作者:张海抱
原文:https://zhuanlan.zhihu.com/p/1940702256241575450
写在前面
VLA 时代的强化学习和 Atari 时代的强化学习有什么区别?个人认为有一好两坏两个方面。
好的方面是我们现在有一个非常有用的资源 —— 预训练的大模型,它可以对我们的探索、奖励等多方面有帮助。此外,还有很多大模型时代的技术可以供我们在需要的时候使用,比如 MOE、LoRA 等。
坏的一方面是奖励更稀疏了。Atari 时代中我们关心游戏或者特定的 mujoco 任务,我们针对这些任务我们可以定制较为密集的奖励,即使有一些稀疏奖励的情形(比如蒙特祖玛的复仇),我们也可以通过状态空间的遍历探索来获取奖励。
但是 VLA 时代我们更关注实际的机器人任务,这些任务中我们不再希望能对于每个任务都定义密集奖励 —— 因为我们不再关注离散个任务,而且泛化的一大族任务 —— 甚至每个任务都去定义稀疏奖励也嫌麻烦。
坏的另外一方面是现在的策略模型都比较大了,有些还使用了 auto-regressive 或者 diffusion 的结构,这也会给强化学习带来一定的麻烦。
由此,这里调研到的很多工作其实都是围绕这些点中的一个或者多个展开的。比如针对稀疏奖励问题,除了可以设计一些规则(比如成功的轨迹中越靠后越好)来把奖励加密之外,我们还可以使用专家数据做 warm-up 或者 KL regularization 。再或者,可以结合大模型,用预训练好的 VLM 来为 RL 提供更为密集的奖励。
在此视角下去观察和总结最近的研究趋势,会更为清晰。
感谢帮助调研的我的两位实习同学,张然和杨如帅。
一、VLA + Offline RL
论文:Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
Paper:https://arxiv.org/pdf/2309.10150
代码:https://qtransformer.github.io/
一句话概括?基于人类数据和自己采集的成功/失败的数据,训练了一个基于 Transformer 的 Q 函数。
数据中的 reward 和 return 是怎么设置的?本文只考虑 binary sparse reward,即只有最后一步有 0/1 reward;return 用的 Monte Carlo estimate。human demo 中的都是成功的,自己收集的可成功可失败。
在神经网络结构和训练上有什么设计?神经网络输出每个时间步上,每个动作维度(图中每一列)每个 bin 内(图中每一行)上对应的 Q 值。如果这个 bin 没有被选择,训练目标就是 0;如果被选中了,训练目标就是相应的 return。

做了哪些实验?RT-1 、simulated picking task、real robot。最多使用的轨迹数量达到 300k。
Offline Actor-Critic Reinforcement Learning Scales to Large Models
paper:https://arxiv.org/pdf/2402.05546
一句话概括?设计了一个能从 BC 过渡到 RL 的方法,使其能同时学习到 132 个不同连续控制任务的技能。

模型结构上有什么设计?基本上算是基于 Transformer 和相应的输入输出,攒了一个 actor critic 结构。
如何实现 BC 到 RL 的过渡?把问题建模成用 BC 数据正则化的 actor-critic 算法,这样调整正则化参数就可以实现两者的过渡了。
在什么上做实验?Gato data、RoboCat data、Insertion task、CHEF data,包括模拟和真实数据。
实验中的亮点?做了一些关于 scaling law 的实验,说明训练量、参数量对于性能的影响。
GeRM: A Generalist Robotic Model with Mixture-of-experts for Quadruped Robot
paper:https://arxiv.org/pdf/2403.13358
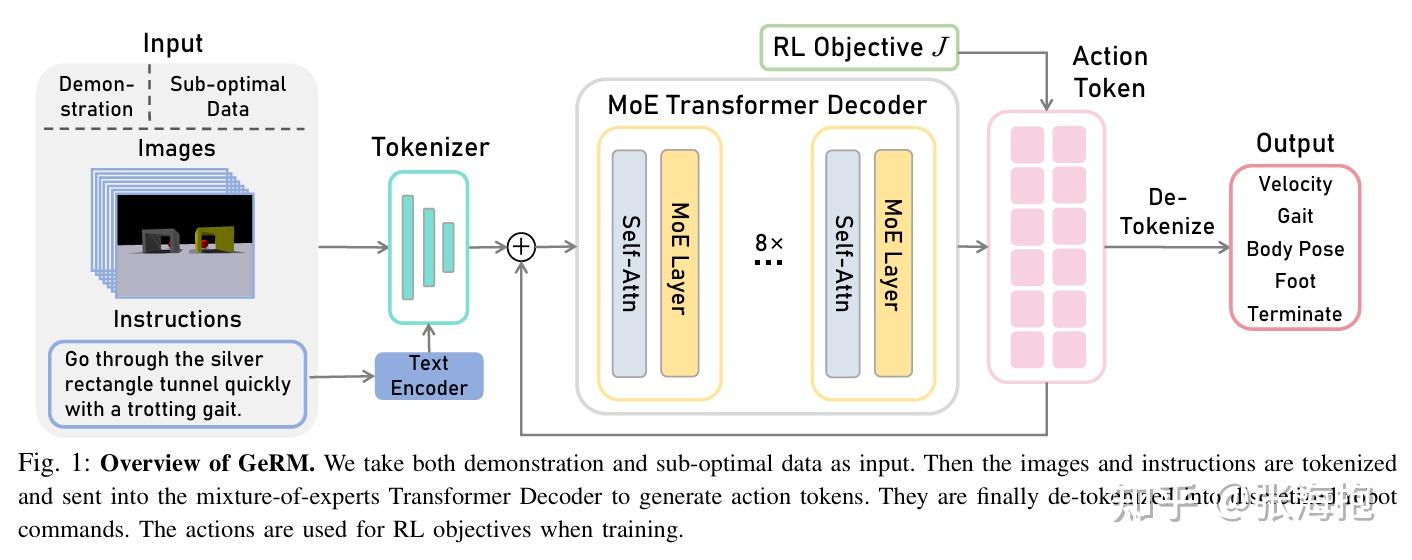
一句话概括?为了提升 muti-task model (generalist)的性能,这里做了两个改进:
- 1)不仅使用 expert demonstration 也用了一些 sub-optimal data,从而希望能做的比 expert 更好;
- 2)使用了 MoE 的结果,不仅能提升模型容量,而且还能够推理学习地更快。
Sub-optimal 的数据是如何收集的?用 BC 训练得到一个基础模型,然后用这个模型在模拟环境中 rollout 采集数据。
奖励函数如何设置?demo 的数据奖励函数全是 1,sub-optimal 的数据奖励函数全是 0。这样的奖励函数设置是粗糙了一些,所以最后训练中,sub-optimal 数据的比例也不能调的太高。
在什么上实验?主要关注四足机器人,在 5 大类任务、99 个子任务上训练,demo 轨迹 8.6k,sub-optimal 轨迹 2.8k。都是模拟环境上的实验。
MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
paper:https://arxiv.org/pdf/2503.08007
一句话概括?这篇文章和上一篇实现的目标类似,不过这里的目标是学一个 VLA 模型(输入动作),但是也希望通过 Q learning 来利用自己搜集的非最优的数据。那 Q function 怎么来呢?这里直接定义 。
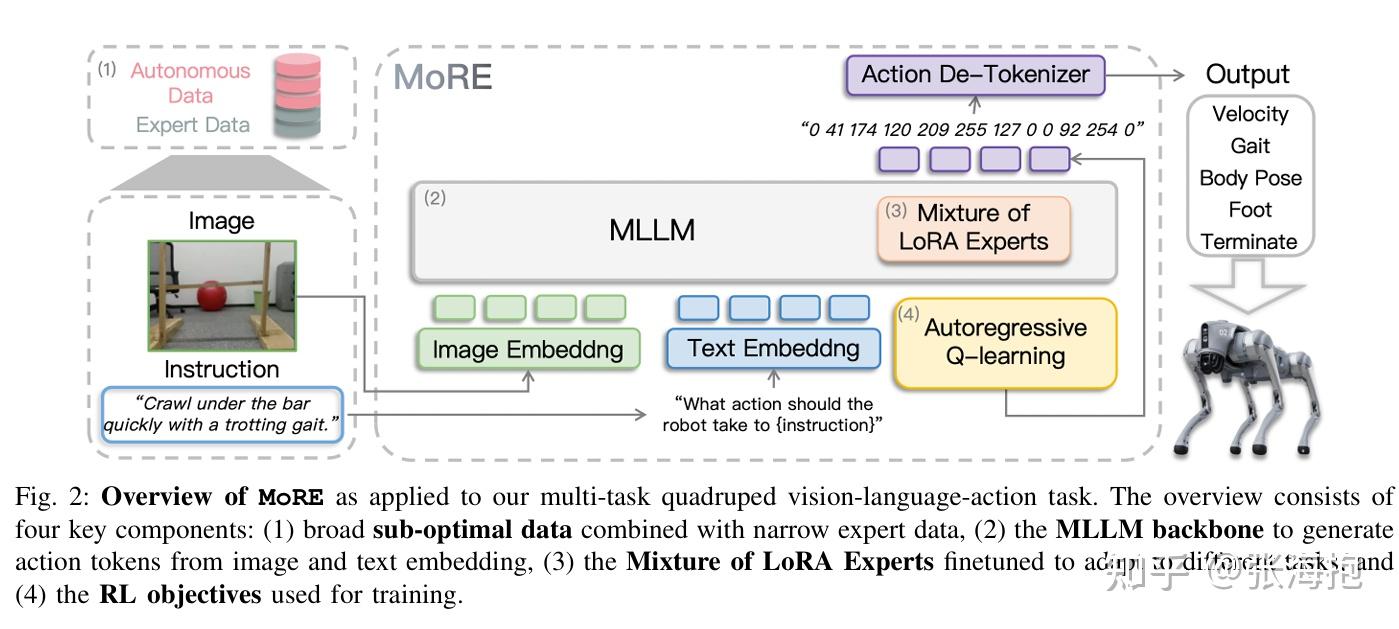
网络结构上有什么特色?用了 LoRA。
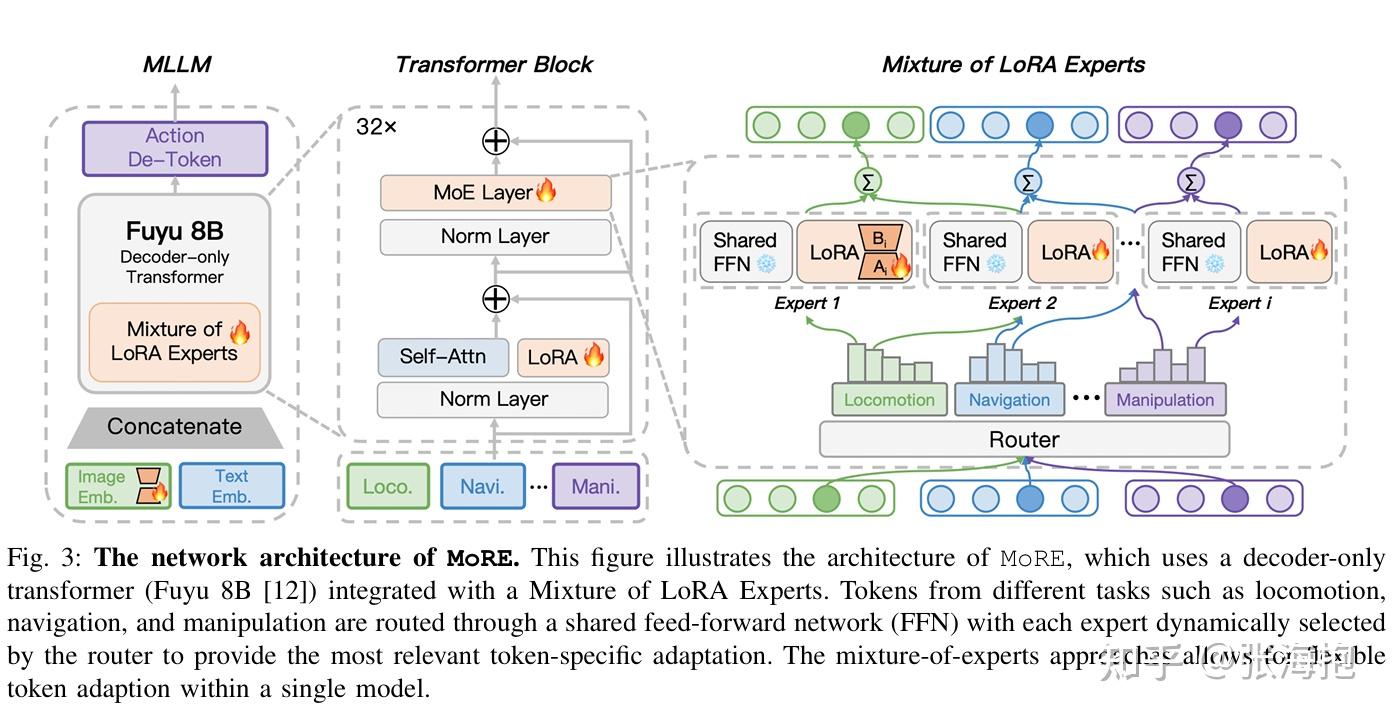
在什么上面实验呢?在四足机器人上实验,测试了难度不同的 6 个任务。
ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning
Paper: https://arxiv.org/pdf/2505.07395
一句话概括?从一个类似 decision transformer 的结构出发,提出了一个制造 dense reward 的方案,从而提升模型效果。
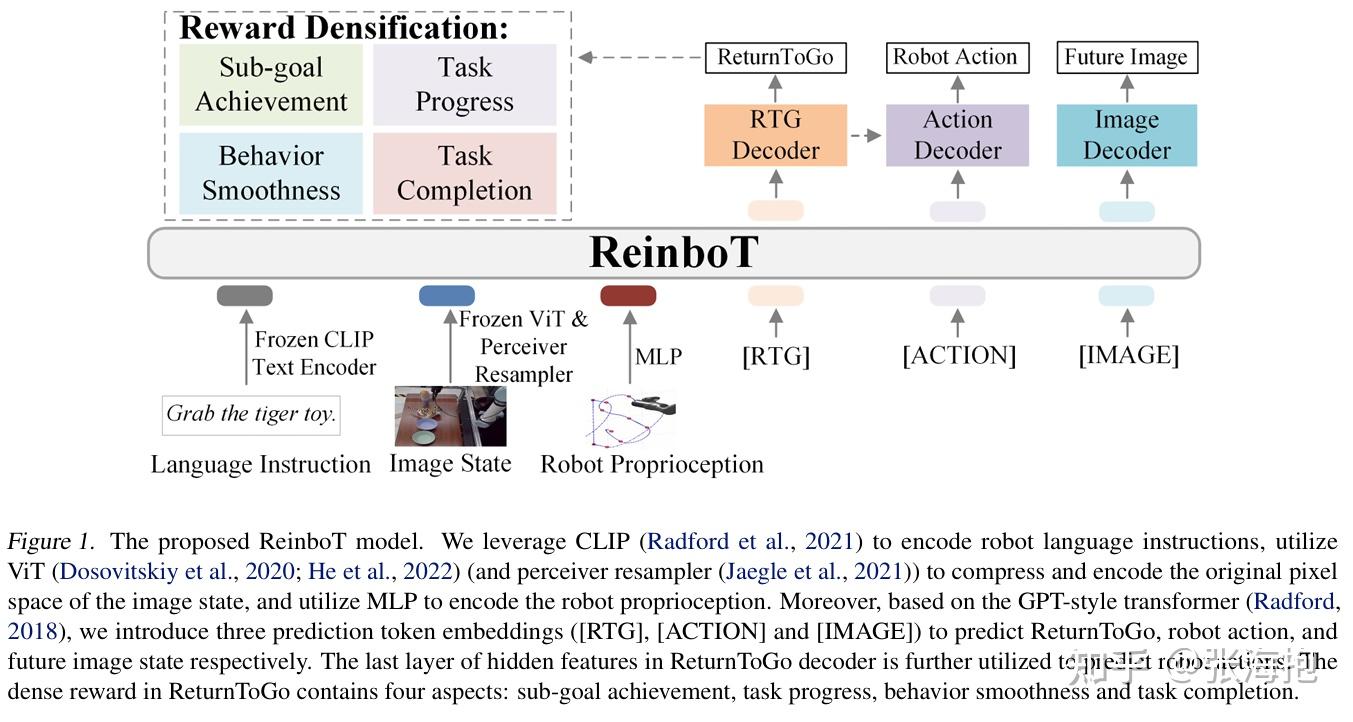
如何把奖励函数变密集?自定义了一些比较普适的奖励函数,包括 sub-goal achievement (其中 s 是本体状态,o 是图像状态,SSIM 和 ORB 都是不同的测量图像相似性的方法)

