作者:Zhennan
https://zhuanlan.zhihu.com/p/78268350517
本文主要介绍 DPPO 及后续相关工作的进展,有任何补充欢迎在评论区给出,同时由于篇幅原因,本文会尽可能地写文章的 insights 以及输出我个人的观点,而不会花太多篇幅讲具体的方法论
Diffusion Policy Policy Optimization [1]
论文:Diffusion Policy Policy Optimization
网页链接:https://diffusion-ppo.github.io/
DPPO 干了什么
Diffusion Policy 火热发展,微调 Diffusion Policy 的 idea 应运而生;
DPPO 的方法论
做过 Diffusion Model 的人都知道,扩散模型的最终输出分布不可解析,这意味着我们无法直接计算 log prob; 但好在虽然从宏观上。最终分布的解析无法求,但内部每一步的去噪过程最终输出的都是一个高斯分布,即每个去噪步都可以看作(或者说 reformulate)一个小的 Markov 决策过程(MDP) ;这就是所谓的双层 MDP 【外部 MDP 是与环境交互的 MDP ,内部是一个扩散过程 MDP】
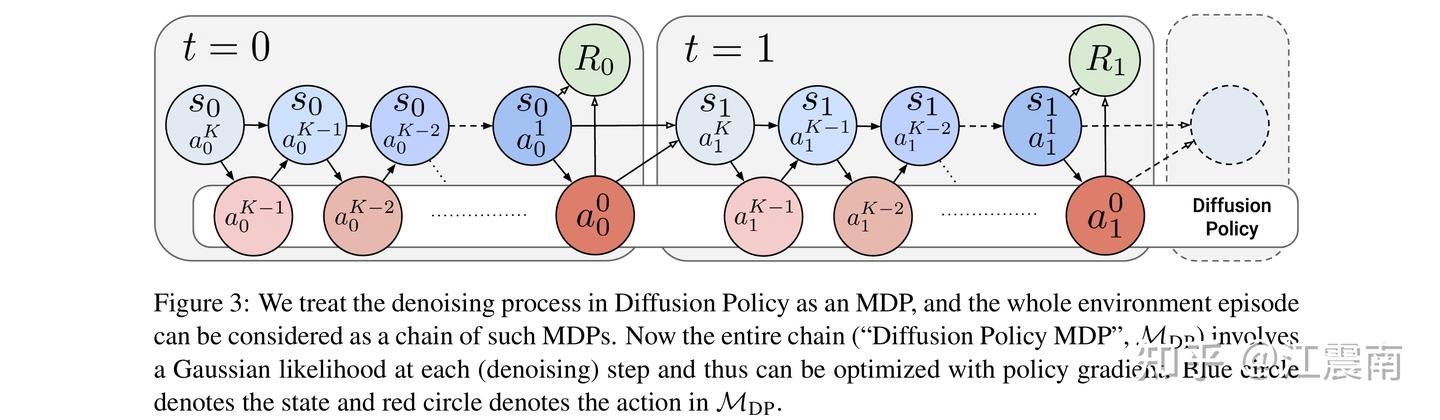
key insights
1.扩散链条不能太长 & 只finetune 最后几步:非常make sense 的一个观点,因为扩散 MDP 中可能只有最后几个去噪步对于实际的 action 生成非常重要,过长的扩散链条会导致训练变难;论文的解决方案是在 finetune 时用了 DDIM,以及在部分 setting 下只微调最后几步(例如5步) ; 特别地,由于 DDIM 是 deterministic sampler ,所以又不能计算 log prob 了;但是 DDIM 简单地解决了此问题,加噪声就好了 【实际上这是 DDPM 等 sampler 常用的解法,在推理时也会对去噪后的 sample 加噪,控制此加噪强度的参数叫 \eta 】,实践中,训练时 \eta=1 ,推理/eval 时 \eta=0
2.noise scheduling:在 DDIM 去噪时,有一个参数叫 \sigma_{k} ,控制了去噪的噪声方差;在采样动作(训练交互)时,clip min,防止 \sigma_{k} 太小【传统 \sigma_{k}在最后一步时可能为0.001,paper 将其 clip到0.01~0.1】,以防止失去 exploration 的能力 ; 在训练计算似然比时,同样 clip \sigma_{k},防止 \sigma_{k} 太小导致似然梯度爆炸,从而提升训练稳定性。
我的观点
(1)性能劣势:虽然 DPPO claim 在 robomimic 上的一些 task 取得了不错的 performance,但其在经典控制任务D4RL的表现是比较让人沮丧的 —— 以 HalfCheetah 为例,DPPO 的平均回报仅在 50006000 左右,而传统强化学习算法普遍可以达到 1000012000,部分SOTA 方法甚至已突破 15000+ 。值得注意的是,后续一些基于 DPPO 的改进工作(基于 DPPO 的 codebase,如 ReinFlow 等)在性能上也并未取得明显提升。这不禁让人疑惑:问题究竟出在工程实现、超参数设计,还是 DPPO 框架本身存在某种结构性局限?
