作者:李子牛
https://zhuanlan.zhihu.com/p/1963218041199387877
最近在忙毕业论文,顺便整理过去几年「大模型+强化学习」的关键进展,写了一篇综述(Review of Reinforcement Learning for Large Language Models: Formulations, Algorithms, and Opportunities)。在这个过程中,发现了一些比论文本身更有趣的事情,想分享出来。我觉得这段心路历程揭示了 ReMax 这项研究是怎么诞生的,以及其中遇到的困难是如何被克服的,或许对其他人也有启发和鼓励。
ReMax是什么?
ReMax 是我们在 2023 年 10 月提出的一个强化学习算法,专门为大语言模型的微调设计。ReMax 是 LLM 时代第一个成功打通 REINFORCE 类算法(不依赖价值模型)的工作,开启了 REINFORCE 系列方法在 LLM 中的研究。同时,我们还给出了关于方差降低、数据异质性、内在不确定性与外在不确定性探索等方面的理论insight。

ReMax的诞生
ReMax的诞生,本身就是一个“意外”。ReMax的主体工作是一个月内完成的。回望2023年秋,那段为期一个月的高强度研究,其初衷其实非常纯粹——我们只是对LLM强化学习的理论基础感到好奇,想弄清楚经典的REINFORCE算法在这里是否真的行不通。谁也没想到,最终竟直接催生了ReMax。
起源
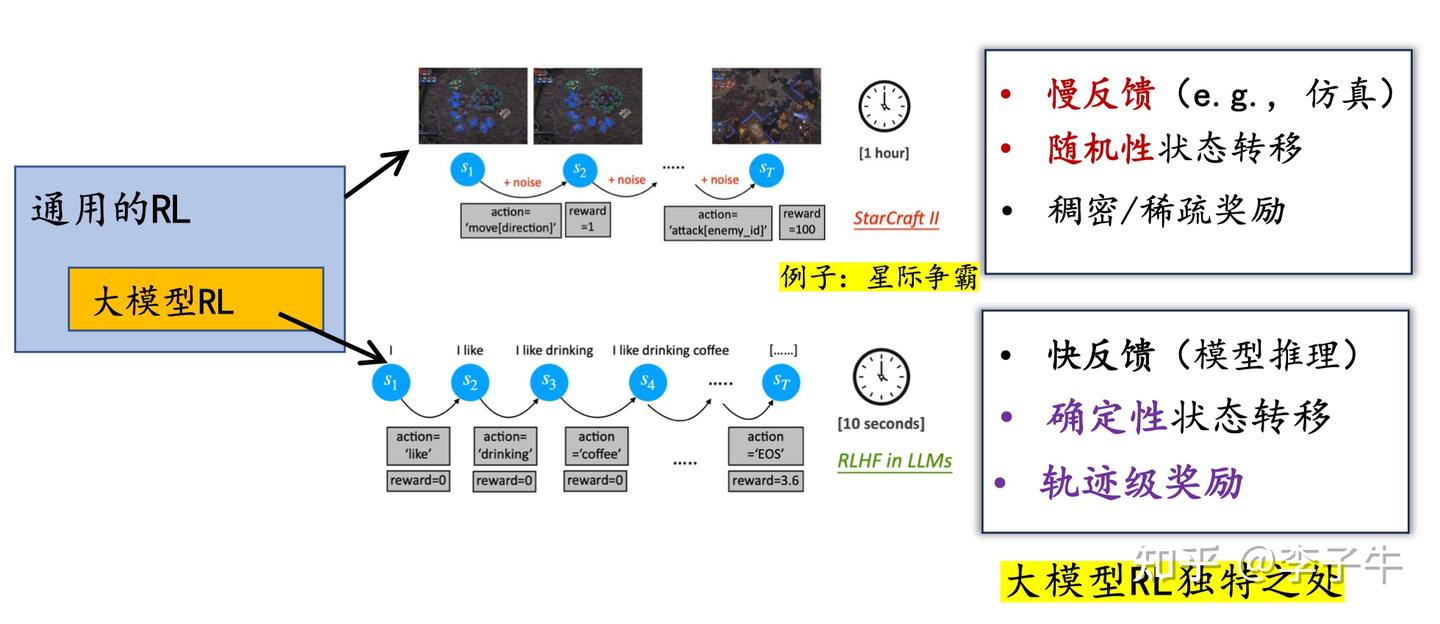
这个工作的起源是 2023 年春天的一次 LLM 讨论会,那时我刚开始接触大模型。我最感兴趣的是它的设定:状态、动作和奖励是如何定义的?遗憾的是,很多经典论文(比如 Instruct GPT)并没有给出明确的表述,而是默认使用了 PPO 算法。我印象很深的是,在学习《Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization》(ICLR 2023 Notable Top-25%)这篇论文时,我和许天花了很多时间讨论其中的定义。我们逐渐意识到,大家心中默认的建模方式是:
- 状态(state):已生成的 token 拼接成的上下文
- 动作(action):当前要生成的 token
- 奖励(reward):整句话的得分
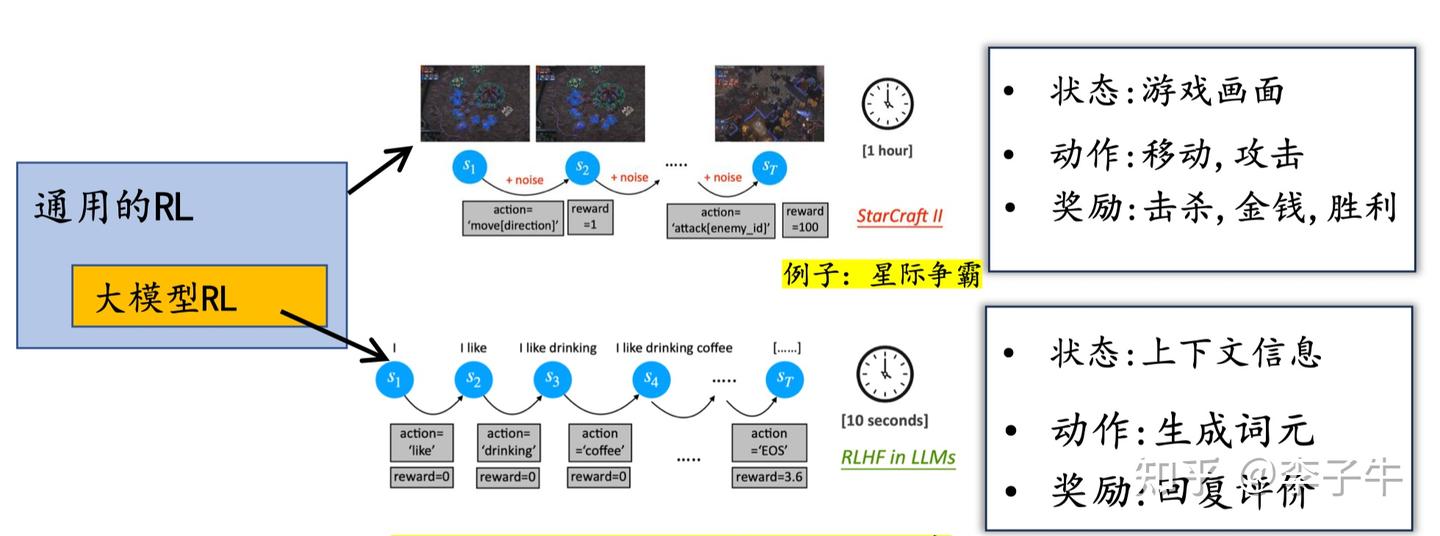
