作者:我要吃鸡腿
https://zhuanlan.zhihu.com/p/1965839552158623077
在 VLA 架构解析:告别“黑箱”与“空谈”,探寻自动驾驶的“大脑”进化史——以理想汽车为例 中,我们已经清晰地辨析了“真假”VLA的区别,并按时间顺序梳理了VLA从被动的“解释器” 到主动的“决策核心” 的四个进化阶段。我们理解了VLA“是什么”以及“为什么”它是自动驾驶的未来方向。
然而,从概念的演进到技术的落地,中间隔着巨大的工程鸿沟。VLA这个“统一大脑” 究竟是如何在现实中被构建出来的?它又是如何巧妙地将V(视觉)、L(语言)和A(行动)这三个曾经分离的模块,真正“熔铸” 成一个统一、高效、可导的智能体的?
要回答这些问题,最好的方式就是深入解剖当前行业中最顶尖的实现方案。因此,本文我们将聚焦于“如何实现”的工程细节,通过详细解构两个代表性的VLA架构——理想汽车的MindVLA 和小米/华科的ORION来具体探究,看看它们是如何将VLA的理论蓝图转化为强大的自动驾驶能力的。
一、理想MindVLA:V/L/A三位一体的重构
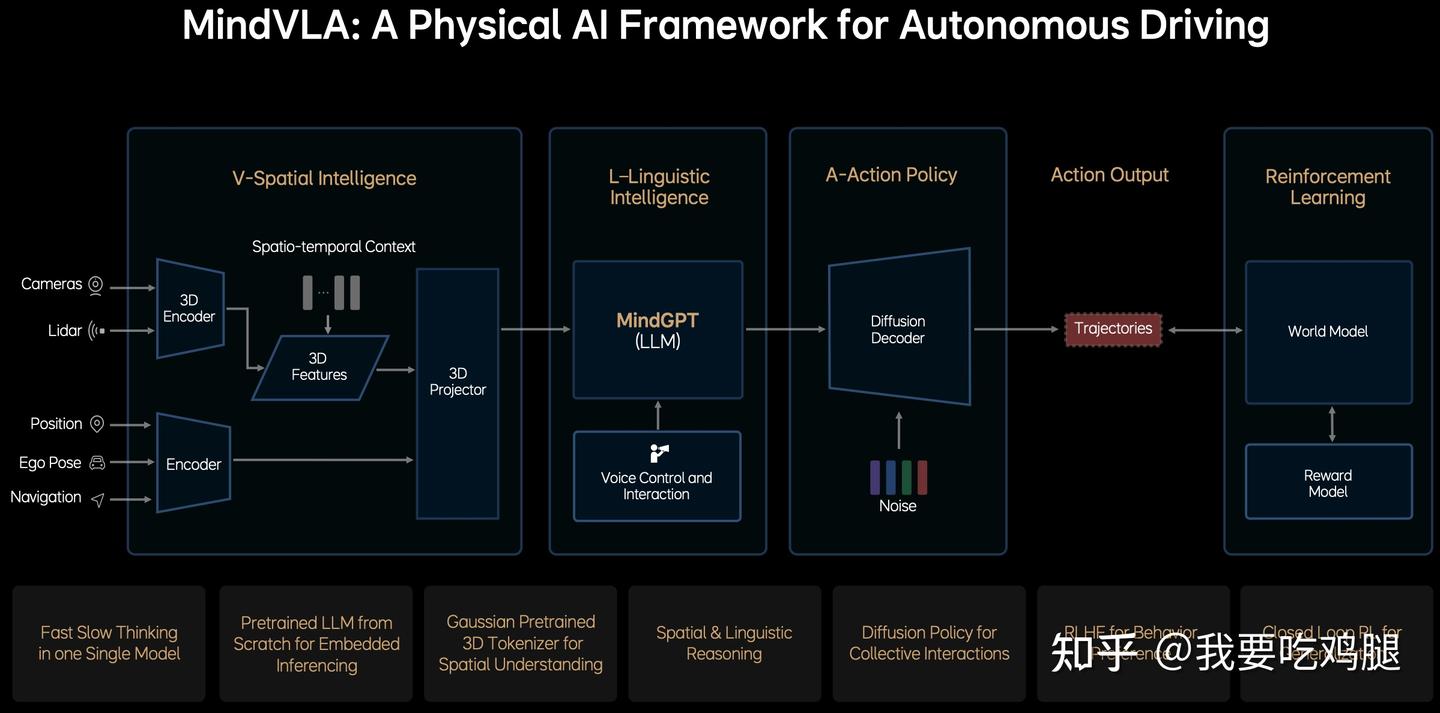
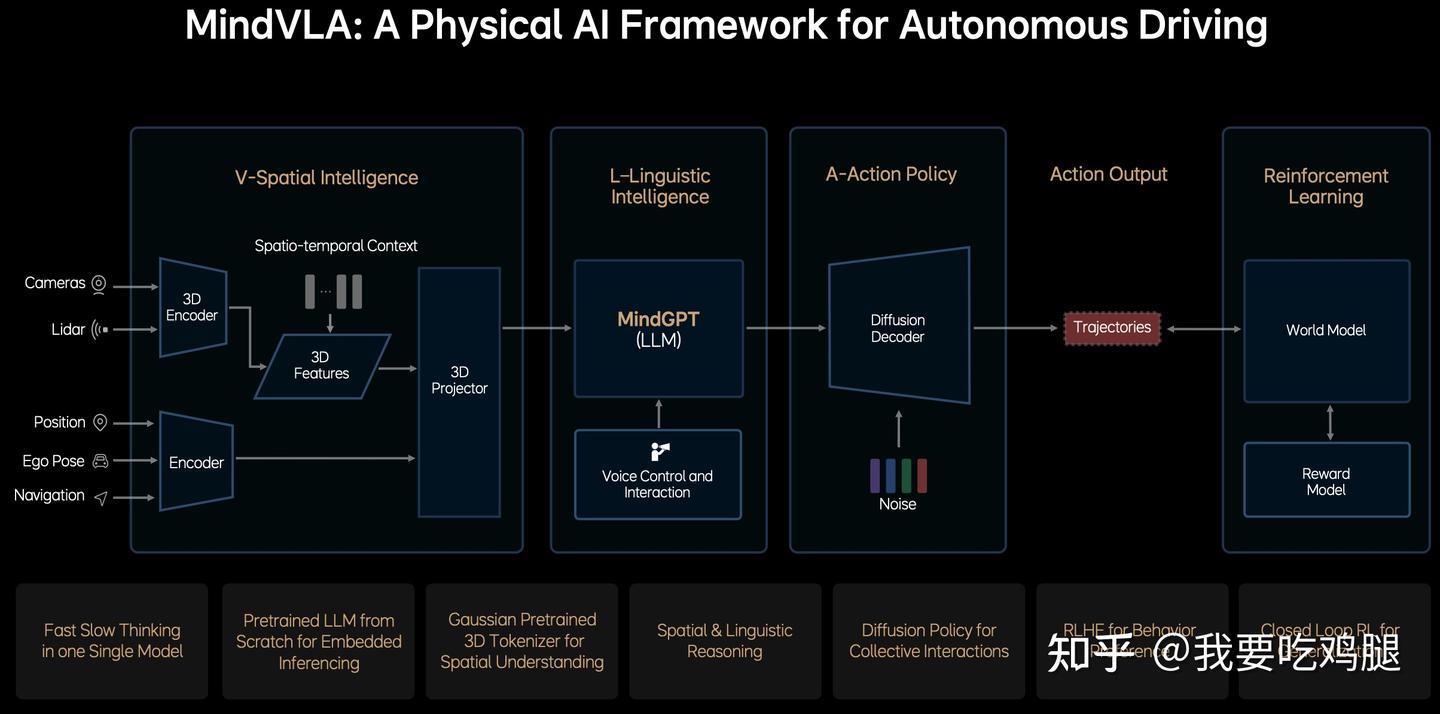
我们将要分析的第一个“玩家”,是理想汽车的MindVLA。这个案例的典型性在于,它清晰地向我们展示了如何从上一代“快慢双核”的拼凑架构(E2E + VLM),彻底进化为一个V/L/A/RL(视觉/语言/行动/强化学习)四位一体的、完全统一的物理AI框架。
- 空间智能模块:输入为多模态传感器数据,使用 3D 编码器提取时空特征,然后将所有传感器与语义信息融合成统一的表征。
- 语言智能模块:嵌入式部署的大语言模型 MindGPT,用于空间 + 语言的联合推理,支持语音指令和反馈,可能实现人车交互。
- 动作策略模块:使用扩散模型生成车辆未来的行为轨迹,引入噪声来引导扩散过程以生成多样化的动作规划。
- 强化学习模块:使用 World Model 模拟外部环境响应,评估行为后果;使用奖励模型(Reward Model):提供偏好或安全性评估,可能采用人类反馈(RLHF);使用闭环学习根据行为轨迹进行持续优化和泛化。
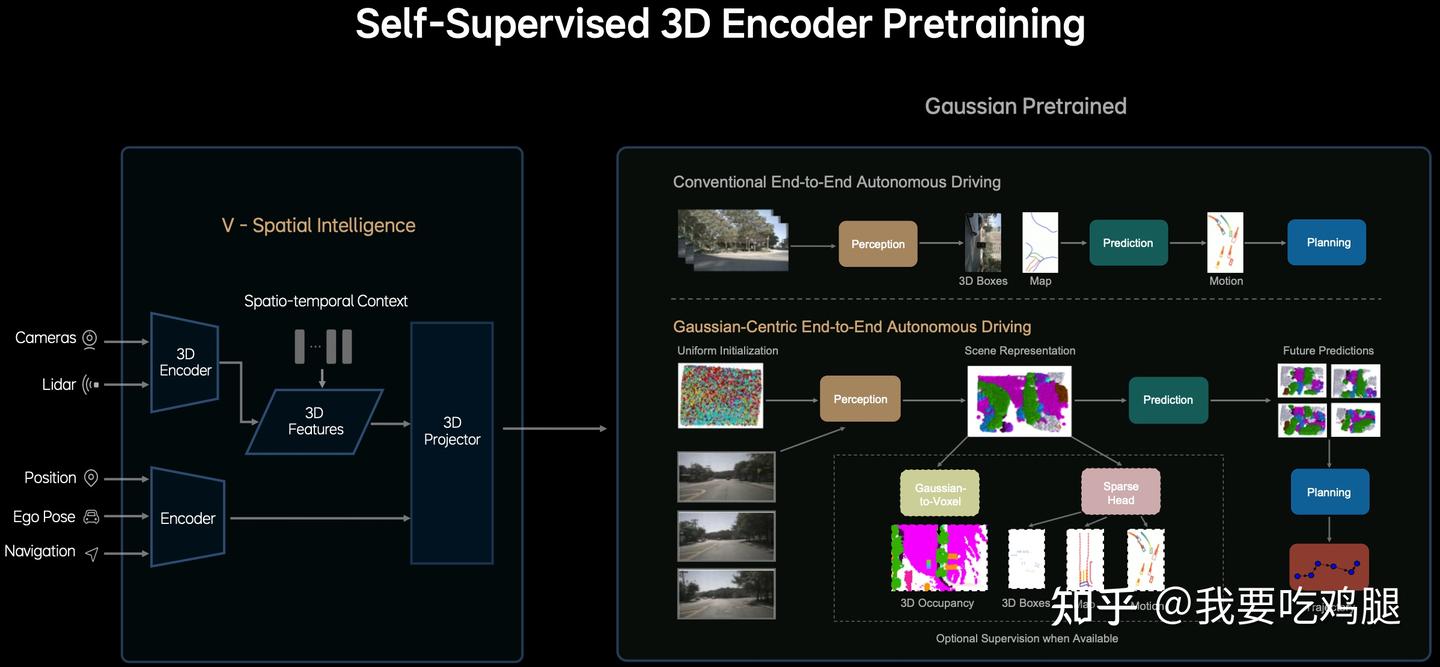
1.1.3 如何实现?——“自监督”的统一场景表示
上图清晰地展示了MindVLA的V模块是如何颠覆传统感知流程的:
传统流程 (Conventional End-to-End Autonomous Driving):
- 这是一个多阶段、串行的管道:Image -> Perception (感知) -> 3D Boxes (输出3D包围盒) -> Map (构建局部地图) -> Prediction (预测物体运动) -> Motion (输出运动状态) -> Planning (规划轨迹)。
- 严重依赖监督学习: 这个流程的每一步都高度依赖人工标注(如3D框、地图元素等)进行监督训练。
- 信息损失: 信息在从一个模块传递到下一个模块时,会经过离散化和抽象(例如从原始图像到3D框),不可避免地会丢失大量原始细节。
MindVLA流程 (Gaussian-Centric End-to-End Autonomous Driving):
MindVLA V模块的工作流程结合了多方信息,可以更精确地分解如下:
步骤一:多源输入融合与特征提取 (Inputs & Encoding)
接收多源数据: 系统首先接收来自车辆多个传感器的原始数据流。这包括高维感知数据,如摄像头(Cameras)的多视图、多帧图像 (T, T-1, T-2, T-3) 和激光雷达(Lidar)的点云,以及低维状态/导航数据,如车辆定位信息(Position)、自车姿态(Ego Pose)和导航信息(Navigation)。
并行编码: 这些不同类型的数据通过不同的编码器并行处理:
- 高维数据(图像/点云)送入一个强大的3D Encoder (GaussianAD Fig.2 中显示多帧图像 首先经过一个CNN+FPN 提取多尺度特征)。
- 低维数据(状态/导航)送入另一个相对简单的Encoder。
时空特征提取:3D Encoder 不仅处理当前帧,还会结合历史帧信息来提取蕴含了丰富时空上下文(Spatio-temporal Context) 的3D Features(3D特征)。低维 Encoder 则输出车辆自身状态和目标的特征。这两组特征并不在此步骤融合。
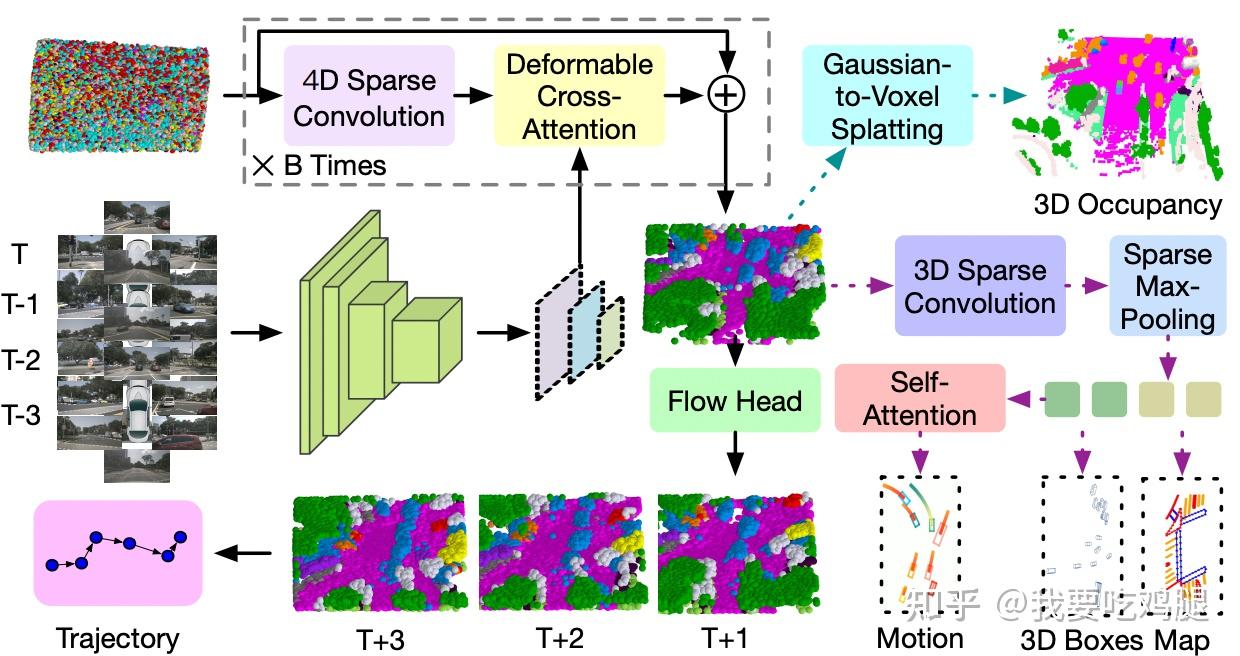
步骤二:核心 - 高斯中心场景重建 (Gaussian Refinement Loop)
高斯初始化 (Uniform Initialization): 流程从一个“高斯均匀初始化” 出发——在3D空间中“撒”下大量随机的初始高斯球(可视化为彩色点云)。
迭代优化循环 (Refinement Loop "X B Times"): 这是生成Scene Representation 的核心。初始高斯球会进入一个迭代循环(重复B次),每次循环包含两个关键操作(对应论文中的Gaussian Encoder):
- 4D Sparse Convolution: 用于高斯球之间的时空交互 。这使得模型能够理解场景的动态变化和高斯球之间的相互关系。
- Deformable Cross-Attention:这个步骤在逻辑上接收步骤一中 3D Encoder 输出的 3D Features 作为核心输入,将步骤一中从多帧图像提取的视觉特征(3D Features)融入到每个高斯球中进行交叉注意力的计算。
统一输出 (Scene Representation): 经过B次自监督学习(Self-Supervised Pretraining) 的迭代优化后,每个高斯球的参数(位置、形状、颜色、透明度、语义) 都被逐步优化(progressively refine),最终形成了那个统一的、高保真的 Scene Representation(场景表示),这不再是离散的框或栅格,而是一个由数百万优化后的3D语义高斯球构成的、连续的数字孪生世界。
步骤三:优势与应用
自监督优势: 这个核心的Scene Representation是自监督生成的。它主要依赖多视图图像之间的一致性等数据自身的信息学习,极大地减少了对昂贵人工3D标注的依赖。
统一表示取代中间步骤: 这个“稀疏但全面” 的3DGS表示取代了传统流程中所有离散的、信息有损的中间步骤(如显式的3D Boxes和Map构建)。
直接用于下游任务 : 这个Scene Representation可以直接或经过简单处理后用于后续核心任务的高质量输入:
- 预测(Prediction):通过一个专门的Flow Head 预测每个高斯球未来的位移(即高斯流 Gaussian Flow),从而直接预测未来的Scene Representation(T+1, T+2, T+3),实现对整个场景(包括动静态元素)演化的建模。
- 规划(Planning):基于对当前和未来完整3D场景的深刻理解,规划模块(输入来自Flow Head预测的未来表示)可以直接生成驾驶轨迹(Trajectory)。
可选的解码路径 : 可以选择性地从统一的3DGS表示中解码出传统输出,这些只是可选的辅助监督或输出,并非主流程必需。:
- 密集任务: 通过Gaussian-to-Voxel Splatting 转换为密集体素特征,用于3D Occupancy(3D占用栅格)。
- 稀疏任务: 将高斯视为“语义点云”,先通过3D Sparse Convolution 进一步处理,然后通过Sparse Max-Pooling 或其他Sparse Head(稀疏头) 来输出3D Boxes(3D包围盒)、Map(矢量化地图元素)。
- 运动任务: 也可以通过Self-Attention 处理高斯表示来预测Motion(特定物体的运动状态)。
步骤四:连接大脑 - 最终投影与Token化 (Projection - Connecting V-Module to L-Module)
V模块的最后一步是将所有必要信息传递给下游的L模块(语言智能),3D Projector(3D投影器) 是这个最终的“接口”和“融合点”。
输入: 它同时接收两路输入:
- 来自高维路径的3D Features,其核心内容是由步骤二(高斯中心流程)生成的那个高保真的Scene Representation (即优化后的高斯球集合)。
- 来自低维路径Encoder的输出,代表车辆自身的状态和导航目标。
处理:3D Projector 负责将这两路信息融合,并将这个融合后的高维、连续表示“投影”或“Token化” 成L模块(如MindGPT)能够理解和处理的输入格式(例如一系列嵌入向量或Token)。
MindVLA的V模块革命全流程:
首先并行处理多源传感器输入,通过3D Encoder(利用4D稀疏卷积处理时序)提取高维的3D Features 和低维的状态特征;
然后,利用3D Features和初始随机高斯球,通过一个包含4D Sparse Convolution和Deformable Cross-Attention的自监督迭代优化循环,生成一个连续、高保真的3D高斯Scene Representation,取代了传统的多阶段、离散化感知管道。这个表示是如此丰富,以至于它既可以直接用于下游的“Prediction”(预测)和“Planning”(规划),也可以在需要时(作为可选的监督任务)轻松地从中“解码”出传统的3D占用、3D box、地图或运动信息。
最后,这个“3D数字孪生世界”(表示为3D Features)与车辆自身状态特征一起,通过3D Projector 被高效地融合并“翻译”给“大脑”(L模块),为其进行高质量的3D空间推理、未来场景预测(基于Flow Head 输出的高斯流)和规划奠定了坚实无比的基础。
简而言之,MindVLA的V模块不再是给“大脑”提供一堆零散的、粗糙的“3D框”和“BEV栅格”,而是直接提供了一个高精度的、连续的、可微分的“3D数字孪生世界”。这个“世界”随后通过3D Projector(3D投影器) 被“Token化”,为L模块(语言智能)进行高质量的3D空间推理和时序预测,奠定了坚实无比的基础。
1.2 L (语言)革命:从“拿来主义”到“从零预训练”
V模块(视觉)的革命,为“大脑”提供了前所未有的高保真“数字孪生世界”。但现在,VLA面临一个更棘手的问题:这个“大脑”(L模块,语言智能)该如何构建?
1.2.1 “拿来主义”的困境
一个最简单、也最“偷懒”的办法,就是“拿来主义”:直接使用一个开源的LLM(大语言模型),比如Qwen 或LLaMA,然后用驾驶数据对它进行“后训练”(Post-training)或“微调”(Finetune)。
这正是“快慢双核”和许多VLM的思路。但MindVLA的团队清醒地认识到,这是一个根本性的错误。
为什么?因为这些开源LLM是为2D互联网而生的。它们的核心训练数据是海量的网页文本和2D图片(比如猫、狗和食谱)。它们的大脑中没有任何关于3D物理世界的基本常识。它们不懂惯性、不懂重力、不懂物体的空间遮挡、更不懂车辆的运动动力学。
你无法通过“微调”,教会一个“2D大脑”去真正理解一个“3D世界”。强行让一个2D文本模型去处理3D驾驶任务,就像我们上一篇文章的第二章所说的,会导致“空间精度不高”和“语义鸿沟”等所有顽疾。
1.2.2 MindVLA的答案:“从零开始打造LLM”
MindVLA的L模块(语言智能)进行了一场彻底的革命,其核心就是:“从零开始打造LLM”(Crafting LLM from Scratch),并为其“量身定制设计以实现实时边缘推理”(Tailored Design for Real-Time Edge Inference)。其产物就是MindGPT。
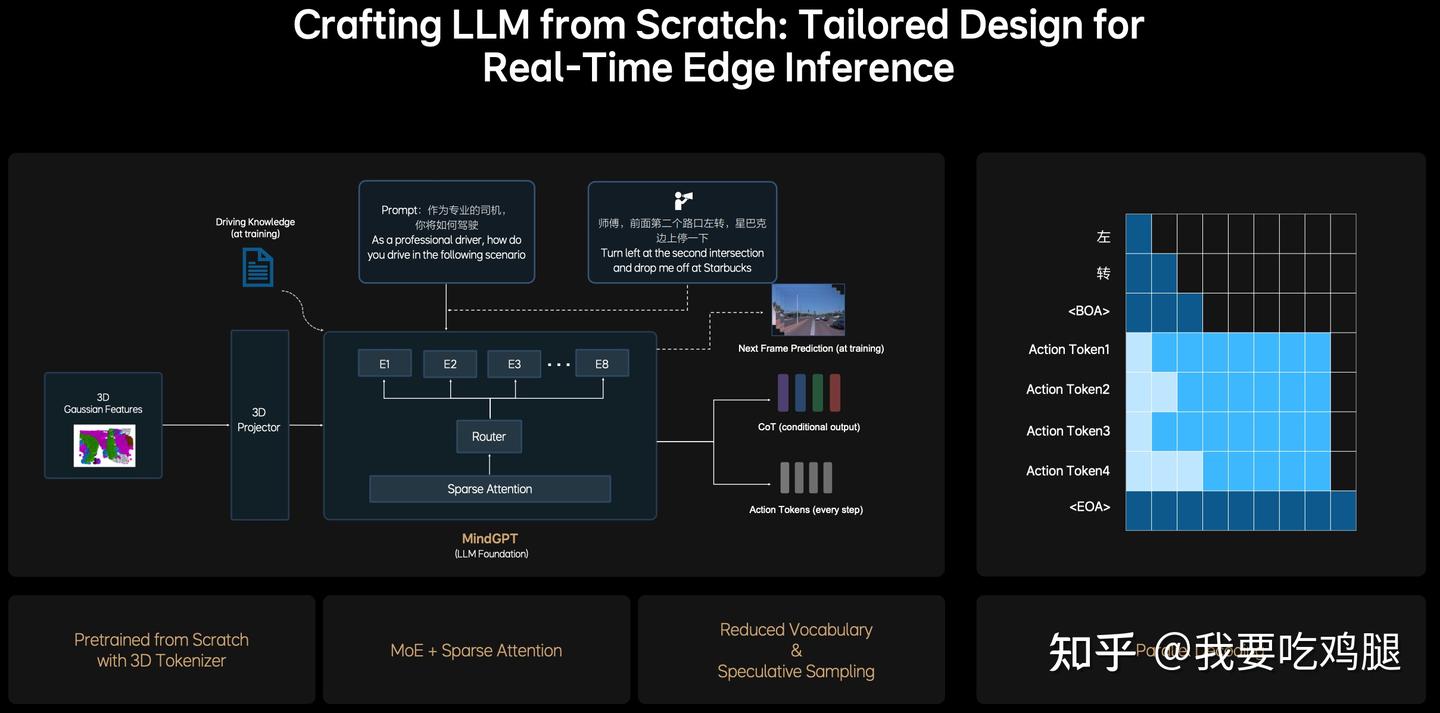
这个“L大脑”从“受精卵”阶段就被设计为“驾驶员”,而不是一个被强行“转行”的“诗人”。这场革命体现在两个方面:
革命点一:专为3D驾驶而生的“训练”
MindVLA的“大脑”在学习“说话”之前,就先学会了“看懂空间”。
- 3D“词汇表”(Tokenizer): 传统LLM的“词汇表”(Tokenizer)是“单词”(如apple, car)。而MindGPT的“词汇表”是 “高斯预训练的3D Tokenizer”。这意味着,它用来“思考”的基本单元,直接就是V模块(经过3D Projector 处理)输出的“3D高斯特征”。它的“母语”天生就是3D空间,而不是2D文本。
- 3D“教科书”(Training Task): 传统LLM的训练任务是“完形填空”或预测下一个单词(如“今天天气很___”)。而MindGPT的训练任务是“未来帧预测”(Next Frame Prediction) 和 “GoT(条件输出)”。
采用人类思维模式 + 自主切换快思考慢思考,慢思考输出精简的 CoT(采用的固定简短的 CoT 模板) + 输出 action token;快思考直接输出 action token。
这至关重要。它强迫模型不再是“记忆”,而是去“理解”这个世界的物理因果律。它必须学会:“如果我(自车)以这个速度,而那辆车(他车)的3D高斯特征在这样变化,那么‘下一帧’的3D高斯特征‘应该’是......”