(2)范式优势:DPPO 是一种微调 Diffusion Policy 的文章,但某种程度上,我也愿意称之为一个 offline2online 的工作,而我认为 PPO 解 offline2online 是非常优雅的 (可以追溯到 Uni-O4 [2] 这篇paper);传统的 Offline2Online 方法大多采用 value-based 思路(如 Cal-QL 等)。这类方法的核心是通过最大化 Q(s,a) 来更新策略网络参数,但在 Offline2Online 阶段,Q(s,a) 往往极不稳定——特别是在训练初期——因为 OOD(out-of-distribution)action 会导致 Q(s,a) 的高估(overestimation),从而引发严重的性能下降。但是 PPO 没有这个问题,因为它是使用 Policy gradient 进行性能提升的,而且它的 advantage 可以通过 GAE 直接计算,不需要去建模 Q(s,a),从而避免了 Q 过高估带来的一系列 performance drop 的问题 (做过 offline2online 的同行应该都知道这个问题有多苦恼hh)。换句话说,PPO 在 Offline2Online 过程中提供了一种更加稳健的优化路径:Diffusion Policy 作为 pre-training 的 warm-start policy,提供了合理的初始化分布;PPO 则在此基础上进行策略梯度式的精调,实现平滑的 offline → online 过渡。从范式角度看,这种解法称得上干净优雅——也是我个人喜欢 DPPO 的地方。 【其实做了一些同期工作,但是DPPO 出来之后感觉idea完全撞了就没继续往下做了哈哈哈】
ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning
ReinFlow 干了什么
基于 DPPO 的改进版本,一句话概括:就是更快、更好 !文章提出微调 Flow Matching 策略(含 Rectified Flow、Shortcut Model),核心做法是在推理轨迹上注入可学习噪声,把原本确定性的流动路径转成离散时间马尔可夫过程,从而得到闭式且精确的逐步转移似然,哪怕很少甚至 1 个去噪步也能稳定做策略梯度优化。
Reinflow 的方法论
与 DPPO 其实面临了同一个问题:如何去计算 log prob ? Reinflow 的解法是:在每一个噪声步都去进行噪声注入,变ODE 为 SDE —— 然后在短的去噪轨迹上进行精确的likehood 计算 【简单来说就是获得了一个联合对数似然的逐步分解】
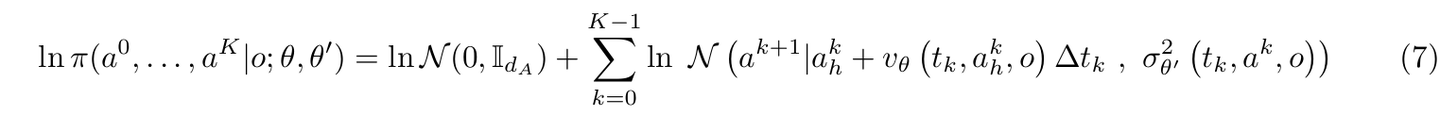
在噪声设计上,作者设计了一个噪声网络,同时接收观测 o 与时间 t,输出噪声强度。
文章还加了一些小 trick,包括 W2 距离、熵正则,以鼓励探索 ; anyway,算法实现非常干净,本质上抛弃了DPPO 原有的双层 MDP 结构,直接去解联合对数似然,而不是求解每个去噪步的 log prob;

Reinflow 的insights
a. 噪声网络的输入很重要。 让噪声网络同时条件在观测 o 与时间 t,比只看 ooo 的成功率更高——可以在不同去噪步自适应调节噪声强度是必要的。
b. 正则化 & W2 约束。 在运动任务(如 Humanoid)上,熵正则带来更强探索与更高性能;而 W2 的应用需要 case by case,有时过强的 W2 限制反而会束缚在线探索。
我的一些观点
其实所有的 finetune Diffusion Model / Reinflow 都避免不了去解 log prob ,DPPO 去做了一个双层 MDP ,这是非常简单有效的选择;而 reinflow 这种求联合概率分布的方式似乎更优雅一点。
以及 以 ODE solver 为基础的模型,是 deterministic 的,要想计算 log prob 必须加噪,reinflow采用的解法是用噪声网络,而同期的 FlowGRPO 的解法是加一个可计算(非 learning)的噪声,噪声强度由 t 和超参控制 \sigma_t=a\sqrt{\frac{t}{1-t}} ; 期待看到一个第三方测试,看看哪一种加噪方式更work
RL-100: Performant Robotic Manipulation with Real-World Reinforcement Learning[5]
