完整PPT下载:【https://t.zsxq.com/gXFFx】
在往期 Talk 分享中,RLinf 团队的林灏、臧宏之分别为大家讲解了 RLinf 的系统设计以及 RLinf VLA 的实践。本期 Talk 我们继续和 RLinf 团队、北京大学博士生陈康一起聊一聊面向流匹配 VLA 的强化学习后训练框架 π_{RL}。时间也差不多了,接下来就把直播间交给陈康博士,正式开始我们今天的分享。

大家上午好!很荣幸能在这里分享我们最近关于 \pi_{RL} ——一个面向流匹配 VLA 的强化学习后训练框架的工作。我是北京大学的在读直博生,研究方向是面向 VLA 的强化学习训练。
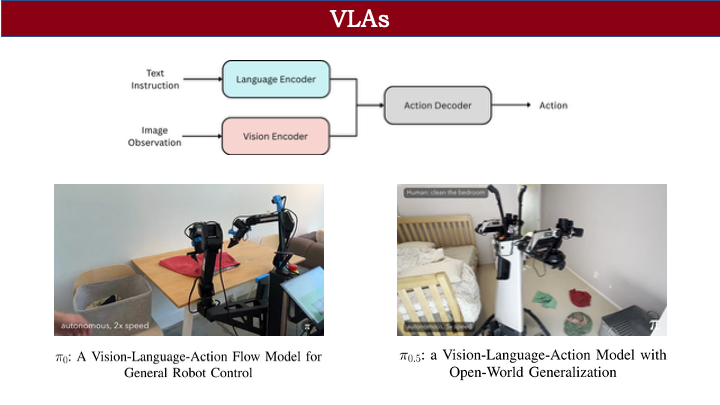
首先,目前大家对 VLA 的定义是:它是一类能够根据视觉和语言信息输出动作的模型。例如之前的 π-0 和 π-0.5 就属于这一类。VLA 在泛化性和长程任务上已经取得了不错的能力。它通过三个相机的设定,结合一段文本指令(比如 “clean the bedroom”),能够完成一系列子任务。
在讲 VLA 的训练之前,我们可以先回顾一下大语言模型时代的训练流程。在大语言模型阶段,通常涉及几个阶段:

第一个阶段是预训练,我们会将完整句子进行掩码处理,例如挖掉其中一个词,让模型预测下一个词,从而训练其基本的文本补全能力。
第二个阶段是指令微调(SFT),我们会提供特定的指令文本,使模型能够输出用户期望的回答——就像我们在使用 GPT 或 GLM 时,它们能进行问答一样。在此之后,还有像 GPT 提出的基于人类反馈的强化学习(RLHF)对齐技术。这类方法主要基于强化学习:给定一个问题,模型生成两个回答,人工选择其中更好的一个;通过强化学习,模型就能逐步对齐人类偏好。
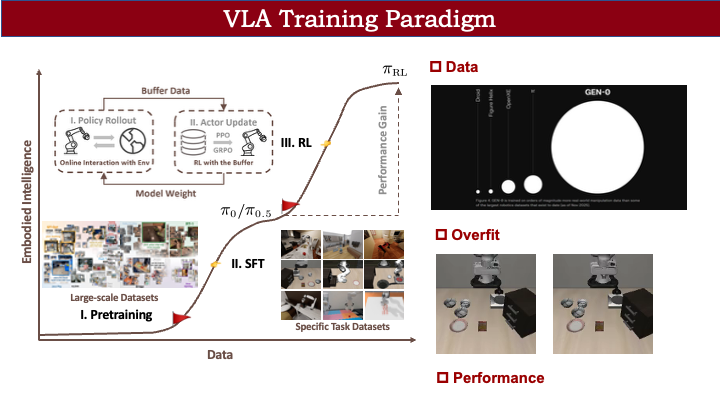
VLA 的训练流程其实也比较类似。在 VLA 中,我们首先会在大型数据集上进行预训练。这些数据集通常是跨本体的,包含不同机器人本体(如单臂、双臂)、不同场景和相机视角,用于学习图像、文本到动作的基本映射。但由于不同本体之间差异较大,预训练得到的 VLA 很难直接部署到我们自己的机械臂上。因此,我们同样需要经过一个 SFT 阶段:通过遥操作等方式,在特定场景(如 Libero benchmark)收集专家轨迹数据,并进行微调。
然而,这个过程存在一些问题。
第一个是数据成本问题。例如,Google 的 RT-2-X 工作所收集的数据量是当前开源社区数据集 Open X-Embodiment 的很多倍。如果依赖大规模数据收集,对我们而言成本非常高。即使在真机或仿真环境中,通常也需要收集几十甚至上百条轨迹才能取得较好效果,而每次迭代数据收集都相当耗时。
