作者:宇宙哇
https://zhuanlan.zhihu.com/p/1969545638023767020

《Kimi Linear: AN EXPRESSIVE, EFFICIENT ATTENTION ARCHITECTURE》,这篇论文提出了一种新的注意力架构,试图解决当前大模型在处理长文本时面临的效率和性能瓶颈。
读完这篇论文,你将收获三点:
1.理解核心矛盾:明白为什么标准的注意力机制在处理长文本时会变得又慢又耗内存。
2.掌握解决方案:了解Kimi Linear是如何巧妙地将一种新的线性注意力与传统注意力结合,来同时提升效率和性能的。
3.看清技术价值:能够判断这项技术在实际应用中的潜力和价值,知道它为什么被称为“全注意力架构的直接替代品”。
为什么我们需要新的Attention架构?
Transformer是现代大模型的基石,而它的核心就是注意力机制。这个机制的强大之处在于,它能让模型在处理一个词时,同时“关注”到输入序列里的所有其他词,从而捕捉丰富的上下文信息。
但这种“全局关注”是有代价的。它的计算复杂度和内存占用量,会随着输入序列长度的平方(也就是O(n²))增长。这意味着,如果文本长度增加10倍,计算量和内存需求可能会增加近100倍!这就导致了模型在处理长文档、长对话或者一整本书时,会变得非常非常慢,而且极度消耗硬件资源,也就是我们常说的“键值缓存(KV Cache)”爆炸。
为了解决这个问题,研究者们提出了线性注意力(Linear Attention)。它的计算复杂度只和序列长度线性相关(O(n)),效率极高。但天下没有免费的午餐,早期的线性注意力虽然快,但在表达能力上,也就是模型的效果上,通常不如标准的“全注意力”。
于是,一个核心问题就摆在了我们面前:我们能否创造一种架构,既有线性注意力的超高效率,又能达到甚至超越全注意力的性能呢? 这正是Kimi Linear这篇论文试图解决的问题。
Kimi Delta Attention (KDA) 是什么新东西?
Kimi Linear架构的核心,是一种叫做Kimi Delta Attention (KDA) 的新模块。我们可以把它看作是线性注意力的一种高级进化版,它借鉴并改进了名为Gated DeltaNet(GDN) 的思想。
要理解KDA,我们先得知道线性注意力是怎么工作的。你可以把它想象成一个带有“记忆”的系统,类似于循环神经网络(RNN)。它在处理每个新词时,会更新一个固定大小的“记忆状态(State)”,这个状态压缩了前面所有词的信息。这样一来,它就不需要保存整个序列的KV Cache了。
Kimi的研究者认为,之前的线性注意力之所以效果不够好,一个关键原因是“记忆管理”机制不够精细。而KDA就在这里做了关键改进:它引入了一种“更细粒度的门控机制”。
简单来说,这个“门控”就像一个开关,用来控制记忆的遗忘和更新。之前的模型可能只有一个总开关,对所有记忆通道“一视同仁”地进行遗忘。而KDA则给每个记忆通道都配了一个独立的、精细的开关。这使得模型可以更智能地决定,哪些维度的信息是重要的需要长期保留,哪些信息可以快速忘掉。这种精细化的记忆管理,大大提升了模型的表达能力。

这张图展示了Kimi Delta Attention (KDA)模块最核心的 “记忆更新”和“信息提取” 过程。我们可以把它分成两部分来理解:
1.左边的大公式:如何更新记忆状态 S_t。
2.右边的小公式:如何利用更新后的记忆 S_t 来计算当前步的输出 o_t。
下面的矩阵示意图,就是这个公式的可视化版本,可以结合起来看。
St 代表什么?—— 模型的“压缩记忆”