[又来夹带私货啦哈哈哈] RL-100 是我认为相当有分量的一项工作。这个项目的起点,源于我和本论文一作 Lei Kun 的一次交流,当时我们讨论了 PPO + Diffusion Policy 的可行性。巧的是,那段时间DPPO 刚发布,对我造成了不小的心理冲击hhh。但我也不想让自己之前积累的一些 insights 和努力白费,于是就想着,干脆找个大佬一起,把这个方向真正做深、做透。幸运的是,一年的努力下来,最终结果应该还算不错。
RL-100 干了什么事
RL-100 是一项旨在推动真实机器人强化学习 落地的工作。我们希望告诉外界,RL 究竟能把 robotics 的能力干到什么程度,可以说是我们对于 RL 天花板的一次探索。我们在 7个不同任务上实现了 100% 成功率 (测试 900条轨迹成功900条,无剪辑)。
RL-100 的方法论
RL-100 总的框架仍是双层 MDP 的结构,并分为三阶段训练:IL -> Iterative Offline RL -> Online RL
(1) IL
除了传统的用 imitation learning loss update encoder,我们还额外使用 重建(Recon)与 VIB 正则以增强 Encoder 的表征稳定性:
(2)迭代式离线 RL
(2.1)顾名思义,我们用离线 RL 更新完 policy 后,会使用此 policy 再 rollout 一些数据,然后继续进行 Offline Reinforcement learning finetune,也有人称这种范式为 batch learning;
(2.2)离线 RL 实际上的优化目标和在线的优化目标是一致的,区别仅在于 Adv 计算的不同,online 阶段通过 GAE 估计优势,Offline 阶段以 IQL 的方式 估计优势。
(3)在线更新
论文还提供了一个 optional 的选择 —— 可以将 DDIM 的策略蒸馏到 consistency model 上,以支持高频推理
RL-100 的一些 insights
a. 噪声方差裁剪: 我们发现,除了 clip \sigma_{min} 之外,clip \sigma_{max} 也非常重要,这既可以避免过大方差导致的 OOD/危险 动作、也避免过小方差导致探索枯竭;具体地,我们单步控制时会采用clip \sigma_{max}=0.8,而一些比较难的任务或者 action chunk 控制,则 clip \sigma_{max}=0.1
b. 视觉表征与编码器更新(Recon+VIB、是否冻结): 我们发现,如果在在线过程中冻结 encoder,会严重 bound 住 performance 上限;而如果直接用 policy loss更新 encoder,又可能导致表征漂移从而还是影响策略性能。所以我们加入了 Recon loss & VIB loss,以增强 encoder 的稳定性,同时支持其在在线训练中学到更多表征
c. 扩散参数化:Diffusion 的预测目标应该选择 ϵ(噪声)还是 x0(干净样本)?【体现在 Diffuser中是 prediction_type 这个参数】;
显然 , \epsilon\mathrm{-pred} 的方差更大,尽管 DP3 等工作因此选择后者x0-pred,但方差更大的 \epsilon\mathrm{-pred} 正是在线学习所需要的,因为我们需要更强的 exporation,因此性能上限更高
d. Iterative Offline 非常重要:过去的很多工作忽视了 Offline RL 的重要性,但实机表明,Offline RL 确实大有非常有必要,性能提升非常明显 ; 尽管这种现象在仿真里不是很明显
e. 2D vs 3D 观测: 在许多任务上,经过 crop 的 3D 点云学习更快、上限更高,尽管 2D 点云表现也不错
f. 一步一致性策略(CM)vs. 多步 DDIM: 在消融中,CM 与 K-步 DDIM 学习速度与最终成功率几乎重合,但推理单步、频率更高,适合需要高响应频率的实机控制
【其实我至今仍有疑惑,为什么 offline RL 在仿真中性能提升有限,哪怕是给一个非常 diveristy 的数据集,但是真机中 Offline RL 却表现得非常好,如果有懂行的大佬还望不吝赐教】
