作者:木牛流码
https://zhuanlan.zhihu.com/p/1971681801295619070
引言
权威性声明:本文的核心洞见与数据,源自微软研究院(Microsoft Research)与 Salesforce 研究院(Salesforce Research)联合发表的论文《LLMs Get Lost In Multi-Turn Conversation》。研究团队通过超大规模实验(模拟了超过20万次对话),系统性地揭示了当前所有主流大语言模型在多轮对话中的一个关键缺陷。
《LLMs Get Lost In Multi-Turn Conversation》
https://arxiv.org/abs/2505.06120
我们都习惯了与 ChatGPT、Claude 这样的AI进行“聊天式”的互动。我们会先提出一个初步想法,然后在接下来的几轮对话中不断补充细节、修正要求。比如,你可能会先说“帮我写个Python函数”,然后补充“需要处理列表输入”,接着又说“哦对了,还要能处理空列表的异常情况”。
这种逐步细化的沟通方式,对人类来说再自然不过。我们满心期待AI能像一个聪明的同事那样,完美地整合所有信息。但现实是,AI真的能跟上我们的思路吗?还是说,在对话的“九曲十八弯”里,它早已悄悄“迷路”了?
这篇论文直面了这个核心问题。它为我们揭示了一个普遍存在却常被忽视的现象——“对话迷航”(Lost in Conversation)。文章将带你深入理解:
- 核心问题:为什么看似强大的LLM,在多轮对话中的表现会断崖式下跌?
- 实验设计:研究人员如何巧妙地将“单次指令”转化为“多轮对话”,从而量化这一问题?
- 最大价值:你将清晰地看到,性能下降的根源并非模型“能力”不足,而是其惊人的 “不可靠性”。这对于我们如何使用、评估以及未来如何构建AI系统,都有着至关重要的启示。
准备好了吗?让我们一起坐上“滑滑梯”,轻松滑向这个有趣发现的核心。
实验设计:如何科学地让LLM“迷路”?
为了客观衡量LLM在多轮对话中的表现,研究人员设计了一套精妙的实验框架。核心思想是:将一个完整的、信息齐全的指令,拆分成零散的“信息碎片”,然后在多轮对话中逐一喂给模型。
这就好比对比两种烹饪方式:
1.一次性给食谱(单轮对话):直接给厨师一份完整的、包含所有步骤和配料的详细食谱。
2.分步给指令(多轮对话):先告诉厨师“今天做宫保鸡丁”,等他准备好了,再说“要多放点花生”,过一会儿又补充“别放太多盐”。
通过对比厨师在这两种模式下做出的菜品质量,我们就能知道他处理零散信息的能力如何。
核心方法:指令分片(Sharding)
研究人员将这个拆分过程称为“指令分片”(Sharding)。他们从多个高质量的单轮指令测试集(如代码生成、SQL查询、数学计算等)中提取原始指令,然后像切蛋糕一样,将其分解成多个逻辑上独立的信息片段(Shards)。
举个例子,一个完整的数学题指令可能是:
“一个面包师烤了100个面包,卖掉了60个,又烤了45个。请问他现在有多少个面包?”