在此基础上,我们明确写出了状态转移(state transition):state + action → next state,其实就是将当前生成的 token 拼接到上下文中,这个过程是确定性的。这是 LLM 中强化学习任务的一个重要特点!基于这一点,我们认为 REINFORCE 这类直接策略梯度算法应该适用于这类任务。
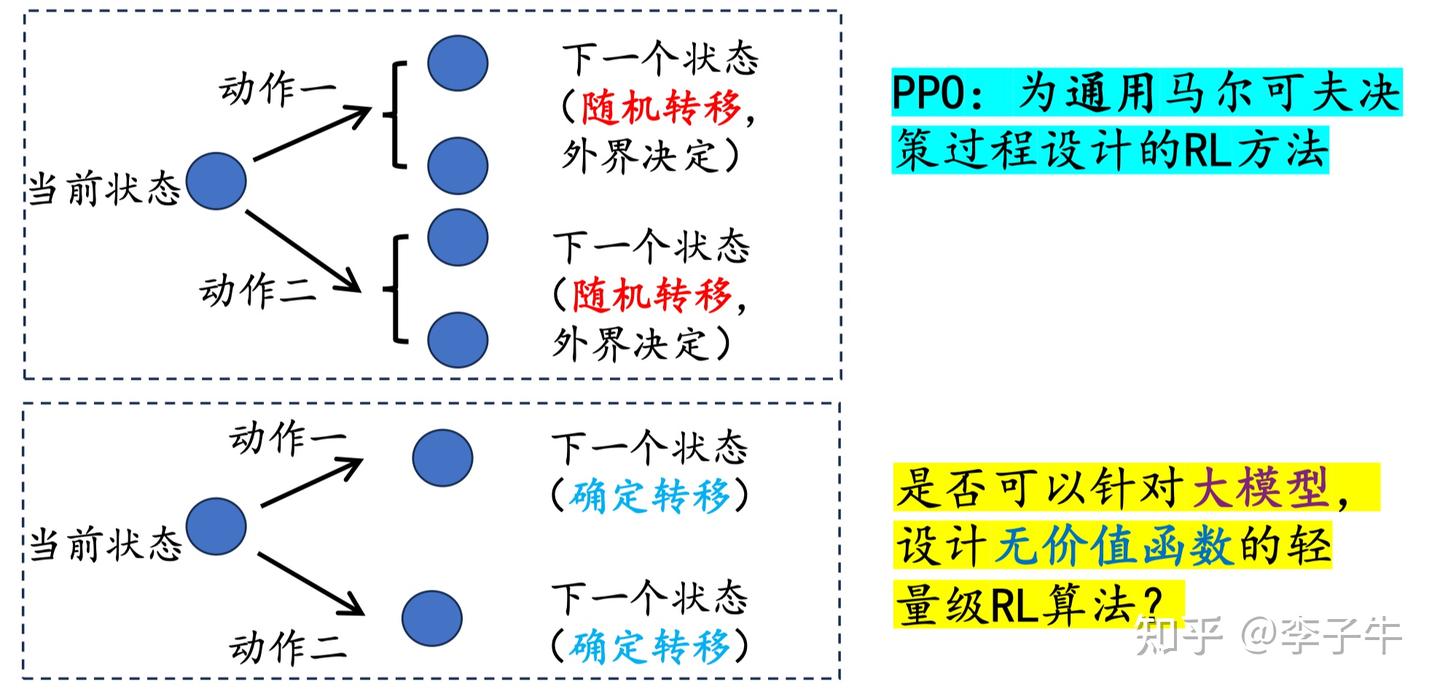
但我们当时非常不确定,一来不确定这样做有什么好处,二来这个想法本身听起来有点“疯狂”:REINFORCE 类算法最早发表于 1992 年,到 2023 年已经被深度强化学习界冷落了近 30 年!在过去的10年,RL community都在研究通用的,随机转移下的理论保证。如果当时有人跟我说他想在 LLM 里尝试 REINFORCE,我可能会鄙视他,不想再和他说话。事实上,ReMax 论文刚挂出来的前几个月,也受到了类似的质疑。所以这个想法在当时就被搁置了(部分原因也是我们在忙其他工作,没有特别重视)。
契机
那是什么让我们重新想做这个工作呢?时间来到 2023 年暑假,当时我参加孙若愚老师课题组的讨论,学习了很多 LLM 相关论文,典型的有 LoRA 和 MeZO。这两篇工作都在讲一个故事:LLM 的微调很贵,因为模型很大,所以需要内存高效的算法。这时我才意识到,降低内存需求是一个很重要的贡献方向。
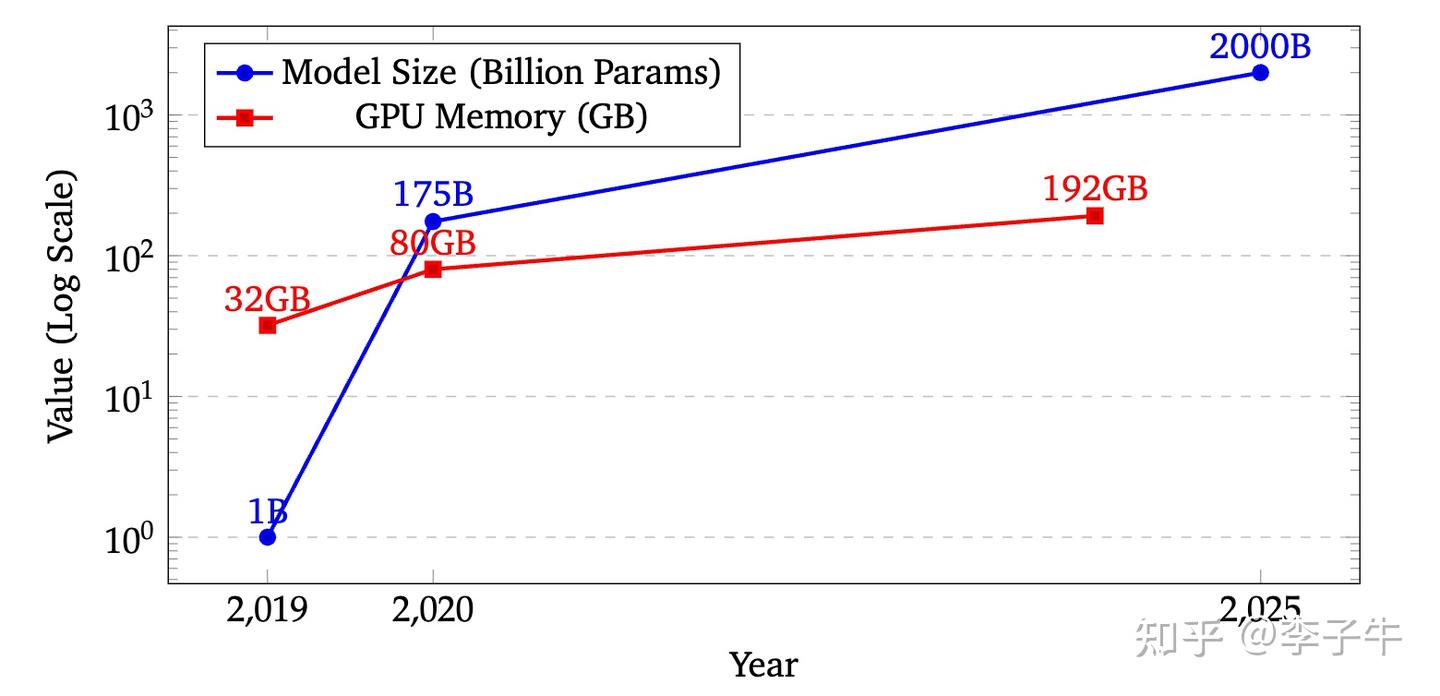
而且,我们还注意到了一个点:像LoRA和MeZO这样的算法,在降低memory需求的时候,都会或多或少的牺牲性能。而使用REINFORCE类算法替代PPO,应该是不会牺牲性能的(这是个conjecture,但是做理论的人,认可确定性转移的话,应该是会同意这个观点的)。
同时,我们也关注到同期的工作,比如 DPO(2023 年 5 月),它基于 LLM 的特殊性质简化了策略优化求解,并降低了显存需求。但我们并没有因此放弃对 REINFORCE 类算法的探索,因为我们认为 DPO 是一种离线强化学习算法,与 PPO、REINFORCE 这类在线算法有本质区别。(后来我们专门写了一篇短文Policy Optimization in RLHF: The Impact of Out-of-preference DataPolicy Optimization in RLHF: The Impact of Out-of-preference Data探讨这个话题,这篇短文还被 John Schulman 在 OpenAI 内部转发了:)
