作者:金伟阳,HKU博士生
TLDR
SRUM是一个非常直接的后训练方法,其动机在于:当前生成理解统一模型(UMMs)的理解端性能优于生成端,在对偶问题中生成做不好的事情理解端可以轻松解决。
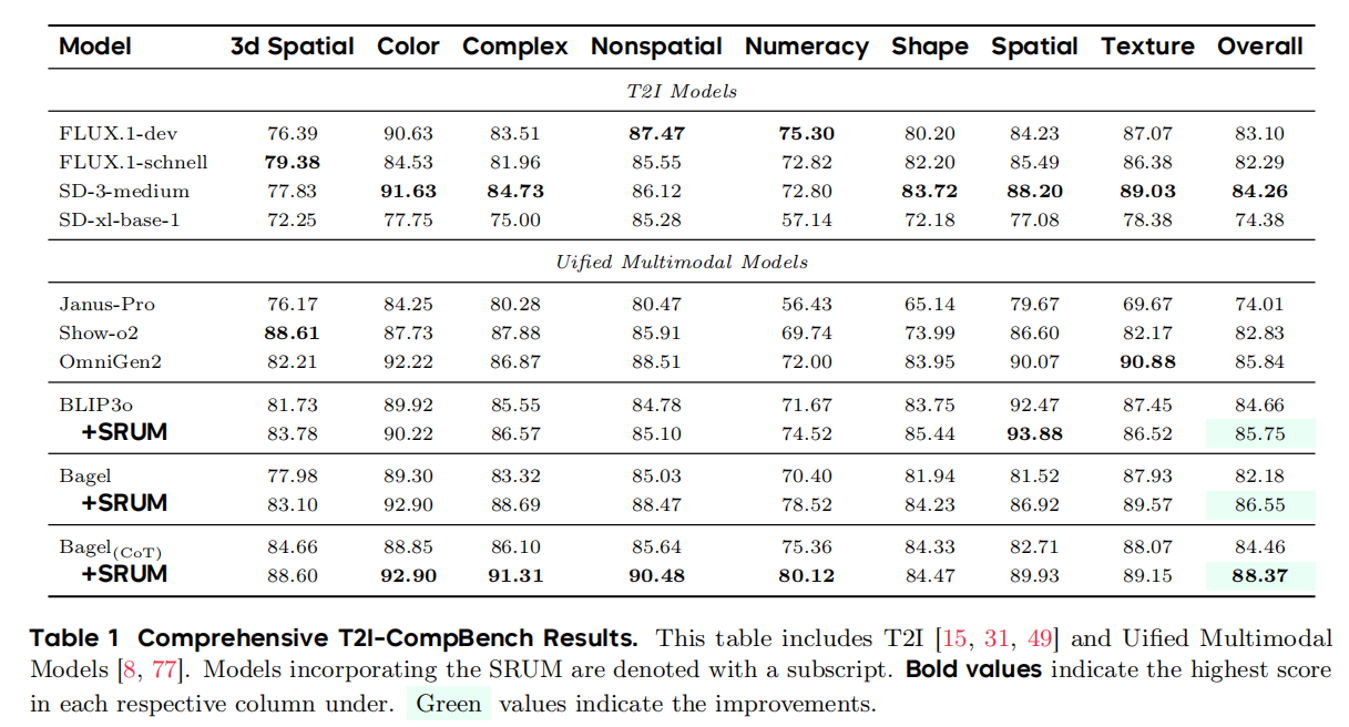
由此,SRUM通过一些指令设计,能让理解端能够直接为生成端提供密集的奖励信号。实验上,仅使用约6k条提示和极少的训练时间,就能在T2I-CompBench上提升4–6个点,并在Geneval,WISE,T2I-Reasonbench上表现出优秀的泛化性能。
背景
在通往通用人工智能(AGI)的漫长探索中,一个核心议题始终萦绕不去:模型能否在内在循环中实现自我迭代与进化? 随着大规模预训练语言模型的兴起,这一愿景的实践进入了新阶段。从自我奖励语言模型的开山之作,到后续“LLM-as-judge”的机制探索,研究者们在纯文本领域取得了鼓舞人心的进展。
然而,当我们将类似的自我进化体系移植到多模态大模型时,却遭遇了天然的瓶颈。多模态模型不仅需要文本,更依赖大量高质量图像数据来驱动进化,而此类图像资源的获取与标注成本极高,成为制约其发展的关键障碍。这使得多模态模型的自我进化之路一度陷入困境。
幸运的是,研究社区展现出了无穷的创造力。从早期变色龙、Transfusion、LlamaFusion的架构探索,到MetaMorph的初步尝试,再到Bagel系列的逐步成熟,一条新的路径逐渐清晰。