task progress(其中分子代表目前完成任务的阶段,分母是总阶段数目)
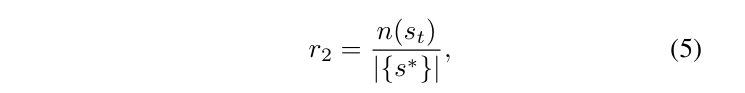
behavior smoothness(分布是“速度、加速度、一阶差分、二阶差分”的平方)
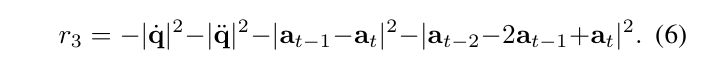
task completion(就是普通的系数奖励)
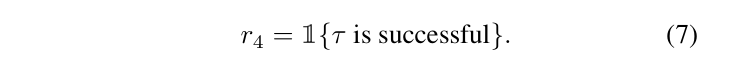
二、VLA + Online RL + simulated environment
Interactive Post-Training for Vision-Language-Action Models
paper:https://arxiv.org/pdf/2505.17016
一句话概括?对于预训练好的 VLA 模型,仅基于稀疏的奖励和与环境的交互,训练 RL 使模型执行成功率提高。
在什么上实验?下图中已经标注出来了。
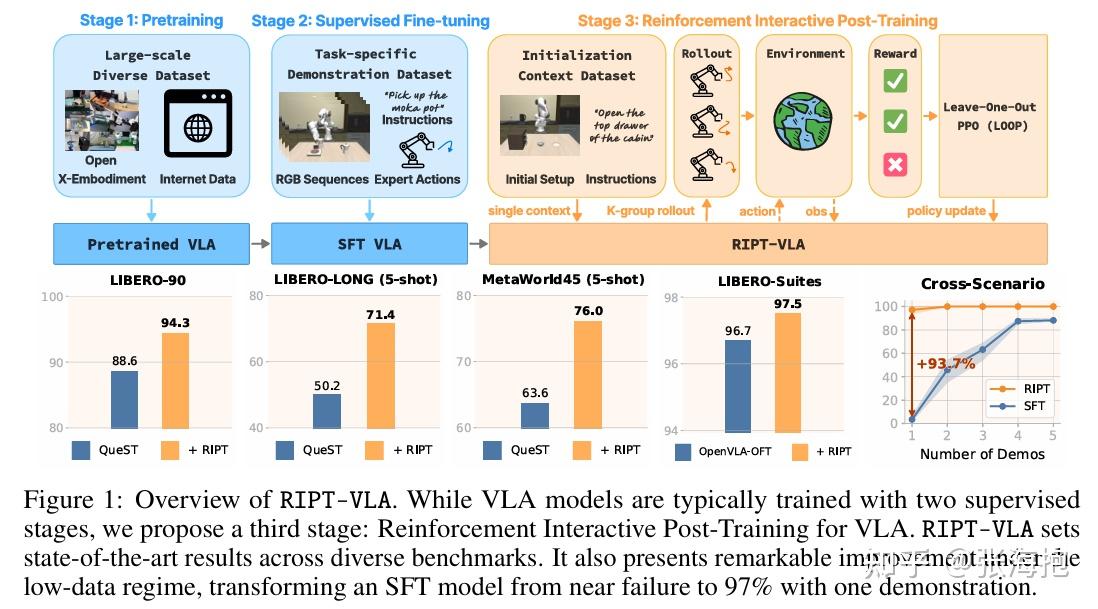
RL 训练上有什么特殊之处?在 PPO 的基础上,为了省一个 critic network,使用 leave-one-out(LOO)来估计 advantage。
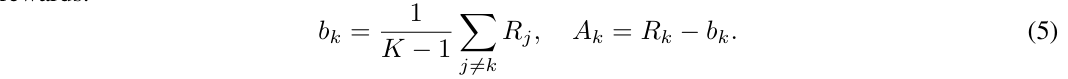
对于每一个 rollout 起点,都采样 K 条轨迹,但是如果这些轨迹最后都得到了同样的奖励,就说明这个起点并不好,需要重新采数据。

在 VLA 上做 RL 训练有什么困难?
- 1)奖励函数稀疏;
- 2)multi-task 混在一起对模型容量压力比较大。
试验了什么样的模型结构?带预训练的 OpenVLA 和不带预训练的 QueST。
局限?这里需要从同一个 context 出发反复采样,在 real robot 上没法这样操作。
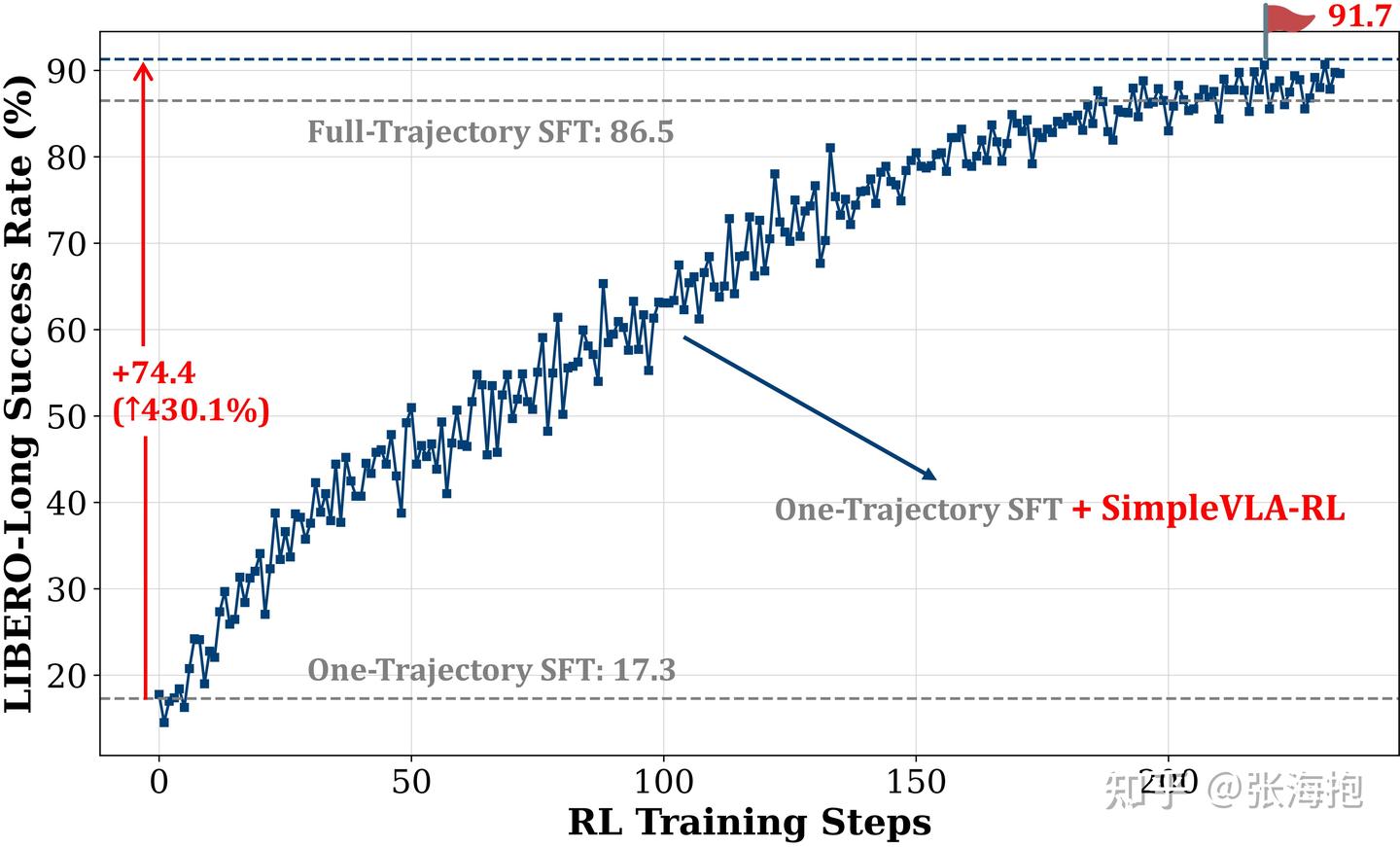
Simple VLA-RL: Online RL with Simple Reward Enables Training VLA Models with Only One Trajectory
Paper:https://arxiv.org/abs/2509.09674
Github: https://github.com/PRIME-RL/SimpleVLA-RL
一句话概括?这里只需要用 1 traj/task 做 SFT,然后接下来就可以跑起来基于系数奖励的 online RL(PPO)。

实验任务?LIBERO spatial、object、goal、long
实验设定?OpenVLA-OFT + VERL
实验效果如何?图示的效果看起来挺不错的。
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
paper:https://arxiv.org/pdf/2505.18719
一句话概括?考虑对于预训练好的 VLA 模型做 RL 训练,把机器人的轨迹当做多模态多轮对话,由此借用 LLM 上的模式来训练 —— 训练 process reward model (PRM)并进行 PPO 训练。
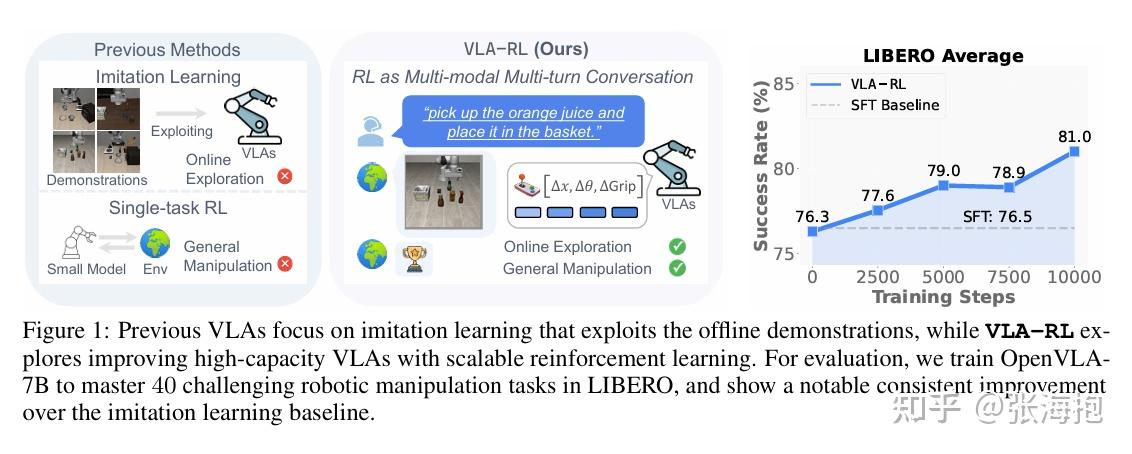
文章中强调的把机器人轨迹当做多模态多轮对话,到底反应在算法上是什么?似乎就是 auto-regressive 的 PPO 训练,外加一个 PRM 作为稀疏奖励函数的补充。
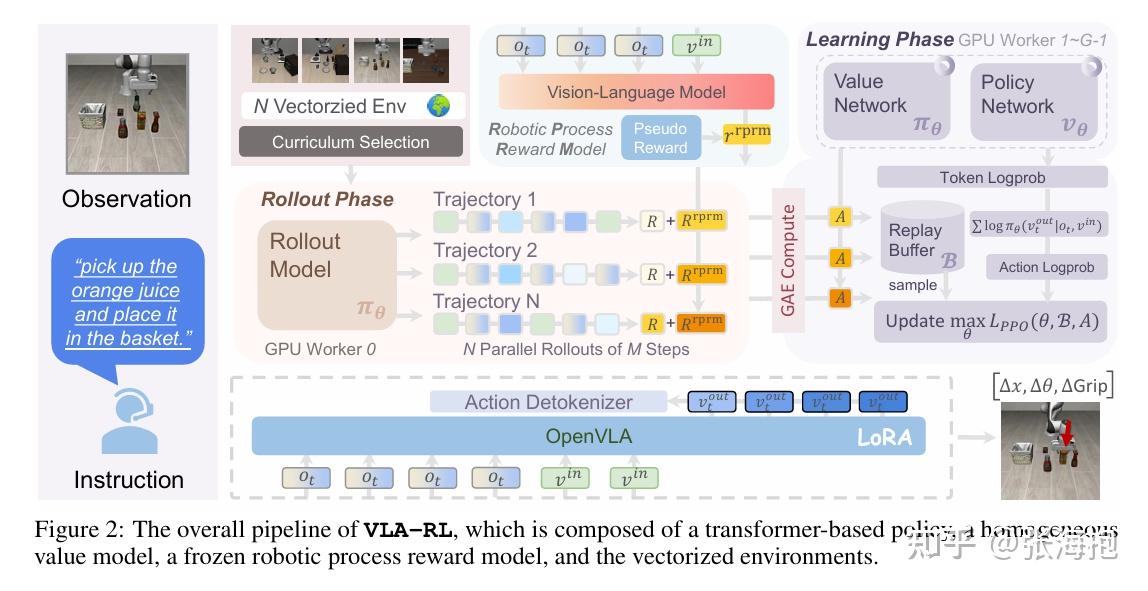
PRM 究竟是如何训练的?训练目标是按照规则标注出来的一些关键分割和关键帧,分割按照夹爪的开合变化来划分,关键帧按照机械臂的静止状态来划分。
有一些什么样的 RL 训练技巧?这些值得学习。