再尝试
在 ICML(7 月)和 NeurIPS Rebuttal(8 月)结束后,我迫不及待地想探究这个方向。但这时遇到了新麻烦:LLM 的训练和常规训练非常不同。以前我所有的神经网络训练单卡就能跑,但 LLM 的训练一上来就需要数据并行和多卡运行。于是我开始学习分布式训练基础。非常感谢 HuggingFace 的教程,让我很快上手了分布式训练。这里有个小插曲:当时主流的分布式训练框架大概有两类:
- 基于 HuggingFace Accelerator,配合 LoRA 训练,比较容易上手;
- 基于 DeepSpeed 的 DeepSpeed-Chat 框架,文档不全,但对全参数调优支持较好。
在好朋友秦泽钰的建议下(他建议训练全参数,不要用 LoRA),我选择了后者,后来证明这个选择是对的。我花了一周左右学习,终于在 4×V100-32GB 的机器上跑通了 RLHF 的三阶段(SFT、RM、PPO)复现。但很快发现 PPO 训练太慢了,一个训练周期要好几天。想要更快,就需要更好的机器(比如A100)。
俞扬老师的大力支持
这时,我想到了我的贵人——俞扬老师。我听说他有 4090 机器,而 4090 的 FLOPS 是 V100 的 3 倍左右,用 4090 会快很多。于是我找俞老师询问是否能借用机器,但没敢说是为了尝试 REINFORCE,怕说了之后他不借给我。
没想到俞老师很快回复,说 4090 机器不能借,但可以帮忙租 A100,并且马上帮我联系了供应商。这个过程中,袁雷学长帮了我很多。我当时受宠若惊,但在看到厂商的报价单后惊呆了:8×A100-40GB 月租 3.5 万,8×A100-80GB 月租 6 万。这是我从未想过的数字。
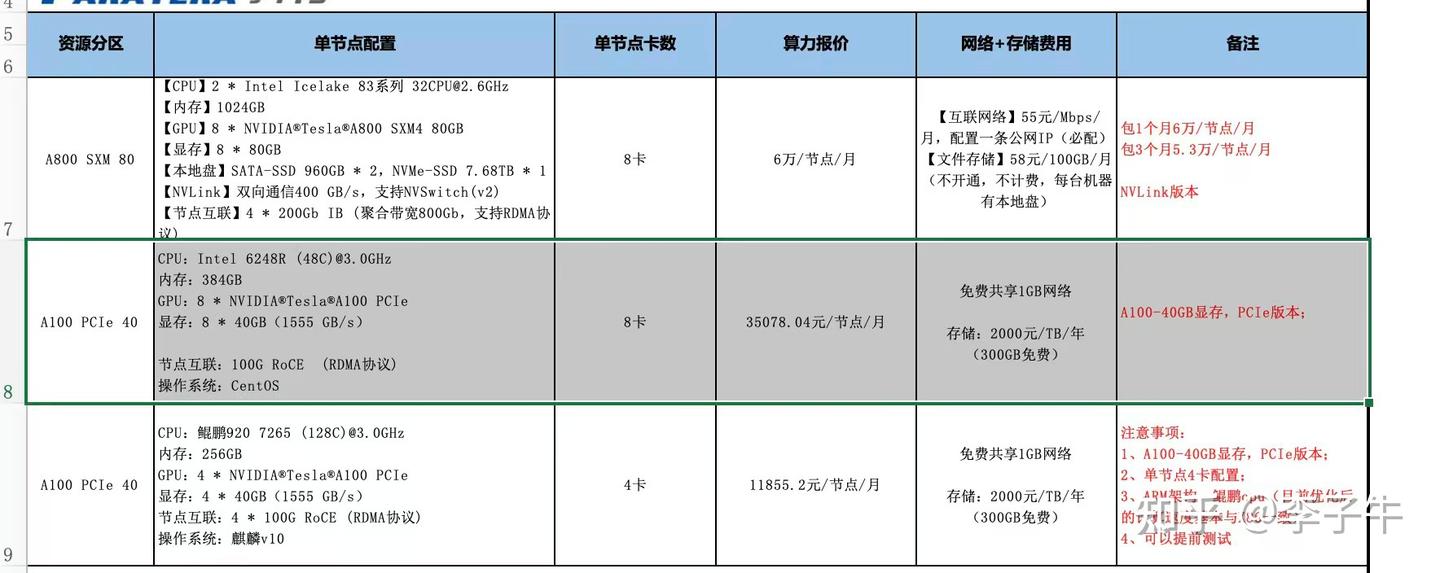
我实在不敢花这么多经费,最终选择了 8×A100-40GB。心里非常忐忑,因为我还没验证 REINFORCE 的可行性。接下来就是抓紧验证。DeepSpeed-Chat 跑 7B 模型很慢,所以我决定切换到《Is Reinforcement Learning (Not) for Natural Language Processing...》论文里的实现,用的是 T5 模型(只有几百 M)。那段代码也很难读,对我这样的初学者来说,搞不明白 encoder-decoder 和 decoder-only 的区别,以及代码实现中的坑。但花了一周时间,最终还是成功实现了 REINFORCE,并验证了可行性!
