作者:瑕疵很多的大宝贝
https://zhuanlan.zhihu.com/p/1965822436948842025
声明:本文翻译自NVIDIA Megatron Core Dev Blog:Optimizing DeepSeek-V3 Training Performance on NVIDIA GB200 NVL72本文对提到的 GPU 型号进行了模糊化处理,仅供技术讨论,具体信息请参考原文。另外叠个甲,有一些单词我就不翻译了,比如 baseline、kernel、fusion 等,以及一些模型结构和算子如 attention、router 、dispatch、combine 等,指代更加明确。
以下是正文。
本文将介绍我们基于 Megatron Core(以下简称 MCore)+ Transformer Engine(以下简称 TE) 的软件栈,在 Grace Blackwell 机柜式系统上使用 256 张 GPU,使用 MXFP8 精度预训练 DeepSeek-V3 模型,如何一步步将性能优化到 970 TFLOPS / GPU,相比于 Hopper 平台上的 380 TFLOPS(参考这篇文章的估计)加速了 2.55 倍。相关的特性已经,或将陆续开源到 Megatron Core 和Transformer Engine仓库。我们也同步提供了复现文档 A Guide to Reproduce DeepSeek-V3 Pre-training Performance on GB200,包括了 Dockerfile、依赖的软件包、集群配置和训练参数等。
方法论
优化一个模型的预训练性能,我们的方法论一般是:
1.找到一个性能基线(baseline)。这个 baseline 一般是当前软件栈在给定的硬件平台和训练精度下,通过调整模型并行、重算等配置能取得的最好性能。
2.使用性能分析工具如 Nsight System(以下简称 Nsys)或者 PyTorch Profiler ,抓取 profile 文件(通常也会称之为 timeline 或者 trace),并进行分析,找到性能的瓶颈。例如,有没有显著的暴露出来的通信、有没有占比显著较高的 kernel、GPU kernel 排布是否紧密等。我们通常会更倾向于使用 Nsys,因为在 NVTX 的帮助下,它对于 CUDA API 以及 GPU 上 kernel 的运行情况展示更加清晰。
3.针对性能瓶颈进行优化。然后重复 1-3 步,直至达到性能预期。
1. Baseline
DeepSeek-V3 创新性地使用了 FP8 混合精度进行预训练,在不牺牲模型精度的前提下,节省了显存,提升了训练速度。我们将 DeepSeek-V3 所采用的 FP8 recipe,即激活值(activation) 以 1x128 的粒度进行量化、权重(weight) 以 128x128 的粒度进行量化,称为 blockwise scaling recipe。MCore (v0.13+)和 TE (v2.3+)已经对其进行了支持。
而在 Blackwell 平台上,得益于第五代 Tensor Core 对 MXFP8 格式的原生支持,我们采用了 MXFP8 recipe 这一更细粒度的量化方案进行训练,即 activation 和 weight 均以 1x32 的粒度进行量化、同时使用 E8M0 作为缩放因子(scaling factor 或 scale)的格式。
这里顺便介绍一下 Blackwell 平台上 MXFP8 GEMM 和 Hopper 平台上 Blockwise FP8 GEMM 实现方案的区别。在 Hopper 平台上,由于 Tensor Core 本身不支持带 scale 向量的乘法,因此量化的粒度必须大于等于 GEMM 计算的块(tile)大小。这也决定了在 Hopper 平台上,1x128 几乎是可用的最细的量化粒度了,如果使用更细的粒度进行量化,GEMM 的性能会有非常大的损失(因为必须使用更小的块进行 GEMM 计算)。而 Blackwell 平台由于原生支持 MXFP8,GEMM 中的反量化过程(即乘以 scale)在 Tensor Core 内部完成,因此全程不需要 CUDA Core 的参与,能够达到更好的性能,同时能够支持更细粒度的量化(1x32)。
在我们开始在 Grace Blackwell 机柜式系统上优化 DeepSeek-v3 的时间点,我们的 baseline 已经包含了如下的特性:
1.MXFP8 recipe,即模型中所有的 linear 层的 fprop/wgrad/dgrad 的输入以 1x32 的粒度进行量化,而 Scaled Dot Product Attention (SDPA)/Embedding/LM Head/Router/Loss/Optimizer 等仍然保持在原有的高精度。关于 FP8 recipe 的细节,可以参考我们在2025年6月份的 NVIDIA AI Open Day(中文视频)和 GTC 2025(英文视频)上的分享。在 MCore 中开启的选项为 --fp8-recipe mxfp8 --fp8-format e4m3。
