作者:LLM迷思
https://zhuanlan.zhihu.com/p/1976639267406111489
最近一直在 RL 做了一些工作,同步优化做的比较多,其中一个比较有意思的是在VeRL上实现了 RollPacker 的部分工作,在开源模型上实现了30%以上的优化效果。同时,配套优化方案,完善了一整套分析、收敛、对比验证的流程,收益还是可以的。
这里简单介绍下 RollPacker,RollPacker 是 Alibaba 联合香港科大推出的强化学习同步优化方案。
RollPacker实现了2.03倍至2.56倍的端到端训练时间减少,与同期优化工作RLHFuse相比,在多达128个H800 GPU上为Qwen2.5系列大型语言模型实现了高达2.24倍的加速。其主要结构分为:
- Tail batching:一种新颖的同步强化学习 rollout 调度策略,显著增强强化学习 rollout 推理性能。如下图所示。
- 并行性规划器:动态分析 rollout 工作负载并为每个步骤选择最优 TP 配置来减少rollout 开销。
- 奖励调度器:reward 与 rollout 并行流水线化计算,为每个样本评估动态调整计算预算,有效降低其开销。
- 流式训练器:通过在 rollout 和训练之间引入更细粒度的重叠,流式调度 rollout 和训练阶段,减少设备空闲时间,提高效率。

tail batching
GPU 气泡主要源于一小部分提示生成过长的响应。一种朴素的解决方法是从 rollout batch 中排除这些长尾响应。然而,这种方法会引入两个关键问题:(P1) rollout 阶段可能无法满足构成有效 batch 所需的提示或响应数量;(P2) 系统性地排除长提示会扭曲训练样本分布,可能损害模型性能。
为解决 P1,tail batching 利用推测性执行,通过超额分配请求并仅保留最快完成的部分。在GRPO算法下,每个 rollout 步骤需要采样 P0 个提示,每个提示生成 R0 个响应。tail batching 不是精确启动 P0 个提示,而是启动更多提示,仅接受最先完成的 P0 个。
类似地,每个提示生成超过 R0 个响应,但仅保留最先完成的 R0 个。这种“竞速完成”的推测性方法自然过滤掉长响应,生成平衡的、较短的 batch,从而在保持所需 batch 大小的同时最小化空闲气泡。
为解决 P2,tail batching 保证没有永久排除长提示。在 rollout 执行期间被中止的提示被添加到长提示队列中。一旦队列达到 P0 个提示,这些提示将在专用的长轮次中进行批量调度,并允许生成完整长度响应。由于长轮次发生频率较低,并与短轮次交错进行,在保证提示始终存在的情况下,使得 rollout 步骤保持高效。