有了这个结果,我和俞老师也确认了A100机器的租赁,当时定在国庆开机,租一个月。我的目标是把llama-2 7B在上面跑成功。
国庆冲刺
国庆期间我没有休息,抓紧在 A100 上配置环境、数据、模型,跑起来。印象中遇到了很多问题,因为 DeepSpeed-Chat 当时还不成熟,我只能不断在 GitHub issue 里找解决方案。最后花了 2–3 天终于跑通了。
但坏消息是:在 OPT-1.3B 和 LLaMA-2-7B 上跑 REINFORCE 不 work。我非常怀疑是不是代码写错了,明明 T5 已经 work 了,这些模型应该也可以啊。我开始不断 debug、review 代码。这些坏消息也不敢告诉合作者,怕打击大家。但是我经过了优化理论的训练,知道训练的稳定性要查看gradient norm。查阅文档,我找到了一个关键参数:global_gradient_norm。
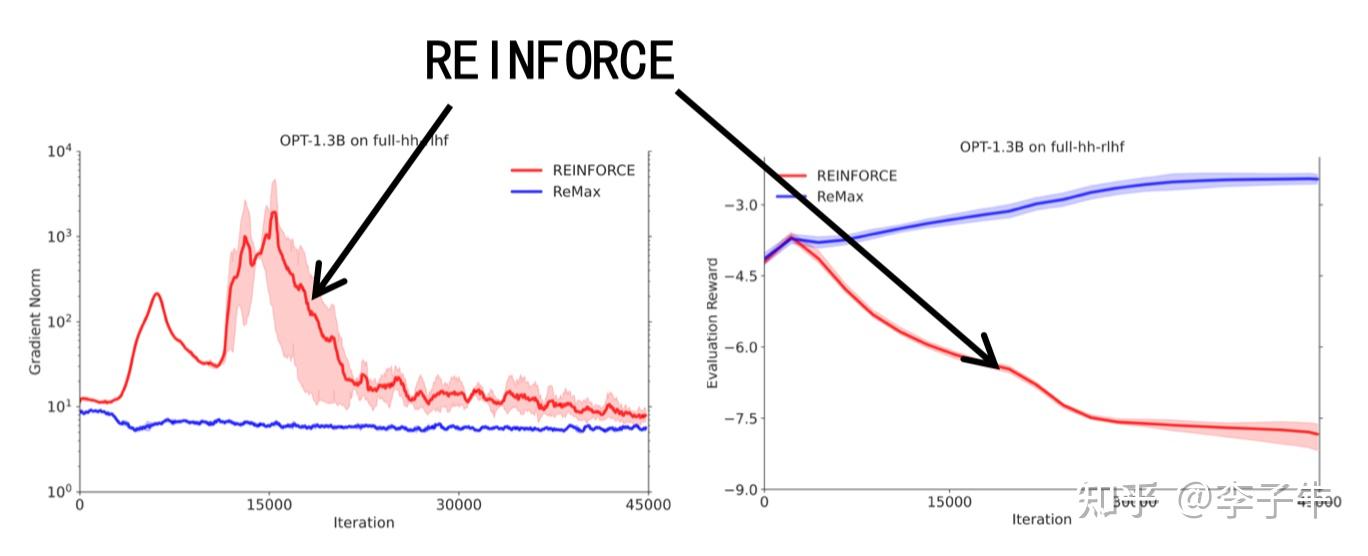
通过追踪梯度范数,我发现 REINFORCE 的梯度炸了。这时我在想,是不是随机梯度的方差太大导致训练崩溃?我该放弃吗?
REINFORCE → ReMax
但我不想放弃。大家都在说 REINFORCE 的梯度方差大,Richard Sutton 的书里也这么说。但为什么呢?我设计了一个对照实验:只训练一个 prompt,整个数据集里只有一个样本(有意思的是,后来有论文说 RL 在单样本训练下就非常有效)。我不信在这个设定下做不通,结果果然做通了!
那为什么在整个训练集上不行呢?盯着训练曲线看,我意识到一个问题:奖励分布在变化,而且不同 prompt 对应的奖励分布是不同的。这时我想起了苏炜杰老师的一篇论文《Reward Collapse in Aligning Language Models》中也提到了这个观察。这对训练有什么影响?如果每个问题的分布不同,比如问题 1 的分布是 [-5, -1],问题 2 的分布是 [5, 10],那么在问题 1 中采样到 reward = -1,和在问题 2 中采样到 reward = 5,它们的量级和含义是不同的:前者已经是一个很好的行为,应该增大 reward,但 reward 本身是负的,单样本优化得到的梯度方向看起来却是要降低似然;后者 reward 为正,但是一个坏行为,原则上应该降低似然,但 reward 为正,单样本优化却要增大似然。
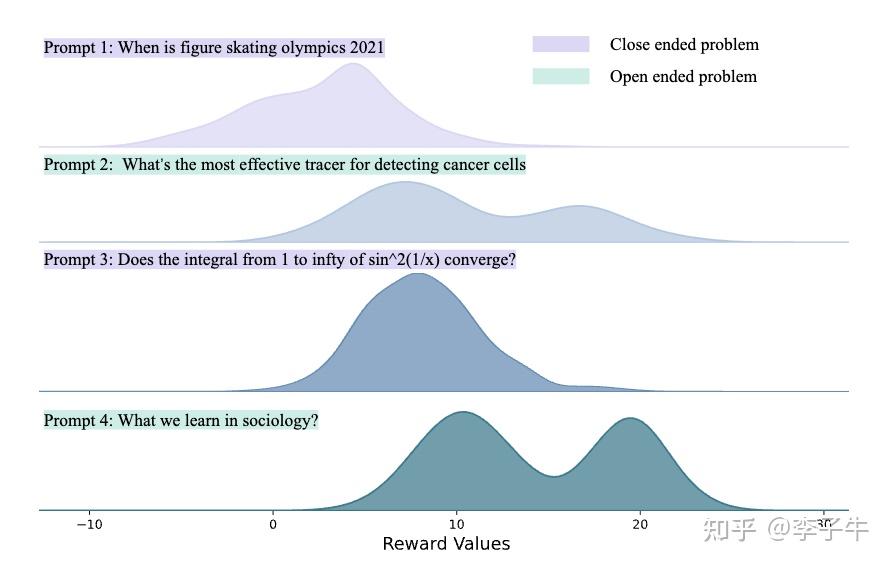
怎么解决这个问题?看起来需要一种归一化。很容易想到数据预处理这类技术。但强化学习中的奖励是动态变化的,不可能依赖数据集预处理来解决。需要一个动态更新的归一化方法。这时我想到:这不就是 RL 中的 “baseline” 吗?
