作者:九老师
https://zhuanlan.zhihu.com/p/1976336943878005134
最近陆续有了一些研究LLM中RL相比SFT更不容易造成灾难性遗忘的工作,清晰地指出是RL的On-Policy特性带来了参数的稳定,而SFT将模型参数推向与预训练分布差异很大的方向,导致了遗忘问题(如图,遗忘问题的衡量就是随着新任务的学习,旧任务的平均表现下降)。
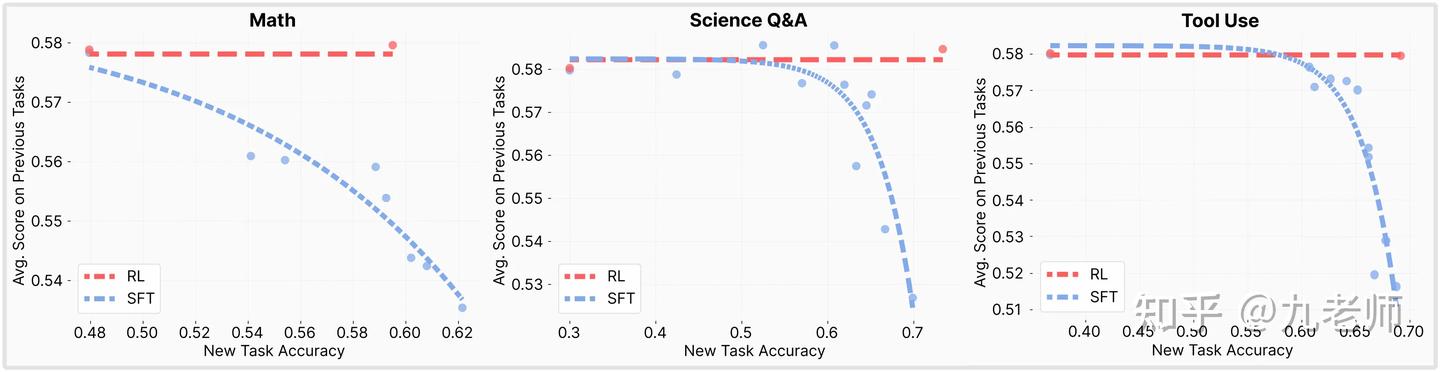
这一清晰地结论,点亮了我对很多事情的理解,推荐系统原来孤立的问题也有可能连成一片,有了更深层次的支撑。
本文包括:
- LLM领域,RL比SFT更不容易造成灾难性遗忘的工作解读
- 严格来讲,PPO是个near-on-policy算法
- 推荐系统是标准的off-policy 监督学习,(猜想)许多缺陷也应当由此而生
RL比SFT更不容易造成灾难性遗忘
“SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training”指出了,在复杂文本规则和视觉变体任务中,采用RL进行微调使模型对未知变体表现出卓越的泛化能力,而纯SFT模型往往记忆训练集,导致在分布外场景下性能不佳,但是文章没有深入核心原理。
“Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training ” 展示了,在多任务持续微调场景下,传统SFT会导致先前任务能力的严重退化(灾难性遗忘),而采用强化学习微调(RFT)可以显著保留并提升模型的已学知识。RL对已学任务几乎零遗忘,某些一般能力甚至优于微调前,与同时多任务训练的上限相当 。
进一步分析发现,这种稳定性主要归功于RFT的内隐正则化作用,而非仅仅靠KL惩罚或CoT。所谓内隐正则化是指:在 RFT 中,由于奖励是随机的、有方差,更新目标不是一个确定的 label,而是一个“概率性的优劣反馈”。总体感觉分析还不够彻底,但也指出这是RL本身的性质,与优化技巧无关。
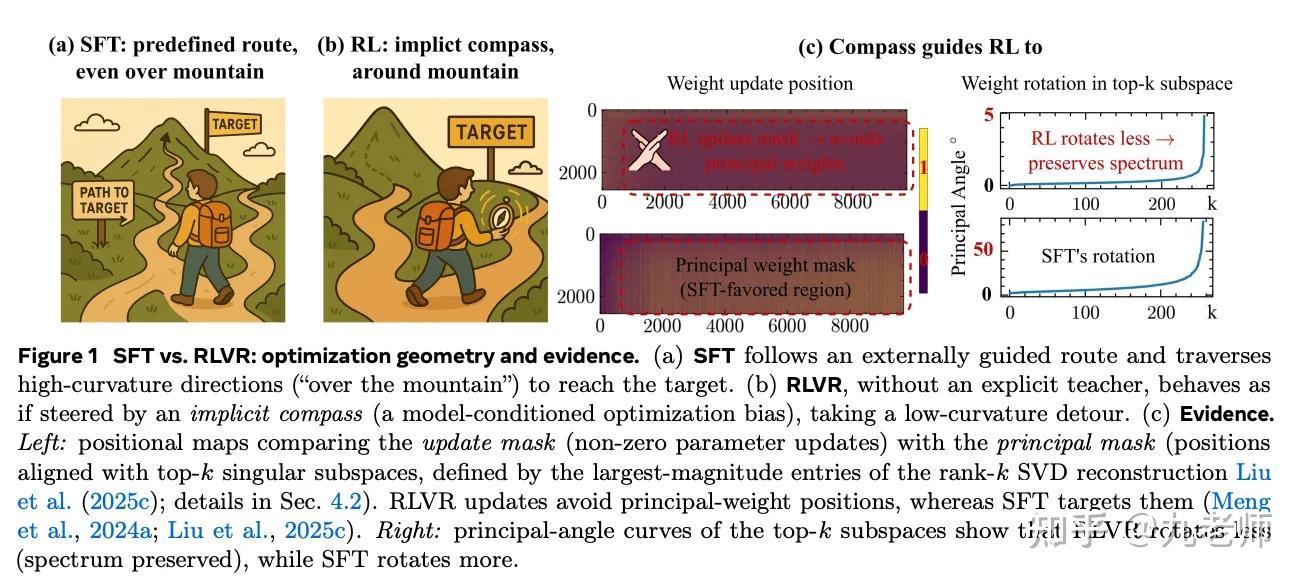