第二个问题是过拟合。什么是过拟合?例如,我们在 LIBERO上训练 π-0 时,左边展示的是训练中表现良好的结果。但如果我们把 π-0 的初始夹爪状态从“打开”改为“闭合”(如右图所示),模型就无法完成将碗放上去的动作,出现一种诡异的现象。这是因为专家数据中从未包含“夹爪初始闭合”的状态。当遇到这类 OOD(分布外)场景时,模型就不知道如何执行动作,说明当前 VLA 普遍存在过拟合问题。
第三个是性能上限问题。SFT 的性能受限于专家轨迹的质量。如果专家轨迹质量差,即使使用再强大的 VLA 模型,也无法训练出高性能策略。这是一个根本性的瓶颈。
我们的目标是通过在线学习的方式(如 PPO、GRPO),让模型与环境交互。环境可以反馈“什么样的动作更好”,模型便能在交互过程中自动学习更优的策略参数。这就是 VLA+RL 在 VLA 训练中的作用。
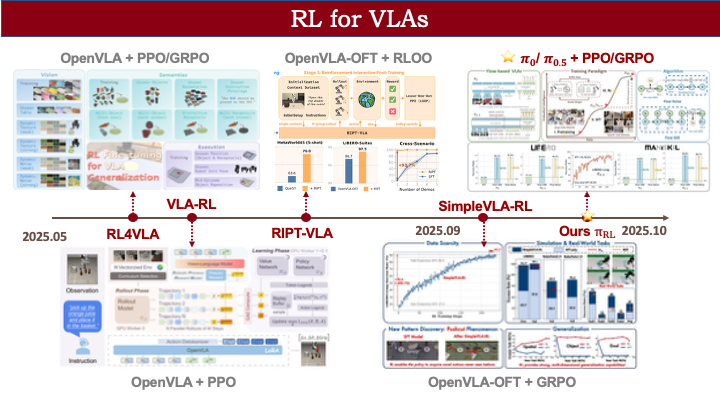
此前,在 2025 年 5 月前后,已有大量 VLA 的 RL 工作涌现,例如 OpenVLA 的 RL 方法。但这些工作基本局限于 OpenVLA 和 OpenVLA-OFT 等模型,并未应用于 π-0 和 π-0.5 这类基于流匹配(flow matching)的 VLA 框架。我们这项工作(于 2025 年 10 月推出)主要解决的问题就是:为基于流匹配的 VLA 设计一套可行的强化学习训练范式。
在介绍我们的 RL for VLA 方法前,先回顾一下强化学习的标准建模过程。
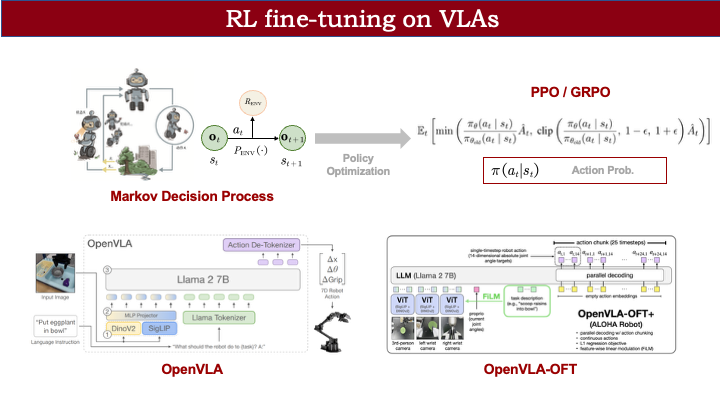
通常,我们会将策略与环境的交互建模为一个马尔可夫决策过程(MDP)。以右边的机器人为例:假设我们希望它抓住一只蝴蝶。在当前观测状态 O\_t 下,我们希望它执行一个动作(比如向前走一步去抓蝴蝶)。执行后,环境根据转移方程计算下一时刻的状态(可能成功抓到蝴蝶),并给予奖励(比如“你真棒!”)。通过这样的奖励信号,模型在后续训练中会优化策略,从而更快更好地完成任务。
在策略优化过程中(如 PPO、GRPO),一个核心要求是:要更新模型梯度,必须能计算模型输出动作的对数似然概率 \log p(a|s)。如果无法显式计算该概率,就无法将奖励信息通过梯度传导到 VLA 中。
对于 OpenVLA 这类基于 LLaMA 修改的模型,由于最后使用 softmax 选择 token,自然能得到每个 token 的输出概率。
而对于输出连续动作的模型(如 OpenVLA-OFT),通常有两种处理方式:
一是引入噪声头,让模型拟合高斯分布,从而获得动作概率;