等等,再想想。PPO 里有价值模型,价值模型提供了 baseline 估计,怪不得训练稳定。REINFORCE 里怎么做 baseline 呢?Richard Sutton 的书里没有仔细说,因为他(和当时的研究者)不认为 REINFORCE 是一个很好的强化学习算法。但这也不难想,价值模型在学习奖励分布的均值,我们可以用奖励分布的均值作为 baseline 估计。
但等等,估计奖励均值需要大量采样(这其实就是 GRPO 算法!)。这样会非常慢!有没有其他思路?这个问题让我想了好几天,晚上甚至想到凌晨 2 点睡不着。我需要一个计算高效、可靠、且不引入梯度估计偏差的 baseline。根据理论要求,这个 baseline 只能和 prompt 相关,不能和采样的 response 相关。终于在某一个时刻(具体记不清了),我想到了用greedy decoding,而不是stochastic sampling。当时看来,用stochastic sampling会让 baseline 和 response 耦合,导致偏差;而greedy decoding直接解耦了采样随机性。此外,greedy decoding可以认为是从分布中取众数,而众数是一个分布的良好估计器!

想到这个想法后,我立刻实现。果然,所有问题都解决了!这个想法简单、有效,而且整体算法相比 PPO 更节省内存,非常棒!
ReMax的名字由来
当时我和朋友张雨舜分享了国庆期间的这一波三折。他觉得很有意思,然后问我算法打算叫什么。我当时的代码里叫 REINFORCEGreedyTrainer,因为我觉得只是在 REINFORCE 基础上改了一下,所以算法名就叫 REINFORCEGreedy。他说这个名字太拗口,REINFORCE、REINFORCEMENT Learning、REINFORCEGreedy……听着就晕。我觉得他说得对,但我也想不出更好的名字。他建议我简化一下。我在想,什么特征比较厉害?Max,挺厉害的。而且greedy decoding就对应 max这个算子,忽然想到了 “ReMax”。他觉得这个名字非常好,既尊重了 REINFORCE,又突出了我们的改进。就这样,ReMax 这个名字诞生了。
至此,国庆10 月 7 日已经过去了。
论文写作
有了初步结果后,我开始写论文。但 LLM 训练不能只看训练曲线,还需要下游评估。当时我们参照 LIMA 论文,用 GPT-4 打分来评价模型质量。用 GPT-4 需要 API,我也没有。忘了当时是怎么买的 API 服务,也忘了是怎么学会调用 API 的。只记得 API 也很贵,只好先用 ChatGPT 打分看初步效果。当时我们甚至不知道要在什么下游任务上评测,选了 LIMA 测试集里的问题。看到模型的胜率非常高,相比 PPO 有 70% 左右,我很惊讶,因为我们预期只能和 PPO 打平(算法同源),不会超越。
与此同时,王本友教授邀请我参加他们组会讨论强化学习。我分享了 ReMax 的算法和结论,也提出了我的困惑。蒋峰博士当时指出,用 GPT 评价模型时,需要交换位置,否则打分会受到位置偏差影响。这时我才意识到,我确实把 ReMax 的模型回复放在了第一位,导致得分偏高。修复这个问题后重新评估,结果回到预期,与 PPO 差不多,但相比 SFT 提升显著。
那一周里,我一边跑实验,完善 OPT、LLaMA 上的结果,一边写论文,时间非常紧张。可想而知,我的论文初稿写得很乱。我的朋友张雨舜参与进来,帮我重写了大量内容,甚至几乎是全文重写。他强烈要求把 3 月份观察到的 MDP 性质等关键洞察写进去,认为这些性质会从根本上推动更多研究。我一开始有点抵触,担心对 NLP 背景的读者来说初次阅读难度太大,影响论文的广度,但最终接受了他的建议,后来证明他是对的。
在论文基本写好后,我拿给孙若愚老师看。他提了很多意见,其中一点是担心价值模型的内存问题是否真的那么严重,因为 Instruct GPT 中 175B 的模型只用了 7B 的价值模型,这种情况下价值模型占显存不到 50%。但后来证明这个想法不完全对,OpenAI 使用 7B 的价值模型也是出于计算代价考虑,如果没有计算考虑,他们也会有更大的value model。孙老师还阅读了 ReMax 的理论部分,提出了一个关键问题:为什么奖励减去一个 baseline 可以降低方差?从统计理论来说,一个随机变量减去一个常数,不会改变方差。
这个问题当时把我问住了。是啊,为什么呢?事实上我当时也没想明白,甚至怀疑是不是哪里搞错了。但 Richard Sutton 的书里也是这么写的:baseline 可以降低方差。这个对话发生在晚上,我已经想不动了。回去睡了一觉,第二天整理公式,发现实际的梯度估计中,减去的是 score function(对数概率的梯度)乘以 baseline。虽然 baseline 是常数,但前面的 score function 是随机变量,因为它和 (x, y) 都有关,而 y 是随机采样的。这就解释了孙老师的疑问。但孙老师还不满意,问有没有方差降低的理论保证?如果这件事足够重要和基础,就需要理论保证。当时我以为只要证明贪心采样是经验奖励的一个近似,而经验奖励能降低方差,就可以保证方差降低。但后来证明我错了。不过这已经是第二话的内容了,我们先把论文以最基础的版本挂上了 arXiv。(注:ReMax 论文的 related work 中详细回顾了 RL 的方差降低工作,其他工作少有,欢迎对技术演变感兴趣的读者去阅读。)