S_t 的全称是“记忆状态矩阵”(Memory State Matrix)。
可以把它想象成模型在处理到第 t 个词时,对前面所有内容的一个高度压缩的记忆摘要。与标准注意力需要存储所有词的Key和Value不同,线性注意力只需要维护这一个固定大小的 S 矩阵。当新的词进来时,模型不是把新词的Key和Value存下来,而是用它们来更新这个记忆矩阵 S。
现在来拆解 S_t 的计算过程,也就是如何更新记忆:
这个更新过程可以分为三步,对应着图中的不同部分:
第一步:选择性遗忘 (Forgetting)
- 公式部分:
\text{Diag}(\alpha_t) S_{t-1}
- 解释:S_{t-1} 是上一步的“旧记忆”。
\text{Diag}(\alpha_t) 是一个对角矩阵,也就是KDA的 “细粒度门控”。它就像一排精密的开关,分别控制着“旧记忆”S_{t-1} 中不同维度的信息保留多少。
的值接近1,对应的记忆维度就被保留;值接近0,就被遗忘。 - 示意图:图中那个红色的对角矩阵乘以淡蓝色的旧记忆矩阵 S_{t-1},就代表这个过程。
第二步:修正与调整 (Correction)
-
公式部分:
(\mathbf{I} - \beta_t \mathbf{k}_t \mathbf{k}_t^\top) -
解释:这部分是“三角法则”(Delta Rule)的体现。它会对遗忘后的记忆进行一次微小的修正,让记忆变得更精确。你可以把它理解成“温故知新”里的“温故”,在回忆旧知识(经过遗忘的S_{t-1})的同时,根据当前的新线索 k_t (Key)进行一些调整。
-
示意图:图中 (
[单位矩阵] - [向量] × [向量]) 的部分,形象地展示了这个修正操作。
第三步:写入新信息 (Writing)
-
公式部分:
+ \beta_t \mathbf{k}_t \mathbf{v}_t^\top -
解释:这是“知新”的过程,也就是把当前第 t 个词的信息真正地写入记忆。具体来说,就是将当前的“键”k_t 和“值”v_t 关联起来,形成新的知识,然后添加到修正后的记忆中。
-
示意图:图中 + 号后面的
[向量] × [向量]操作。
通过 遗忘 -> 修正 -> 写入 这三步,模型就完成了从旧记忆 S_{t-1} 到新记忆 S_t 的更新。
ot 代表什么?—— 当前步的“输出”
o_t 的全称是 “输出向量”。
如果说 S_t 是模型到目前为止积累的全部知识(记忆),那么 o_t 就是针对当前第 t 个词的“提问”,从这份知识中提取出的相关答案。这个答案就是当前注意力层的最终计算结果,它将被传递给模型的下一层。
o_t 的计算公式非常简洁:
这个过程可以理解为一步:
查询与提取 (Querying)
- 解释:q_t 是当前第 t 个词的“查询向量”(Query Vector),代表了当前这个词对上下文的“提问”。例如,一个动词可能会“提问”它的主语是谁。模型用这个“问题” q_t 去查询刚刚更新好的“记忆” S_t,两者的乘积就是提取出的最相关的信息,即输出 o_t。
- 示意图:在图的右下角,用虚线隔开的部分清晰地展示了这个过程:更新后的深蓝色记忆矩阵 S_t 与橙色的查询向量 q_t 相乘,最终得到橙色的输出向量 o_t。
整个KDA机制,就是通过这个高效的 “更新记忆-查询输出” 循环,来模拟标准注意力机制的效果,从而在保持线性复杂度的同时,实现了强大的性能。

从这张图里可以看到KDA在执行效率上的优势。与另一种叫做DPLR的通用方法相比,KDA在处理长序列时,执行时间要短得多,效率提升了将近一倍,这证明了其设计的硬件友好性。
为什么不只用KDA,还要混合使用呢?
