作者:浮生梦晓
https://zhuanlan.zhihu.com/p/1979237927641949997
前段时间调研了一些 RL 训练框架,目前开源社区的 RL 训练框架可以说百花齐放,老牌的有 openlhf、trl、unsloth、verl。还有今年新开源的 slime、AReaL、Rlinf、RL2、ROLL 等等,肯定还有很多没列出来的,就不一一列举,也看不过来。
由于工作的场景需求是对于 VL 多模态模型进行实际环境的 RL 训练,这个过程需要 multi turn,因此很多框架可能目前并能很好的适配。重点对 verl、slime、AReaL、RL2 做了代码阅读分析,与实际 RL 环境进行适配。这里先说一下我调研框架过程中纠结的一些点。(个人看法,轻喷)
点 1:各训练框架尺有所短、寸有所长,都有各自的架构很好的地方,也有相对待完善的方面。
目前没有一款可以很好适配多模态模型去做我的需求业务的 agentic rl 训练的框架,当然这也不是框架的原因,主要在于 agentic 环境与具体业务相关,没有办法从框架层面抽象出来一个函数或者类来适配所有的 agentic 环境,这也是我从一个框架调研到另一个再到另一个的原因。
我一直想找一个社区活跃度比较高,对于环境适配代码相对修改较少的框架,这里直接说,最后选择了 AReaL。(我的具体业务环境不展开说了,简单来说是需要每个训练样本都有不同的环境状态,除了模型的输出内容去环境里执行动作以外,还需要框架会话与环境多次交互,这一点就卡死了大部分 RL 框架的 agent loop 控制流,当然除非做侵入式代码修改,但框架更新后 rebase 又很麻烦)
点 2:我比较纠结的是 RL 训练过程中 GPU 的编排问题
在 rlhf 和 rlvr 时代(听上去很遥远,实际上也就是 25 年前半年以及之前)训练过程中长尾效应没有 agentic rl 那么明显,所以异步 RL 训练的想法并没有在早起成熟的 RL 训练框架中体现出来。
之前开源的 RL 框架基本上都是训练和推理同步的架构方案,典型代表像 verl,verl 实现了这几个模型的简单命令编排,但没有改变同步运行的本质,也就是整个训练流程都要遵循下图中 1,2,3 来进行,先推理后训练。
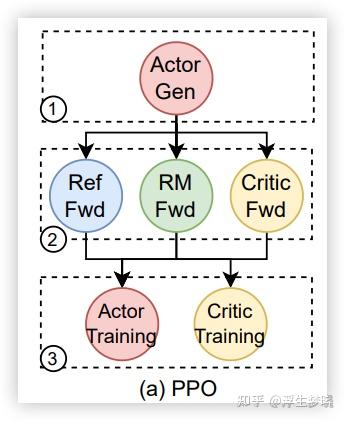
同步的 RL 训练玩的也比较花,比如是在相同的 GPU 集群上,推理时训练的模型卸载,训练时推理的模型卸载,这种可以在容器内部署,也可以物理上执行。也可以在不同的 GPU 集群上流水线的方案,就像 verl,但这样就会造成训练效率的低下以及 GPU 空转。
因此我对于以同步 RL 训练为主的框架都是浅尝辄止,没有深入研究,verl 是因为今年 10 月份增加了全异步训练的 monkey patch 才对其源码进行来阅读,不过代码中写死了 agentic 的执行流程,修改起来代码量不小,后面会稍微详细的说一下。
点 3:数据流向与数据结构
