作者:瑕疵很多的大宝贝
https://zhuanlan.zhihu.com/p/1969540014166761755
随着 DeepSeek-V3、Ling 2.0、Minimax-M2 等顶级开源大模型纷纷使用 FP8 精度进行预训练,FP8 训练也算经受住了考验,得到了顶尖实验室的认可。本文会详细介绍不同的 FP8 recipe,以及使用 FP8 加速计算和通信、降低显存占用的技术细节。本文也是对 2025 年 6 月 NVIDIA AI Open Day 北京站上的 talk 《FP8 混合精度训练方案与性能分析》的前半部分的扩充和勘误。尤其是考虑到其中一些问题还经常在各种场合被问到,文字内容还是更方便拿来作为参考。
1. FP8 是什么
FP8 是一种 8 位的浮点数数格式,NVIDIA 从 Ada(SM89)和 Hopper(SM90)这一代开始提供 FP8 精度的 Tensor Core 支持。在 NVIDIA GPU 上,提供两种 FP8 格式:
- E4M3:由 1 个符号位、4 个指数位和 3 个小数位组成,在 PyTorch 中对应的数据类型是 torch.float8_e4m3fn;
- E5M2:由 1 个符号位、5 个指数位和 2 个小数位组成,在 PyTorch 中对应的数据类型是 torch.float8_e5m2。
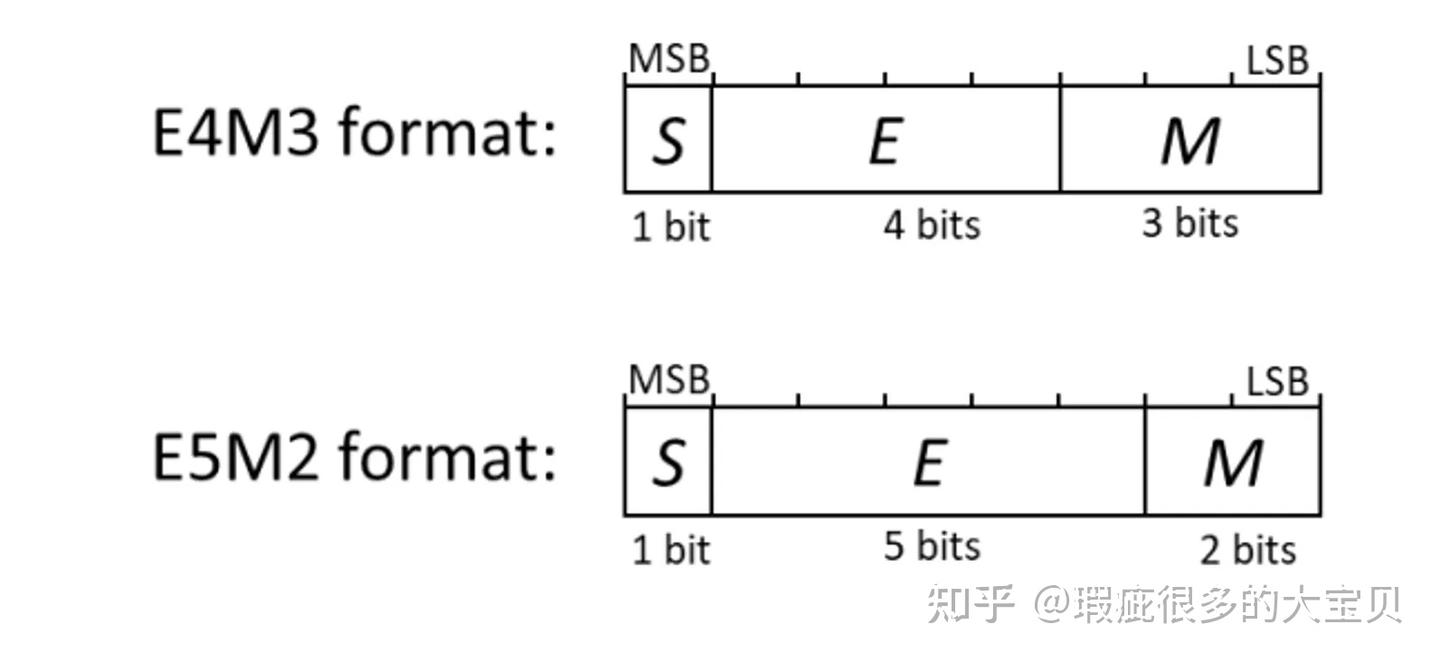
那有的小伙伴可能要问了,为什么 torch.float8_e4m3fn 结尾有个 fn 呢?其实这里的 E4M3 和 E5M2 是 OCP 标准的 FP8 格式,参考图 2。其中 E4M3 没有保留对 inf 的表示,所以 PyTorch 给它加了一个后缀 fn。

OCP 同时还定义了 MXFP8 的标准,即每 32 个 E4M3/E5M2 的 FP8 数据共享一个 E8M0 的 scale,如图 3、4 所示,均截图自 OCP 白皮书。


那么为什么要使用 FP8 进行训练呢?泛泛而谈的话,我们可以很容易列出以下这些好处:
- 加速计算。FP8 Tensor Core 的算力是 BF16 的两倍,这可能也是大家希望使用 FP8 训练的主要动力;
- 节约显存。使用 FP8 训练,在理想情况下,应该能把 weight 和 activation 占用的显存减半;
- 加速通信。如果通信也能用 FP8,就能减少一半的通信量。
听起来确实很美好,那实际情况是什么样呢?后面的内容我会先介绍一下不同的 recipe,然后从计算、存储、通信三个方面来讨论 FP8 training 的一些细节。
2. FP8 Recipe
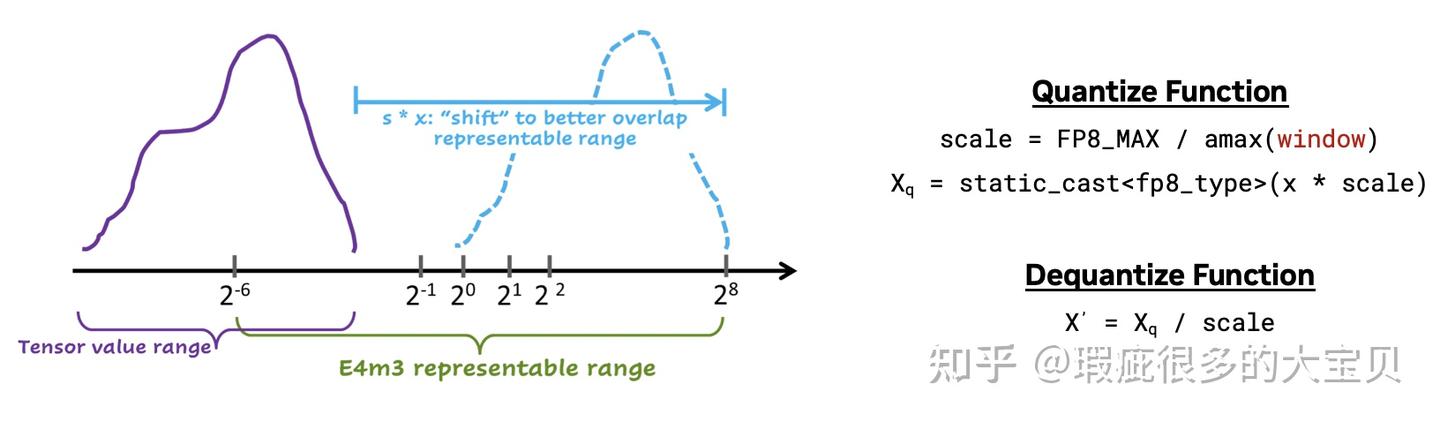
FP8 的表示范围和精度都有限,因此想要使用 FP8 进行训练,必须要有一套缩放算法。熟悉混合精度训练的读者应该知道,BF16 训练是不需要缩放的,FP16 训练需要一个全局的缩放因子。而 FP8 的缩放算法是以一个 tensor 或者一个 tile(也被称为 sub-channel/group/block 等)为一个单元,将其中绝对值最大的值(absolute max,即 amax)放缩到 FP8 能表示的最大值,其他值按比例缩放。如图 5 所示:
NVIDIA Transformer Engine(TE) 提供了完整的 FP8 训练解决方案,包括量化、GEMM kenrel 等。这里顺便介绍一下 Megatron-Core(MCore) 和 TE 的关系,如果以一个 transformer layer 为分界线,
- TE 负责 layer 以内的东西,如低精度量化、GEMM、大部分的 kernel fusion、scaled dot product attention(SDPA)backend 、tensor parallel(TP)overlap、context parallel(因为 CP 的实现可以认为是藏在 Attention 内部,外部不需要感知)等;
- MCore 负责 layer 以上的东西,如模型并行(PP/EP/DP)、模型的搭建、optimizer、checkpoint 等。