分片后,可能会变成这样: 碎片1(第一轮对话):“我想让你帮我计算一个面包师的面包数量。” 碎片2(第二轮对话):“他一开始烤了100个。” 碎片3(第三轮对话):“后来卖掉了其中的60个。” 碎片4(第四轮对话):“最后,他又新烤了45个。”
通过这种方式,研究人员确保了多轮对话的总信息量与单轮指令完全一致,从而实现了公平的比较。
模拟类型:设计巧妙的“控制变量”
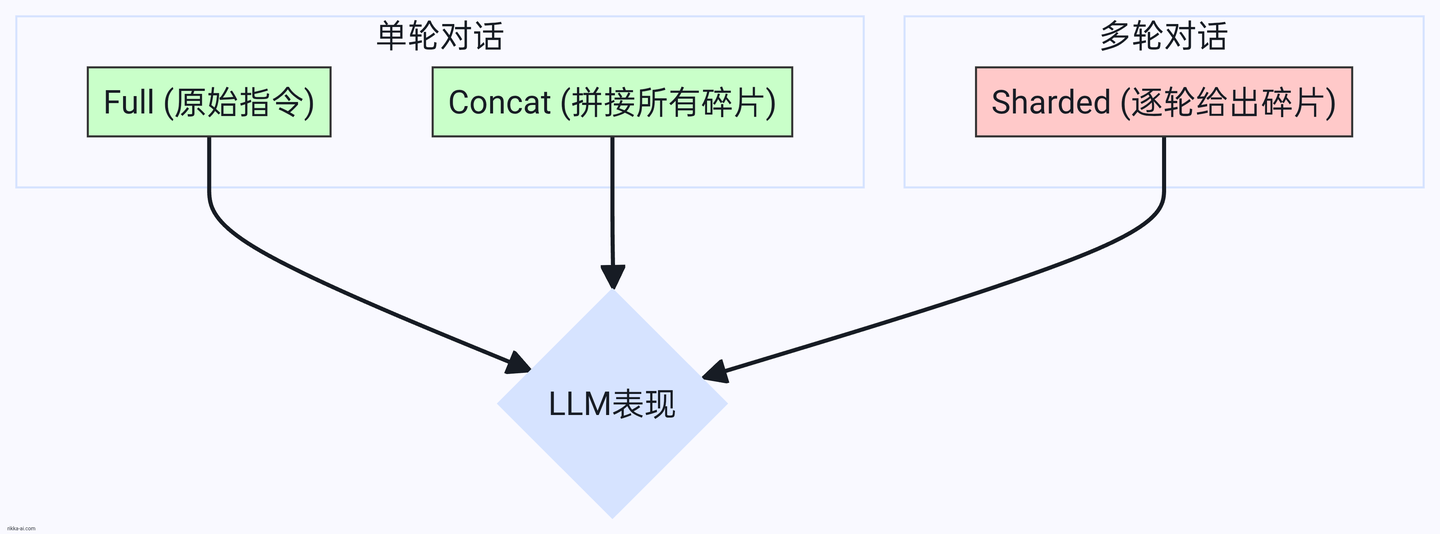
为了精准定位问题,实验设置了多种对话模拟类型,其中最重要的三种是:
1.Full(完全指令):标准的单轮对话,将原始的、未经分片的完整指令一次性发给LLM。这是我们的性能基准。
2.Concat(拼接指令):也是单轮对话,但内容是将所有“信息碎片”用项目符号拼接在一起一次性发送。这个巧妙的设计用来验证“分片”过程本身是否导致了信息损失。如果模型在Full和Concat上表现都很好,就说明它能理解分片后的语言。
3.Sharded(分片对话):真正的多轮对话,每一轮只透露一个“信息碎片”。这是实验的核心,旨在模拟真实世界中信息逐步到位的场景。
关键指标:能力 vs. 可靠性
仅仅看平均分是不够的。为了更深入地剖析问题,研究人员定义了两个关键指标:
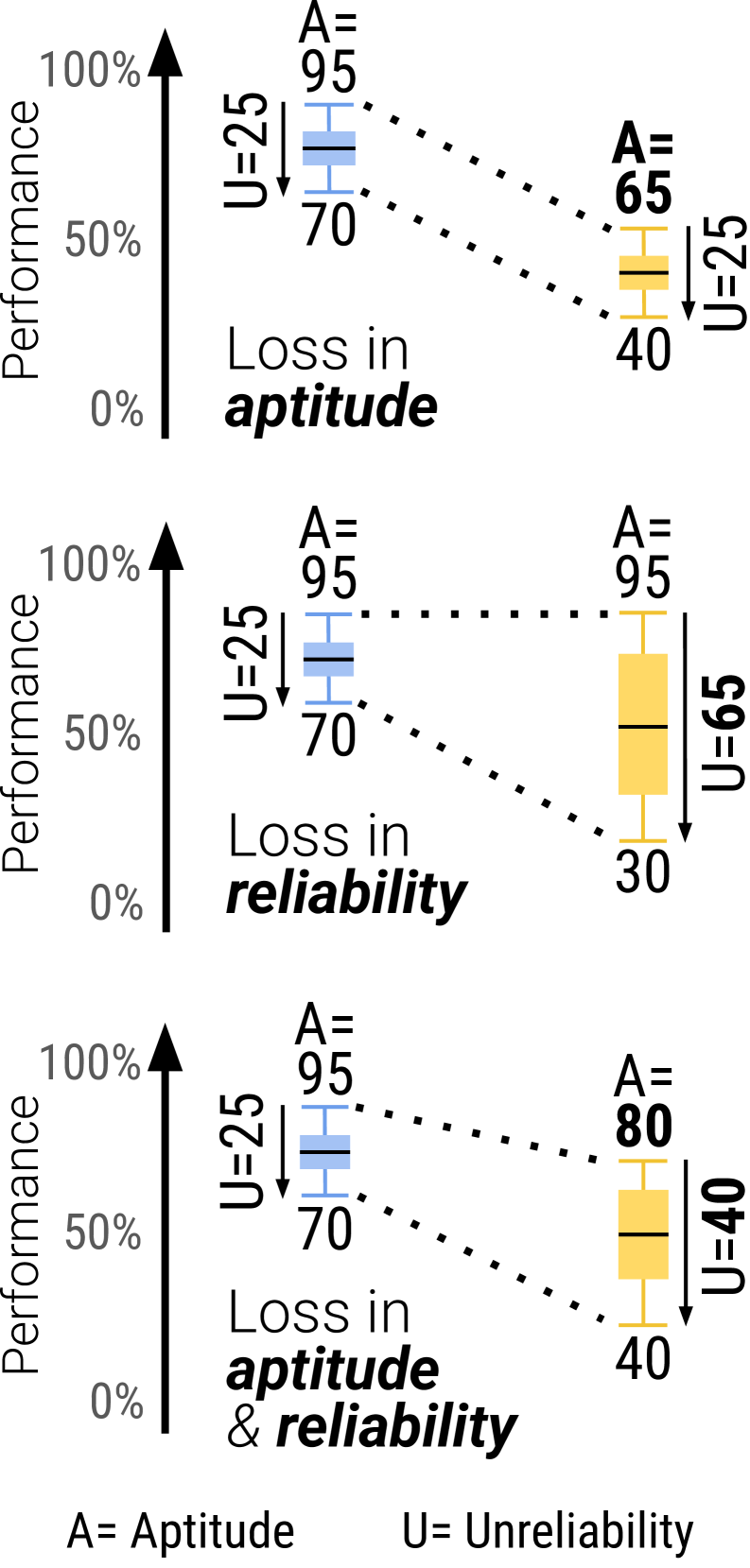