最终,统一多模态模型进入了研究者的视野:它集理解与生成双重能力于一身,能够同时处理图像与文本的输入与输出。这一根本性突破,使得多模态模型得以在内部闭环中自足地创造与评判数据,曾经横亘在自我进化道路上的核心难题,终于迎刃而解。
探索
而另一方面,显存的UMMs都存在一个显著性问题,理解>生成,针对一类对偶任务,模型理解做得很好但是生成出现了问题。于是,天然的,我们希望理解能够guides生成,我们希望能够打造框架的循环。
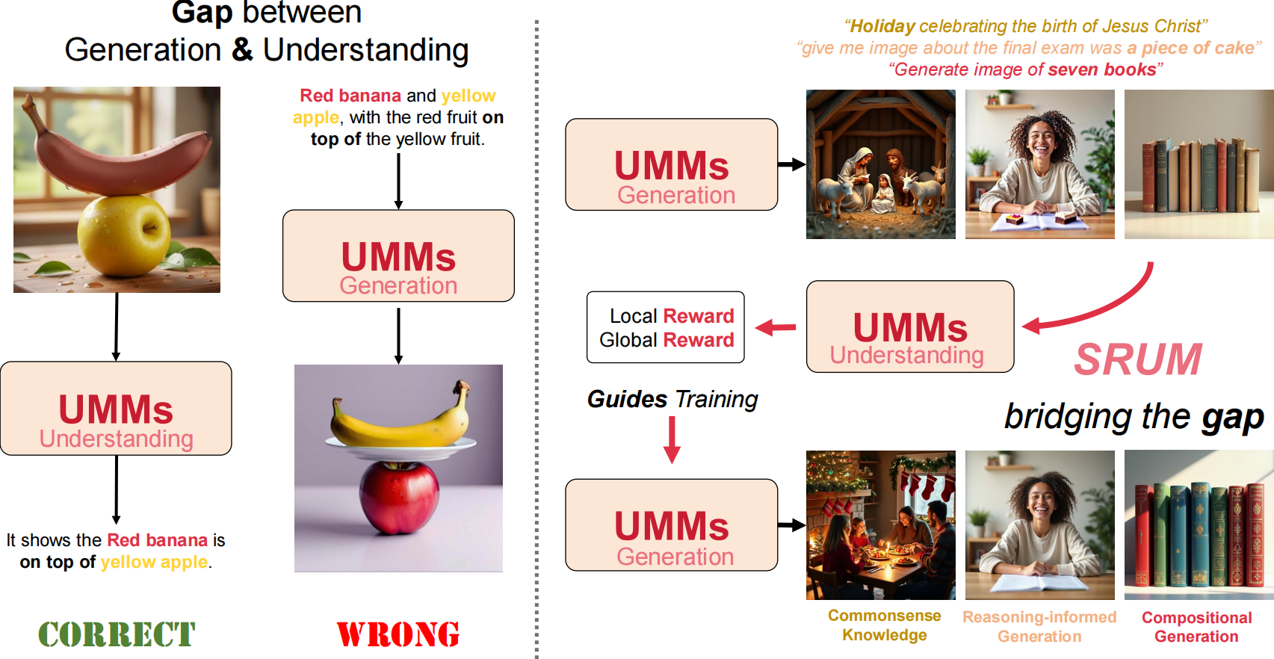
SRUM从这个视角考虑,并且进行了更加细粒度的rewarding process,我们会针对当前图像和prompt区域以及全局的吻合程度让理解部分进行打分并且转化为训练过程当中的rewards。
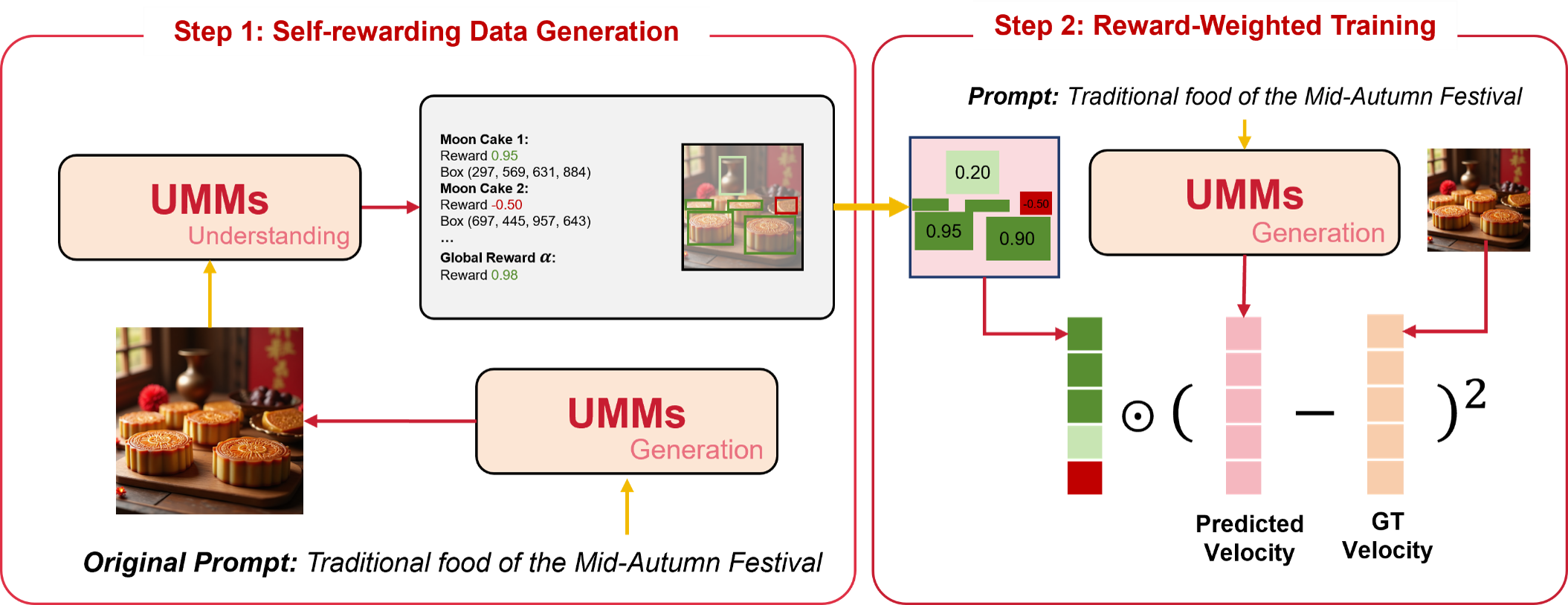
首先,我们会进行相关数据的自我生成,根据一组分布的prompt让模型自己产生图像候选,然后在理解端进行细粒度的rewarding。
最后,我们把reward转化为dense的reward map从而顺利加入到训练当中,我们在训练时候会加入约束的损失项来防止reward hacking,这点是学习过去类似DPO的奖励方法。最终我们在general的benchmark上达到了很好的生成效果。
