
随着 GenAI 视觉模型(如 Sora 2、Google Nano Banana)的爆炸式发展,其惊人的效果背后是庞大的计算资源消耗。图像和视频模型的推理 FLOPs 甚至远超 LLM,导致部署成本高昂,难以普及。
-oQYg.png)
SANA系列模型作为高效生成式基础模型的前沿探索,通过引入线性注意力(Linear Attention)等创新架构,实现了在不牺牲质量的前提下,极大地提升了处理超长序列和高分辨率生成任务的能力。线性注意力是处理超长序列的关键,它将复杂度从 (O(N^2)) 降低到 (O(N))。
这不仅是一个数学上的优化,更是解锁大语言模型(LLMs)和长视频生成无限上下文长度的关键
SANA
论文:Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer
链接:https://arxiv.org/abs/2410.10629
代码:https://github.com/NVlabs/Sana
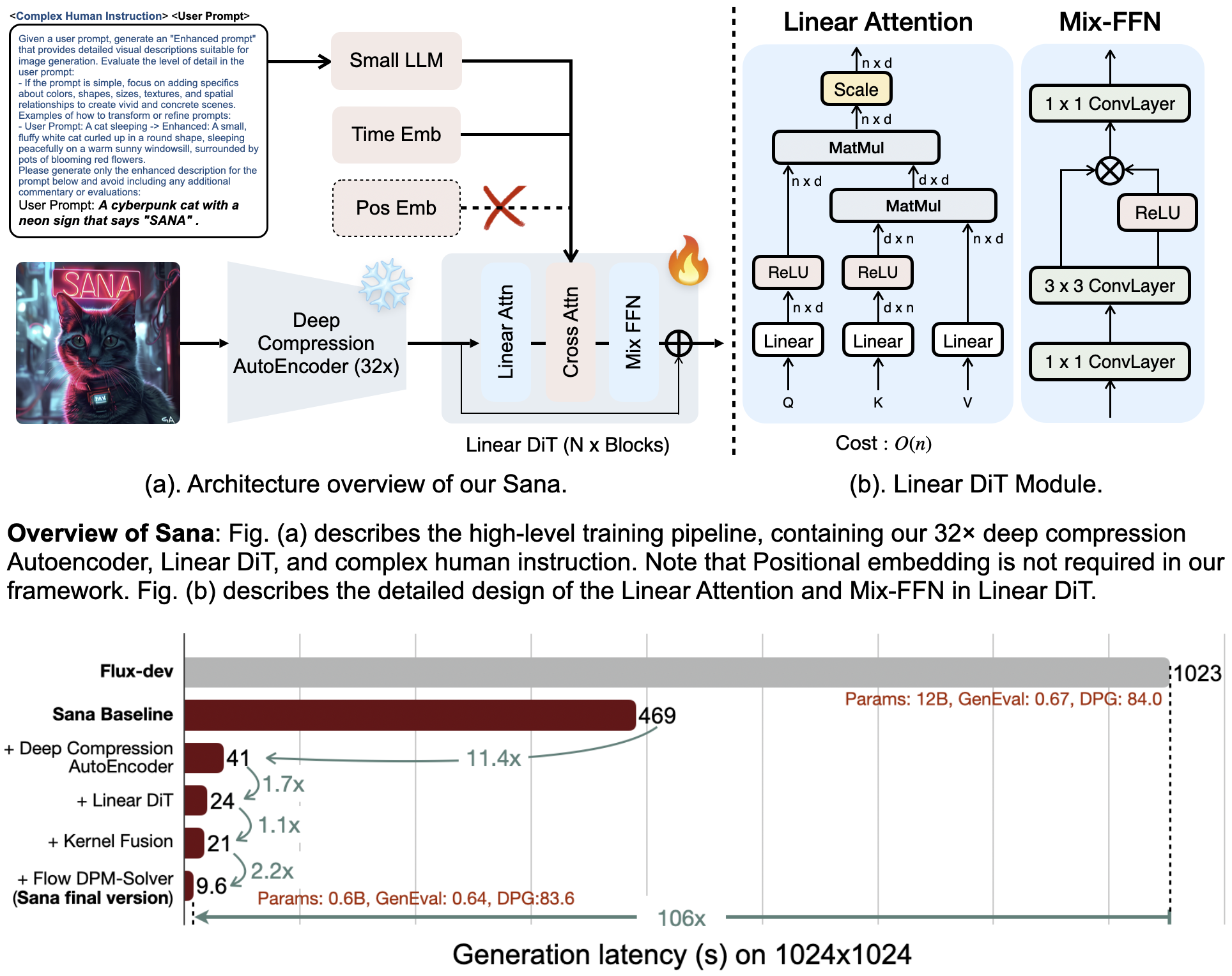
SANA 是文本到图像(T2I)的框架。它的厉害之处在于能高效生成高达 4096 × 4096 的超高分辨率图像。Sana-0.6B 模型尺寸比一些大型扩散模型小 20 倍,但吞吐量却快了 100 多倍。