“The Path Not Taken: RLVR Provably Learns Off the Principals” 宣称bf16下,RLVR(Reinforce Leaning with verifiable rewards)显示约 36%-92% 参数没有改变,而 SFT 只有约 1%-19%。RL看似只“调动”了少量参数,却能显著提升模型能力。它认为机制是,RL在权重空间中避开主方向(principal directions)进行优化,也就是“off-principal”学习。SFT 更新主权重、造成谱结构扭曲、子空间大幅旋转,造成了灾难性遗忘。
RL能做到的原因包括:KL约束;低曲率空间更新;因数值精度低效梯度被“隐藏“。整体感觉是更加深入了现象,而并未讲清楚了核心的机制和决定性的差异点。但是给出来的比喻很形象(如图),RL会选择走“平坦”的“低曲率”路径。
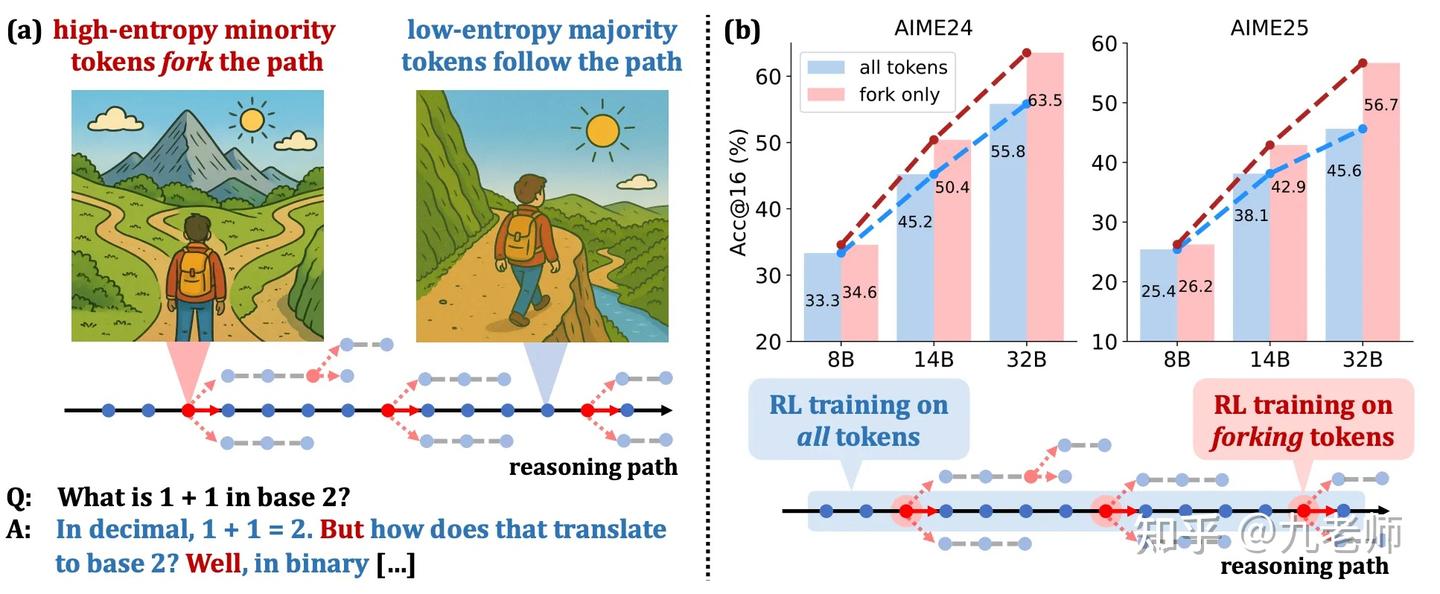
“Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning” 有几乎类似的发现,在 RLVR 训练推理模型时,真正起关键作用的,只是少数“高熵 token”(大约 20%),而大多数“低熵 token”(大约 80%)几乎不动。
低熵可以理解成模型对下一个 token 很确定(概率非常偏向某个词),高熵就是模型在这里很犹豫,分布比较平(多个选项都有可能),这些位置恰好是 推理分叉点(forking tokens),换个 token 就会走完全不同的解题思路或证明路径。也通过实验证明了,20% token ≈ 100% 的 RL 收益,只训练其他80%无效且有负向效果。
“RETAINING BY DOING: THE ROLE OF ON-POLICY DATA IN MITIGATING FORGETTING”和“RL’S RAZOR: WHY ONLINE REINFORCEMENT LEARNING FORGETS LESS” 这两篇把“为什么 RL 不容易遗忘”这个问题,直接挖到了最核心、最本质的层面:关键不是 KL惩罚、不是奖励形式、不是优势函数、不是熵、不是小步更新,而是On-policy(On-policy是指产生样本的策略和要更新的策略是同一个)。
