作者:骑虎南下
https://zhuanlan.zhihu.com/p/1931235792501608813
这里,分两个主要模块介绍AI模型推理引擎整体架构与主要功能。回顾AI落地的发展过程,我们可以简单地将AI模型的发展分为小模型领域与大模型领域。
在小模型领域以CNN模型为主,模型结构变化多样分为分割,检测,识别,NLP等各个类型。
在大模型领域,模型结构比较统一以LLaMa系列,Deespeek系列,Qwen系列等模型均起源于Transformer结构,新增比如MLA,MoE的一些局部改造。
小模型推理框架
在小模型领域推理框架发展已经比较成熟,从NCNN,TNN,到后来的MNN,TVM整体推理引擎的架构比较完善。

如上图,来源于MNN的介绍文档,借此图简单介绍整个CNN模型框架主要功能。
Tools 模块
1 . Converter模块:
a . 主要实现Torch模型/ONNX模型到框架上层IR或者框架自定义图的转换,包括模型解析,图生成,算子替换等主要功能。
b . 主要实现自定义图的优化,包括常量折叠,算子融合,模型结构优化,静态显存管理等主要功能。
2 . Compress模块:
在满足一定精度守护的前提,实现比如模型后量化,模型剪枝等模型压缩类处理。
3 . Express模块:
支持带控制流的模型运行,比如一些跳转OP的实现,支持自定义算子Plug-IN等。
4 . CV模块:
负责实现常见的CV类前后处理函数,支持框架跑模型完整的PipeLine流程,比如一些Resize函数 。
Runtime 模块
1 . Pre-Inference模块:
比如实现模型的内存分配与管理,动态Shape推导以支持模型动态Shape推理,进一步提升模型性能。
2 . 后端设备与算子模块:
a . 各类不同算子极致优化,包括Stressen矩阵乘,Winograd卷积,低精度推理等。
b . 各类不同芯片的异构执行,CPU上的Neon/Avx优化,GPU上的OpenCL/CUDA优化等。
大模型推理框架
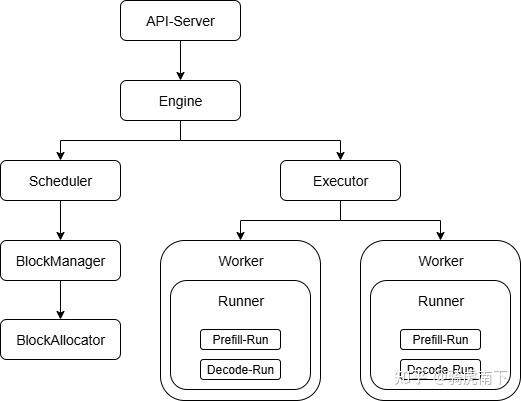
在大模型领域推理领域这几年也出现一批推理引擎,比如LightLLM,vLLM,LM-Deploy等。这里以vLLM的推理逻辑为例简单介绍下大模型引擎如何工作。
大模型推理框架在整个模型Build阶段或者说初始化阶段与小模型框架有很多相似之处,比如需要算子融合,显存复用,算子替代,模型压缩。
但是大语言模型因其自回归推理的特点,又有很多推理的特性实现,包括Continuous Batching,Paged Attention,Packing,Chunked Prefill等。这些特性的核心都是提升组Batch的并发能力,这也导致框架有其自有特点。
1 . vLLM以服务框架的形式提供一整套的API接口给调用者使用,针对不同应用场景分为Chat接口与Completion接口。
2 . 在推理模块分为两大块,调度器模块与执行器模块,调度器模块主要负责组Batch的特性实现比如Continuous Batching,Chunked Prefill,Paged Attentntion。执行器模块主要负责模型的具体推理,包括不同Rank上的Worker执行,模型的首Token推理与Decode推理。
3 . 其中Scheduler的Block Manager / Block Allocate主要负责KVCache的管理与分配。
总得来说,CNN领域小模型的推理更聚焦于与芯片上模型推理加速,大模型领域因为模型结构统一推理更多侧重于动态Batch,服务调度。