2.Blackwell 平台上 Multi-head Latent Attention (MLA) kernels 的支持,由 cuDNN 9.11 提供。
3.MXFP8 Grouped GEMM,使用 multi-stream + cuBLAS 的实现。这种实现的优点是,我们能以最快的速度支持各种量化方案:只要 single GEMM 支持,我们就能有一个性能不错的 Grouped GEMM 的实现。我们的 multi-stream + cuBLAS 的方案在 K=7,168,N=2,048 的 shape 上可以达到 2,672 TFLOP/s (flush L2),性能基本与高度优化的 Grouped GEMM 相当 [4]。此外,我们也会持续对 Grouped GEMM 的性能进行优化。在 MCore 中开启的选项为 --moe-grouped-gemm。
4.Kernel fusion,如
- Yarn RoPE fusion,默认开启
- Permute fusion,在 MCore 中开启的选项为 --moe-permute-fusion。
- Cross-entropy loss fusion,在 MCore 中开启的选项为 --cross-entropy-loss-fusion。
5.支持任意的 Pipeline Parallelism (PP) layout ,使得 PP 更加均衡,MCore 中对应的选项为 --pipeline-model-parallel-layout [layout]。
6.Primary weights in FP8。FP8 混合精度训练有两种权重的保存方案,一种是保留 BF16 的 model weights(区别于保存在 optimizer 中的 master weights),在每个 global batch 的第一个 micro batch 将 model weights 量化到 FP8 并保存下来(根据具体的 FP8 recipe 和硬件平台,可能会额外包含一份转置的 FP8 weights)。这种方案的优点主要是简单,不需要改动 optimizer 部分,而缺点则是会同时保留一份 BF16 和一份 FP8 的 model weights,导致 FP8 混合精度训练占用的显存反而比 BF16 还高。第二种方案就是只保留 FP8 的 model weights,这种方案的优点是可以省显存,同时在开启 MCore 的 Distributed Optimizer(ZeRO-1)的情况下,能够以 FP8 的精度进行模型参数的 AllGather,从而减小 DP 的通信量。而缺点是实现起来非常复杂,特别是结合了 Distributed Optimizer 之后,不同的 FP8 recipe 都需要 case by case 的处理。细节也可以参考我们在 2025年6月份的 NVIDIA AI Open Day上的分享(中文视频)。在 MCore 中开启的选项为 --fp8-param-gather。
7.BF16 optimizer states。根据技术报告,DeepSeek-v3 使用了这个特性。当然,这个特性是和训练精度正交的,无论是 BF16 还是 FP8 训练,都可以使用。在 MCore 中开启的选项为 --use-precision-aware-optimizer --main-grads-dtype fp32 --main-params-dtype fp32 --exp-avg-dtype bf16 --exp-avg-sq-dtype bf16。
8.Fine-grained recompute。通过重算一些计算量较小、但显存占用较大的 module,以较小的代价节省了大量显存,从而尽量减少模型并行。在我们的 baseline 版本中,fine-grained recompute 仅支持 BF16,因为 FP8 训练需要额外的处理。在 MCore 中开启的选项为 --recompute-granularity selective --recompute-modules [modules]。
9.Token dispatcher 支持 NCCL AlltoAll 和 DeepEP 两种实现。但在我们测试 baseline 性能的时间节点,DeepEP 还不支持 Grace Blackwell 机柜式系统上的 Multi-Node NVLink(MNNVL),所以我们只能使用基于 NCCL AlltoAll 的实现。在 MCore 中开启的选项为 --moe-token-dispatcher-type alltoall。
