作者:JayNing
https://zhuanlan.zhihu.com/p/196909645458175683
本文是Nathan Lambert在PyTorchCon 2025分享训练开源的Olmo-Thinking模型的文字笔记, 内部加入了笔者的一些批注和思考

Nathan Lambert 00:00
大家好,非常荣幸能在这里分享。我在艾伦人工智能研究所(AI2)工作,多年来一直专注于强化学习(RL)和开源模型。有意思的是,我们长期耕耘的这些领域,如今正成为行业热点。
所以,我今天想和大家聊聊,现在大大小小的实验室都是怎么训练推理模型的。
这其实可以看作是,为了实现模型的推理能力,大家把整个训练技术栈(training stack)重新设计了一遍。
Nathan Lambert 00:28
当我们提出要构建 Olmo 这个新的开源推理模型时,一个很自然的问题就是:为什么我们还需要一个新的大语言模型?
毕竟,市面上已经有很多顶尖模型,比如 Qwen、Mistral,以及来自 OpenAI、英伟达、Hugging Face 等行业巨头的作品。可以说,市场已经相当饱和。
因此,我们必须回答一个核心问题:通过前所未有地开放我们的训练流程,究竟能为整个社区带来什么独特的价值? 我们又该如何利用这种开放性,去构建一个社区真正需要、并且能够持续演进的生态系统?

Nathan Lambert 00:54
我长期关注的方向是将强化学习(RL)与大语言模型结合。这个领域虽新,但机制复杂。两篇针对 Qwen 系列的研究表明,Qwen2.5 与 Qwen3 已成为社区做 RL 的常见基座(base model)。
由此引出一个关键问题:这些模型在 RL 基准上的亮眼表现,究竟是因为其预训练数据包含与基准或奖励模型高度相关的模式,从而更易“刷分”,还是因为 RL 训练确实提供了新的、可泛化的学习信号?
这一疑问也促使大家反思方法论:我们观察到的提升到底是“学会了”,还是“迎合了”奖励与数据分布。 我参与的那篇关于“虚假奖励”(Spurious Rewards)的论文进一步说明,如果奖励或数据存在缺陷,模型可能依赖伪信号获得高分,而非真正能力的提升。

Nathan Lambert 02:04
这里有一个具体的例子,它进一步说明了这个关于强化学习(RL)的深刻问题。
尽管我们无法拿到 Qwen 模型的训练数据来直接验证,但我们可以做一个推测。当你给 Qwen 的基础模型一个数学题——这个题与一个已经成为行业标准的基准测试(Hendrycks MATH 数据集)中的题目高度相似时,会发生什么呢?
惊人的是,即便没有任何外部工具的辅助,模型也会直接生成代码,并以极高的精度解出答案。 并且,无论你使用测试集中的原题,还是仅仅修改了数字的变体题,结果都完全一样。 这强烈暗示了一点:Qwen 的基础模型在预训练阶段,很可能已经“见过”甚至“记住”了这些评测数据。 这就给我们带来了真正的挑战:如果基础模型已经记住了答案,那么我们后续在其上进行的强化学习,究竟是在学习真正的推理能力,还是仅仅在学习如何触发模型已有的记忆?这正是为什么我们必须深入理解模型本身,否则,我们根本无法对自己构建的RL系统建立真正的信心。”

