提到具身智能就绕不开的经典工作,自动驾驶的VLA虽然在本体确定的情况下(汽车四轮形式),也看起来只有EMMA比较合理的方案,那么来看下本体还不确定收敛的具身行业。我认为目前核心关注的应该是机械臂的操作技术突破。 (以产生和物理世界的交互,末端执行器更多使用两指夹爪、机械臂数量上的也可以任意拓展,从单臂的精细操作进阶到多机械臂协同工作,从固定机位进阶到可移动机械臂形态)。
那么接下来学习并深度解析一下具身智能的经典VLA方案。也就是Pi-0(后面还有pi0.5/pi0-fast)。这都是Physical Intelligence的经典工作。这类的方案具有多任务的泛化性与实时推理能力,也被称之为“Generalist Policy”(通才策略)
这里是一个团队的工作量,建议大家看之前对diffusion policy/flow matching有一些概念再开始
随着深入了解发现单靠VLA这种方法还是不够的(复杂任务成功率未到可用状态)。
PI-0
先来看看他们颇具浪漫主义气息的INTRODUCTION
A human being should be able to change a diaper, plan an invasion, butcher a hog, conn a ship, design a building, write a sonnet, balance accounts, build a wall, set a bone, comfort the dying, take orders, give orders, cooperate, act alone, solve equations, analyze a new problem, pitch manure, program a computer, cook a tasty meal, fight efficiently, die gallantly. Specialization is for insects.
——Robert A. Heinlein, Time Enough for Love
上面是美国科幻作家罗伯特·海因莱因(Robert A. Heinlein)的著作《时间足够你爱》(Time Enough for Love),是其笔下角色Lazarus Long 的一句名言。它的核心含义是:过度追求单一领域的专业化会限制人类的潜能,而真正的智慧在于全面发展。
paper:https://arxiv.org/abs/2410.24164
blog:https://www.physicalintelligence.company/blog/pi0
Motivation
人类可以在开放物理环境中的完成各种任务,且智能地适应环境限制、语言命令和意外扰动。
但MLLM这种模型放到物理环境交互怎么做呢?同时还要解决机器人的多任务多场景泛化性和灵活执行任务
对高度多样化的机器人数据进行预训练,然后对所需的任务进行微调或提示会更有效。这可以解决数据稀缺性挑战,通才模型(generalist model)可以使用更多的数据源——包括来自其他任务、其他机器人甚至非机器人来源的数据(人类动作视频)——并且它可能会解决鲁棒性和泛化挑战,因为多样化的数据表现出更大的观察和动作覆盖范围,提供各种场景、校正、 恢复行为。
重点考虑三个部分:
- 必须在非常大规模数据上进行,因为大规模预训练的效果在较小规模上并不存在(涌现问题)。
- 需要正确的模型架构,这种架构可以有效地利用不同的数据源,同时能够表示与复杂的物理场景交互所需的行为
- 需要正确的训练策略(可能是最重要的因素),通常 NLP 和CV的大模型在pre-training 和 post-training都需要比较合适的训练策略。(比如InstructGPT中的一些训练策略、用强化学习等)
针对这三个瓶颈的办法,本文提出了一个原型模型和学习框架,即Pi0
Pi0具体是什么?
先说答案:
利用在互联网数据训练的VLM+action expert 组成一个VLA模型,这里结合开源+内部的机器人数据训练得到异构本体foundation model,然后可以在不同的本体/特定的任务上post-training,以完成多任务的泛化或某种复杂任务的灵巧操作。
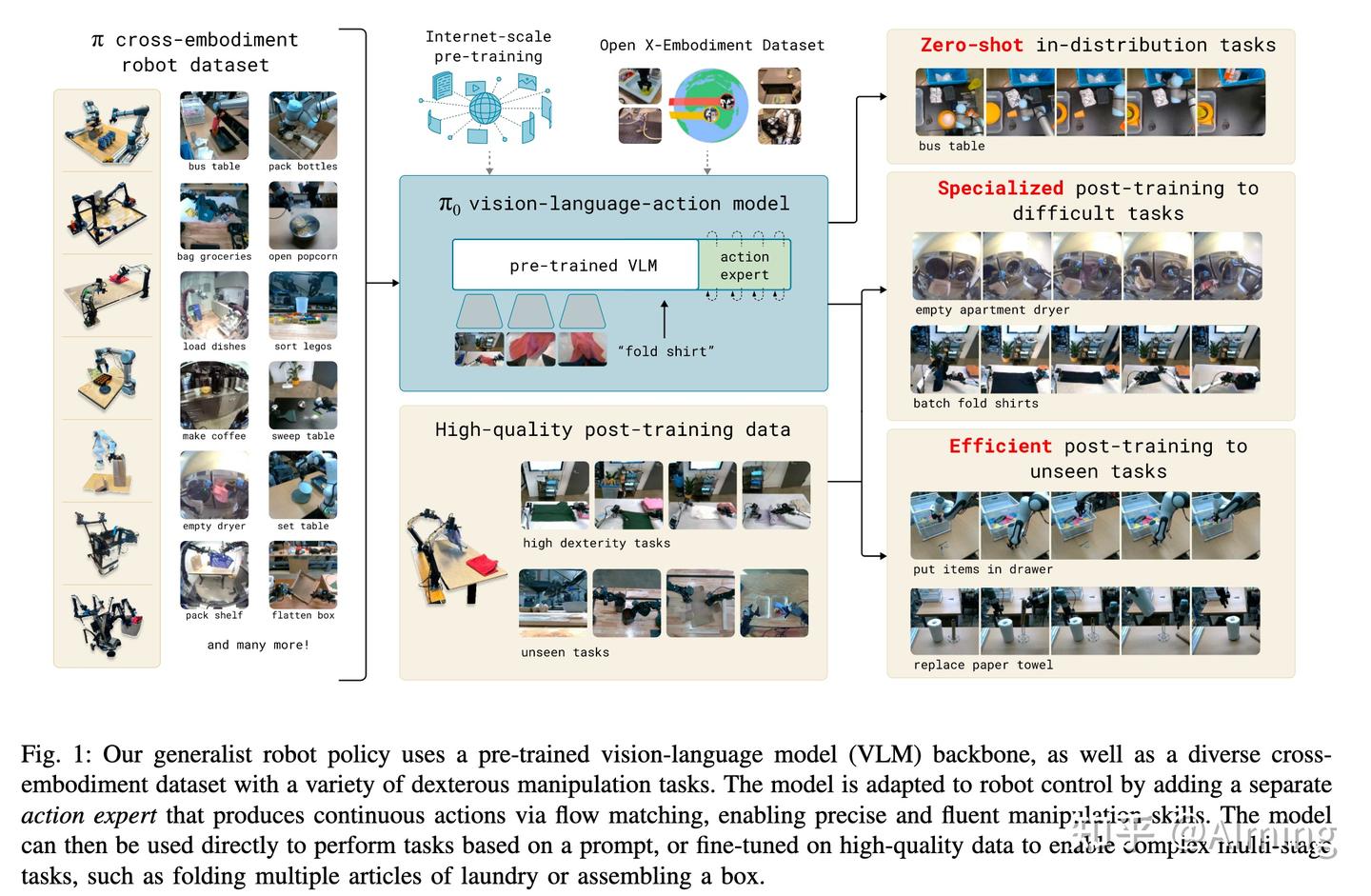
先解释几个概念:
训练阶段:pi0模型训练需要走(Pre-training ->post-training(FT))的训练。
Pre-training:这里有面向于具身智能的专用数据集,如open x-embodiment dataset和 pi cross-embodiment robot datasets,使用这些数据进行训练,已经包含了大量场景的机器人操作数据(论文把这一步也叫pre-training,其实也没问题),这个阶段后会得到一个foundation model,也就是一个可以统一所有任务/本体的基础模型,这样的模型具备初步的泛化性,但不一定专门用于在任何一项操作任务上实现高性能。
Post-training(fine-tuning):根据上一个阶段的foundation model,进行ft, 这里分为两类任务的post-traing数据,以提高模型在某种任务表现的专门数据,包含unseen tasks(未见任务)、high dexterity task (高灵巧任务),包括20 多项任务