基于上述软件栈,我们在 Grace Blackwell 机柜式系统上,使用 256 张 GPU、 TP1/PP8/VPP4/EP32/MBS1/GBS2048 的并行配置,开启了 dense 层(即 DeepSeek-v3 的前三层)MLP 部分、MoE 层 MLA up projection 的重算( --recompute-modules mlp up_proj),PP layout 为 --pipeline-model-parallel-layout Et|(tt|)*30L (共 32 个 stage,其中第一个 stage 为 Embedding + 1 层 transformer layer,最后一个 stage 为 Loss,中间 30 个 stage 为 2 层 transformer layer),使用 AlltoAll token dispatcher (NCCL backend),开启 BF16 optimizer states, 达到了 494 TFLOPS/GPU 的性能。而这个性能显然不太令人满意,接下来我们将对其进行分析和优化。
2. 性能优化
抓取 baseline 对应的 Nsys timeline 进行分析,以一个 forward iteration 为例,可以看到,最大的性能问题是:kernel 之间有较大的空隙,CPU launch 的速度赶不上 GPU 执行的速度。我们把这种现象称为 CPU overhead 或者 host boundedness,不同于我们通常意义上的 launch bound 问题,这种 overhead 主要来自于 Python 代码(如循环、getattr 等)、PyTorch 的 Python 和 C++ 逻辑代码(例如一个简单的 torch.empty,不会调用任何 CUDA kernel,但是却会在 Host 侧产生几微秒的 overhead)、CUDA kernel launch 等。出现这种现象的原因是,一方面 GPU 执行 kernel 的速度越来越快,导致没有足够的时间去掩盖(overlap) CPU 的执行时间,另一方面 FP8 training 和 fine-grained MoE 模型引入了更多的量化、router 等 kernel。解决 CPU overhead 的思路主要是通过 kernel fusion 来减少 kernel 的数量,并通过 CUDA Graphs 进行 graph launch 来跳过(bypass)CPU 侧的一些工作。
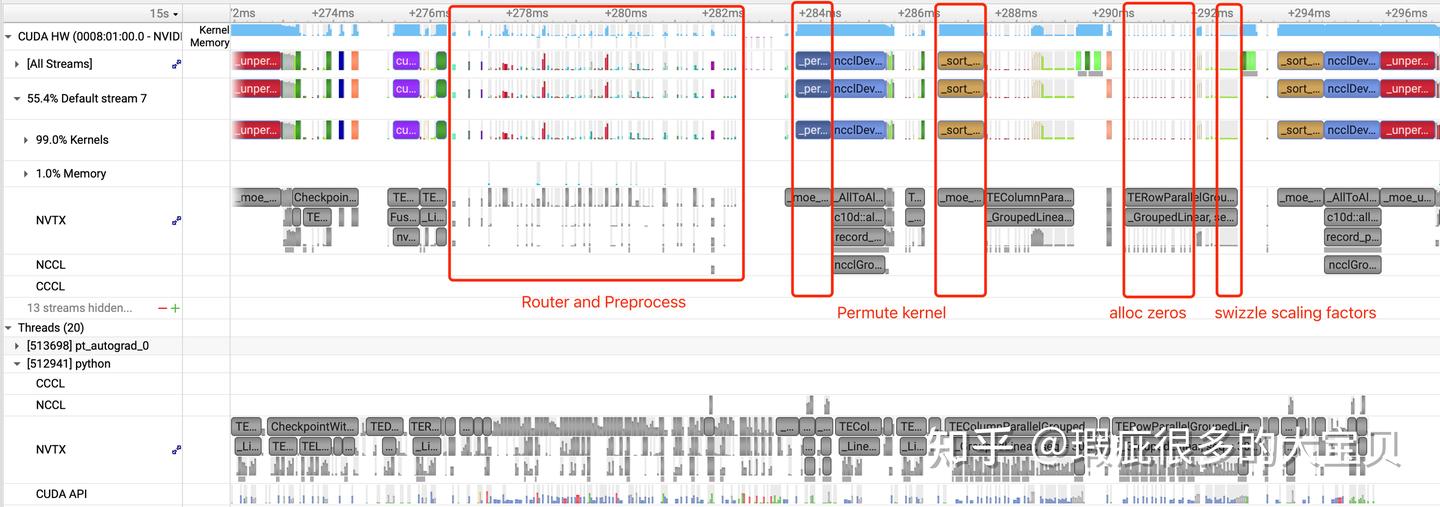
除了 CPU overhead,我们还可以看到其他几个比较明显的问题:
- Permute kernel 的长度明显不太正常, 暗示这个 kernel 需要优化。
- Expert 部分在 GEMM 之前,有大量的细碎 kernel,这显然是不正常的,我们需要定位到这些 kernel 在干什么,能否消除或者进行 fuse。
- 基于 NCCL alltoall 的 token dispatcher 需要显式的 global token permutation,因此不是最优的。
- 由于 CPU overhead,recompute MLA up projection 的开销比预期中大。
因此我们的优化计划大概是:
1.Kernel fusion and optimization
2.通过节省显存来开启更多其他的优化,例如减少 recompute、开启 CUDA Graphs 等
3.通过 CUDA Graphs 降低 CPU overheads
4.CPU 侧的优化
5.HybridEP :基于全新的 API 开发的 Expert Parallel(EP)通信库,功能类似于 DeepEP,但能够以更少的 SM 达到更高的带宽,同时完全支持 MNNVL
2.1 Kernel Fusion and Optimization
2.1.1 优化 Permute kernel
MoE 模型中的 permute 操作是在显存上对 tokens 进行重排,以便进行通信或者计算。使用 NCCL backend 的 AlltoAll dispatcher 在 EP 通信的前后分别需要一次 global 和 local permute。而使用 DeepEP 或 HybridEP 的 Flex Dispatcher 将 global permute fuse到了通信 kernel 中,不需要显式将 tokens 复制 top-k 份,但仍然需要在 EP 通信结束之后使用一个 permute kernel 将分发到不同 local expert 的 tokens 复制并重排。TE PR 1927 大幅提升了 top-k 远小于 expert 数量的情况下的性能(例如DeepSeek-v3 的 256 experts,top-k=8),最多有 10 倍的加速。MCore 中开启的选项为 --moe-permute-fusion,同时我们推荐设置 --enable-experimental 来开启更激进的 fusion。
2.1.2 对 MXFP8 量化部分的显存分配进行了 fuse