Nathan Lambert 02:54
在此基础上,强化学习(RL)社区正进行着大量前沿研究,比如通过DAPO、CSIPO等算法来探索如何改变模型行为——当然,具体的算法名称并不重要。 这些研究普遍面临一个核心挑战:模型的‘探索’能力严重不足。 这意味着,模型倾向于在预训练阶段学到的知识范围内“原地打转”,而无法生成真正新颖、有价值的内容。
我们的论文中一个引人深思的实验揭示了问题的严重性:研究人员用完全随机的奖励去训练一个RL模型,模型的数学解题能力反而提升了。
这听起来很荒谬,但我们的解释是:这并非RL算法的功劳,而是算法的内在偏好,无意中激活了预训练数据中本就潜藏的知识。 这种由数据驱动的“伪进步”,正困扰着整个行业,让我们无法评估RL的真实效果。
因此,我们的核心主张是:要想实现真正的算法创新,我们必须打破这个黑盒。我们需要一个数据完全透明、过程完全可观测的系统,去真正理解算法与数据之间的复杂互动。否则,我们所谓的‘进步’可能只是幻觉。”
Nathan Lambert 04:10
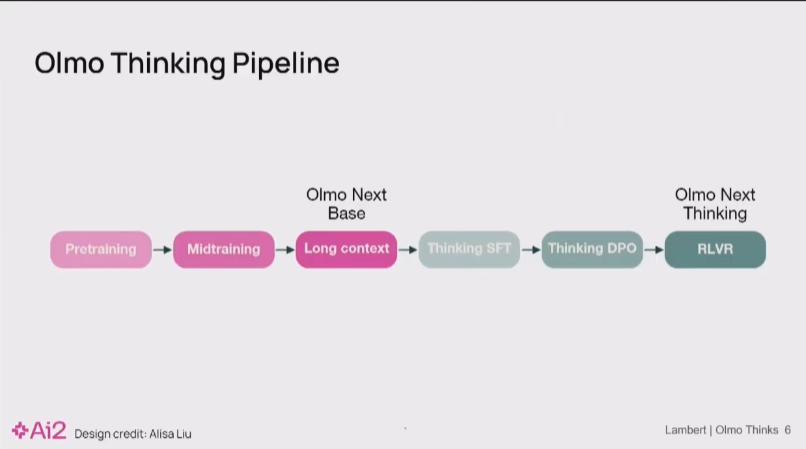
这正是我们打造 Olmo 的初衷: 我们希望构建一个端到端(end-to-end)的透明框架,覆盖从预训练、中间调优到所有后训练环节。
其核心目的,就是为了让研究者能清晰地分辨:模型的性能提升,究竟是源于算法的真实贡献,还是仅仅因为它学会了利用数据中的虚假关联(spurious correlation)来‘应付’评测。
因此,我今天的分享,将聚焦于我们在此过程中遇到的一系列棘手挑战。 这些挑战,都源于我们努力提升 Olmo 模型推理能力的实践过程。
Nathan Lambert 04:41
我们遇到的第一个重大挑战是:为了高效地进行强化学习(RL),我们必须对之前那套‘勉强够用’的 Olmo 2 的架构进行改造。
Nathan Lambert 04:50
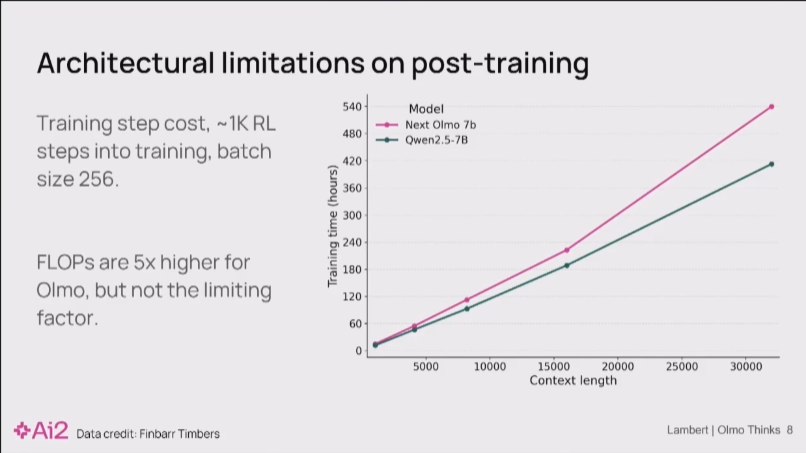
问题的根源在于,RL对计算资源,尤其是内存,有着极高的要求。起初这让我们很困惑,因为如果我们只看单步训练的计算成本,Olmo 和 Qwen 这样的模型非常接近。
后来我们发现,一个在去年模型中被忽略的关键特性,成为了性能瓶颈:我们没有采用 GQA。
GQA 能够极大地节省显存。这个架构缺陷在监督微调(SFT)小规模RL等内存开销较小的阶段并不明显,因为那时的训练成本看起来差不多。然而,一旦进入内存密集型的RL阶段,缺少GQA的劣势就暴露无遗,成为了我们必须解决的问题。”
在第一张图同样上下文长度下训练 1000h GPU hour以下下两条线的差距并不悬殊。
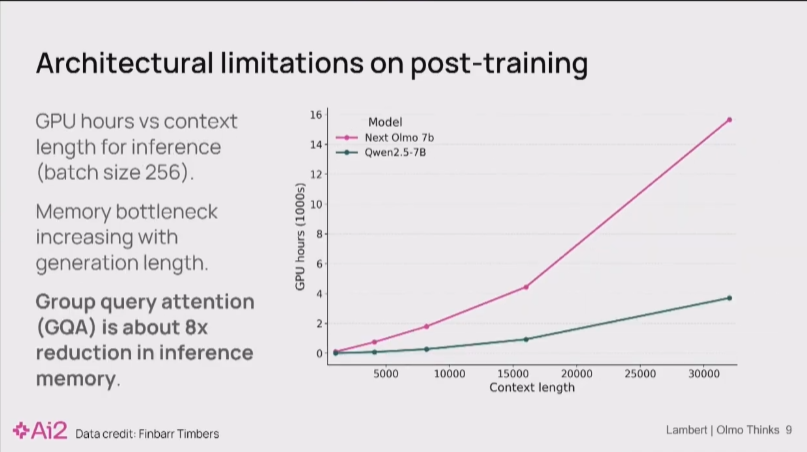
Nathan Lambert 05:26
但是,当你进行大规模强化学习时,大量的计算资源实际上都花在了推理(inference)上。
而 GQA 这一架构优化,恰恰能将注意力机制的内存占用降低约8倍。缺少它,直接导致我们的 7B 模型在RL训练中,内存开销堪比一个 32B 的庞然大物。