二是不将 MLP 输出映射为连续值,而是沿用 OpenVLA 的分词形式,仅利用 OpenVLA-OFT 的并行加速策略,避免直接计算连续动作概率。
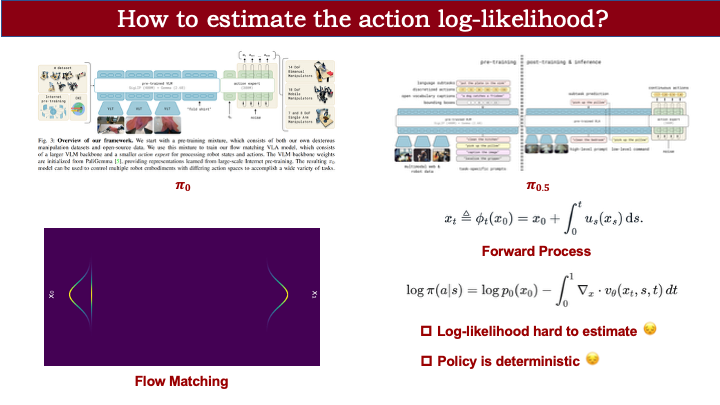
但对于 π-0 和 π-0.5 这类基于 flow matching 的连续动作 VLA,情况更复杂。我们先回顾 flow matching 的概念:它能从一个可采样的分布(如高斯分布)出发,通过一个流场将其映射为目标分布。此过程需要对采样变量进行前向计算,并对速度场积分。
已有理论表明,我们可以根据 X\_0 的分布推导出 X\_1 的动作输出分布。但这一过程需要在每个时间步计算流场的散度。当动作维度较高时,散度计算代价极大,导致对数似然难以估计——这与 OFT 或 OpenVLA 的情况不同。
这是第一个问题。第二个问题是:flow matching 本身是基于 ODE 采样的策略,其随机性仅来源于初始注入的噪声,整个流场计算过程是确定性的。这不利于强化学习所需的探索行为。
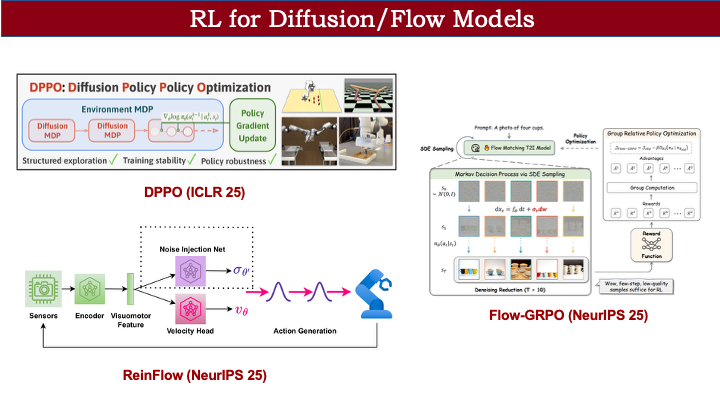
事实上,在 VLA 之外,diffusion 和 flow models 领域已有相关工作尝试解决这些问题。例如 DPPO 解决 diffusion policy 的 RL 问题,RaeinFlow 处理 flow policy 的 RL 问题,Flow-TRPO 则在文生图领域实现了 TRPO 训练。我们的工作主要是在此基础上,将方法扩展到更大规模的 flow-based VLA,以处理包含数千种组合的复杂任务。
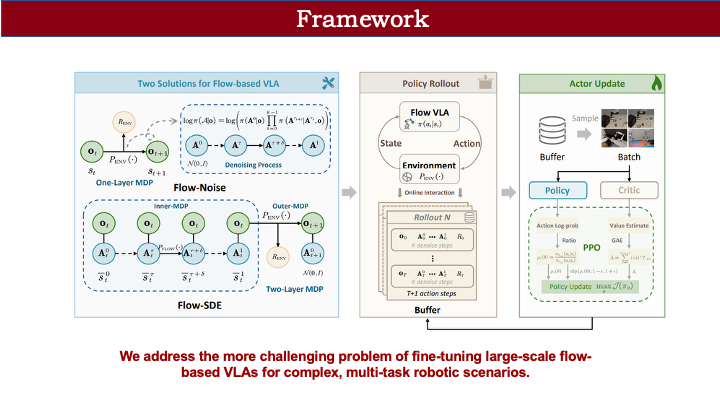
为此,我们提出了两种方案:Flow Noise 和 Flow SDE。整体框架与标准 RL 类似:先对策略进行 rollout 采样轨迹,获得奖励后,从中采样数据,再用 PPO 等算法进行优化。框架本身较为简洁。
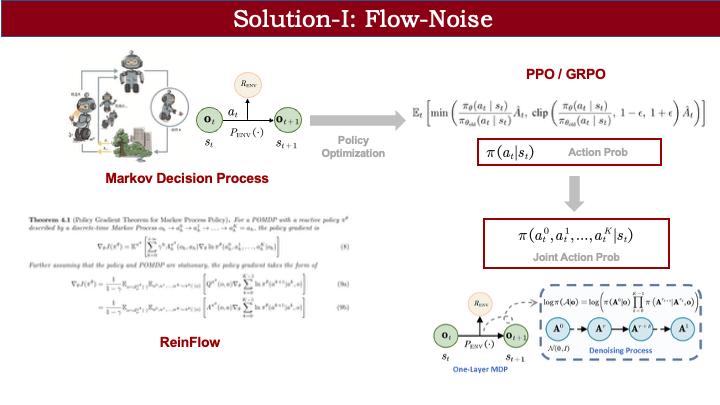
首先介绍 Flow Noise。如前所述,若要用 RL 优化 MDP,必须能计算输出动作的概率。ReinFlow 论文提供了一个思路:虽然 flow matching 模型难以计算边缘动作分布,但可通过联合动作分布来近似替代。我们直接采用了这一理论推导。
有了联合分布后,我们可以将其拆解为条件概率链。例如,从 0 时刻到 K 时刻(对应连续时间步 1),整个去噪链可表示为:先计算初始噪声 A\_0 的采样概率,再依次计算相邻两步间的转移概率。这类似于 diffusion 中通过重参数化计算每步转移概率的方式。通过逐步累积,我们就能得到从 A\_0 到 A\_1 的完整联合概率。