其实这也是同步和异步训练带来的一个影响。在 verl 中将传统的 rlhf 训练的流程看成一个数据流图,数据在 actor、critic、reference、reward 中进行流转,最后来计算 PPO 公式得到损失,再对 actor 进行反向传播,参照下图:
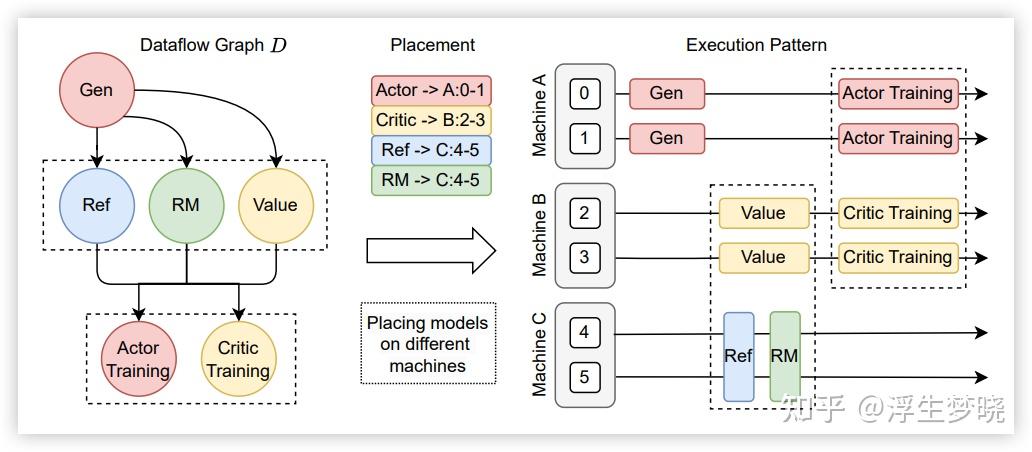
为此 verl 专门设计了一种数据格式:DataProto
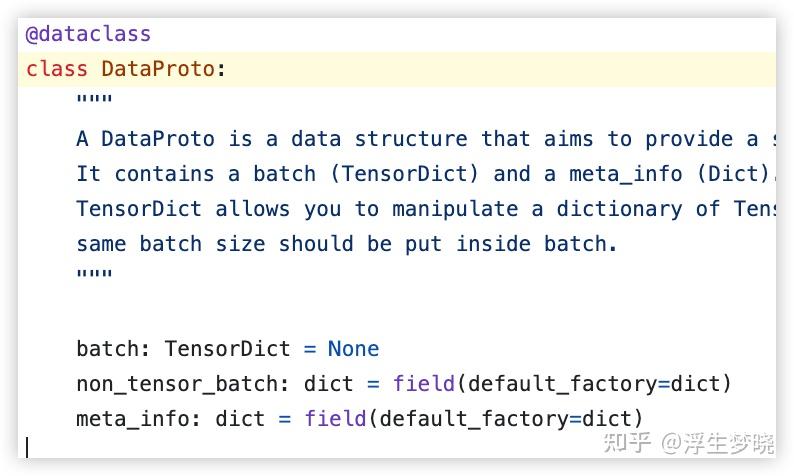
从这个数据结构组成上来看并不复杂,它是以 batch 为粒度进行数据传输的,这在长尾效应不明显的 RL 训练中是高效的,但是在 agentic rl 中反而成了一种负担。
原因很简单,训练的 DataProto 和推理的 DataProto 是否要是同一批数据呢,如果是同一批那就要考虑长尾样本的延迟,如果不是同一批那这个设计反而代理额外的时延(推理的样本异步执行,结果再去组成一个 DataProto)。verl 源码中是前者的实现,但在补丁代码中是使用的后者。
点 4:异步 RL 训练框架肯定优先级比较高
今年开源的几个框架都支持异步 RL 训练,但异步会带来效率上的提升,但也会存在一些问题,首当其冲的就是数据偏移问题,换句话说就不是真正的 on policy 训练,因为训练的数据可能是更早几轮的策略模型生成的,在强化学习训练中大家的共识就是 on policy 效果优于 off policy。
另一个问题就是异步 RL 训练占用的 GPU 资源较高,相对于同步训练中训练和推理共用 GPU 集群来说,异步 RL 训练必须将训练和推理部署在不同的 GPU 上,且二者需要去实验来获得一个比例,来保证异步 RL 训练和推理尽量的减少 bubble。
除了以上内容外,从各 RL 训练框架代码中获得了一些关于 RL 的启发认识,有的是之前知道但不清楚代码如何去实现,也有的是从代码上新认识到的。
1、当前几乎所有的 RL 训练框架都是训推分离的
也就是训练引擎使用 FSDP、Megatron,推理引擎采用 sglang 或者 vllm。训练和推理之间采用 ray 来充当胶水,作用就是分配资源,分布式远程调度等。
RL 训练框架真正实现的是对于数据的管理、训练引擎和推理引擎的调度、模型权重的迁移(训练后的模型权重更新到推理引擎,训练与推理不同切分方式的适配)以及环境的适配。
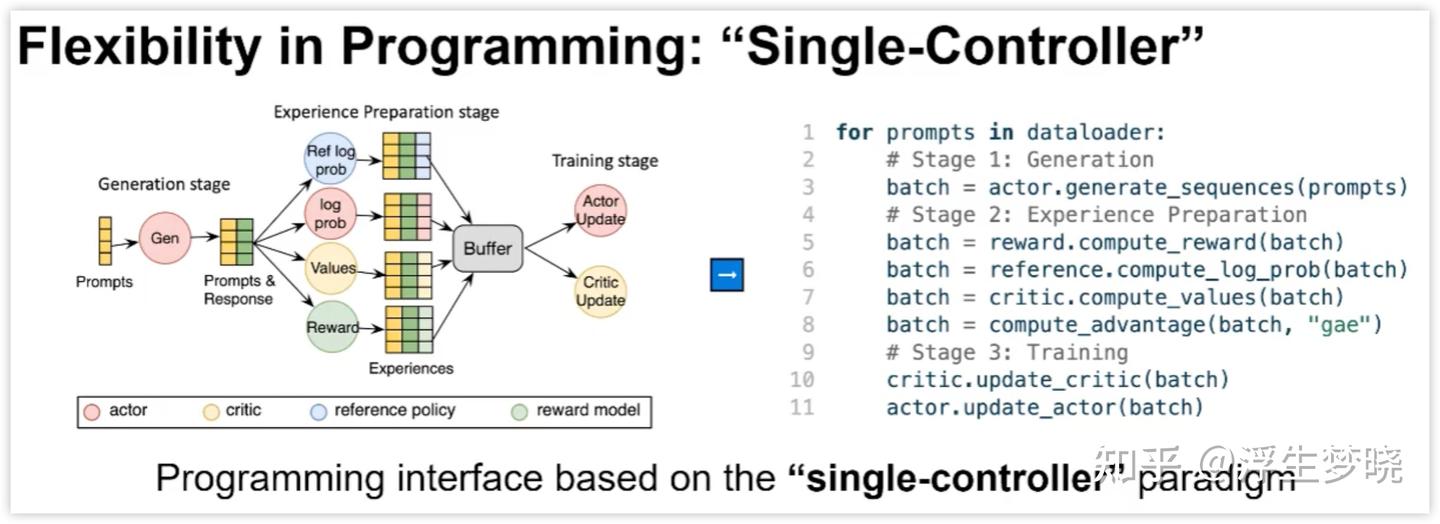
每个框架在这四个方面有不同的侧重,比如 verl 侧重在训练引擎和推理引擎的调度,包括其为了践行 SPMD 思想(类似于 torchrun 和 CUDA 的运行,每个设备 rank 上都会有相同的代码,而各设备会根据自己的约束来执行各自的那部分代码)编写了 single_controller,通过封装底层的 ray 代码让用户只需要简单的命令来实现复杂的模型编排部署,如下图所示,这种模式天然简约。
但这种模式在异步 RL 训练反而成了瓶颈,异步需要额外的代码去更新权重、处理生产者与消费者的关系,保持 SPMD 风格会使得代码量骤增。其他的框架基本上是直接调用 ray,通过 placement_group 来分配 GPU 资源,remote 来调度。