在讨论 FP8 训练的时候,我们经常听到一个词:FP8 recipe,它至少包含了以下这些方面:
- FP8 的格式:一般来说,有两种选择,一种是纯 E4M3;一种是 Hybrid,也就是 activation 和 weight 用 E4M3,gradient 用 E5M2,这样在前向的时候是一个 E4M3E4M3 的 GEMM,而反向的时候是两个 E4M3E5M2 的 GEMM。
- 量化的粒度:FP8 训练至少需要 per-tensor 的量化粒度,也就是每个 tensor 计算一个 scale。如果以更细的粒度进行量化,那就需要确定量化 tile 的大小、以及 tile 是 1D 还是 2D 的。
- 模型中的哪些部分可以使用 FP8 量化:这个目前比较统一,也就是所有的 linear layer 都进行 FP8 量化。以一个典型的 transformer layer 为例就是 qkv linear、projection linear、fc1 和 fc2 都进行 FP8 量化,而 embedding、lm head、SDPA、main gradients、optimizer(包括了 main parameters、optimizer states)等仍然保持在原有的高精度。没有 reduction 的通信理论上都可以使用 FP8,例如 AllGather、AlltoAll 等,而有 reduction 的通信仍然保持高精度。现在也有一些工作在探索 FP8 attention,但目前没有实际的生产模型使用。
理论上来说,可以任意组合上述的条件来造出很多 FP8 recipe,但实际上常用的、TE 支持的有以下几种:
1、Per-tensor scaling recipe:使用 Hybrid format,量化粒度为一个 tensor。per-tensor scaling 实际上又包含了两种实现,区别在于如何计算图 5 中的 amax:
- Delayed scaling:amax 是从一个包含了过去若干个 step 的 amax 的 history buffer 中取的最大值。这样做的好处主要是打破了 “计算 amax” 和 “对数据进行量化” 之间的依赖,并且只需要读一次 global memory,就可以在对数据进行量化的同时统计当前的 amax 并加到 history buffer 中,因此性能比较好。但是其缺点是由于用来量化的 amax 不是当前的真实值,精度可能存在一些问题。我们的实验表明在大于 7B 的模型上就可以观察到 delayed scaling 带来的收敛问题。因此在当下,我们可以直接忽略 delayed scaling。
- Per-tensor current scaling:或者叫 live scaling、in-time scaling 之类的。它的实现非常直观,就是对当前的 tensor 统计 amax,然后计算 scale,再对数据进行量化。它的缺点就是需要读两次 global memory,一次统计 amax,一次进行量化,因此性能会比 delayed scaling 稍差一点。Nemotron-H-56B 使用了 per-tensor current scaling 进行训练,证明了 per-tensor current scaling 的收敛性。
2、Blockwise scaling recipe:MCore 和 TE 里的 blockwise recipe 特指 DeepSeek-V3-like,也就是使用纯 E4M3 的量化格式、input 和 gradient 以 1x128 的 1D tile 进行量化、weight 以 128x128 的 2D tile 进行量化。这也是现在最流行的 FP8 training recipe,有多个顶级大模型为其背书。
3、MXFP8 scaling recipe:使用纯 E4M3 的格式,input、gradient、weight 均以 1x32 的 tile 进行量化,scaling factor 格式为 E8M0。理论上来说,MXFP8 的量化粒度比 Blockwise scaling 更细,在精度上也会更好。这也是 NVIDIA 在 Blackwell 上主推的 FP8 recipe。
