作者:dung defender
https://zhuanlan.zhihu.com/p/1974143141406864151
论文:Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting
链接:https://arxiv.org/pdf/2510.18874
这篇paper讲的故事很有意思,说是LLM模型在后训练过程中,SFT和RL的方法相比,更加容易导致灾难遗忘。
这里我们明确一下具体使用的SFT方法和RL方法:
SFT方法
用专家模型来采样下游任务的text 轨迹,然后用supervised learning来更新LLM的权重。(注意啊,这里的SFT数据并没有包含原始的pretrain的数据)
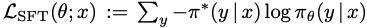
RL方法
用GRPO之类的policy optimization方法来优化LLM在下游任务上的performance,具体的loss是一个task reward 加上 目前LLM和原始LLM的分布的KL loss。
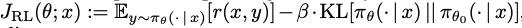
作者通过实验发现RL的方法训练的LLM在原始任务上的forget现象较少,但是sft方法导致的原始任务遗忘现象比较明显。
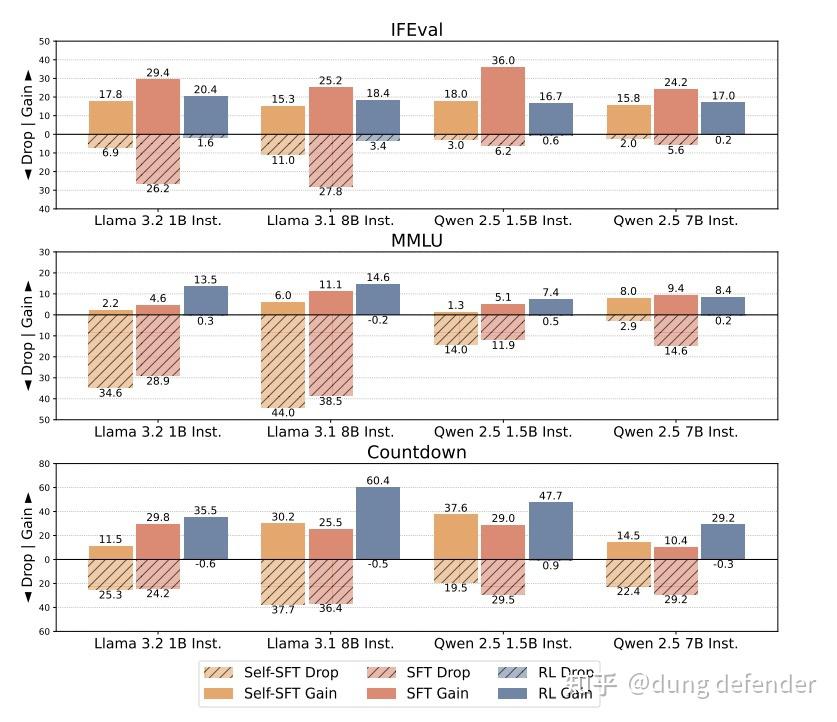
这篇文章用公式分析了很多可能的理论解释。这里我们不推导任何公式,直接从逻辑思考上想一想这个事情。
首先我们要明白SFT和RL的优化方式的区别
SFT相当于一个纯behaviour cloning,给定在下游任务上的一个optimal text 轨迹的分布,我们直接让LLM来学习这个分布,那么当SFT数据的optimal text轨迹并没有cover 原始任务的时候,这样的优化方式必然会导致严重的遗忘问题,这点毫不意外。
打个比方,好比我们学会了骑自行车,现在我们给定了很多开汽车的数据,我们的优化目标是拟合开汽车的数据,那么当然会导致在骑自行车上的能力的退化,因为我们的目标并不包含要保持会骑自行车的能力。
那RL的优化方式区别是什么呢?
RL的优化,相当于让模型自己慢慢探索出来如何从原始任务学会解决下游任务。最关键的一点是RL的优化想要稳定,得要求模型优化的时候的变化要足够小。我们回想一下,为什么PPO加上一个advantage clip效果就会好很多?
RL的本质就是一个sampling based 的优化过程,我们有一个分布,采样得到的轨迹有的reward大,有的reward小,那么我们就增大采reward大的轨迹的概率,减小采reward小的轨迹的概率。这个过程中我们希望模型更新要足够稳健,不能过于激进。
打个比方,比如投资股票,如果看到某只股票突然猛涨或者猛跌就立马追涨杀跌,那么这样的策略大概率是很难稳定的获利的。所以PPO比之前的RL算法效果好的一个最本质的原因就是clip掉了那些有很大reward涨落的轨迹,让模型的优化更加稳定。
所以从这个角度看,RL这个算法天然地就会限制LLM模型后训练之后和之前的差别(更像是分布的锐化,而非参数空间的巨大改变),所以遗忘现象没有普通的sft严重也是很合理的事情了。所以哪怕不推理任何数学公式,我们也可以定性地预测出实验的结论。