2、RL 训推分离的训练流程中的控制流还是在训练侧
也就是训练的控制流代码中,其实这非常好理解,强化学习训练与正常的 llm 做 sft 和 pre-train 训练区别不大,因为都是基于梯度回传的思想来实现的,区别就在于损失函数不再是交叉熵,且数据的来源需要 rollout 推理生成,如下图实现的简单 GRPO 训练代码。
因此强化学习训练无需考虑的很神奇,如果不考虑效率直接用 pytorch 手动撸或 ai 生成一个小模型的 rl 训练代码也就半天时间。
def train_step():
# 1. Model and optimizer
model = transformers.AutoModelForCausalLM.from_pretrained(「Qwen/Qwen2.5-7B」)
optimizer = optim.Adam(model.parameters(), lr=1e-5)
# 2. Data
prompts, answers = prepare_data()
options = {"n": 8}
# 3. Generation and advantage
generations = model.generate(prompts, **options)
grpo_scores = calculate_varifiable_rewards(prompts, answers)
# 4. Train
loss = calculate_gradient_policy(generations, grpo_scores)
loss.backward()
optimizer.step()
optimizer.zero_grad()
3、关于训练侧更新了 actor 模型的权重后如何将新的模型权重从训练引擎传递给推理引擎
这一部分涉及的问题在于训练侧的模型切分方案与推理侧的模型切分方案不一致,而模型如果比较大的话权重的传输也是不小的时延。当前比较简单的方案是直接调用 sglang 或者 vllm 的 fast full 接口,例如 slime 中代码
HTTPS://GitHub.com/THUDM/slime/blob/main/slime/backends/fsdp_utils/update_weight_utils.py#L223
AReaL 中代码
HTTPS://GitHub.com/inclusionAI/AReaL/blob/main/areal/core/remote_inf_engine.py#L1025
从实现的角度来说也比较好理解。感兴趣可以看下面说明:
比如训练引擎使用 FSDPv2,推理引擎使用 sglang,则在初始化时会对于训练和推理进行 GPU 资源分配,以及传入切分规则(dp、tp、sp 等),FSDPv2 通过 device mesh 完成模型的切分。sglang 则将切分后的模型权重加载到各 rank,每个 rank 会记录自己负责的模型权重的元数据。