尽管KDA已经非常强大了,但纯粹的线性注意力在某些任务上,比如需要精确无误地从超长文本中检索某个细节时,仍然可能存在理论上的瓶颈。
为了“取长补短”,Kimi Linear采用了一种非常务实的混合架构。它并不是把所有层都换成KDA,而是将KDA层和传统的全注意力层(论文里叫MLA, Multi-Head Latent Attention)结合起来使用。

具体是怎么混合的呢?它们采用了一个3:1的比例:每3个KDA层之后,插入1个MLA层。
我们可以这样理解这个设计:
- KDA层(主力员工):负责处理大部分的序列信息,它们工作效率高,速度快,擅长处理局部和顺序依赖。
- MLA层(项目经理):虽然“出场”次数少,但它能提供一个“全局视野”,让模型能够把不同部分的信息整合起来,进行更高层次的推理和关联。
这种设计非常巧妙,既利用了KDA层的高效率,又通过少量的MLA层弥补了纯线性注意力可能存在的全局信息捕捉不足的问题。最终,它在整体上将KV Cache的使用量减少了75%,同时保证了强大的模型性能。
Kimi Linear的实际表现怎么样?
理论说得再好,也要看实际效果。论文用大量实验来验证Kimi Linear的性能。他们将Kimi Linear模型与两个强有力的基线模型进行了公平对比:一个是纯全注意力模型(MLA),另一个是之前的混合模型(GDN-H)。

我们来看这张论文开头的核心图。图(a)展示了在不同任务上,性能和解码速度的权衡。无论是4k短文本的MMLU-Pro任务(红星),还是128k长文本的RULER任务(蓝点),Kimi Linear都处在“帕累托最优”的位置,也就是在相似的速度下性能最高,或在相似的性能下速度最快。图(b)则显示,随着解码长度增加到1M(一百万)tokens,Kimi Linear的每个token生成时间(TPOT)远低于MLA,速度优势达到了6.3倍。
除了速度,在模型效果上,Kimi Linear也表现出了全面的优势。
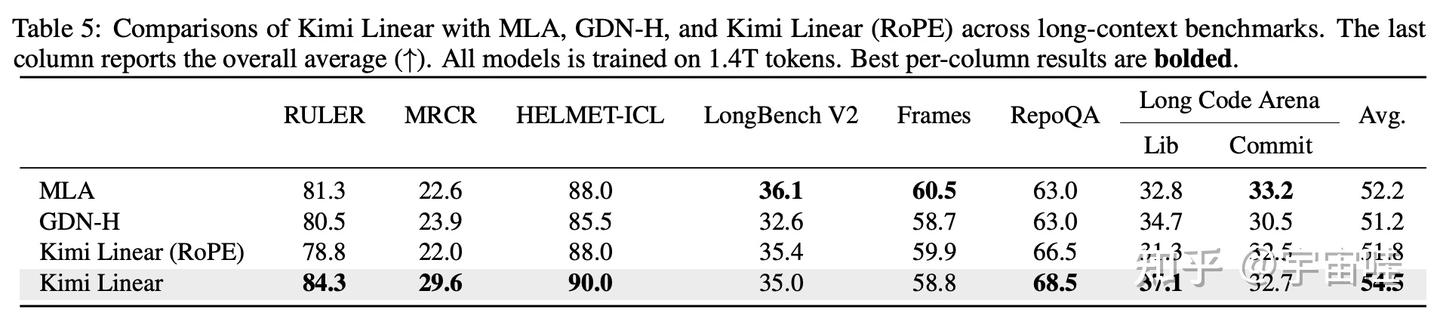