“Retaining by Doing”先在数学上证明了,SFT就是最小化forward KL,倾向于覆盖多模式(Model-cover),RL就是最小化Reverse KL(KL不对称),倾向于追着当前模式移动(model-seeking)。然后再一个“多模态”的高斯混合模型上做验证,真正导致 RL 不忘的不是 KL正则,也不是优势函数,而是 on-policy 数据。进一步验证,不一定必须 RL,只要让 SFT 更 on-policy 即可减少遗忘。
“RL’s Razor”认为,SFT 使用外部标注,强制模型朝标注分布移动,可能离 π₀ 很远;RL(on-policy) 用的是模型当前自己生成的数据,因此更新只会“在模型本来就比较可能的输出附近调整”,自然就保持模型与 π₀ 更接近(小 KL)。这个现象称之为RL’s Razor:在所有能解决任务的策略中,RL 会优先选择 KL 最小的那个。
他们从信息几何角度证明:对二值奖励的 RL,policy gradient 可以看成在最优策略集合上的 KL 最小投影。因此 RL 本质上在做 “尽可能不改变原模型的最优更新”。和“Retaining by Doing”类似,它构造了一个“oracle” SFT 标签,使其在保证正确性的前提下 KL 最小。结果这种 SFT 比 RL 还要忘得更少。
所以 RL 更像在做 constrained optimization:在保持 KL 最小的前提下寻求 reward 最大。
综合看,SFT 在做“跨分布替换”:两个分布差异大的时候,梯度会非常大,更新会覆盖旧知识,高干扰(high interference),导致遗忘严重。(On-policy)RL 在做“自洽分布的微调”:数据与模型当前分布一致,更新方向是“自洽的”,不推开旧能力,干扰最小,自然保护旧任务能力。 这比我们之前讲的“低曲率”和“高熵”更本质,不是因为“曲率低和高熵“所以更新在那里,因为更新来自 policy 本身(on-policy),所以自然落在“不会伤害自身结构的方向”,更为第一性。
小结:为什么 RL 不容易遗忘?