通过这种原生3D输入和面向物理的训练任务,MindVLA的L模块在预训练阶段(Pretrained from Scratch with 3D Tokenizer),就获得了传统LLM所不具备的两大核心能力:强大的3D空间理解和深刻的时序推理能力。
革命点二:专为“车端芯片”而生的“架构”
LLM是庞大而缓慢的。而自动驾驶需要至少30Hz(每33毫秒)的实时响应。如何在一个小小的车端芯片(Edge Inference) 上运行一个百亿甚至千亿参数的大模型?
MindVLA的架构设计给出了答案:
1、MoE + 稀疏注意力(Sparse Attention): 这是实现“低算力跑大模型”的核心。MindVLA采用了MoE(混合专家)架构。
- 如图 1.4 所示,当一个“3D高斯特征”被输入时,它首先会经过一个“路由器”(Router)。
- 路由器会“智能地”决定这个任务应该由哪个“专家”(E1, E2 ... E8)来处理。例如,一个“刹车”相关的Token可能被路由给“E1刹车专家”,一个“变道”相关的Token可能被路由给“E3变道专家”。
- 这意味着,在任何一次推理中,都只有一小部分专家(如2个)被激活,而不是整个庞大的模型。它用“稀疏激活”换来了极高的推理效率。
2、并行解码(Parallel Decoding): 这是实现“实时动作”的“杀手锏”。
- 传统的LLM(如ChatGPT)生成文本是自回归的(auto-regressive),即一个字一个字地“蹦”出来(“我-今-天-很-高-兴”),这非常慢。
- MindVLA巧妙地区分了“思考”和“行动”。当它需要输出“思维链”(CoT)来解释时,它可以慢慢地“蹦”字。但当它需要输出动作(Action Tokens)时,它采用了“并行解码”(Parallel Decoding)。
- 如图 1.4 右侧所示,Action Token 1(转向)、Action Token 2(油门)、Action Token 3(刹车)... 它们是在一个步骤中被同时(in parallel)生成的,而不是一个一个地“蹦”出来。这极大地压缩了生成动作的时间,是满足30Hz实时响应的工程关键。
综上所述,MindVLA的“L (语言)革命”,是彻底抛弃了“拿来主义”的捷径。它通过“从零打造”,创造了一个天生懂3D、会推理、且为车端芯片深度优化的“驾驶大脑”。这个“大脑”不再是“快慢双核”中那个笨拙、缓慢、只会“说教”的VLM,而是一个真正高效、统一的“决策核心”。
1.3 A (行动)革命:从“轨迹点”到“Diffusion策略”
现在,MindVLA的“眼睛”(V模块)已经构建了一个高保真的3D世界,“大脑”(L模块)也已经在这个3D世界中完成了高效的思考和推理。
最后一步,就是“手脚”(A模块,行动策略)如何将“大脑”的决策,完美地执行为物理世界的驾驶动作。
1.3.1 “行动”的困境
传统的“行动”模块(规划器)通常是僵硬的。它们要么在有限的“轨迹库”中搜索一条最接近的轨迹,要么通过复杂的数学公式(如MPC)解出一个最优解。这就像是“在给定的选项中选一个最好的”,而不是“创造一个完美的答案”。
1.3.2 MindVLA的答案:Diffusion(扩散模型)
MindVLA的A-Action Policy(行动策略) 再次进行了一场革命:它采用了Diffusion(扩散模型)。
Diffusion(扩散模型)在AI绘画(AIGC)领域已经大放异彩,它从一堆“噪声”中“生成”出精美的画作。MindVLA将其创造性地用于“生成”驾驶轨迹。
这种“生成式”的行动策略,带来了传统方法无法比拟的两大优势:
优势一:精细化与“拟人化”的动作
Diffusion模型极其擅长生成连续、平滑、且“风格化”的输出。这意味着它生成的驾驶轨迹,不再是冷冰冰的、由直线和圆弧构成的“机器轨迹”,而是精细化的、高度“拟人”的平滑轨迹。
正如理想的工程师所比喻的,这就像是经典的“旋轮线”(最速降线)问题:
- 传统的规划器可能找到一个“代数函数”(如一条斜线或抛物线),它能走,但可能很“颠簸”。
- 而Diffusion(扩散模型)则能通过“变分函数”找到那个物理上最优的“旋轮线”解。
- 这个解,就是那条在安全、效率和乘坐舒适度(如G值)之间达到完美平衡的“黄金轨迹”。
优势二:从“反应”到“博弈”的集体建模
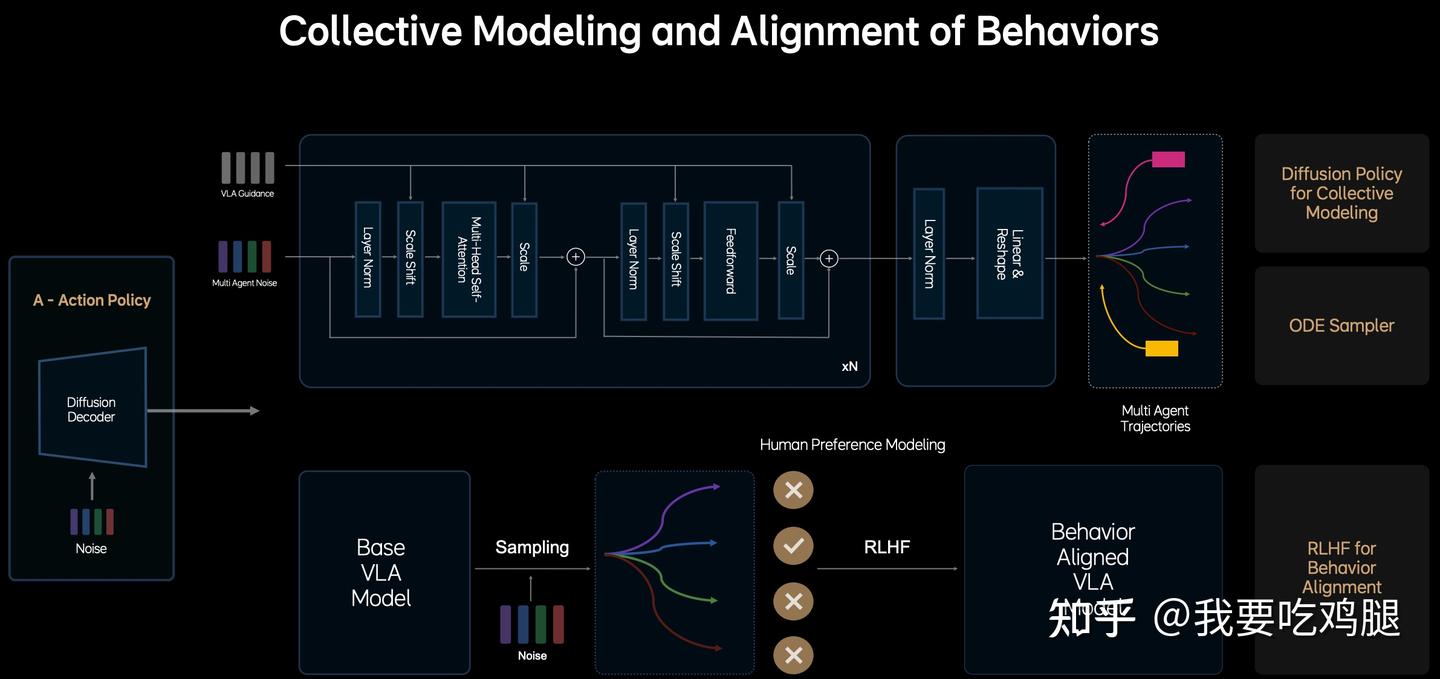
MindVLA的A模块并不仅仅在规划“我”(自车)该怎么走。它在做一个更高级的事情:“行为的集体建模”(Collective Modeling and Alignment of Behaviors)。
- 输入端融合了“他者”信息: 其核心处理模块(那个包含Multi-Head Self-Attention的Transformer结构) 接收的不仅仅是代表自车意图的“VLA Guidance”,还同时接收了“Multi-Agent Noise”。这个“多智能体噪声”可以理解为模型对环境中其他关键智能体(如旁边的车辆、前方的行人)未来行为不确定性的一种表示或采样。
- 联合建模交互: 模块内部复杂的Multi-Head Self-Attention 等结构,使其能够联合地(Collectively) 建模自车意图与其他智能体潜在行为之间的复杂交互。它不再是孤立地规划自车,而是在一个共享的空间中同时考虑“我”和“他”的未来可能性。
- 输出端预测“全局”未来: 最关键的是,其最终输出不是一条单独的自车轨迹,而是“Multi Agent Trajectories”(多智能体轨迹)。这意味着,MindVLA在生成“我”的最优轨迹的同时,也在同步预测和生成“他”(如周围车辆、行人)的最可能轨迹。
这实现了从“反应式”到“博弈式”的进化:
- 简单的“反应式”系统: 就像一个新手司机,只看前车,“他刹车了,我再刹车”;“他变道了,我再减速”。这种系统缺乏预判,容易在复杂交互中措手不及。
- MindVLA的“博弈式”系统: 它更像一个经验丰富的老司机,能够进行预判和博弈。通过对“Multi Agent Trajectories” 的联合建模,它可以进行类似“我猜测那辆车可能会向我变道,所以我提前轻微减速并向右打一点方向以为他预留空间” 这样的前瞻性规划。
优势三: 如何实现“实时”?—— ODE Sampler
Diffusion(扩散模型)虽然强大,但它有一个众所周知的致命弱点:慢。
标准的Diffusion需要成百上千步的“去噪”迭代才能生成一张图。而自动驾驶的控制循环必须在30Hz(约33毫秒)内完成。
MindVLA的工程优化再次登场:它使用了“基于常微分方程的ODE Sampler”(ODE采样器)。
这个采样器极大地加速了Diffusion的生成过程。它不再需要“成百上千步”,而是可以将轨迹的“收敛”压缩到“大概2到3步内完成”。这个工程上的突破,才使得Diffusion这个“AIGC”技术,终于得以被塞进“自动驾驶”的实时控制循环中。
至此,MindVLA通过V、L、A三个模块的彻底革命,已经构建了一个能看懂3D世界、能思考、能生成完美动作的“统一大脑”。
但还有一个最后的问题:这个“大脑”生成的动作,如何确保是“安全”的、“舒适”的、并“符合人类价值观”的?