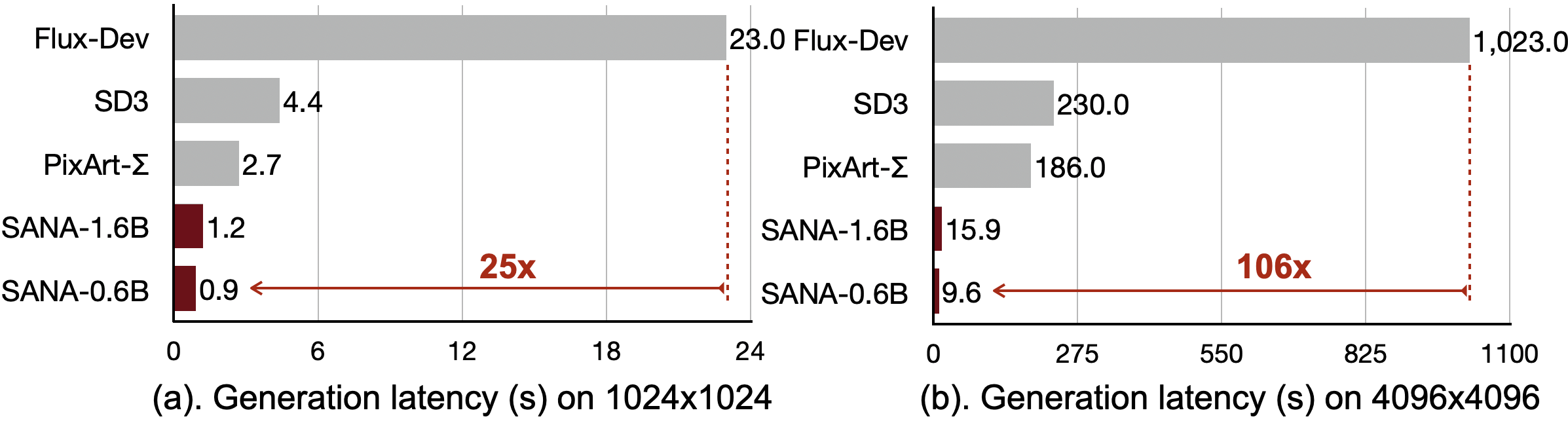
它非常轻量,可以在 16GB 笔记本电脑 GPU 上部署,生成一张 1024 × 1024 的图像不到 1 秒。实现高分辨率靠的是深度压缩自编码器,将图像压缩倍数提高到 32 倍,以及用线性 DiT替换了所有传统注意力机制,。
SANA 1.5
SANA-1.5 是一种面向高效扩展的线性扩散 Transformer(Linear Diffusion Transformer),用于文本到图像生成任务。
论文:SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
链接:https://arxiv.org/abs/2501.18427
在 SANA 的基础上,SANA-1.5 引入了三项关键创新:
第一,高效训练扩展(Efficient Training Scaling):采用深度增长范式(depth-growth paradigm),将模型参数规模从 16 亿(1.6B)平滑扩展至 48 亿(4.8B),同时显著降低计算资源消耗;该方法结合了一种内存高效的 8 位优化器(8-bit optimizer),大幅减少显存占用,提升大规模训练的可行性。