分析
而为了分析SRUM本身的性质和work的原因,首先我们进行了消融实验,我们采取了在推理过程中的模块消融和针对超参数的设计。
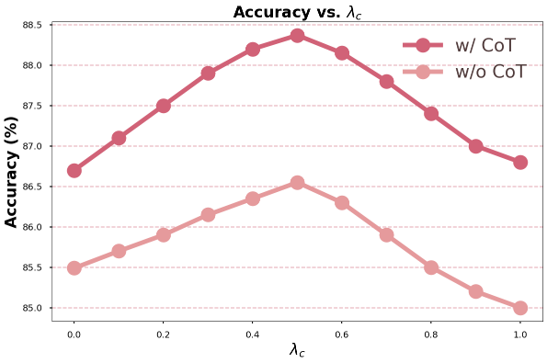
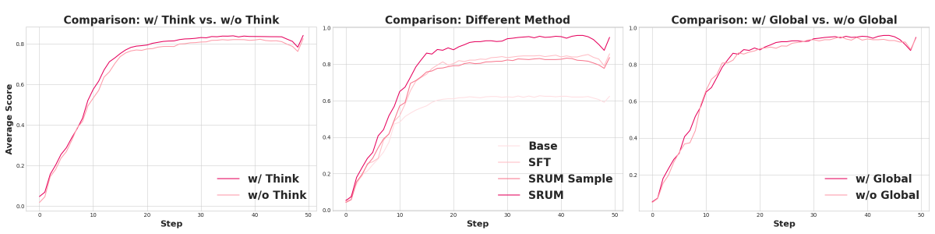
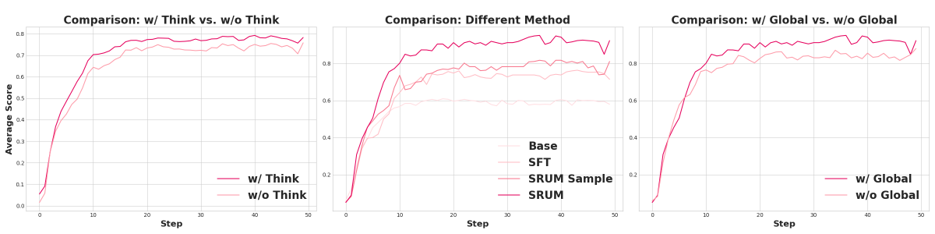
我们会发现在Bagel的实验当中,think模式的开启对layout的效果作用很有效但是对于细节部分表现一般。同时我们设计的global reward对于layout的作用是毋庸置疑的。
另一方面,我们考虑了sample level的奖励形式对比,可以发现这种模式很难处理细节上的生成。
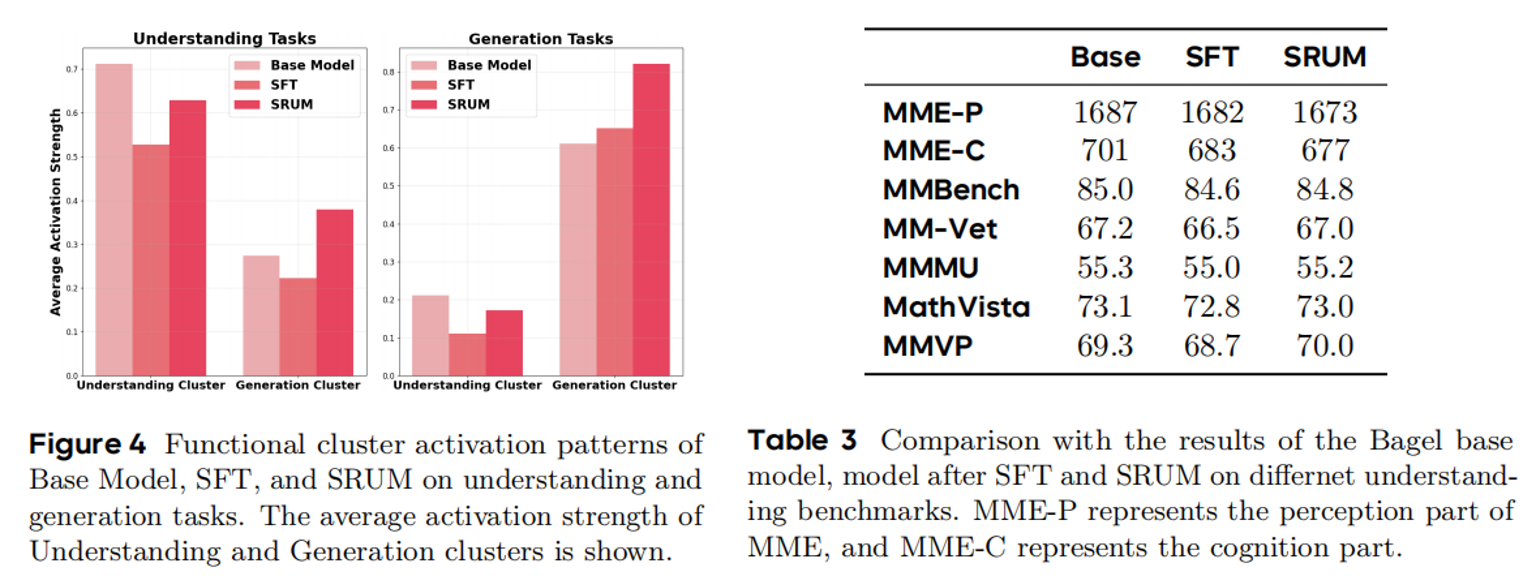
而在理解模块相关的实验中可以发现,我们的方法相比SFT,对于理解部分的损害十分微小,并且在MMVP甚至略有增长,这充分说明SRUM是无痛的将理解引导生成,完成了自我促进。
而且有意思的是,在观察不同参数聚类的激活情况结果,我们可以发现SRUM能够同时促进理解和生成簇在不同任务的激活,使得模型能力出现了一种潜在的协同,这是一个非常积极的信号(我会在最后结合谈这一点)。