3. FP8 计算
我们结合具体的硬件平台来看一下不同 FP8 recipe 的计算流程。首先以一个 linear module 为例,BF16 训练的计算流程如图 6 所示。fprop/dgrad/wgrad 三个 GEMM 的输入都是 BF16,fprop/dgrad 的输出也是 BF16,而 wgrad 的输出通常是 FP32,因为 gradient 需要累加,最好使用 FP32 来保证精度。另外值得注意的是,在 Tensor Core 内部都是使用 FP32 进行累加的,输出的不同精度只是最后 cast 出来的,这一点对 BF16 和 FP8 GEMM 都是成立的。
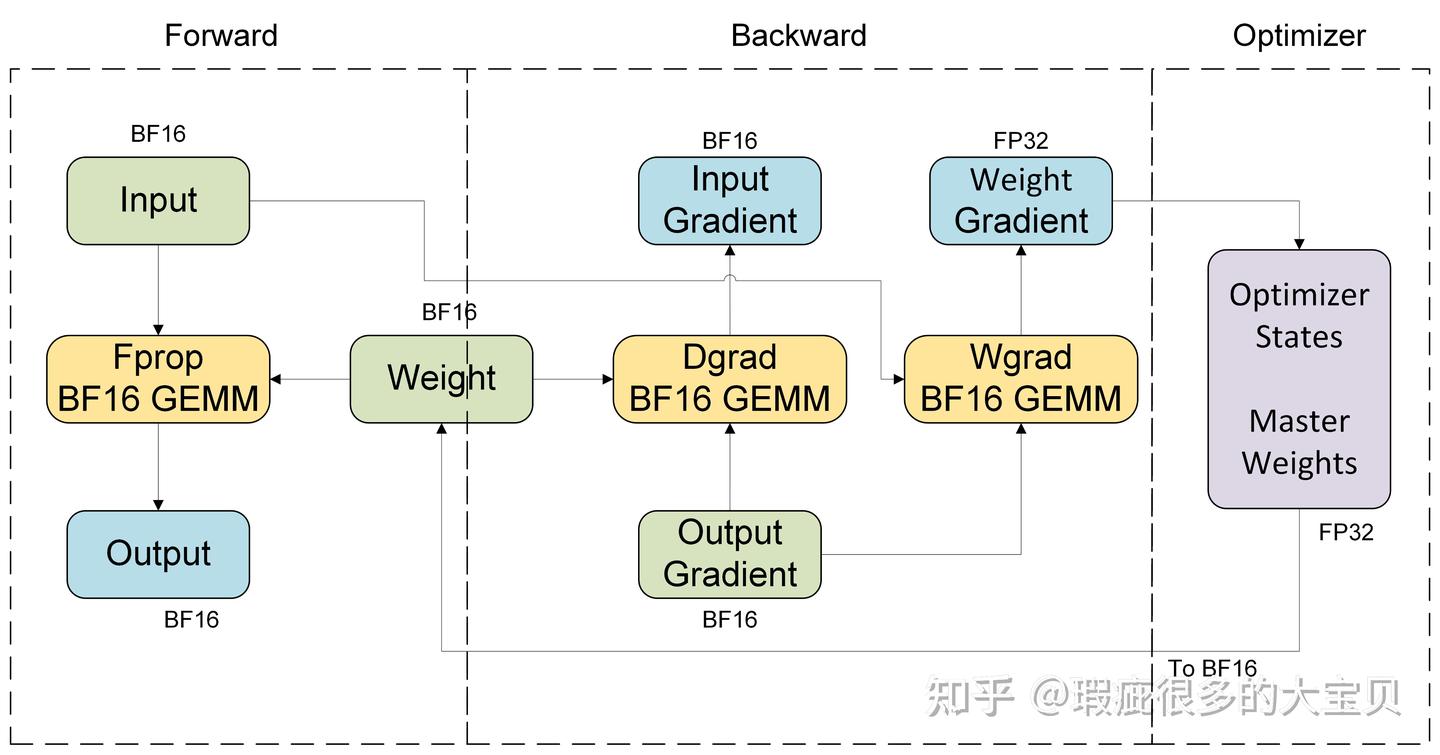
使用 FP8 加速训练,其实就是在加速 fprop/dgrad/wgrad 这三个 GEMM,我们要做的主要就是把 GEMM 的 input 量化到 FP8,而 GEMM 的 output,如图 6 所示,是 BF16 或者 FP32 的,一般情况下不需要进行量化。另外,具体的计算流程其实会跟硬件平台有关,因为 Hopper 上只支持 TN layout(以 cuBLAS 的视角,cuBLAS 是 column major 的,它和 PyTorch Linear 的关系可以参考这篇文章) 的 FP8 GEMM,因此需要 input/weight/gradient 的转置来进行 dgrad 和 wgrad GEMM 的计算。而 Blackwell 平台支持任意 layout 的 FP8 GEMM,因此它不需要进行转置,但如果量化方向不同,仍然需要 row-wise 和 col-wise 的数据。
3.1 Per-tensor Current Scaling
TE v2.2 和 MCore 0.13 版本开始添加了 per-tensor curren scaling 的支持。
如果直接使用 TE,我们只需要在 autocast context 里指定 recipe 为 Float8CurrentScaling,即
with fp8_autocast(fp8_recipe=Float8CurrentScaling()):
model()
如果使用 MCore,则可以通过命令行参数开启
--fp8-format hybrid
--fp8-recipe tensorwise
3.1.1 Hopper 平台
Hopper 平台上的 per-tensor current scaling 的计算流程如图 7 所示。我们会用一个量化 kernel 同时对 tensor 进行 cast 和 cast_transpose 操作,其中 weight 的量化只发生在第一个 micro batch 并被保存下来,后续同一个 global step 里的 micro batch 会直接复用这个 cache,这个优化对于所有的 recipe 和硬件平台都是通用的。而在前向计算结束后,对于 input,我们仅保存一份 colwise 的 fp8 量化版本来做反向计算(即虚线框里的都不会被保存),因此可以减少保存的激活值大小。
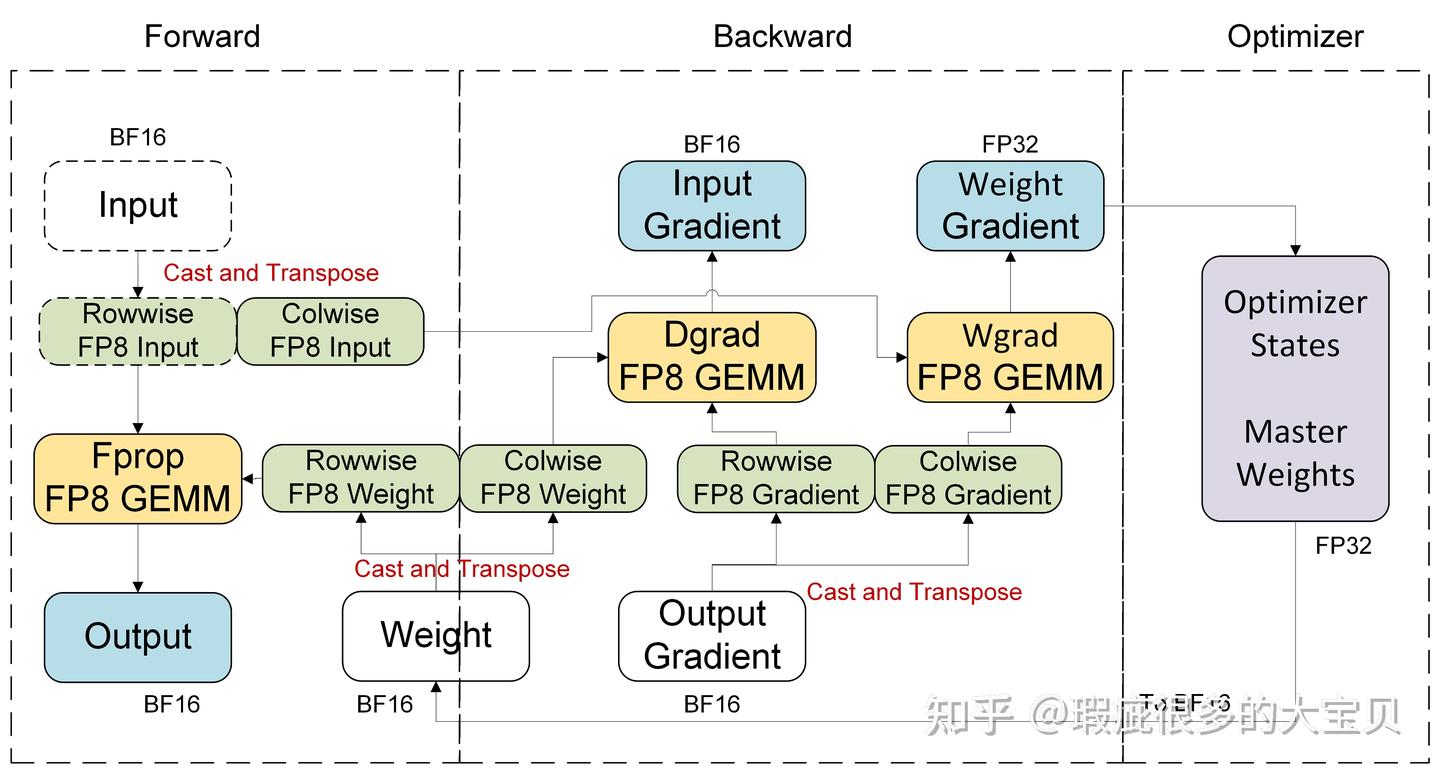
假设 input 的 shape 是 [m, k]、weight 的 shape 是 [n, k],如果对应到模型里,m 是 token 的数量,k 是 input hidden size,n 是 output hidden size,那么三个 TN layout 的 GEMM 的计算公式为
Y[m, n] = W[n, k] @ X[m, k]
dX[m, k] = W^T[k, n] @ dY[m, n]
dW[n, k] = X^T[k, m] @ dY^T[n, m]
其中 [ ] 里为每个 tensor 的 shape,后文中均遵循这种 notation。
3.1.2 Blackwell 平台
Blackwell 平台支持任意 layout 的 FP8 GEMM,因此每个 tensor 只需要一份 FP8 量化的版本,而不需要转置。其计算流程如图 8 所示。