VLM:视觉语言大模型,这里用的PaliGemma,这里主要是指代在使用大量互联网文本图像数据上去预训练VLM
PaliGemma: 2024 年 Google I/O 活动上发布(今年2025I/O刚举办大家感兴趣也可以去看看),它是一种基于两个模型的组合多模态模型:视觉模型 SigLIP 和大型语言模型 Gemma,这意味着该模型是 Transformer 解码器和 Vision Transformer 图像编码器的组合。它将图像和文本作为输入,并生成文本作为输出,支持多种语言。
Action Expert:接受VLM输出,专门输出action的网络,这里使用的flow matching,是VLA中 action的重要组成部分。
Open X-Embodiment dataset :是一个由 DeepMind 创建并开源的超大规模机器人数据集,汇集了来自 22 种不同机器人类型的数据. RT-2也这个数据集上训练的,简称OXE dataset
Pi cross-embodiment robot datasets:pi0公司自己采集的本体数据集,一共7 种不同机器人配置,和 68 个任务的不同数据,长度为1w个小时。cross-embodiment robot 也可以理解为异构本体,不同的机器人类型具有不同的配置空间和动作表示,包括固定基座的单臂和双臂系统,以及移动机械手。自动驾驶中也有类似的事情,不同相机安装角度、型号、个数都算是某种程度的异构。(在具身智能领域有一个专门的词汇即“通用数据”)
接下来看图中内容:
三大类机器人数据:
- 内部异构本体多任务数据集 :Pi cross-embodiment robot datasets
- 开源机器人数据集 Open X-Embodiment dataset3
- 用于特定任务/要想拓展未见任务的post-training机器人数据集
这里采用了异构本体训练方式cross-embodiment training
可以完成的任务类型:
- Zero-shot in-distribution任务: Zero-shot 但是强调了任务的 in-distribution(这里不是场景的in-distribution)。通俗讲就是任务类型是见过的(比如清理桌台),但是具体到某种数据没见过,这样也可以一定程度泛化。在VLA系列04中,也发现其实Zero-shot Out-of-Distribution 都没打过Simple baseline。 肯定Zero-shot in-distribution task会好一些。
- 用特定任务数据微调后的困难任务:这里重点提及的是柔性操作的任务,叠衣服这种(叠衣服很困难,想象一下不同类型/颜色/材质的衣服在以各样的形状散落在场景中如果通用处理这件事)
- 高效FT后的未见任务:这里就是训练阶段阶段没有见过的任务,但是在post-training也可以具备这样的能力
模型
VLA model (VLM+Action expert),输出的action 能够以高达 50 Hz 的频率控制机器人,以执行灵巧的任务,例如衣物折叠。
利用在互联网大模型预训练的视觉语言模型 (VLM) ,通过VLM的常识、语义推理和解决问题的能力,进一步训练模型以整合机器人动作(aciton),将其转化为VLA模型
为了能够执行高度灵巧和复杂的物理任务,使用了action chunking architecture架构 (预测动作序列,核心思想是将动作分块(Chunking)与时间集成(Temporal Ensemble)结合,提升动作执行的平滑性和鲁棒性) 和flow matching(diffusion的一种变体,flow match是噪声等于零的特解,更简单直接,可以看零推导理解Diffusion和Flow Matching)来表示复杂的连续动作分布。
使用Action expert,将flow matching与 VLM 相结合,然后使用流式输出来增强 VLM。
训练策略
百万兆级别的MLLM中常见的就是pre-training/post-training两阶段 ,pi0也发现同样有效,首先在一个非常大和diverse的语料库上进行预训练,然后在更具体、更特别的数据上进行微调(期望的行为模式是灵巧性、效率和稳健性)。
这里会有两个问题:
- 仅根据高质量数据进行训练并不能教会模型如何从错误中恢复,因为纠正错误的数据特别稀少。
- 仅用较低质量的预训练数据进行训练并不能教会模型如何高效、稳健地行动。
为了上述两个问题:所以要让模型尝试尽可能以类似于高质量数据的方式运行,但仍然具有一系列恢复和更正,可以在出现错误的情况下部署这些恢复和更正。
使用语言命令、对下游任务进行微调以及结合输出中间语言命令以执行复杂和时间扩展任务的高级语义策略来评估模型。
使用超过 10,000 小时的自采机器人数据+OXE数据集进行“预训练”(论文里也叫这个为预训练,但是其实VLM互联网的预训练不一样,重点在于这个一阶段训练的模型不是最终想要的,所以称之为预训练阶段),并针对各种灵巧的任务进行微调,包括折叠衣物、清理桌子、将盘子放入微波炉、将鸡蛋堆入纸箱、组装盒子和装袋杂货。
这样的学习框架可以学习长程任务,有的长达数十分钟,用于结合身体灵活性和组合复杂性的行为。例如,我们的洗衣折叠任务需要机器人纵各种可以以任何配置开始的服装物品,并按顺序折叠多个物品。我们的餐桌清理任务需要辨别新奇物体的类别(垃圾或盘子)。
