论文地址:https://arxiv.org/abs/2507.20534
Kimi k2 做了哪些优化?
Kimi K2 不是传统的 “单一大模型”,而是一种叫 “混合专家(MoE)” 的架构 —— 可以理解成 “一群专家分工干活”:
- 总参数有 1 万亿,但每次实际工作时,只激活 320 亿参数(相当于只调用一部分 “专家”),这样既能保持大模型的能力,又不用每次都 “满负荷运转”,节省计算资源;
- 它的核心目标是提升 “智能体能力”—— 也就是让模型能像人一样 “自主做事”:比如自己用工具(像查天气、算数据)、解决多步骤问题(比如修代码 bug、写复杂程序)、甚至在互动中学习改进,而不只是被动回答问题。
优化点
我们推出了Kimi K2,这是一款混合专家(MoE)大型语言模型,具有320亿激活参数和1万亿总参数。我们提出了MuonClip优化器,它在Muon的基础上进行了改进,采用了新颖的QK-clip技术来解决训练不稳定性问题,同时保留了Muon出色的token效率。基于MuonClip,K2在15.5万亿token上进行了预训练,且未出现任何损失峰值。
在后期训练阶段,K2经历了多阶段的后期训练过程,其中亮点包括大规模智能体数据合成管道和联合强化学习(RL)阶段,模型通过与真实和合成环境的交互提升了自身能力。
训练这么大的模型,最头疼的是 “训练不稳定” 和 “优质数据不够用”,团队用了两个关键方法解决:
1. 新优化器 “MuonClip”:让训练不 “崩”
之前训练大模型时,经常会出现 “注意力数值爆炸”(模型计算时某些数值突然变得极大,导致训练中断或效果变差)。团队在原有优化器基础上,加了个 “QK-Clip” 机制 —— 就像给数值加了个 “安全阀”,一旦超过阈值就轻轻 “拽” 回来,既保证了训练稳定(全程没出现过 “训练崩溃”),又没降低模型学习效率。
2. 用 “数据重写” 榨干优质数据价值
高质量训练数据不够用是行业难题,团队没硬找新数据,而是用 “重写” 的方式把现有数据 “变废为宝”:
- 比如把知识类文本(像百科)换不同风格、不同角度重写(比如把 “地球是圆的” 写成 “从太空看,地球是一个蓝色球体”),既保留事实,又让模型学到更多表达方式;
- 把数学资料改成 “学习笔记风格”(比如把公式推导写成 “第一步算什么,为什么这么算”),还翻译其他语言的数学资料,让模型更懂数学推理;
- 这样一来,原本 1 份数据能当好几份用,还不会让模型 “学腻”(避免过拟合)。
kimi k2适合做什么?
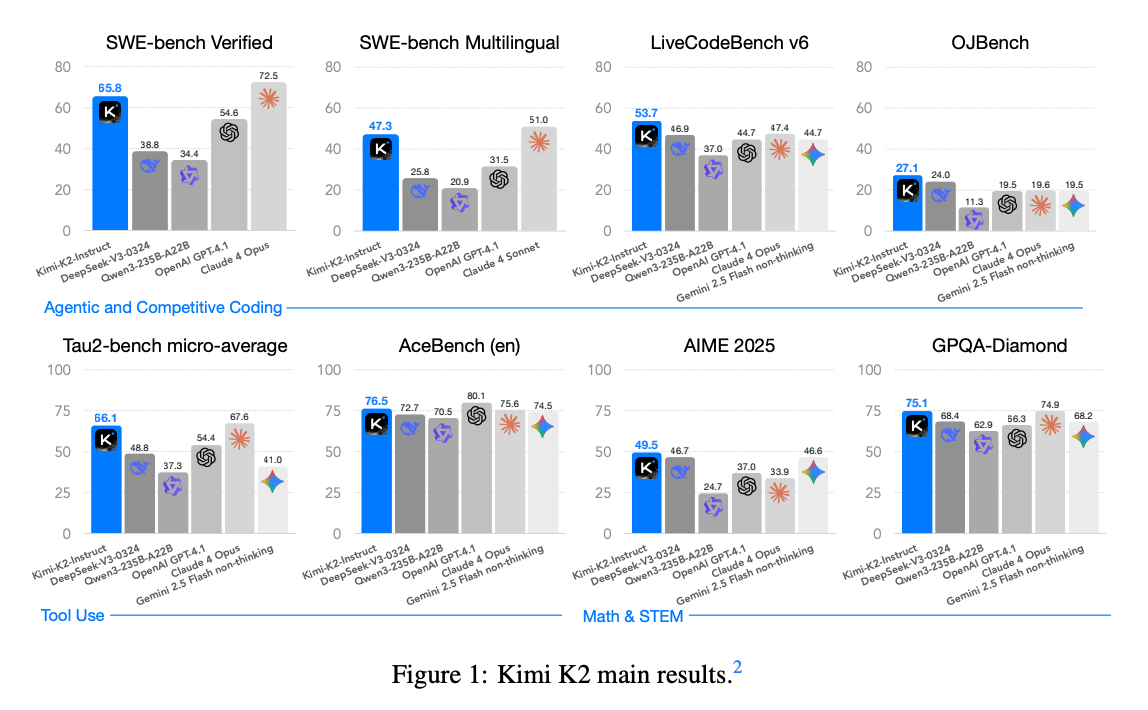
团队用很多权威 “测试题” 给 K2 打分,结果显示它在开源模型里算顶尖水平,尤其在这些方向:
1. 写代码、修代码:能解决真实工作问题
- 比如 “修复 GitHub 上的代码 bug”(SWE-bench Verified 测试),K2 单次尝试成功率 65.8%,多次尝试能到 71.6%,接近闭源的 Claude 4(约 80%);
- 多语言编程也厉害:支持 C++、Java 等多种语言,测试得分 85.7%,比其他开源模型都高;
- 连 “竞赛级编程题”(比如 LeetCode 难题)都能搞定,得分 53.7%,超过大部分开源和部分闭源模型。
2. 用工具、处理多步骤任务:像个 “小助手”
- 测试里让模型用工具处理真实场景(比如查航班、修电信故障),K2 得分 66.1,比其他开源模型高一大截;
- 复杂工具调用(比如连续用计算器 + 查数据)也能应对,得分 76.5,接近 GPT-4.1 的水平。
3. 数学、逻辑推理:不只是 “算题”,还懂 “思路”
- 美国数学竞赛题(AIME 2024)得分 69.6%,比其他开源模型高 10 分以上;
- 逻辑题(比如数独、密码解码)得分 89% 左右,比 Qwen 等模型强很多;
- 研究生级别的 STEM 题(比如物理、化学推理)得分 75.1%,也是开源里顶尖。
4. 日常用也靠谱:知识广、少 “胡说”
- 常识问答(MMLU 测试)得分 89.5%,接近人类专家水平;
- 很少 “hallucinate(瞎编)”:测试显示它的回答和事实的一致性达 88.5%,比很多开源模型都准;
- 长文本处理也行:能读懂 12.8 万字的内容,还能准确提取信息(比如从长文档里找关键数据)。