三个 GEMM 的计算公式为
Y[m, n] = W[n, k] @ X[m, k] # TN layout
dX[m, k] = W[n, k] @ dY[m, n] # NN layout
dW[n, k] = X[m, k] @ dY[m, n] # NT layout
3.2 Blockwise scaling
TE v2.3 和 MCore v0.13 版本增加了对 blockwise scaling recipe 的支持,同时要求 CUDA 12.9+。
如果直接使用 TE,我们只需要在 autocast context 里指定 recipe 为 Float8BlockScaling,即
with fp8_autocast(fp8_recipe=Float8BlockScaling()):
model()
如果使用 MCore,则可以通过命令行参数开启
--fp8-format e4m3
--fp8-recipe blockwise
Blockwise scaling 在 Hopper 平台上的计算流程如图 9 所示

对于 Linear module 来说,它和 per-tensor current scaling 的区别只是量化方式的区别,其他方面都是类似的。三个 GEMM 均为 TN layout,计算公式为
Y[m, n][BF16] = W[n, k][128x128] @ X[m, k][1x128]
dX[m, k][BF16] = W^T[k, n][128x128] @ dY[m, n][1x128]
dW[n, k][FP32] = X^T[k, m][1x128] @ dY^T[n, m][1x128]
第二个 [ ] 表示精度(BF16/FP32)或者是 FP8 的量化粒度。可以看到,我们其实只需要两种 blockwise (有的地方也叫它 groupwise 或 sub-channel)GEMM,即 128x128 @ 1x128 (2Dx1D)和 1x128 @ 1x128(1Dx1D)。cuBLAS 从 12.9 版本开始支持 Hopper 上的这两种 GEMM,DeepGEMM 在最开始的版本仅支持 2Dx1D,但也在后续的版本里添加了对 1Dx1D 的支持。
在很长一段时间内,blockwise scaling 仅支持 Hopper 平台,因为在 Blackwell 上我们有更精细化的 MXFP8 recipe。但是考虑到用户迁移的成本,TE 现在也在 Blackwell 平台上,通过 MXFP8 模拟的方式,支持了 Blockwise scaling recipe。也就是将一个 1x128 的 tile 表示为 4 个共享 scaling factor 的 MXFP8 (128x128 可以表示为 128x4 个 MXFP8),最终调用 MXFP8 GEMM 来实现上述 2Dx1D 和 1Dx1D GEMM 的计算。
观察上面的计算流程,不难发现,如果是在 Blackwell 平台上,实际上我们只需要一份 FP8 weight。因为对于 2D 量化来说,cast 和 cast_transpose 的数值是一样的,仅仅是内存上转置了一下,对于 Blackwel 平台来说是不必要的。
3.3 MXFP8 recipe
TE v2.0 和 MCore v0.12 开始提供了 MXFP8 recipe 的支持。MXFP8 仅支持 Blackwell 平台,因为只有 Blackwell 的 Tensor Core 支持 MXFP8 的 GEMM,这是一个硬件限制,或者说新硬件的新功能。
如果直接使用 TE,我们只需要在 autocast context 里指定 recipe 为 MXFP8BlockScaling,即
with fp8_autocast(fp8_recipe=MXFP8BlockScaling()):
model()
如果使用 MCore,则可以通过命令行参数开启
--fp8-format e4m3
--fp8-recipe mxfp8
MXFP8 recipe 在 Blackwell 平台上的计算流程如图 10 所示,