对照代码和 Nsys timeline,我们发现 Expert 部分的细碎 kernel 主要有两种,一种是分配 MXFP8 的 scaling factor 时的 torch.zeros,一种是对 scaling factor 进行 swizzle。之所以需要使用 torch.zeros 而不是 torch.empty 来分配 scaling factor 的显存,是因为 Tensor Core 要求 scaling factor pad 到特定的 shape,pad 部分填充 0。在优化 2.1.3 中,我们将这些填充 0 的操作 fuse 到了 swizzle scaling factor 的 kernel 中,从而完全移除了 torch.zeros 调用。
对每一个 tensor 进行 MXFP8 量化时,需要分配 4 个 tensor,即 {row-wise, col-wise} * {data, scaling factor}。前文提到,即使使用 torch.empty 来分配显存,每次 PyTorch API 调用会产生几微秒的 overhead,因此造成了严重的 CPU overhead。我们这里解决的方法是提前为 data 和 scaling factor 分配一大块显存 buffer,然后通过计算指针偏移的方式,用 aten::from_blob API 从这块 buffer 中构建 tensor,从而避免大量的 torch.empy/zeros。具体实现可以参考TE PR 1793、1934 和 2134,这项优化取代了之前的实现,默认开启。
2.1.3 Fuse 了多个 swizzle scaling factor 的 kernel
前面提到,Expert 部分的细碎 kernel 的第二种是对 scaling factor 进行 swizzle。这是因为 Tensor Core 要求 scaling factor 按照一定的规则 swizzle(参考 cuBLAS 文档)。我们将对多个 input tensor 的 scaling factor 的 swizzle 操作 fuse 成一个 kernel,并在其中处理了 pad 部分填 0 的情况,因此可以完全消除上述分配 buffer 时的 torch.zeros kernel,并且减少了 swizzle kernel 的数量,缓解了 CPU overhead。具体实现可以参考 TE PR 2019,这项优化取代了之前的实现,默认开启。
另外,理论上我们可以将 swizzle scaling factor fuse 到量化 kernel 中,之所以目前没有这么做,主要是考虑到在需要通信 MXFP8 数据的时候,例如 TP 和 EP Dispatch(目前还不支持),未经 swizzle 的 scaling factor 更方便通信。当然理想情况是将量化 kernel 实现成可配置的,在需要进行通信的地方不进行 swizzle,反之进行 swizzle,从而避免冗余操作。
2.1.4 Router 部分的 Kernel fusion
Router 部分包含大量的 element-wise 算子,主要是为了计算 routing map,即 token 应该被分配到哪些expert,以及计算和统计 aux loss。我们对其中的一部分 kernel 进行了 fuse,将 router 部分的 kernel 的总数从 72 个减少了 31 个。具体实现可以参考 TE PR 1883(部分实现参考了Shopee @LLM迷思 给 MCore 提的 PR),MCore 中开启的选项为 --moe-router-fusion。这里不能完全 fuse 的原因是,剩下的 kernel 有一些被通信 kernel 分隔,不容易 fuse。还有很多 kernel 分散在不同的 Python 逻辑代码里,如果强行 fuse,会破坏 Python 的代码结构。而且后续我们会对 router 部分使用 CUDA Graphs,已经可以很好的解决 CPU overhead 的问题,因此继续 fuse 的意义不大。
2.1.5 量化 kernel 和正则化 kernel 的 fusion
cuDNN 支持将 MXFP8 的量化 fuse 到正则化 kernel 里,包括 Layernorm 和 RMSNorm。我们推荐使用 cuDNN 9.14 并设置以下环境变量来开启这项优化。
NVTE_NORM_FWD_USE_CUDNN=1
NVTE_NORM_BWD_USE_CUDNN=1
在同样的并行配置下,我们测得优化 2.1.1 和 2.1.2 将端到端(E2E)性能提升了 35 TFLOPS,优化 2.1.3 提升了 35.5 TFLOPS,优化 2.1.4 提升了 10.5 TFLOPS,优化 2.1.5 提升了 13.8 TFLOPS。开启了优化 2.1.1、2.1.2、2.1.4 的 Nsys timeline 如下(之所以没有包含 2.1.3 和 2.1.5,是因为这两项优化是后期加入的,此时的 timeline 已经叠加上了其他的优化,无法直接比较):
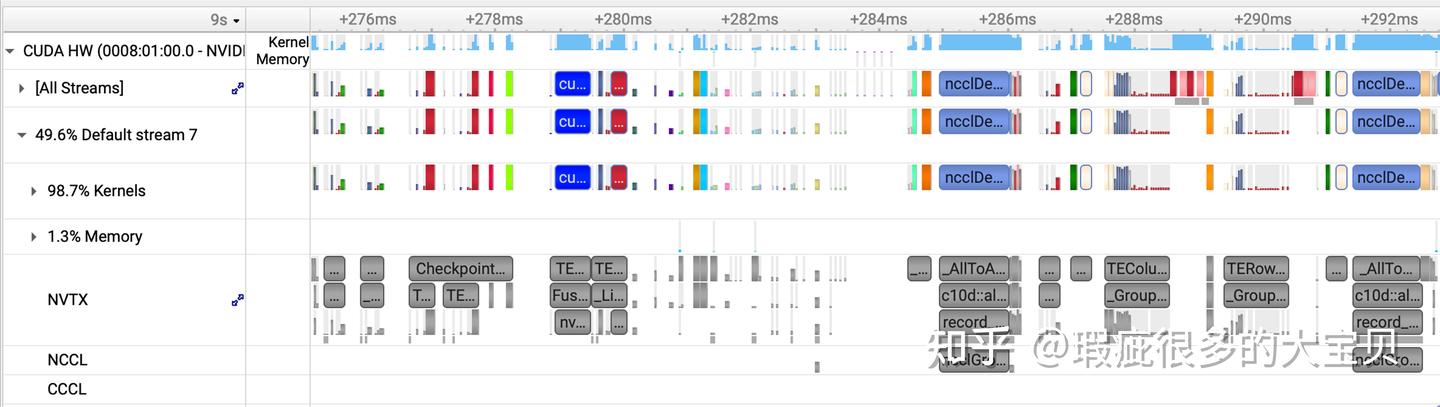
虽然看上去仍然不是很令人满意,但已经有所改善。
2.2 Memory optimization
2.2.1 DeepEP
