作者:RuYy
https://zhuanlan.zhihu.com/p/1966633724058793147
最近一年都关注着Diffusion领域,与大红大紫的DiT-based视觉生成模型的不同,扩散语言模型(Diffusion Language Models,DLMs)颇有隐而不发之意,虽反响不甚热烈,又偶有令人惊艳的工作出现。对研究者而言,这是一片蓝海,押宝于这个方向不失为一种优良选择。
扩散模型作为视觉生成领域绝对的统治者,其在文本生成中的能力也不禁引人遐想——一种与自回归完全不同的训推范式,具备全局视野的鲁棒性优势以及与视觉生成无缝集成的能力,有没有机会超过自回归模型(Auto-Regressive Models,ARMs)呢?
于是乎,我忙里偷闲进行了一些调研,在此分享(绝对不是组会的任务,顺便发上来)
阅读本文,你将会结合顶会论文了解到:
- 1.从训推范式理解扩散机制
- 2.扩散模型为什么适合视觉生成
- 3.扩散模型如何推广到文本?其优劣势如何?
- 4.总结对比ARM和DLM,以及前景
前言:扩散的训推范式
当我们在讨论扩散时,我们在讨论什么?
广义的扩散模型(Diffusion Models)代表了一种通过神经网络学习和预测数据分布的范式,而不仅仅局限于特定的算法实现(如DDPM等)。这种范式的核心在于其独特的"拆楼"(训练)和"建楼"(推理)过程。
训练:从有序到混沌。
- 输入:有意义的、符合特定分布的内容(如清晰的图像、有语义的文本)
- 过程:通过多个加噪步骤,逐步向数据中添加噪声。模型在这个训练过程中学习条件下的数据分布变化和加噪规律。
- 输出:加噪直至变成完全的噪声分布
推理过程则是从混沌到有序的逆向过程。输入为完全的随机噪声,在条件指导下,通过相同的步数逐步预测并去除噪声,直至输出有意义的、符合目标分布的内容。
这种扩散的训推范式具备以下独特之处:
- 迭代性:通过多步骤的渐进式变化实现数据转换
- 可控性:每个步骤都可以接受条件指导
- 灵活性:可以根据具体任务调整步数和噪声添加/去除策略
从而为AI生成领域提供了一个全新的思路,使得模型可以通过学习数据分布的渐变过程来实现高质量的生成结果,不论是视觉还是文本。
背景:视觉生成中的扩散模型
为什么扩散模型在视觉生成领域表现得这么好?
扩散模型在视觉生成领域的卓越表现并非偶然。视觉数据的本质特征与扩散模型的工作机制高度契合。图像和视频中的像素本质上是连续变量,可以自然地映射到连续空间中(如将RGB的0~255映射到[-1,1]区间)。这种连续性使得扩散过程中的逐步去噪变得异常自然,每一步的变化都可以被视为一次平滑的图像转换,从模糊逐渐过渡到清晰。
然而,扩散模型在处理长序列视频生成时也面临着显著挑战。主要体现在两个方面:首先是全注意力机制(Full Attention)带来的高计算开销,其次是视觉模态本身和逐步去噪算法中存在的数据冗余问题。
业界和学术界已经提出了多种优化方案来应对这些挑战。观察发现,视觉生成的计算激活往往表现出固定的模式,而时间步(Timestep)之间的特征也具有相似性。基于这些特点,研究人员提出了多种解决方案:
- 采用Step Distillation压缩步数
- 通过Feature Cache机制复用特征(TeaCache,CVPR 2025)
- 引入稀疏注意力(如SparseVideoGen, ICML 2025)
- 量化注意力(如SageAttention, ICLR 2025)

这些优化方案从算法、权重和激活等多个层面入手提升计算效率,本质上都是处理扩散算法中平滑变化和视觉模态本身局部性导致的冗余。
跨界:语言模型-突破离散数据的藩篱
扩散范式的跨界表演。
扩散模型在迈向语言生成领域时,首先遇到了一个根本性的挑战:文本数据的离散特性。与图像中连续的像素值不同,文本是由离散的token序列构成的。这种本质差异使得传统的扩散过程难以直接应用——我们无法像处理图像那样,对文本进行"平滑"的噪声添加或去除。
举个例子进一步说明图像和文本的区别:图像中,假设0代表白色,1代表黑色,那么0和1中的任何一个小数都可以代表某种灰度值,是有实际意义的。但文本中,0代表小猫,1代表小狗,但1.5是没有任何实际意义的——我们没有办法给一只小猫做“加噪”操作。
如何适配文本的离散性与扩散的连续性之间的矛盾,学界一直在做探索,下面给一张DLM综述中的统计图:
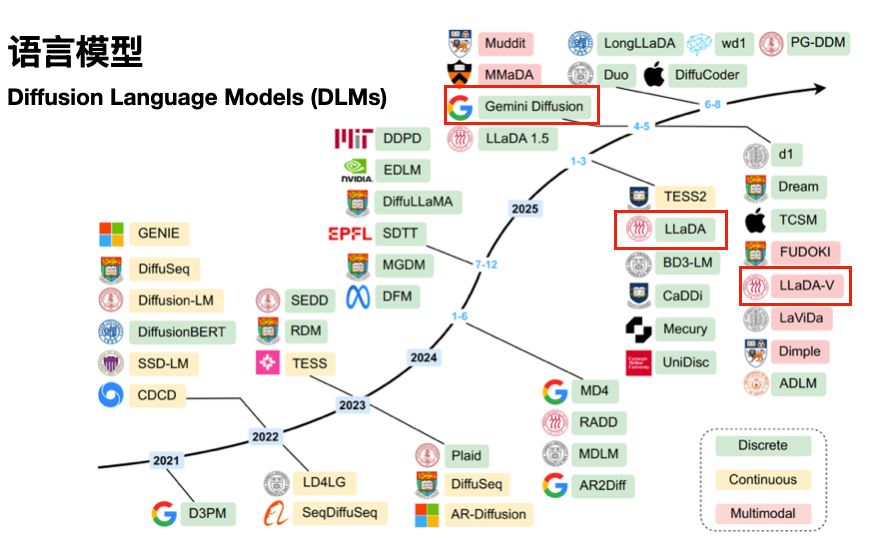
可以看见从Diffusion诞生起(2021年),学界就开始了语言diffusion的探索,此前一直是尝试将文本连续化,让模态适应算法,直到2024年,让算法离散化才逐渐登上舞台。到了2025年,学界的LLaDA、业界的Gemini Diffusion才逐渐进入我们的视野。
接下来我们介绍一些有趣的论文。
起源:LLaDA-扩散模型的语言突破
人大的工作。LLaDA提出了一种创新的解决方案,成功将扩散思想推广到语言生成领域。其核心创新在于重新设计了加噪和去噪过程,它通过掩码(masking)机制解决了文本数据离散性的问题。在训练阶段,模型将完整文本序列通过随机掩码逐步转化为噪声;在推理阶段,则从完全掩码序列出发,逐步恢复原始文本。掩码率从0到1的线性变化,实现了平滑的转换过程。这种设计使得离散文本数据能够自然地融入扩散模型框架。
在架构设计上,LLaDA采用双向注意力机制替代了传统的因果注意力,实现了所有掩码位置的并行预测。通过精心设计的交叉熵损失函数,模型能够高效地学习文本生成任务。
从这里我们可以初步看见DLM的一些独特优势:没有ARM的反向诅咒、时序漂移等固有问题;并行推理具备更快的生成速度;基于掩码机制的灵活的错误修正能力。
在此基础上,人大继续推进DLM相关的研究,继续发布了LLaDA 1.5、LLaDA-V等模型,可谓是国内DLM研究的前沿高地。
探索:DLM擅长的场景-数据受限
https://github.com/JinjieNi/dlms-are-super-data-learners?tab=readme-ov-file
NUS的工作。提出了一个关键问题:在数据受限而非计算受限的场景下,哪种建模范式能够从有限的数据中提取更多价值?