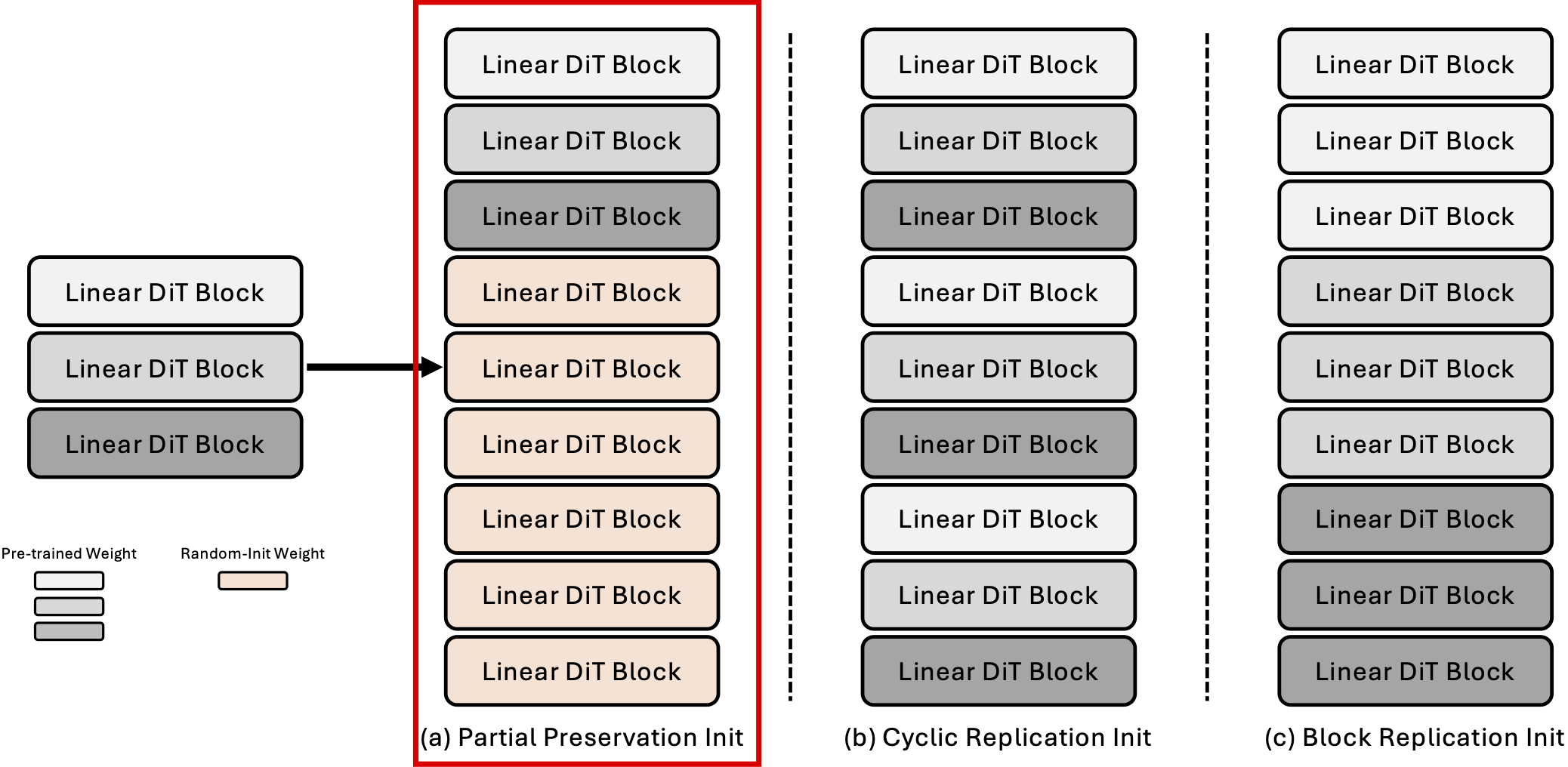
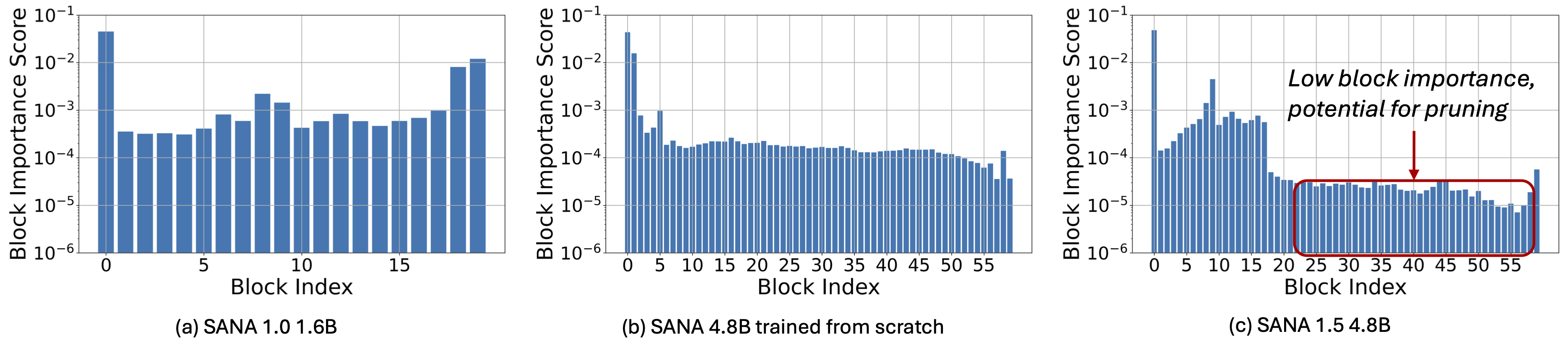
第二,模型深度剪枝(Model Depth Pruning):提出一种基于模块重要性分析(block importance analysis)的技术,可对模型进行高效压缩,支持任意目标尺寸的裁剪,且在压缩后仅需极少量微调即可恢复生成质量,几乎不损失图像保真度。
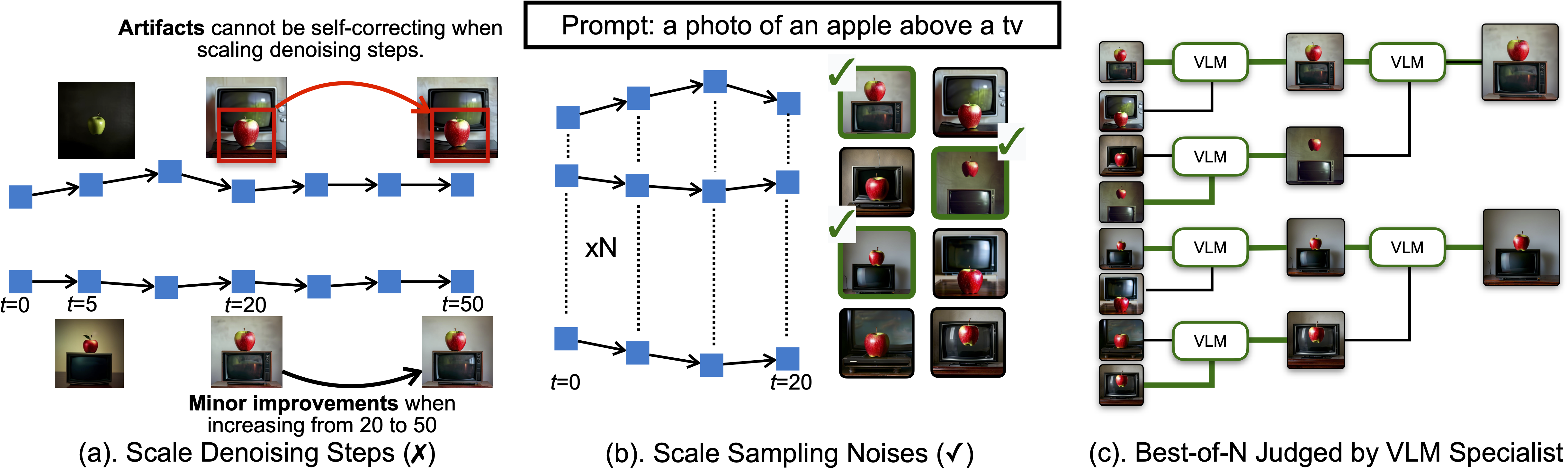
第三,推理时扩展(Inference-time Scaling):通过重复采样策略,在推理阶段以增加计算量为代价换取等效的模型容量提升,使较小规模的模型在实际生成效果上逼近甚至媲美更大模型的表现。
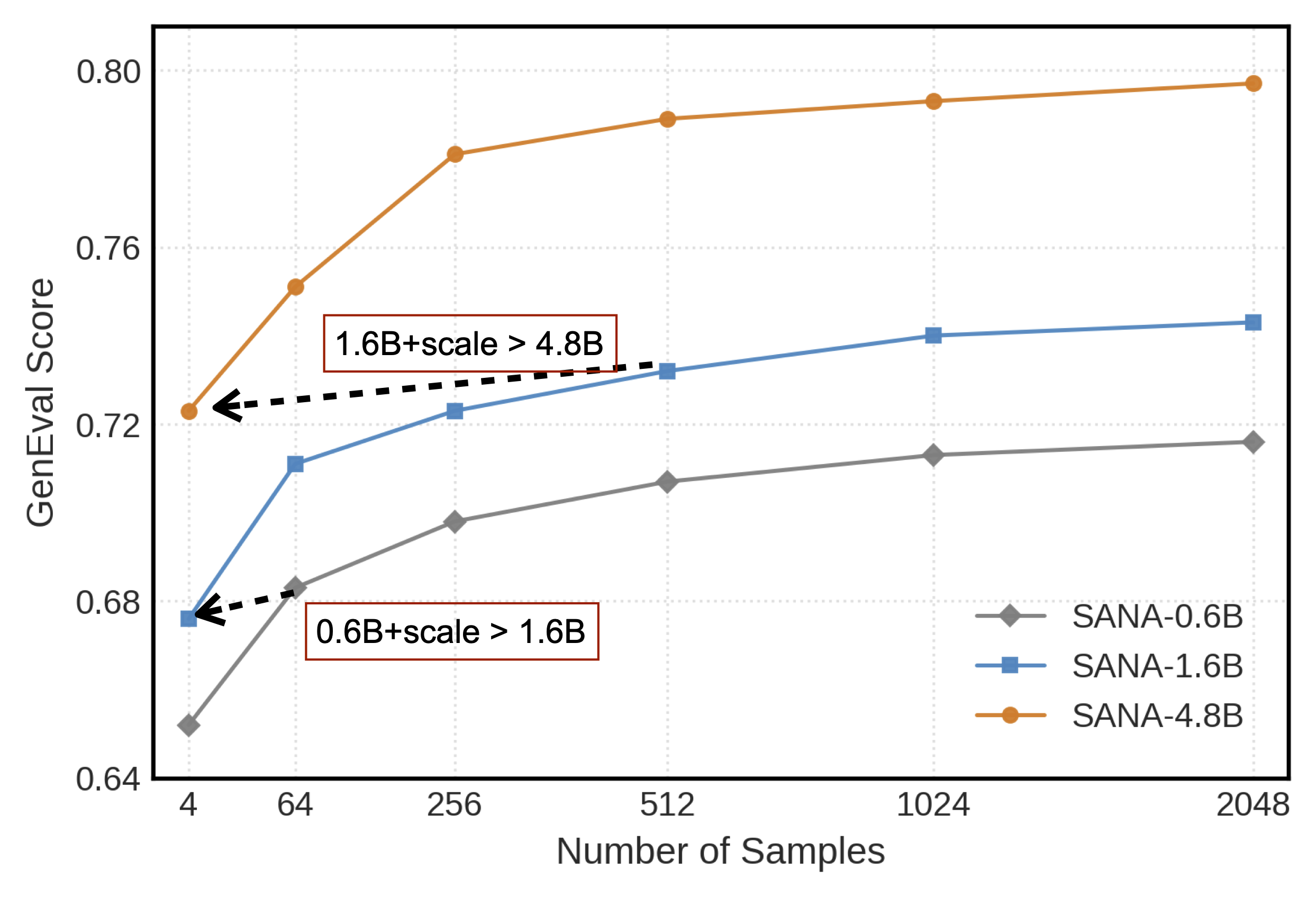
凭借上述策略,SANA-1.5 在 GenEval 基准上取得了 0.81 的文本-图像对齐分数;进一步结合推理时扩展技术,该分数可提升至 0.96,刷新了 GenEval 的当前最佳纪录(SoTA)。这些创新使得模型能够在不同计算预算下灵活缩放,同时保持高质量输出,从而让高性能图像生成技术更加普及和可及。
SANA-Sprint