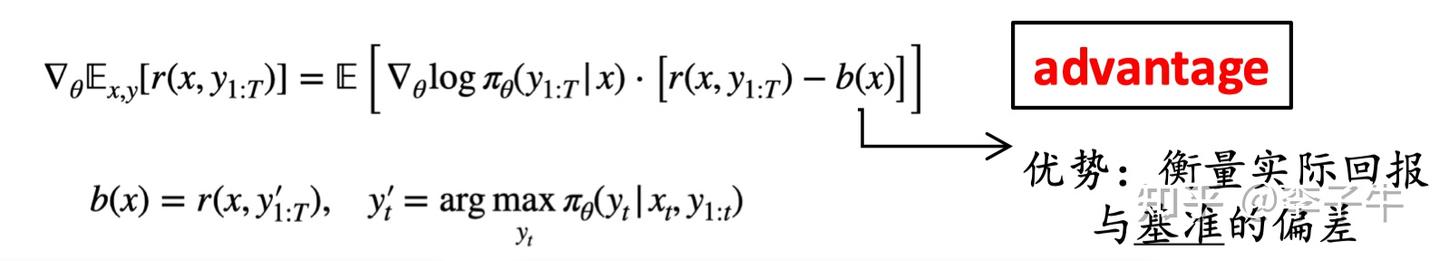
ReMax的第二阶段
ReMax 论文出来后,俞老师帮忙做了很多推广,有不少朋友来夸我们。我的朋友秦泽钰说这是他读过LLM+RL里写的最清楚的。但也有很多质疑声音,觉得REINFORCE类算法不靠谱等等。而且租赁的服务器即将到期,我们暂停了实验结果的进一步推进,转而在理论方面进行完善。我们最想证明前面提到的方差降低。
我一开始以为这是一件简单的事。按照上面的误差分解,只要证明奖励分布的均值作为 baseline 估计可以降低方差,而且贪心采样得到的奖励是分布的众数,可以估计奖励均值。但很快,我和许天发现错了。即使想证明期望奖励作为 baseline 可以降低方差,也是非常困难的,因为存在反例!在这个过程中,我们甚至翻阅历史文献,找到了 1991 年 Peter Dayan(强化学习早期元老之一)的论文《Reinforcement Comparison》。
在那篇论文中,Peter Dayan 首次指出,尽管直觉上期望奖励可以作为 baseline 降低方差,但实际上并非如此。他考虑了一个 2 动作的 bandit 问题,说明期望奖励在某些情况下可以降低方差,但也存在反例表明期望奖励作为 baseline 甚至可能增大方差。他还修复了这个问题,提出了一个最优 baseline,可以达到最小方差。我们顺着这条线查阅文献,发现 Evan Greensmith、Peter L. Bartlett 和 Jonathan Baxter 在 2004 年的 JMLR 论文《Variance Reduction Techniques for Gradient Estimates in Reinforcement Learning》中进一步探究了最优 baseline 的设计,并给出了一种通用形式。
基于这些结果,我们开始担心 ReMax 是否不够有效。我们赶紧在 Peter Dayan 给出的 toy case 上验证,发现问题没那么严重。在最优动作尚未收敛时,ReMax 是可以降低方差的;而当最优动作接近收敛时,虽然 ReMax 相比 REINFORCE 不能降低方差,但此时整体方差已经很小,所以大一点也没关系。至此,我们证明了 ReMax 的方差降低理论。

同时,我们也给出了 LLM 设定下最优 baseline 的设定。虽然它有解析解,但计算代价很大,需要在计算 baseline 前事先求解 score function,因此不实用,难怪十几年来没人关注。我们认为 ReMax 中的贪心 baseline 是一种有效且简单的策略。
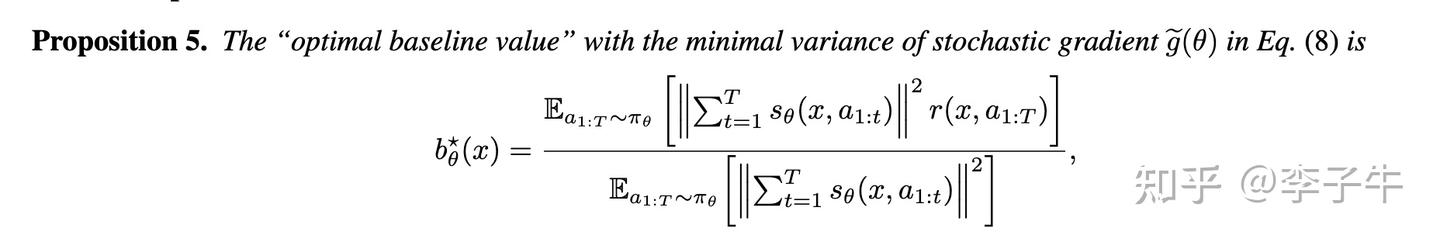
ReMax的第三阶段
ReMax 论文的第一版 arXiv 在 10 月份发布,当时 ICLR 的投稿截止已过。因为论文偏向 LLM,我们打算投 12 月的 NAACL。但不幸的是,NAACL拒稿了,因为我们在投稿前更新了 arXiv。当时还发生了一件不开心的事:我们的投稿被审稿人转发到微信群,质疑我们理论的正确性。这让我对 NAACL的审稿规范性产生怀疑,于是决定将论文投往机器学习会议,并准备 1 月份的 ICML。
在这个阶段,孙老师和我的朋友林志航帮忙申请到了新的计算资源。我打算在实验层面做更多探索,主要研究了三个方面:
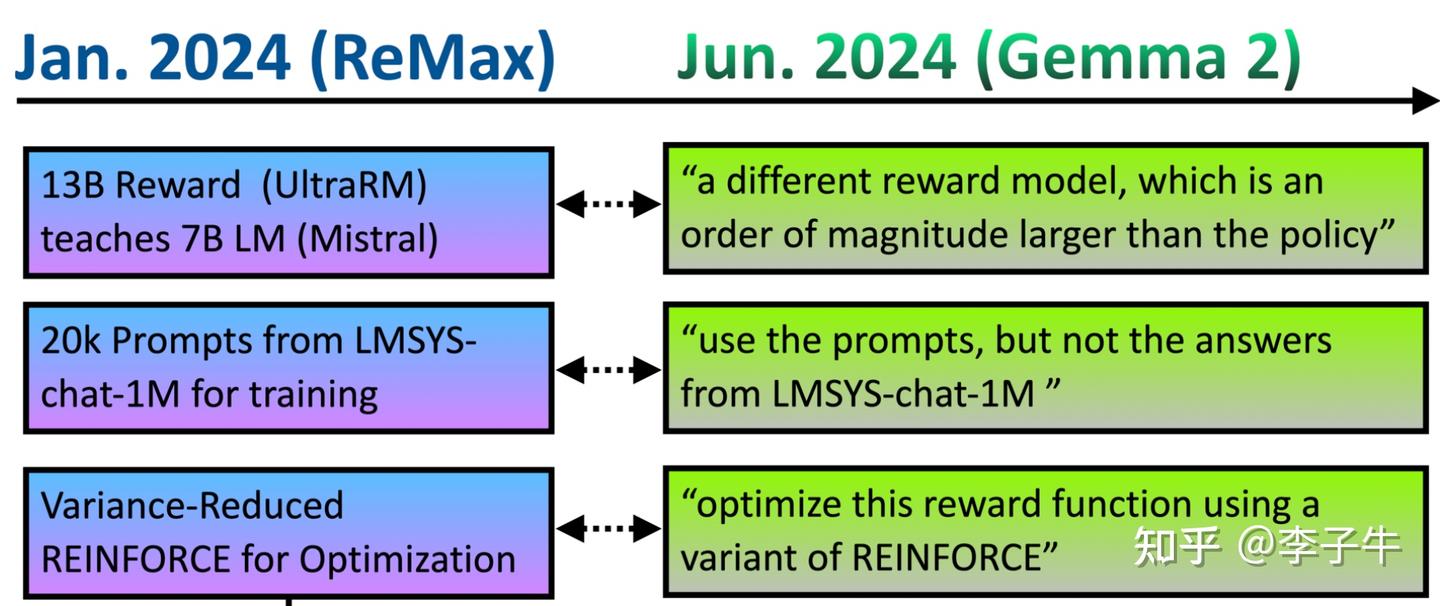
1.探究 DPO 作为 RL 的起点:我们认为 DPO 和 SFT 一样是离线算法,可以从偏好数据集中获得更好的初始点,再接 RL 进一步提升。结果验证了有效性:DPO 初始胜率为 68.3%,经过 ReMax 优化后达到 84.7%,显示出在线 RL 带来的显著提升。
2.探究更大奖励模型的收益:我们发现大奖励模型(14B)比小奖励模型(7B)有更好的奖励准确率,而奖励模型在训练中显存占用不高(不到 10%),所以大一点的计算负担不大。我们使用 UltraRM-14B 指导 Mistral-7B 训练,观察到进一步提升。优化后的模型在当时 AlphaEval 榜单上是 7B 家族的第一名。
3.RL 训练数据集的影响:RL 训练数据集只需要 prompt,不需要 response 和偏好标注,因此选择范围更大。我们研究了三种数据:in-distribution(奖励模型的训练分布)、lmsys-chat-1m(面向真实用户请求的分布)、sharegpt-en(高质量指令调优数据分布)。发现 sharegpt-en 最有效,但没有进一步探究原理。后来在推理时代,大家对 RL 训练数据集的分布有了更细致的讨论。