需要强调的是,因为 Blackwell 支持任意 layout 的 FP8 GEMM,所以上图中的 rowwise 和 colwise,仅是量化的方向不同,在内存上没有进行转置。三个 GEMM 的计算公式为
Y[m, n][BF16] = W[n, k][1x32] @ X[m, k][1x32] # TN layout
dX[m, k][BF16] = W[n, k][32x1] @ dY[m, n][1x32] # NN layout
dW[n, k][FP32] = X[m, k][32x1] @ dY[m, n][32x1] # NT layout
这一部分在我 6 月份 AI Open Day 的 talk 中其实是出现了一些错误,这里也是对其进行了修正。
我们可以看到,由于 MXFP8 recipe 中 weight 也选择了 1D 量化,因此即使 Blackwell 支持任意 layout 的 FP8 GEMM,我们也需要保存两份 FP8 量化的 weight tensor,即 rowwise 和 colwise。而如果选择 2D 量化(如 32x32),则可以避免这种情况。
4. FP8 存储
本章讨论一下使用 FP8 训练对显存的影响:FP8 能不能减少显存的占用?答案是能,但没有那么容易😂
4.1 FP8 weights
细心的小伙伴可能已经发现了,前面 Linear module 计算流程的图里,都有一个略显奇怪的点:我们的 FP8 weight 是从 BF16 weight 量化而来的。这意味着,我们需要在训练中同时保存 BF16 和 FP8 的 weight,导致 FP8 训练的显存占用甚至比 BF16 还高。为什么要这么做呢,我个人总结主要有两个原因:
- 这个方案可以让 FP8 linear drop-in replace BF16 linear,因为量化到 FP8、FP8 GEMM 等过程完全发生在 FP8 linear module 的内部,甚至最后计算出来的 wgrad 都是 attach 到 BF16 model weight 上的,用户完全不需要管具体的细节。
- 实现简单。这个后面会具体解释。
那么能不能去掉 BF16 weight,直接从 FP32 的 master weights 量化到 FP8 的 weight 呢?技术上肯定是可行的,而且可以和保留 BF16 weight 的方案保持 bitwise 对齐,只是会非常复杂,因为我们需要解决两个问题:
1、FP8 tensor 的表示。由于在这个方案下,FP8 weight 直接暴露到 linear module 的外部,因此需要一个对象对其进行表示,且由于 PyTorch autograd 机制的限制,这个对象必须是一个 PyTorch tensor。
那么 torch.float8_e4m3fn 类型的 tensor 行不行呢?答案是不行,第一它不带 scale,第二它不能同时包含 rowwise 和 colwise data。为了解决这个问题,TE 继承 torch.Tensor 实现了一个 QuantizedTensor 对象。但继承 torch.Tensor 是有代价的,对其进行很多操作都会附带一些额外的 CPU overhead。
2、兼容 Distributed Optimizer(DistOpt,MCore 的ZeRO-1 实现)。由于 ZeRO-1 是一个免费午餐,它没有增加通信量,却减少了 optimizer states 的显存占用,同时把 AllReduce 拆成了 ReduceScatter 和 AllGather,使得 DP 的通信可以和计算进行 overlap,因此在 LLM training 里面基本都是默认打开的。
MCore 的 DistOpt 的实现中,为了让保证不同 chunk 的 RS 和 AG 通信的均衡,将 master weights 展开成一个 1维 tensor、拼起来、再在 DP rank 之间进行均匀切分(参考 MCore 文档里的这两幅图)。