Fine-tuning Diffusion Policies with Backpropagation Through Diffusion Timesteps [6]
一句话概括:预先采样高斯噪声,视作环境的一部分,rollout 基于提前给定的噪声,做确定性计算,再加扰动,维持探索 【噪声条件化】

GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning [7]
原则上不应该出现在这个系列里,但挺喜欢这篇文章的,还是安利一下。不属于微调,是直接做 Online RL with Diffusion model 的,提供了一种叹为观止的 log prob 求解方法:借助扩散模型求逆,构建噪声和动作转换,确保每一次采样都能计算出准确的概率密度。【建议看原文】
还有一些很有意思的工作:DSRL, QVPO, FPO ,由于和 DPPO、DQL 都没什么关系,等有时间才出一系列来讲讲。
值得注意的是,本人只是基于个人喜好以及逻辑列出了一些值得读的paper,如果要真正了解这个领域,还有很多值得读的paper ,也欢迎各位补充
[1] Allen Z. Ren,Justin Lidard,Lars L. Ankile,Anthony Simeonov,Pulkit Agrawal,Anirudha Majumdar,Benjamin Burchfiel,Hongkai Dai,Max Simchowitz, Diffusion Policy Policy Optimization
https://arxiv.org/search/cs?searchtype=author&query=Lidard,+J
[2] Kun Lei,Zhengmao He,Chenhao Lu,Kaizhe Hu,Yang Gao,Huazhe Xu, Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization, ICLR 2024
https://arxiv.org/search/cs?searchtype=author&query=Lu,+C
[3] Tonghe Zhang,Chao Yu,Sichang Su,Yu Wang, ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learnin, NIPS2025
https://arxiv.org/search/cs?searchtype=author&query=Su,+S
[4] Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, Wanli Ouyang, Flow-GRPO: Training Flow Matching Models via Online RL
https://arxiv.org/search/cs?searchtype=author&query=Li,+Y
[5] Kun Lei,Huanyu Li,Dongjie Yu,Zhenyu Wei,Lingxiao Guo,Zhennan Jiang,Ziyu Wang,Shiyu Liang,Huazhe Xu, RL-100: Performant Robotic Manipulation with Real-World Reinforcement Learning
https://arxiv.org/search/cs?searchtype=author&query=Yu,+D
[6] Ningyuan Yang,Jiaxuan Gao,Feng Gao,Yi Wu,Chao Yu, Fine-tuning Diffusion Policies with Backpropagation Through Diffusion Timesteps
https://arxiv.org/search/cs?searchtype=author&query=Gao,+F
[7] Shutong Ding,Ke Hu,Shan Zhong,Haoyang Luo,Weinan Zhang,Jingya Wang,Jun Wang,Ye Shi, GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning
https://arxiv.org/search/cs?searchtype=author&query=Luo,+H