这样的资源效率是完全无法接受的。这一发现让我们别无选择,只能下定决心推倒重来,重新进行预训练。 因为只有从架构根源上解决问题,我们才能真正实现下游RL实验的高效率和快速迭代。”
将纵轴变成数千GPU小时 后两条线的差距变得极为夸张。随着上下文变长,Olmo 的资源消耗呈指数级增长,而 Qwen 则平缓得多。
Nathan Lambert 06:00
接下来,我将具体介绍我们在数据处理上采取的关键策略和步骤。
Nathan Lambert 06:04
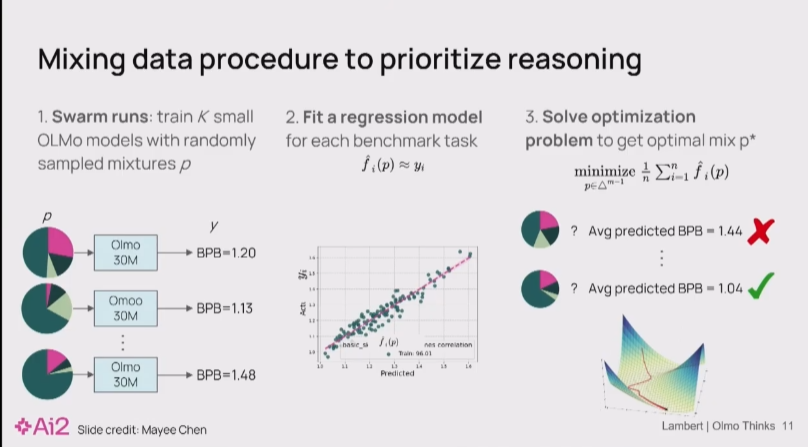
当你有数万亿 token 的数据,却只能用其中一小部分来训练时,数据配比就成了一门科学。过去,大家可能凭经验,多加点代码、多加点数学数据。但我们采用了一种更系统化的方法,
“好,我们来深入探讨数据。在预训练阶段,我们面临一个核心问题:我们拥有的数据(高达数万亿token)远超实际能使用的量。那么,如何智能地筛选出最优的数据组合呢?
答案是,你的数据选择,本质上反映了你对模型能力的期望。 想要模型在推理上更强,一个直接的策略就是增加数学、科技和代码数据的比重。
但具体该如何操作?在AI2,我们采用了一种系统化的方法:
其实就是RegMix 2407.01492. 按笔者个人的经验这里的 指标一般选 paloma/c4_en/bpb lm_eval/averages/macro_avg_acc_norm 和你希望的目的相关的指标 如 lm_eval/mmlu_5shot/choice_logprob_norm. 然后做个权重 log_sum去解帕累托点
e.g. 80% paloma/c4_en/bpb + 10% lm_eval/averages/macro_avg_acc_norm + 10% "lm_eval/mmlu_5shot/choice_logprob_norm" 然后用lightgbm求解
1.首先,我们会在海量数据源的各种子集上,训练大量的小型模型。
2.其次,我们通过在一个固定的验证集上观察它们的性能指标, 并拟合一个关于配比与指标的回归模型
3.求解这个模型得到配比
在我们的案例中,我们增加了 10% 到 20% 的评测指标,这些指标更侧重于数学和代码,这极大地改变了所谓的“最佳数据”的构成. 最终,新模型在数学和代码上表现更出色,但这并非没有代价——它在像MMLU这类更泛化的知识评测上,性能出现了轻微的下降。
这就是数据工作中一个无法回避的Trade-off。目前,很难做到‘鱼与熊掌兼得’。构建能够量化权衡的工具链,是一项耗时且关键的工程。
Nathan Lambert 07:35
我们之前Olmo模型的另一个关键短板,是缺乏处理长上下文的能力。
这在推理时代是致命的。 因为现代推理模型,尤其是在生成代码等关键应用上,需要输出长达数万token的复杂答案。而我们旧模型的上下文长度仅有4K或8K,这与实际需求存在着数量级的差距。在这样的基础上,赋予模型强大的推理能力根本无从谈起。
这就引出了一个核心的战略问题:我们的瓶颈在哪里?
是数据问题——我们缺少像闭源实验室那样,拥有科学书籍、学术论文等公认能提升长上下文能力的高质量数据?
还是架构问题——模型的设计本身就从根本上限制了它处理长上下文的能力?
