作者:小秋
https://zhuanlan.zhihu.com/p/1979682819170145066
前言
快慢双系统早已不是第一次在具身智能里被提出来了。
从 Daniel Kahneman 的《思考,快与慢》到机器人,大家都在拿 System 1 / System 2 打比方:一个负责“本能反应”,一个负责“慢速思考”。
在具身领域,近期有个把这件事玩明白的是 Figure 团队的 Helix:用一个大号 VLM 做高层理解和规划(慢系统),再配一个小而快的视觉运动策略模型做实时控制(快系统),还直接在双 GPU 上异步跑,规划和控制各司其职,知乎已有很多大佬解读,就不赘述了。
今天想要分享的文章依然是快慢双系统,是一篇由北大多媒体信息处理研究室联合智平方科技等工作团队的新作,慢系统不再只是 VLM,而是一个视频扩散模型 VDM,用来深挖时序视频中自带的“空间 + 运动”潜在表示;
快系统则是一个 DiT 风格的扩散动作头,专门负责高频输出机器人动作。通讯作者是北大计算机的仉尚航助理教授,值得一提的是她曾在BAIR担任博士后研究员,师从 Kurt Keutzer 教授和 Trevor Darrell 教授。
论文:Video2Act: A Dual-System Video Diffusion Policy with Robotic Spatio-Motional Modeling
链接:https://arxiv.org/abs/2512.03044
代码:https://github.com/jiayueru/Video2Act
动机
作者在积木传递任务中对 DINOv2、SigLIP 和 VDM 的 Grad-CAM 激活进行了可视化,分别从两种常见的机器人视角进行观察:静态的第三人称视角(头部摄像头视角)和动态的第一人称视角(手腕摄像头视角)。
高亮区域表示对模型特征响应贡献最大的空间位置,从而以类似注意力的方式可视化模型的关注点分布,相比之下,VDM 的特征始终聚焦于被操作的前景物体,即使在剧烈的自我运动(ego-motion)下也能保持强大的空间结构感知能力。
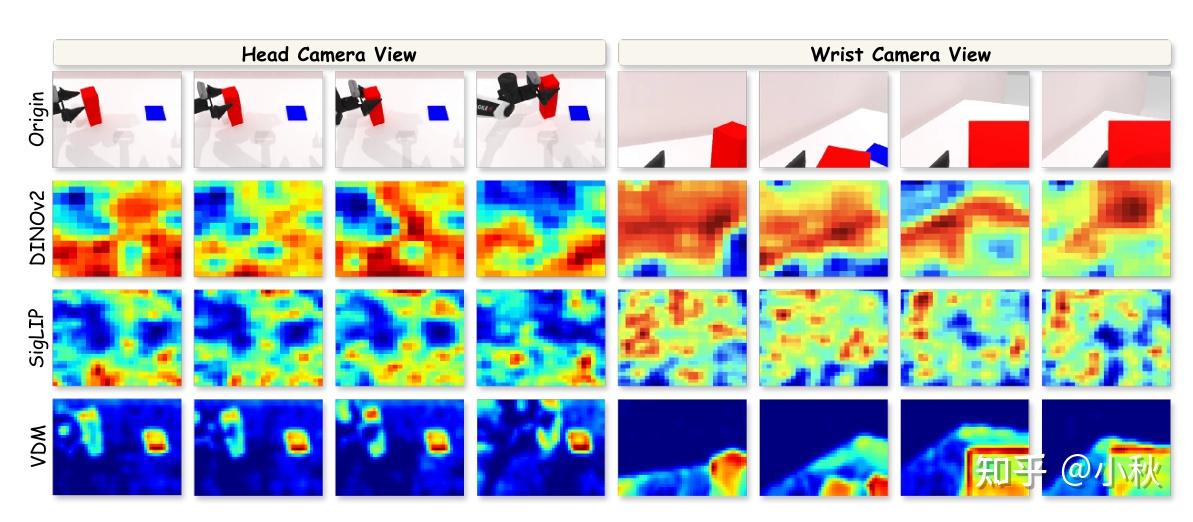
除此结果之外,作者观测到一个现象:VDM 在机器人里其实还没被用“对”。现有很多不错的 VLA 工作借助预训练 VLM 的静态图片编码器提取视觉特征,而 VDM 充当的角色更多是把未来的视频预测出来当“imagined rollouts”或者用 VDM 做视觉 backbone,提升对物理世界的理解,这样就浪费了 VDM 本身跨帧里 encode 的连续、物理一致的运动表征。