通过大量对照实验,研究发现了一个显著的"智能交叉"现象:当独特数据量有限时,扩散语言模型(DLMs)在性能上持续超越相同规模的自回归模型(AR)。具体而言,DLMs表现出超过3倍的数据效率 - 在相同的总token预算下,用0.5B独特token训练的DLM能够达到用约1.5B独特token训练的AR模型的性能水平。
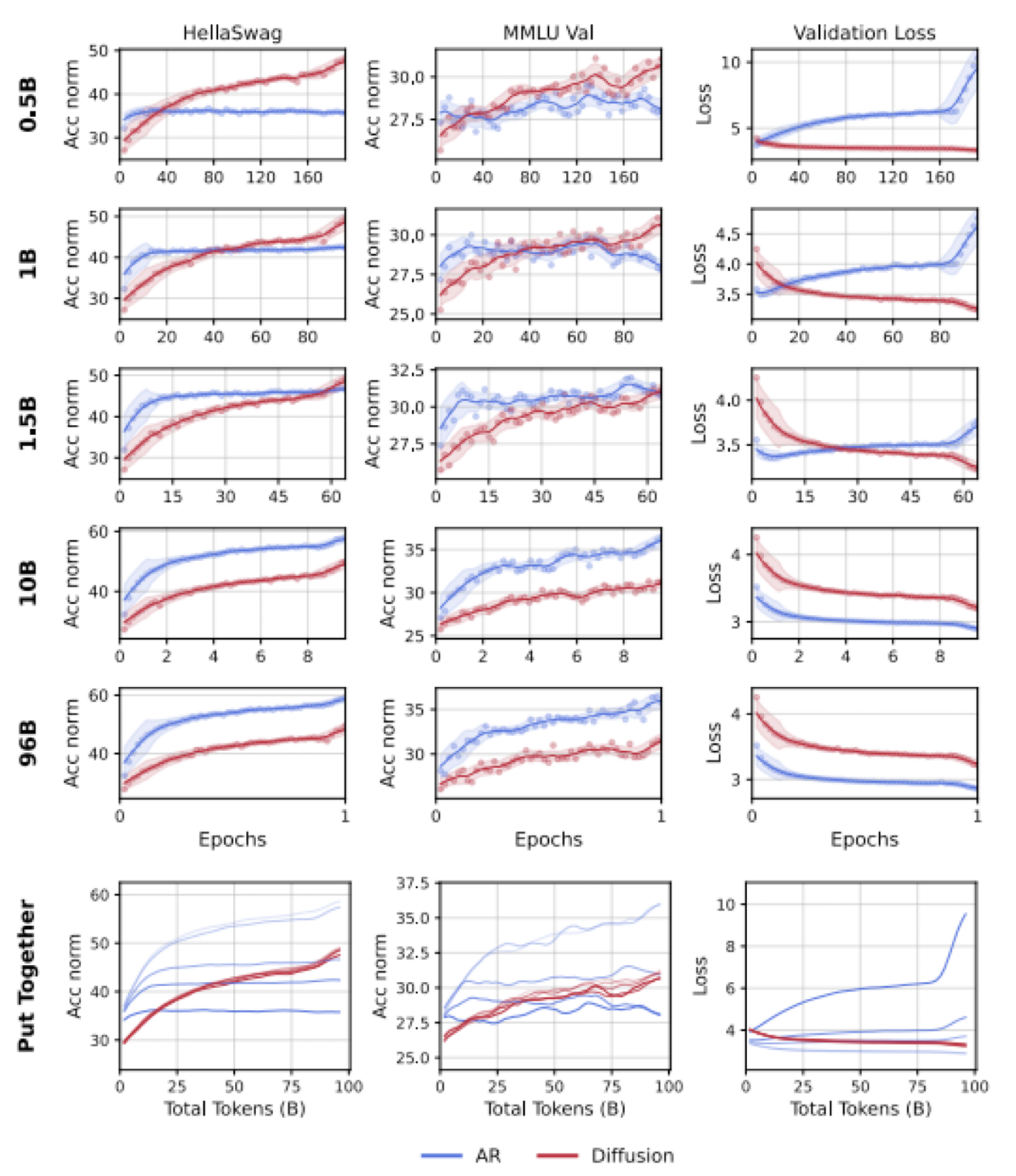
究其原因,DLM的优势来自于:
1.全知视角:Full attention的机制摆脱因果关系约束,能够更全面地捕捉文本中的依赖关系。
2.计算密度高:同一个数据,Full attention的计算密度显然更高。
3.自然数据增强:扩散过程每一次加掩码都自然地实现了数据增强。
但是,为什么在数据变多以后,ARM能够后来居上呢?论文从两方面回答此问题:
1.资源限制。全向注意力需要消耗更多的计算资源,成为了DLM的瓶颈。
2.算法上限。自然语言本身具有很强的因果性(most text data are generated by humans, and humans are RNNs):AR模型的从左到右建模方式天然符合人类语言生成的特点,在数据充足时,这种归纳偏置(inductive bias)反而成为优势,DLM的任意顺序建模能力在这种情况下优势不明显。