这个问题我们必须回答。
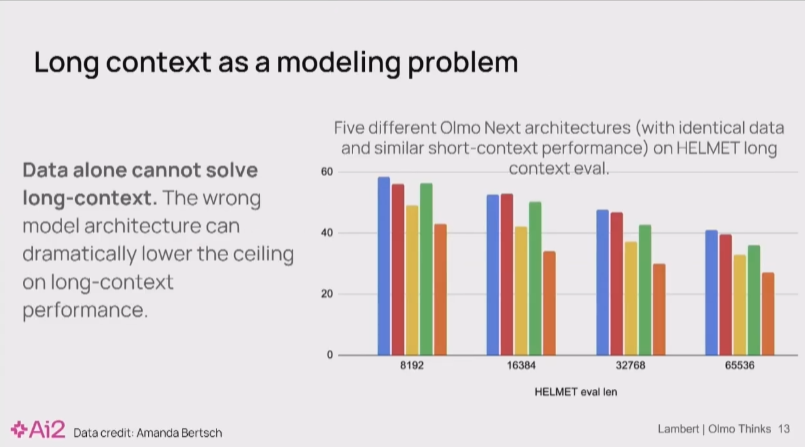
Nathan Lambert 08:18
那么,长上下文的瓶颈究竟是数据还是架构?我们的实验给出了一个明确的答案:问题完全出在架构上。
我们的核心假设是,问题源于一个特定的归一化层(Normalization Layer),即 QK Norm,它从根本上限制了模型在长上下文中的推理能力。
这张图表提供了强有力的证据。 我们设计了一个严格的对照实验:图中展示了 Olmo 的五种架构微调版本。关键在于,它们都使用了完全相同的2万亿token数据进行训练。唯一的变量就是架构本身。
结果一目了然:尽管数据完全相同,但这五种架构在长上下文任务上的性能表现却有天壤之别。
这揭示了一个深刻的教训: 许多在过去被认为是次要的架构细节,在模型能力向推理等新领域拓展时,会成为决定性的瓶颈。这些问题之所以被长期忽视,仅仅是因为在那个时代,极限的推理能力还不是我们和同行们追求的首要目标。
一个Frontier Lab已经发觉很久(大概在4月份很多人已经意识到了 最前沿的实验室在1月前已经意识到了)但没有成为共识的结论. 具体可以参考大海捞针的任务中的注意力分布,QK norm会丢失很大的细节 可参考2501.18795 但其实QK Norm能很大程度的修正loss spike问题. Qwen3也有QK Norm, 实际上又是一个trade off
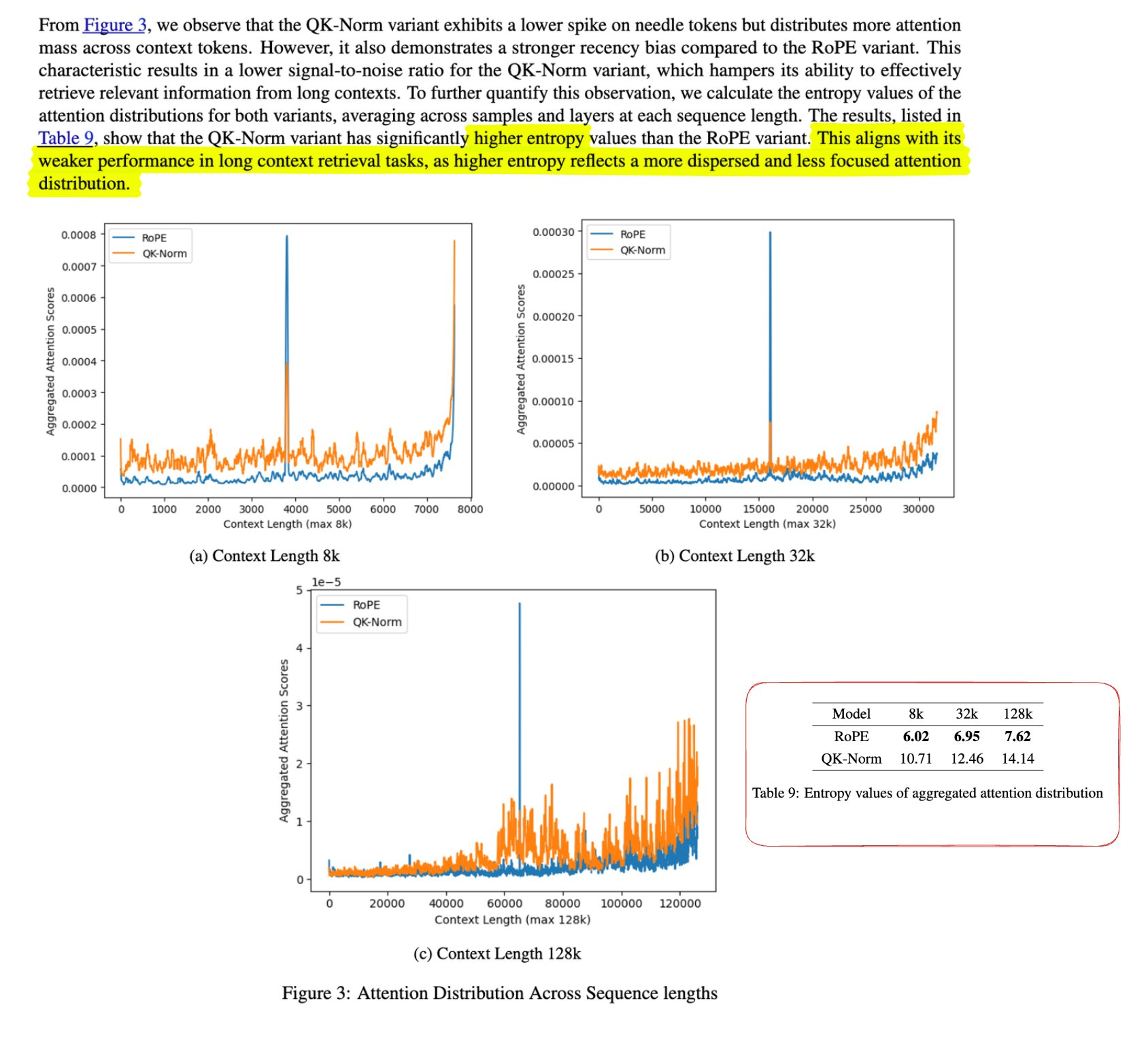
Nathan Lambert 08:54
好的,现在我们进入我个人最感兴趣的部分:现代推理模型的后训练(Post-training)究竟是如何进行的?