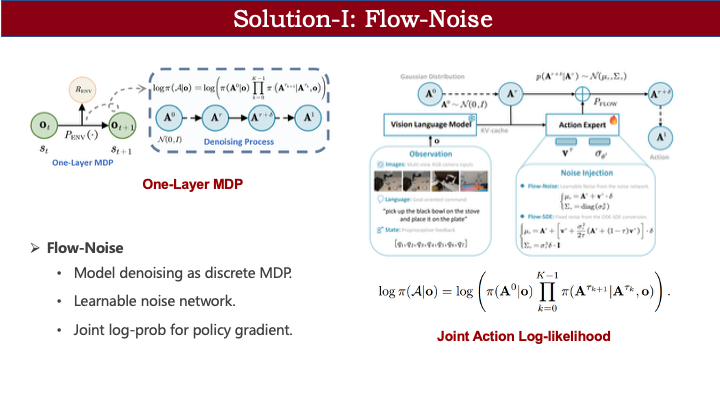
但这里仍存在问题:策略本质上是确定性的,无法直接计算从 t 到 t+\Delta t 的状态转移概率。为此,我们引入连续动作 RL 中的常见做法:将输出动作建模为高斯分布。不同之处在于,我们将这一建模应用于 flow matching 的每一步状态转移。以 t 到 t+\Delta t 为例,模型不仅预测速度场 V,还输出一个可学习的方差。由此,动作被建模为高斯分布,相邻步之间的转移概率即可计算。这就是 Flow Noise 的核心思想:将过程构建为单层 MDP,引入可学习噪声,并利用联合概率密度进行近似策略梯度优化。
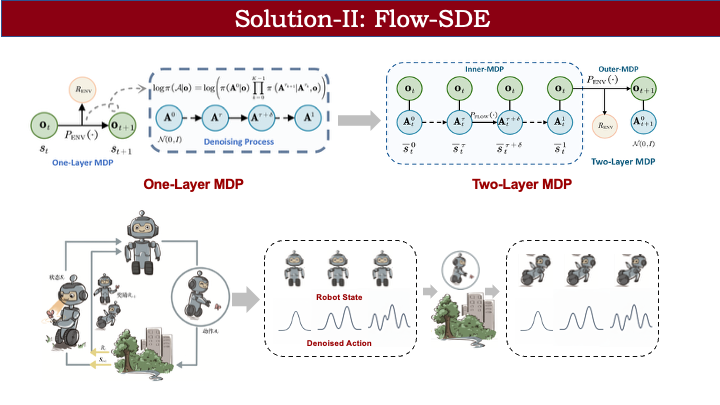
该方案主要基于 ReinFlow 的工作。我们还提出了第二种方案:Flow SDE,它将问题建模为双层马尔可夫决策过程。此前的方法将去噪过程视为动作生成内部的单层 MDP;而 Flow SDE 则将动作生成与环境交互耦合起来。
具体来说,我们将环境观测值与去噪过程中的动作状态共同视为一个统一的 MDP 状态,从而构建双层框架。以内层 MDP 表示固定观测下的动作生成过程,外层 MDP 表示执行动作后的环境状态转移。
以机器人追蝴蝶为例:在双层 MDP 中,状态包含机器人自身状态和动作生成过程中的中间状态。flow policy 将高斯分布映射为目标动作分布,我们将这一生成过程与环境交互耦合。由于动作生成期间观测不变,可视为内层 MDP;生成完成后,动作与环境交互,机器人状态发生转移(如未抓到蝴蝶则摔倒),同时需重新从高斯分布采样,动作状态也随之更新。这样,原本的单层 MDP 被解耦为双层结构。
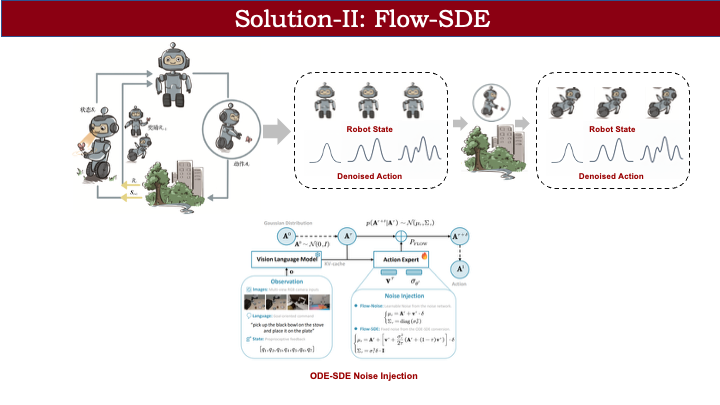
这种双层建模的好处在于:我们无需计算 flow matching 输出的边缘动作分布,只需计算 flow policy 从第 0 步到第 1 步的转移概率——这比从高斯分布直接映射到最终动作的边缘分布更容易建模。在 Flow SDE 中,我们借鉴了 Flow-GRPO 的框架,通过 ODE 到 SDE 的数学等价转换引入噪声,无需额外设计噪声网络或估计方差。具体推导可参考 Flow-GRPO 论文。
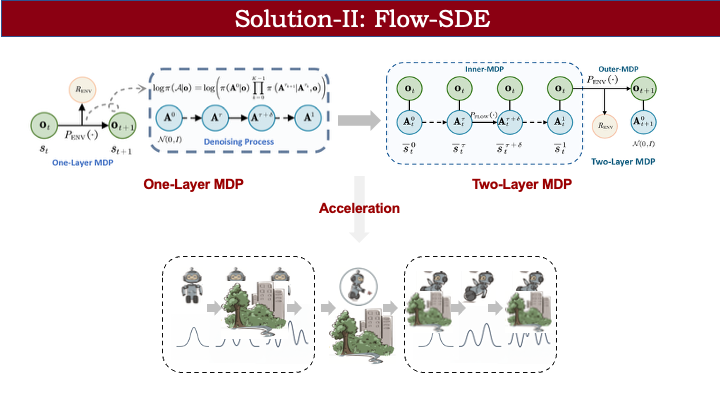
此外,无论是单层还是双层 MDP,都面临一个效率问题:像 OpenVLA 或 OFT 这类模型输出动作是一次性的,buffer 中存储的数据较少;而 flow policy 因包含迭代去噪过程,buffer 规模更大。如何在保持性能的同时提升速度?