- 能力(Aptitude):衡量模型在最佳状态下的表现。可以理解为模型在多次尝试中,能达到的最高水平(论文中定义为第90百分位的分数)。这代表了模型的理论上限。
- 不可靠性(Unreliability):衡量模型表现的波动范围。它计算的是最佳表现(90百分位)和最差表现(10百分位)之间的差距。差距越大,说明模型越不稳定,像个情绪化的“艺术家”,时而灵感爆发,时而一塌糊涂。
这个设计,让我们不仅能看到LLM“会不会做”,还能看到它“能不能稳定地做好”。
惊人发现:所有LLM都在多轮对话中“迷航”
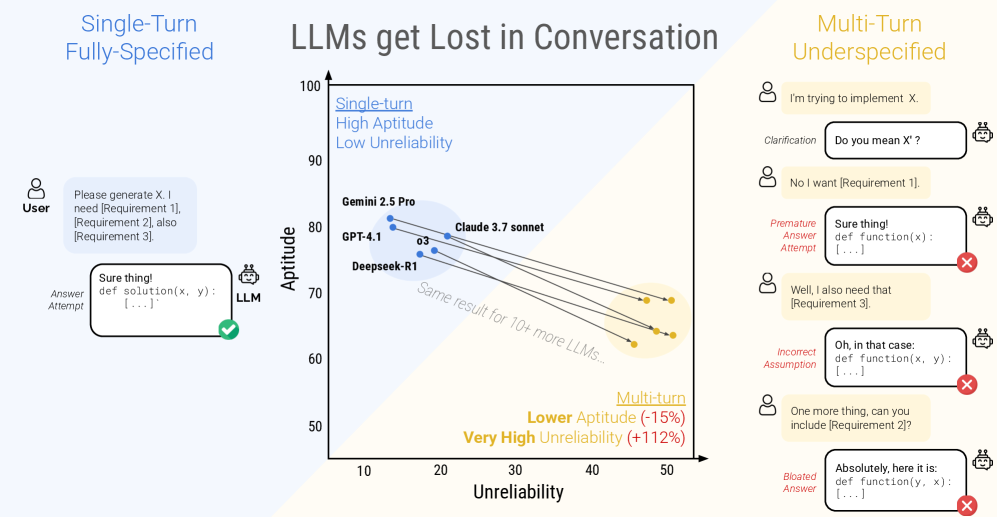
研究团队对包括GPT系列、Gemini、Claude、Llama在内的15个主流LLM进行了测试,涵盖了代码、数据库、数学、摘要等6大类任务。结果令人震惊。
发现一:性能普遍断崖式下跌
数据显示,从单轮的Full模式切换到多轮的Sharded模式后,所有模型的性能都出现了显著下降,平均降幅高达39%!
这意味着,一个在单轮测试中能拿到90分的优等生,放到多轮对话的场景里,可能只能勉强及格。更重要的是,这种现象是普遍的,无论是开源小模型还是顶尖的闭源模型,无一幸免。