当 FSDPv2 训练引擎完成一轮训练产生新的模型权重后,会从 FSDP 的 torch.DTensor 转成 torch.Tensor,每个训练 rank 会将数据广播到推理的 rank,推理的 rank 会根据 sglang 初始化时记录的元数据判断这部分权重是否保留,如果保留直接将模型权重存入到原模型权重指针地址处,覆盖掉旧的模型权重。如果不保留直接丢掉,最终完成全部推理 rank 的权重更新。
当然这部分会有很多 trick,如果直接由训练的 rank 广播给每个推理的 rank,则通信的开销会很大,一般的常用的 trick 是训练侧会先进行 all-gather,将权重分桶(按层或按容量)在每个 node 的 rank0 上去广播给推理引擎(slime 的实现)。
而上面的 AReaL 代码是使用了分桶传输,这样可以降低通信消耗。verl 中当前的方案比较一般,既没有 all-gather,也没有分桶。另外sglang和verl都实现了router功能,直接发给router,由router转发给各rank的方案也是一个主流方案。
HTTPS://GitHub.com/volcengine/verl/blob/main/verl/workers/rollout/sglang_rollout/http_server_engine.py#L350
4、训练引擎与推理引擎存在 gap 的问题
这里的 gap 有两种,介绍之前需要先说一下 RL 流程,RL 训练需要先将指令发送给推理引擎进行 rollout,rollout 得出每个序列轨迹。
如果是 on policy 的 RL 训练本应该直接使用 rollout 的轨迹来计算优势,进而计算目标函数来进行梯度回传。但当前的训推引擎是分离的,sglang 和 vllm 这种推理引擎自己实现的 CUDA 算子以及存在的各种优化,包括不限于(KV 量化、算子融合、模型编译等)。
另外也可能训推异构导致硬件计算精度等原因会使得推理引擎得出的序列轨迹里每个 token 的 logits 与训练引擎相同序列轨迹的 logits 存在差异,这种差异会使得原本是 on policy 的训练退化成 off policy 的 RL 训练。关于这个 gap 问题多篇论文和博客都有讨论The AI workspace that works for you。
解决的方法其实也比较传统,既然推理引擎和训练引擎的分布存在差异,那直接使用重要性采样来在推理数据分布中拟合训练引擎数据的分布。也有的优化在这个重要性采样上加上 clip,防止二者差异过大。也有的 trick 是提前通过数据分布计算出来这个比值,在真实训练时加上,这样不必重新将轨迹内容放入训练引擎 prefill 重算了。
如果是 off policy 的 RL 训练则本来就应该计算重要性采样,也就是 rollout 需要记录轨迹的 logits,在训练模型上进行 prefill 获得该轨迹在当前策略模型上的 logits 再去做重要性采样,这样做出的重要性采样既包含不同版本间策略模型训推分布的差异,也包含训推框架之间的差异。