我们首先专注训练于一个小模型,之后会训练更大的模型。

Nathan Lambert 09:13
我们可以通过使用reasoning数据“蒸馏”的方式,高效地训练出性能优异的专用推理模型。
关键在于利用强大的推理模型(如 DeepSeek)来生成高质量的训练数据,然后用这些数据对小模型进行SFT。
1.获取种子数据: 从 Hugging Face 等平台选择一个高质量的开源数据集(例如 OpenThought 3)。
2.数据精炼: 对其进行更严格的筛选和优化。
3.数据生成: 利用处理后的数据作为范例,通过强大的模型API(如 DeepSeek)生成规模更大、质量更高的新数据。
这个方法的效果非常好。对于任何想在特定领域拥有专用推理模型的团队来说,只要能调用一个强大的API,就很有可能成功复现并扩展这一流程。
有一些来自OT作者的一些消息(小道消息)和笔者的一些经验来补全这部分的一些疑问:
0. 更多的数据集总是能更好 OT4仅仅是扩展了大小没有变方法论就成功又涨了不少点
1. 为什么不使用最厉害的模型作为教师: 有些发现有时稍弱一些的教师模型反而能更好地充当教师角色QwQ-32B 生成数据效果优于 R1. 而且各个任务的最好的教师也不一致(参考3)
2. 为什么要Extend 上下文: 他们没觉得真的没觉得有太大影响; 实际上OT3有 60%的数据都是被截断的(16k), 但按作者消融的结果来看模型实际上学习的是思考的模式, 所以说被截断不但没有下降反之还有点帮助. 而如果你需要进一步scale模型的话or有更好的过滤准则的话 生成长一点总是好的
3. OT是个专注于math code STEM的数据集 所以说肯定得加入IF来提升整体的效果 他们内部用的chat sota数据集(比Tulu略好)叫dcft系列是用llama-3.1-nemotron-70b标的
4. 这点说的是你随便找个seed做还是需要和OT一样做一些类去重处理的 具体可以参考OT论文
5. SFT在小模型做效果是高效的详情参考R1论文
在通过推理蒸馏完成监督微调(SFT)后,我们发现其实可以用一个简单却非常有效的步骤:应用preference tuning技术。即使是DPO
在我们的评测集上,这一步操作可以轻松带来好几个百分点的性能提升。
这是一个尚未被广泛采用的优化技巧,Hugging Face 发布的 smollm3 模型就是一个很好的参考,他们也采用了类似的DPO流程来增强模型能力。
