作者:爱工作的小小酥
https://zhuanlan.zhihu.com/p/1967662447109310211
多模态大模型在提升各项能力的时候,会发现grounding能力一直处于落后的状态。很多指标都比不过专有的相关任务的模型。那么现在都有什么方法来提升大模型的这项能力呢?
今天就介绍几篇解决这个问题的方法。
方法概览
阅读过几篇论文后,发现目前的解决方法主要有以下几个方面:
1、直接生成离散的坐标值。
2、将坐标进行编码为特定的token,让模型生成token。
3、大模型后面追加一个目标检测器,使用大模型后的特征输出定位坐标。
4、推理流程修改为循环的状态,每次都缩小图片区域。
5、转化为检索的任务,让模型直接输出对应的区域编号。
方法简述
方法一:直接生成离散的坐标值
现有的很多多模态大模型基本采用的都是这个方法,例如qwen vl系列。就是直接将grounding任务转化为生成任务,输入一张图,模型输出多个坐标值,即(x1,y1,x2,y2)的形式。
不同的模型架构对坐标值的输出范围有时候会不一样,有的采用直接输出绝对坐标,有的是归一化到(0,1000)后的坐标值。
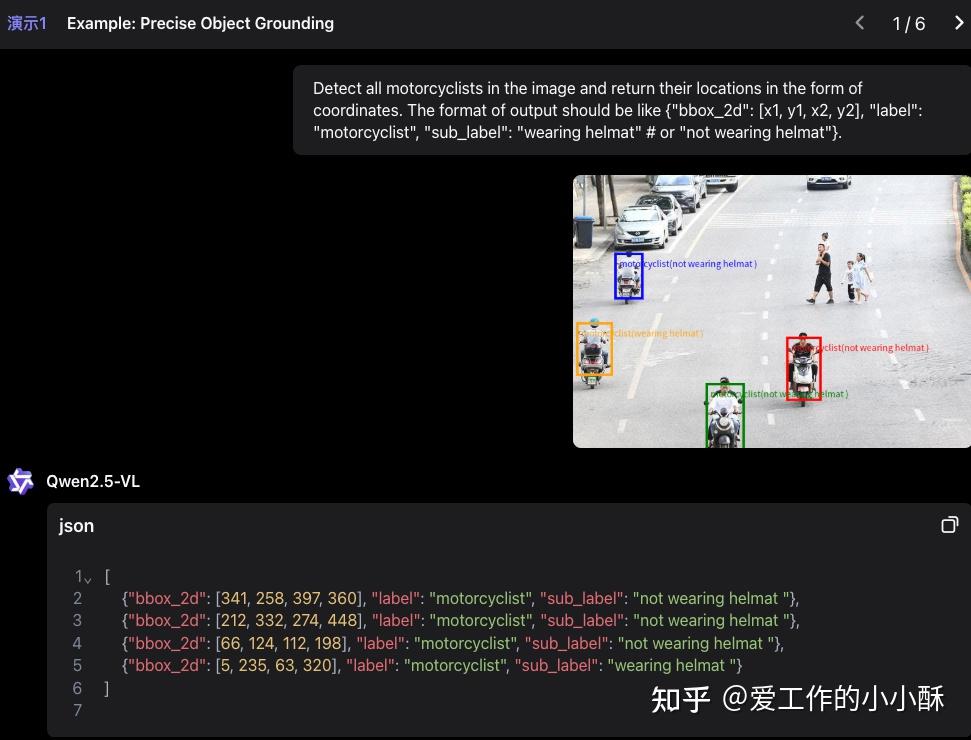
这种方式训练方案的复杂度较低,不需要对原始的语言模型做较多的修改,但是由于是直接生成坐标值,坐标值之间没有连续的语义信息,这和原始语言模型基于语义连贯性预测下一个token稍微有点违背,可能会导致整个的效果不是特别好。
方法二:为坐标值编码特殊token
由于离散的坐标没有语义信息,且带有小数点的数字容易生成错误,这种方式对原生的生成模型来说不是很友好。有研究者就将这个问题转化为「特殊token」生成的方式,来缓解这种语义上的不连贯以及复杂字符串生成的问题。