这篇文章从算法的角度,通过大量实验说明DLM和ARM在文本理解生成任务中有各自擅长的区间,但是,从扩展性和上限来看,ARM是优于DLM的。本文局限在于,毕竟是学术界文章,训练规模太小,因此该论断的适用范围仅限3B左右的小模型。
进阶:如何扩展DLM-学界尝试
Scaling Up Masked Diffusion Models on Text,ICLR25,人大的工作。
这篇文章首次给出了DLM的scaling law。
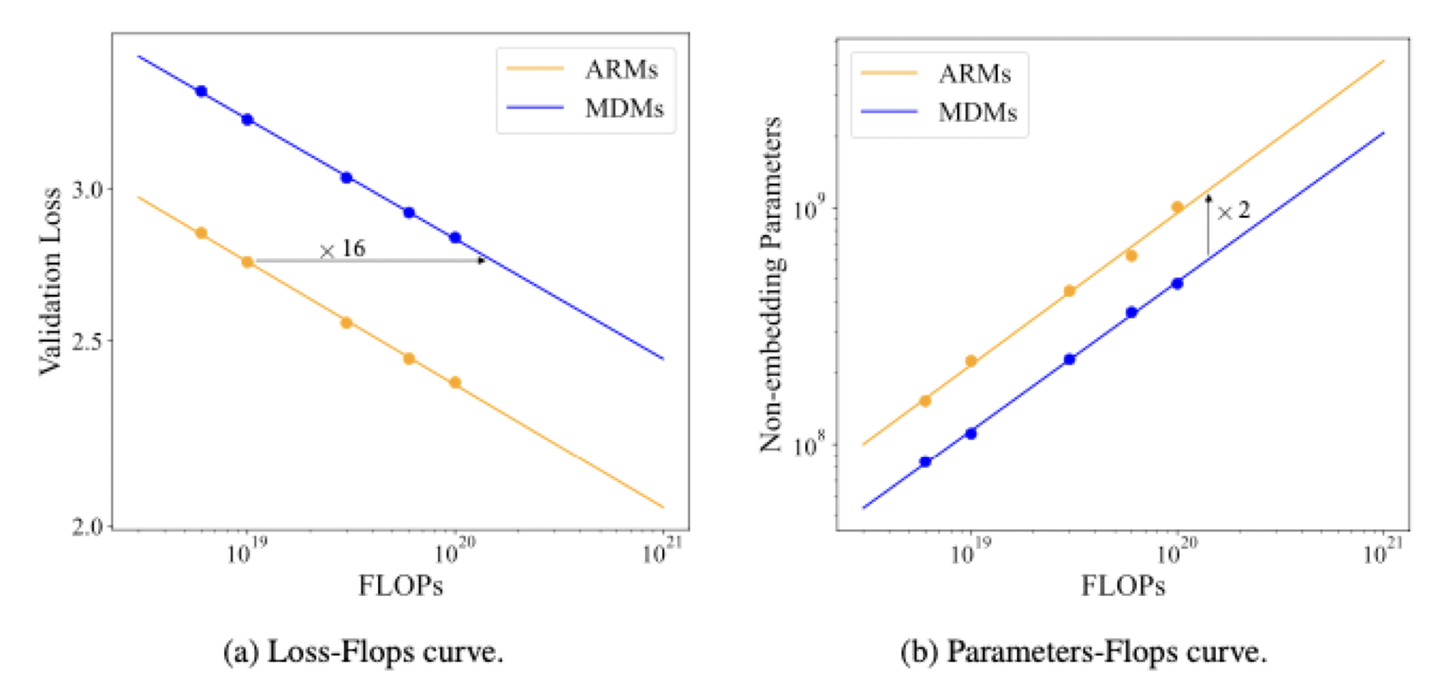
从精度角度看,1.1B的DLM可以达到Llama2-7B的效果。这与之前nus的文章结论是一致的,在小模型情况下,得益于全向注意力机制,DLM具备更高的信息密度。
但福兮祸之相依,全向注意力同样成为了瓶颈。
从性能角度看,训练效率比ARM慢了16倍。训练作为prefill主导过程,ARM只需要一次因果注意力,DLM却需要对同一个样本进行50次加噪和全向注意力。
但是,DLM的推理效率是ARM的两倍。推理是decode过程,DLM是多步并行的decode(计算密集),ARM是多步逐token decode(访存密集)。因此此处的两倍速度,是得益于并行解码的吞吐量优势盖过了多步去噪和全向注意力的计算量劣势。这种速度优势能否在长序列和缺乏KV Cache的情况下延续?不得而知。
里程碑:如何扩展DLM-业界尝试
Training DLMs at Scale using Autoregressive Models,初创公司Radical Numerics 在今年10月的工作,开源了目前最大,性能最好的DLM模型RND1 。
