
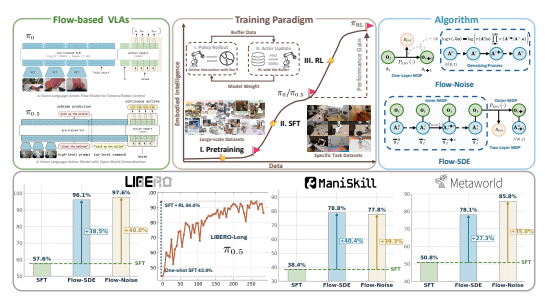
强化学习可以减少 VLA 模型对大量数据的依赖。我们提出了面向流匹配VLA( π_0, π_{0.5})的强化学习微调框架 π_RL ,提出了 Flow-Noise和 Flow-SDE两种微调技术路线。
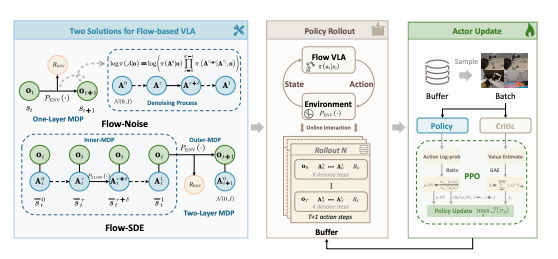
- Flow-Noise 在单层 MDP 中引入可学习噪声,通过完整的去噪序列计算动作似然;
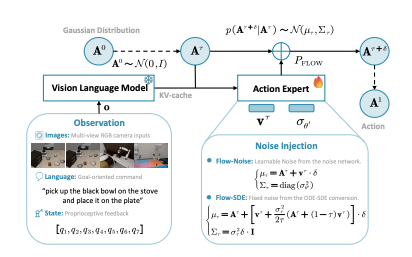
- Flow-SDE 则将去噪过程转化为随机微分方程(SDE),在双层 MDP 中实现“边生成边交互”的强化学习。
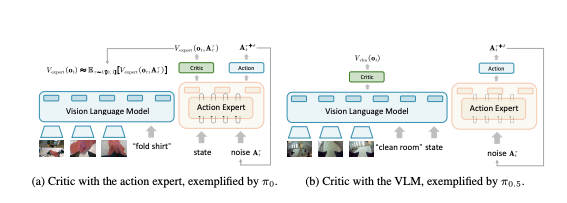
两种方法共同解决了流式模型在强化学习中难以求解似然的问题。
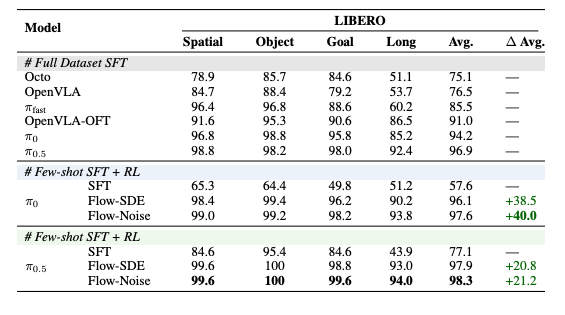
在公开测试平台LIBERO平均性能达到97.6%和98.3%,同时在包含4,352种抓取-放置任务组合的ManiSkill环境当中成功率涨幅 50%,最终成功率超90%。

12月6日(周六)上午10点,青稞Talk 第95期,北京大学博士生陈康,将直播分享《从 π_0 到 π_{RL} :面向流匹配 VLA 的强化学习后训练框架》。
论文:π_𝚁𝙻 : Online RL Fine-tuning for Flow-based Vision-Language-Action Models
链接:https://arxiv.org/abs/2510.25889
代码:https://github.com/RLinf/RLinf
分享嘉宾
陈康,北京大学计算机学院在读博士生,以第一作者身份在CVPR、NuerIPS、AAAI等会议上发表多篇文章,研究方向为VLA强化学习训练及计算摄影成像。
主题提纲
从 π_0 到 π_{RL}:面向流匹配VLA的强化学习后训练框架
1、流匹配 VLA 模型介绍及 RL 训练难点
2、面向流匹配 VLA 的 RL 微调框架 π_{RL}
- Flow-Noise
- Flow-SDE
3、π_0 和 π_{0.5} 微调实践
4、AMA (Ask Me Anything)环节
直播时间
12月6日10:00 - 11:00