同时,Concat模式下的性能与Full模式基本持平,这有力地证明了性能下降的“罪魁祸首”并非指令分片带来的语言变化,而是“多轮”和“信息不完整”这个对话形式本身。
发现二:罪魁祸首是“不可靠性”,而非“能力”不足
这是本次研究最核心的洞见。
- 在单轮对话中,模型的能力和可靠性通常是正相关的。也就是说,越强的模型,表现越稳定。
- 然而,在多轮对话中,情况完全变了。模型的能力(Aptitude) 仅出现了轻微下降(平均约16%),但不可靠性(Unreliability)却平均飙升了112%!
这意味着什么?
打个比方,一个顶尖的射击运动员,在靶场上(单轮对话),每次都能稳定打出9环、10环的好成绩(能力强,可靠性高)。可一旦把他带到野外,让他一边移动一边射击,每隔几秒才告诉他下一个目标在哪(多轮对话),他的表现就变得极不稳定。他或许偶尔还能打出10环(能力还在),但更多时候可能是5环、3环甚至脱靶(可靠性急剧下降)。
LLM在多轮对话中正是如此:不是它忘了怎么“瞄准”,而是它在复杂的动态环境中,失去了保持“稳定发挥”的能力。
发现三:两轮对话就足以让LLM“迷路”
你可能会想,是不是因为对话轮数太多,模型才记不住?研究人员通过“渐进式分片”实验发现,哪怕只是将一个指令拆分成两片,进行简单的两轮对话,模型的性能下降和不可靠性飙升问题就已经非常明显了。