理论上来说,在 Grace Blackwell 机柜式系统上开启专家并行,所有的 EP 通信都在 NVLink domain 内,得益于 MNNVL 的双向 1.8 TB/s 的高带宽,EP 通信将被极大的加速。但 DeepEP 目前仍然没有官方支持 NVLink domain 大于 8 的场景。我们在这个社区 PR 的基础上,支持了 EP32 的场景。但这个支持并没有得到很好的优化,在 EP32 的场景上使用 24 个 SM,dispatch 只能达到约 400 GB/s,combine 只能达到约 190 GB/s 的 algorithm bandwidth,距离 MNNVL 的理论单向带宽 900 GB/s 有较大的差距。因此我们切换到 DeepEP 之后,并没有拿到通信的收益,而是拿到了一些节省显存的收益(DeepEP 不需要显式的 global permute,因此降低了显存峰值消耗),并降低了CPU overhead(DeepEP 使用一个 fused kernel 进行 EP 通信的 preprocess,将 router 和 preprocess 部分的 kernel 数量进一步降低到了 17个),所以我们将 DeepEP 放在了 Memory optimization 的部分。
在 MCore 中开启 DeepEP 的选项为:
--moe-token-dispatcher-type flex
--moe-flex-dispatcher-backend deepep
2.2.2 Fine-grained recompute for FP8
通常的 recompute 会对多个 module 进行重算,从而省掉所有中间的 activation,但重算一个 module 是没有效果的。而我们想做一些更细粒度的重算,即重算一些计算强度较小但显存占用较大的 module,从而以较小的性能代价节省较多的显存。因此我们在MCore里实现了一种output discarding recompute,来支持重算单个 module。
此外对于 FP8,我们需要额外考虑,被丢掉的 output 的 fp8 量化版本,可能会被后面的层保存,此时就达不到节省显存的目的。因此我们需要告诉 fp8 module,保存原本的 input(从而能够被正确丢掉)而不是量化版本。但代价是反向时需要重新量化。实现细节可参考 [MCore commit] 和 [TE PR 1865]。
这个技术同样适用于 SDPA 和其后的 Linear module(称为 Projection Linear)。因为 SDPA 是一个特殊的 module,它会保存自己的 output 来做反向计算,而 Projection Linear 会保存 input 来做反向计算。在 BF16 training 中,这两个 tensor 实际是同一个 tensor,只占用一份显存。而 FP8 training 中,SDPA 会保存一份 BF16 的 output tensor,而 Projection Linear 会保存一份 input tensor 量化后的FP8 tensor,这两个 tensor 不共享显存,因此会导致实际保存了 1.5 倍的大小。我们可以用类似的手段告诉 Projection Linear 保存原本的 input 而不是量化版本,从而达到节省显存的目的,同样地,代价是反向时需要重新量化。
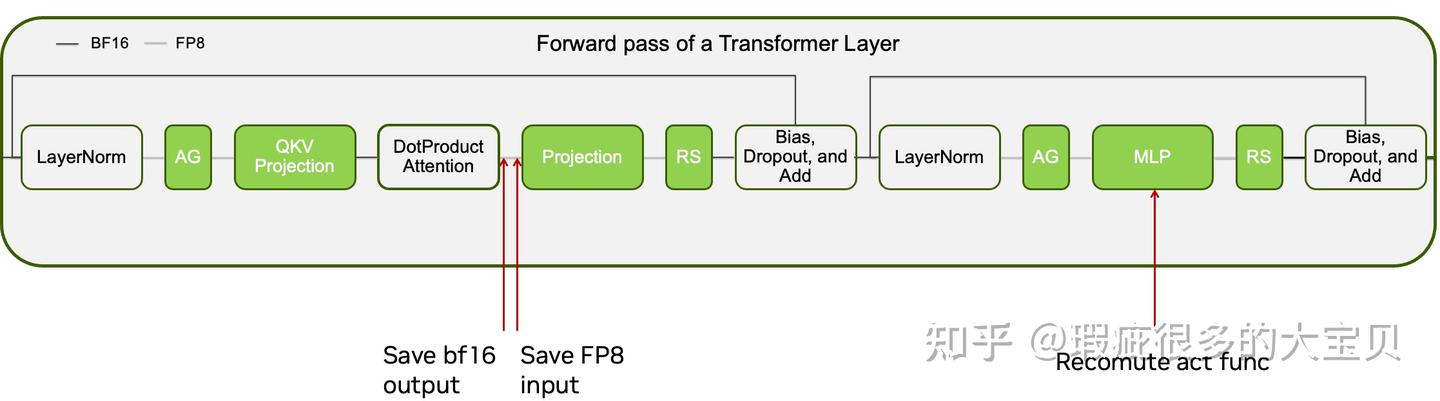
E2E 测试表明,enable DeepEP 减少了router 和 preprocess 部分的 CPU overhead,提升了 54.3 TFLOPS的性能。而使用 fine-grained recompute,消除了 SDPA 和 Projection 之间保存的多余的 activation,使我们能够关掉 MLA up projection 的重算,提升了 44.7 TFLOPS 的性能。原因是,MLA up projection 虽然计算密度较小,理论上重算的代价较小,但是因为这部分也有严重的 CPU overhead,所以关闭重算之后能够获得一定的性能提升。相应地,重算的参数改为 --recompute-modules mlp moe_act。下图是开启了 DeepEP 并使用新的重计算参数的 Nsys timeline:

2.3 CUDA Graphs
CUDA Graphs 是解决 CPU overhead 的终极武器,它能够将一系列的 GPU kernels capture 成静态的 graph,在后续的 iteration 通过 replay 的方式一次性 launch 整个 graph 里的 kernel,完全 bypass CPU 上的逻辑。但也因此 CUDA Graphs 要求被 capture 的部分必须是静态的,不能有 dynamic shape。在 dropless MoE 模型中,routed experts 部分是动态的,而其他部分均是静态的,包括attention、router、EP preprocess 和 shared experts。因此我们希望能够将这静态的部分全部 capture 起来,完全消除掉 CPU overhead。