基于上面的这个思想,推理引擎其实就可以使用量化推理,反正无论如何都要计算训推差异重要性采样,那使用 fp8 或者 4bit 量化更快推理岂不美哉。
实际上我们知道 PPO 中的重要性采样是需要被裁剪的,如果重要性采样过大,也就是数据差异太大会容易造成训练的不稳定,而一旦该数据被 clip 掉则就不在有梯度回传(不清楚的看 PPO 的求导公式)。
所以推理引擎不能一味的追求推理速度而造成输出分布的失真。fp8 或许还可以使用,4bit 量化推理目前还没有广泛使用,关键就在于 4bit 量化推理带来的分布差异会有些高,很容易被裁剪。所以没有任何精度损耗且推理提效的推测解码成了推理引擎的新宠,目前各 RL 训练框架都已经适配或正在适配推理引擎的推测解码。
上面只提到了 RL 训推的第一个 gap,从第一个 gap 可以知道 rollout 出的数据需要在推理引擎重新 prefill 来计算重要性采样,这样就引发了第二个 gap,即 rollout 出的序列对应的 token 分布与重新 prefill 进行 tokenizer 编码后对应的 token 分布不一致。
举个例子,如果推理引擎 rollout 得到的序列为:我喜欢吃西红柿。输出的 token 分布为:[我,喜欢,吃,西红柿],但是这个训练在训练引擎 prefill 编码时就很可能编码吃:[我喜欢,吃西,红柿]。token 分布都不一致了还怎么去计算重要性采样。所以可以看到所有的 RL 训练框架在 rollout 返回时会同步返回输出的 token ids,直接将 token ids 输入给训练引擎,避免二次编码的问题。
5、环境的适配以及奖励的管理
我在调研这几款 RL 框架时尤其注意其 agentic RL 训练的支持,对于外部环境的接入模式,以及奖励的计算方式,毕竟有的奖励是动作粒度从环境中得到的,也有的奖励是对于整个轨迹的。
在 verl 中的 agent 多轮训练代码逻辑在这里的设计是判断 agent 的状态来选择不同的函数句柄,比如 agent 多轮执行过程中可能需要人去输入新的内容,也有的是只与环境进行交互,代码逻辑如下图:
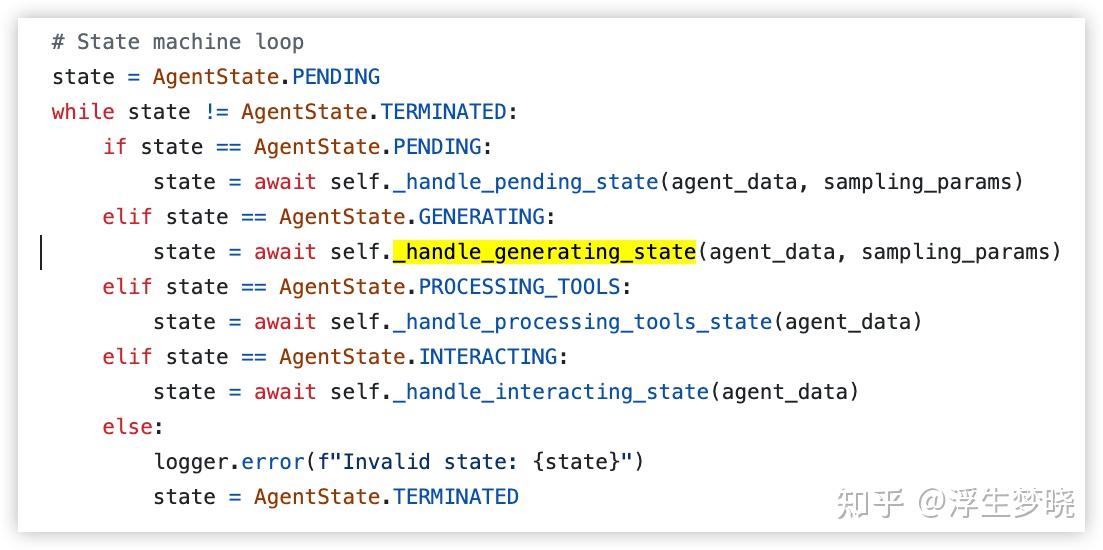
这种交互方式实际上涵盖了一般的 agent 多轮的状态,比如执行完 self._handle_generating_state 后,也就是推理引擎输出了内容,会根据输出内容是否解析出 action 执行 function call,是否达到最大交互次数来更新 state 的状态进入下一个循环。
而在 self._handle_processing_tools_state 中,也就是动作给环境执行的函数中是通过 self._call_tool来对这个动作输出 observation。
也就是说 verl 当前版本其实还是以工具的视角来进行 agent 多轮训练,并且处理流程很多都写死了,只能在模型输出的结果里去与工具交互,而真实复杂的环境交互可能需要多次交互,且每个 rollout 中的环境未必一致,verl 当前的 agent loop 相对有些僵化。