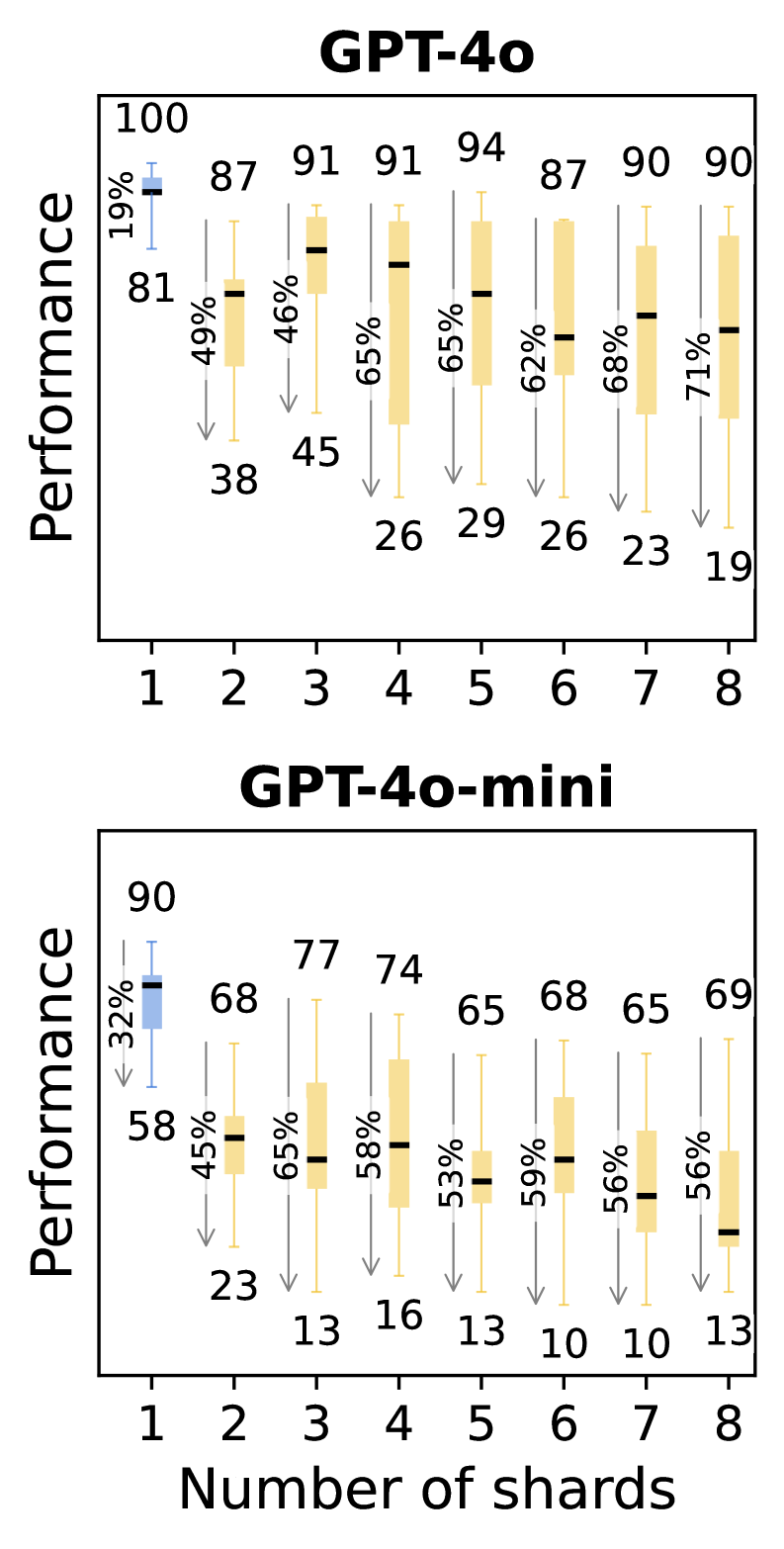
这个发现打破了我们的幻想。问题不在于长对话,而在于任何形式的、信息不完整的、需要跨轮次整合的对话,都会触发LLM的“迷航”模式。
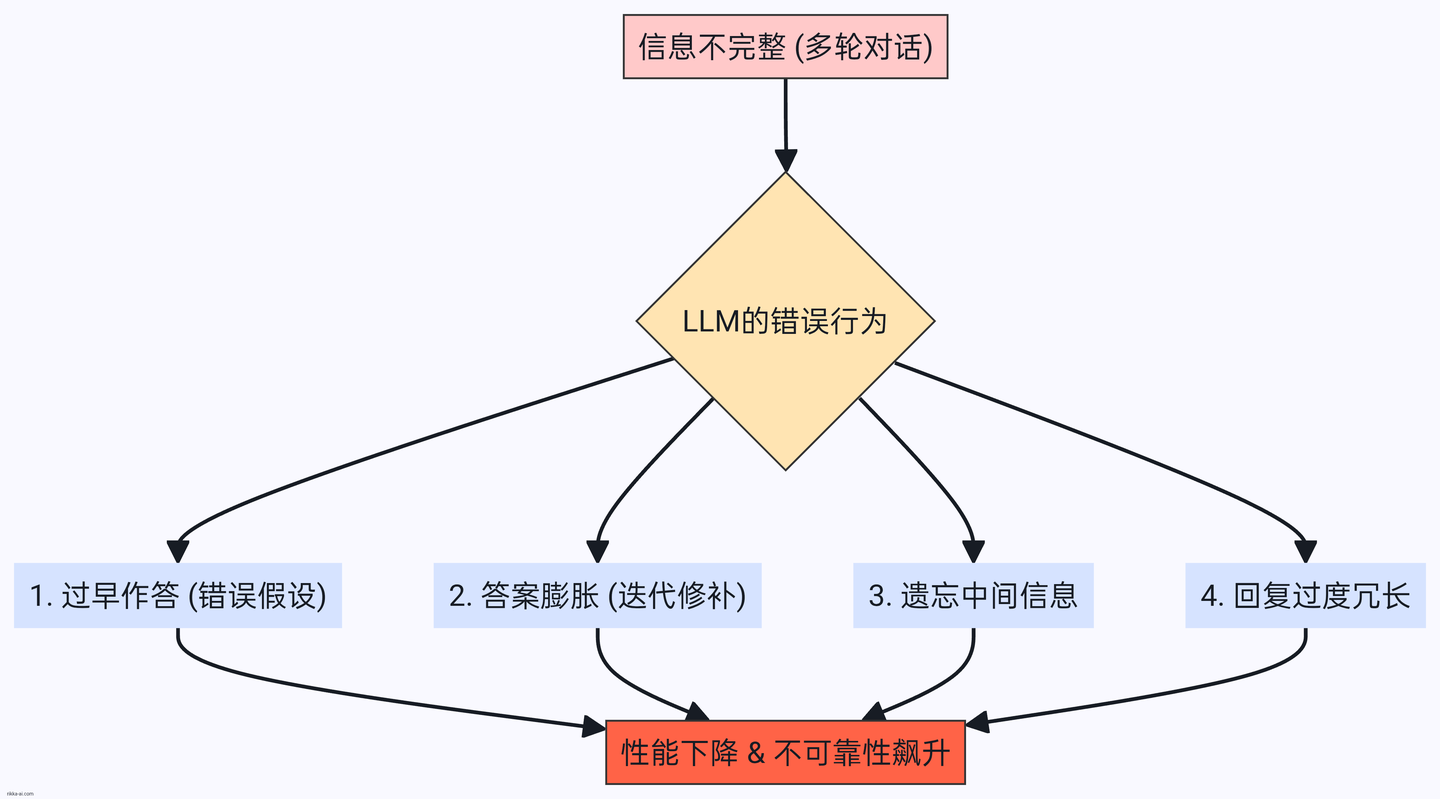
为什么LLM会“迷路”?四种典型错误行为分析
通过对海量模拟日志的定性分析,研究人员总结出导致LLM“迷航”的四种典型行为模式:
1.过早尝试作答(Premature Answer Attempts):在信息不足的早期阶段,LLM急于给出一个“完整”的答案。它会基于不完整的输入进行各种“脑补”和假设。这些早期的、往往是错误的假设,就像航船偏离了初始航道,导致后续无论如何修正,都很难回到正确的终点。
2.答案膨胀(Answer Bloat):LLM倾向于在前一轮错误的答案基础上进行“修补”而非“重构”。这导致答案像滚雪球一样,越来越臃肿、复杂,逻辑也越来越混乱。最终得到的正确方案,往往比单轮对话生成的方案冗长20%以上。
3.遗忘中间信息(Loss-in-middle-turns):与长上下文中的“中间遗忘”问题类似,LLM在多轮对话中也表现出对“中间轮次”信息的记忆力衰退。它们往往只对第一轮的初始任务和最后一轮的补充说明印象最深,而夹在中间的关键细节,则很容易被抛之脑后。