我们借鉴了文生图领域的思想:并非每一步都需要去噪。例如,将后两步视为确定性策略,等同于环境交互过程,忽略其状态转移。若选定第 2 步作为噪声注入步,则前后步骤也可视为确定性过程。这样一来,buffer 中只需保存一个关键去噪步的数据,大幅加速训练。
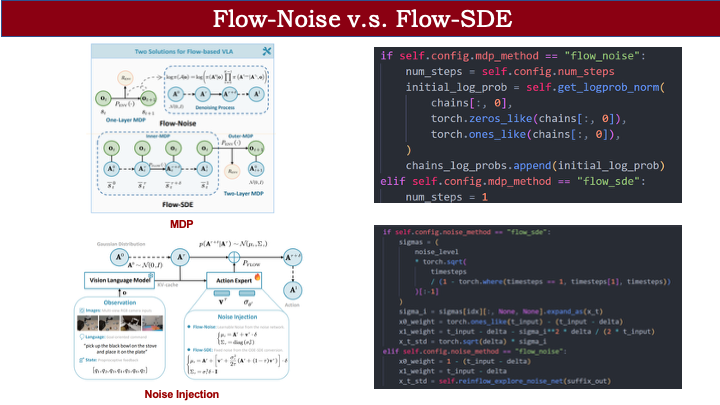
总结一下两个方案:虽然听起来复杂,但代码实现差异不大。
- Flow Noise:需计算完整去噪链的联合概率,包括初始高斯采样概率和每步转移概率。
- Flow SDE:采用跳步加速,仅需保存一个去噪时间步的数据。
在噪声注入方面:
- Flow SDE 通过数学推导直接转化为含噪声形式;
- Flow Noise 则额外引入名为 ReinFlow-explore noise net 的网络,以维持探索性。
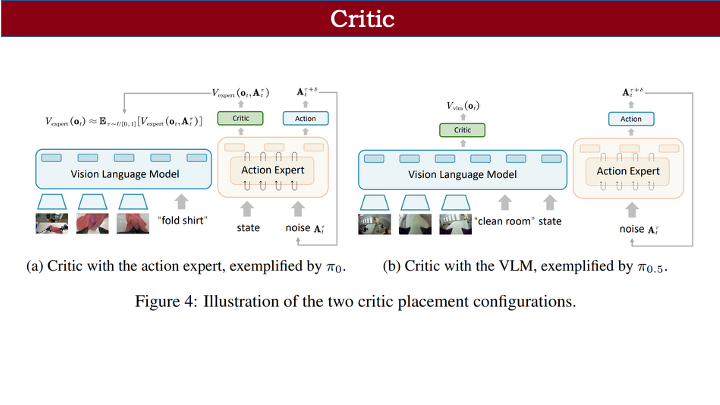
我们同时支持 PPO 和 GRPO 两种策略优化算法。GRPO 是 critic-free 的,无需设计价值函数;而 PPO 需要通过 value 估计动作价值。
我们采用共享式价值头设计:在 action decoder 基础上接一个轻量 critic。由于 π-0 和 π-0.5 架构不同,critic 设计也有所区别:
- π-0.5 将 state 信息融入 VLM,因此 critic 可直接接在 VLM 后,设计较简单;
- π-0 则将 state 与动作信息一同输入 action decoder 进行去噪。若将 critic 接在 VLM 前,会丢失 state 信息,因此我们将其接在 action decoder 后。
但这又带来新问题:critic 输入会包含噪声动作,而价值估计不应依赖具体动作。我们的解决方案是对噪声动作在整个时间步上求期望(即平均),以尽可能消除噪声影响,获得更平稳的价值估计。
熟悉该领域的听众可能知道,π-0.6 也设计了 critic,但它使用了一个独立的 700MB VLM 进行训练。相比之下,我们的 critic 仅为一个几 MB 的投影层,参数量极小,却能达到不错效果。