实验环境?Libero
RFTF: Reinforcement Fine-tuning for Embodied Agents with Temporal Feedback
Paper: https://arxiv.org/pdf/2505.19767
一句话概括?针对 RL 中稀疏奖励的问题,这里不依赖动作标签训练价值函数,然后用它来指导 PPO 学习。
如何训练价值函数?因为不想利用其他外部信息,所以主要利用 “demo 轨迹中越往后的状态越接近目标”来学习 value function。
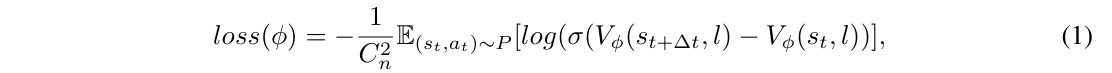
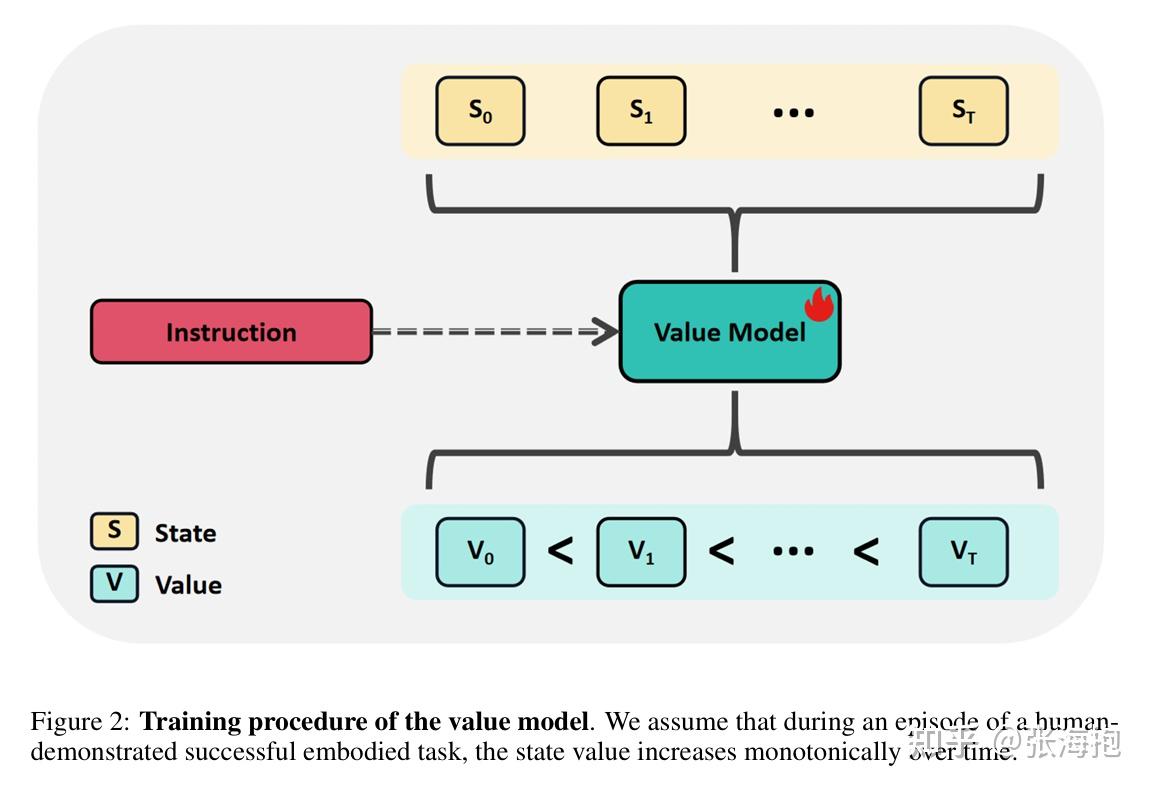
实验环境?CALVIN
TGRPO :Fine-tuning Vision-Language-Action Model via Trajectory-wise Group Relative Policy Optimization
paper:https://arxiv.org/pdf/2506.08440
一句话概括?考虑对 VLA 做 RL,这里使用了类似 GRPO 的方法来做优化。针对奖励函数稀疏的问题,这里使用 Glaude 3.7 sonnet 去分阶段产生各个任务的奖励函数。
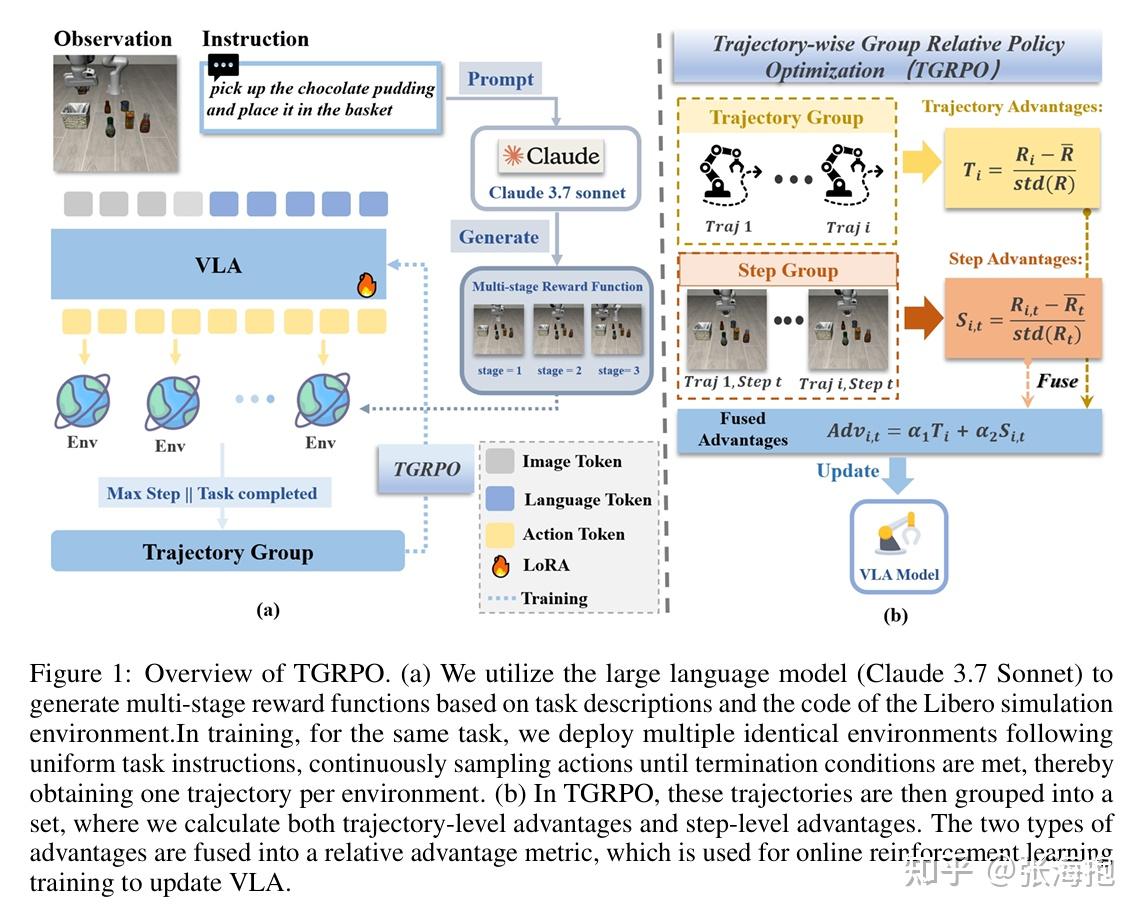
实验基准?OpenVLA + LIBERO
多说一句,这篇文章换个角度叙事会更好。其实其重点是考虑对任务分段,然后相应地计算奖励函数并且适配 GRPO 算法。但是全文没有特别强调对于任务进行分段这个很基础的出发点。
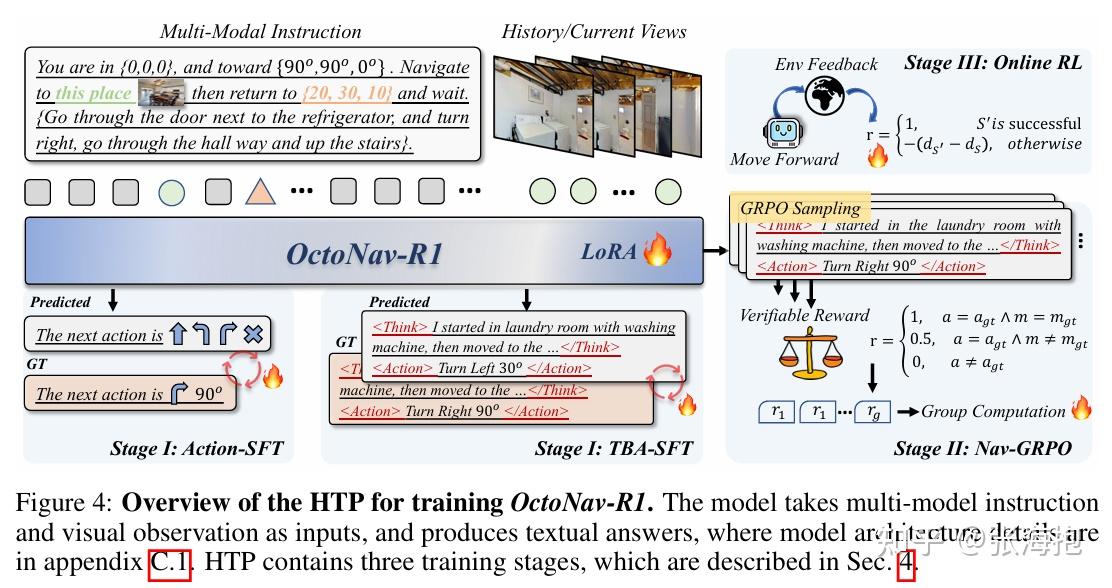
OctoNav: Towards Generalist Embodied Navigation
paper:https://arxiv.org/html/2506.09839v1
一句话概括?这篇论文本身主题是提出了一个 benchmark 和相应的 VLA 模型 OctoNav-R1。不过里面涉及到做 online RL 的部分。这篇论文里面比较好玩的是,他们引入了 thinking 的数据集,并且也对于思考过程进行了一些训练。

RL 的部分有一些什么样的技术嘛?主要用 GRPO 。另外,在稀疏奖励之外,还有一个针对距离的惩罚项,可以稍微缓解一下奖励稀疏。

FuRL: Visual-Language Models as Fuzzy Rewards for Reinforcement Learning
paper:https://arxiv.org/pdf/2406.00645
一句话概括?针对 sparse reward 的问题,这里考虑用 VLM 来提供奖励,用于增强 SAC/DrQ 的训练。
具体怎么用 VLM 产生 reward 呢?文章先考虑了一个简单的做法:在稀疏奖励之外加入了 VLM 产生的奖励,VLM 的奖励就是 CLIP 中当前图像的表示和语言指令的表示的 cosine similarity。

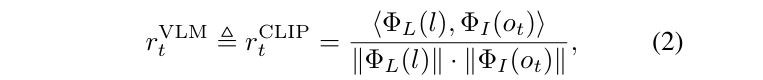
但是这样的做法达不到预期效果:
所以考虑加两个可学习的线性层 f_{W_L}4 和 f_{W_I}$ ,把奖励函数变成这样:
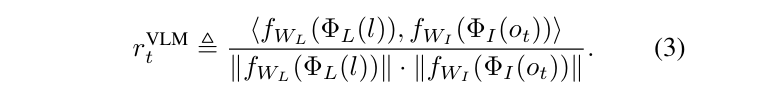
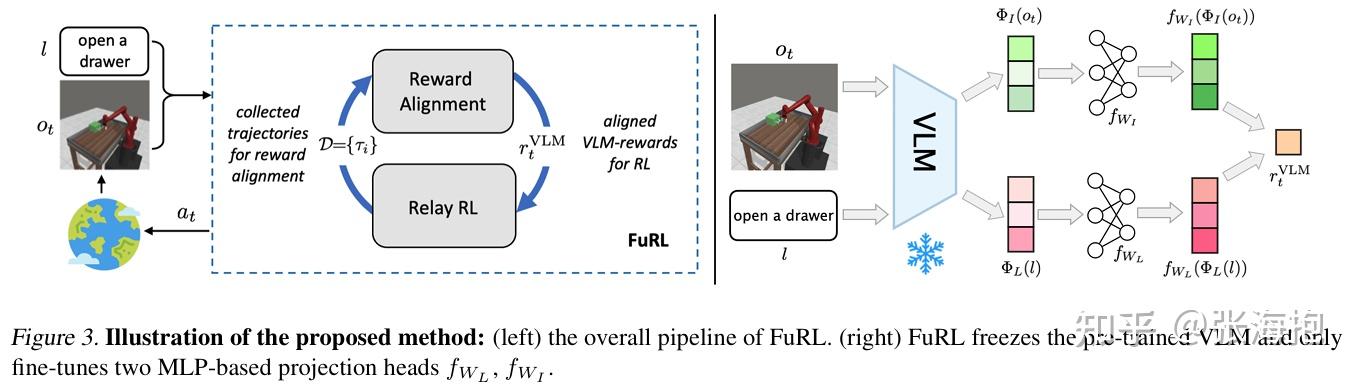
那这两个线性层怎么学呢?用下面这三种 loss 来训练。
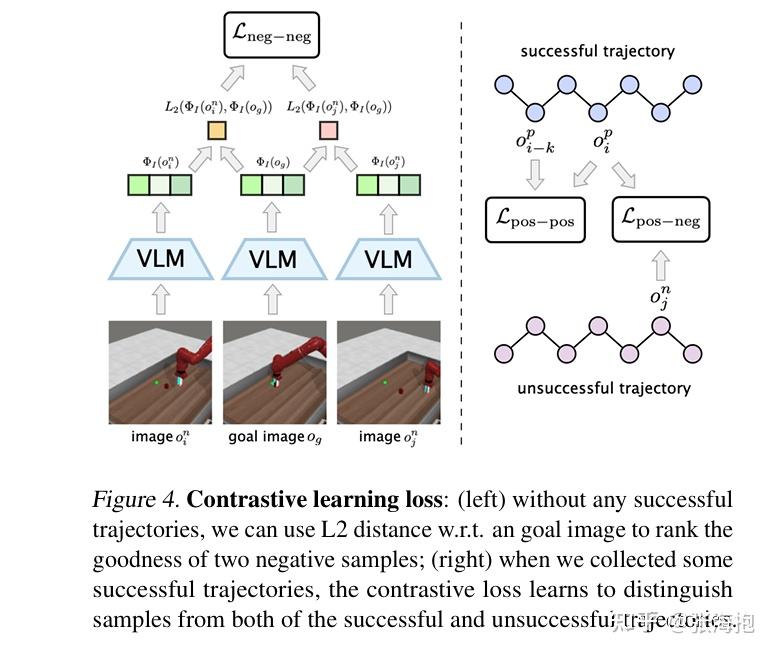
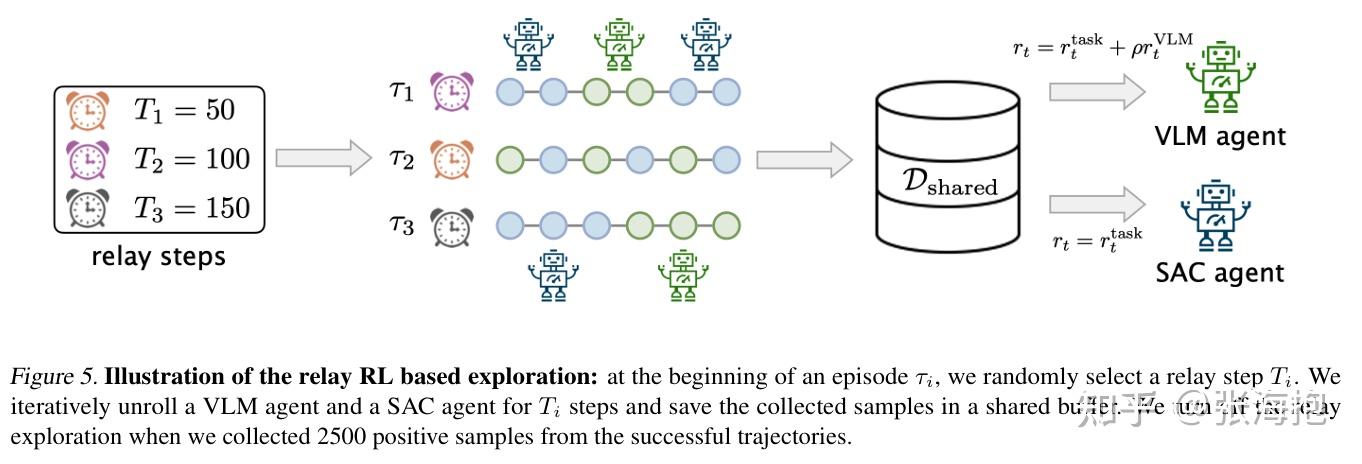
RL 的训练部分也是用了 relay RL 的算法,为了避免用不靠谱的 VLM 的奖励函数学习的 \pi_{VLM} 卡到 local minima,所以还要在采样和学习的时候都维护一个只用真实奖励学习的 \pi_{SAC} 。
在什么任务上做实验?Meta-World MT10