在这个方法中,最核心的是定义「特殊token」是什么。对于grounding这种任务来说,核心目标就是生成box的坐标值,一般是(x1,y1,x2,y2)的形式。而这种坐标值是一个连续的值,无法直接转化为离散的、固定个数的特殊token。但是对于grounding这种任务来说,候选坐标的范围其实是固定的,一张图上的重要元素一般是可以枚举的。

因此,我们可以将目标点的坐标初始化为特殊token,例如:(0.2,0.3,0.4,0.5)可以作为 TOKEN_1 加入到词表中。然后模型预测坐标的时候,直接预测TOKEN_1即可,不再需要预测一长串的坐标字符串,从而简化了整个任务。
在OFA这篇工作中,就是直接使用的PIx2seq中的离散化坐标值的方式。其将(x1,y1,x2,y2)坐标归一化到[1, n_{bins} ]之间,这里的 n_{bins} 就是box的数量,模型只需要预测是哪一个box即可,不需要直接给出坐标值。作者在论文中也实验了使用500个bins基本可以找到所有的objects。

在OFA中使用了1000个bins,只要使用坐标的地方都改为了bin,例如grounded QA任务的一个例子为:

通过这种方法其实是减小了整个任务的难度,也更加符合语言模型生成的逻辑性。但是因为前期需要提前新增box bin,可能会导致bin的覆盖范围不足,最终导致模型的泛化力不足。
方法三:增加专有模型
语言模型的建模目标是预测下一个token,经常使用交叉熵损失作为损失函数。而对于grounding任务来说,核心目标是预测的坐标准不准确,经常采用MSE直接计算目标坐标值和预测的坐标值之间的差距。这两个的建模目标存在着固有的偏差。
但是,我们可以借助两者的优势,将大模型编码特征的能力和专有模型对坐标强大的拟合程度结合起来,在大模型的后面再增加一个专有模型,专门用于预测坐标值。