我们在 MCore 和 TE 里开发了 Partial CUDA Graphs 的功能,允许我们仅对模型中的一部分进行 capture。在 MCore 中的参数为 --cuda-graph-scope,支持的选项有:
- attn: capture attention 部分。
- mlp: capture dense layer 的 MLP 部分,例如 DeepSeek-V3 的前三层为 dense layer。
- moe: capture moe 部分,仅支持 token-drop MoE。
- moe_router: capture moe router 部分。在不开启 shared expert overlap 时,会同时 capture shared experts。
- moe_preprocess: capture EP 的 preprocess 部分,必须和 moe_router 同时使用。
- mamba: captures the mamba layer.
在DeepSeek-v3中,我们最终使用了 --cuda-graph-impl transformer_engine --cuda-graph-scope attn moe_router moe_preprocess来 capture attention、router、EP preprocess 和 shared experts。Partial CUDA Graphs 只支持 --cuda-graph-impl transformer_engine。另一种 CUDA Graphs 的实现被称为 local,它支持 full-layer 和 full-iteration 两种模式,但目前还不支持 dropless MoE 模型。
CUDA Graphs 的一个限制是其会占用额外的显存。Partial CUDA Graphs 总共需要 capture LM2 个 graph,其中 L 是每个 GPU 上 transformer layer 的层数,M 是一个 step 中包含的 iteration 数量,2 是因为我们需要为前向和反向计算分别 capture 一个 graph。这些额外的显存来自于三个方面:
1.CUDA Graphs 本身的结构会占用一些显存,其大小和 CUDA Graph 的节点数量成正比,但是总量是比较小的,基本可以忽略。
2.CUDA Graphs 需要使用一个独立的、静态的显存池,这个显存池里的显存不能再被 PyTorch 的 caching allocator 复用。
3.每个 CUDA Graph 需要一个静态的输入和输出 buffer。
我们为了优化 CUDA Graphs 的显存占用做了一系列的优化。对于上述的第 2 点,我们按照 replay 的顺序 capture CUDA Graphs,让所有的 CUDA Graphs 使用同一个显存池,尽量降低显存碎片问题。对于上述的第 3 点,我们尽可能地在不同的 PP stage 之间复用显存 buffer ,详情可以参考 TE make_graphed_callables() API 的 _order 和 _reuse_graph_input_output_buffers 参数。此外,我们还对于 MoE 模型、不同的 FP8 recipe、灵活的 PP layout 等做了一系列 CUDA Graphs 的适配和优化,来保证它们的准确和高效。
在下面这幅图中,展示了我们开启 CUDA Graphs 之后的 timeline(这幅图里还包含了 2.1.3 fuse swizzle scaling factor)。可以看到,CPU overhead 问题有了很大的缓解,目前只有 routed experts 部分还有一些 CPU overhead。开启 CUDA Graphs 总共提升了 84.8 TFLOPS 的 E2E 性能。
此时,我们可以看到,DeepEP 的性能问题开始变成一个瓶颈,后续我们会有工作对其进行优化。

2.4 CPU-side Optimizations
将bindpcie 添加到每个训练进程的启动阶段,从而自动探测本机的 GPU/NUMA 拓扑,并用 numactl 将该进程下的所有线程绑定到与其操作的 GPU 对应的本地 CPU NUMA 节点,可以提升 70.6 TFLOPS 的性能。
这里值得一提的是,由于 FP8 训练中 CPU overhead 是一个主要的性能问题,而在语言模型的训练任务中,通常只有少数几个 CPU 核心负责 launch kernel,处于高负载状态。例如在 DGX/HGX NVL8 的系统上,如果进行绑核操作,那么 8 个 GPU 分别对应 8 个进程,对应 8 个 CPU 核。因此我们推荐将 CPU 配置为允许部分核心 boost 到最高频率的模式,可以显著提升 FP8 训练的性能。