那么当我们想要直接从 FP32 的 master weights 量化到 FP8,再进行 FP8 的 AllGather 时,问题就出来了:每个 rank 上只有 1/DP 个 master weights 的 shard,也就是说,一个 master weight 可能会被切到多个 DP rank 上,那么怎么做 FP8 量化呢?
几乎每一个 recipe 都需要 case by case 的处理,以 per-tensor current scaling 为例,我们需要以下这些步骤
- 根据 master weights 计算出每个 param 对应的 local amax,对于 rank 上不存在的 param,填 0;
- 对这个 local amax tensor 进行一次 global allreduce max,来得到 global amax;
- 使用 global amax 对每个 rank 上的 parameter shard 进行量化,得到 FP8 的 model weight;
- 对 FP8 的 model weight 进行 FP8 AllGather,完成一轮更新。
图 11 和 12 以 2 个 DP rank、3 个 parameter 为例展示了这个过程,其中绿色的 parameter w_1 被切到了 2 个 rank 上,浅绿色的部分在 DP rank 0 而深绿色的部分在 DP rank 1。
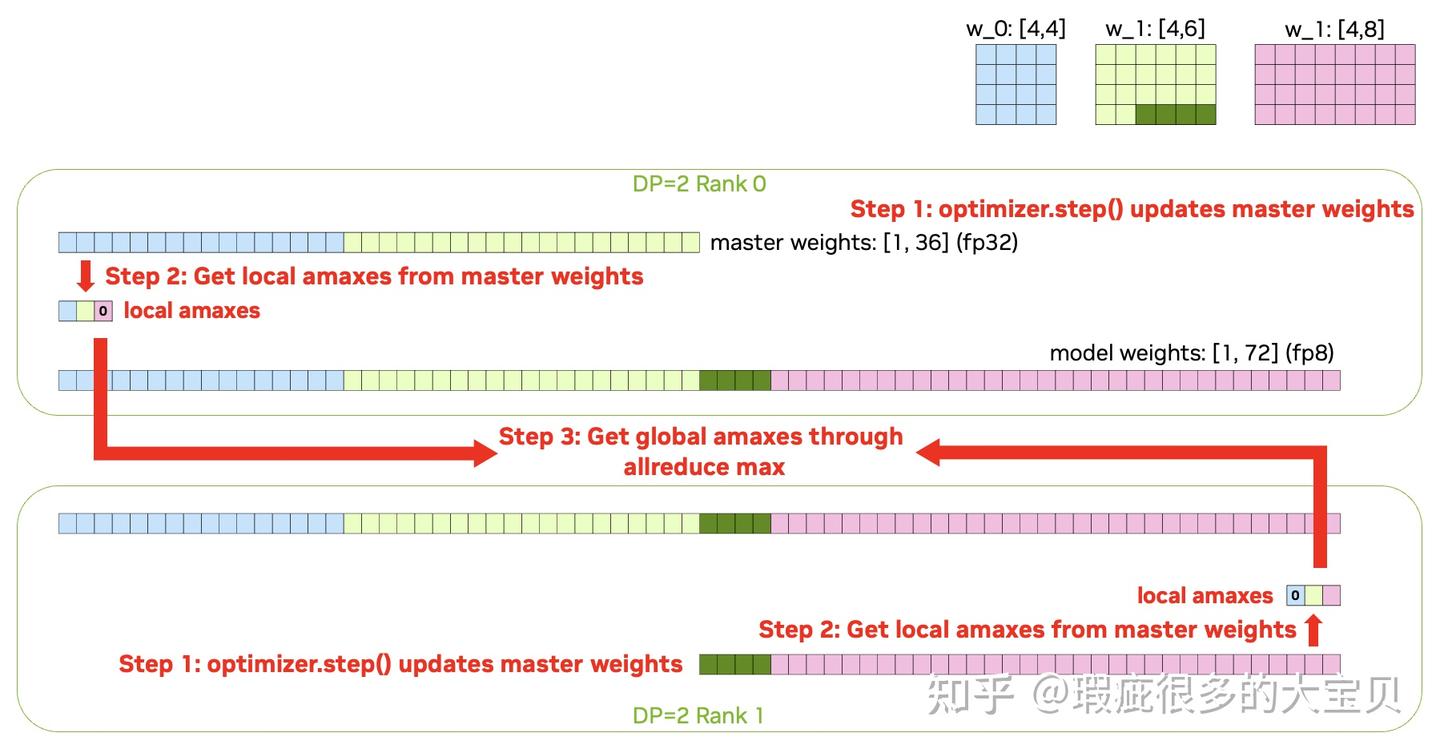

看起来也没有那么复杂是不是,那么留一个作业题,要如何为 Blockwise scaling 和 MXFP8 实现这个 feature?🐶
这个 feature 有很多名字,最开始我们把它叫 “native fp8”,因为保留了 BF16 weights 的方案不够 native。后来可能是觉得 native fp8 不够直观,不知道它具体干了啥,所以有了一个新名字 “FP8 primary weights”,强调了 primary weights 就是 FP8 的而不是 BF16 的。这个名字还不错,但是在 MCore 里,开启这个 feature 的 argument 叫 --fp8-param-gather。。。Emmm 也行吧,它确实也把 parameter gather 变成了 FP8 的通信,但其实反而不如 fp8 primary weights 直观。
在有了这个 feature 之后,FP8 training 的常驻显存(weights、gradients、optimizer states)已经可以跟 BF16 打平了,甚至在某些情况下会更少,比如 per-tensor current scaling on Blackwell 这种只要保存 1 份 FP8 weights 的情况。这里整理了一个表格来方便对比。

表格里的数字代表每一个参数占用的 bytes 数。这里我们不考虑 BF16 optimizer states,因为它和训练精度无关,FP8 training 可以用,BF16 training 也可以用。
另外为什么 BF16 training 的 master weight 这一项是 2 ?因为 TE 里有一个逆天优化叫 store_param_remainders。这个优化是什么意思呢?考虑到 BF16 正好是取了 FP32 的前 16 个 bits,所以如果 model weights 是 BF16 的时候,只要额外再存 16 bits 的 mantissa,那么拼起来不就是 FP32 的 master weights 了?我只能说天才。但是这项优化只对 model weights 是 BF16 的时候生效,因为其他所有的浮点数精度都没有这种性质。
4.2 FP8 activations
这个就比较简单了,前面我们在讲不同 recipe 的计算流程的时候就可以发现,所有的 recipe 都只需要保存一份 colwise fp8 input 来做反向就行了,相比于 BF16 training 直接把保存的激活值减半了。实际训练中,尤其是 MoE 模型,expert 部分的激活值占用的显存是相当大的,因为 expert 部分的 token 数量是膨胀了 topk 倍的。因此使用 FP8 training,激活值占用的显存的降低是很可观的。