- 预训练和微调阶段(短文本):在通用知识、数学推理、代码生成等多个基准测试上,Kimi Linear的表现全面超过了MLA和GDN-H。
- 长文本评测:在处理128k长度的文本时,Kimi Linear的优势更加明显,平均分(Avg.)最高,达到了54.5,显著领先。
- 强化学习(RL)阶段:在需要模型进行复杂推理的RL训练中,Kimi Linear的提升速度和最终性能也明显优于全注意力模型MLA。
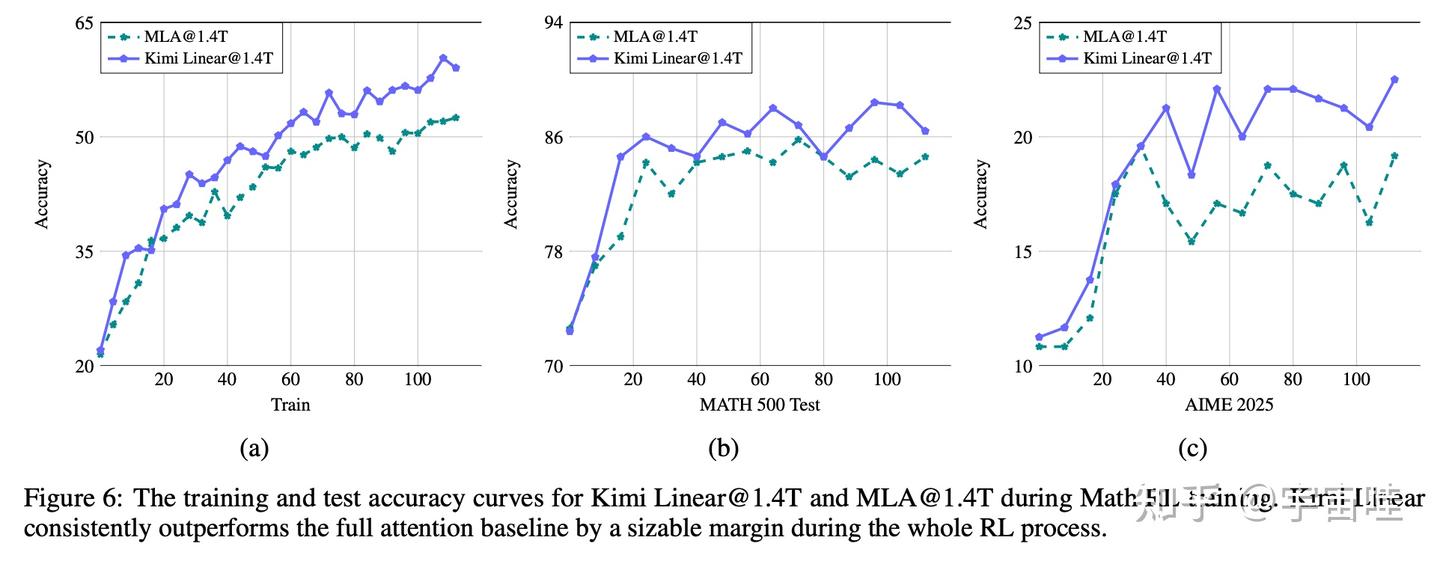
这张图展示了在数学RL训练过程中,Kimi Linear(蓝线)的准确率增长速度和最终达到的高度,都明显超过了MLA(绿线),证明了其架构在复杂推理任务上的学习效率和潜力。
总而言之,大量的实验结果表明,Kimi Linear的设计在各种场景下都成功地实现了性能和效率的双重提升。
总结
首先,它提供了一个非常成功和实用的范例,证明了混合架构是当前通往高效长文本大模型的一条有效路径。它不是一个微小的改进,而是在架构层面的一次成功探索,并且给出了具体的实现方案。
其次,Kimi Linear的设计(尤其是3:1的混合比例和KDA的细粒度门控)在性能和效率之间取得了出色的平衡,并且被证明在各种任务上都行之有效。这对于想要构建自己模型的开发者来说,有很强的工程参考意义。
最重要的是,论文的作者团队开源了KDA的底层算子、vLLM的集成以及预训练好的模型。这意味着社区里的任何人都可以使用、验证和改进这项技术。这种开放的态度极大地推动了整个领域的技术发展。
总的来说,Kimi Linear更像一份详尽的“技术报告”,而不是一篇纯理论文章。它向我们展示了如何构建一个在长文本时代既强大又高效的大模型。如果你对LLM的底层架构感兴趣,或者对如何处理超长上下文问题感到好奇,这篇论文绝对值得你花时间去仔细阅读。
源链接:
https://arxiv.org/abs/2510.26692
https://github.com/MoonshotAI/Kimi-Linear