最后我们探索了模型在知识领域生成的泛化性,也发现了不错的结果。我们设计了模型在WISE上使用其中一类prompt进行训练,发现SRUM可以使得另外两类的结果出现促进,这是十分有意义的。
思考
在大量实验和试错过程中,我们也得出了一些符合直觉的见解:
理解与生成是否相互冲突?
在UMMs中,这种现象确实存在。我们观察到,一旦使用某一类任务(例如生成或理解)对模型主干进行监督微调,另一项能力往往会迅速衰退。提升一种能力,常常以另一种能力的衰减为代价。
尽管目前UMMs的训练效果尚难言理想,但从我们进行的激活实验来看,若能选择适配的训练策略,模型的理解与生成能力之间仍可能浮现出潜在的协同效应。这为后续探索UMMs的训练范式提供了可行的指导方向。
后训练方法是“版本答案”吗?
当前像RECA这样的工作也聚焦于后训练阶段。但我们认为,这类训练范式或许应尝试前移,将其视为SFT阶段的一部分并作出适当适配,这样可能更具实践意义。
在我们看来,UMMs的模块均衡问题始终围绕两条主线展开:架构设计与训练范式。我们所做的尝试,正是希望借助模型的原生能力,在训练范式这条路径上引入一些革新性的思路。
为何要坚持推进UMMs?
这是一个常谈常新的话题。本质上,我们希望实现从理解到生成的知识迁移,这也是我们此前构建WISE Benchmark的初衷。