这样的好处是,不同本体的机器人都共用一个foundation model,如果想要不同的本体形态和任务,再在特定的任务上ft就好了
模型概览

如图三所示,首先构建了一个混合训练集由两部分组成
- 内部的灵巧操作数据集的加权组合,该数据集由 68 个不同任务的 7 个不同机器人配置上
- 整个 OXE 数据集 ,其中包含来自 22 个机器人的数据。
然后训练阶段:
- pre-training阶段使用不同的语言标签,结合任务名称和段注释(子轨迹的细粒度标签,通常长度约为 2 秒),然后得到的foundation模型可以遵循语言命令,并以基本熟练程度执行各种任务。
- 对于复杂而灵巧的任务,采用post-training,该程序使用高质量的精选数据使模型适应特定的下游任务。研究了使用少量到中等量数据进行高效的post-training,以及使用较大的数据集进行高质量的post-training,以完成复杂任务,如洗衣折叠和移动操作。
- 使用混合数据将基础的 PaliGemma VLM(初始化模型参数) 转换为 π0,添加使用flow matching的action输出来生成连续的动作分布。(使用 PaliGemma 是因为端侧友好,模型相对较小(对于实时控制很有用),pi0框架与任何VLM 都兼容)
pi0模型细节
参考框架Transfusion
核心还是 transformer 架构,image encoders将机器人的图像embedding到对齐到与语言token相同的embedding空间中。
conditional flow matching 来模拟动作的连续分布。flow matching可实现高精度和多模态建模能力,特别适合高频灵巧的任务。
整体架构参考 Transfusion,它使用多个目标输出(连续图像+离散文本)训练单个transformer,这里pi0输出(连续动作+离散文本)
这里有两种监督token的形式
- 连续动作使用flow matching loss监督
- 离散文本通过cross-entropy loss监督
在 Transfusion 的基础上,发现对机器人特定的(action和state)标记使用一组单独的权重可以提高性能。此设计类似于Moe(mixture of experts,这里可以理解为两个专家的混合,但是这个和大家广为熟知的moe不是一个东西,本质上是是第一个expert输出KV cache,然后action expert不用单独处理图像文本,只接受kv cache然后进行特征交互,最终输出action)
- 第一个expert用于图像和文本输入处理,主要给第二个expert提供图像和文本对应的kv cache
- 第二个expert用于机器人特定的输入和输出,其对应的权重参数(weights)是一个负责动作相关任务的专家模块(action expert)
输入
o_{t} 是观测值,包括多个 RGB 图像、一个语言命令(command)和机器人的本体state(关节角度)组成,那么 ot = [I_{t}^{1}, ...,I_{t}^{n}, l_{t}, q_{t}] ,就是 i 个图像(每个机器人有 2 或 3 个图像,这里一般分为腕部相机和全局相机), l_{t} 是语言token 序列, q_{t} 机器人state,这里是关节角度向量。
对于输入的图像和state先分别通过各自encoder,然后通过linear层对齐到language空间中
action输出
从形式上讲,我们想要对数据分布 p(A_{t}|o_{t}) 进行建模,就是对输入输出建立概率分布模型
其中 A_{t} = [a_{t},a_{t+1}, ..., a_{t+H-1}] ,对应于未来动作的ation chunk(就是连续的动作块,一个块代表当下的动作)(其中 H = 50)
对于动作块 A_{t} 中的每个动作,都对应于一个动作token。
训练阶段
conditional flow matching loss:

t 下标表示机器人时间步, \tau 上标表示flow matching的时间步,其中 \tau ∈ [0, 1]。先前的工作(比如Movie gen)已经证明了,flow matching与简单的Linear-Gaussian概率路径或者Optimal Transport(OT,最优传输)路径相结合时,效果很好。
这里解释下
Linear-Gaussian路径:
线性插值和高斯噪声的叠加使得概率密度流具有闭式解,计算梯度时可直接求导,无需复杂近似,降低训练难度。
OT路径:
最优传输路径从物理视角看是“最省力”的移动方式(类似两点间直线最短),能减少流匹配过程中的路径弯曲,提升生成样本的保真度。
训练稳定性提升:
当流匹配(Flow Matching)使用Linear-Gaussian或OT路径时,模型学习的目标函数(即“flow”)具有明确且平滑的几何结构(走直线),避免了复杂路径可能导致的梯度爆炸或局部最优陷阱。
概率路径公式:
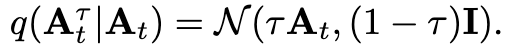
这里定义了一个高斯分布,从原始动作 A_{t} 中采样出带有噪声的动作 A_{t}^{\tau} 。参数 \tau 控制了采样的噪声量
训练步骤如下:
- 随机采样噪声 ε ∼ N (0, I) ,这里每个分量都是独立同分布的,且服从均值为零、方差为1的一维正态分布。
- 进行“noisey action” 生成: A_{t}^{\tau} = \tau A_{t} +(1-\tau)\epsilon ,就是给当前时刻的动作加噪声
- 然后训练网络让输出的flow:v_{θ}(A_{\tau}^{t} , o_{t}) 去匹配去噪向量场 u(A_{t}^{\tau} |A_{t}) = ε − A_{t} . 这个向量场表示从带噪声的动作 A_{t}^{\tau} 恢复出原始动作 A_{t} 的方向。(这就比较好理解为什么叫flow matching了)
模型可以从头开始初始化或从任何 VLM 主干进行微调,本文中使用 PaliGemma 作为VLM。PaliGemma 是一个开源的 30亿参数 VLM,可在大小和性能之间方便地进行trade-off。
action expert添加了 300M 参数(从头开始初始化),意味着总共有 3.3B参数 。
附录b包含超级多细节,值得一看
整体遵循 PaliGemma VLM 设计,但有以下几个要点:
1.机器人特定token的额外输入和输出,包括状态向量 q_{t} 和动作向量 A_{t} 标准的 PaliGemma 架构只接受一系列图像和一个语言提示。这里为机器人本体状态的添加一个输入 qt,使用linear projection成embedding。最后一组输入token对应于噪声动作块 A_{t}^{\tau} ,token数量等于动作范围(这里 H = 50)。只使用对应于 H 噪声动作的 transformer 输出,使用linear将其解码为 v_{θ}(A_{\tau}^{t}, o_{t}) 。
2.添加时间步长的位置编码对于每个噪声动作 a_{t′}^{τ} 转成embedding,然后flow matching的时间步长 \tau 经过正弦位置编码函数,然后concat到一起,送到mlp过一个swish激活函数
3.attention mask:这里用了blockwise causal attention mask ,分为三个块:
- 第一个块包含来自PaliGemma VLM预训练的输入模态(图像+文本)
- 第二个块是机器人状态
- 第三个块是噪声动作
在每个块内部,存在完整的bidirectional attention mask,但不同块之间的token不能相互关注。这种设计旨在最小化因新输入而导致的分布偏移
action expert里使用完整的bidirectional attention mask,是保证所有的时间的action都可以信息传递。
4.Action expert:是一个具有两组权重(也称为专家)的单个transfomer网咯实现的。每个token通过Router(主要作用是决定输入数据(如标记或样本)应该被分配到哪个专家(Expert)进行处理。Router通常是一个学习到的参数化网络,通过训练来优化分配策略,使得每个专家能够处理其擅长的token)送到其中一个专家,这些权重仅通过self-attention层进行交互。
输入处理:图像和语言提示符 [It1,...,Itn,ℓt]被Router到较大的VLM主干网络。在VLM预训练期间未看到的输入 [qt,Atτ] 被Router到Action expert。
PaliGemma基础:PaliGemma基于Gemma 2B语言模型,使用multi-query attention和特定的配置参数(如width2048、depth18、mlp_dim=16384、num_heads=8等)。
专家交互:由于专家仅在self-attention层中进行交互,因此width dim和mlp_dim在不同专家之间不一定需要匹配。这里详细解释下:因为action expert要接受VLM的kv cache(对应的image和text部分)配置文件里action expert的head_dim为256,也就是对应的qkv最后一维度都会view成256;VLM部分的hidden_size: 2048,num_attention_heads: 8,最终输出的kv cache的特征维度也是2048/8=256。所以他们之间可以进行self-attention。
这里要和代码对应着看 width维度和mlp_dim分别对应配置文件中的"hidden_size"和"intermediate_size",这里的vision /text/action expert对应的配置文件均不同,唯一相同的是qkv对应的head dim。所以这里也不是大家之前理解的传统意义上的moe的形式,核心是混合了多个expert的网络负责不同的输出。
推理速度优化:为了加速推理过程(这需要Action expert进行多次前向传递),将Action expert缩小为 {width=1024, mlp_dim=4096},从而使得参数数量约为300M。
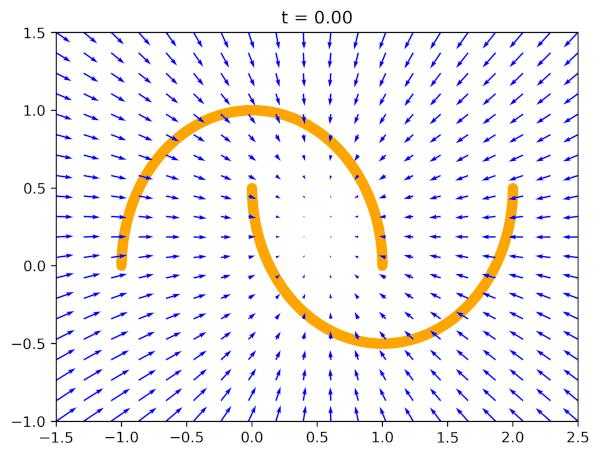
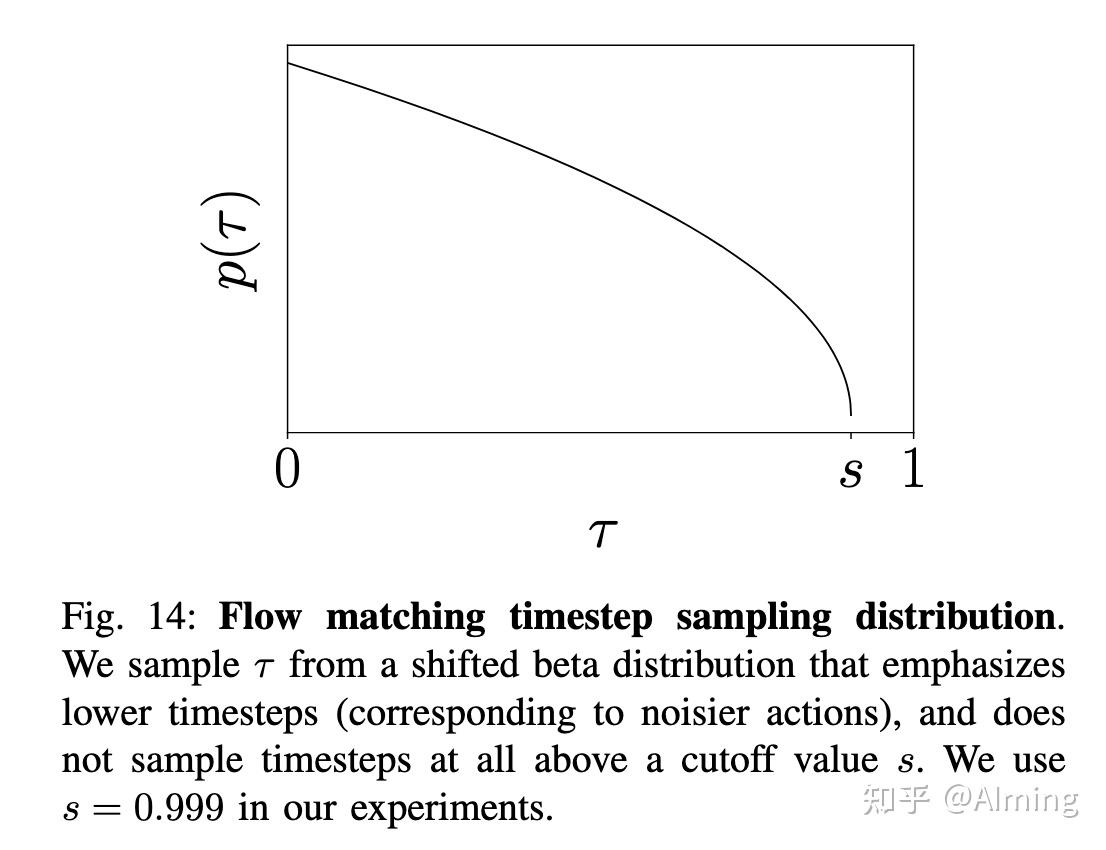
5.flow matching的时间步长采样:原始的方法都是在区间内均匀采样时间步长。Esse等人提出了一种logit-normal分布的采样方法,强调中间时间步的重要性。他们认为在高时间步(低噪声水平)时,模型只需要学习数据的均值。