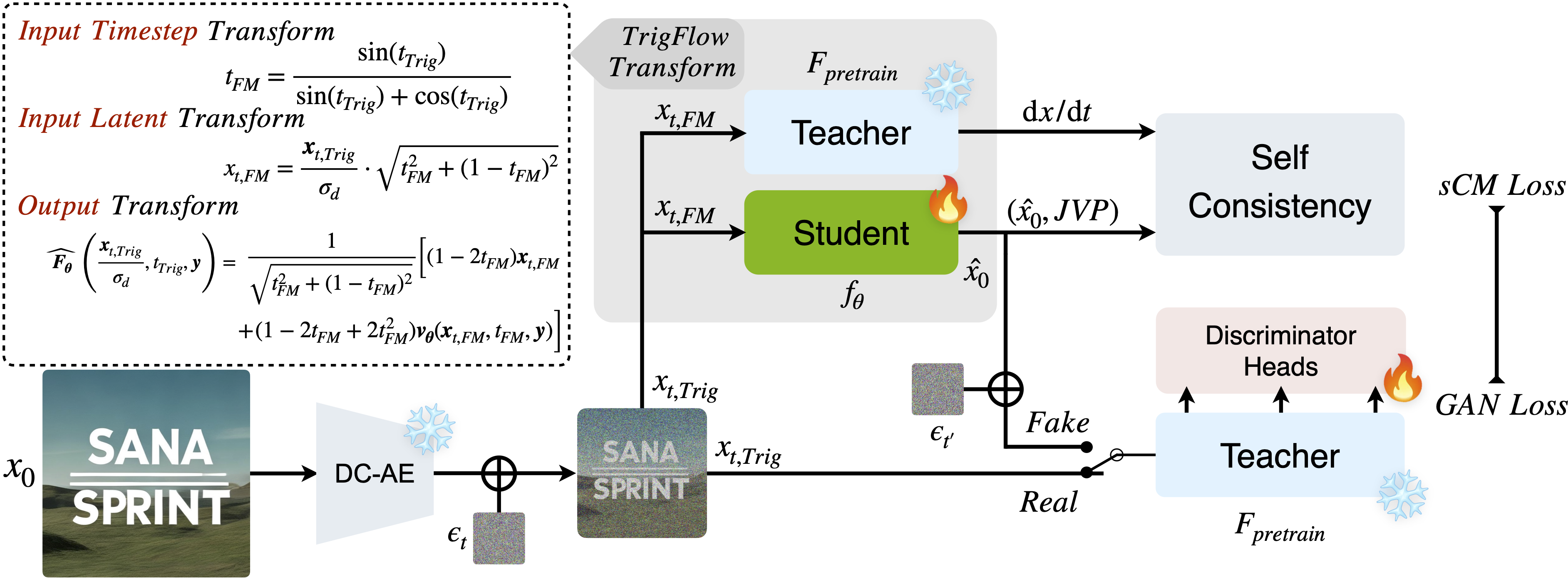
SANA-Sprint 是一种高效的扩散模型,专为超高速文本到图像(Text-to-Image, T2I)生成而设计。该模型基于一个已预训练的基础模型,并通过混合蒸馏技术,将原本需要约 20 步的推理过程大幅压缩至仅需 1 到 4 步,从而在保持高质量图像输出的同时实现毫秒级生成速度。
论文:SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation
链接:https://arxiv.org/abs/2503.09641
SANA-Sprint 的核心贡献包括以下三点:
第一,提出了一种无需额外训练的方法,可直接将预训练的流匹配(flow-matching)模型转化为适用于连续时间一致性蒸馏(sCM)的形式。这一方法避免了从头开始训练一致性模型所带来的高昂计算成本,显著提升了训练效率。
在此基础上,团队进一步引入了混合蒸馏策略:其中 sCM 负责确保学生模型与教师模型在整体分布上保持一致,而潜在对抗蒸馏(Latent Adversarial Distillation, LADD)则专门用于提升单步生成结果的细节保真度和视觉质量。