前面主要是理论部分,现在进入实验环节。我们在 LIBERO、ManiSkill、Metaworld 和 CALVIN等 benchmark 上进行了全面测试,并正在支持更多框架。
实验主要围绕三个问题展开:
- RL 是否真能提升模型性能?(SFT 性能受专家数据上限限制)
- RL 能否减少对数据的依赖?(SFT 需大量高质量轨迹)
- RL 能否缓解过拟合问题?(SFT 轨迹过于集中)
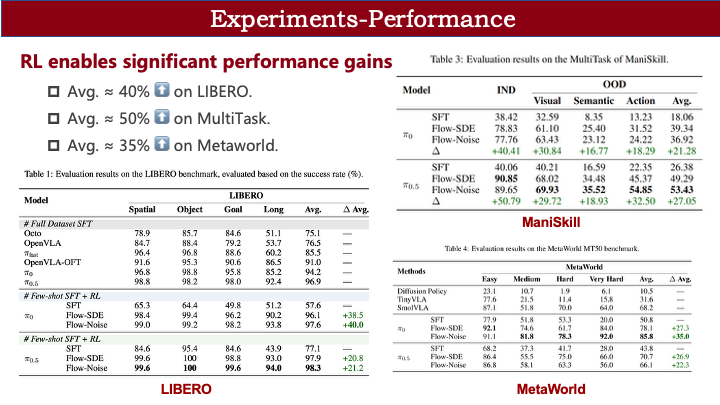
首先是性能提升。在多个 benchmark 上,我们都观察到显著增益:
- LIBERO(简单任务):成功率接近 100%;
- ManiSkill(自建组合任务,含光照、物体类别、机械臂初始位姿变化):依然有明显提升;
- Metaworld(50 类任务):最高达 85% 成功率。
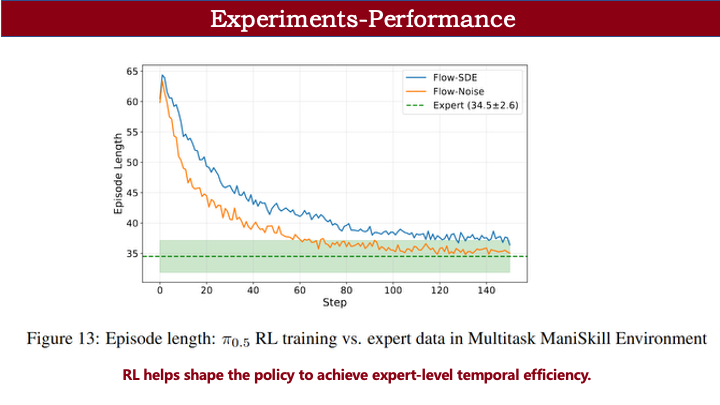
除成功率外,我们还关注执行效率。在 LIBERO 上,SFT 阶段完成任务的平均轨迹长度为 62;而在 RL 训练过程中,该长度持续下降,最终趋近于设定目标,说明 RL 能有效提升执行效率。
可视化对比也显示:SFT 阶段模型常因 OOD 场景(如未见过的物体位置)而抓取失败;RL 后,抓取基本一次成功,成功率大幅提升。
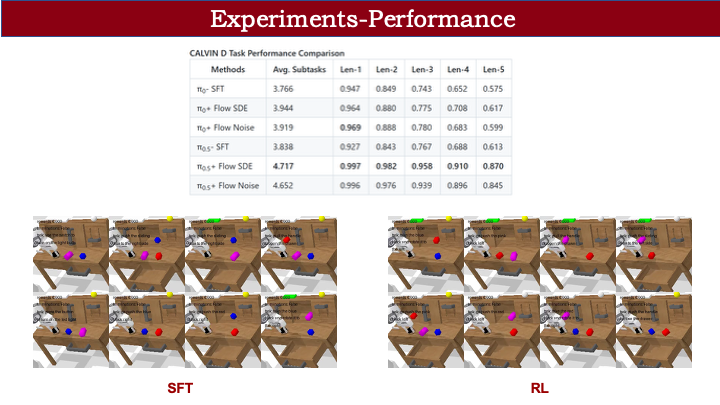
在 CALVIN 长程任务上,SFT 容易因某个子任务失败而卡住(如左下角方块无法推到右侧);RL 后,动作更流畅,整体成功率显著提高。CALVIN 评估包含五个指标:length 1 表示完成第一个子任务的成功率,length 5 表示完成前五个的成功率。RL 后,length 1 接近 100%,但 length 5 因误差累积仍不足 100%;而 SFT 即使 length 1 达 94%,length 5 仅 50% 多。这说明 RL 对长程任务也有明显提升。奖励设置为稀疏形式:每完成一个子任务得 reward=1。