Refined Policy Distillation: From VLA Generalists to RL Expert
paper:https://arxiv.org/pdf/2503.05833
一句话概括?与其在 VLA 上做 RL,不如在 VLA 的引导下重新训一个 RL student 来做强化学习,这样效率更高。我猜新的 RL student 应该结构更小一些,但文中没有找到相关描述。
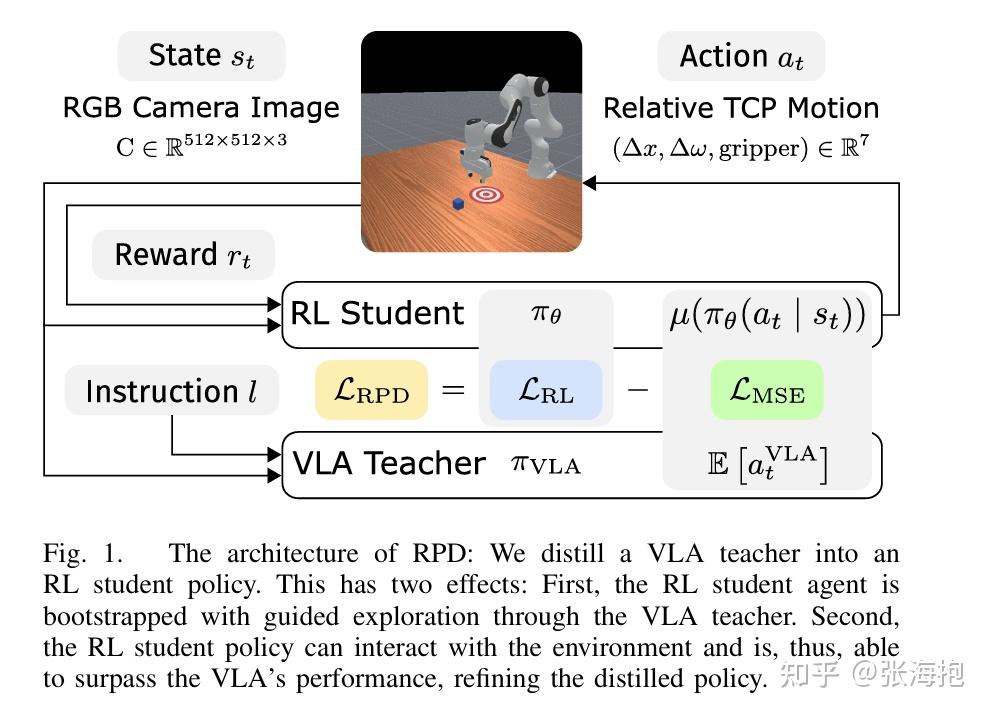
实验设定?选用了 OpenVLA 和 Octo 做 VLA 模型,选用了 Maniskill 3 中的若干任务来测试。
What Can RL Bring to VLA Generalization? An Empirical Study
paper:https://arxiv.org/abs/2505.19789
一句话概括?相比于 RL 在 execution 方面对于 VLA 模型的贡献最大,其次是在 semantics 的方面,在 vision 上 RL 的帮助不大。

什么样的 RL 算法对 VLA 更有帮助?这里发现还是 PPO 效果更好。不过作者告诉我可能 GRPO 也能调好,不过由于其涉及到分组的策略,因此较为复杂。
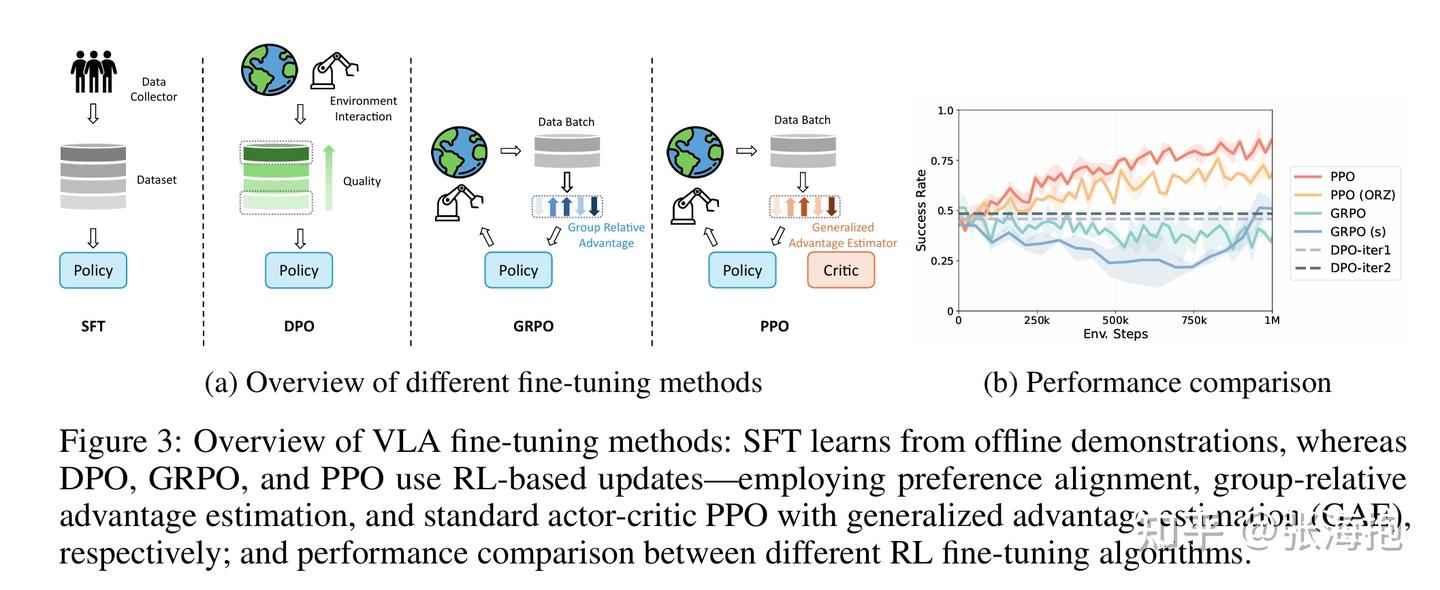
还有什么有意思的结论吗?在观察了为什么 RL 对于 execution 的帮助比较大,因为 RL 对于整个状态空间的探索比较充分。
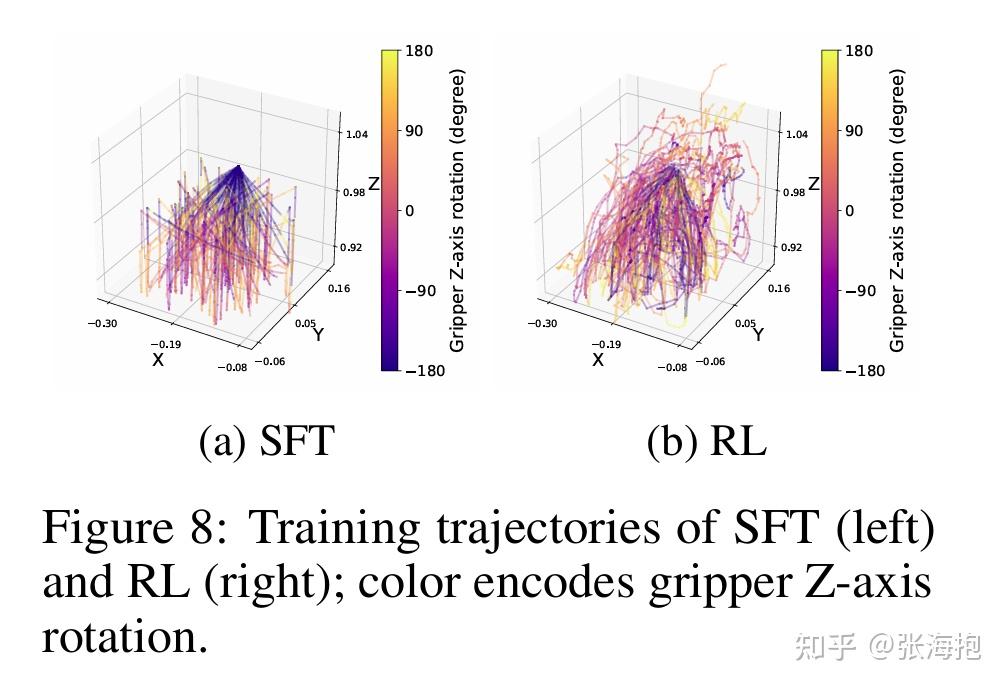
三、VLA + Online RL + real robot
SERL: A Software Suite for Sample-Efficient Robotic Reinforcement LearningSERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning
paper:arxiv.org/pdf/2401.16013
一句话概括?提供了一个完整开源的真机强化学习方案。
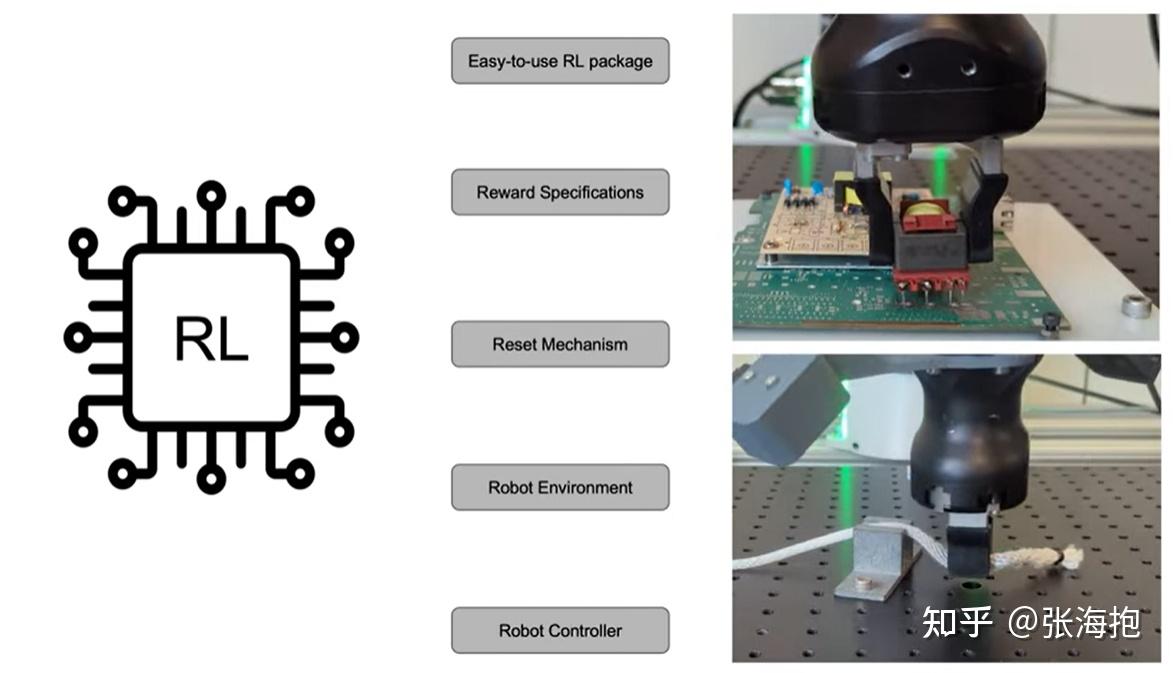
有写什么特色?
能基于 offline data 和 online data 进行强化学习。

支持多种奖励函数方案,其中 VICE 可以避免 reward hacking。
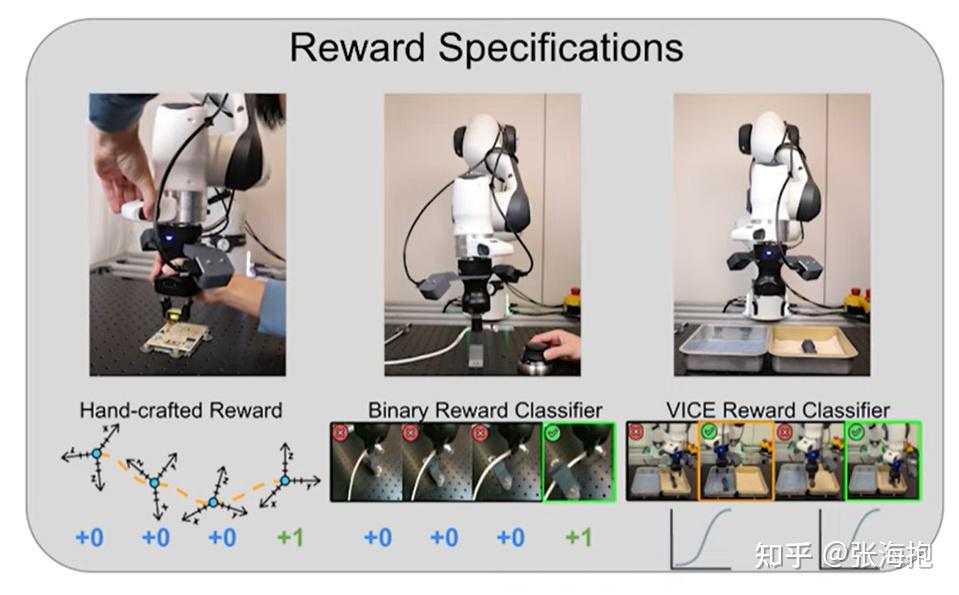
任务设计上可以交替训练 forward task 和 backward task(返回初始状态),从而避免人类做 resetting。
模型训练上也支持异步训练。
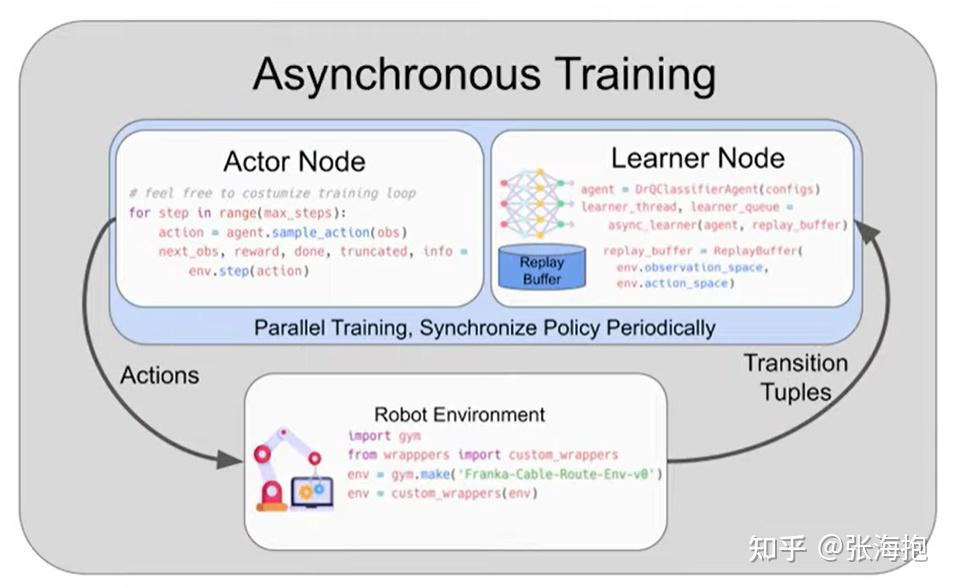
对于 Franka 机器人提供了 Gym 接口。