4.过度冗长(Overly-verbose):分析发现,模型在多轮对话中回复得越啰嗦,最终得分反而越低。研究人员推测,冗长的回复中往往包含了更多的自我假设,这些假设会反过来“污染”对话历史,让模型自己都分不清哪些是用户的要求,哪些是自己的“脑补”。
对我们的启示:路在何方?
这项研究不仅揭示了问题,也为不同角色的参与者提供了宝贵的启示。
对AI系统和Agent构建者的启示
有人可能会说,既然LLM本身处理不好,我们可以用Agent框架在外部管理对话历史,比如每一轮都把所有历史信息“打包”再发给LLM。
实验测试了两种类似的策略:Recap(在最后一轮总结所有信息)和Snowball(每轮都重复之前的所有信息)。结果显示,这些方法有一定效果,但无法根治问题,性能依然远低于单轮对话。这说明,依赖外部“拐杖”是治标不治本的,LLM需要从根本上提升其原生的多轮对话能力。
对LLM构建者的启示
长期以来,LLM的军备竞赛都集中在提升“能力”(Aptitude)上,比如在各种基准测试中刷分。这项研究则发出了一个明确的呼吁:请将“可靠性”(Reliability)置于同等重要的位置!
一个真正有用的AI,不仅要在“考场”上拿高分,更要在真实、动态的“应用场景”中稳定发挥。未来的模型需要专门针对多轮对话的可靠性进行优化。有趣的是,实验发现,即使将模型的温度参数(temperature)降至0,也无法有效解决多轮对话中的不可靠性问题,这表明问题根植于模型架构和训练方式,而非简单的生成随机性。