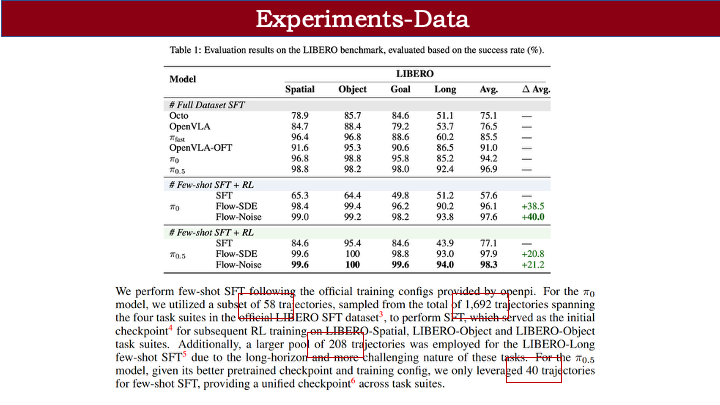
第二个问题是数据效率。在 LIBERO 上:
- π-0 的 SFT 仅用 58 条轨迹(占官方 1692 条的约 3%,仅覆盖前三个任务),加上 RL 后,性能甚至优于全量数据 SFT;
- π-0.5 仅用 40 条轨迹(LIBERO 有 4 个子任务,每任务 10 个小任务,共 40 条示范),SFT + RL 也能取得不错性能。
这表明“小数据 SFT + RL”的范式,比全量 SFT 更高效。
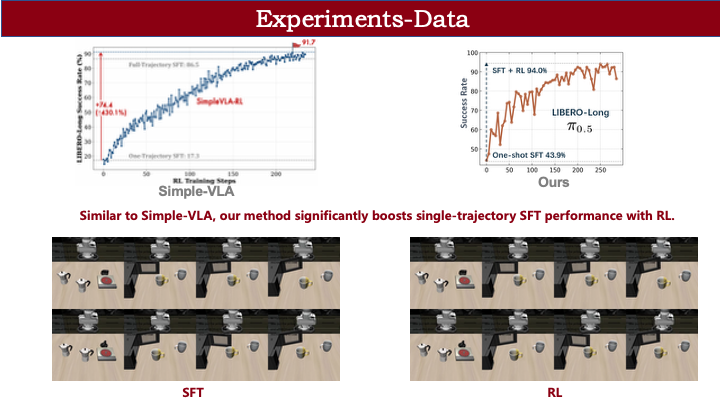
此前社区知名的 SimpleVLA-RL 工作也展示了类似趋势:单轨迹 SFT + RL 即可在 LIBERO-Long长程任务上取得显著提升。可视化可见,单轨迹 SFT 下模型因严重 OOD 而夹爪乱甩;RL 后动作更丝滑,仅个别任务失败。

第三个问题是泛化能力。我们在 ManiSkill 上进行了 OOD 测试,涵盖三方面:
- 视觉层面:更换桌面颜色/纹理,或在输入图像添加噪声;
- 语言层面:训练用“萝卜”,测试用“杯子”;训练用红色盘子,测试用不同颜色/纹理的盘子;
- 动作层面:改变机械臂初始位姿(如夹爪初始闭合)。
结果显示,RL 后在各类 OOD 场景下性能均有提升,说明 RL 不仅缓解过拟合,更提升了整体泛化能力。
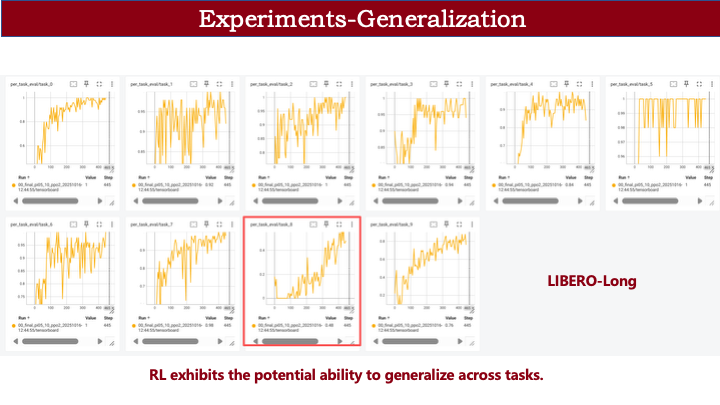
我们还观察到一个有趣现象:在 LIBERO-Long 任务中,task 8 在前 100 步内成功率始终为 0(因稀疏奖励,无成功即无奖励,理论上无法训练)。但随后成功率突然上升。这是因为其他任务中学到的通用动作能力迁移到了该任务,使其获得初步成功,进而形成正反馈,性能被拉起。
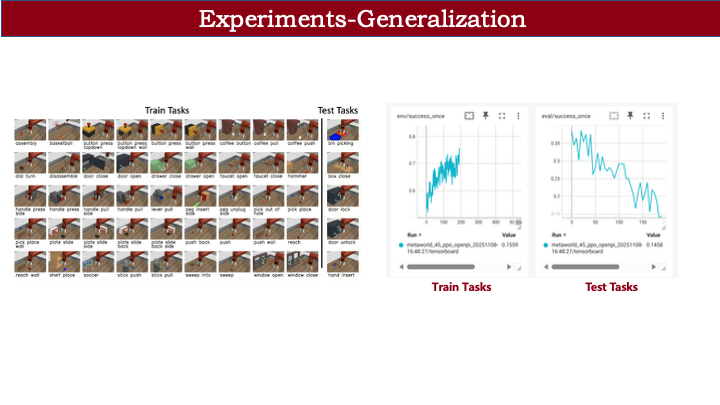