但是有两个需要注意的点:
第一个是 SDPA 和 Projection linear 之间的激活值。SDPA 是一个很特殊的算子,它需要额外保存自己的 output 来做反向,而 projection linear 需要正常保存自己的 input 来做反向。如果是 BF16 training,这两个 tensor 实际上是同一个 tensor,只占用一份显存。
但如果是 FP8 training,SDPA 保存的是 BF16 的 output,projection linear 保存的则是这个 BF16 tensor 量化后的 FP8 tensor,这两个 tensor 不再是同一个对象了,因此会占用 1.5 倍的显存。对于这个问题,要么就不管了,占的也不是很多。要么就让 projection linear 保存 BF16 的 input,在反向的时候重新量化一次。
第二个是 TP。这里的 TP 一般默认是指开了 SP 的 TP,也就是通信是 AG 和 RS 的。这个我放在后面和 FP8 通信一起讲。在开了 TP 的情况下,想要同时拿到 FP8 TP AG 通信的收益和 FP8 activation 的显存收益是需要一些额外 efforts 的。
总之,目前我们确实在开了 fp8 primary weights 的情况下,拿到了一些 FP8 节省显存的收益。只是这个收益并不是特别明显,只有在一些特殊的 case 下会对性能有比较大的影响。比如用 2048 个 80GB 的 Hopper 卡训 DeepSeek-V3 的时候,FP8 能跑的并行配置(比如 Deepseek-V3 论文里的那个),BF16 是会 OOM 的。BF16 如果想跑起来,只能调整并行配置,那么性能就差很多了。
5. FP8 通信
前面也提到了,理论上不带 reduction 的通信都可以用 FP8 加速,但也要结合实际情况。而且我们的一个原则是,使用 FP8 通信和不使用,尽量做到数值上是等价的,因此 “量化-通信-反向量” 这种为了加速而加速的方案基本是不考虑的。我们这里就讨论一下各种模型并行 TP/CP/EP/PP/DP 里的通信能不能被 FP8 加速。
首先排除 CP 和 PP。CP 是因为 attention 部分现在都是高精度的,不太可能单独把通信部分量化到 FP8。PP 是因为 PP 的通信量较小,一般能比较好的 overlap。而且 CP 和 PP 里强行用 FP8 通信的话就会是上面说的 “量化-通信-反向量” 这种模式,不但精度是有损的,而且由于量化反量化的开销,速度上也不一定有收益。
DP 的 FP8 通信已经在 4.1 节讲过了,可以把 parameter allgather 变成 FP8 的,而且精度上是无损的(和使用 BF16 allgather 的 FP8 training 比,而不是和纯 BF16 training 比),相当于是把 weight 量化到 FP8 这个过程提前到 optimizer里了。
5.1 TP 通信的 FP8 加速
TP 的 AG 可以使用 FP8,而且也是无损的,区别无非是 “先进行 BF16 AG,再量化到 FP8” 还是 “先量化到 FP8,再进行 FP8 的 AG”。只是这里也需要对不同的 recipe case by case 的处理。我们的原则是要保证开不开 TP 的情况下,量化后的 FP8 tensor 是一样的。例如对于 per-tensor current scaling,那么我们需要
- 计算 local amax;
- 在 TP group 内对 local amax 进行 allreduce amax,得到真正的 amax;
- 对 1/TP 的 shard 进行 rowwise 和 colwise 的量化;
- 对 rowwise data 进行 FP8 AG 来进行 fprop GEMM 的计算。同时将 colwise FP8 data 保存下来,在反向计算的开始阶段,对 colwise data 进行 FP8 AG。
