序章:三条哲学
在探讨技术之前,我们需要先确立三条基石性的认知:
人类的本质:人类在生物界的独特性在于高等智慧,而人与动物的分野,在于制造与使用工具的能力。
大模型的定位:ChatGPT 标志着人类首次赋予机器高等智慧。大模型之于现代人类,如同智慧之于原始人类,不仅不可或缺,更不可退化。
Agent 的使命:Agent 本质上是让 LLM(大语言模型)学会制造与使用工具,从而赋予“智慧”改造现实世界的能力。既能改造世界,必能创造无穷价值。
一、 范式转移:从“对话”到“Agent”
2025年,许多人尚未察觉的最大变量,是我们正从 Chatbot 时代 真的已经跨越至 Agent 时代。
大家对 Chatbot 的界面再熟悉不过:用户通过命令行与 LLM 轮番对话。投资人曾对 Chatbot 市场持悲观态度,这并非没有道理。
Chatbot 的交互本质是高认知负荷的——用户需要时刻盯着屏幕,绞尽脑汁设计 Prompt,再将结果手动搬运到业务场景中。这种“不够爽”的体验导致了极低的效率提升和用户粘性。
Agent 的革命性
Agent 引入了关键角色:Tool(工具)。
在 Agent 模式下,用户发出指令后,LLM 不再只是“说话”,而是调用工具(Function Call)。LLM 将参数输入给 Tool,Tool 与环境(Env)交互并将反馈回传给 LLM。
自主循环:如果 LLM 认为任务未完成,它可以自主进行多轮“调用-反馈-修正”的循环,用户无需介入。
结果导向:直到任务彻底完成或需要人类决策时,Agent 才会返回结果。
Claude Code 是这一理念的集大成者。以 Claude Opus这个LLM 为大脑,文件系统和命令行作为环境,它能自主完成检索、修改、创建、执行等一系列代码任务。
这种“一条指令,数小时自主工作”的体验,将人类从繁重的重复劳动中解放出来。这不仅带来了极高的用户付费意愿和粘性,对于 LLM 厂商而言,Agent 带来的 Token 消耗量相比 Chatbot 更是指数级的增长。
2026年的 Agent,绝不仅限于 Coding,它将延伸至操作系统控制、表格处理、生活服务等所有领域。AI 写代码不过半年,却已深刻重塑了工作流。
二、 技术前瞻:预训练(Pre-training)的深耕
2026年,预训练将进入“存量精耕”阶段。
数据策略:人类互联网的自然数据增量有限,谷歌等巨头的思路已转向高质量数据合成。互联网数据嘈杂且呈长尾分布,淘金难度加大。同时,海量的图片、视频、音频等多模态数据(VLM)仍有巨大的挖掘空间。
架构演进:在高效长文本处理、Loop Transformer 等旨在提高单 Token 质量的架构上,仍有顶尖人才在持续推动。
AI Infra 的挑战:我们需要极优秀的工程师来驾驭 Megatron,确保低精度训练的正确性与效率。MoE、From Scratch 训练、特殊架构的适配,都需要顶级 Infra 团队的支持。代码的一行谬误可能导致数月的时间浪费;反之,10% 的效率优化将带来天文数字般的成本节省。
三、 核心战场:后训练(Post-training)与 RL 时代
后训练正全面走向 RL(强化学习)时代,SFT(监督微调)将变得越来越轻量化。
1. 蒸馏之路断绝,唯有自力更生
从顶尖模型(OpenAI, Claude, Gemini)进行蒸馏已变得异常困难。巨头们不再提供原始思维链(CoT),仅提供总结版,甚至在数据中“投毒”。
OpenAI 的新接口更是直接云端托管 CoT。这意味着,依赖蒸馏将导致与顶尖模型的差距越拉越大。我们必须构建自己的 RL 基建、数据和算法。
2. RL Infra 的历史
由 OpenRLHF 胡建定义的范式已成为行业标准:
推理引擎:vLLM / SGLang
训练引擎:DeepSpeed / FSDP / Megatron
调度层:Ray
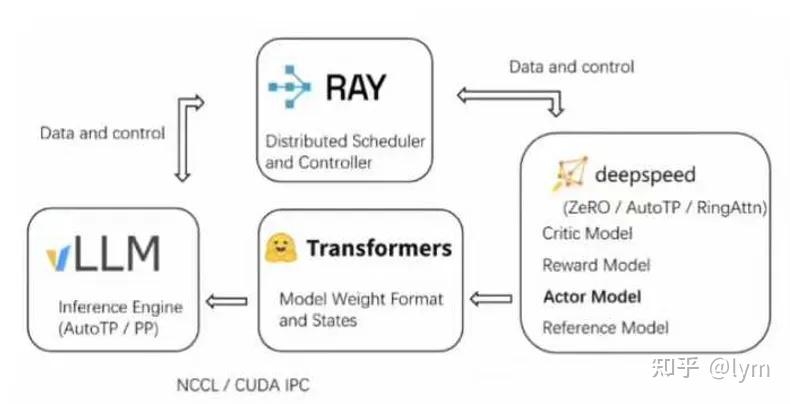
这一范式已被 Verl, Slime, ROLL 等框架广泛采纳。正如 OpenRLHF 核心作者所言,各大厂内部其实都在维护一套类似的 RL 框架。大规模 RL 是一项由算法主导,训练与推理 Infra 紧密配合的系统工程。
3. 2025-2026 RLHF/RLVR 的演进方向
从单轮到多轮主导:Math 任务通常是单轮的,但未来的核心是多轮复杂任务(如 GPT-5 级别的长时间工程执行)。Verl 等框架侧重单轮,而在多轮任务中,Re-tokenize 等问题仍需解决。
长期稳定训练的探索:目前的 RLHF 往往在数百步后即面临崩溃,需要反复“短期训练-采样-SFT”的循环。MoE 模型的路由坍塌(Routing Collapse)和训推不一致问题,都需算法与 Infra 结合进行进一步理论与实践上的创新。
规模与环境的复杂度升级:从简单的 Math Reward (If-else),到 Code SWE,再到与浏览器、操作系统的交互,Agent 所处的环境越来越复杂。这需要强大的工程团队提供大量高并发、高可靠的沙箱环境。
Slime 框架的启示
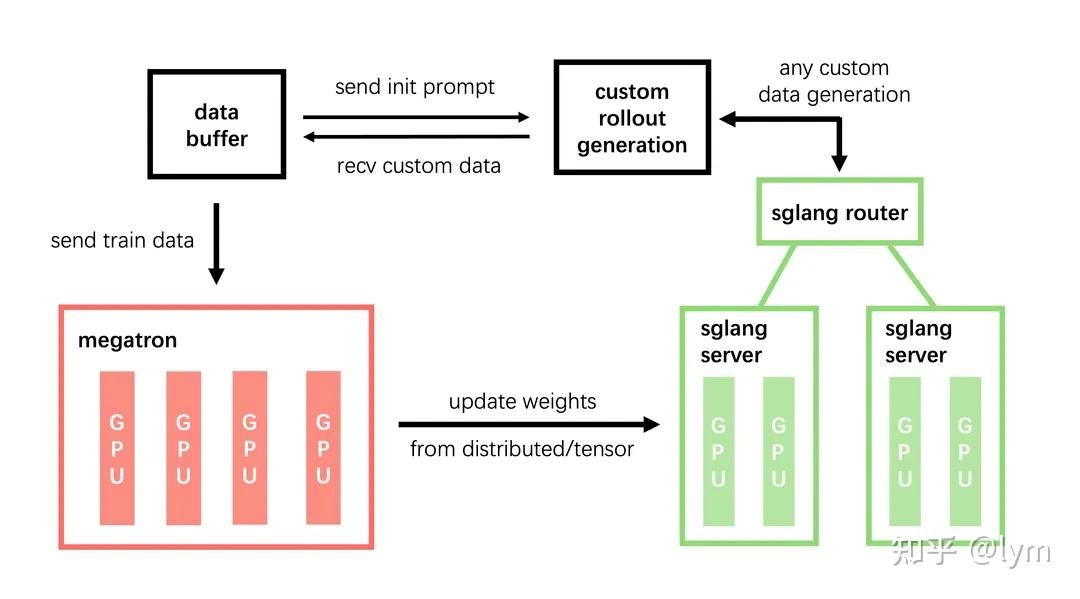
这里不得不提 Slime,它是专为 Agent 时代设计的框架。其核心优势在于解耦了 Agent 框架与 RL 框架,利用 RadixTree 技术确保了多轮对话logits的准确性,并在 GLM 百亿参数模型上完成了 Scaling 验证。
开源社区的合力开发使其在特性上处于领先地位。这证明了:算法主导 + 强 Infra 支持 + 开源共建 是 RL 框架的最佳路径。
四、 决胜关键:Agent 时代的弹药库
DeepSeek v3.2 等前沿模型的成功并非偶然。要在这场战争中获胜,必须储备以下“弹药”:
顶级的算法与架构设计师:定义方向,找到进一步scaling的方法。
强悍的 Infra 团队:精通 Megatron 及 vLLM/SGLang,掌控低精度训练与极致优化。
云服务工程能力:提供稳定、高并发、零差错的大量多样的真实沙箱环境。
算力资源:充足的 GPU 集群。
开源与探索氛围:拥抱社区,快速迭代。
长期主义的组织架构:建立稳定合理具有前沿探索性的组织。
五、如何Agent scliang?
未来的 Agent 必须并行化,通过Agent RL。现在的 Agent 多是线性工作流,未来模型需要学会并行&异步思考,并行&异步toolcall,自主组织工作流。
这将带来极致的用户体验,当然,也伴随着巨大的 Token 消耗,这也许是科技巨头在新时代的盈利手段之一。
六、 结语:长期主义的胜利
RLHF 真的有意义吗?
NIPS 的论文或许会质疑 RL 对 Base Model 的上限限制,但围棋界的 AlphaGo 早已证明,RL 足以从零训练出超越人类的 SOTA 模型。
与其质疑,不如解决当前 RLHF 存在的 Scaling 问题。LLM 的核心在于如何构建“探索-验证-再探索”的飞轮,实现性能左脚踩右脚的螺旋上升。
AI 时代,The more you invest, the more you save.
变革已至,且在加速。刷榜毫无意义,投机取巧终将反噬。我们需要思考在工程和科研上与顶尖模型的真实差距,看透指标后面隐藏着的技术差异,坚持长期投入,真正的收益往往伴随着长延迟反馈。
愿我们在今天种下的种子,在三个月、半年乃至一年后,能结出最丰硕的果实。