这就是我们在第三章要解构的,VLA的最终闭环——世界模型(World Model)与RLHF(人类反馈强化学习)。
二、小米/华科ORION:用“规划Token”弥合“语义鸿沟”
如果说MindVLA是通过“V/L/A三位一体”的重构,从零打造了一个“3D原住民大脑”,那么由华中科技大学和小米联合提出的ORION,则为我们展示了另一条同样巧妙、且更侧重于“对齐”(Alignment)的VLA实现路径。
ORION的核心目标,是正面攻克我们在上一篇文章的第二章中提到的那个VLM顽疾——“语义鸿沟”。即,如何将VLM的“语义推理空间”(如“应减速”)优雅地“翻译”给“轨迹行动空间”(如[x, y, z, ...])。
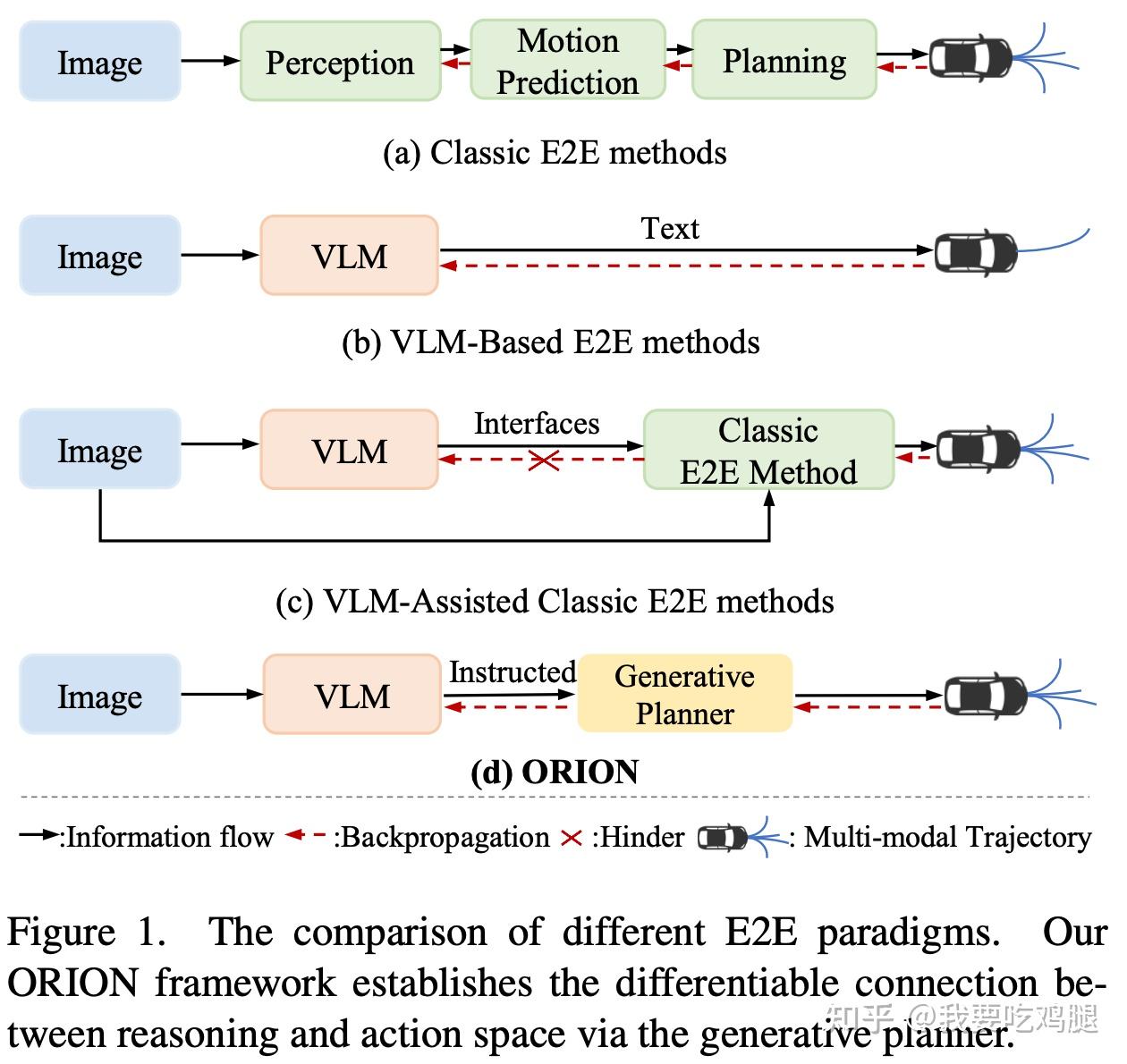
ORION 是一个“通过视觉语言指令指导轨迹生成的端到端自动驾驶框架”。它的架构设计精妙地回答了MindVLA也必须回答的两大难题:“如何处理时序?”和“如何弥合鸿沟?”。
ORION的VLM(L模块)是整个系统的“决策中枢”。与MindVLA从零训练不同,ORION选择了一个强大的VLM基座,并赋予了它三大核心职责:
- 理解用户指令(如“在下一个路口左转”)。
- 理解当前视觉信息(如“前方有行人”)。
- 理解长时程的历史上下文(如“那辆车在10秒前就开始频繁变道”)。
ORION的VLM(L模块)会结合这三类信息,对驾驶场景进行多维度的分析。它不仅会输出“场景描述”或“关键物体行为分析”,更重要的是,它会进行“历史信息回顾”和“动作推理”(Action Reasoning)。
这个“动作推理”正是ORION的L模块的核心:VLM利用其自回归特性(auto-regressive),将所有复杂的场景信息(历史、现在、指令)聚合(aggregate)起来,最终“推理”出一个高度凝练的、总结性的“决策”。这个“决策”并非直接的轨迹数值,而是一个抽象的“规划Token”。
在ORION中,VLM的L模块承担了MindVLA的MindGPT中“思考”和“推理”的全部职责。但它如何解决“时序瓶颈”和“语义鸿沟”这两大顽疾呢?这就要靠它搭载的两大创新模块。
2.1 关键模块1:QT-Former(时序处理)
ORION 的L模块(语言核心)要负责的第一件事,就是理解长时程的历史上下文。
正如我们在上一篇中深入分析的那样,这对传统的VLM架构是一个“顽疾”。VLM通过“叠加多帧图像” 来建模时序,会立刻撞上“Token长度限制”和“巨大计算开销” 这两堵墙。你无法让VLM记住30秒前发生的事情,因为它的“上下文窗口”根本装不下这么多帧的图像Token。
ORION的第一个天才创新,就是引入了QT-Former(Querying Transformer-Former),一个基于查询的时间模块(a query-based temporal module),专门用来解决这个“时序瓶颈”。
QT-Former本质上是一个高效的“长时程记忆聚合器”。它彻底抛弃了“叠加所有帧”的笨办法,而是巧妙地引入了三种类型的可学习查询(learnable queries)和“记忆库”(Memory Bank)。
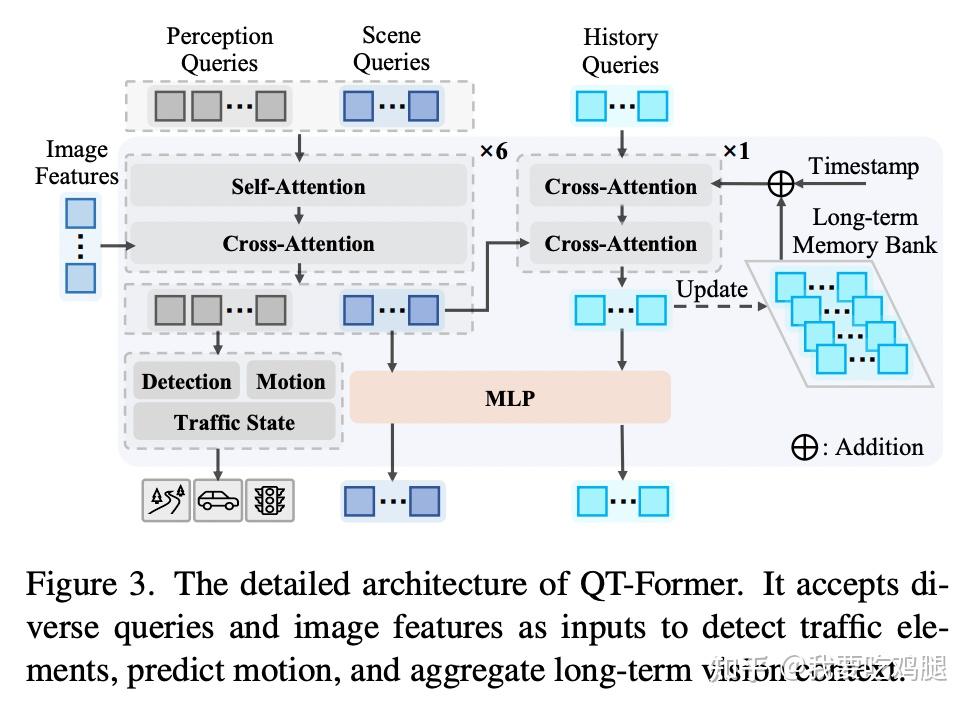
让我们根据上图 来详细拆解QT-Former的工作流程:
1.输入与查询初始化:
QT-Former接收来自Vision Encoder 的当前帧图像特征(Image Features)。
同时,它初始化三种可学习的查询向量 :
- 感知查询(Perception Queries):用于提取与具体物体检测、运动状态和交通信号相关的细粒度信息。
- 场景查询(Scene Queries):用于捕捉当前场景的整体关键信息,作为传递给下游LLM的“场景令牌”。
- 历史查询(History Queries):用于与“记忆库”交互,提取相关的历史信息。
2. 当前帧信息处理(循环x6次):
查询间交互: 感知查询和场景查询首先通过自注意力(Self-Attention) 机制相互交换信息。
特征提取: 然后,这两种查询通过交叉注意力(Cross-Attention) 机制与当前帧的图像特征(Image Features) 进行交互,从中提取相关信息。这个过程会重复6次(x6) 以充分提炼特征。
感知任务输出: 经过处理的感知查询被送入多个辅助头(Auxiliary Heads),用于执行具体的感知任务,如物体检测(Detection)、运动预测(Motion)和交通状态(Traffic State)识别。
场景令牌生成: 经过处理的场景查询则形成了代表当前场景关键信息的场景令牌(Scene Tokens)。
3. 历史信息处理(循环x1次):
记忆检索:历史查询(History Queries) 首先通过交叉注意力 与长期记忆库(Long-term Memory Bank) 进行交互。记忆库中存储了过去n帧(例如n=16)的历史查询结果,并通过时间戳嵌入(Timestamp) 区分不同时刻的信息。这一步是为了“回忆”过去。
当前场景关联: 带着“回忆”的历史查询,再次通过交叉注意力 与当前帧的场景查询(Scene Queries) 进行交互。这一步是为了“提取当前场景中与历史最相关的细节”。
记忆更新: 经过当前场景信息更新后的历史查询,会被存入记忆库(遵循FIFO原则,替换掉最旧的记录),用于下一帧的“回忆”。
4. 输出与连接:
最终,经过处理的场景令牌(代表当前) 和历史令牌(代表过去) 会通过一个MLP(多层感知机) 进行转换,然后一起被送入下游的大语言模型(LLM,即L模块)。
QT-Former的引入,为VLA带来了三大核心优势:
1. 解决了“时序瓶颈”: VLM(L模块)不再需要处理海量的历史图像Token,它只需要处理QT-Former返回的那个小巧的“记忆特征”。这极大地减少了计算开销,并彻底摆脱了“Token长度限制”。
2. 增强了场景理解: 通过高效聚合长时程信息,QT-Former增强了模型对历史场景的理解能力。它能更准确地捕捉静态交通元素(如“我1分钟前路过的那个路牌”)和动态物体(如“那辆车在过去30秒一直在异常加速”)的运动状态。
3. 融合了历史与现在:QT-Former使得模型能够将“历史信息”无缝地“整合到当前的推理和动作空间中”。L模块的决策(“规划Token”)不再是基于“当前这一帧”的“应激反应”,而是基于“过去1分钟”所有信息的“深思熟虑”。
QT-Former完美地解决了“L(语言)核心”三大职责中的“历史”部分。现在,ORION只剩下最后一个,也是最关键的挑战:如何弥合“语义鸿沟”,将“推理”与“动作”对齐?
2.2 关键模块2:VLM + 生成模型 (弥合鸿沟)
QT-Former 解决了“历史”问题,现在ORION 只剩下最后一个,也是最关键的挑战:如何弥合“语义鸿沟”(Semantic Gap)。
即,如何将L模块(VLM)的“语义推理”(如“前方拥堵,应缓慢跟车”),“翻译”成A模块(行动)的“物理轨迹”([x, y, ...]数值)?