这点还是非常值得关注的 对于一些reward稀疏的任务是很难做RLVR的,一般期望SFT去缓和, 但SFT会对泛化有一定影响 所以说thinking-dpo实际上提供了一个优秀的新思路 smollm所用到的数据集是smoltalk2/Preference/tulu_3_8b_pref_mix_Qwen3_32B_Qwen3_0.6B_think 实际上就是把thinking的步骤当中优化目标但是是RL
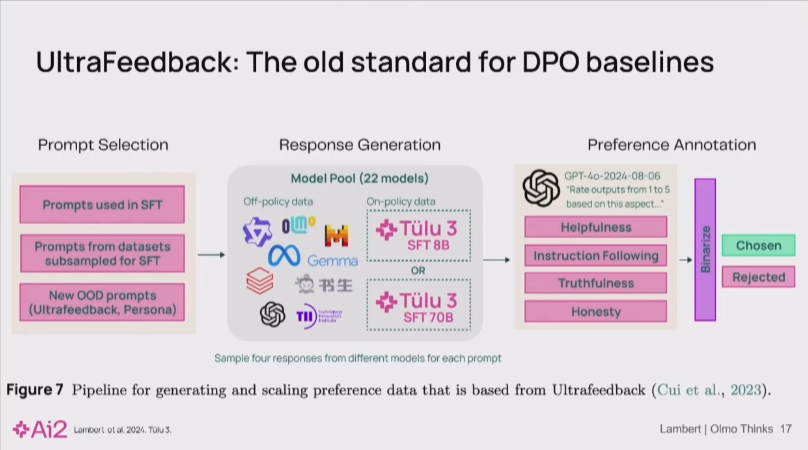
Nathan Lambert 10:08
早期的偏好调优方法,如为UltraFeedback数据集收集数据时所采用的策略,其核心是构建一个“模型池”(model-pool)。该策略旨在从大量不同的模型中,针对同一提示(prompt)收集多种回答。随后,通过对这些回答进行排序,构建出一个以“乐于助人、诚实”为目标的偏好数据集。

Nathan Lambert 10:35
然而,这种传统的“模型池”方法正面临性能饱和的瓶颈。主要原因是,随着基础模型能力的普遍提升,对于许多常见的聊天查询,不同模型的回答已经变得高度相似。这导致区分回答优劣的难度显著增加,即使采用LM-as-a-Judge的自动化评估方法,在通用的后训练数据集上也很难做出有效的区分。

Nathan Lambert 10:50
为应对上述挑战,我们的策略转向了基于“增量学习假设”(delta learning hypothesis)的偏好学习方法。该假设的核心观点是:在偏好学习中,“选中”(chosen)答案与“拒绝”(rejected)答案之间的相对差异(delta),比“选中”答案本身的绝对质量更为关键。
这一观点与DPO等对比损失函数(contrastive loss function)的机制高度契合,因为模型需要通过明确的“对比”来产生有效的学习梯度。在实践中,我们采用以下方式构建对比数据:
- • “选中”答案:由一个强大的模型(如 Qwen-3 32B)生成。
- • “拒绝”答案:由一个能力稍弱的同系列模型生成。
此方法的一个关键难点在于,需要找到一个能力“恰到好处”的弱模型——它既要能进行合理的推理,又不能过于强大,以确保与强模型之间存在足够大的学习信号。
例如,我们发现Qwen 0.6B模型有时甚至因性能过强而难以产生理想的DPO信号。这表明,在某些情况下,可能需要先专门训练一个能力受控的弱模型,以构建高效偏好学习所需的数据生成引擎。
Nathan Lambert 11:41