LLaVA-Grounding这篇工作就是这样做的。其在大模型的后面用一个映射层,将大模型的特征转换到grounding model的特征空间上,再利用grounding model 本身的能力预测坐标值。
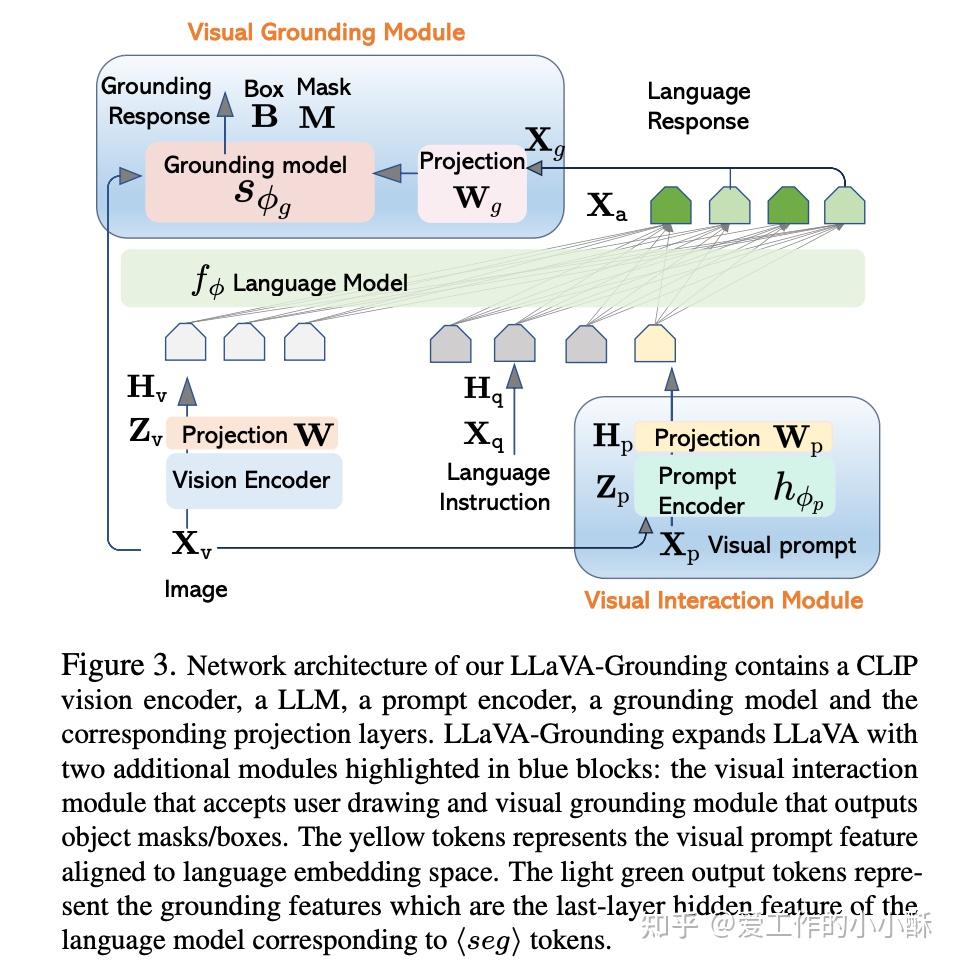
这种方法结合了大模型和专有模型的独特优势,使整个模型的grounding能力得到更好的增强,但是整体的模型结构的复杂度会增大很多,可能导致训练存在不稳定,以及推理变得更加费时的问题。
方法四:推理流程复杂化
模型的grounding能力不好,主要体现在模型对图片的细粒度识别能力较差上。那么如果提高模型的细粒度识别能力,相对应的grounding的能力也会得到提高。
目前在提高大模型细粒度识别能力上的工作也很多,这里就不进行展开介绍。从这个角度出发较为直观的一个方案是「裁剪原始图像」。既然模型在面对一整张图时,对其中的小细节可能「看不清」,那是不是放大细节部分,只关注包含细节的子图,模型就可以「看清」了呢。
ZoomEye这篇工作就是采用不断的让模型定位大块区域,逐渐裁剪原始图像,让模型逐渐可以只关注到包含目标object的区域,从而提高模型的grounding能力。这个的思想类似于我们在从一张图上寻找object的过程,我们一般是先看到整个图像的内容,然后逐渐聚焦到含有目标object的区域。

这种方法从人类认知的角度,拆解了模型识图的流程,通过增加流程的复杂度,提高了模型的细粒度识别能力。但是流程过于复杂常常会引起其他的负面影响,这也是目前主流模型没有一直采用此方法的原因。
方法五:简化任务难度,生成变检索
有没有即不增加方案流程、模型结构的复杂度,也能增强模型在grounding任务的泛化能力的方法呢?