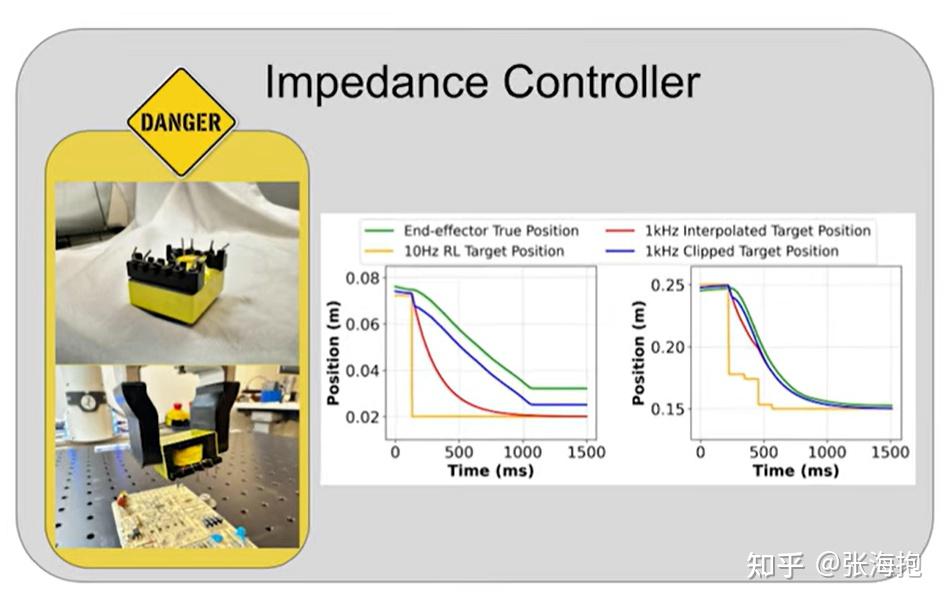
文章中还提供了底层的控制器代码,底层控制器代码是很重要的。比如控制的六维力通常被设置成
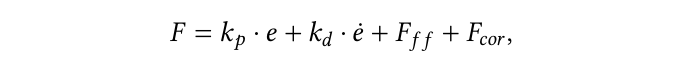
其中 e 表示当前位姿和目标位姿的差值。第一项是主要的控制项,第二项为了抑制震荡,后面还有前馈补偿、动态补偿、离心力补偿等。在此基础上,文章还对于误差 e 做了截断,可以有效防止任务执行的时候损坏道具。比如下图中左边的曲线就展示了如果某个位置被挡住的话,就不会完全执行。
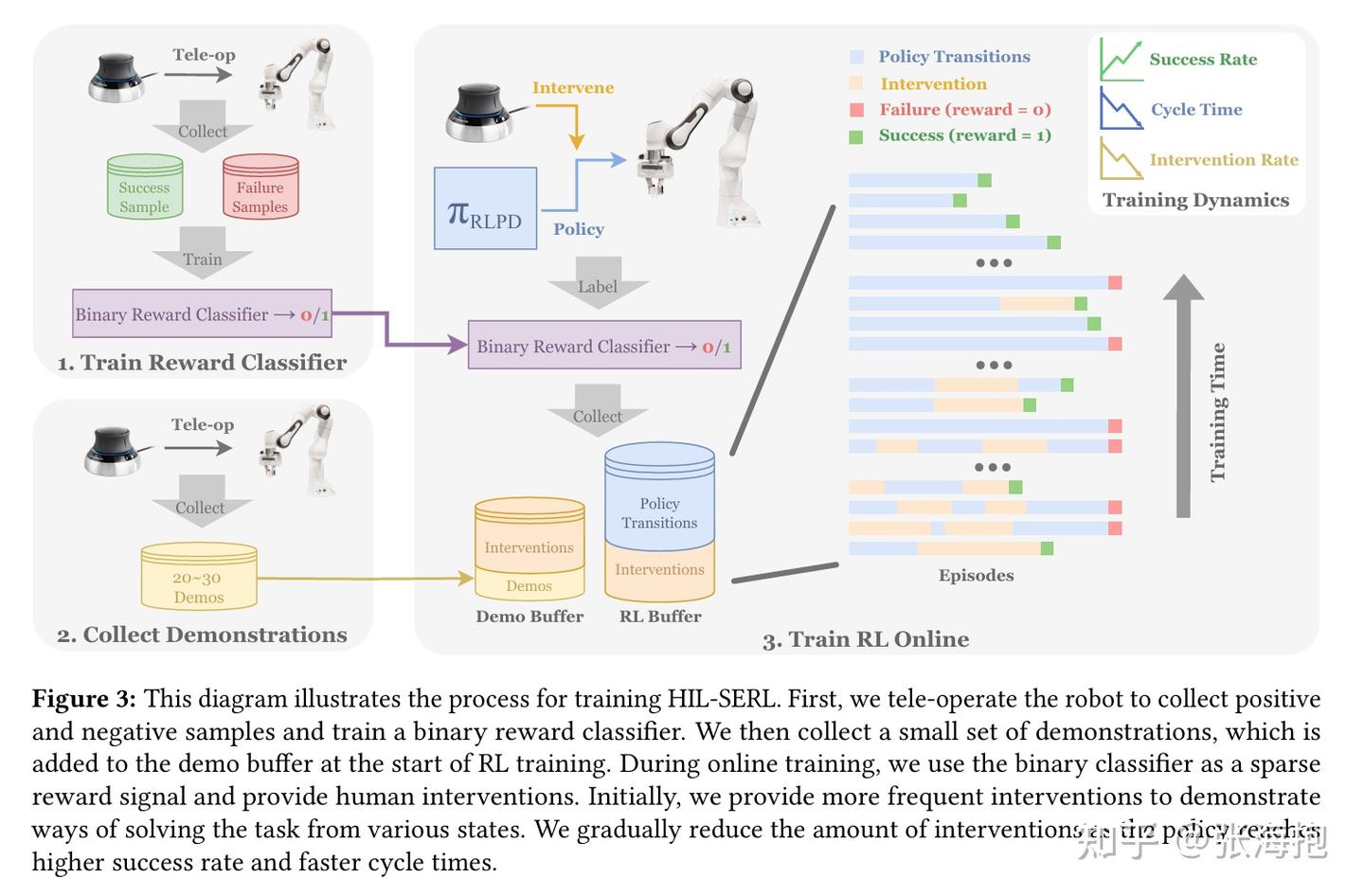
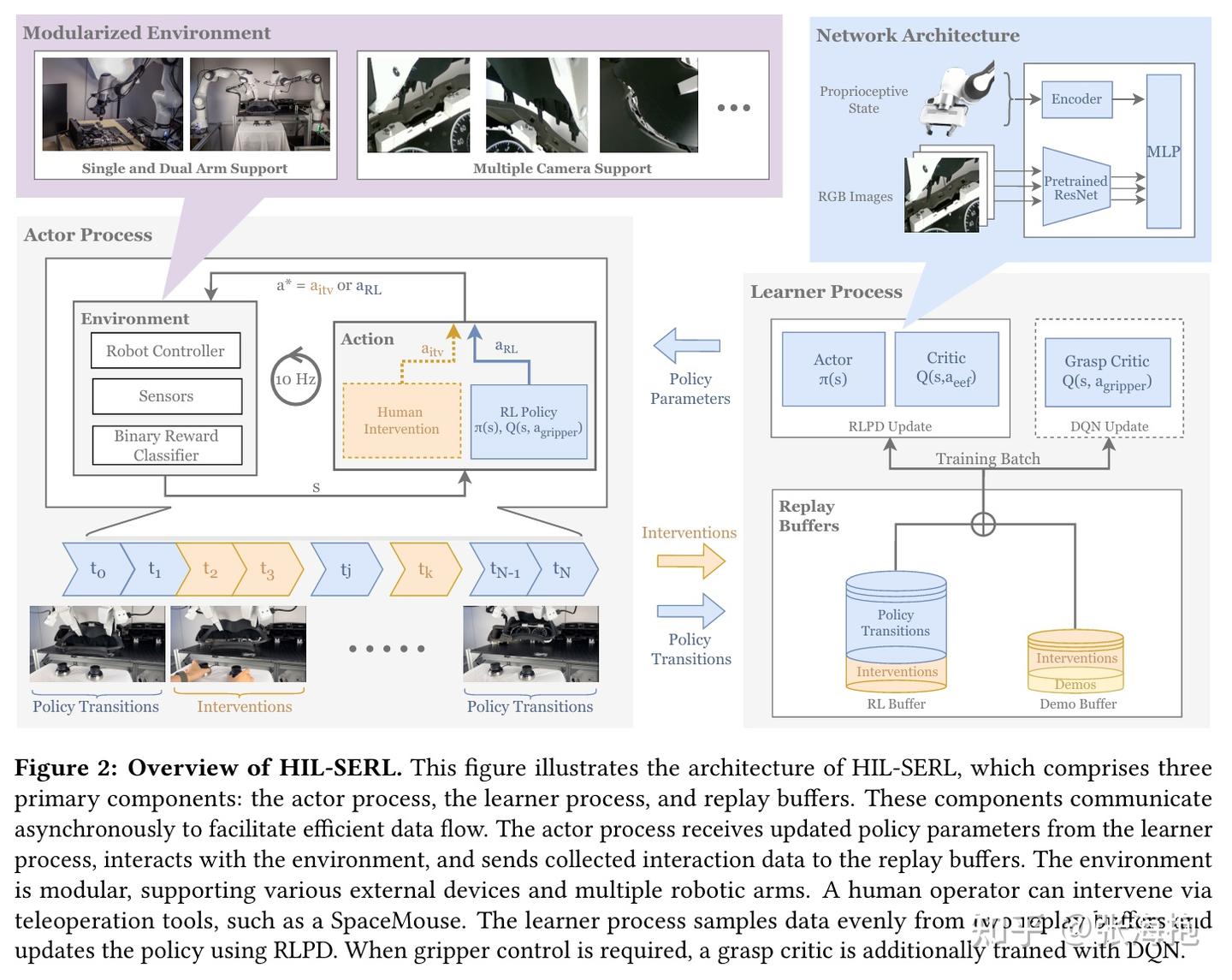
HIL-SERL: Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning
paper: https://arxiv.org/pdf/2410.21845
一句话概括?在 SERL 的基础上,设计了 human-in-the-loop 的方案,人类可以在轨迹中途接管 RL 探索,产生的轨迹一样可以记录到强化学习的 buffer 里面帮助 RL 学习。
有什么值得注意的设计上的细节?他们单独设计了一个 grasp critic,用来对于离散的抓取动作进行打分。
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
paper:https://arxiv.org/pdf/2412.09858
一句话概括?上一篇文章研究了如何在真机上做强化学习的训练,这里就研究这些数据是不是能够进一步帮助 VLA 模型的微调。
为什么要用 RL 策略采集到的数据做 VLA 的微调?因为 RL 的数据不仅执行上比人类更优,而且能够覆盖更丰富的状态,帮助模型更全面的学习。
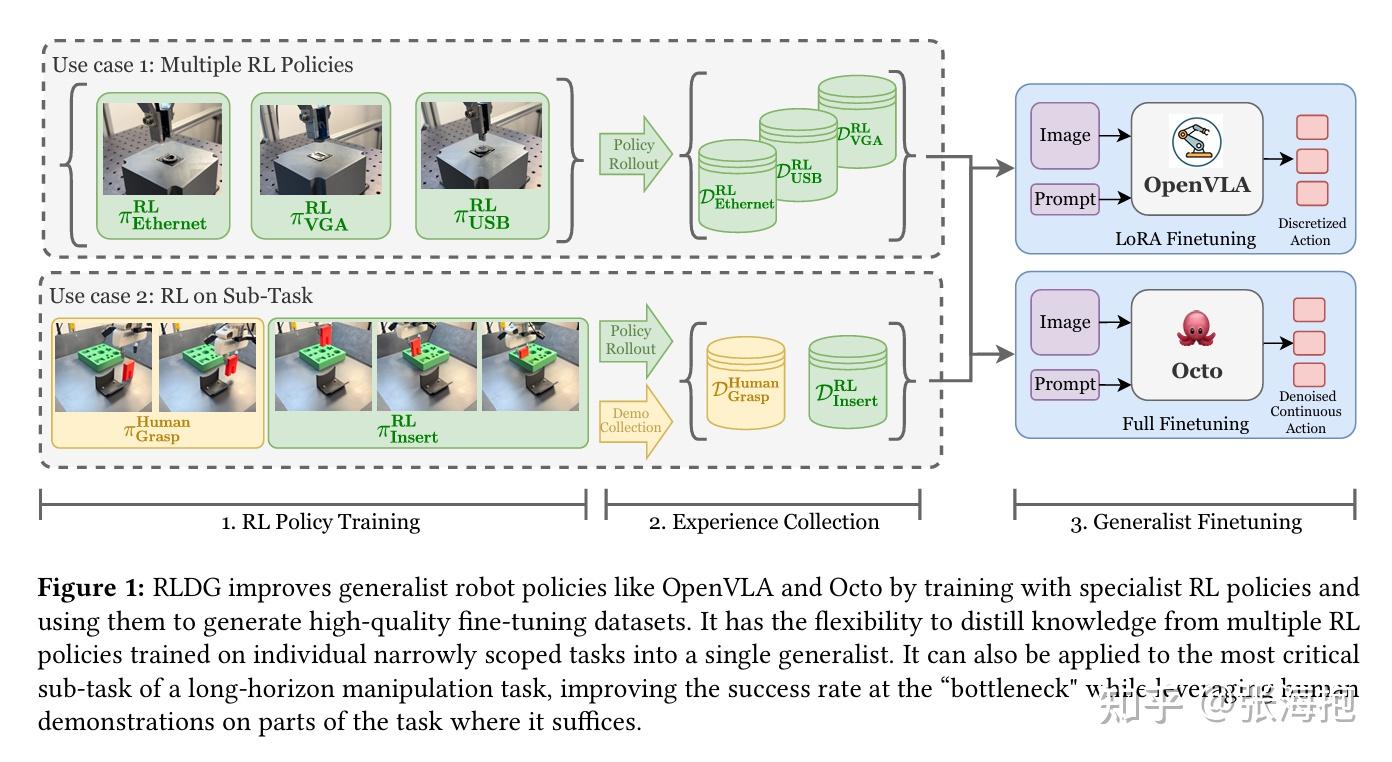
在什么任务上学习?这里考虑了如下一些真机任务

ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
paper:https://arxiv.org/pdf/2502.05450
一句话概括?从预训练好的 VLA 开始,先用 offline 数据训练,后用 offline+online 的数据进行训练,这两个阶段对于 actor 和 critic 的训练都有统一的目标。