但是VDM 推理太慢,直接接在 policy 上不现实,要更强视觉 backbone,但推理延迟顶不住。我们将这两件事情合在一起,就是本文的动机,简单来说:已有 VDM + VLA 很强,但没充分显式利用“时空运动表征”,而且太慢。Video2Act 想把这两点一块解决。
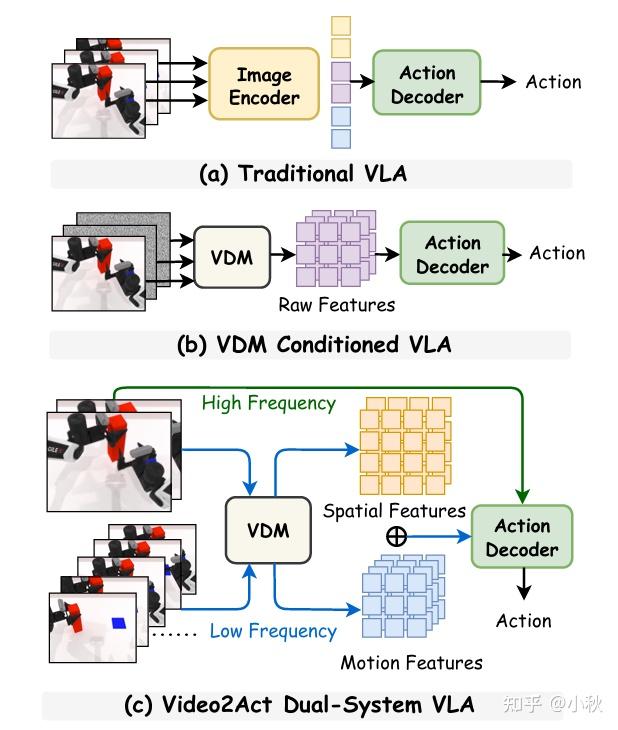
双系统框架
好了,那我们来看看 Video2Act 到底在做什么,有哪些细节。具体来说,Video2Act 把 VDM 里跨帧编码的东西拆开来用:从中显式抽取前景边界(foreground boundaries)和帧间运动变化(inter-frame motion variations),同时滤掉背景噪声和任务无关偏置——比如相机轻微抖动、光照变化这些会干扰策略学习却和操作目标没太大关系的成分。得到的就是一组“空间上告诉你该动谁、时间上告诉你它怎么动”的 spatio-motional 表征。
然后,这些表征被当作条件以交叉注意力的方式注入到 DiT 动作头里,让快系统在每次采样动作时,不是从一堆生硬的图像特征里自己摸索,而是带着“我要操作的对象在哪”“合理的运动趋势是什么”的先验去生成动作序列。
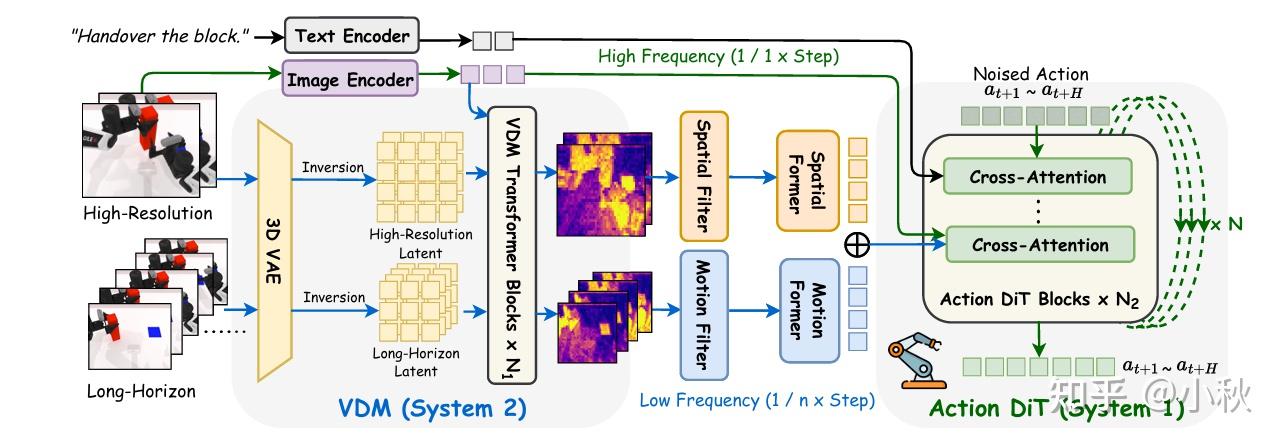
整体结构是一种双系统视频扩散策略,输入机器人观测得到的视频序列(多帧 RGB,以及语言指令 / 任务描述)。
具体而言,作者采用 SigLIP-ViT-L/14 作为图像编码器以提取视觉 token,并使用文本编码器生成指令嵌入。在 System 2 中,作者使用基于 Transformer 的视频扩散模型 Hunyuan,该模型包含一个预训练的 3D VAE,用于将图像编码到潜在空间,并由 60 个 Transformer 模块组成。
作者从中选取前 25 个模块用于特征提取。空间特征与运动特征通过作者提出的空间与运动过滤器抽取,随后通过两个轻量级的 Q-former 进行压缩,以减少 token 冗余,同时保持全局一致性。
对于 System 1,作者采用一个规模为 1B 参数的扩散 Transformer。图像 token、文本 token 与来自 VDM 的 token 通过交叉注意力机制集成到动作 DiT 中用于动作生成。