有意思的是,这些点在 6 个月后 Google 的 Gemma 论文中出现了类似的技术。
ReMax 论文投稿到 ICML 后,初稿得分是 6、6、4,rebuttal 后变为 7、7、6,最终以 poster 形式接收。AC 的评语是:这个方法太简单了,但鉴于对 LLM 类任务的影响,可以接受。显然,AC 低估了我们方法带来的洞察和范式改变,只关注了技术细节。

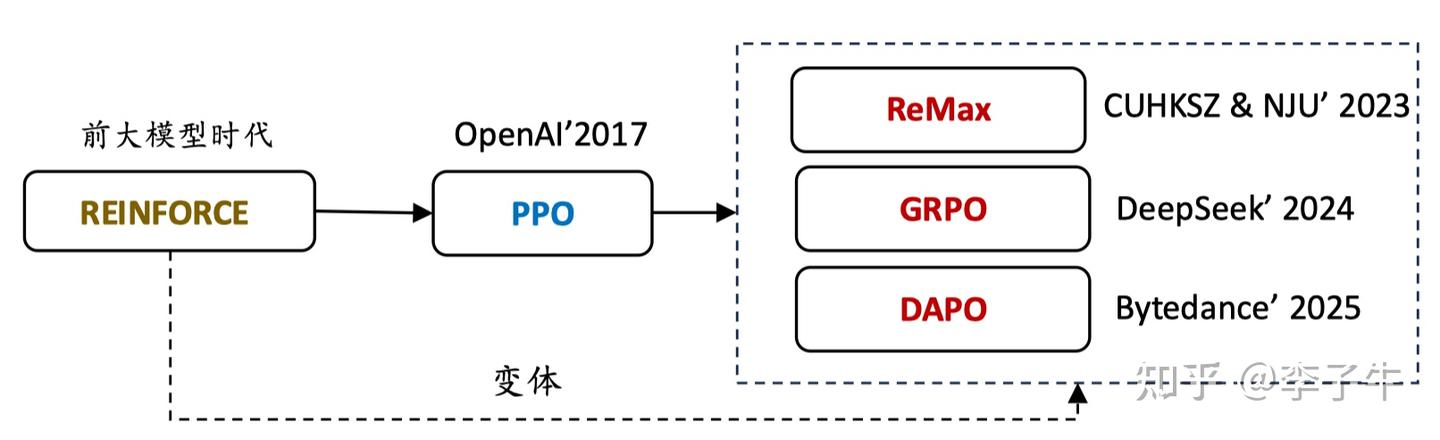
ReMax和PPO,GRPO,DAPO的联系
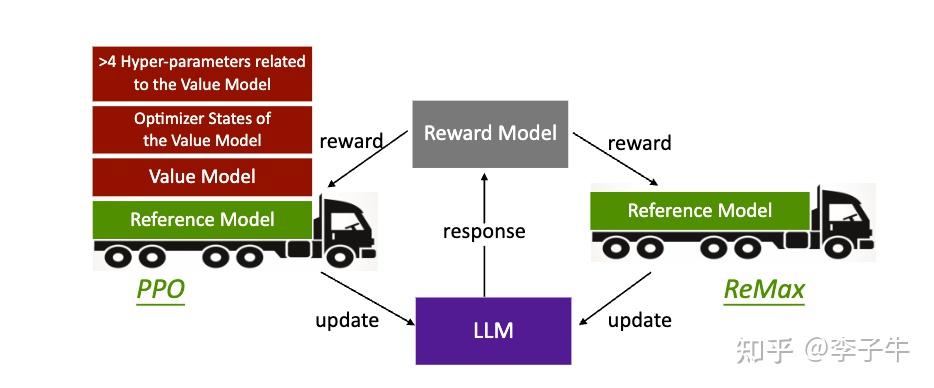
这是我经常被问到的问题。很多人会觉得GRPO是第一个移除value model,简化PPO的算法,其实不是! 从时间上看,ReMax 是为解决 PPO 在 LLM 中的计算缺陷而提出的,于 2023 年 10 月发布。它是第一篇详细说明为什么 LLM 中的 RL 可以这样设计,并给出理论保证的论文。ReMax 论文整体风格谦逊,我们认为无法超越 PPO(PPO 也无法超越我们),只是比 PPO 更节省资源、超参数搜索更简单。我们希望这种计算高效的方法能带来更多应用场景,同时希望我们的理论分析对整个领域有帮助。
后来 GRPO在 2024 年 2 月首次提出,并在 2025 年 1 月的 R1 论文中大放异彩。GRPO 直接面向大规模 rollout 设定,提出用经验奖励均值作为 baseline。其实我们已经想到了 GRPO 的想法,但没有采用。为什么?因为在 2023 年 10 月,RL 基础设施主要是 DeepSpeed-Chat,采样生成速度较慢,GRPO 的大量 rollout 对我们来说代价太高。但到了 2024 年,以 DeepSeek 的强大实力,RL 基础设施已大幅改善,利用 vLLM 等技术可以实现高效的大规模轨迹采样,这时用经验奖励作为 baseline 是更自然的选择。
顺便提一下,在23年和24年初alignment和chatting时代,ReMax 和 GRPO 论文都没有受到太多关注,当时大家的焦点是 DPO 算法变体。直到数学推理(mathematical reasoning)时代,尤其是 O1 和 R1 这两个重要工作出现后,REINFORCE 类算法才受到广泛关注。我认为一个额外因素是基础设施的改变:在 2023 年和 2024 年初,RL 基础设施非常初级,不好用;DPO 类算法可以借助已有的预训练和 SFT 基础设施轻松实现,因此得到广泛应用。2024 年后,RL 基础设施大幅改善,出现了很多好用的框架,如 OpenRLHF、VeRL、AReaL、Roll等,大家也可以在此基础上训练 RL。
DAPO(字节跳动,2025年3月)是我眼中LLM+RL领域的又一里程碑。它在GRPO的基础上,通过引入Clip Higher和Dynamic Sampling等关键技术,有效解决了推理任务中长期存在的多样性不足与梯度有效性低两大痛点,显著提升了训练效率。这个工作极大地拓展了LLM强化学习的思路边界,也刺激了我暑期加入字节Seed团队实习。
ReMax论文花絮
ReMax论文初稿完成后,我的两位师兄在后续的探索中给了我很大帮助。
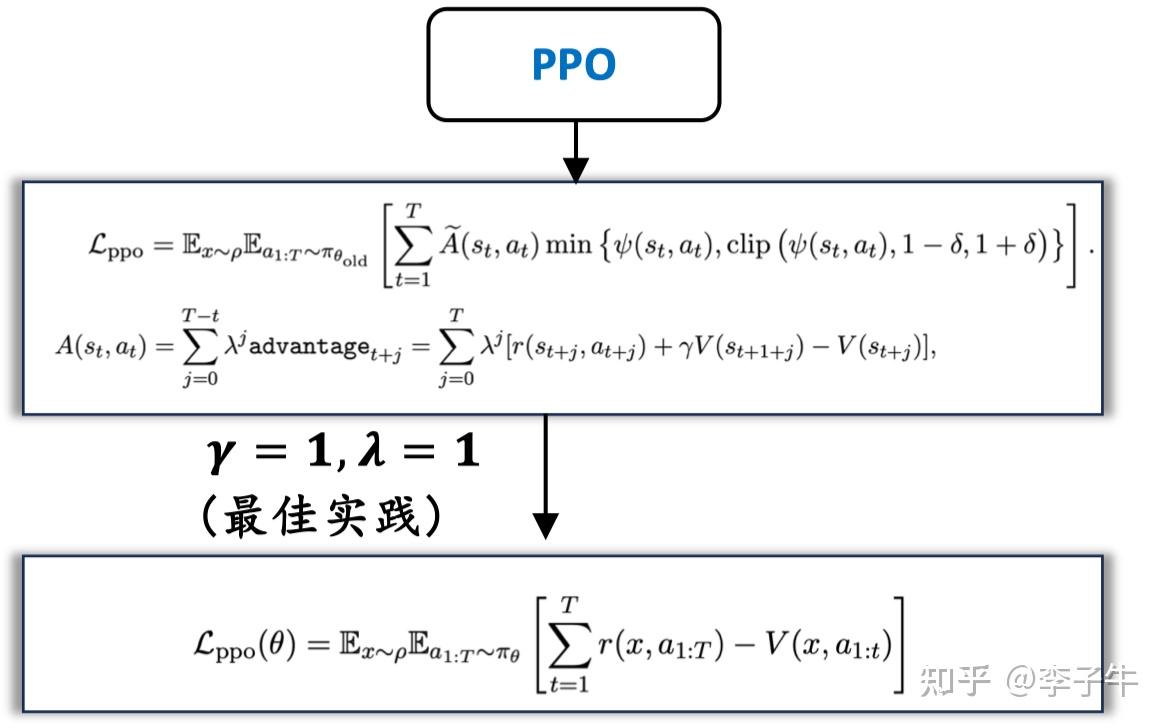
李英儒师兄最早指出:PPO 在超参数 \lambda = 1 和 \gamma = 1 后实践中常见设置),可以简化为 REINFORCE with baseline。在这种设定下,常规的 TD learning 和 GAE 都不起作用。从这个角度看,更能看出 PPO 和 REINFORCE 类算法是同框架同源的。也就是说,如果超参数适当,两种方法的性能上限应该差不多。
此外,在训练7B模型时,ReMax曾在训练中后期出现不明原因的崩溃。我的师兄陈淙靓怀疑是精度或基础设施问题,但为了赶论文,建议我先调小学习率试试。当时我以为 RL 的学习率可以和 SFT 一样大,都是 1e-5 级别。虽然调小学习率到1e-6级别后 work 了,但我仍觉得这是“作弊”,直到后来大家发现 RL 阶段确实需要更小的学习率才接受。我至今仍认为,方差降低后可以使用更大的学习率,获得更快的收敛速度,但没有探索更多。不过,关于精度和基础设施的问题,最近在RL 社区讨论很热烈,可能会成为一个专门的方向。
后续
ReMax 论文完成后,我曾一度认为 LLM 的训练算法改进空间已经不大,因此没有继续深入 RL 方向。过去两年,我的研究重心转向了模型多样性(GEM 论文)和模型探索(Knapsack RL 论文)。经过这些工作,我逐渐形成一个看法:LLM 的训练稳定性问题,是可以通过 baseline 设计和大量采样得到较好解决的;而算法上更值得深入的提升空间,可能在于如何解决“探索”问题——也就是让模型能够应对更复杂的任务,从而扩展其能力边界。当然,这些都只是我个人在研究中的一些品味和判断了。