- 因为 RL 是 On-policy ,更新方向天然与自身分布一致
- 因为优化的是 Reverse KL / 近似 model-seeking
- 因为更新主要集中在 高熵分叉点(而不是主方向)
- 因为 RL updates 避开 principal directions,结构稳定
做一个比喻,一个语言大师(LLM after Pre-Train)去学数学,一种方式是让他背数学解题过程(SFT),一种方式是让他调用语言形成思维(CoT)用奖励驱动它调整语言思维(RLVR)。
先不论数学学得如何,RL因为持续输出(练习)基础语言来描述数学,而这些基础语言能力并不影响数学的结果,所以在训练数学的过程中也不会干扰到它的基础语言能力。但通过背数学解题过程,惩罚的不是没有做对题目,而是没有像数学工作者一样表达,他说的每一句话每一个字都在被纠正,时间长了他甚至忘掉了该怎么正常的说话(灾难性遗忘)。
PPO是个near-on-policy算法
我一直以来的疑惑也因此豁然开朗了
- 疑惑1:我之前做强化学习任务的时候发现,特定任务(生成式强化学习重排)上PPO的表现和REINFORCE with baseline水平相当,GRPO without KL 惩罚的效果好了一大截,并且那个KL正则应该作用不大。
- 疑惑2:最早听说RLHF做法的时候,PPO算法中维护了一个reference model(冻结的基础参数),并对策略更新加入KL散度惩罚,防止新策略偏离原模型分布过远。这是避免Reward hacking而丧失基本能力。这似乎有一些矛盾,似乎和上面讲的(On-policy)RL不会有灾难性遗忘有些矛盾了。
很多的博客都讲过,PPO是一个On-Policy算法,但是它不是100%的绝对On-Policy,而是介于Off-policy之间的near-on-policy。严格的On-Policy是指更新当前策略的数据就是当前策略采样产生的,但凡重用一点,就不是严格的On-Policy。
PPO之所以被认为是On-Policy,是它replay-buffer里面的数据距离当前策略也就是几个或几十个steps,常见的RL库里的PPO超参数都有一个epoch选项,为了提升 sample efficiency,它会对同一批 trajectories 做多次梯度更新。所以当数据使用超出第一个epoch,剩下的数据按照严格口径就是off-policy了。而GRPO及原始的REINFORCE算法,才是100%的严格On-Policy。
PPO正式因为在提高样本利用效率的同时,又使得强化学习效果不降低而出名(好且更快)。PPO或者TRPO实际解决的问题,无论是clip还是trust region都是在想提高样本利用效率变成near-on-policy的同时,使得RL依旧成立。严格on-policy就能做到策略KL变化可控,near-on-policy之后变得更新不可控了,那引入clip或者是trust region来控制KL起到一样的效果。
“InstructGPT”的原始论文中设定了PPO epoch为1(Single Inner Epoch),是因为 LLM 的 RLHF 训练非常不稳定——包括KL 散度爆炸 (KL Divergence)和灾难性遗忘问题。但是开源社区的版本里默认设置了4,这反而更遵循了PPO原始3-10的设定。
“Open-Reasoner-Zero”复现时发现,KL正则不仅没有作用,反而会限制探索,会降低训练效率。它使用了100%的on-policy设置——每轮 rollout 只更新 actor 一次,没有多 epoch updates。
在推荐任务上,它实际要生成的序列很短,所以rollout的成本不高,这种情况下PPO的成本反而更高。但是推荐这个任务实际上非常地吃On-Policy更新,Value-base的优势函数还有估计偏差,就造成了PPO效果一般的结果。严格遵循了On-Policy后,KL正则的必要性就不高了,完全符合上面的理论。
换个角度理解推荐系统缺陷
那么,如果我们接受”SFT 相当于 Off-policy 学习,会遗忘“ 的观点,我们能否重新理解推荐系统的长期表现?以下更多来自于思考和猜想,主要是激发思考与探讨。
推荐系统本质上是一种永续增量的 Online Learning 模式。在实际生产环境里,训练方式通常是“日级批处理”或”流式处理“,并且一般采用了监督学习。
从这个角度看:
- 用上一整年的数据重新训练模型(架构大升级时),类比于大语言模型的 Pre-Train;
- 之后每天、每小时或流式的增量训练,类比于大模型的 SFT(Supervised Fine-Tuning)。
推荐系统会不会有类似 LLM 的“遗忘问题”?