第二,SANA-Sprint 是一个统一的步数自适应模型。这意味着同一个模型可以在 1 步、2 步、4 步等不同推理配置下均实现高质量图像生成,而无需为每种步数单独训练专用模型。这种设计不仅简化了部署流程,也提高了模型在不同硬件和应用场景下的灵活性与实用性。
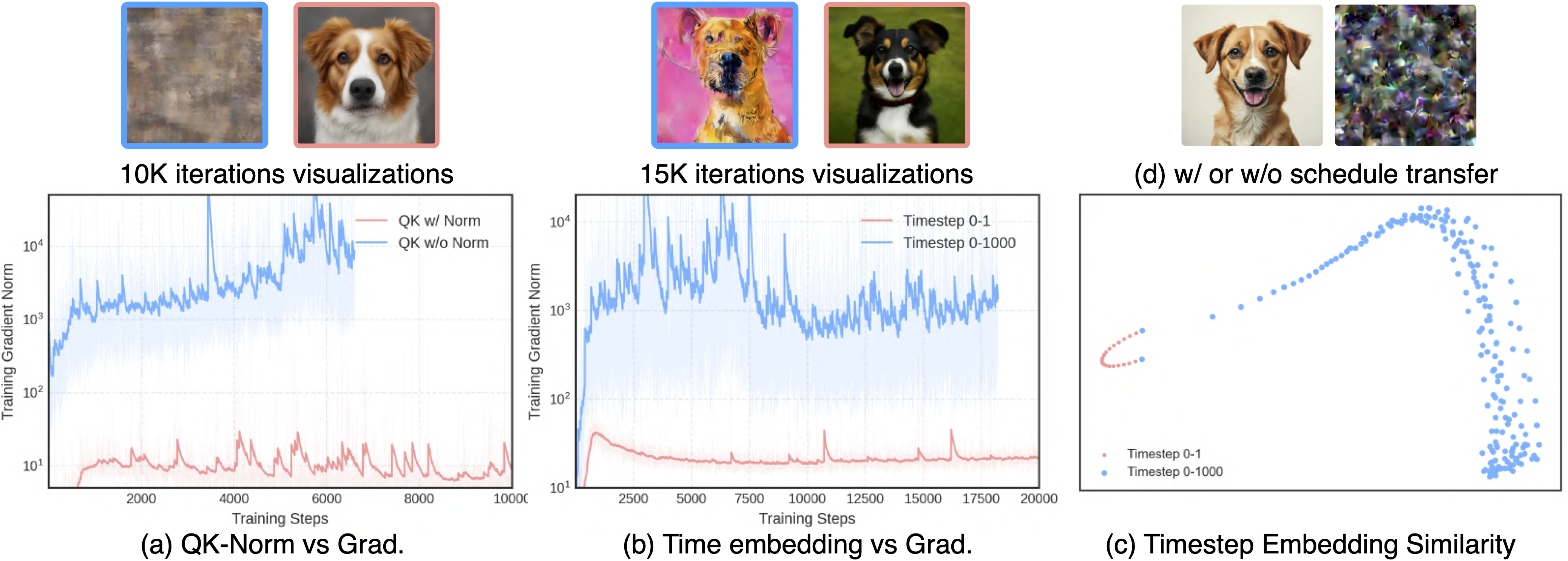
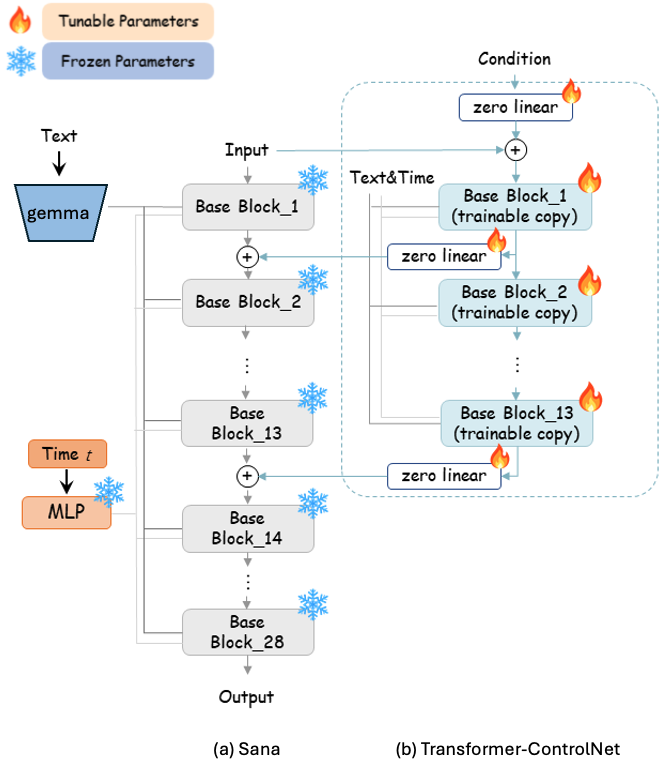
第三,SANA-Sprint 成功集成了 ControlNet,支持实时交互式图像生成。用户可通过边缘图、姿态图、深度图等条件对生成过程进行精细控制,并在极短时间内获得反馈。在 NVIDIA H100 上,ControlNet 模式的生成延迟仅为 0.25 秒,充分满足了设计、创作等需要即时响应的交互场景需求。

在性能方面,SANA-Sprint 在仅使用 1 步推理的情况下,取得了 7.59 的 FID 分数和 0.74 的 GenEval 分数,优于当前最快的 FLUX-schnell 模型(FID 7.94,GenEval 0.71)。
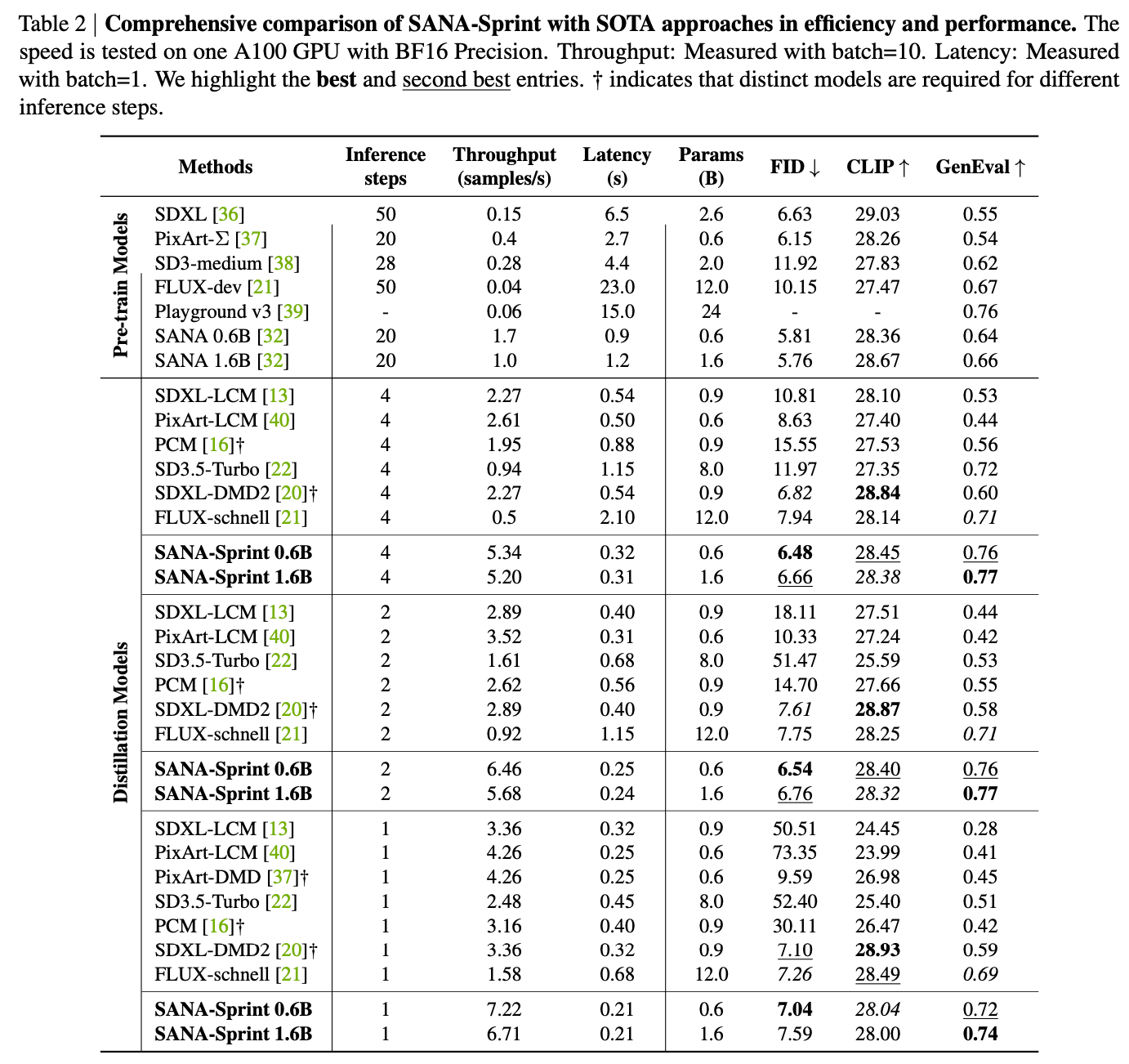