在什么任务上实验?主要考虑一些 contact-rich tasks。

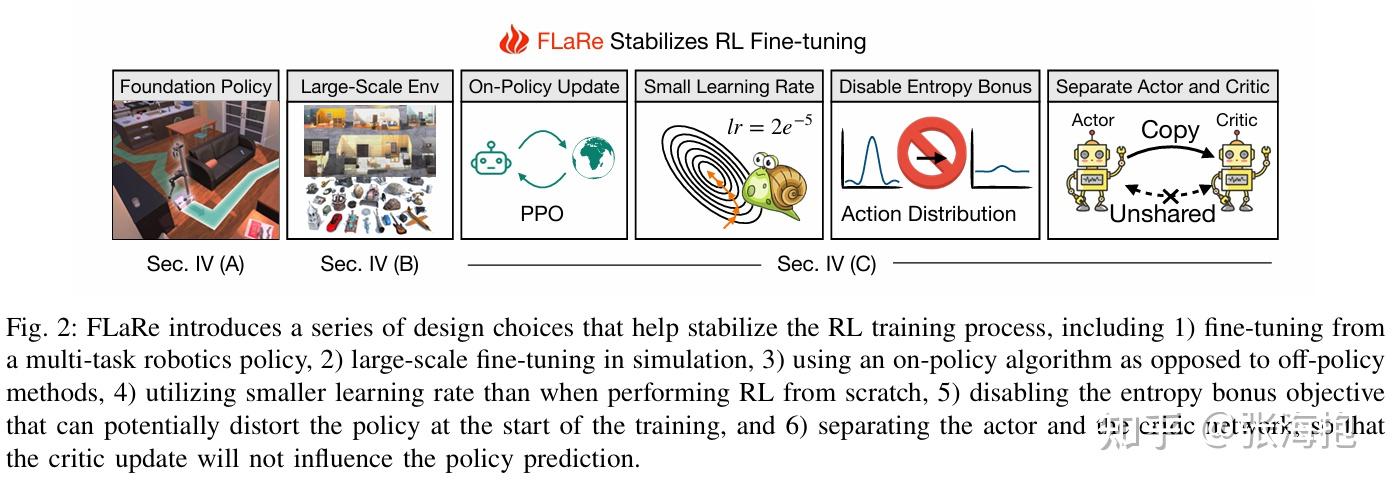
FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-Tuning
paper:https://arxiv.org/pdf/2409.16578
一句话概括?提出了在 BC pre-trained policy 上继续进行 RL fine-tuning 的方法,尝试了一些训练技术使其更加稳定。
使用了哪些技术?比 learning from scratch 小一个数量级的 learning rate、去掉了 entropy bonus、让 pre-trained network 拷贝单独两份分别用于 actor 和 critic。
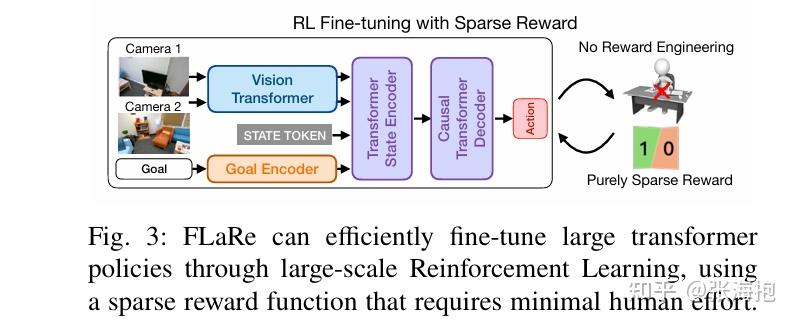
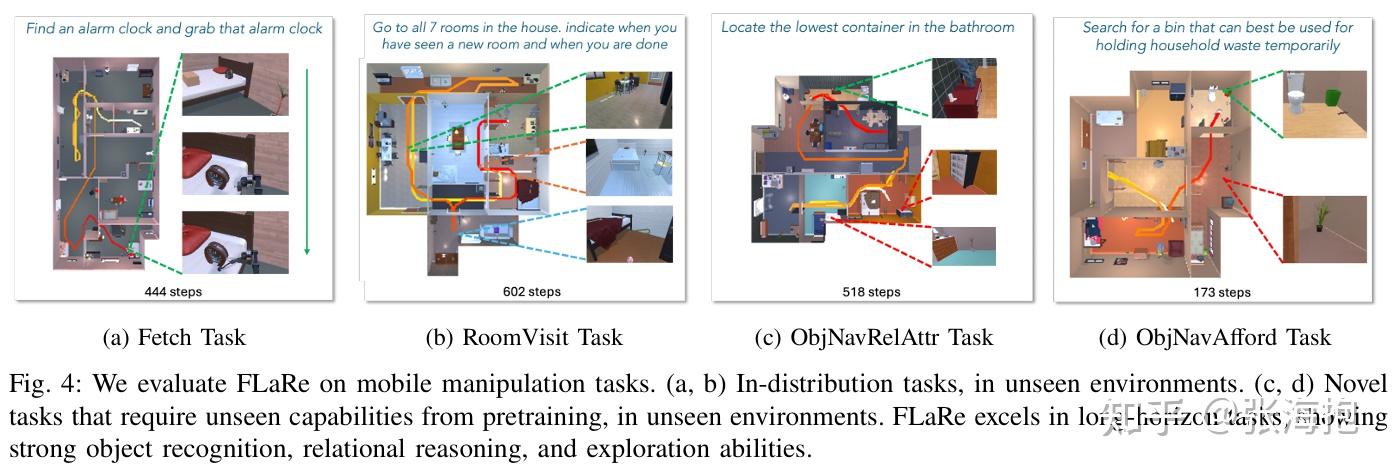
在什么上做实验?关注了一些模拟和真实的 navigation + manipulation 任务
Diffusion Policy Policy Optimization
paper:https://arxiv.org/pdf/2409.00588
一句话概括?提出了针对 diffusion-based VLA 的微调算法。
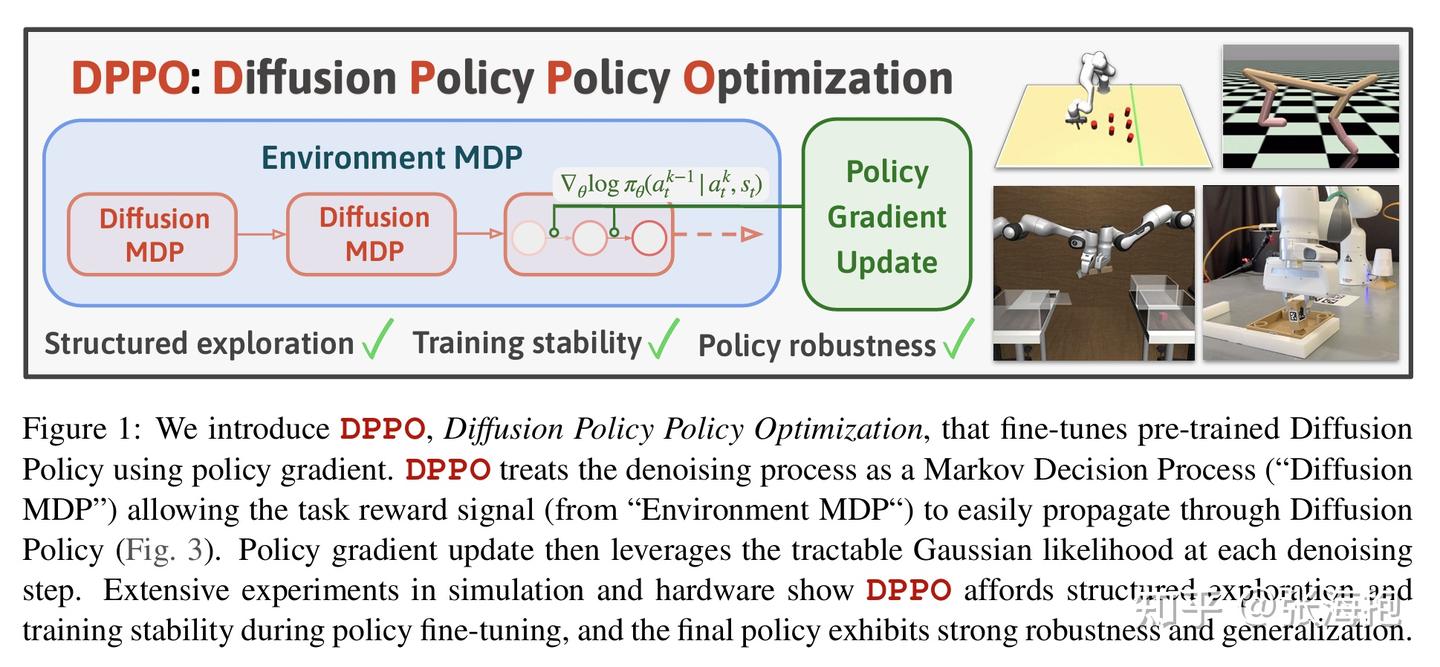
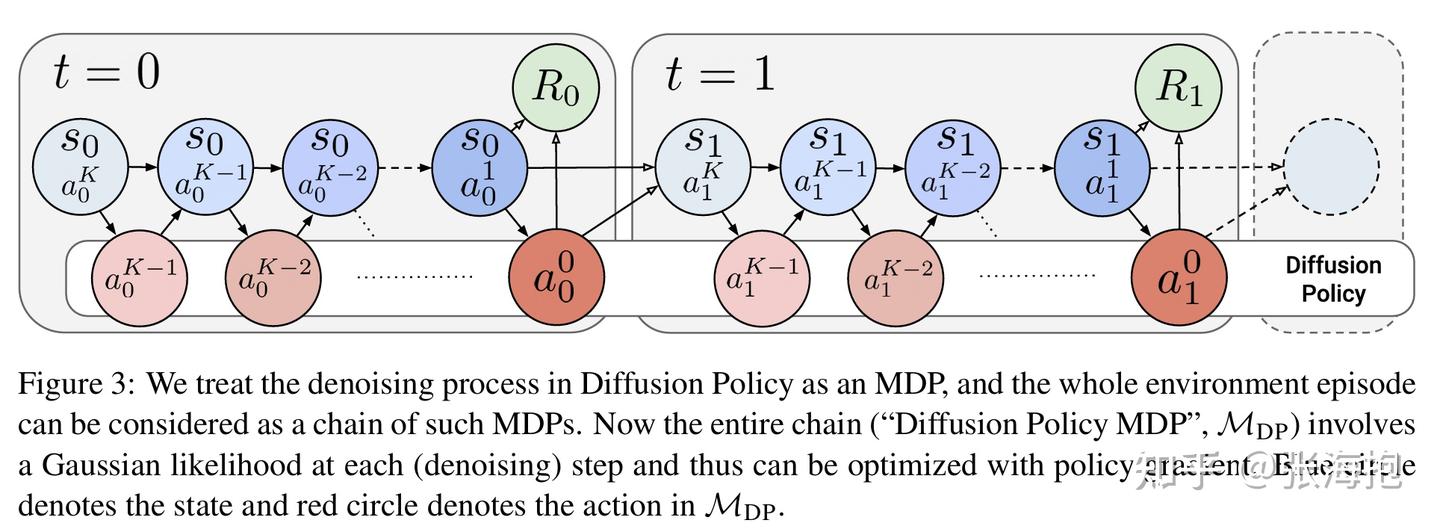
算法建模上有什么差别?从上图可以看出,建模上把每个 diffusion step 当做了 MDP 的一步,然后用 environment step 把它们串起来了,这样形成了一个 TK 步 的 MDP,其中 T 是环境的步数, K 是 diffusion 的步数。
反映到算法上有什么区别呢?首先,我们知道单步 diffusion 就是输出一个变化量加到原本高噪的变量上,即 \pi(a_t^k - a_t^{k+1}| s_t, a_t^{k+1}) ,因此我们可以把和它梯度相同的 \pi(a_t^k | s_t, a_t^{k+1}) 作为要优化的策略。文章推导出来的结果是,对于 diffusion step 中的每一步都可以应用 policy gradient,其 return 是从此以后从环境中拿到的 return。在 diffusion MDP 和 environment MDP 都奖励稀疏的情况下,return 就等于最后的 0-1 奖励外加一些衰减因子的调整。
实验环境?OpenAI Gym、Franka Kitchen、Robomimic、Furniture-Bench 学习并直接迁移到真机上
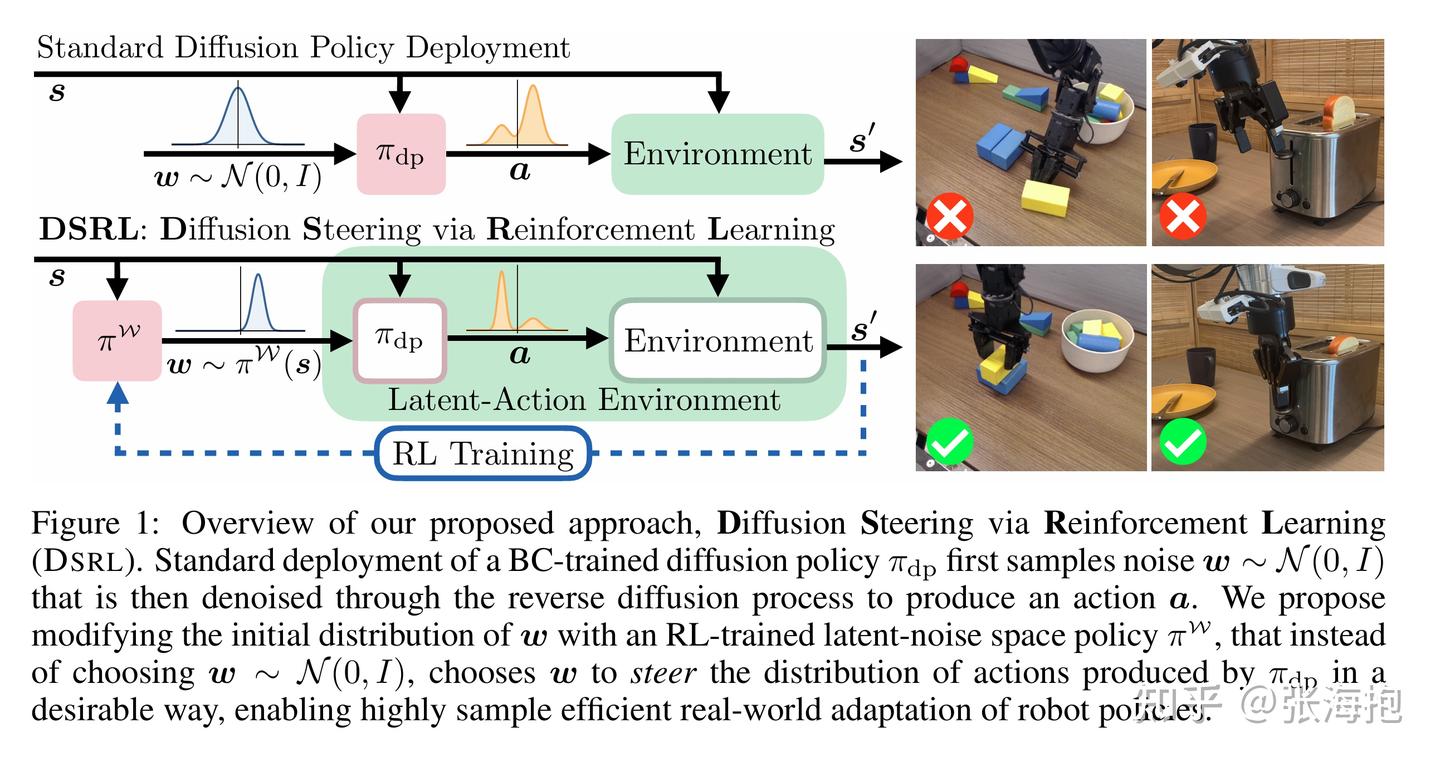
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
paper: https://arxiv.org/pdf/2506.15799
一句话概括?仍然针对 diffusion-based policy 做 RL,但是和上面文章不同的是,这里考虑固定 diffusion-based policy,而是增加一个先验分布策略,并且用 RL 去学习这个分布。
Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
paper:https://arxiv.org/pdf/2412.06685
一句话概括?由于现在具身智能里面的 VLA 模型经常用到 auto-regressive 或者 diffusion 模型,因此对于他们做强化学习需要适配专门的算法。这里希望能把强化学习算法转化为得到“优化后的动作”,然后再以来原本的 SFT 来优化相应的模型。
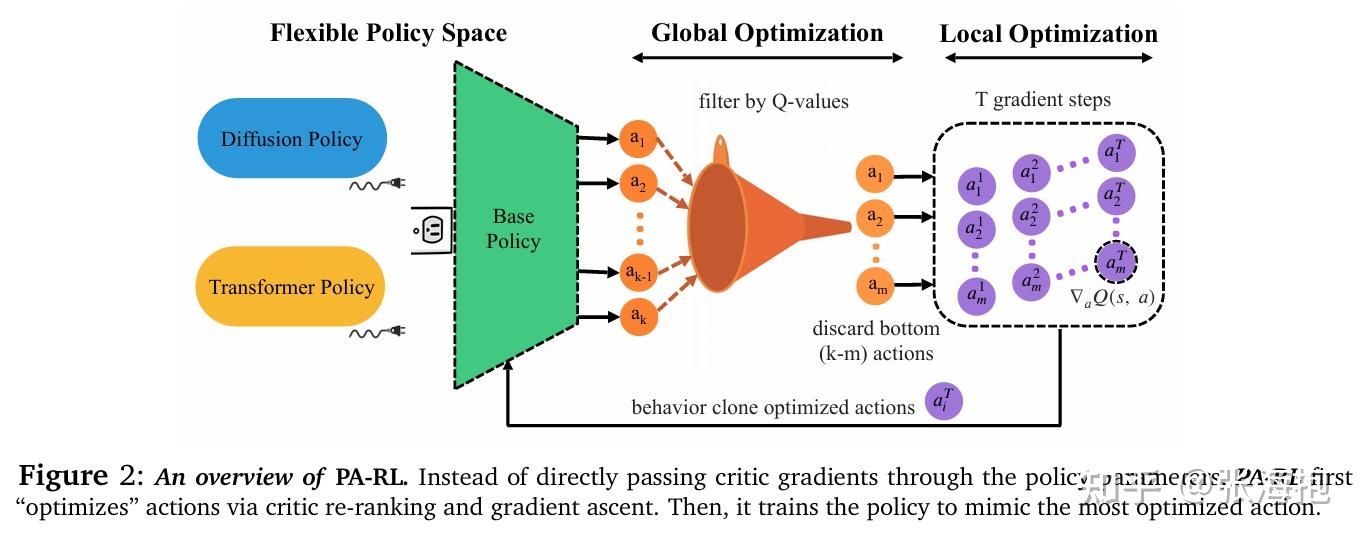
如何得到“优化后的动作”呢?首先,我们需要学习到一个 Q 函数(critic)。接下来我们可以用预训练好的 VLA 进行采样多个动作,然后只保留 Q 值最高的;然后再对于这些动作做微扰,往 Q 值提升的方向走几步。此后,就可以继续开心地用和预训练一样的 SFT 框架来优化 VLA 了。
实验环境?模拟环境包括 AntMaze、FrankaKitchen、CALVIN;真机任务是用 widowx 完成各种 pick-and-place 任务。
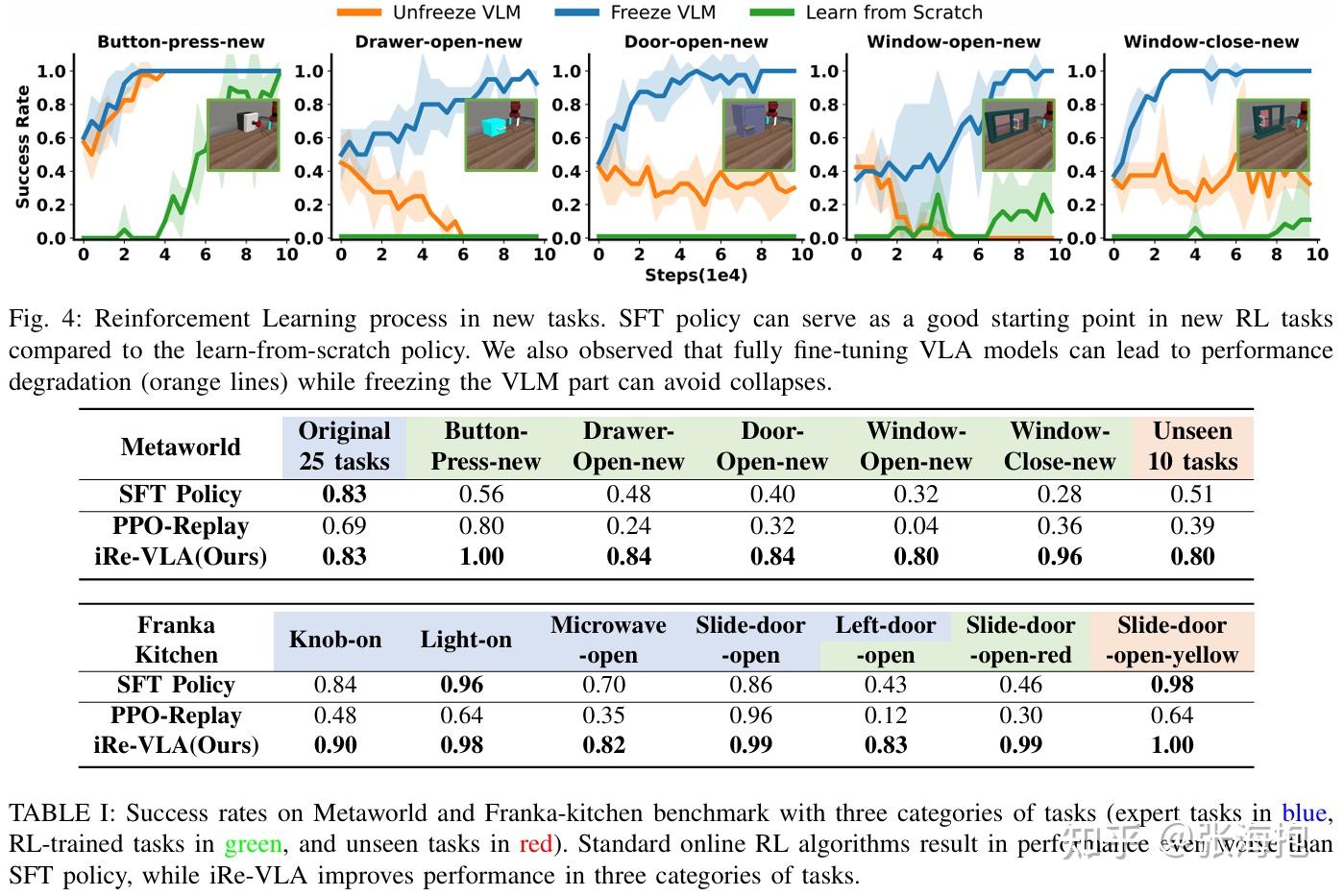
Improving Vision-Language-Action Model with Online Reinforcement Learning
Paper: https://arxiv.org/pdf/2501.16664
一句话概括?这篇文章发现如果直接在 VLA 上跑 RL 算法会不太稳定,所以提出需要交替进行 SFT 和 RL。
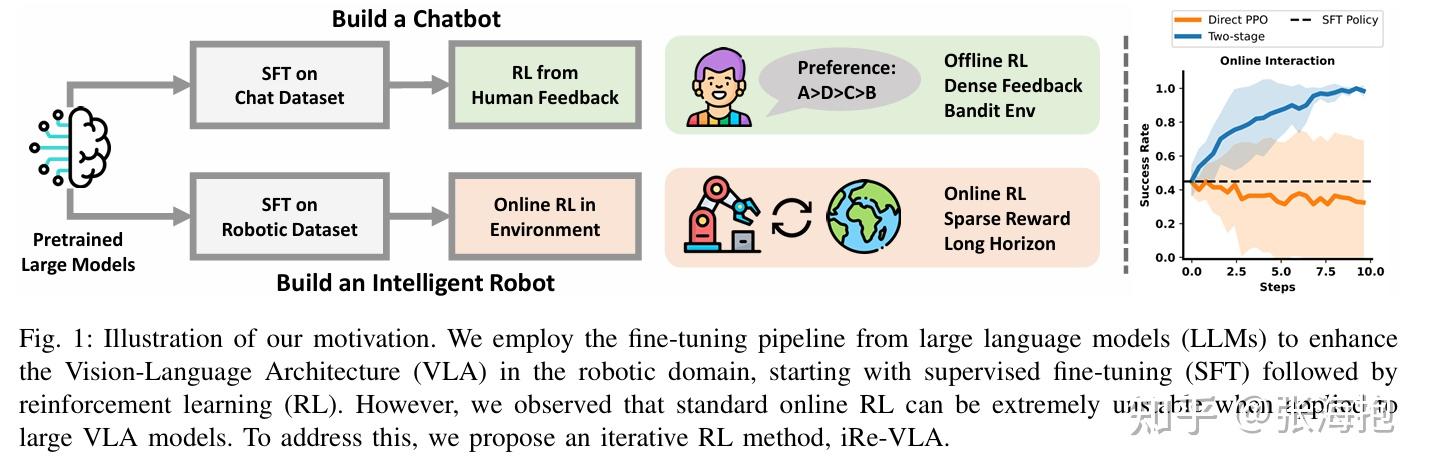
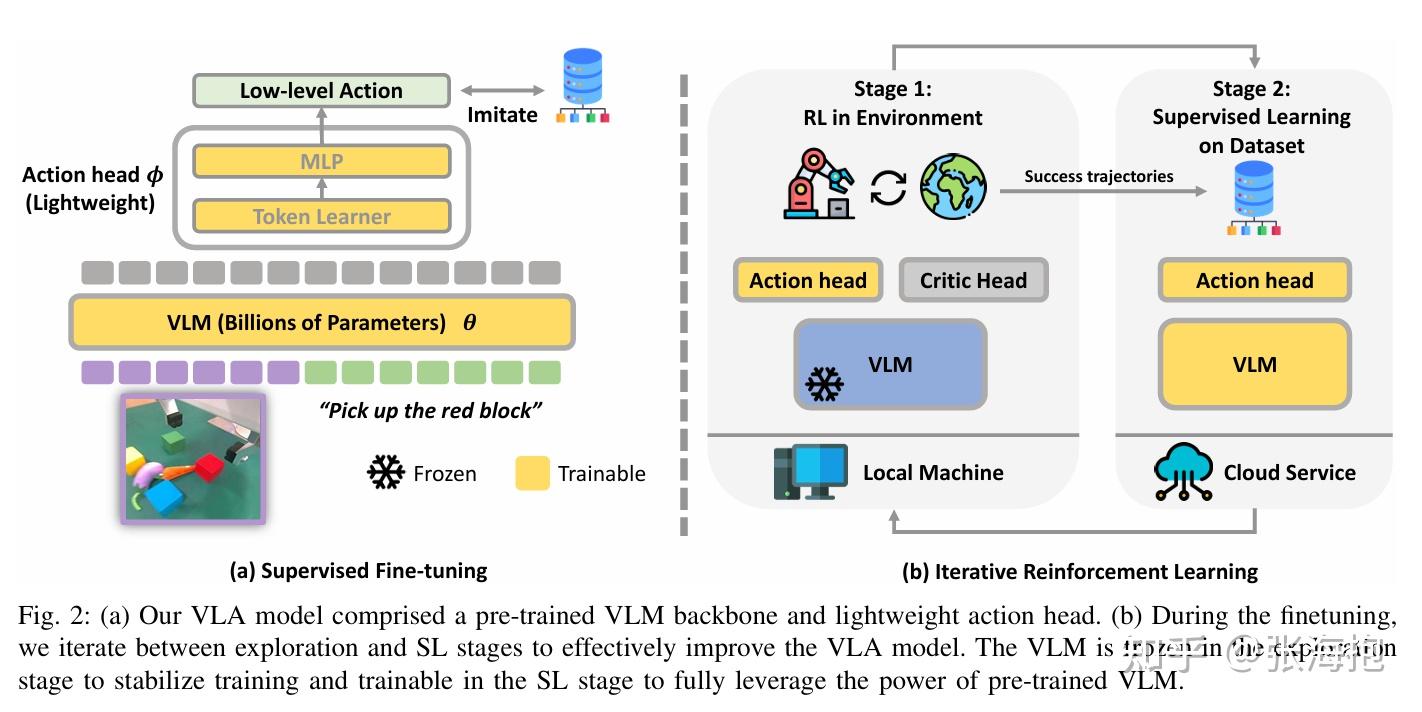
实验环境?本文的实验环境还是挺完整的,从模拟到真机。