借助了 CPU 侧的性能分析,我们正在进行了一些 TE 的 CPU 侧代码的简化工作,包括减少不必要的检查、PyTorch API 调用、CUDA 调用等。 此外,我们还在和 CPU 专家一起探索其他 CPU 层面的优化。
2.5 HybridEP
HybridEP 是 NVIDIA 全新开发的 EP 通信库,功能与 DeepEP 类似,但是能够完全释放 NVL72 架构的性能潜力,同时也支持 Hopper 平台上节点内和节点间的通信。HybridEP 主要具有以下特点:
- 完全适配 NVL72 架构,在 NVLink domain 内,使用 TMA 进行数据拷贝,最小化指令数,减少资源占用。
- 使用 IBGDA 技术对跨 NVLink domain 的 RDMA 通信进行深度优化。
- 在数据分发过程中确保没有任何冗余通信。
- 在 kernel 层面完全异步,并适配了 CUDA Graphs。
- 可以灵活调节占用的 SM 数量,并且用尽量少的 SM 实现优异的性能。
HybridEP 完全适配 NVL72 架构,能够以较少的 SM 资源达到较高的传输带宽。
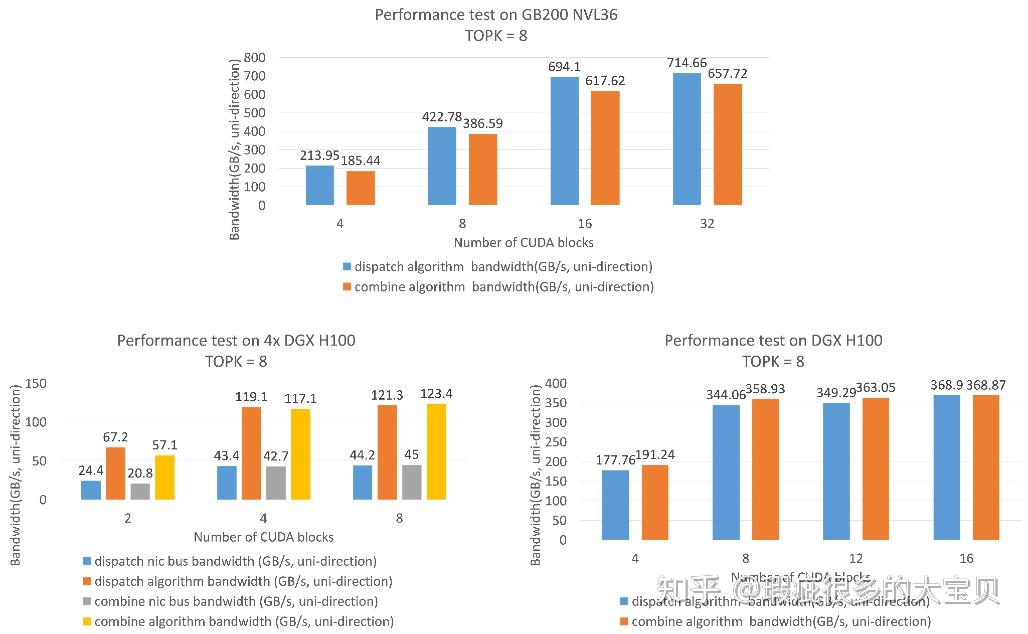
值得一提的是,虽然我们这里只报告了 EP36 的性能,但 HybridEP 实际上支持完整的 NVL72。因此如果未来有模型设计成 expert 数是 72 的倍数,那么 HybridEP 可以充分利用 NVL72 的带宽。这也体现了模型设计和硬件架构相结合的思想。
HybridEP 在接入 MCore 中需要解决一个问题,即实现中,我们需要注册一些特殊的 buffer,使其能被同一个 NVLink domain 中其他的 rank 访问。而由于 dispatch 的输出和 combine 的输入,都存在于 HybridEP 自己注册管理的 buffer 中,这个 buffer 在当前 rank 上是全局唯一,并且在 layer 之间复用的。我们需要一次额外的 D2D(Device to Device)copy,把 dispatch kernel 的输出从 buffer 拷贝到下游需要的 PyTorch tensor 中,或把 combine kernel 的输入从上游的 PyTorch tensor 拷贝到 combine 的输入 buffer 中。而这个 D2D copy 的时长约为通信时长的 10%-20%。
以 EP dispatch 加上其后的 permute 为例,我们实际上需要 3 次对 global memory 的写操作:
1.EP dispatch:将通信的结果写入 HybridEP managed buffer
2.D2D copy: 从 HybridEP managed buffer 拷贝到一个普通的 PyTorch tensor 中
3.Permute: 从 PyTorch tensor 复制并拷贝到permute 的输出,作为 experts 的输入
因此我们可以选择将这个 D2D copy 与后续的 permute 进行 fuse,即在 permute 的同时,完成了 HybridEP managed buffer 与普通 PyTorch tensor 之间的数据搬运工作。进一步的,由于 cuBLAS FP8 GEMM 要求输入的 M 维度对齐到 16(per-tensor recipe 或 blockwise recipe) 或 32(MXFP8 recipe),而 permute 产生的输出很有可能不满足这个要求, 需要在 M 维度进行 pad。这个 pad 任务本质也是一个 D2D copy,也被我们 fuse 到了 permute 的过程中。
在 MCore 中开启 HybridEP 的选项为:
--moe-token-dispatcher-type flex
--moe-flex-dispatcher-backend hybridep
下图展示了我们使用 HybridEP 优化了 EP 通信和 permute/pad 之后的 timeline,提升了 113.6 TFLOPS 的 E2E 性能。

HybridEP 已经开源到 DeepEP 仓库的 HybridEP 分支,欢迎大家试用。
3.总结和展望
我们从 494 TFLOPS 的 baseline 出发,通过性能分析-优化的多轮迭代,最终达到了 970 TFLOPS,取得了 1.96 倍的性能提升。在这里感谢 NVIDIA DevTech 团队的同事们,以及 NVIDIA Compute Arch/TE/cuBLAS/cuDNN 等多个团队的出色工作和协作,我们也会持续优化 MoE 模型的训练性能。
以下是我们按照时间排序的优化历程:
 图
图
3.1 未来的工作
1.完全消除 CPU overhead。我们希望消除 MoE 模型中的 device-host sync(其目的是拿到 tokens per expert 的信息),从而能对整个模型使用 CUDA Graphs,完全消除 CPU overhead。我们使用一个小的代理模型进行估计,这项优化能取得至少 10% 的额外性能收益。可参考 MCore MoE 的 roadmap。