更重要的是,SANA-Sprint 在 H100 上生成一张 1024×1024 图像仅需 0.1 秒,比 FLUX-schnell 快约 10 倍(后者需 1.1 秒)。在消费级显卡 RTX 4090 上,SANA-Sprint 的文生图延迟也仅为 0.31 秒,展现出其在 AI PC(AIPC)等终端设备上的强大应用潜力。
SANA-Video
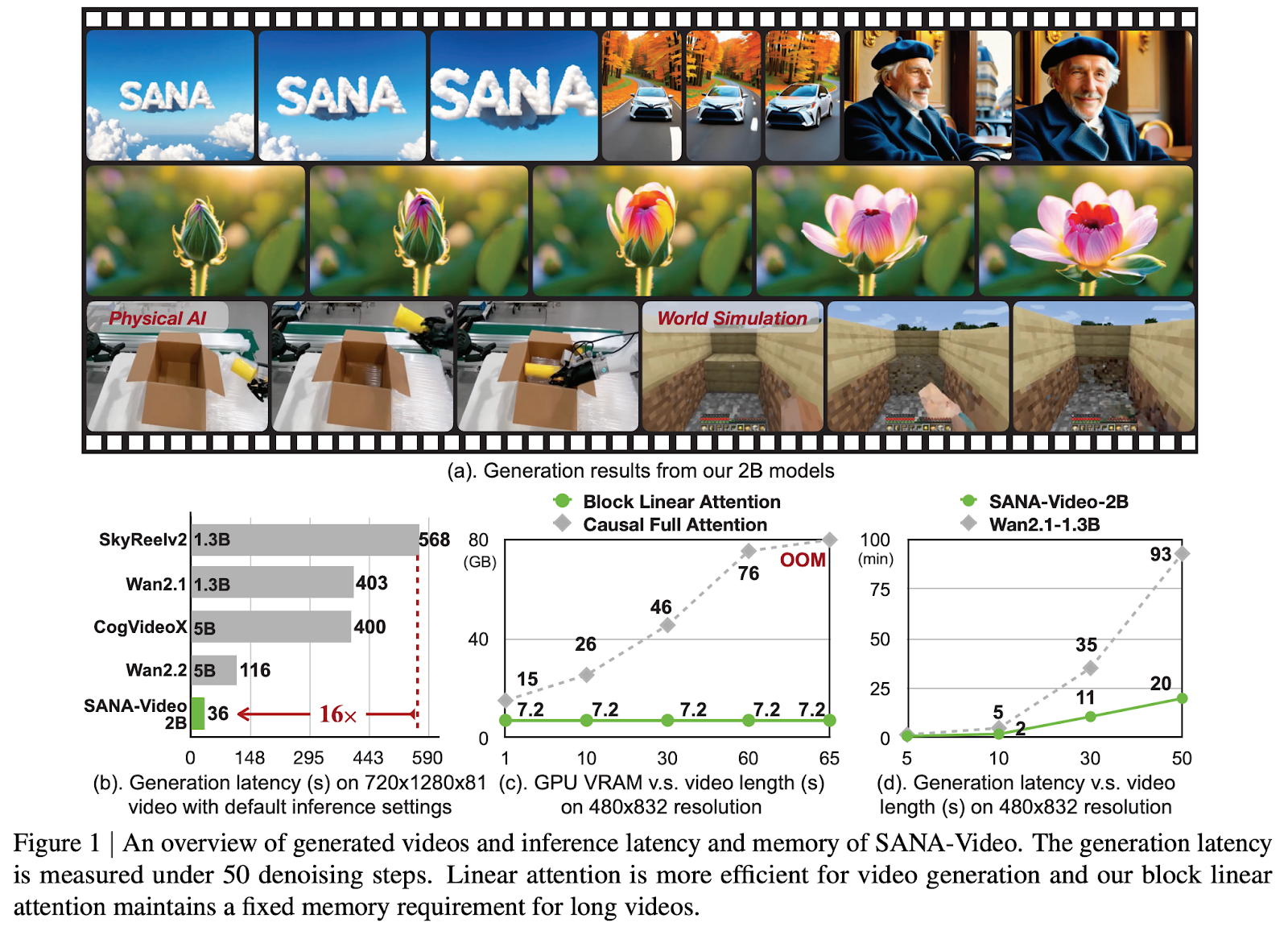
SANA-Video,一种轻量级扩散模型,能够高效生成分辨率达 720×1280、时长可达一分钟的高质量视频。SANA-Video 在保持强文本-视频对齐能力的同时,以极快的速度合成高分辨率、长时长视频,并可在 RTX 5090 GPU 上部署。
论文:SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer
链接:https://arxiv.org/pdf/2509.24695
SANA-Video 的高效性与长视频生成能力源于两项核心设计:
第一,线性 DiT(Linear DiT):我们采用线性注意力作为模型的核心运算单元。相较于传统自注意力机制,线性注意力在处理视频生成中海量 token 时具有显著更高的计算效率。
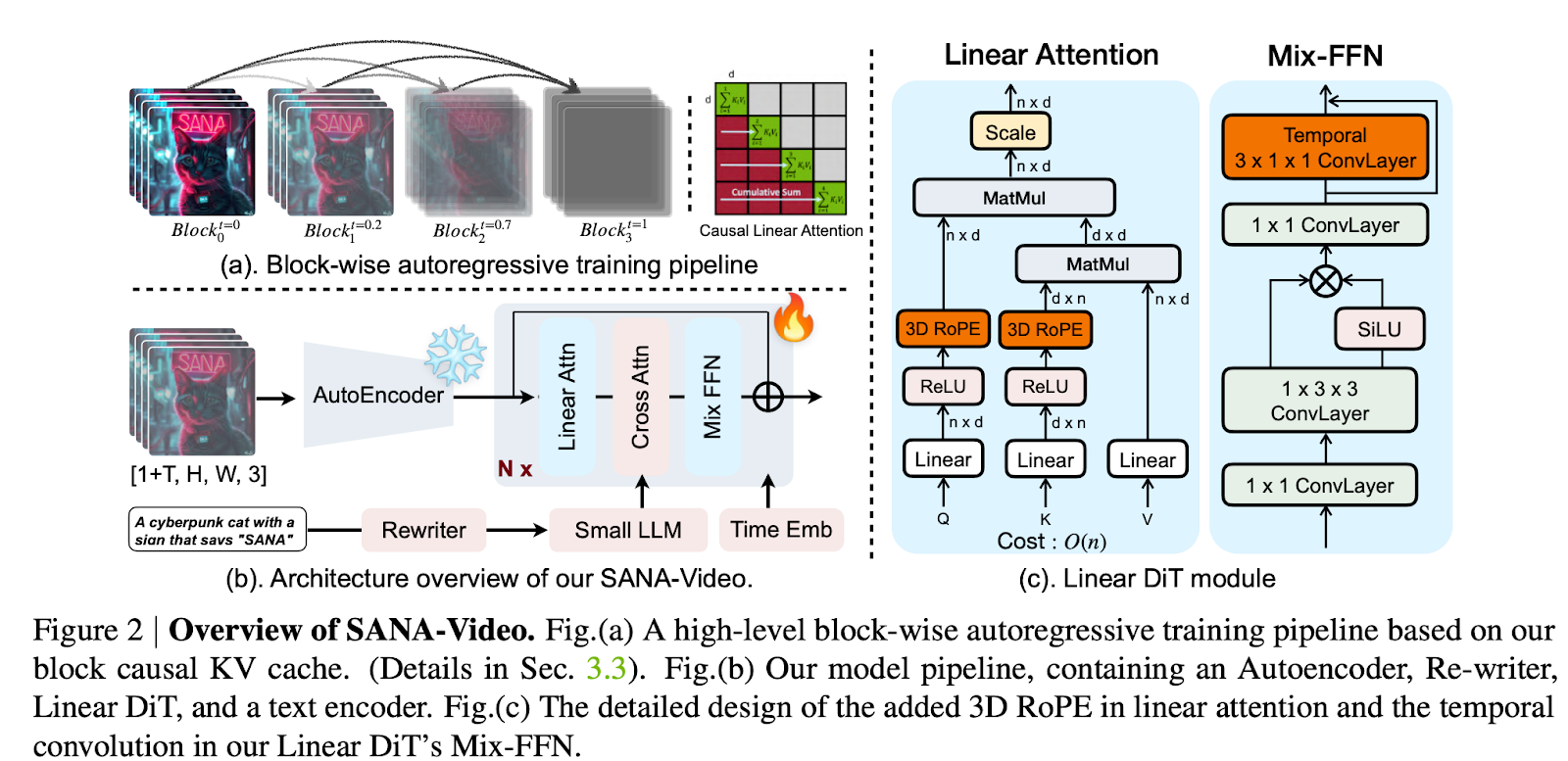