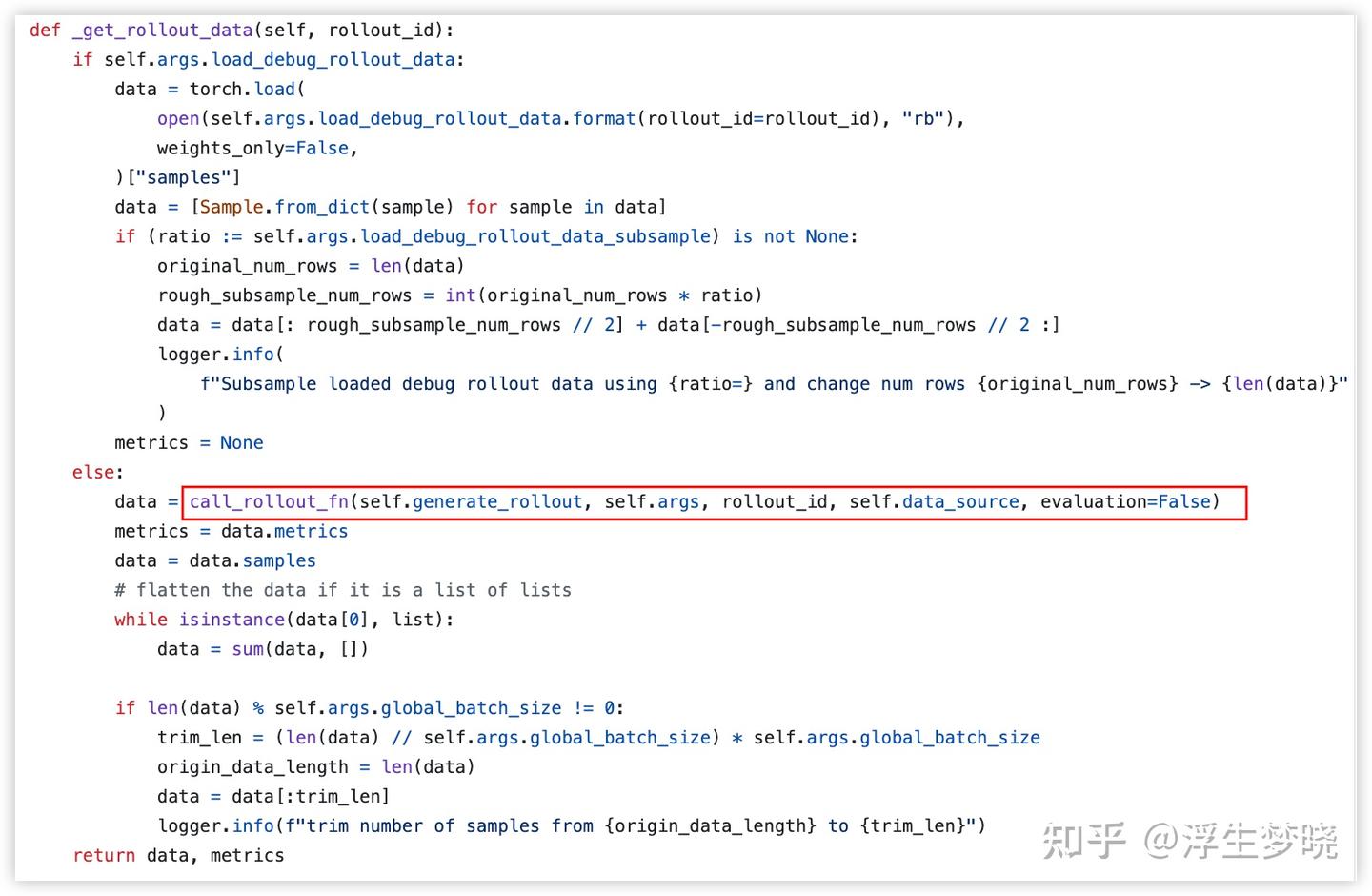
而在 AReaL 和 slime 中设计就相对巧妙一些,在 slime 中可以通过--rollout-function-path 参数可以传递自定义的函数给 rollout self.generate_rollout 就是外部传入的自定义的 rollout 工作流。
在 AReaL 中则需要自定义 workflow 基类中设定了子类必须实现的函数。
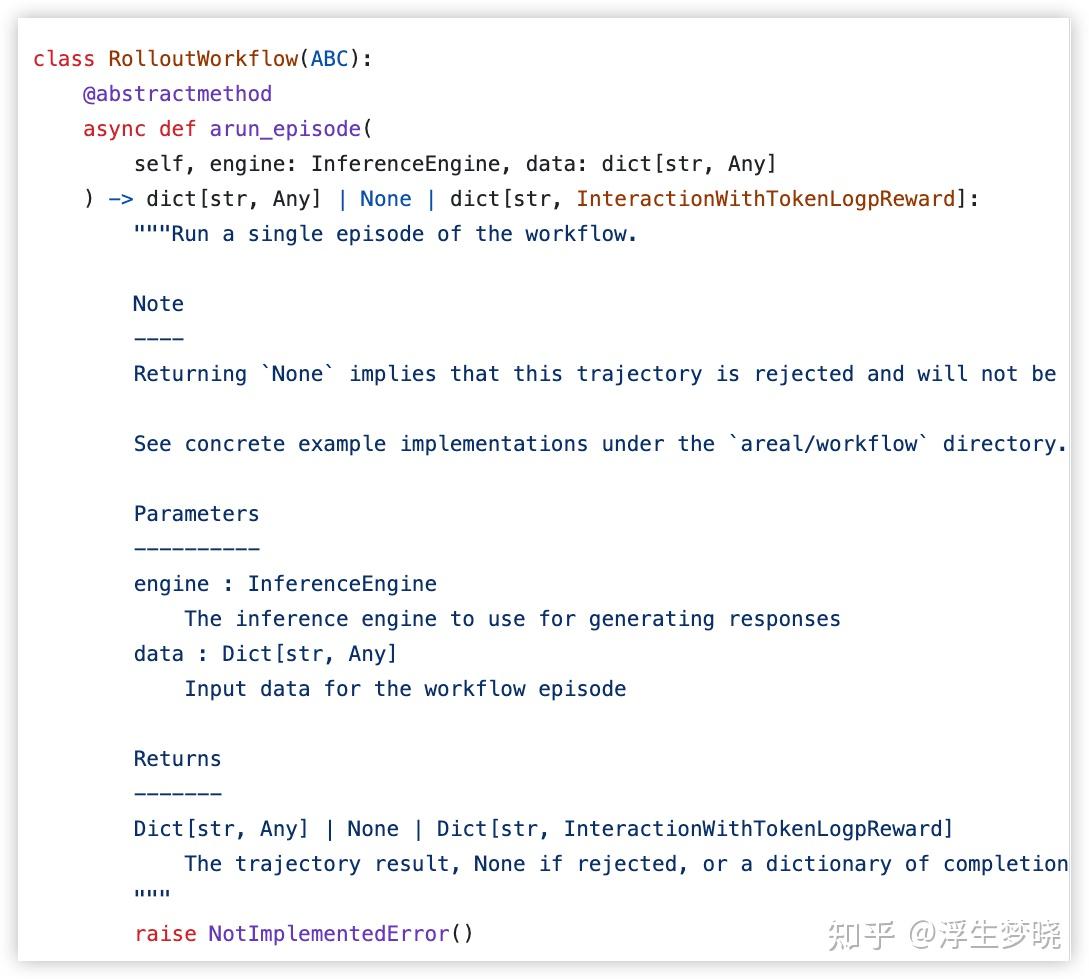
在 example 中可以看见很多自定义 workflow 示例,例如
HTTPS://GitHub.com/inclusionAI/AReaL/blob/main/examples/tir/tir_workflow.py
中内容,虽然在代码实际调用的是使用 workflow 中的 arun_episode 方法,但是这个类实例化时构造函数里是可以做很多工作的,比如初始化环境等,arun_episode 方法也可以实现自定义复杂的环境交互逻辑。
综合来说所有 RL 框架中环境交互的部分都是异步实现的,这一点毫无争议,不可能每一个样本都阻塞线程。
6、异步训练的处理方案
这部分就直接拿 AReaL 来说吧 ,我个人感觉 AReaL 的异步方案是当前主流 RL 训练框架里比较成熟的,包括 verl 也专门 pr 了 recipe 来实现异步训练。实现上与 AReaL 大差不差,还有一些其他方案(可以看 verl 的 recipe 上 readme),代码实现上也是大同小异。核心思想就是我们熟悉的不能再熟悉的生产者和消费者关系。推理引擎做 rollout 相当于生产者,训练引擎需要数据相当于消费者。
同步 RL 与异步 RL 的示意图直接截了 AReaL 论文中的图,其实没什么好说的,从图中就可以看到同步方案会存在很多 bubble,且推理时存在训练资源浪费,训练时存在推理资源浪费。异步 RL 会交替异步进行,每完成一轮就进行一次模型权重更新。

对于生产者和消费者的关系模式借用 verl 中图:
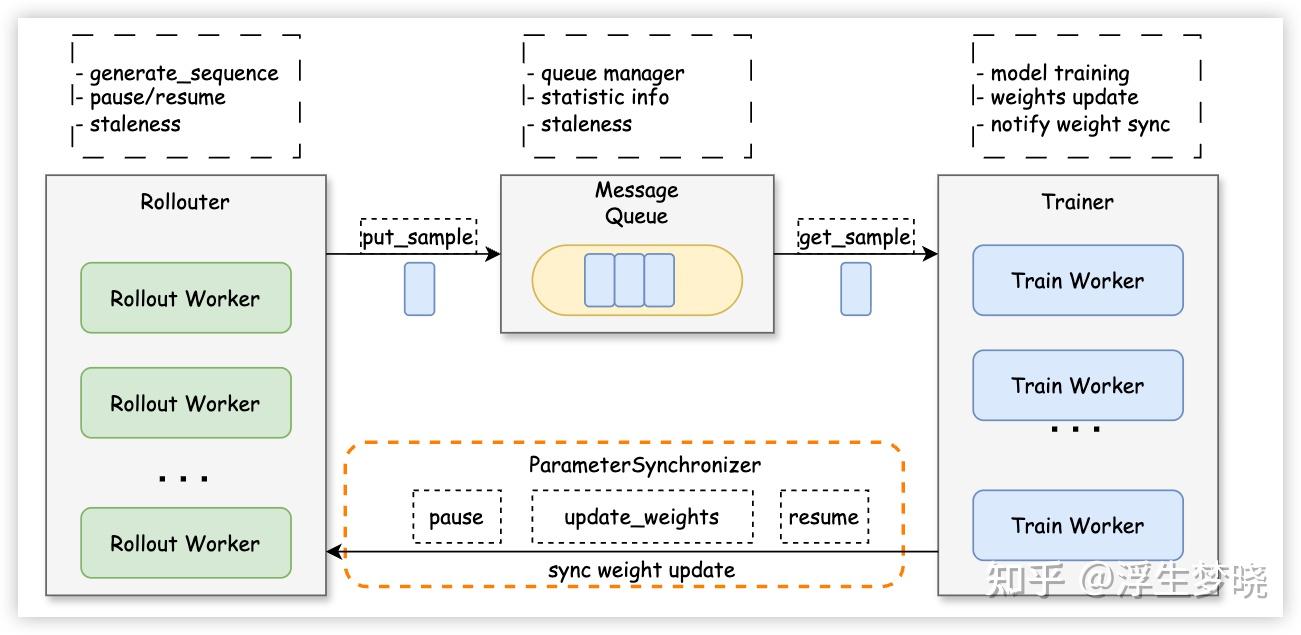
rollout 出的数据会放在一个消息队列中,这个管理队列相当于 replay buffer,当数据达到一定 batch size 后训练引擎会从这个消息队列中获取数据来进行训练,相反如果消息队列中数据不足则训练引擎等待数据生成。需要注意一个参数:staleness。
这个参数控制着数据是否需要丢弃,考虑现实情况,有一个任务需要 rollout 非常久,当这个任务 rollout 完成时训练引擎已经完成了多次模型权重更新,那这个任务的轨迹是之前模型推理出的,如果使用这个轨迹进行训练哪怕有重要性采样也容易被裁剪,从而导致最后没有梯度。
也就是说 staleness 控制着 rollout 数据不能偏离最新模型分布太久,一般设为 1-2,很早的数据就丢弃掉,因为对训练意义不大。staleness 是如何实现数据控制的,也很简单,每一个 rollout 轨迹都有一个版本号,如果版本号与当前最新模型的版本号差距大于 staleness,则从消息队列中丢弃。