这样我们既能拿到 FP8 通信的收益,又能拿到只保存 1/TP FP8 activation 的显存收益。是不是很简单?那么也留一个作业题,对于 Blockwise scaling recipe 和 MXFP8 recipe,如何实现类似的 feature?🐶
5.2 EP 通信的 FP8 加速
EP 的通信是一个 alltoallv,其 FP8 加速方案 DeepSeek-V3 的报告已经给出来了,而且 DeepEP 的实现也早已开源。
这里我就简单提一下,为什么 EP 通信的 FP8 化是无损的?也很简单,因为从 EP 通信结束到 FC1 的FP8 GEMM,中间所有的 op 都只是内存搬运,因此 “量化到 FP8 → FP8 的 EP 通信 → FP8 的内存搬运 → FP8 GEMM” 和 “BF16 的 EP 通信 → BF16 的内存搬运 → 量化到 FP8 → FP8 GEMM” 在只考虑前向的情况下是完全等价的。
但是如果考虑反向,就不一样了。为了拿到 FP8 通信的收益,EP 通信的时候只能选择传输一份 rowwise FP8 data,没有反向时需要的 colwise FP8 data,因此需要一个额外的 de-quantize and re-quantize (in the other direction) kernel 来得到 colwise FP8 data。这个 kernel 的开销是相当大的。
也因此,在 Grace Blackwell 上,我们没有选择用 FP8 dispatch,因为算上这个反量化再量化的开销,总体是没有收益的。另外就是,这里必须要使用 E8M0 或者说 power-of-2 的 scaling factor,只有这样,double quantization 和 single quantization 的数值几乎是完全等价的(只有一些特殊值不同,比如 sub-normal 的值)。
EP 通信能 FP8 化的还有一个重要原因是 DeepSeek-V3 选择了对 activation 沿 token 纬度进行 1D 量化,这和 DeepEP 按 token 发送数据的设计理念是吻合的。
试想一下,如果是 per-tensor current scaling,要如何实现 FP8 dispatch?几乎是不可能的。因为我们需要保证用不用 FP8 dispatch 是等价的,但是对于 dispatch 之后的 tensor,它在 dispatch 之前是分散在很多个 EP rank 上的,想计算出其 amax 再量化是很困难的。
而且在这种 recipe 下,同一个 token,在被发到不同的 expert 上之后,其量化的结果并不同,这意味着我们几乎无法在 dispatch 之前对其进行量化,因为强行做的话,需要量化出多个版本,这个代价是得不偿失的。同样的,如果对 activation 进行 2D tile 的量化,那也几乎无法实现 FP8 dispatch。
因此 activation 沿 token 维度进行 1D 量化是一个非常重要的选择,类似地 MXFP8 也可以实现 FP8 dispatch。
6. 总结
本文更多的是从计算流程上讨论 FP8 training的一些技术细节,而略去了具体实现上的一些繁杂的优化,尤其是跟 Blockwise scaling 和 MXFP8 的 scaling factor 相关的一系列复杂的要求。毕竟这部分只跟实现上的复杂度有关,而不影响对整体流程的理解,就不过多展开。
从前面的分析可以看出,activation 沿 token 维度进行 1D 量化、weight 进行 2D 量化,是非常正确的选择,对于性能优化非常友好,而且 weight 的 2D 量化还有一些其他很好的性质,这里就不展开。
所以我在想 TE 能不能支持一种 weight 是以 32x32 粒度量化的 MXFP8 recipe?好消息是 NVFP4 recipe 是符合 “activation 沿 token 维度进行 1D 量化、weight 进行 2D 量化” 这一设计理念的。坏消息是,Blackwell 上的 FP4 GEMM 只支持 TN layout,因此即使 weight 是 2D 量化,也需要保存两份。惊不惊喜🐶