并行性规划器
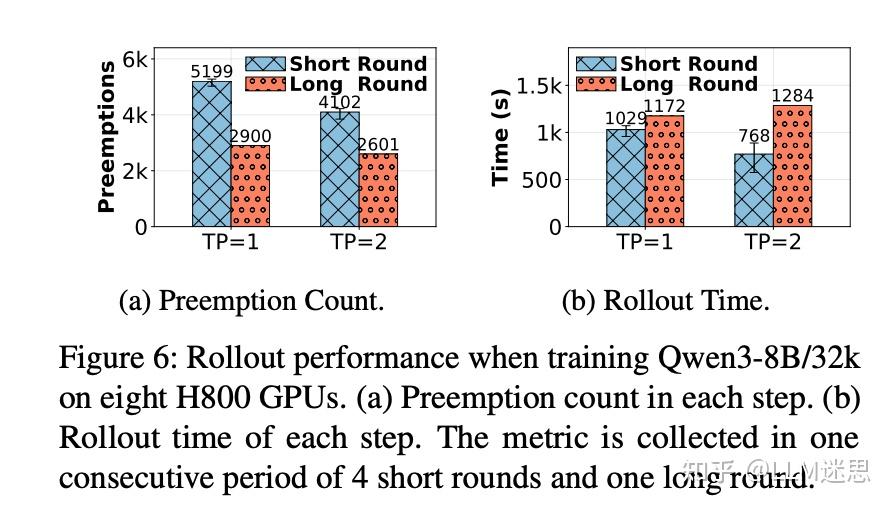
tail batching 在短轮次中增加了并发响应的数量,从而对GPU内存造成更大的压力。现有的LLM服务引擎通常通过抢占正在进行的请求来缓解内存压力,即通过交换键值(KV)缓存来为其他请求释放GPU内存。短轮次和长轮次的最优TP大小不同,因此需要动态调整。
RollPacker引入了并行性规划器,以每步骤为基础重新配置TP大小,且开销可忽略。在离线阶段,规划器在没有tail batching的情况下分析最优TP大小,并将其用作训练开始时的默认配置。
作者跟踪抢占次数并根据轻量级启发式方法调整TP大小:抢占次数突然增加(例如,>1.05倍)会触发TP增加(大小翻倍),而连续四个步骤保持零抢占则触发TP减少(大小减半)。为限制跨节点通信,TP 组被限制在单个 GPU 服务器内。
如下图在训练 Qwen3-8B 模型时,配置为 32k 响应长度和 128 的 batch 大小,短轮次比长轮次多出高达 1.79 倍的抢占次数,引入了显著的计算开销。
奖励调度器
奖励调度器将奖励评估以异步方式进行,已完成的 rollout 的 worker 被分派进行奖励计算,与正在进行的 rollout 阶段并行执行。这种设计将奖励评估与 rollout 重叠,部分隐藏了开销。
RollPacker 引入了自适应超时机制。对于每个测试用例,它跟踪训练期间正确响应的最大执行时间,记为Tanchor。当新响应的执行时间超过此阈值时,沙箱执行被提前终止并分配零奖励。自适应超时机制大幅减少了短轮次中不必要的超时情况。
与同步奖励计算相比,异步奖励计算在Qwen2.5系列模型,参数规模为7B、14B和32B,分别实现了1.48倍、1.35倍和1.18倍的加速。
流式训练器
随着rollout的推进,GPU利用率下降。流式训练器通过减少专用于rollout的GPU数量,并将释放的设备重新用于训练。使用重新分配的GPU进行训练时,仅使用数据并行副本的子集;梯度更新被推迟到rollout完全完成后,以保持在线策略强化学习的正确性。

如上图算法所示。一旦满足缩减标准并重新分配GPU,流式训练器开始在重新分配的训练GPU上处理已完成的响应。rollout和训练现在作为生产者-消费者对运行:rollout生成响应,而训练通过流式模型消费它们,调整生产和消费速率。流式训练器异步获取已完成的响应,并与正在进行的rollout并行计算梯度,从而减少整体步骤时间。
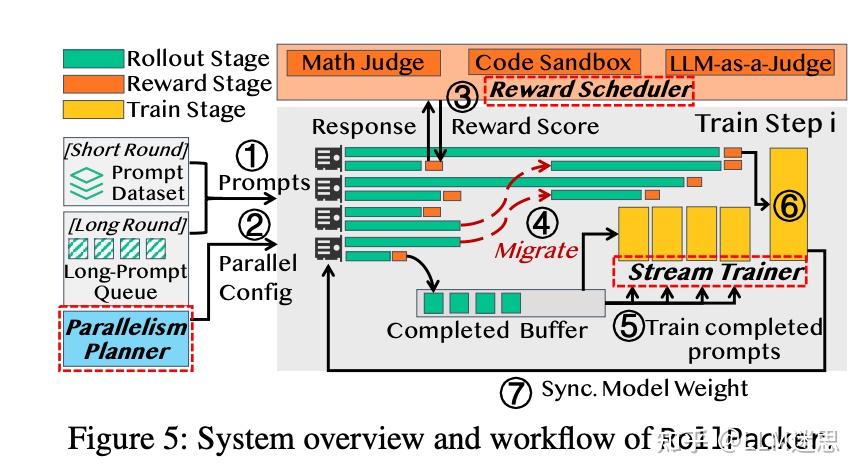
上图展示了 RollPacker 在同步强化学习任务中协调 rollout、奖励和训练阶段的完整流程。