或许可以可以把它想象成:VDM 做了一次“高成本物理理解 +运动规划草稿”,DiT 在这个草稿上做快速、低成本的“最后决策 + 细节控制”。双系统协同策略基本和 Helix 一致,System 1 借助 System 2 提供的阶段性特征输出作为条件控制,通过每个时间步的最新观测完成实时动作执行。
空间运动建模
标题中除了 Dual-system 可别忽略了Spatio-Motional Modeling,文章用不小篇幅对这里做了说明。仔细观察双系统框架可以发现作者对输入的视频流做了分解,高分辨率和长视野窗口。
两个输入相互补充,用以同时捕捉细粒度动作细节和长视野运动变化(具体shape等可以看原论文)。通过 VDM 的 VAE 分别编码后,不着急做扩散,先各自强化一下效用(具体操作实际上借助到了信号处理的一些技巧)。
对于高分辨率输入的编码,引入Sobel 空间过滤算子,Sobel 算子是一种经典的图像梯度检测工具,用于捕捉边缘、结构轮廓、物体边界(特别是前景物体)等信息,计算上就是计算图像在x、y两个方向的梯度再勾股一下,得到边缘强度图。 Sobel filtering 可以强化物体结构,让模型更关注哪个物体在被操作、哪些部位需要对齐等等。
对于长视野输入的编码,引入基于频域的快速傅里叶变换(FFT),将时间维的序列视为一个信号,在时间轴上做一维离散傅里叶变换 DFT,用高通滤波 suppress 掉低频保留高频,再反变换得到 motion feature。以此流程可以去除低频背景、 ego-motion 噪声的干扰,让特征更强调运动,专注真正相关的 motion pattern。
启发
如果说 Helix 那一代快慢双系统工作,更多是在语义理解和低层控制之间把“大模型负责看、小模型负责动”这件事跑通,那 Video2Act 则在同一条路上往前挪了一格:它没有再去堆更大的多模态骨干,而是认真回答了一个更具体的问题——在真实机器人操作里,视频中的空间信息和运动信息应该怎样拆开建模,又怎样以一种算力可承受的方式输送给策略网络。
通过“VDM 抽取时空运动表征 + DiT 作为条件扩散策略 + 两者异步协同”的设计,作者给快慢双系统提供了一个更细粒度、更贴近物理细节的实现范式。
未来也不一定采用这种,明天突然冒出一个完全不同的架构也不是没可能,也不知道发布于昨天的这个新作会不会成为一个优秀的作品,不过本篇还是有不错的启发意义:强感知模块未必要死死绑在每一步控制上,它可以低频地输出稳定、筛过噪声的时空线索,把高频、低延迟的闭环决策留给轻量策略网络完成——真正让快和慢在具身系统里各安其位。