AReaL 中的实现要更复杂很多,
AReaL 中这部分代码
HTTPS://GitHub.com/inclusionAI/AReaL/blob/main/areal/core/workflow_executor.py
HTTPS://GitHub.com/inclusionAI/AReaL/blob/main/areal/core/async_task_runner.py
staleness 管理代码:HTTPS://GitHub.com/inclusionAI/AReaL/blob/main/areal/core/staleness_manager.py
在 AReaL 中共涉及到 4 个队列,2 个无界队列_pending_inputs 和_pending_results,2 个有界队列 input_queue 和 output_queue。共 4 个线程参与,分别是主线程、事件循环线程、生产者线程和消费者线程。
数据流向是先流入到_pending_inputs 队列,这一步由主线程完成,在流入 input_queue 队列,这一步由生产者线程完成,rollout 管理器从 input_queue 中取数据并执行后将结果存入 output_queue,这一步由事件循环线程完成,最后从 output_queue 放入_pending_results,这一步由消费者线程完成。再从_pending_results 中取结果给训练引擎,这一步由主线程完成。
之所以这么复杂一部分是便于 staleness 进行管理,也考虑到实际执行的 rollout 同时处理数据的能力(input_queue 容量代表同时 rollout 的数量),防止大批量数据同时传递给 rollout 后。另外这种方案也便于下面讨论的 partial rollout 管理。
7、只依靠异步训练并不能很好的解决长尾问题带来的资源浪费和效率低下
还需要一个技术方案:partial rollout,这个方案和异步 RL 训练基本上同时出现,也是 AReaL 论文中核心创新方案之一,目前也是基本上支持异步 RL 训练的框架都已经实现,示意图如下。
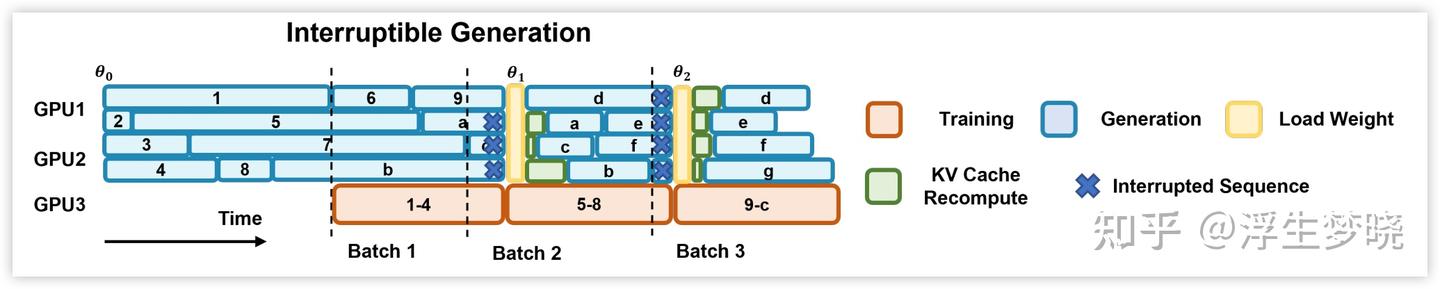
在上图中可以看到,当 rollout 产生 1 个 batch 数据(这里是 4)后训练引擎异步开始训练,当训练引擎完成训练时需要将新的模型权重传递给推理引擎,但这时推理引擎还在进行推理任务,partial rollout 的含义就是对正在 rollout 过程中的任务进行截断,保留已经 rollout 完成的那部分数据,暂停推理引擎的使用,开始从训练 rank 广播新的模型权重给推理 rank 进行模型参数更新,这个过程中训练引擎不受影响继续异步训练。