本文方法:作者们采用了一种偏移的beta分布来采样时间步,强调较低的时间步(对应于较高的噪声水平)。这种方法不采样高于某个阈值s的时间步。实验中使用s=0.999
这里假设动作预测任务与高分辨率图像合成是不同。虽然预测文本标签条件下的平均图像相对容易,但预测机器人当前观测条件下的平均动作要困难得多。这是因为输入的观测非常有用,它应该比文本标签更多地限制可能动作的分布。
设计考虑:设计的采样分布强调了低时间步(高噪声情况),并且不采样超过给定阈值s的时间步,因为这些时间步不需要采样,只要积分步长δ(这里是0.1)大于1−s即可。使用的分布为贝塔分布,如下面图14所示
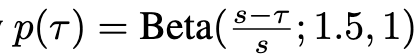
推理阶段
- 输入观测 o_{t} :多V相机,机器人state,文本prompt
- 初始状态:动作从随机噪声开始,即 A_{t}^{0} ∼N(0,I)
- 积分过程:使用前向欧拉积分规则对学习的向量场进行积分,从τ=0τ=0到τ=1τ=1。公式为:

高效推理:通过缓存 o_{t} 的注意力key和values,并在每个积分步只forward 动作 A_{t}^{\tau} 对应的token,可以提高推理效率。( o_{t} 在噪声采样阶段是不变的)
每次我们预测一个新的动作块 A_{t} 时,必须对每张图像进行编码,对 o_{t} 对应的token进行 forward,然后运行 10 步flow matching。
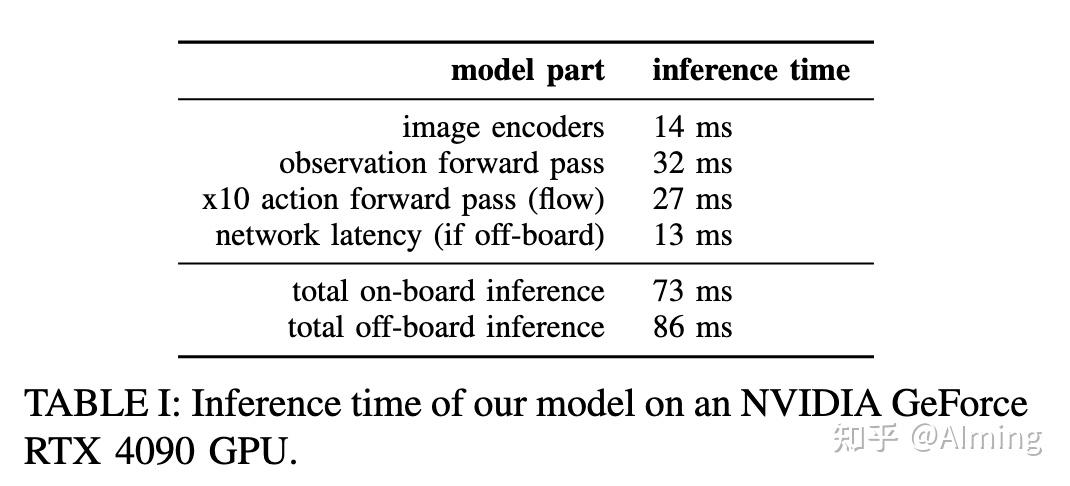
表 I 总结了 3 张相机图像(两个腕部相机+一个全局相机)执行此作的计算时间。在4090 GPU 测速。对于移动机器人,推理是通过 Wi-Fi 连接在云端完成的,这增加了少量的网络延迟(13ms)。进一步的优化、量化和其他改进可能会进一步缩短推理时间。 (不太理解为什么这里非要云端推理,感觉也没有必要,自动驾驶测试车上也用4090,并不非要云端推理)
该模型一次推理生成 50步动作,因此可以在再次运行推理之前执行最多 50 个动作。
这样可以更频繁地运行推理,并使用各种聚合策略组合来自不同推理产生的动作。
这里尝试了temporal ensembling,发现它损害了policy性能,因此选择不聚合 action,而是执行 action chunk 开环。
对于 20Hz UR5e 和 Franka 机器人,每 0.8 秒运行一次推理(执行 16 个动作后),对于所有其他以 50Hz 运行的机器人,我们每 0.5 秒运行一次推理(在执行 25 个动作后)。
这里感觉还有很多优化空间,比如一个token能否代替一段轨迹,而不是一个token代表单个轨迹
非 VLM baseline模型(pi0-small)
本文还训练了一个基线模型,没有使用 VLM 初始化进行ablation,叫 π0-small
仅有 470M 参数,不使用 VLM 初始化,该模型用于评估纳入 预训练VLM 的好处
与主模型有以下不同:
- 使用 DistilBERT 对语言命令的token进行编码;
- action expert 通过 cross attention 观测encoder的输出,类似于传统的encoder-decoder,而主模型是类似Moe混合形式;
- 图像使用较小的预训练 ViT 编码器( R26-S-32 ResNet-ViT hybird)进行编码;
- ViT 图像编码器不共享权重;
- 编码观测值的 transformer 主干(在 ViT 图像编码器之后)未对 Internet 数据进行预训练;
- aciton expert使用 DiT 架构 而不是 Gemma 架构,因此使用 AdaLN-Zero 层合并了flow matching时间步长 τ。
除此之外,这些模型大致相似:都使用预先训练的 ViT 图像编码器,都对观测encoder和action expert使用单独的权重,都采用相同的观测,并且都执行 10 步flow matching来预测动作块。
数据收集和训练策略
光有上述的模型结构是不够的,还需要正确的数据集和正确的训练策略
本文模型采用多阶段训练程序。
预训练阶段的目标是让模型接触各种任务,使其能够获得广泛适用的通用物理能力
后训练阶段的目标是为模型提供熟练和流畅地执行所需下游任务的能力。
因此,对训练前数据集和训练后数据集的要求是不同的:训练前数据集应涵盖尽可能多的任务,并且每个任务中都应涵盖各种行为。相反,训练后数据集应涵盖有利于有效执行任务的行为,这些行为应表现出一致且流畅的策略。
直观地说,多样化(但质量较低)的预训练数据使模型能够从错误中恢复并处理高度不同的情况,这在高质量的训练后数据中可能不会发生,而训练后数据则教会模型很好地执行任务。
预训练数据:
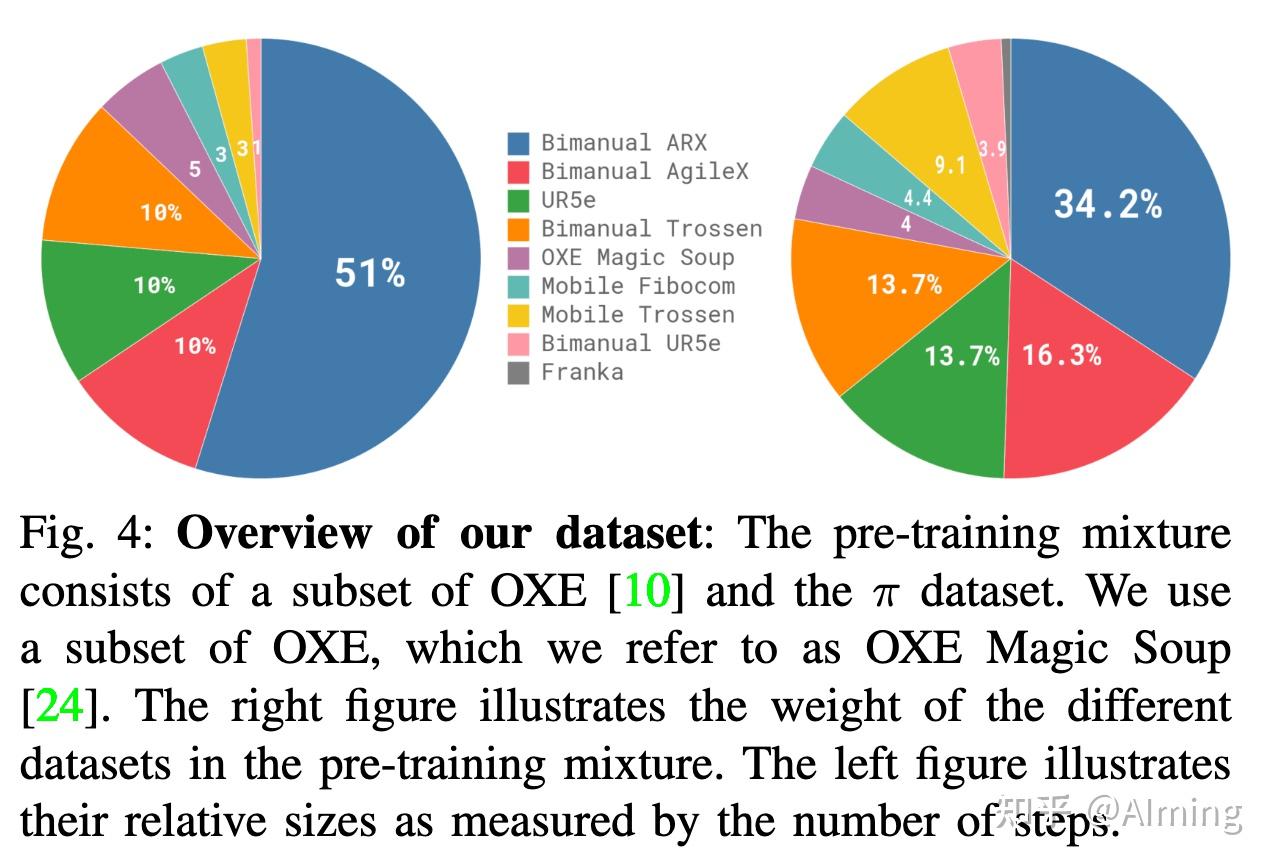
图 4 中由于每个训练样本都对应一个timestep — 即元组 (ot, At)
根据时间步长来量化数据。9.1% 的训练混合由开源数据集组成(OXE、Bridgev2、DROID)
这些数据集中的机器人和任务通常有一个或两个摄像头,并使用 2 到 10 Hz 之间的低频控制。这些数据集涵盖广泛的对象和环境。