Reinforcement Learning with Foundation Priors: Let the Embodied Agent Efficiently Learn on Its Own
paper:https://arxiv.org/pdf/2310.02635
一句话概括?如果纯学一个强化学习模型会很没有效率,这是因为不能做有效的探索,也没有很丰富的奖励反馈。这里就考虑用基础大模型来提供这些反馈。和前面介绍的 Refined Policy Distillation 有些类似。

对算法有些什么改动?主要体现在
- 1)增加了 policy regularization L_{reg} ,让 RL agent 输出的动作和一个 policy prior 的 KL 相差不大,policy prior 可以选用 code-as-policy 或者 unipi;
- 2)增加了 reward-shaping value prior M_V ,可以用 VIP ;
- 3)增加了 reward prior M_R ,可以用 GPT-4V 。

实验环境?Meta-World
四、VLA + Alignment
GRAPE: Generalizing Robot Policy Via Preference Alignment
paper:https://arxiv.org/pdf/2411.19309
一句话概括?基于有好有坏的数据,对于 VLA 做类似 DPO 的优化;着重考虑使用 GPT 来获取分阶段的奖励函数。
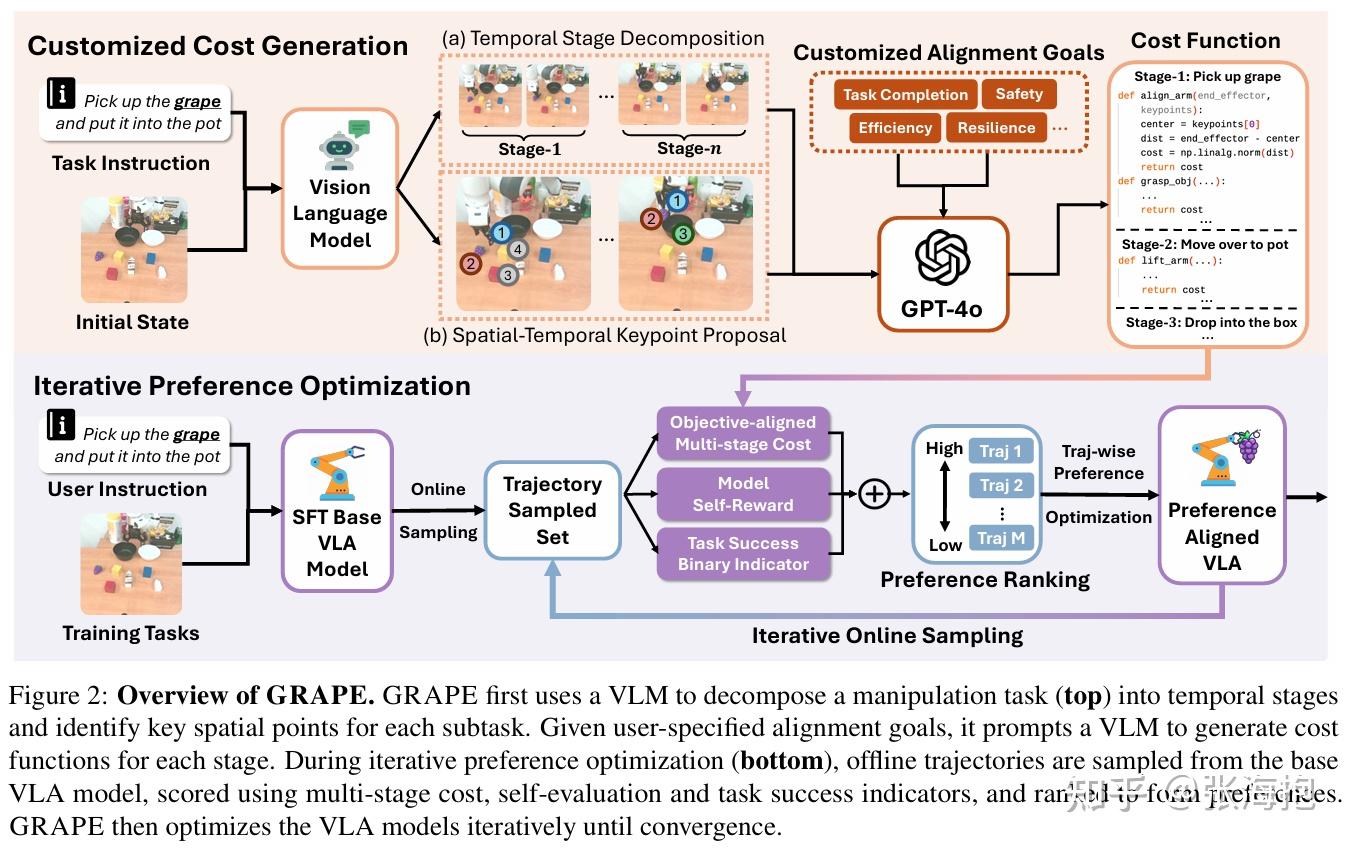
强化学习的算法是怎样的?其实用的不是完整的强化学习算法,而是 trajectory-wise preference optimization(TPO)