第二,面向块线性注意力的恒定内存 KV 缓存(Constant-Memory KV Cache):设计了一种基于块的自回归生成方法,利用线性注意力的累积特性构建一个恒定内存占用的状态缓存。该 KV 缓存使 Linear DiT 能够在固定内存开销下获取全局上下文信息,无需传统 KV 缓存,从而高效支持分钟级长视频生成。
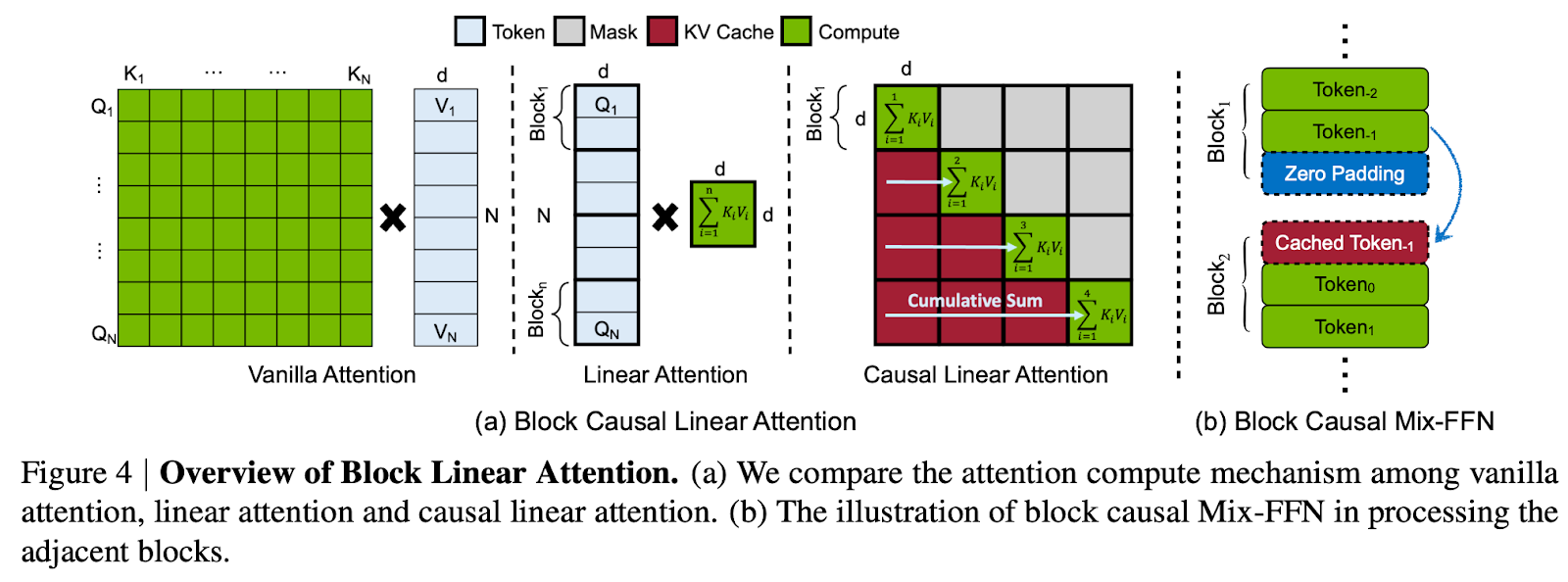
此外,还探索了有效的数据过滤策略与模型训练方案,将整体训练成本压缩至仅需 64 块 H100 GPU 训练 12 天,约为 MovieGen 训练成本的 1%。得益于这一极低的训练开销,SANA-Video 在性能上已可与当前先进的小型扩散视频模型(如 Wan 2.1-1.3B 和 SkyReel-V2-1.3B)相媲美,同时实测推理延迟降低 16 倍。
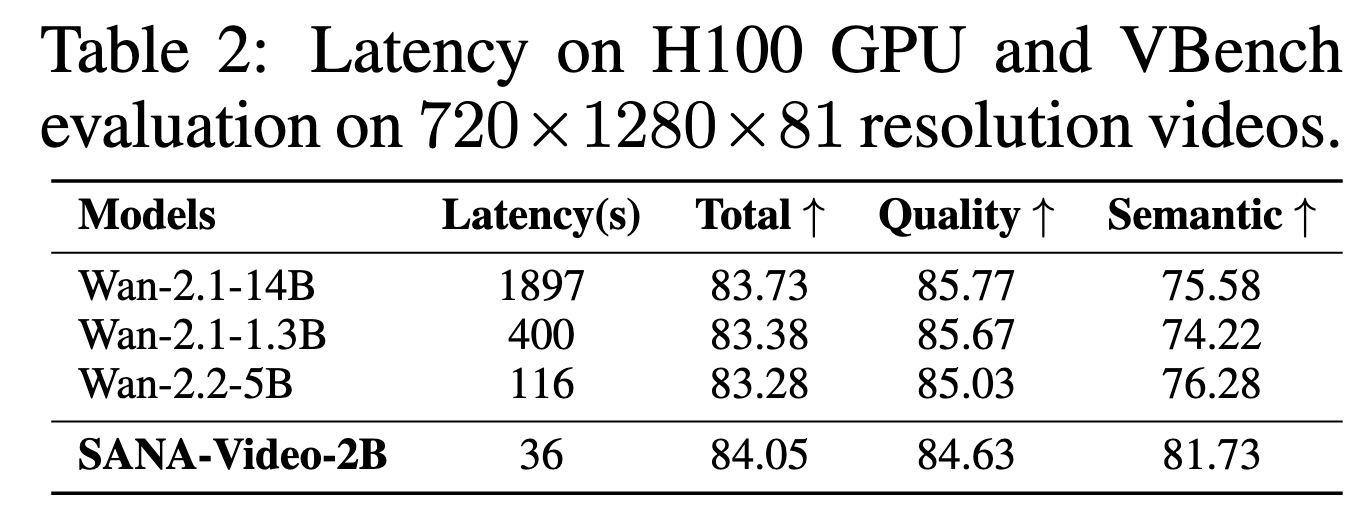
在推理端,SANA-Video 支持在 RTX 5090 GPU 上使用 NVFP4 精度运行,将生成一段 5 秒 720p 视频的时间从 71 秒缩短至 29 秒,实现 2.4 倍的加速。

12月16日(周二)晚8点,青稞Talk 第98期,香港大学MMLab博士生陈俊松,将直播分享《SANA-Series:探索图像视频扩散模型的高效设计与加速》。