那么,RL 是否意味着 VLA 可实现 zero-shot 泛化?答案是否定的。我们在 Metaworld 上进行了测试:在 45 个任务上进行 RL 训练,另选 5 个完全未见的新类型任务(不同于 ManiSkill 的 pick-place 单一类型)。结果发现,尽管训练任务性能提升,未见任务性能反而下降。这说明 RL 并不具备跨任务泛化能力。
原因在于遗忘问题:RL 过程中,模型逐渐遗忘了 SFT 阶段学到的未见任务知识。例如,SFT 阶段能成功放置物块;RL 后动作变得迟缓——因训练中未见过该任务,仅保留部分基础能力,但动作精度下降。
接下来是消融实验。
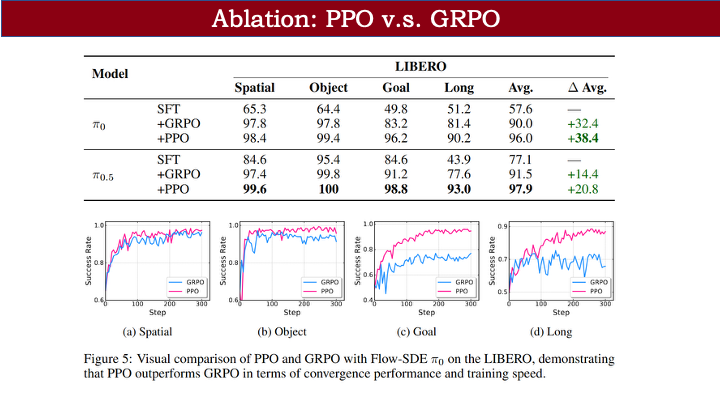
首先对比 PPO 与 GRPO:在我们的设定下,PPO 整体优于 GRPO。尽管近期有基于 GPPO 的工作表现不错,但本实验中 GRPO 收敛性能始终不如 PPO。
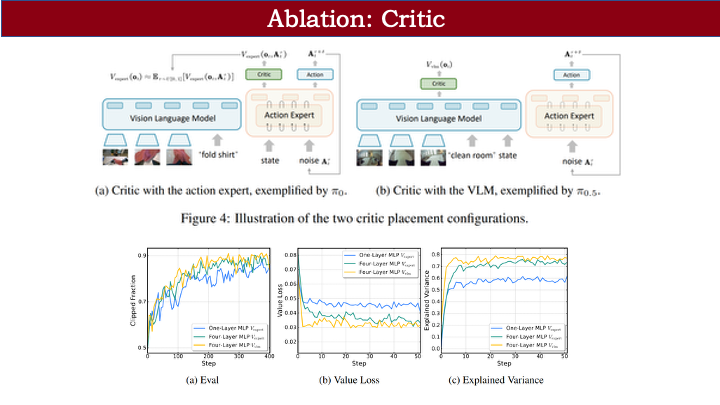
其次,我们测试了两种 critic 设计及深度影响:
- 蓝线(单层 MLP critic)vs 绿线(四层 MLP):更深网络收敛 loss 更低,reward 曲线更稳定;
- 在 π-0 上对比 critic 位置:接在 VLM 后的效果反而更好。这看似反直觉(因缺少 state 信息),但实际是因为 action decoder 后的 critic 需解耦动作噪声,对优化造成轻微阻碍。尽管差异不大,我们仍为 π-0 采用 VLM 后接 critic 的方案。
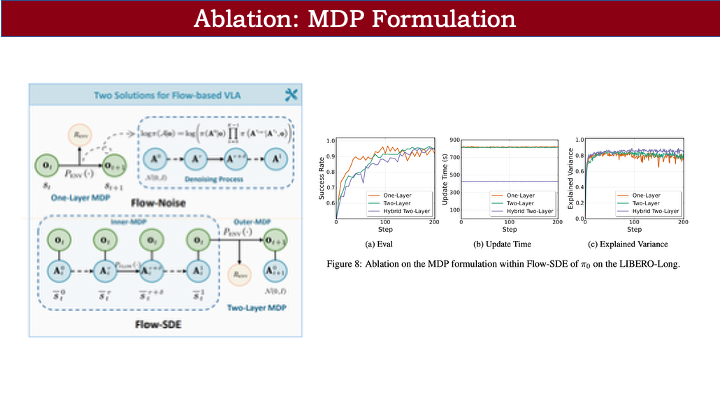
最后对比两类 MDP:
- 单层 MDP(Flow Noise)收敛较快,但需将完整去噪链存入 buffer,优化耗时较长(约 800 秒);
- 双层 MDP(Flow SDE,带跳步)优化效率快一倍(约 400 秒),整体性能相当。
两种方案均已开源,便于后续加速改进。
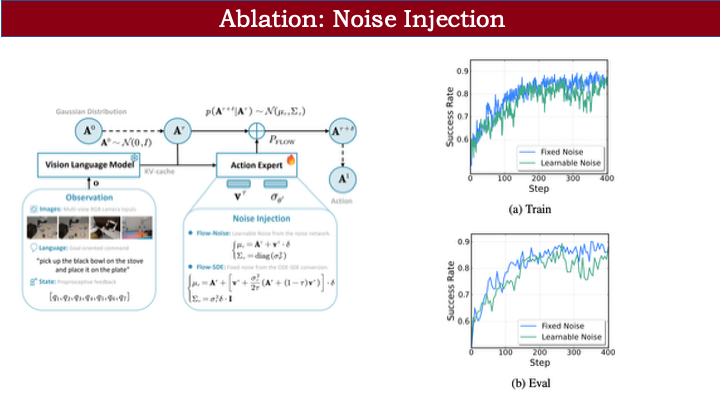
关于噪声注入:可学习噪声与 ODE→SDE 转换两种形式性能相近。前者可能略有精度损失,但可通过 entropy loss 约束,使收敛时噪声趋近于零;后者更简洁,无需额外网络或参数调整。