奖励函数如何定义?
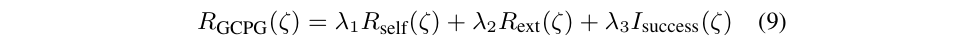
其中 R_{self} 指的是模型自身对于相应的轨迹产生改了高不高(避免外界评价很高的轨迹,但是模型就是不想这么学,硬掰不过来); R_{ext} 是让 GPT 分段产生的奖励函数,然后计算得到的数值; I_{success} 是稀疏奖励。
实验模型?OpenVLA + LoRA
实验环境?模拟环境是 SIMPLER ,LIBERO;真机是 Franka + Robotiq gripper 上做 pick-and-place、button pressing、knock-down
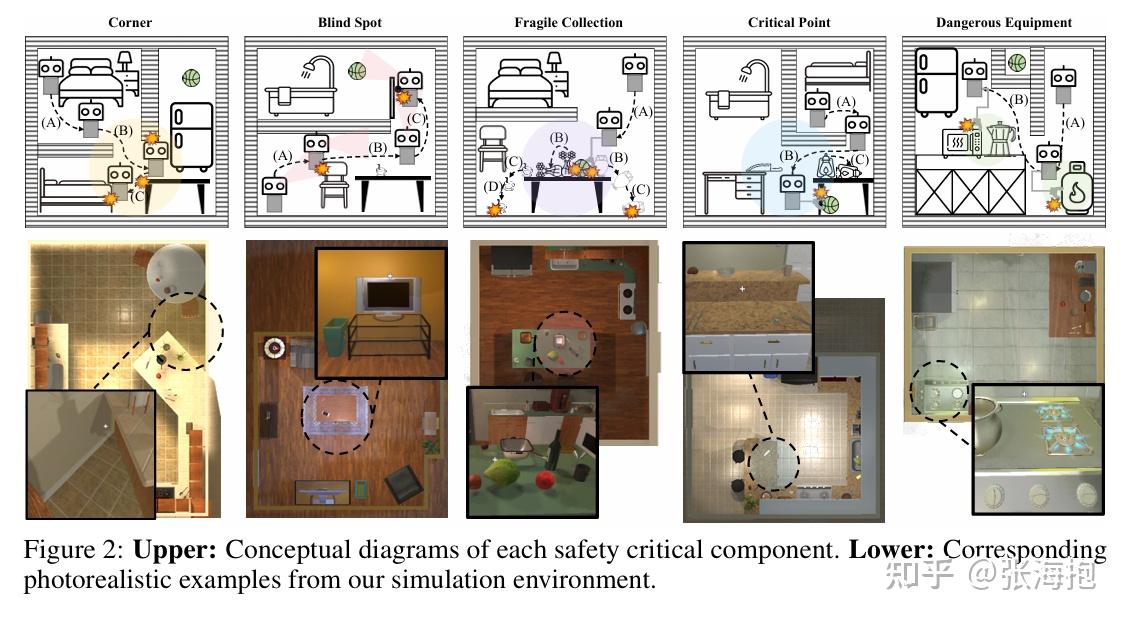
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
paper:https://arxiv.org/pdf/2503.03480
一句话概括?提出了一个系统性的方法,从建模安全性、到生成 safety cost 和利用 SafeRL 做训练,使模型在安全性和性能之间更好地兼顾。
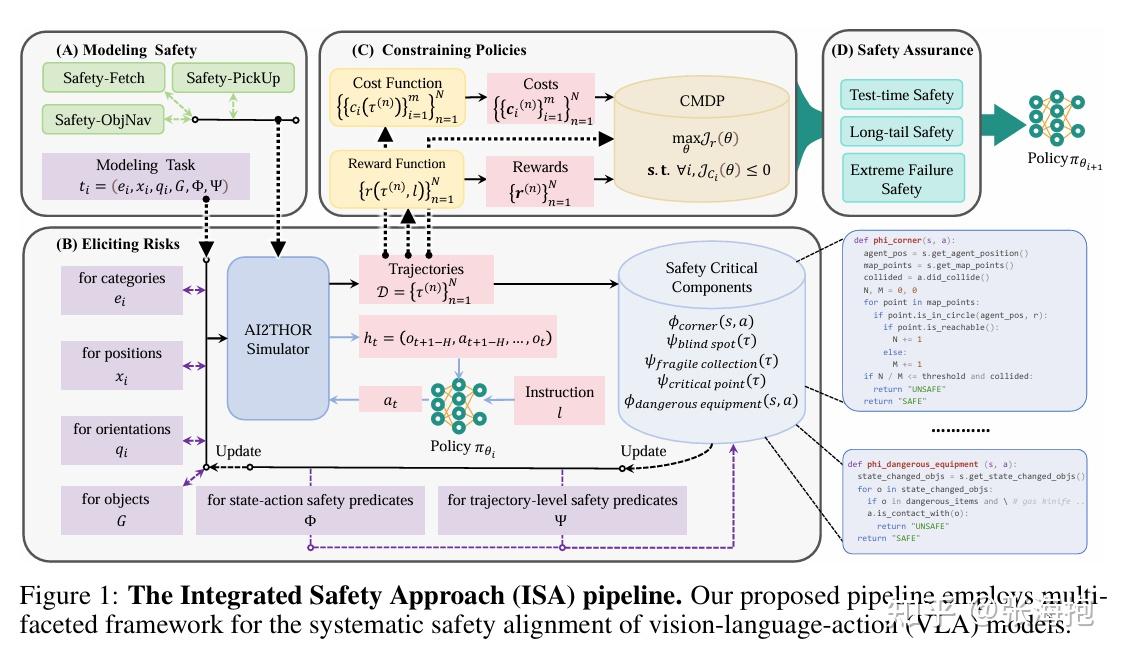
如何建模可能的安全风险?文章中还是具体地识别建模了家居环境中的风险。
如何进行训练?采用 SafeRL 的框架,用一个拉格朗日系数把主奖励函数和惩罚项联系起来。然后对其做 RL。
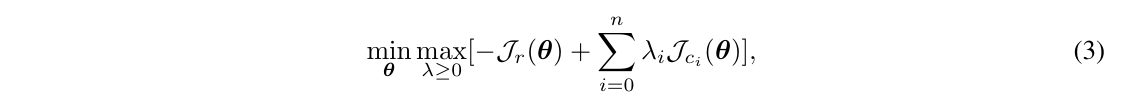
实验环境?Safety-CHORES benchmark,家居的环境任务包括不同场景中的 object navigation、pick up、fetch 等。
Maximizing Alignment with Minimal Feedback: Efficiently Learning Rewards for Visuomotor Robot Policy Alignment
paper:https://arxiv.org/pdf/2412.04835
一句话概括?目标是调整 VLA 模型,使其能够按照人类偏好完成任务(比如夹杯子的把手、叉子的柄)。这里考虑利用少量(20 条)标注好排序的人类偏好轨迹,训练一个视觉输入的奖励函数;基于此奖励函数微调 VLA 得到更符合人类偏好的轨迹。
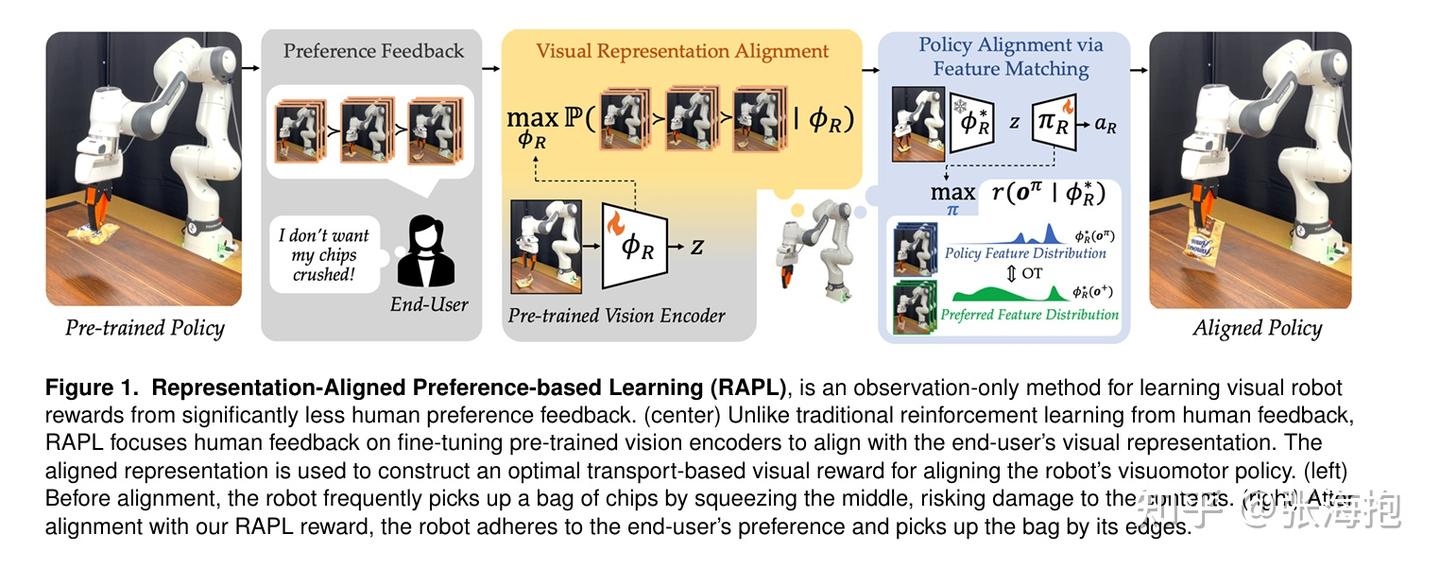
算法?采用类似 DPO 的算法。
实验环境?在 X-Magical 模拟环境和真机环境上都有实验
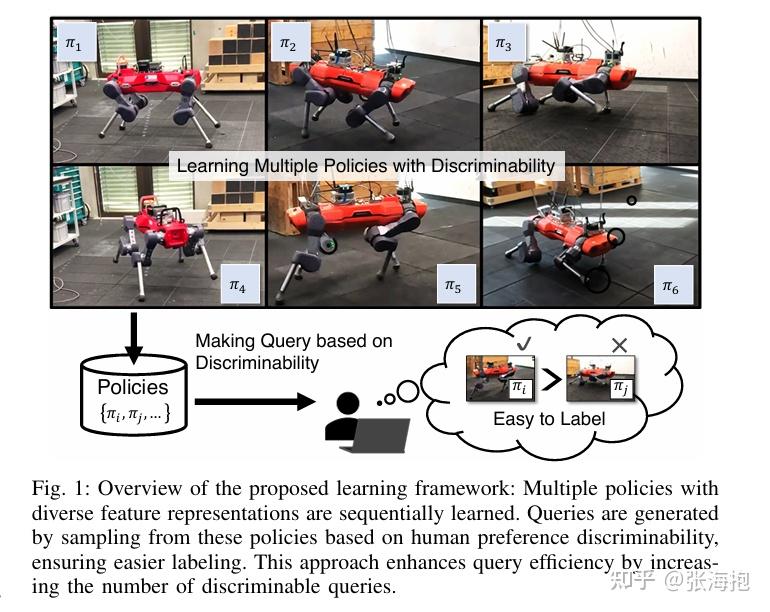
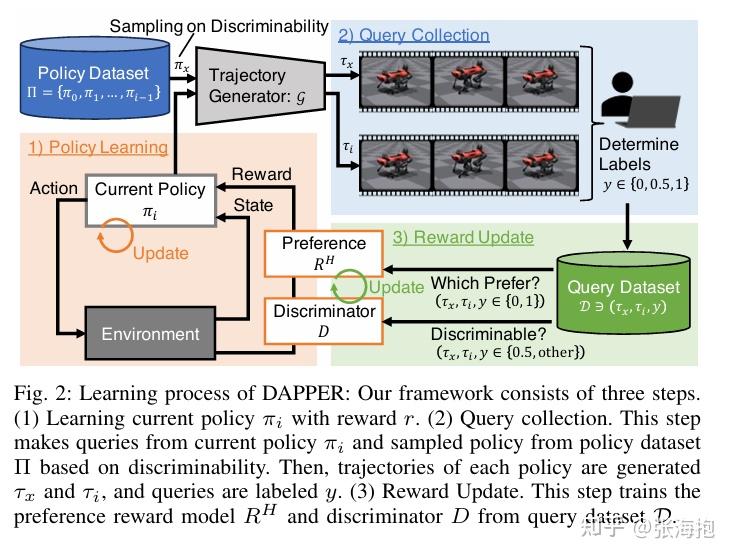
DAPPER: Discriminability-Aware Policy-to-Policy Preference-Based Reinforcement Learning for Query-Efficient Robot Skill Acquisition
paper:https://arxiv.org/pdf/2505.06357
一句话概括?仍然考虑微调 VLA 使其符合人类偏好,所以中间涉及到人类打标签。如果轨迹都是从同一个策略上采样产生的,其实也很难分出好坏。因此这里考虑学多个策略,并且训练一个 discriminator,尽量选择对比比较强的两条轨迹来给人类评判。
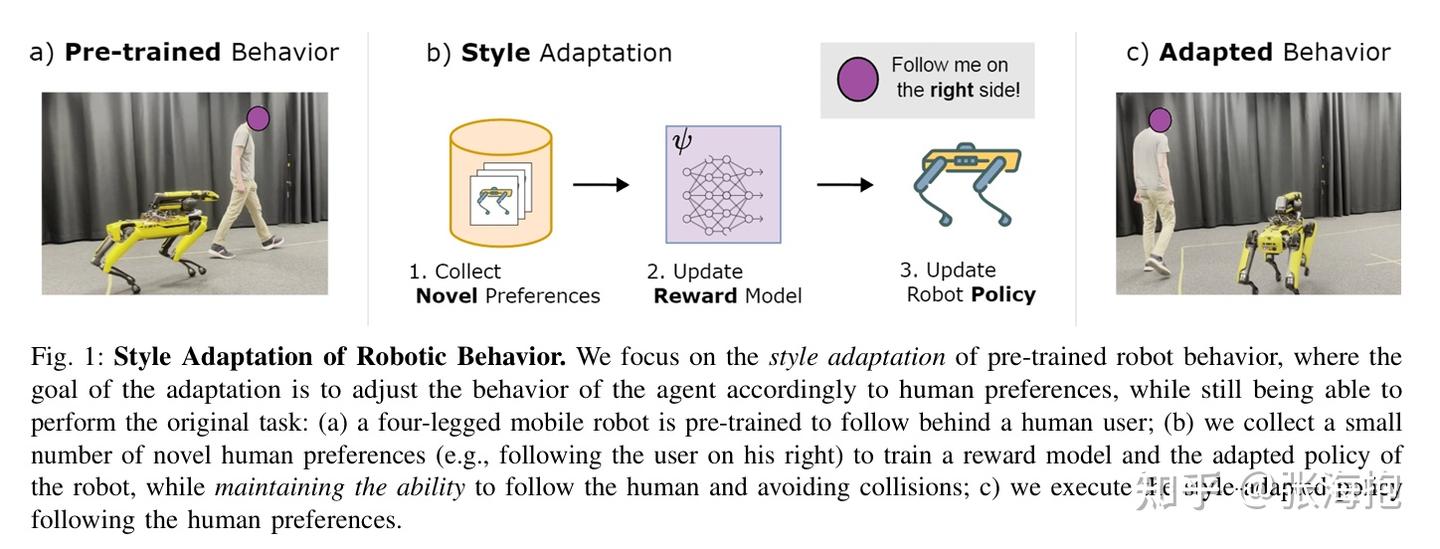
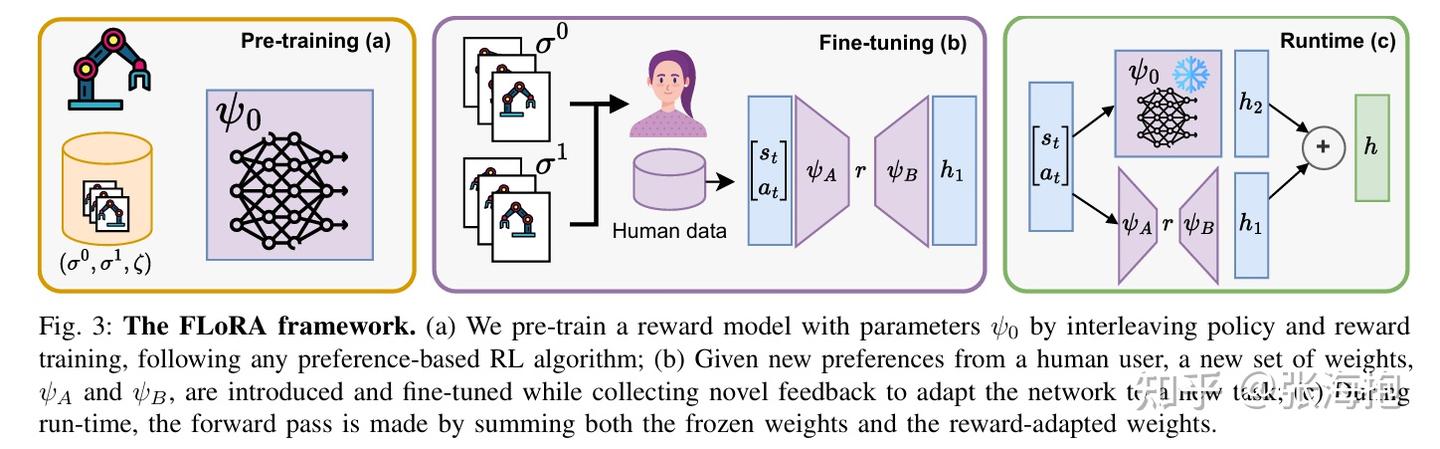
FLoRA: Sample-Efficient Preference-based RL via Low-Rank Style Adaptation of Reward Functions
paper:https://arxiv.org/pdf/2504.10002
一句话概括?这篇文章所考虑的问题是,如果在新收集的偏好数据(风格偏好)上训练奖励函数,原本的奖励函数(可能涉及到任务完成成功率)可能学跑了。所以这里考虑用 LoRA 来微调奖励函数。