MindVLA 的方案是“从零训练” 一个天生懂3D的LLM。而ORION 则提出了一种同样天才的“解耦-对齐”方案。
ORION的核心创新在于:它并不强迫VLM(L模块)去直接生成那些它不擅长的、高精度的轨迹数值。
相反,它将“思考”和“执行”彻底分开:
1.L模块(VLM)只负责“思考”:
VLM(语言核心,ORION中使用Vicuna v1.5 )在结合了用户指令(Instruction)、当前视觉信息(来自QT-Former的场景令牌) 和历史信息(来自QT-Former的历史令牌) 后,会进行复杂的“动作推理”(Action Reasoning),它的最终输出,不是一个轨迹,而是一个高度凝练、抽象的“规划Token”(Planning Token)。这个“规划Token”就是VLM“思考”的结晶,是它对“语义鸿沟”这边(推理空间)的最终答案。例如,这个Token可能就代表了“减速让行”或“坚决超车”的语义。
2.A模块(生成模型)只负责“执行”:
ORION引入了一个专门的A模块——一个生成模型(Generative Model),它可以是VAE(变分自编码器)或扩散模型(Diffusion Model)。 这个生成模型(见图2.1 (d) 中的“Generative Planner”)的唯一任务,就是接收L模块传来的那个抽象的“规划Token”,并将其作为“条件”(Condition),来“生成”最终的、高精度的、多模态的驾驶轨迹。
如图2.1中的(d) ORION 架构。VLM(L模块)输出“Instructed”(指令,即规划Token),“Generative Planner”(A模块)接收该指令并生成轨迹。这种方式打通了反向传播(红色虚线),实现了端到端优化。
这种“VLM(思考)-> 规划Token -> 生成模型(执行)”的架构,完美地解决了“语义鸿沟”:
- 专业分工: VLM(L模块)专注于它最擅长的语义理解和逻辑推理(生成“规划Token”)。生成模型(A模块)则专注于它最擅长的数值拟合和轨迹生成。
- 弥合鸿沟: “规划Token”成为了那座跨越“鸿沟”的桥梁。它既是L模块推理的“终点”,又是A模块生成的“起点”,从而将VLM的“推理空间”与轨迹的“动作空间”完美地“对齐”(Alignment) 了。
- 全程可导: 最重要的是,如图 (d) 所示,这个“规划Token”是可微分的,反向传播(Backpropagation)的“梯度流”(红色虚线)可以从最终的轨迹(A模块)一路畅通无阻地流回VLM(L模块)。
总结:
ORION 的架构(VLM + QT-Former + 生成模型) 向我们展示了如何通过精妙的模块组合和“对齐”思想,将复杂的视觉问答(VQA)任务和轨迹规划(Planning)任务,优雅地统一到了一个可以进行端到端优化的VLA框架中。
无论是MindVLA 的“三位一体”重构,还是ORION 的“解耦-对齐”方案,它们都殊途同归——“组装”好一个“统一大脑”。
三、“世界模型”与“RLHF”如何炼成“老司机”?
通过前面的两种分发,我们可以“组装”好了一个VLA“统一大脑” 的物理形态。
但一个刚刚“组装”好的大脑,只是一个空有潜力的“新手”,而不是一个经验丰富的“老司机”。它如何获取知识?如何积累经验?如何在犯错后学习?如何确保它的驾驶决策是“安全”的、“舒适”的、并“符合人类的价值观”?
答案,就在于VLA架构的最后一块、也是最关键的一块拼图:一个强大的“闭环飞轮”(Closed-Loop Flywheel)。
这个“飞轮”系统,就是VLA的“驾驶学校”。它由三个紧密啮合的齿轮共同驱动,让VLA的驾驶能力得以“飞速进化”:
- 数据 (Data): 飞轮的“燃料”。
- 人类反馈 (RLHF): 飞轮的“价值观”校准器。
- 世界模型 (World Model): 飞轮的“无限加速器”。
本章,我们就将详细拆解这个“闭环飞轮”的每一个齿轮,看看它们是如何协同工作,最终将一个“新手”VLA“炼成”一个真正的“老司机”的。
3.1 数据 (Data):成功的基石
VLA飞轮的第一个齿轮,也是驱动整个系统进化的“燃料”,就是数据。
在人工智能领域,尤其是深度学习中,数据和算法同等重要。但对于VLA而言,数据的地位甚至更高。因为VLA的能力——无论是感知、推理还是行动都不是由人类工程师一行行“编程”写死的,而是从海量数据中“涌现”(Emerge)出来的。
3.1.1 “数据规模定律”:VLA的铁律
VLA的进化遵循着一条简单而残酷的铁律——“数据规模定律”(Data Scaling Law)。
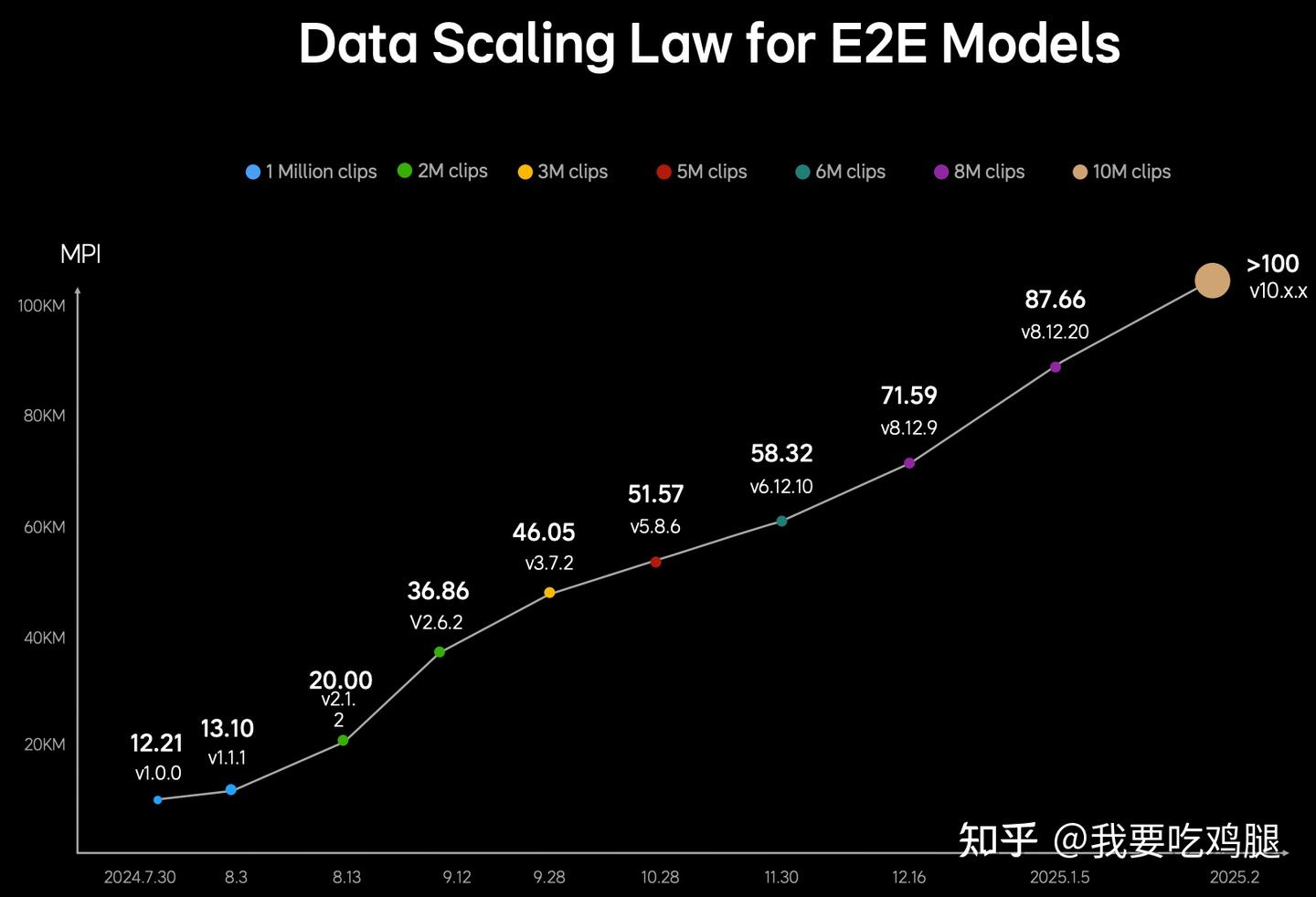
这张图表 揭示了VLA的“进化公式”:
- 在1 Million clips(100万个驾驶片段)时,MPI仅有可怜的12.21公里。
- 当数据量增长到3M clips(300万)时,MPI达到了46.05公里。
- 当数据量达到10M clips(800万)时,MPI实现了质的飞跃,达到了87.66公里。
- 最终,随着数据量的持续增加,MPI突破了100公里 大关。
这证明了:VLA的“智商”是靠数据“喂”出来的。更多的驾驶数据(Clips)能线性地、可预地提升智驾性能(MPI)。
3.1.2 数据的“质”远比“量”更重要
“数据规模定律” 似乎在说“量”就是一切。但正如理想的工程师所言:“单从公里数来讲,做到1000万Clips或者2000万Clips,并不困难,但能够弄出这么多类型、这么多有价值的数据,这是我们的优势之一。”
这就是VLA数据飞轮的核心挑战:数据的“质量”远比“数量”更重要。
VLA需要的是什么“高质量”数据?
答案是:(视觉+语言+行动)三模态对齐的数据。
- 视觉(V): 这一帧的图像/雷达数据是什么?
- 行动(A): 此时驾驶员做了什么动作(转向-2.3°)?
- 语言(L): 驾驶员为什么这么做?(“因为我看到行人有探头的趋势”)
这种(V+L+A)三模态对齐的数据,尤其是覆盖“犄角旮旯”(corner-case)场景的,是“极其稀缺且昂贵” 的。

3.1.3 如何获取“高质量”数据?VLA的“数据炼金术”
既然(V+L+A)数据如此稀缺,VLA的工程师们发明了两种“数据炼金术”来制造“燃料”:
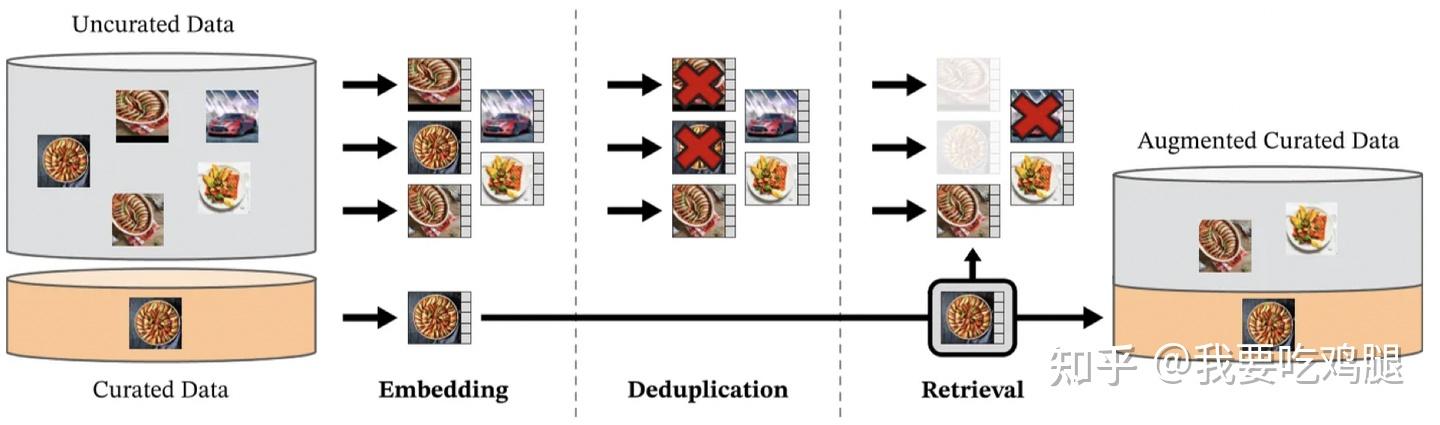
1. 炼金术一:从“沙子”中“淘金”(过滤与检索)
我们每天都有海量的“Uncurated Data”(未精选数据,即沙子),但只有极少数是“Curated Data”(精选数据,即金子)。
2. 炼金术二:用“AI”标注“AI”(自动标注)
在很多情况下,(V+L+A)数据甚至根本就不存在。例如,ORION 团队发现,在他们的仿真环境中,“缺乏高质量的VQA(视觉问答)标注”。
他们的解决方案不是去“雇人标注”,而是“设计一个自动化的VQA标注流水线”,来创造一个全新的数据集:Chat-B2D 。
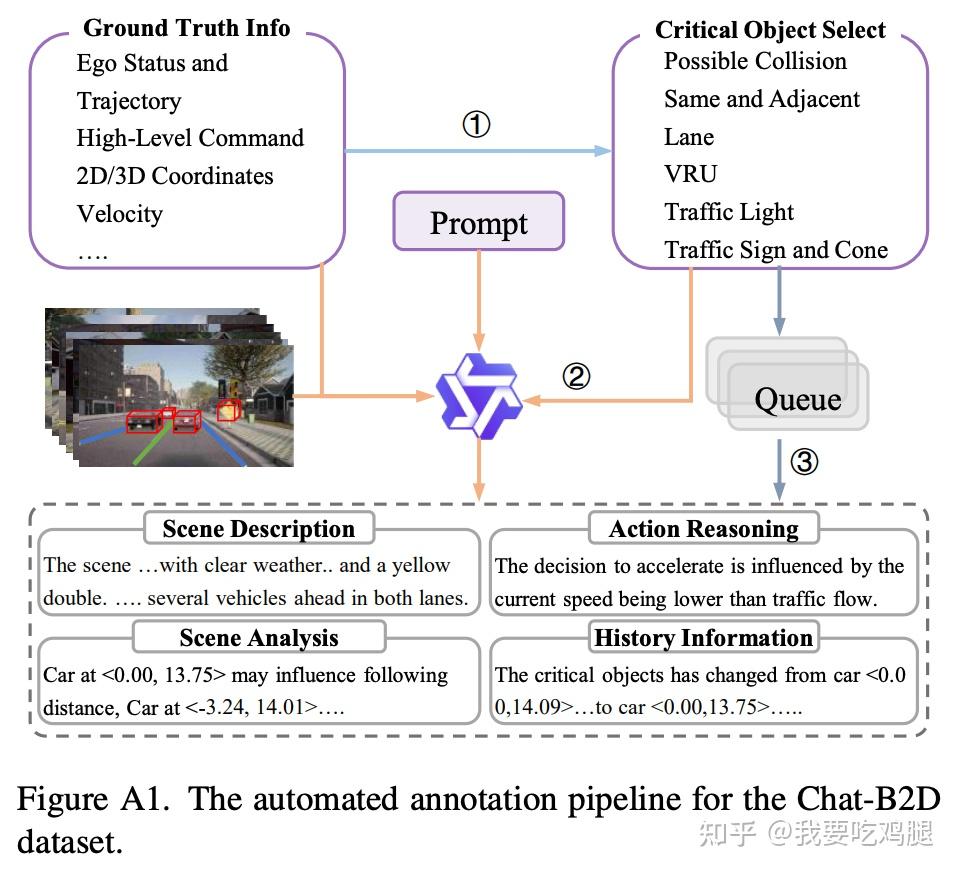
这条流水线 的工作方式是:
- 输入(V+A): 工程师向流水线输入“Ground Truth Info”(真值信息,如自车轨迹、速度 )和“Critical Object Select”(关键物体,如“潜在碰撞”的物体 )。
- 标注(L): 他们用这些(V+A)信息,去Prompt一个更强大的“教师VLM”(如Qwen2VL-72B )。
- 输出(L): 这个“教师VLM”会自动生成缺失的“语言”数据,如“Scene Description”(场景描述)、“Action Reasoning”(行动推理)和“History Information”(历史信息)。
数据(Data)是VLA飞轮的“燃料”。但“燃料”的质量决定了飞轮的效率。“数据规模定律” 只是基础,更核心的是通过“检索” 和“自动标注” 等“炼金术”,源源不断地制造出“(V+L+A)三模态对齐” 的高辛烷值“燃料”。
3.2 人类反馈 (RLHF):对齐价值观
“数据”(Data) 解决了VLA“吃饱”的问题,但这立刻带来了第二个问题:如果“燃料”(数据)本身就有问题怎么办?
