 的鲁棒性改进,后来还推出了 offline 变体 RWM-O 用于 offline RL。

如上图,这张图按列展示了多种机器人环境(机械臂操作 + 多种四足/双足 locomotion),每个环境上方是 RWM 神经网络模拟器在“想象”中自回归 rollout 的轨迹,下方是同一策略在真实物理模拟中的轨迹。
对 ANYmal D 四足机器人,还在最底一行给出了 真实机器人的硬件运行画面,说明策略完全是在 RWM 这个 learned simulator 里用 MBPO-PPO 风格的 model-based RL 训练出来,然后零样本直接部署到现实。
从“Imagination ↔ Ground Truth ↔ Deployment”三行对比可以看出,RWM 在长时预测上与真环境高度一致,从而支撑了 sim-to-real 的鲁棒性提升。图中覆盖了 manipulation 和 quadruped locomotion 两类任务,体现了该神经网络模拟器既能建模臂式操作,也能建模腿足动力学,是一个通用的 world model。
RLVR-World: Training World Models with Reinforcement Learning
https://arxiv.org/pdf/2505.13934
不再把 world model 当“被动监督任务”,而是用 RL 信号直接训练 world model,使其在辅助策略优化时更有用(例如,更好地区分高收益与低收益轨迹)。
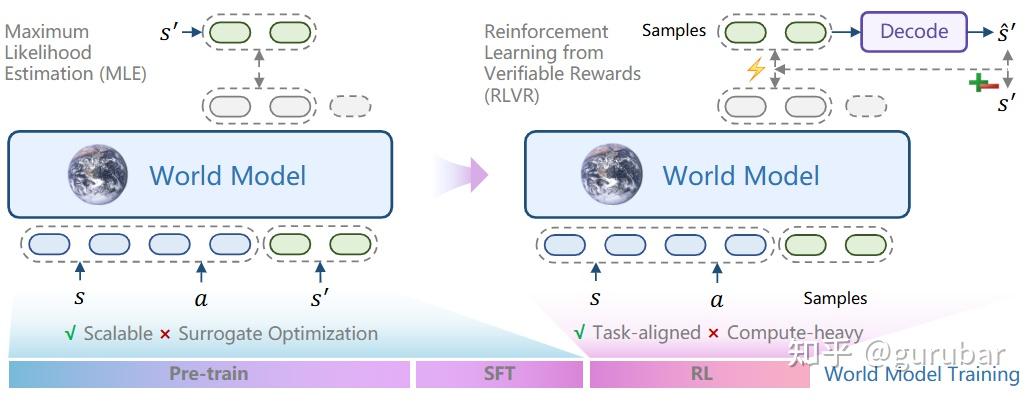
如上图,图左边是世界模型只用 MLE 等监督目标 做预训练/微调,相当于“被动”拟合下一步状态分布,和真正关心的任务指标(回报、感知质量)并不对齐。
图右边则把同一个 world model 接到 RLVR 环路 里:先从模型采样一批完整轨迹或预测序列,再把它们解码成视频/语言状态,与真值比较得到 可验证 reward(准确率、LPIPS 等)。
这些 task-specific reward 被当成 RL 信号,通过 GRPO 更新 world model 的参数,让模型更偏向生成“高奖励”的预测、压制“低奖励”的预测。
因此,直接体现了的核心思想:不再把 world model 只当监督学习任务,而是用 RL 信号对它做后训练,使它在区分高收益 vs 低收益轨迹、服务后续策略优化和 MPC 时更有用。
Policy Evaluation in World Models
Evaluating Robot Policies in a World Model (WPE / WorldGym)
https://arxiv.org/pdf/2506.00613v1
训练一个 action-conditioned diffusion 视频 world model,然后用它来对不同 VLA 策略进行蒙特卡洛 rollout + VLM 打分,实现“只用一帧起始图像,在 world model 内评估策略”。结果显示,world model 下的成功率与真实机器人实验高度相关,至少能可靠排序不同策略版本。

如上图,图中上、下两行分别是真实机器人执行得到的视频帧和世界模型在同一动作序列下生成的帧,说明先训练了一个 action-conditioned diffusion 视频 world model 作为“虚拟环境”。
给定一帧(或少量)起始观测和待评估策略 π,先在真实世界 rollout 得到真实成功率 ρ(π),同时在世界模型中对策略做多次蒙特卡洛 rollout 得到估计值 ρ^(π)。
把世界模型生成的视频和语言目标一起喂给 VLM,让它判定任务是否成功,从而给每条 imagined 轨迹打分。图中的 “World Model Evaluation” 模块用 MSE、感知相似度等比较生成与真实视频的一致性,以验证世界模型能否忠实跟随动作输入。
如上图可以概要地阐述:在训练好 action-conditioned diffusion world model 后,可以 只用初始图像 + 策略输出的动作,在模型内评估不同 VLA 策略,并且他们在实验中发现这种评估与真实机器人实验的成功率高度相关,足以可靠区分和排序不同策略版本。
与生成策略/模仿学习的联合(GPC, FLARE, DEMO³, World4RL)
GPC:Generative Predictive Control(参考前面)
https://arxiv.org/pdf/2502.00622
如前所述,GPC 用 world model 对 diffusion policy 的 action chunk 进行 look-ahead 规划,是把“policy + world model”在控制框架中真正合起来的一步:policy 负责从历史“回看”,world model 负责“向前想象”。
FLARE:Implicit World Modeling for VLA Policies(参考前面)
https://arxiv.org/pdf/2505.15659
利用未来 latent 对齐,使得 diffusion/flow policy 自带一个 implicit world model,不需要显式环境 reconstruction,就能在 latent 中进行“未来推演”,对多任务模仿学习和 egocentric video 预训练都很友好。
DEMO³(参考前面)
https://arxiv.org/pdf/2503.01837
将 world model、reward、policy 三者当成一个联合学习问题,特别适合多阶段 manipulation。
World4RL(参考前面)
https://arxiv.org/pdf/2509.19080
将 diffusion world model 与 RL 算法 tightly-coupled,用在多轮视觉-语言-动作 agent 和机器人控制上,体现 world model 在复杂多模态 RL 中的作用。
语义世界模型与 LLM/VLM-as-Judge
Semantic World Models
https://weirdlabuw.github.io/swm/static/documents/swm.pdf
探索把 VLM/LLM 与 world model 结合,让世界模型不仅预测像素,也生成语义 token / reward signal,从而更好地支撑高层规划和语言条件任务。

如上图所示,图左边展示输入:当前观测图片、候选动作序列,再加上一条关于“未来会怎样”的自然语言问题,一起喂给一个经微调的 VLM——这就是语义 world model。
SWM 把图像编码、动作投影到 LLM token 空间,然后像普通大模型一样做自回归生成,但输出的不再是像素,而是对应问题的文字答案(yes / no 等语义 token)。也就是给定一组“问题 + 期望答案”(比如“方块是否被抓起?答案=是”),用不同动作序列反复调用 SWM,得到答案概率,把它们汇总成一个 语义奖励/打分信号。
这个语义分数再被用在采样式或梯度式优化里,迭代更新动作序列,相当于“在 world model 里,用语言奖励来做规划与策略改进”。SWM 把 VLM/LLM 能力 + action-conditioned world model 融合在一起,让模型直接生成高层语义 token / reward,而不是像素,从而更适合做语言条件任务和高层规划。