对普通用户的启示
作为用户,了解LLM的这一弱点,可以帮助我们更高效地与它协作:
1.如果时间允许,重开一个对话:当你感觉当前的对话已经变得混乱,AI开始“胡言乱语”时,继续“纠正”它可能收效甚微。更有效的方法是,复制关键信息,重新开启一个全新的对话。这相当于让AI“重启大脑”,避免在错误的对话历史中越陷越深。
2.先整合,再提问:尽量在提问前,自己先将需求梳理清晰,形成一个信息完整的指令,一次性交给AI。如果你在对话中补充了许多信息,可以先让AI帮你总结一下:“请整合我们目前讨论的所有需求”,然后将它总结的内容复制到一个新对话中,作为最终指令。
结论
“对话迷航”现象的揭示,为我们泼了一盆恰到好处的“冷水”。它提醒我们,尽管大语言模型在许多方面取得了惊人的进步,但它们在理解和处理动态、零散的对话信息方面,仍有很长的路要走。
这项研究就像一张精准的“航海图”,不仅标示出了当前LLM在多轮对话这片广阔海域中的“暗礁”,也为未来的模型开发者指明了航向。下一次,当你发现AI在多轮聊天中变得“糊涂”时,请记住,它可能不是“笨”,只是“迷路了”。而理解这一点,正是我们更好地驾驭AI这艘大船的第一步。