在SFT和DPO之后,下一步是在小模型上规模化地实施RLVR。然而,这是一个极具挑战性的工程问题,通常伴随着高昂的时间成本和复杂的技术难题。构建稳定、高效的RL训练工具是当前行业内许多团队共同面临的难点。接下来,我们将探讨典型RLVR训练循环中的核心工程挑战。

Nathan Lambert 11:52
我们这个由 2 到 4 人组成的小型研究工程团队,整个夏天都在构建强化学习工具。在座的很多人也都在做这件事。这就是为什么我很高兴能来参加这个会议和大家交流。
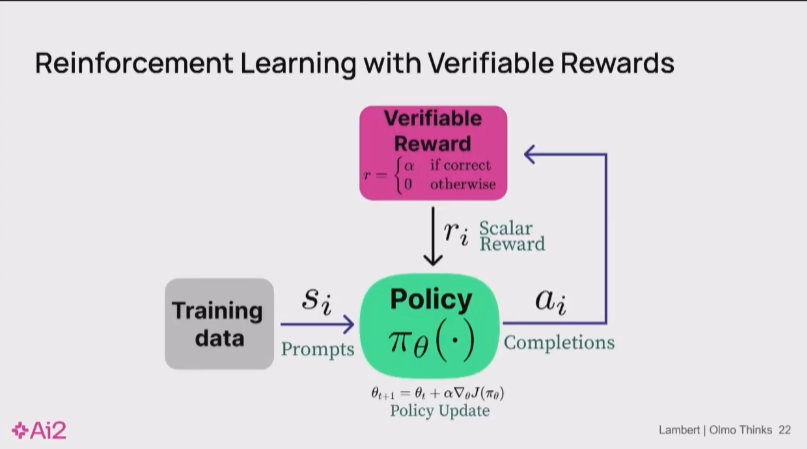
Nathan Lambert 12:00
我会很快地过一遍这些基础内容,以便引发讨论,这就是大家以前见过的那个RLVR循环。
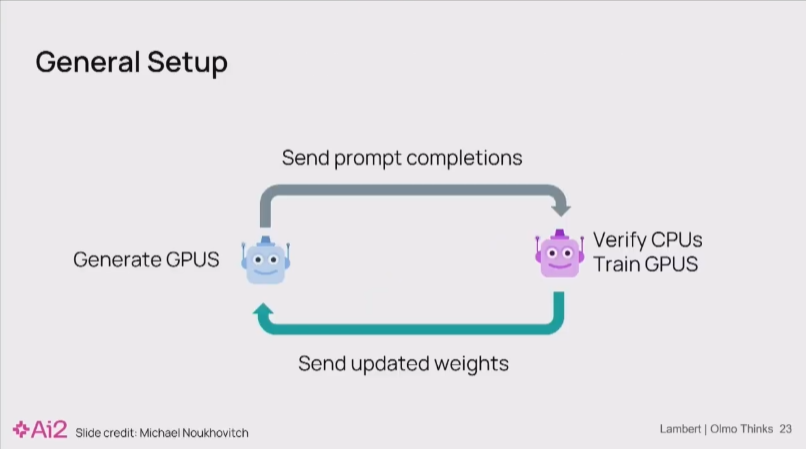
Nathan Lambert 12:12
在实践中,一个典型的RL训练系统包含两组独立的GPU集群:一组用于推理生成(如使用vLLM),另一组用于模型训练和梯度更新。
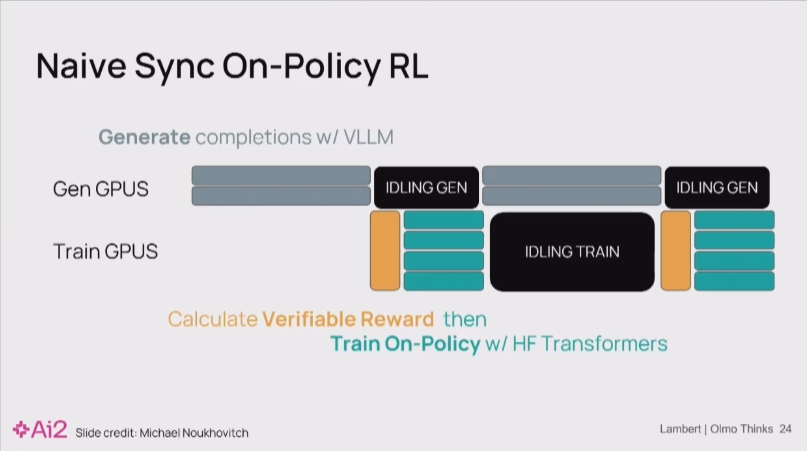
Nathan Lambert 12:25
若采用同步流程(即生成->训练->生成),会导致其中一组GPU在另一组工作时处于空闲状态,造成严重的计算资源浪费和高昂成本。
为解决此问题,我们可以采用Asynchronous和Off-Policy的RL算法。
然而,这种效率提升是有代价的:它牺牲了部分数值稳定性和理论收敛性。“Off-Policy”源于生成器(vLLM)和训练器(如Hugging Face Trainer)中的模型状态不完全同步,导致它们各自的概率分布存在偏差。这些细微的数值差异会在训练中累积,构成主要的稳定性挑战。
可参考 https://yingru.notion.site/When-Speed-Kills-Stability-Demystifying-RL-Collapse-from-the-Training-Inference-Mismatch-271211a558b7808d8b12d403fd15edda 大概就是你看似on-policy 实则off-policy了
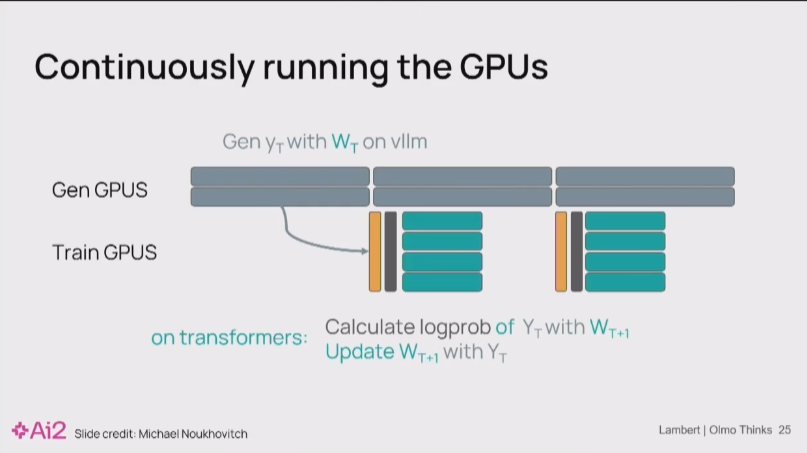
Nathan Lambert13:14
该方案的核心是解耦生成与训练:生成器集群持续不断地产生数据,而训练器集群则使用最新的数据进行梯度更新。这种并行化设计能最大化GPU利用率。

Nathan Lambert 13:16
为了解决异步RL中的数值挑战,核心任务是校准来自不同模型实现(生成器与训练器)之间的概率分布。以下是几种关键的解决方案:
1.修改(CUDA)核函数(kernel):修改算子使其有batch-invariant性让vLLM和 Hugging Face 的结果更匹配 (我们试了但没能平衡好性能和准确性)
2.重新计算对数概率 (Re-calculating Log Probs):在vLLM生成token后,将其传递给训练器模型,重新计算一次对数概率。这种方法能确保梯度计算的数值精度,但代价是增加了额外的GPU计算开销,本质上是用计算时间换取准确性(我们现在的方法 很贵)

Nathan Lambert 14:05
现在很多人都在用的一个技巧是重要性采样 (Importance Sampling):通过重要性采样,可以将一个概率分布下的采样数据有效地用于另一个分布的期望计算。在RL中,这通常表现为重新加权(re-weighting)从奖励模型中获得的优势奖励(advantage rewards),以修正因策略不匹配带来的偏差。
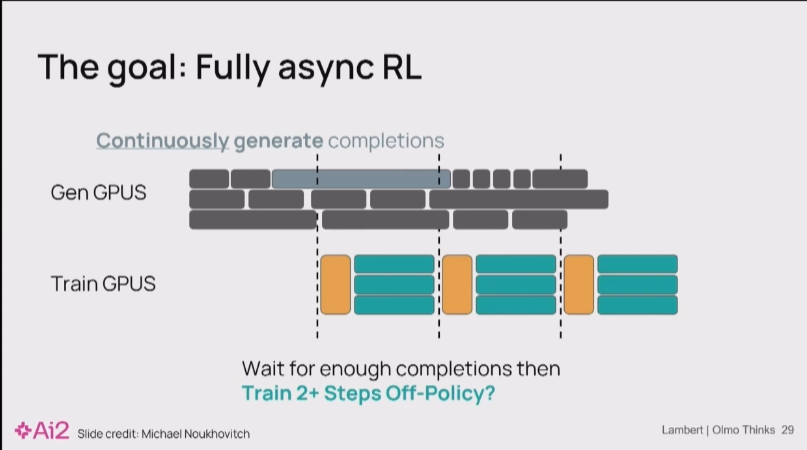
Nathan Lambert 14:25
你还可以玩一个花样动态权重更新 (Dynamic Weight Updates):这是一种更高级的同步技术。在训练过程中,可以周期性地将训练器更新后的权重插到生成器中,即使中断正在进行的长文本生成也要执行。这能有效减少生成器和训练器之间的“策略延迟”。
实际上就是Split placement + partial rollout 因为如果是不做这种partial rollout的Split placement基本2+ step off就掉点了 而这里通过控制Staleness 就可能可以做到2+step(几乎等同于 但是是以Staleness角度)的async rl
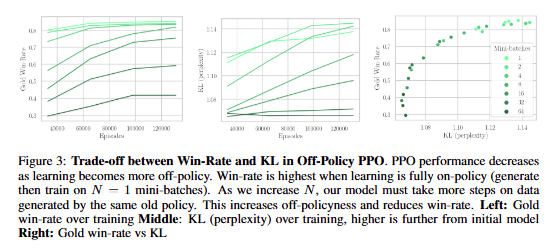
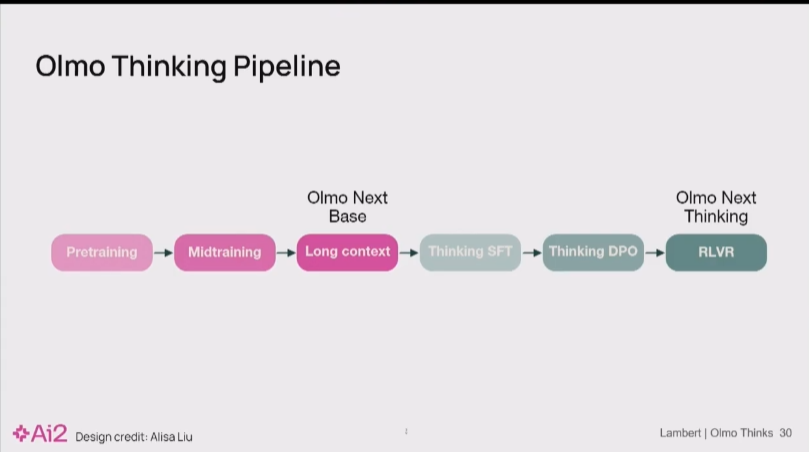
Nathan Lambert 14:46
这就是对你需要做的各种事情的再一次快速概览。

Nathan Lambert 14:51
接下来的工作就是真正地扩展这一切,以便用更有趣的强化学习方法来训练更大的模型,并为其添加工具。这些都是我们准备要做的事情。
Nathan Lambert 15:01
我们现在就有持续数天的强化学习任务正在运行。所以,如果你对学习这些模型,或者对构建训练它们所需的工具感兴趣,可以联系我或者 AI2 团队的成员,因为构建工具和模型是一项巨大的工程。感谢大家的聆听,期待稍后与大家交流。