为了学习灵巧和更复杂的任务,还使用了内部数据集的 903M条数据,其中 106M 来自单臂机器人,797M 来自双臂机器人。此数据有7种不同类型本体。
68 个任务,其中每个任务都由复杂的行为组成,例如,“bussing” 任务涉及将各种不同的盘子、杯子和餐具放入清理箱,并将各种垃圾放入垃圾桶。请注意,这个任务的定义与以前的工作都不同,以前的工作通常使用名词和动词的任意组合(例如,“pick up the cup”与“pick up the plate”)来构成一个不同的任务。
因此,数据集中的实际行为范围比这个 “任务 ”数量所暗示的要广泛得多。
使用的七种本体

- UR5e:带有平行钳口夹持器的手臂,带有腕部安装和肩扛式camera,总共用于两个摄像头图像和7D自由度的配置以及运动空间。
- Bimanual UR5e。两个 UR5e ,总共三个摄像头图像和一个 14D配置和动作空间。
- Franka。Franka 设置有两个摄像头和一个 8D 配置和动作空间。
- Bimanual Trossen.。有两个 6-DoF Trossen ViperX 臂,其配置基于 ALOHA 设置,带有两个腕式摄像头,一个全局摄像头,以及一个 14 D配置和动作空间。
- Bimanual ARX & bimanual AgileX.:使用两个 6-DoF 臂,并支持 ARX 或 AgileX 臂,具有三个摄像头(两个腕式和一个全局摄像头)和一个 14 维配置和动作空间。这个类包含两个不同的平台,但运动学属性相似归位一类
- Mobile Trossen & mobile ARX.:基于移动 ALOHA 平台,在移动底座上有两个 6-DoF 臂,是 ARX 臂或 Trossen ViperX 臂。平台的非完整约束基座增加了两个动作维度(移动的X,Y),分别是 14 D配置和 16 D动作空间。有两个腕部摄像头和一全局摄像头。也是运动学属性相似归位一类
- Mobile Fibocom: 两个 6-DoF ARX 臂位于全息底座上。该基础为 14 D配置, 17 D动作空间,添加了三个移动维度(两个用于平移,一个用于转向)。我们在图 4 中总结了每个机器人的数据集比例。
非完整约束基座指的是机器人的移动基座(比如轮子、履带等)在运动时受到方向性限制,不能自由地向任意方向瞬时移动或转动。
实验评估
评估指标
VLA任务的评估指标是每个任务和方法的 10 个 episodes(事件)的平均标准化分数,其中episode完全成功时得分为 1.0,部分成功得部分分数。
例如,“bussing”(清理餐桌)任务的分数是正确放置在适当容器中的对象所占的比例。附录E包含了超级多任务的具体评测方式,感兴趣可以细看。
对于每个任务都会设计一个分数来量化任务的进度。
1.在预训练数据中存在的各种任务上,π0 在预训练后的表现如何?
评估的时候,只做预训练阶段,然后开箱即用评估

有图中5种评测任务:
- 衬衫折叠:机器人必须折叠 T 恤,T 恤开始时是压平的。
- 简单清理餐桌:机器人必须清洁桌子,将垃圾放入垃圾桶,将盘子放入洗碗机。该分数表示放置在正确容器中的对象数。
- 困难清理:具有更多目标和更具挑战性的配置,例如故意放置在垃圾目标上的器皿、相互阻碍的目标以及一些不在预训练数据集中的目标。
- 杂货装袋:机器人必须将所有杂货装袋,例如薯片、棉花糖和猫粮。
- 从烤面包机中取出吐司
和OpenVLA 进行了比较,OpenVLA 是一个最初在 OXE 数据集上训练的 7B 参数 VLA 模型 。我们在完整的混合预训练数据集上训练 OpenVLA。对于 OpenVLA 来说,这是一个非常困难的数据集,它不支持动作分块或高频控制。
还与 Octo 进行了比较,较小的 93M 参数模型。虽然 Octo 不是 VLA,但它使用了diffusion policy,可以和flow matching 的VLA 比较。也在混合数据集预训练 Octo。由于时间限制,无法训练与完整模型相同数量的 Epoch 的 OpenVLA 和 Octo。
这里有以下几种模型:
- 主模型为 700k 步
- 主模型的“partity”版本,仅训练了 160k 步
- baseline1: OpenVLA 为 160k
- baseline2 :Octo 为 320k
- baseline3: OpenVLA-UR5e版本 ,只使用 UR5e 数据进行了微调,没有异构本体数据训练,希望为 UR5e 提供更强大的baseline。
- π0-small 模型,没有 VLM 预训练。
评估结果

如图 7 所示的结果表明,π0 遥遥领先,在衬衫折叠和更轻松的餐桌整理上有近乎完美的成功率,并且在所有基线上都有很大的改进
OpenVLA 在这些任务上性能很差,因为它的自回归离散化架构不支持动作块。
UR5e版本 的 OpenVLA 模型性能更好,但仍远低于 π0 的性能。
Octo 确实支持动作块,但表示能力相对有限。
这种比较说明了将大型、富有表现力的VLM架构与通过flow matching或diffusion对复杂分布进行建模的能力相结合的重要性。此外,与 π0-small 的比较说明了结合 VLM 预训练的重要性(当然这两者也不能公平对比,参数量都差距很大)
这些实验表明,π0 提供了一个强大的预训练模型,能够使用各种机器人有效地执行各种任务,性能比以前的模型好得多。
2.π0 的指令跟随能力如何?