目前来看,理解端的能力尚未充分赋能于生成端,因此像SRUM这类方法,目前仅能视为过渡方案,期待未来能进一步优化。
为何要推动模型自我进化,72B规模的外部模型打分不够可靠吗?
这一点其实颇具争议,背后涉及我们对“智能”本质的理解。正如过去元学习所探讨的那样,我们不仅希望模型能够学习,更希望它们能学会自我学习——在初期接受人类监督之后,逐步实现自主提升,而非永远停留在“无法成长的婴儿”阶段。
此外,当UMMs步入新阶段,其理解能力远超现有开源模型时,SRUM是否将成为推动能力跃迁的关键答案?这也值得持续思考。
总体而言,我们仍可得出阶段性结论:利用理解端提供密集奖励是正确方向,区域级奖励也具有可行性(该思路同样适用于T2I模型)。而对学界而言,后训练因其隔离性与轻量化特性,仍是研究UMMs的理想起点。
我们期待后续有更多研究者与我们一起,将SRUM扩展至更大规模,探索其潜在性质。欢迎交流与合作,共同推进这一方向的深入发展。
Arxiv:https://arxiv.org/abs/2510.12784
代码(辛苦大家帮忙Star一下):
https://github.com/WayneJin0918/SRUM
Hugging Face Paper(辛苦大家帮忙upvote一下):
https://huggingface.co/papers/2510.12784