2.扩展到更大规模的 GPU 数量。当前我们的并行配置已经被 GPU 数量限制住了(EP32 * PP8 = 256 GPUs),如果扩展到 512 卡上,我们可以探索 EP64 的性能。理论上由于 EP64 仍然在 NVLink domain 内,因此其通信开销仍然较小。而大 EP 可以减少 local expert 的数量,从而减少量化等开销,并提高 Grouped GEMM 的性能。
3.探索利用 NVLink-C2C 的 CPU offloading 技术。由于 Grace Blackwell 机柜式系统上有 NVLink-C2C,CPU 和 GPU 之间有相比于 PCIe 更快的连接,因此 offloading 是一个非常有前景的特性。例如,借助 CPU offloading,我们能否进一步缩小模型并行的大小、或者将 MBS 提升到 2?如果可以,那将极大提升计算强度,前面提到的很多 CPU overhead 的问题可能就不存在了。
4.持续的Kernel 性能优化和更激进的 Kernel fusion 策略。例如 Grouped GEMM、SDPA kernel 的性能优化,GEMM + activation + quant 的 fusion 等。
3.2 一些讨论
1.Q:在 Grace Blackwell 机柜式系统上为什么我们没有使用 FP8 dispatch?
A:FP8 dispatch 不是一个免费午餐,由于我们只能传输 row-wise 的 FP8 数据,因此我们需要一些额外的 “de-quantize and re-quantize” kernel 来计算 col-wise FP8 数据用于反向计算。这些 kernel 的开销抵消了 FP8 dispatch 节省的通信时间。
2.Q:在 Grace Blackwell 机柜式系统上为什么我们没有使用 1F1B AlltoAll overlap(一种类似 DualPipe 的 inter-batch overlap 方案,详情参见简装版 deepseek dualpipe: 基于 interleaved 1f1b 的 moe 通信计算 overlap)?
A:首先得益于 NVL72,EP 通信非常快,overlap 的必要性不大。其次 1F1B AlltoAll overlap 也不是免费午餐。它将前向和反向分成了多个 stage 进行调度,不同的 stage 之间有一些同步,从而加重了 CPU overhead,因此在 Grace Blackwell 机柜式系统上总体是负收益。我们希望在进一步解决 CPU overhead 的问题之后,重新评估 1F1B AlltoAll overlap 的收益。
3.Q:相比于 Hopper 平台有多少性能提升?
A:DeepSeek 的技术报告里没有公布其预训练阶段的 TFLOPS,但有一些文章对其进行了估计,大约在 380 TFLOPS 左右,因此 Grace Blackwell 机柜式系统上的 970 TFLOPS 达到了 2.55 倍的性能提升。这个数字甚至超过了 Grace Blackwell 机柜式系统相比于 Hopper 平台在单卡 FP8 算力上 2.5 倍的提升。我们知道,模型中只有一部分算子(如 GEMM 和 SDPA 等)能受益于 Tensor Core 算力的提升,所以总体的加速比通常会小于 2.5 倍。这得益于 Grace Blackwell 机柜式系统上的 Multi-Node NVLink 使得我们能够进一步优化 EP 通信,同时其更大的显存可以让我们探索更优的并行配置。
4. 相关资源
环境和训练任务启动脚本
1.A Guide to Reproduce DeepSeek-V3 Pre-training Performance on GB200。复现文档,包括了所需的 Dockerfile、依赖的软件包、集群配置和训练参数。
2.Megatron-MoE-ModelZoo。提供了使用 MCore 端到端训练常见模型(如DeepSeek-V3、Qwen3等)的配置和启动脚本。
技术博客和报告
1.DeepSeek-V3 MFU 估算。
https://zhuanlan.zhihu.com/p/16480858047
2.FP8 混合精度训练方案与性能分析。2025 年 6 月 NVIDIA AI Open Day 分享。
https://www.bilibili.com/video/BV1mpMwz9Ey5/
3.Stable and Scalable FP8 Deep Learning Training on Blackwell. 2025 GTC 演讲。
https://www.nvidia.com/en-us/on-demand/session/gtc25-s72778/
4.Cursor's Blog on Faster Grouped GEMM Kernels and MoE Training.
https://cursor.com/cn/blog/kernels