当推理引擎完成参数更新后继续对之前截断的任务进行 rollout,也就是说这部分任务 rollout 轨迹前部分是旧策略模型生成的,后部分是新策略模型生成的。AReaL 中 input_queue 是进行 rollout 的任务,当被截断时连带已经生成的轨迹放入_pending_inputs 队列的队头位置。
以上是阅读修改RL训练框架代码后获得的一些启发,下面是一些关于RL训练的思考
1、老生常谈的RL算法问题
当前的LLM的RL算法习惯分为两类,序列级奖励算法和token级奖励算法,前者有GRPO、DAPO、REINFORCE等算法,后者有Decoupled PPO、REINFORCE++等。
这里不一一介绍,根本上都是PPO算法的变体。区别就是对整个轨迹每个token相同的奖励值还是不同的奖励值。LLM是以token为动作粒度进行优化的,如果将奖励放在序列维度肯定无法做到精细训练,而放到token粒度又很难,原因在于很难有一个客观合理的奖励方案去对序列里每个token做奖励(反向KL散度的模型蒸馏是一个不错的方案,但教师模型很难获取),token粒度太小了。
实际上我们llm实际执行的动作粒度是多个token组成,具体是由业务环境决定的,所以如果想做到领域RL最优是否也需要在业务场景的动作粒度上进行奖励才好?这一点存疑,等待验证。
另外RL训练是否也需要分阶段训练比较好,比如一开始进行序列级RL训练,先不管中间过程是否摆烂,保证最后结果的正确性。再进行细粒度的RL训练,无论业务动作粒度还是token粒度去调优推理的中间过程?还是直接同时关注序列和每个token奖励更好?同样等待验证。
2、RL奖励和环境
就像karpathy说的,现在RL成功与否的关键在于环境和奖励,环境不说了,就是纯工程优化的问题,奖励的设置是行业研究的热门,主流方案还是llm as judge或者agent as judge,只不过用了很多提示词trick。
比如在提示词中划分出严格的打分维度,让多个闭源模型组成评审团,不让llm或者agent打分而是排序等(又感觉回到了rlhf时代)。但根本上仍无法避免reward hacking的问题,为每个任务设置校验规则又无法scaling。只能靠时间去慢慢磨,慢慢的把数据收集好训练单独奖励模型或者一点点的做校验规则。
最后总结一下这几个RL框架,说实话verl和AReaL代码写的很工程化,但读起来是真费劲,封装太多,上手难度比较高。
相比slime代码很简洁,流程明确,我一开始奔着朱子霖大佬去看到slime,奈何当时slime刚开始适配FSDP,megatron又不支持vl模型,我是vl模型多轮训练的场景,更倾向于异步RL训练,需要尽快实现一个demo,只是粗读了slime代码感觉异步训练这块写的还不是很成熟才跳到verl。
但verl的rollout流程太僵化,不适用于我的环境,因为在环境工具调用前我需要从数据中获取一些状态内容发送给环境来让环境初始化,侵入式修改verl又带来额外工作量,因此又转向AReaL。
AReaL代码是真的难读,一个函数高达5-6次的调用,但不得不佩服代码质量是真的高。
想简单入门的推荐看RL2
https://github.com/ChenmienTan/RL2
代码逻辑简单,很容易理清基本逻辑,值得阅读。