推荐本身并不是基于Base Model去学一个新的任务,它的任务、场景是一贯的,那遗忘的定义模型逐渐失去对某些旧用户/旧模式的拟合能力。
做一个思想实验:在某天之后,把一批特定用户的样本全部从训练数据中移除;随时间推移,观察模型对这批用户的 AUC(当然要排除掉兴趣迁移的影响), 如果AUC曲线逐渐下滑, 说明模型正在“遗忘”这些老模式。
这个视角与 LLM 的 catastrophic forgetting 在概念上是统一的,只是推荐系统由于任务恒定、数据分布自然漂移,过去我们不这么称呼它。
为什么推荐系统似乎没有明显“忘得很严重”?
我想off-policy SFT的问题也会影响推荐系统,只是传统推荐模型的特殊架构设计恰好规避了这一点。
对 LLM 来说,知识主要存储在影响共享表征的大量 Dense 参数里,例如 Qwen2-7B 中,FFN 参数占约 75%。任何一次 SFT 都可能覆盖这些主方向。
而传统推荐模型非常不同,Dense部分只有几M或几十M,而Embedding部分却有100B~1T(千亿、万亿参数)。
所以即便SFT训练导致了遗忘,它模式覆盖的可能只有反向激活了部分参数,推荐的巨大 Sparse 部分在一定程度上隔离了任务/用户间干扰,而不会像 LLM 一样波及整个知识结构。
但随着推荐系统向 Dense Scaling(更深网络、更大 Transformer、Embedding 更压缩) 方向演化,这种“自然隔离”会逐步消失。推荐系统可能在未来逐渐暴露出更类似 LLM 的遗忘问题,这对大规模推荐模型的 Scaling Up 可能是一种隐性阻碍。
换个角度理解负迁移?
推荐系统的多任务、多场景学习,会出现一个负迁移问题——多个任务和场景合并数据反而没有独立学习效果更好。传统的解释包括梯度冲突,如梯度夹角理论;有基于MoE的优化,多个Expert依靠gate来隔离相互影响的梯度。
但从 LLM 训练的角度来看,可以提出一个新的解释:是不是可以认为任务2在SFT学习过程中,导致了任务1过去学习pattern的遗忘呢?也许并不是梯度冲突,而是多个任务彼此像是在做 Off-Policy SFT,都在尝试覆盖共享的 principal 参数(高曲率方向),而不是在低曲率方向中添加能力(model-seeking)。
和兴趣遗忘问题类似,我们想过可能是模型结构不好,可能是训练正则不好,但是没有想过可能问题出在了标准的监督学习上。并不是因为梯度“方向冲突”,而是由于Off-policy SFT 的本质是 model-covering(覆盖模型行为分布)。
SFT的feedback loop问题。
除此之外,SFT本身还有feedback loop问题,即模型下一轮学习的数据是上一轮策略构建的(想想这就是Off-policy的定义啊!)。它的本质:模型在用“旧策略”生成数据,但用来训练“新策略”,导致分布越来越往坏或平方向偏移,形成自我加剧的退化循环或停滞不前的天花板。
RL实际上可以突破这个问题,因为他的问题定义更加完整,RL的探索本身就是突破现有pattern的考量。而现在的监督学习控制了数据循环的推荐系统中,要靠大量的人工规则来保障体验,提拉pattern的上限。
所以半开玩笑的讲,今天推荐系统算法工程师有一半人在做 supervised learning ,有一半人在处理 supervised learning 的副作用——体验问题、兴趣探索、用户/物品冷启动。一边在用 supervised learning 学一个”当前策略的局部最优“,一边在用人工规则、策略回退、探索机制去堵住 feedback loop 带来的坑。