在海量的驾驶数据中,必然混杂着大量人类司机的“坏习惯”——有人喜欢急刹车,有人喜欢激进变道,有人是“马路杀手”。如果VLA只是一个“模仿者”,它最终学到的,只会是所有人类驾驶员的“平均水平”,而不是“最优水平”。
我们不希望VLA成为一个“莽撞的20岁新手”,我们希望它成为一个“沉稳的40岁老司机”。
因此,VLA飞轮的第二个齿轮必须介入:RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)。
RLHF是VLA的“价值观校准器”。它的核心任务,不是“模仿”(Imitation),而是“对齐”(Alignment)。它负责将VLA的行为,对齐到人类真正“偏好”(Prefer)的价值观上,例如“安全”、“舒适”、“合规”。
MindVLA 和MindVLA for Robotics 的架构图,清晰地向我们展示了“对齐”的完整闭环:
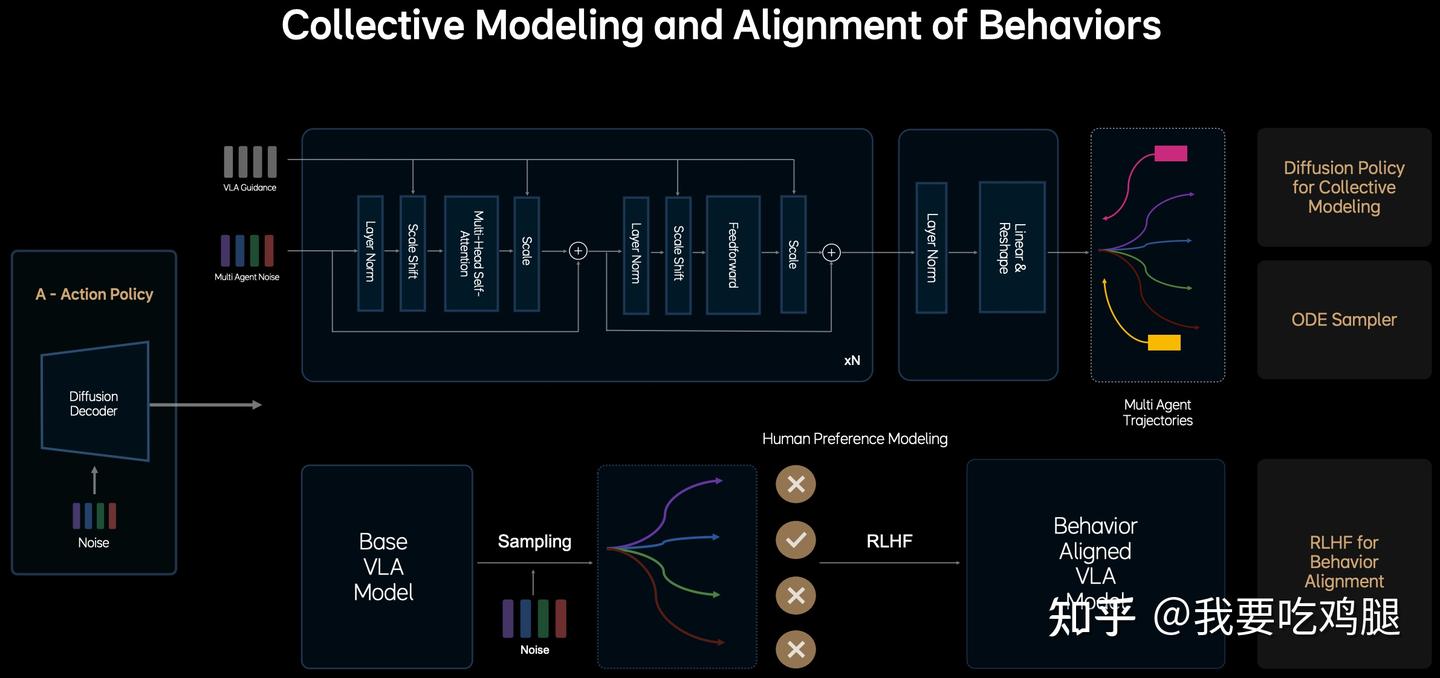
这个“对齐”过程,可以分为三个步骤:
步骤一:采样(Sampling)—— VLA“出题”
首先,我们拿出一个“Base VLA Model”(即只用海量数据“喂”出来的基础模型)。在同一个驾驶场景下(例如“前方路口黄灯”),我们让这个模型生成多种(Sampling)可能的驾驶轨迹:
- 轨迹A:“一脚油门冲过去”(激进)
- 轨迹B:“一脚急刹停住”(安全但不舒适)
- 轨迹C:“平滑减速,G值最低,稳稳停住”(安全且舒适)
步骤二:奖励建模(Reward Model)—— 人类“打分”
接下来,VLA需要知道这三条轨迹中,哪一条是“好”的。这就是“奖励模型”(Reward Model) 的工作,它在MindVLA的强化学习闭环中扮演着“人类偏好裁判” 的角色。
这个“奖励模型”本身也是一个神经网络。它的训练数据,是一个“人类偏好数据集”(Human Preference Dataset)。
这个数据集是如何构建的?理想的工程师给出了一个绝佳的例子:“人类驾驶数据 + NOA的接管数据”。
“接管数据”(Takeover Data) 是一种完美的、强烈的负面信号。当人类驾驶员在NOA(自动辅助驾驶)过程中突然“接管”了方向盘,这个动作本身就在大声地告诉模型:“你(AI)刚才的决策是错误的、危险的、或我不喜欢的(-100分),而我(人类)现在的操作才是正确的(+100分)。”
通过学习海量的“接管数据”和人类的“五星好评”数据,这个Reward Model 就学会了“将人类驾驶偏好转化为奖励函数(RLHF)”。
现在,它可以自动为VLA“出的题”打分了:
- 轨迹A(激进):-50分 (X)
- 轨迹B(急刹):+20分 (✓)
- 轨迹C(平滑):+100分 (✓)
步骤三:强化学习(RLHF)—— VLA“改正”
最后,就进入了RLHF的强化学习训练循环。
“Base VLA Model” 会被“奖励”去生成那些能从Reward Model 拿到高分的轨迹(如轨迹C),并被“惩罚”去避免那些低分轨迹(如轨迹A)。
通过这个“通过人类偏好数据集微调模型的采样过程” 的循环,VLA模型最终进化成了“Behavior Aligned VLA Model”(行为对齐的VLA模型)。
总结:
RLHF是VLA飞轮的“价值观校准器”。它让VLA不再是一个只会“模仿”人类驾驶员(包括其所有坏习惯)的“模仿者”,而是一个被人类“价值观”和“偏好”(Preference) 深度“对齐”(Align) 的“智能体”。
这才是VLA的终极目标:“对齐人类驾驶员的行为,提高安全驾驶的下限”。
3.3 世界模型 (World Model):无限的训练场
我们现在有了“燃料”(Data)和“价值观校准器”(RLHF)。但VLA飞轮的进化,还面临着最后一个,也是最大的瓶颈:效率与安全。
RLHF 需要VLA在海量的场景中“试错”(Sampling)。但我们不能让一台AI驾驶的真车在现实世界中“试错”,去“试”一下撞车会得多少“负分”。同样,只靠“数据”(Data) 也是不够的,因为真实世界的数据是有限的、昂贵的,并且缺乏那些最危险、最稀有的“犄角旮旯”场景。
过去的解决方案是使用“3D游戏引擎”(如CARLA)来构建仿真环境。但这种方案有两大缺陷:
- “场景真实性不足”:游戏引擎的画面再好,也无法100%还原真实世界的光影、物理和随机性。
- “场景建设效率低下”:人工搭建一个高保真城市场景的成本极高,导致场景库规模小,模型很容易“学偏”并“Hack(攻击)”这个固定的奖励模型。
VLA需要一个“无限的、高保真的、且能安全试错的训练场”。这就是VLA飞轮的第三个齿轮,也是它的“无限加速器”——世界模型(World Model)。
3.3.1 VLA的“世界模型”是如何工作的?
MindVLA 的世界模型 不是一个“游戏引擎”,它是一个基于生成式AI 的“数字孪生工厂”。它不去“手动搭建”一个假世界,而是通过“学习”海量的真实驾驶数据,来“生成”一个无限的、高保真的、可交互的“数字孪生世界”。
这个“世界模型”的核心技术,与V模块(视觉)一脉相承:3D高斯建模(3DGS)。
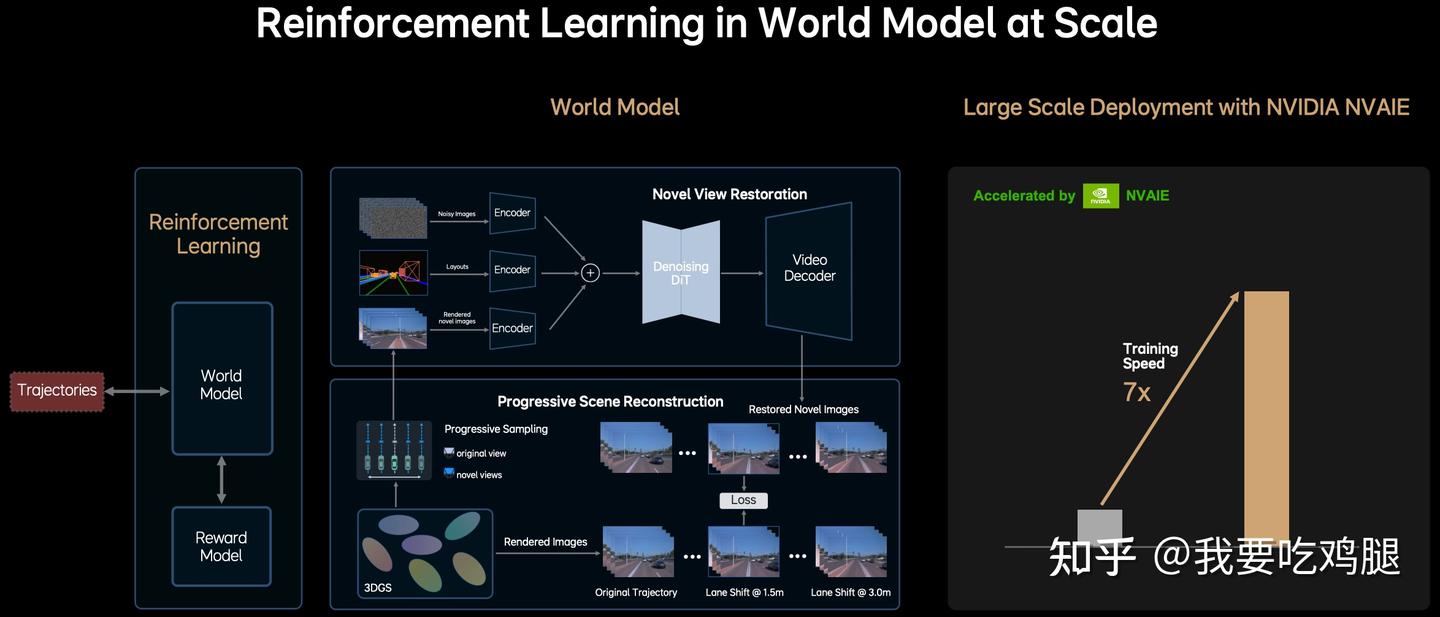
根据上图及其相关信息,这个“世界模型”的工作流程可以分解为以下几个关键步骤:
1. 基础:基于3DGS的场景表示 (Implicit Foundation)
虽然图中没有直接画出,但世界模型的基础,正是V模块 生成的那个高保真的3DGS Scene Representation。这个由数百万高斯球构成的数字孪生场景,是世界模型进行模拟和生成的“画布”。
2. 核心魔法:“假如(What-if)”模拟与物理规律学习 (Progressive Scene Reconstruction)
这是世界模型最核心的功能,体现在图中间的“Progressive Scene Reconstruction”(渐进式场景重建) 模块。
输入: 当前的3DGS场景表示。
“渲染”不同未来的可能性:
- 模型首先通过“渐进式采样”(Progressive Sampling),选择不同的“视角”(views)进行渲染。
- 它会渲染出AI在“原始轨迹”(Original Trajectory) 下应该“看到”的图像序列(Rendered Images)。
- 关键在于: 它同时还会渲染出AI在执行“假如”轨迹(Novel views / hypothetical trajectories) 时会“看到”的图像序列。图中给出的例子是“Lane Shift @ 1.5m”和“Lane Shift @ 3.0m”——即模拟车辆向左平移1.5米或3米后的景象。这与GaussianAD论文中提到的使用仿射变换(Affine Transform)模拟未来观测 r_tilde = t(r, w) 的思想高度一致。
学习物理后果 (Loss Calculation):
- 模型通过计算“Loss”(损失) 来学习。这个损失是通过对比“原始轨迹”的渲染结果和“假如”轨迹的渲染结果之间的差异来实现的。
- 通过最小化这个损失(或更准确地说,通过预测“假如”轨迹的渲染结果与“真实世界”(或基础3DGS表示)渲染结果的差异),世界模型就学会了这个3D数字孪生世界中的物理因果律。例如,它能学会“向左平移3米会渲染出马路牙子的图像”,即“向左平移3米会撞到马路牙子”这个物理后果。
联合优化: 这就是“3D重建和生成模型的联合优化”:利用3DGS的高保真重建能力,结合生成模型(如下文的DiT)的模拟能力,让模型不仅能“看到”世界,更能“理解”在这个世界中行动的后果。
3. 提升真实感与生成能力 (Novel View Restoration)
为了让模拟出的“假如”场景更逼真、更可用,世界模型还包含一个“Novel View Restoration”(新视角重建/修复) 模块。
输入: 来自“渐进式场景重建”模块渲染出的(可能带有渲染瑕疵的)各种视角图像(Rendered Images)。
处理: 这些图像被送入编码器(Encoders),然后通过一个核心的“Denoising DiT”(去噪扩散Transformer) 进行处理。DiT正是MindVLA A模块(行动策略) 中使用的同源技术。
输出: DiT的输出经过视频解码器(Video Decoder),生成“Restored Novel Images”(修复后的新视角图像)。
目的: 这个步骤利用Diffusion强大的生成和修复能力,旨在提升模拟场景的真实感和视觉一致性,为强化学习提供更高质量的训练输入。它可能还能用于生成全新的、训练数据中未包含的场景变体。
4. 整合入强化学习闭环 (Reinforcement Learning Loop)
世界模型 最终被整合到强化学习(Reinforcement Learning) 的闭环中。
流程: VLA智能体(Agent)输出的Trajectories(轨迹) 被送入World Model。World Model模拟执行该轨迹后的后果(即预测的未来状态或渲染的未来图像)。这个“后果”被送入Reward Model(奖励模型,即RLHF) 进行打分。得分(奖励信号)再反馈给VLA智能体,指导其优化策略。
价值: 世界模型提供了一个安全、高效、可无限重复的“虚拟训练场”,让VLA可以在其中进行大规模的“试错”学习,而无需承担真实世界的风险。
总体流程总结:
- 世界模型以高保真的3DGS场景表示为基础。
- “渐进式场景重建”模块负责进行“假如”模拟:它从3DGS中采样不同轨迹(真实的和假设的),并渲染出对应的图像序列(Rendered Images)。这个过程让模型能够预测不同行动的视觉后果,并通过Loss计算 学习物理规律。
- 直接渲染出的图像(Rendered novel images)可能不够完美,因此它们被送入“新视角重建”模块。
- 该模块利用Denoising DiT(扩散模型),结合场景布局(Layouts) 和噪声(Noisy Images),对渲染图像进行“修复”和“增强”,生成更高质量的“Restored Novel Images”。
- 这些高质量的模拟结果(无论是直接渲染的还是修复后的)最终被用于强化学习闭环:作为Reward Model 的输入进行评估,或者作为VLA智能体学习的目标/状态表示。
MindVLA的世界模型 是一个基于3DGS 的强大生成式AI。它通过“渐进式场景重建” 学习物理因果律(模拟“假如”场景),通过“新视角重建”(利用DiT)提升真实感,最终为强化学习提供了一个安全、高效、可加速的“无限训练场”,驱动VLA智能体向“老司机” 快速进化。
3.3.2 “世界模型”的价值:7倍加速
“世界模型” 为VLA提供了一个“无限的训练场”。RLHF(奖励模型) 可以在这个“数字孪生世界” 中,安全、高效、大规模地“惩罚”和“奖励”VLA的每一个“试错”轨迹。
这个“生成+模拟”的过程计算量是极其恐怖的。因此,MindVLA 采用了“NVIDIA NVAIE”进行“大规模部署”(Large Scale Deployment)。
其最终成果是惊人的:训练速度(Training Speed)提升了7倍(7x)。
总结:
“闭环飞轮”是VLA的“进化引擎”。
- 数据(Data) 是“燃料”。
- RLHF 是“价值观校准器”。
- 而世界模型(World Model) 则是“无限的训练场。
这三个齿轮的紧密啮合,最终将一个VLA“新手”,“炼成”了一个真正无惧“长尾场景”、且“行为对齐” 的“老司机”。
四、VLA带来的“物理智能体”新范式
在前面几章中,我们已经深入拆解了VLA的“是什么”(E2E之辨)、“为什么”(VLM顽疾)、“如何进化”(四大阶段)、“如何实现”(MindVLA 与ORION 架构)、“用什么造”(技术栈)以及“如何训练”(闭环飞轮)。
但所有这一切复杂的技术,最终必须回答一个终极问题:“它到底有什么用?”
VLA的终极目标,就是为了攻克传统自动驾驶(无论是基于规则还是VA黑箱)都难以解决的“长尾问题”(Corner Cases)。

这些“长尾场景” 的共同点是,它们无法通过“找规律”来穷举,而必须通过“阅读”和“推理”来理解。VLA,这个拥有“语言大脑” 的架构,正是为解决这一问题而生的。
而当VLA成功地将V(视觉)、L(语言)和A(行动)融合在一起时,它所带来的,就不再仅仅是一个“更好”的自动驾驶功能,而是一个全新的物种:“新产品范式——物理智能体”(New Product Paradigm - Physical Agent)。
“物理智能体” 不再是一个被动执行固定指令的“工具”(Tool),而是一个能与你沟通、能理解你意图、能自主规划的“专属司机”(Chauffeur)。
这种革命性的价值,具体体现在以下四大“用户可感知”的能力上:
4.1 “听得懂”:从“固定指令”到“自然语言理解”
这标志着人车交互的根本性飞跃。
- 过去(非VLA): 你只能说:“导航去星巴克。”
- 现在(VLA): 你可以说:“帮我找个星巴克,在门口把我放下。”

VLA的L模块(大脑) 不仅能解析“星巴克”(一个POI),更能理解“在门口”(一个精确的空间意图)和“把我放下”(一个驾驶动作)。更强大的是,这种交互是可修正的。在行驶途中,你可以随时打断它:“前面路口你最好左转,更顺路。”——VLA能够实时理解这种复杂的、带有上下文的、口语化的新指令,并立即重新规划动作。
4.2 “看得见”:从“依赖地图”到“实时视觉推理”
这标志着VLA开始摆脱对高精(HD)地图的绝对依赖。
- 过去(非VLA): 在没有高精地图覆盖的区域(如大型停车场或新修道路),车辆寸步难行。
- 现在(VLA): 你可以在一个完全陌生的地方,拿出手机拍一张周围的“地标照片”(例如一个便利店的门脸),然后发给你的车。VLA的V模块(眼睛) 会启动“视觉搜索”,将“照片”与它的“实时摄像头”画面进行匹配,然后开到你面前来接你。
4.3 “找得到”:从“被动执行”到“主动推理规划”
这标志着VLA真正拥有了“自主智能”。
- 过去(非VLA): 你需要把车开到车位前,启动“自动泊车”,车辆只负责最后一步的“执行”。
- 现在(VLA): 你可以在停车场入口下车,告诉它:“你自己去占个车位停下”。
MindVLA的L模块(大脑) 会启动“推理”,A模块(手脚) 会启动“探索”。最关键的是,这个过程是“without navigation”(在没有导航的情况下) 发生的。VLA会自主地在停车场内“巡航”寻找空位,如果开进了“死胡同”(dead ends),它能“自主意识到”并“倒车”(reversing out) 出来,继续寻找,直到任务成功完成。
4.4 “跑得通”:从“标准路况”到“攻克长尾场景”

这标志着VLA正将它承诺的“长尾能力” 落地为“可用产品”。
过去(非VLA): 面对可变车道、潮汐车道、ETC收费站,系统只能频繁“降级”或“要求接管”。
现在(VLA): 这张图所展示的交付成果,就是VLA价值的最终兑现:
- “车位到车位”(Parking to Parking):实现了从出发车位到目的车位的“无人工干预”全端到端通行。
- “全国ETC自动通行”(Seamless Easy Pass Lane Recognition)。
- “可变车道的自适应使用”(Adaptive Use of Reversible...Lanes)。
- “智能等待区进入”(Smart Waiting Area Entry),这是通过“实时LED文本理解”(Real-time LED Text Understanding) 来实现的。
这证明了VLA不仅能“看懂”图中的那些复杂路牌,并且真的能“跑通”。
这些令人惊叹的“用户可感知价值”,只是“物理智能体” 浮在水面上的“冰山一角”。它们之所以能实现,是因为VLA这个“统一大脑” 拥有了四项革命性的“内在价值”:
- 思维能力 (CoT): VLA具备了“思维链”(Chain of Thought)的推理能力。
- 沟通能力: VLA可以真正用“语言”(Language)与人类进行双向交流。
- 记忆能力: VLA拥有了“记忆”(Memory),能理解长时程的上下文(如ORION的QT-Former)。
- 自主学习能力: VLA拥有了“世界模型” 和“RLHF”,具备了强大的“自主学习”进化能力。
五、VLA大规模落地的四大挑战
VLA的“物理智能体” 愿景令人激动,它描绘了一个能听懂、看懂、自主规划的未来。理想汽车等先行者甚至已经开始将VLA推向量产车型。
但我们必须保持清醒:从“技术演示”到“大规模可靠部署”,VLA还有一条漫长且充满荆棘的道路要走。正如综述所言,VLA的落地正面临着四大核心挑战,它们像四座大山,横亘在“未来”与“现在”之间。

5.1 算力之墙 (Compute):当“大脑”太重,塞不进“头盔”
VLA的“统一大脑” 功能强大,但也极其“沉重”。
- 参数量巨大: 一个7B(70亿)参数的Llama 2 只是VLA“大脑” 的“起步价”。未来“基础驾驶大模型” 的参数量只会更大。
- 实时性要求苛刻: 自动驾驶的控制循环必须达到30Hz(每帧约33毫秒)甚至更高,才能保证高速行驶时的安全响应。
将如此庞大的模型,塞进功耗和成本都极其受限的车端芯片(Edge Inference)——无论是英伟达的Orin-X 还是未来的THOR-U——并让它在33毫秒内完成一次“看->想->动”的完整推理,这几乎是一个“不可能的任务”。
这正是VLA落地的最大工程瓶颈。理想汽车强调,“在VLA时代,推理算力比训练算力更重要”。
目前的解决方案包括:
- 架构优化: 采用MoE(稀疏激活) 和并行解码(Parallel Decoding) 等技术从根本上降低推理计算量。
- 模型压缩: 通过硬件感知的量化(如FP8 / INT8 推理) 或知识蒸馏,将大模型压缩成适合车端部署的“微型VLA”。
5.2 数据之渴 (Data):当“燃料”稀缺且昂贵
VLA的“智商”是靠“(视觉+语言+行动)三模态对齐” 的数据“喂”出来的。但这种高质量的“燃料” 极其稀缺且昂贵。
- 收集成本高昂: 获取一个包含“驾驶员内心想法”(语言L)的驾驶片段,远比录制一段普通视频(视觉V+行动A)要困难得多。Impromptu VLA 数据集 需要手动标注8万个驾驶片段,成本惊人。
- 覆盖“长尾”困难: VLA最需要训练的,恰恰是那些最危险、最稀有的“犄角旮旯”(corner-case)场景。但这些场景在现实数据中本就罕见,获取足够的训练样本更是难上加难。
- 标注质量难以保证: 即便有了(V+A)数据,如何精准地标注出对应的“语言”(L)——即驾驶员的“思维链”(CoT)——本身就是一个巨大的挑战。自动化标注流水线(如Chat-B2D)虽然高效,但其标注质量仍依赖于“教师VLM”的能力上限。
“数据” 是VLA的生命线,但这条生命线正面临着“供给不足”的严峻挑战。
5.3 安全之问 (Robustness):当“大脑”产生“幻觉”
LLM(大语言模型) 的引入,赋予了VLA强大的推理能力,但也打开了一个“潘多拉魔盒”:新的失效模式。
- “幻觉”(Hallucination): 这是LLM最臭名昭著的问题。如果VLA“幻觉”出一个不存在的障碍物并紧急刹车,或者“幻觉”出一个可以通过的绿灯而闯了红灯,后果不堪设想。
- 指令误解: VLA能“听懂人话”,但也可能“听错”。它可能会错误地解析人类的口头俚语指令(例如将“floor it”——“踩满油门”理解为字面意思)。
- 环境噪声: VLA必须在恶劣天气(雨、雪、眩光)导致的传感器数据损坏,以及充满背景噪音的语音指令下保持稳定。
更深层次的问题是:我们如何对一个由“自然语言”驱动的系统进行形式化的安全验证? 传统的安全规则(如“红灯停”)是明确的,但VLA的决策过程充满了LLM的“黑箱”推理。虽然像SafeAuto 那样引入基于逻辑的安全否决机制是第一步,但如何确保VLA的每一个决策都既“智能”又“绝对安全”,在很大程度上仍是未解难题。
5.4 感知之差 (Perception):当“用户觉得”不够惊艳
最后一个挑战,可能出乎很多工程师的意料,它来自于用户端。
VLA带来的技术飞跃是毋庸置疑的。但这种飞跃,用户能“感知”到多少?