比较了 π0 和 π0-small,以评估它在以下语言命令上的性能。使用人工提供的命令和由高级 VLM 策略指定的命令进行评估
该实验旨在测量 VLM 预训练在多大程度上提高pi0模型的语言指令跟随能力。(π0-small参数量小,这个对比因素很难消除)VLM 初始化既可以实际训练更大的模型而不会过拟合,也可以改善指令跟随能力。
每个任务的文本说明包括要选取的对象和放置这些对象的位置,以及长度约为 2 秒的语言标记段。每个完整任务都包含许多此类段。此评估中的任务包括以下三个:
- 餐桌清理:机器人必须清洁桌子,将餐具和餐具放入垃圾桶,并将垃圾放入垃圾桶。
- 餐桌布置:机器人必须从桶中取出物品来布置餐桌,包括餐垫、盘子、银器、餐巾纸和杯子,并根据语言说明进行调整。
- 杂货装袋:机器人必须将杂货装入袋子中,例如咖啡豆、大麦、棉花糖、海藻、杏仁、意大利面和罐头。
评估五种不同的情况:
π0-flat (和 π0-small-flat) 对应于直接命令带有任务描述的模型(例如,“bag the groceries”),无需中间语言命令。
π0-human (和 π0-small-human) 提供中间步骤命令(例如,要拾取哪个对象以及将其放置在何处)。
以上评估每个模型遵循指令跟随能力:虽然这些中间命令为如何执行任务提供了大量信息,但模型也得能够理解并遵循这些命令。
π0-HL 使用高级 VLM 提供的高级命令计算 π0。这种情况是自主的驱动的,没有任何人类专家指导
评估结果

图 9 中的结果,每个任务平均超过 10 次试验,表明 π0 的准确率遵循的语言明显优于 π0-small。这表明与较大的预训练 VLM 初始化相比有显着改进。此功能转化为通过专家人工指导 (π0-human) 和高级模型指导 (π0-HL) 提高性能。
实验表明,π0 的指令跟随能力在人类专家指导的过程中,任务执行效果最好
3.π0 与专门为解决灵巧操作任务提出的方法相比效果如何?
研究下游灵巧任务,可以从预先训练的初始化中微调模型,或者根据特定于任务的数据从头开始训练它,与之前提出的灵巧操作方法相比。目标是评估pi0架构和预训练的好处
为每个新任务使用不同数量的数据对模型进行微调。虽然每个任务都是新的,但根据任务与预训练数据中的任务的差异程度,将任务分类,如easy和hard。

任务有以下五种:
UR5e 堆叠碗:其中有四个不同大小的碗。由于此任务需要抓取和移动盘子,就像预训练数据中的 bussing 任务一样,因此分类为 “easy” 中。因为训练集中也包含了很多种碗。评估的时候用见过的碗和没见过的碗
毛巾折叠:由于这类似于训练前存在的衬衫折叠,因此我们将其置于“easy”级别。
把保鲜盒放进微波炉:这项任务需要打开微波炉,将塑料容器放入其中,然后关闭它。这些容器有不同的形状和颜色,评估使用见过的和未见过的容器。容器作类似于预训练数据,但在预训练中没有找到微波炉,算“hard"
纸巾更换。这项任务需要从支架上取下旧的纸板纸巾管,然后用新的纸巾卷替换它。因为在预训练中没有发现这样的项目,归为“hard”。
放入抽屉。此任务需要打开抽屉,将物品装入抽屉,然后关闭抽屉。因为 Franka 机器人在预训练中没有类似的任务,归为“hard”。
将微调后的pi0模型与 OpenVLA 和 Octo 进行了比较,它们也采用了预训练和微调策略。
这里目标是评估特定模型,因此我们为这些模型使用公开可用的预训练checkpoint,这些权重在 OXE 上进行训练,然后针对每个任务对它们进行微调。
还与 ACT 和 Diffusion Policy 进行了比较,它们是专门为从较小的数据集中学习灵巧任务而设计的。两者仅在微调数据集上进行训练,这些数据集的大小与 ACT 和 Diffusion Policy 实验中使用的单个数据集相似。
通过对预先训练的基础模型进行微调以及从头开始训练来评估 π0。以此比较π0 架构和预训练的优势。假设带有 VLM 初始化的 π0 架构应该已经为各个任务提供了更强的起点,而预训练过程应该进一步提高其性能,尤其是对于较小的微调数据集。
评估结果
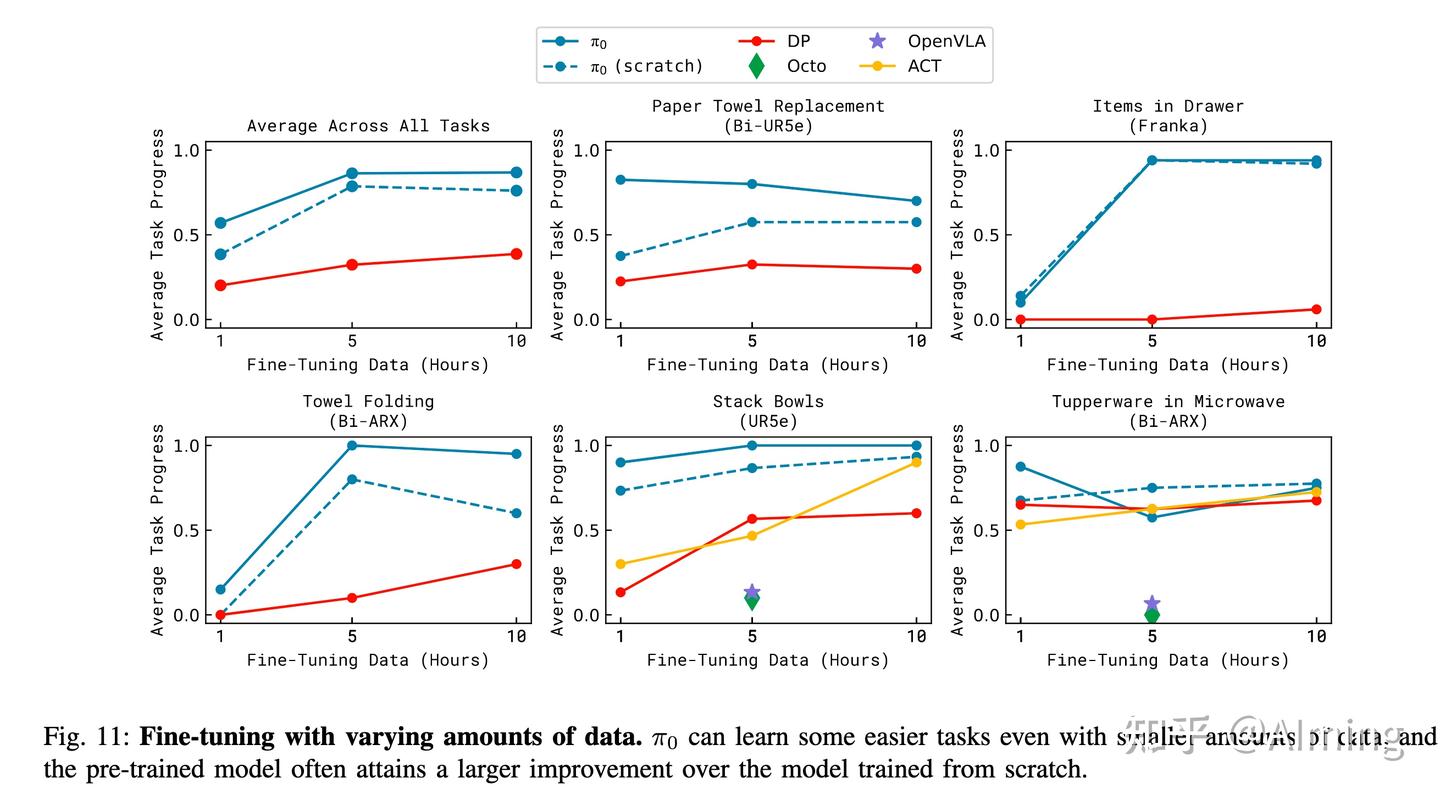
每个任务平均超过 10 次试验,每个任务的微调数据量不同。
由于 OpenVLA 和 Octo 的性能明显较差,因此我们只对其中一个数据集大小运行它们,因为在现实世界中评估如此多的模型会花费时间。
结果表明,π0 通常优于其他方法。