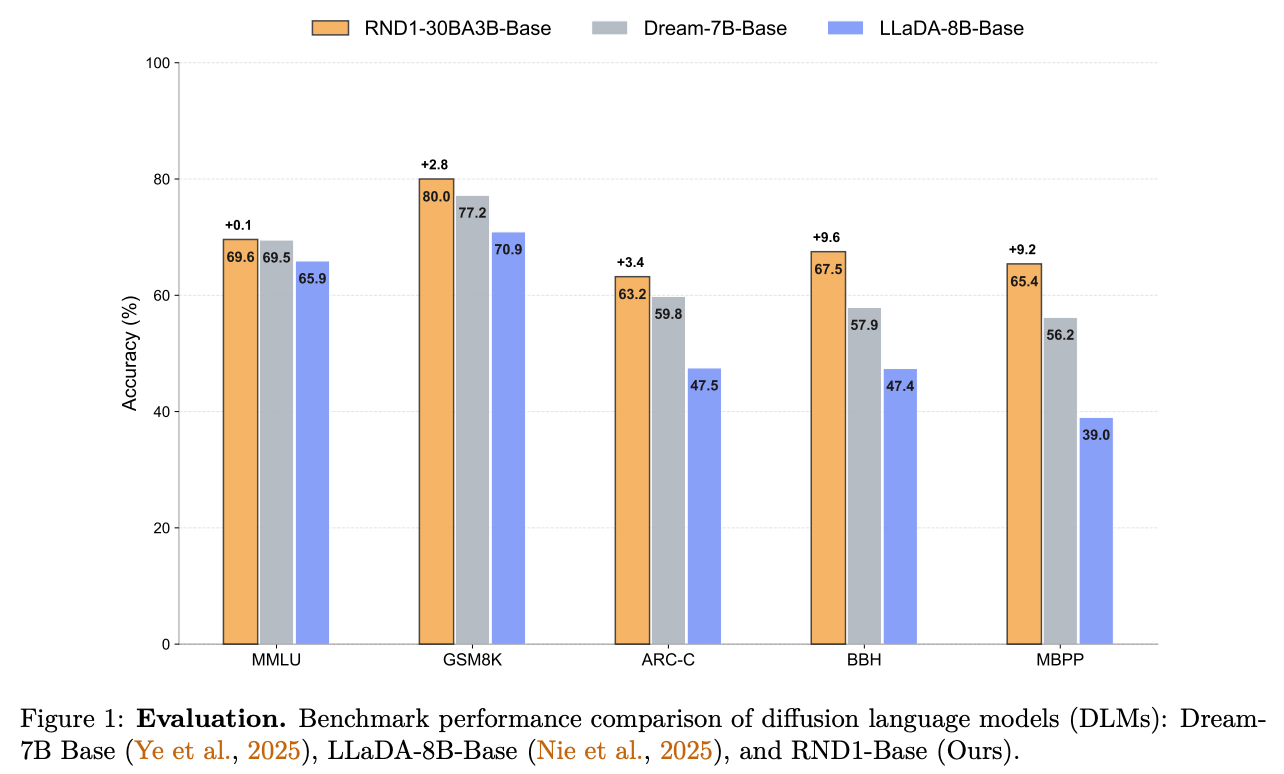
一句话总结他们所做的事情:用500B训练数据在Qwen3-30B-A3B上续训,让它从AR转变为DLM,主要难点在于让注意力从因果变为双向,保持了原有80%-90%的性能。
你可能感到好笑:折腾一通还掉点了。
我会这么阐述这篇工作的价值:证明了DLM是可以在MoE架构下扩展到30B的,虽然性能还不如ARM,但是说明了这条路是能走通的,而且开源,可谓是无私的先行者。
从推理性能看,得益于并行解码,RND1比同规模KV Cache AR快1.4到2倍。
而且RND1在Qwen基础上,还支持vLLM和SGLang等推理引擎,对算法和系统研究者都是非常宝贵的workload。
反思:对DLM的批评-擦边Diffusion
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling,ICLR25,THU和Nvidia的工作。
如果你是视觉生成Diffusion的算法研究者,看到这里你应该早已产生了疑问,那就是所谓的Diffusion language model其实没有diffusion的影子,从原教旨主义来说,至少应该与ddpm,ddim、flow matching之类的连续采样算法沾点边,但是现在的离散扩散模型,只是加mask,更像是将Transformer的预测能力均匀地分摊到了所有的token上,其他与ARM并无区别。