涉及到的论文
1.Schulman, John, et al. "Proximal policy optimization algorithms."arXiv preprint arXiv:1707.06347(2017).
2.Williams, Ronald J. "Simple statistical gradient-following algorithms for connectionist reinforcement learning."Machine learning8.3 (1992): 229-256.
3.Li, Ziniu, et al. "Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models."arXiv preprint arXiv:2310.10505(2023).
4.Li, Ziniu, Tian Xu, and Yang Yu. "Policy optimization in rlhf: The impact of out-of-preference data."arXiv preprint arXiv:2312.10584(2023).
5.Li, Ziniu, et al. "Preserving diversity in supervised fine-tuning of large language models."arXiv preprint arXiv:2408.16673(2024).
6.Li, Ziniu, et al. "Knapsack RL: Unlocking Exploration of LLMs via Optimizing Budget Allocation."arXiv preprint arXiv:2509.25849(2025).
7.Ramamurthy, Rajkumar, et al. "Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization."arXiv preprint arXiv:2210.01241(2022).
8.Shao, Zhihong, et al. "Deepseekmath: Pushing the limits of mathematical reasoning in open language models."arXiv preprint arXiv:2402.03300(2024).
Yu, Qiying, et al. "Dapo: An open-source llm reinforcement learning system at scale."arXiv preprint arXiv:2503.14476(2025).
9.Greensmith, Evan, Peter L. Bartlett, and Jonathan Baxter. "Variance reduction techniques for gradient estimates in reinforcement learning."Journal of Machine Learning Research5.Nov (2004): 1471-1530.
10.Dayan, Peter. "Reinforcement comparison."Connectionist Models. Morgan Kaufmann, 1991. 45-51.
11.Rafailov, Rafael, et al. "Direct preference optimization: Your language model is secretly a reward model."Advances in neural information processing systems36 (2023): 53728-53741.
12.Hu, Edward J., et al. "Lora: Low-rank adaptation of large language models."ICLR1.2 (2022): 3.
13.Malladi, Sadhika, et al. "Fine-tuning language models with just forward passes."Advances in Neural Information Processing Systems36 (2023): 53038-53075.
14.Song, Ziang, et al. "Reward collapse in aligning large language models."arXiv preprint arXiv:2305.17608(2023).