值得注意的是,把保鲜盒放进微波炉任务上 π0 的 5 小时策略与baseline执行类似,随着训练增加,预训练了优势消失了,但 1 小时版本要好得多。如预期的那样,预训练会为与预训练数据更相似的任务带来更大的改进
但预训练模型通常还是比非预训练模型更好,有时高达 2 倍。
4.π0 能否适应复杂的多阶段任务?
将 π0 微调为一组特别复杂的任务,包括折叠衣物和整理桌子。这些任务需要 5 到 20 分钟才能完成。有些需要高级策略的指导。对于某些任务,预训练完全没见过。
以下七种复杂多阶段任务:
- 衣物折叠:这项任务需要一个静态(非移动)双手动系统来折叠衣物。服装在箱中以随机皱巴巴的状态开始,目标是取出项目,折叠它,然后将其放在一堆以前折叠的衣服上。此任务存在于预训练中。
- 移动叠衣:移动机器人折叠衣物,在控制方向和平移的同时面临许多相同的挑战。此任务存在于预训练中。
- 烘干机取衣服:移动机器人必须将衣物从烘干机中取出并放入篮中。此任务存在于预训练中。
- 桌子清理:这项任务需要在杂乱场景中用各种新奇物体的桌子清理,这比开箱即用评估中的基准要大得多的挑战:该策略必须推广到不同形状和大小的未见物体,并执行复杂的灵巧动作,例如扭动夹具拿起大盘子和小心地抓薄的板子。 玻璃杯等精致物品。机器人必须处理密集的杂物并智能地对各种行为进行排序——例如,要清理装有垃圾的盘子,它必须首先捡起盘子,然后将其内容物摇晃到垃圾中,然后将盘子放入垃圾箱。此任务在预训练中不存在。
- 箱子构建:机器人必须组装一个以扁平状态开始的纸板箱。这项任务带来了许多主要挑战:盒子需要以正确的方式弯曲,机器人需要在折叠其他部分的同时按住盒子的各个部分,在折叠运动中利用双臂甚至桌子表面进行支撑。机器人可能需要重试一些折叠,这需要反应灵敏的智能策略。此任务在预训练中不存在。
- 外卖盒:这项任务需要将盘子中的几种食品移动到外卖盒中,需要将物品装入盒子中,以免它们伸出,然后用双臂关闭盒子。此任务在预训练中不存在。
- 包装鸡蛋:机器人需要从一个碗中取出六个鸡蛋,将它们装进鸡蛋纸箱中,然后关闭纸箱。需要以适合它们在碗内姿势的方式抓住鸡蛋,然后放入纸箱的开放槽中。由于鸡蛋的形状、光滑度和需要小心放置。关闭盒子需要使用双臂。此任务在预训练中不存在。
评估结果

这些任务非常困难,且无法用其他方法解决。因此,使用这些任务进行ablation,在预训练和微调后评估 π0,仅在预训练后开箱即用(“out-of-box版本”),以及在没有任何预训练的情况下根据微调数据进行训练(“scratch版本”)。
结果表明, π0 可以解决其中的许多任务,完整的预训练+微调策略在各个方面表现最佳。
与使用预训练模型相比,许多更困难的任务显示出非常大的改进,这表明预训练对于更难的任务特别有用。
π0 的绝对性能因任务而异,主要是由于任务难度和任务在预训练中的表现程度的差异。
这种挑战性的任务虽然没有到完美执行,但是这类任务的效果已经达到了一个新的突破了!
局限性和未来展望
本文提出了一个用于训练机器人基础模型的框架, π0,它包括对高度多样化的数据进行预训练,然后是开箱即用的评估或对复杂的下游任务进行微调。结合灵巧性、泛化和时间扩展的多阶段行为的任务进行了实验。
人们普遍认为,此类模型中的大部分 “知识” 都是在预训练阶段获得的,而后训练阶段则用于告诉模型应该如何利用这些知识来完成用户命令。我们的实验表明,机器人基础模型可能会发生类似的现象,其中预训练模型具有一些zero-shot功能,但像洗衣、跟随这样的复杂任务需要微调
仅使用这些高质量数据进行训练会导致模型脆弱,无法可靠地从错误中恢复,而以zero-shot运行预训练模型并不总是表现出训练后数据中展示的流畅policy。(目前有拿强化学习来解决这方面的问题,下期分享下)
目前这样的模型存在许多限制和未来可探索的事情:
- 实验没有全面探索应该如何组成预训练数据集:合并了所有可用的数据,但了解哪种类型的数据更有助于添加以及应该如何加权仍然是一个悬而未决的问题。
- 目前不是所有任务都能可靠地工作(成功率的问题),并且目前尚不清楚如何预测需要多少数据以及需要什么样的数据才能获得近乎完美的性能。
- 最后,将高度多样化的数据相结合,特别是来自不同任务和不同机器人的数据,对于下游任务有多少正向收益还有待观察(其实某些特定任务,只需要从头到尾训练一个VLA模型也能获取不错的效果)
- 通用的预训练机器人foundation model可能会成为现实,但还有待未来的工作来了解这种普遍性是否延伸到更不同的领域,例如自动驾驶、navigation 和腿部locomotion。