最近的一篇工作VLM-FO1,就是通过增加输入的多样性,将生成问题变为了检索问题,从而简化了整个任务的难度,提高了模型grounding的准确度。
这篇工作保留了原始的多模态大模型的结构,只是在输入的时候增加了多种信息和标记位,让模型直接从输入信息中「选择」正确的标志位。整体的思想和前面的OFA差不多,但是没有将坐标值直接转换为特殊token,而是在ROI特征前面加入了「特殊token标记位」。例如下图中的

上图中的蓝色方框代表整个图的image token,红色块代表每个box对应的image token,后面的绿色方框代表纯文本token。可以看到,在每个红色块序列前面都有一个绿色的特殊token,最终模型需要生成的也是这个token。
例如,在一些相关任务上的生成效果如下:
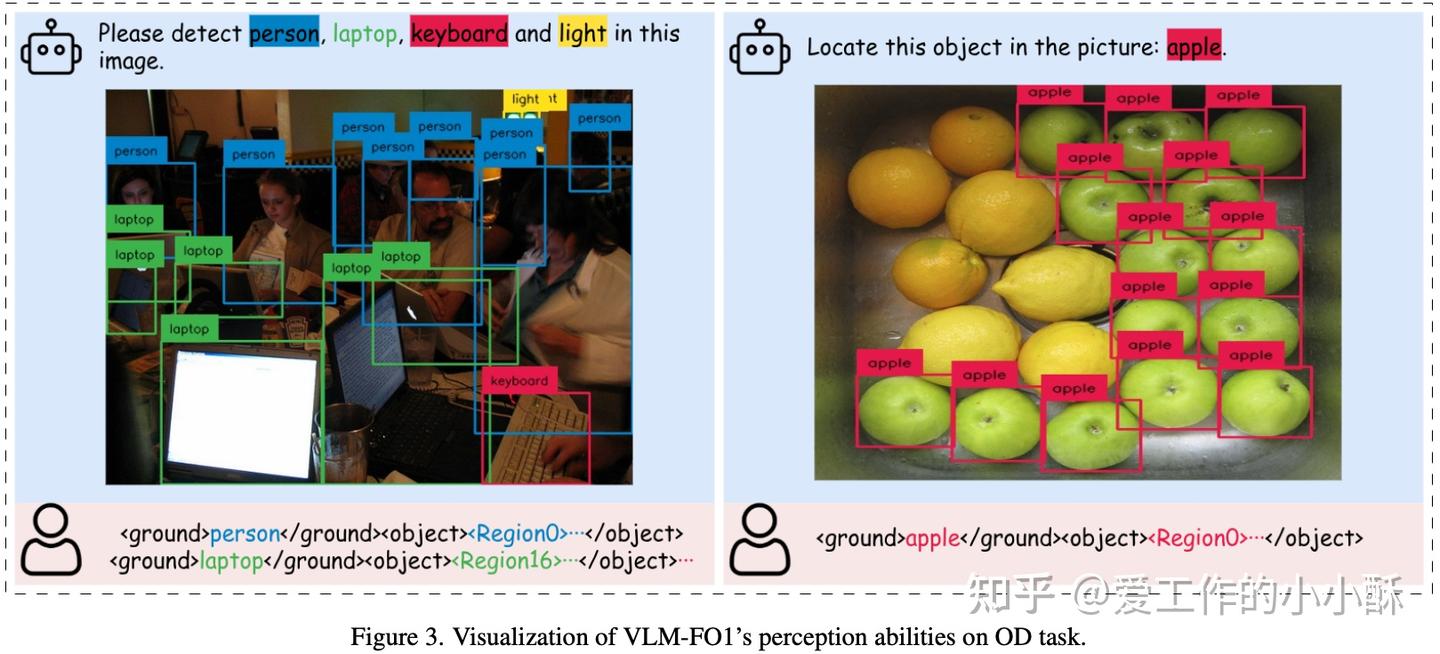

将生成任务转化为检索任务,的确减轻了整个任务的难度,让模型的细粒度识别更加准确了。但是由于前面还是依靠RPN网络得到候选box,进而抽取特征,整个流程上可能会产生误差累积的问题,以及如果box过多的话,输入llm decoder的信息量会过多,也会增加整个模型检索的难度。
总结
上述几种方法大多是从大模型和专有模型的差异点出发构建整个训练方案,借助专有模型的优势,或者发挥大模型本身的优势,简化整个模型训练的难度,从而达到了一个更好的效果。
深入思考一下这个问题,个人认为目前大模型相对于专有模型效果较差的原因可能有以下几个方面:
大模型的视觉信息编码方式存在局限性
- 相较于专有的模型,现在的大模型只是将图像编码为token给语言模型,会损失很多细粒度的信息
对跨模态交互和推理能力建模不足
- 在对齐阶段,缺少更多样更复杂的细粒度识别的数据集
训练目标较为简单,没有直接建模坐标之间的关系
- 大模型的训练目标是token预测,而专有模型会使用mse损失函数直接建模两个坐标之间的关系
期待更多更好的解决方案~