本次分享将聚焦于这一核心挑战,系统介绍四大前沿加速方向,包括DiT架构、VAE、步数蒸馏和 Block Diffusion,并深入展示在高效图像生成 SANA(ICLR 2025 Oral Presentation)、SANA 1.5、SANA-Sprint和长视频生成(SANA-Video, LongSANA)方面的一系列创新工作,为视觉生成模型的普及化提供可行方案。
分享嘉宾
陈俊松,香港大学MMLab博士生,导师为罗平老师。在英伟达研究院实习,由谢恩泽博士与韩松老师指导。研究方向为图像视频高效生成,共发表高水平学术论文十余篇,一作发表包括ICML,ICLR,ICCV,CVPR等业内顶级会议,开源项目GitHub获stars 10k+,谷歌学术引用2000+次,获得国家奖学金,KAUST AI新星等荣誉。
主题提纲
SANA-Series:探索图像视频扩散模型的高效设计与加速
1、视觉生成模型的计算瓶颈,及其四大加速方向
2、高效图像生成:SANA & SANA-Sprint
- 高倍压缩、Linear Attention DiT与步数蒸馏
3、SANA-Video:AR 与 Diffusion 结合生成长视频
4、AMA (Ask Me Anything)环节
直播时间
12月16日(周二)20:00 - 21:00