这篇文章在实验上验证了这个猜测,实验结果彻底地抨击了现在的DLM模式:Mask Language Model 的思想在2018年BERT已经被提出,而套上Diffusion的马甲对精度并无提升,只对文章热度和关注度有提升。
他们说:
MDM本质上训练目标与掩码模型等价,区别仅在于基于似然的损失权重略有不同。在损失函数中引入额外的时间变量,在实践中几乎没有益处。
2. MDM的采样过程计算量大且效率低下,存在一个理论上等价的替代方案,让速度提升20倍,并且反映了掩码模型的随机顺序、逐个标记的解码过程,但是性能仍不如ARM。
- 先前工作的 MDM 在文本生成方面优于 ARM 的现象,并非源于真正的算法优势,而是源于数值问题导致采样过程中生成困惑度指标下降,从而降低了有效温度。
从算法上,更简单的掩码模型不仅足够,而且不存在上述效率低下和数值不稳定的问题。
从系统性能上,与 ARM 相比,MDM 在文本上的扩展面临着根本性的推理效率挑战,因为掩码模型中的双向注意力机制与不兼容,而KV Cache是加速LLM)的关键技术,这些模型需要较长的上下文长度。这一点在大多数现有的扩散语言模型研究中都被忽略或有意淡化了。
基于这些发现,文章认为DLM缺乏取代ARM的明确且令人信服的前景,人们应该重新考虑对 MDM 的投入。
总结:竞争or融合?