正如理想汽车的市场反馈所揭示的:“VLA的感知价值目前还不大,对卖车还没有显著的帮助。”
原因可能有三:
- 新事物认知需要时间: VLA是一个全新的概念,大部分用户还没感知到它的价值。
- 价值在未来,付费在现在: VLA的强大可能在将来(如L3/L4),但掏钱买车是现在。
- L2->L2.9的“边际效用递减”: 最关键的是,现有的L2/L2+(非VLA)系统已经做得相当不错了。VLA带来的提升,更多是从“L2.5提升到L2.9”,解决了那些“犄角旮旯”的长尾问题。但只要系统还停留在L2+(需要驾驶员负责),用户感知的核心差异就不大。
这就像电动汽车的续航里程:
- 从300公里提升到500公里,用户会激动万分。
- 从700公里提升到800公里,用户可能会想:“免费送就要,加钱就算了!”
VLA目前就处在类似700到800的“感知瓶颈期”。工程师们在攻克99%到99.99%的难题,但用户可能只关心那决定性的、从“需要负责”到“无需负责”的L3门槛何时到来。算力、数据、安全和用户感知——这四大挑战如同四座沉重的大山,压在VLA通往大规模落地的道路上。下一代自动驾驶的革命已经打响,但胜利的果实,仍需时间和巨大的努力去摘取。
六、结语:不止于车,VLA是通向“具身智能”的基石
行文至此,我们已经完整地拆解了VLA(视觉-语言-行动)这一革命性的技术范式。我们见证了它如何从“快慢双核”的拼凑 进化为“统一大脑”;深入剖析了MindVLA 和ORION 等顶尖架构的工程实现;理解了其成功的基石——强大的技术栈(V/L/A) 和闭环飞轮(数据/RLHF/世界模型);也正视了它在大规模落地前必须克服的四大挑战(算力/数据/安全/感知)。
但VLA的故事,远不止于“更好的自动驾驶汽车”。
MindVLA的架构图 被同时标注为“用于自动驾驶的物理AI框架” 和“用于机器人的物理AI框架”(A Physical AI Framework for Robotics),这一细节揭示了VLA更宏大的野心:它的架构具有惊人的通用性,其终极目标是驱动所有与物理世界交互的“具身智能”(Embodied AI)。
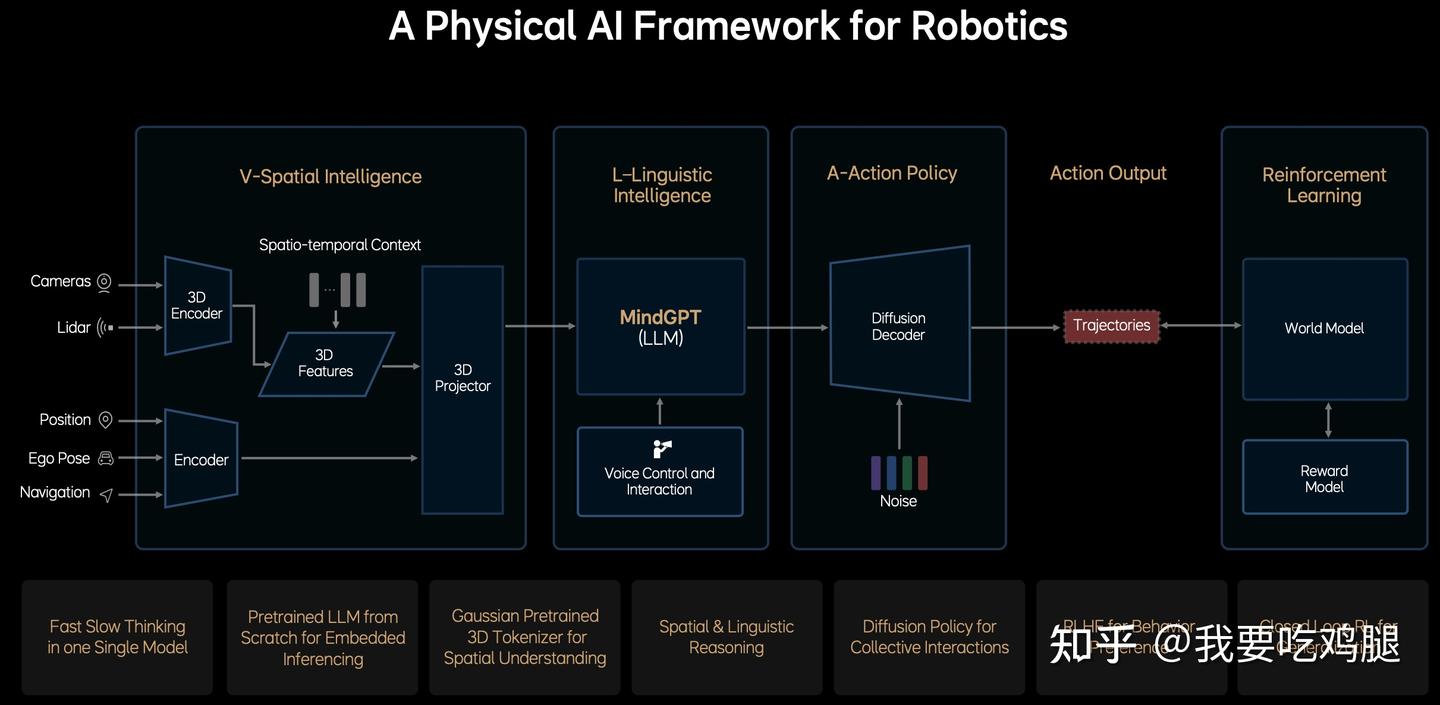
开源社区的OpenVLA项目,更是这一通用性的绝佳例证。
- 架构:OpenVLA 采用了与自动驾驶VLA极其相似的技术栈:Llama 2 7B(L大脑) + DinoV2与SigLIP(V眼睛) + MLP动作解码器(A手脚)。
- 训练: 它在一个包含97万个真实世界机器人演示片段(如抓取、放置、擦桌子) 的大规模数据集上进行了训练。
- 成就: 结果令人瞩目。OpenVLA在复杂的机器人操作任务上的成功率,全面超越了此前由谷歌闭源模型RT-2-X保持的记录。
- 开放: 更重要的是,OpenVLA将其数据、权重和代码全部开源,极大地推动了整个具身智能领域的发展。
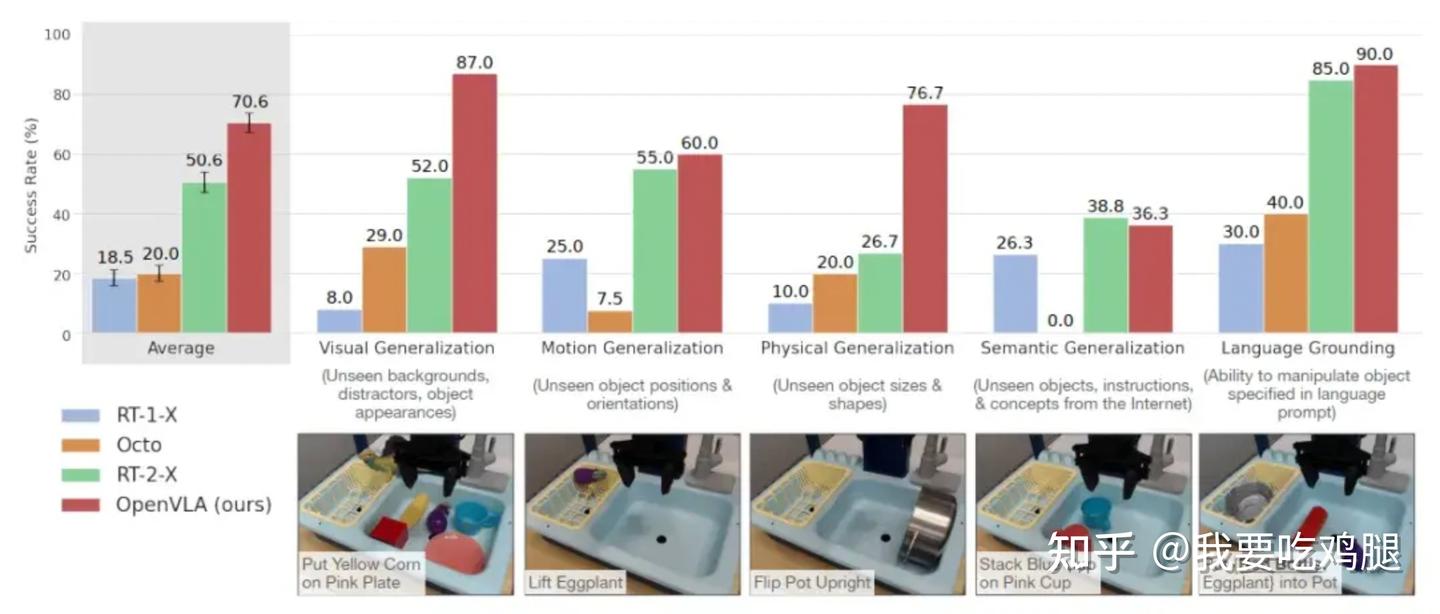
OpenVLA 的成功证明了:VLA不仅仅能“开车”,它还能“操控机械臂”、“理解指令”、“与物理世界交互”。它正是通往通用“物理智能体” 的那把钥匙。
展望未来,VLA的发展将走向何方?麦吉尔大学和清华大学的综述 为我们指明了几个激动人心的方向:
- 基础驾驶(物理)大模型 (Foundation Models): 构建一个GPT风格的“物理世界骨干”模型,通过少量数据微调即可适配不同的车辆或机器人。
- 神经-符号安全内核 (Neuro-symbolic Kernels): 将VLA的“神经网络直觉”与“符号逻辑规则”相结合,为其决策提供“安全气囊”。
- 标准化交通(交互)语言 (Standardised Language): 让车辆之间(V2V),甚至人与机器人之间,能用一种标准化的“语言”高效协作。
从VA的“老司机直觉”,到VLM的“夸夸其谈”,再到VLA的“可解释的大脑”,我们正处在一个激动人心的技术拐点。VLA不仅是自动驾驶的下一次范式革命,更是开启通用“物理智能体”和“具身智能”时代的基石。未来的世界,将由这些能看、能说、能思考、更能行动的智能体,以前所未有的方式重塑。