ARM vs DLM
事物的发展总是螺旋上升的,文章总是希望尽可能加强自己的观点,说好的没那么好,说坏的也没那么坏。在我看来,DLM作为一种利用transformer能力的不同于auto regressive训推范式,其潜力与上限还需要更多更好更solid的工作来证明,现在盖棺定论为时过早。
这里给出一个基于目前研究,两种范式对比的表格,从中可以看到一些有待探索的方向:
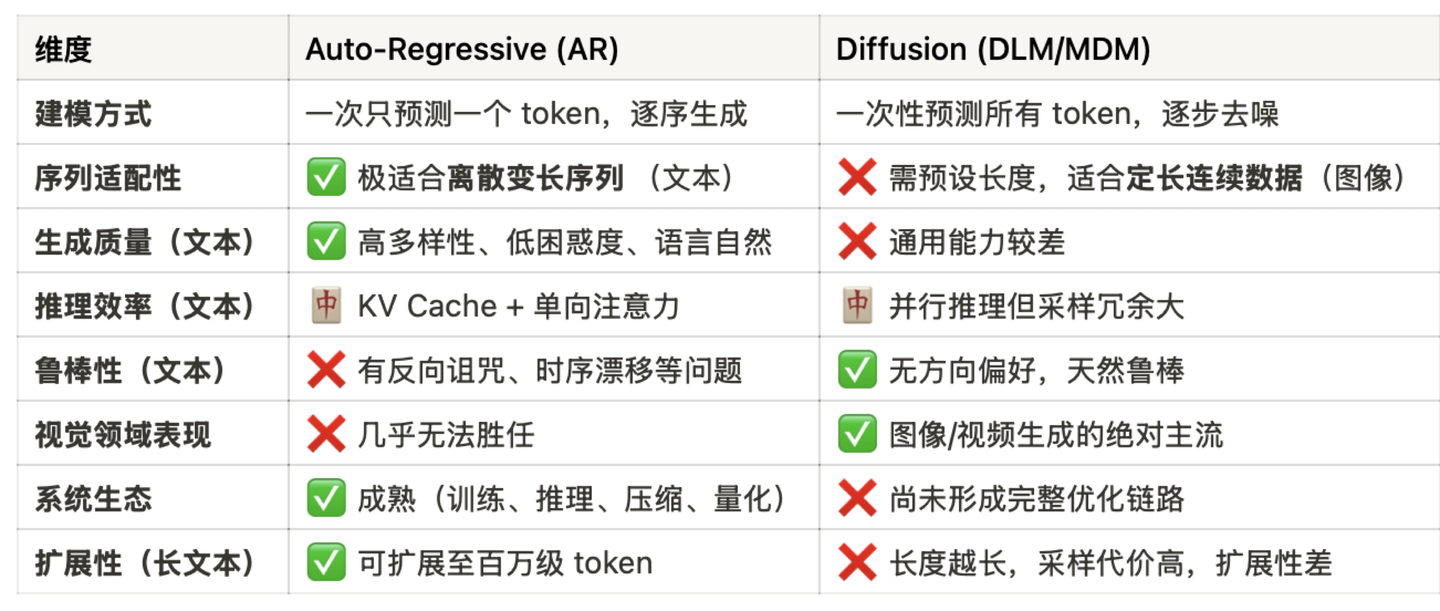
多模态:求同存异
有一点可以确定,真正的AGI一定是多模态的。
我们无法确定DLM在文本生成上是否优于ARM,但也许可以确定在视觉生成上Diffusion碾压ARM。这就决定了Diffusion的范式在短时间内不会退出舞台。
也许相比于谁战胜/取代谁,二者如何融合才是一个更加promising的问题。这里我举一些架构融合的例子:
- 理解-生成统一的多模态模型(Gemini)
- 具身智能VLA:AR理解输入,Diffusion生成动作序列 (pi0)
- 音视频生成:字幕/音频/视频联合生成
- 流式生成:自回归+扩散的视频生成(MAGI-1,SANA-Video)