
来自北京大学与港大 MMLab 等机构合作的最新研究成果——UniSandbox 。这项工作深入探究了多模态大模型领域一个根本性的问题:统一模型中的“理解能力”是否真正反哺了“生成能力”?
代码与数据已在Github开源
Arxiv:https://arxiv.org/abs/2511.20561
Code & Data: https://github.com/PKU-YuanGroup/UniSandBox
背景
近年来,统一多模态模型(Unified Multimodal Models, UMMs)成为了研究热点。从 Janus 到 Bagel,这些模型试图在一个架构内同时通过自回归(Autoregressive)或扩散(Diffusion)方式实现视觉理解与图像生成。我们通常抱有一个美好的愿景:既然模型统一了理解与生成,那么它强大的语言先验,理应能自然地指导和增强其视觉生成能力。
然而,事实果真如此吗?
现有的评估基准往往存在“数据泄露”的隐患——模型可能只是记住了训练集里的图文对,而非真正学会了推理。此外,当生成失败时,我们很难分清究竟是“知识缺乏”、“推理失败”还是“迁移失败”。为了回答这个问题,我们需要一个绝对纯净、可控的实验环境。
UniSandbox 应运而生。这是一个基于合成数据的解耦评估框架,旨在隔离变量,像“沙箱”一样对模型进行压力测试。
UniSandbox 将“理解”拆解为两个核心维度进行探索:
- 推理生成(Reasoning Generation): 模型能否通过数学计算或符号逻辑推理来指导生成?(例如:“生成 3+2 个苹果”或“A代表猫,B代表狗生成A代表的动物”)
- 知识迁移(Knowledge Transfer): 向模型注入全新的、它从未见过的知识(如虚拟人物档案),它能否立刻画出这些人?
为了确保结论的普适性,我们选取了横跨当前 UMMs 三大主流范式的代表性模型进行严苛测试 :
- 自回归(Autoregressive, AR):以 Janus-Pro 为代表。这类模型将图像离散化为 Token,像生成文本一样通过“预测下一个 Token”的方式进行端到端生成。
- AR + Diffusion(浅层融合):包含** Qwen-Image 和 Blip3o**。前者利用最后的隐层状态(Hidden States),后者利用查询向量(Queries)来提取条件信息,进而引导独立的扩散模型进行生成。
- AR + Diffusion(深层融合):以 BAGEL 为代表。它在一个统一的 Transformer 框架内,深度整合了语义理解与扩散生成过程
UniSandbox 的评测结果显示,当前主流 UMMs 在“理解”与“生成”之间存在显著鸿沟 。我们的分析表明,在缺乏引导的情况下,模型的生成过程倾向于退化为浅层的“词袋(Bag-of-Words)”映射,即模型仅能响应简单的关键词,而难以处理复杂的逻辑指令 。
基于此,我们在两个维度上得出了以下结论:
1.推理生成
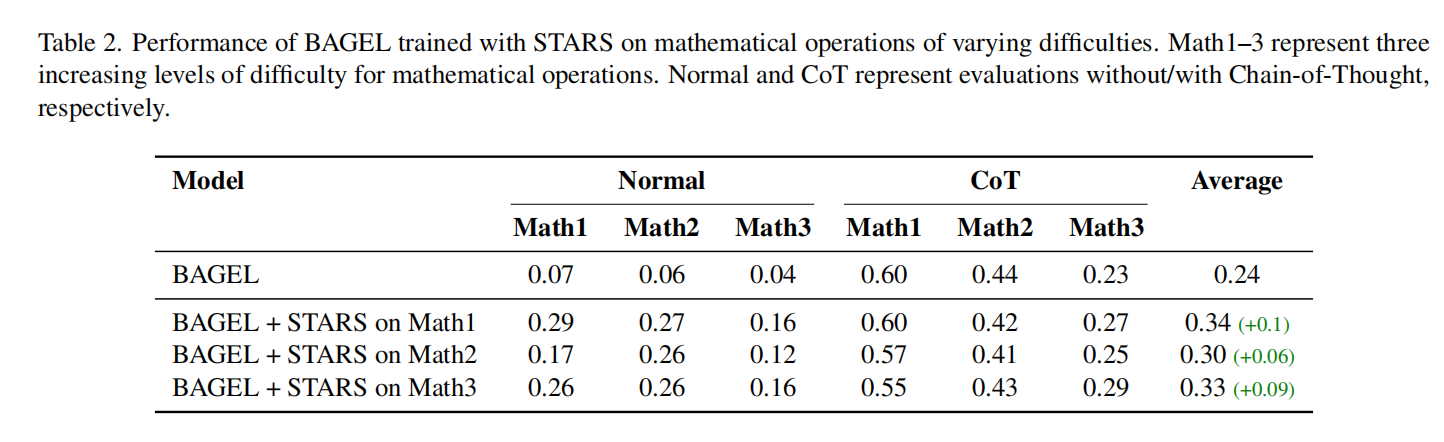
CoT 的桥梁作用与能力内化在数学计算与符号映射任务中,标准模式下的模型得分极低。引入显式思维链(Chain-of-Thought, CoT)后,模型性能得到显著提升,这表明 CoT 是连接理解与生成的有效桥梁 。
进一步的研究通过 STARS(Self-Training with Rejection Sampling) 框架证明,这种推理能力可以被模型“内化”:利用高质量的 CoT 数据进行自训练,模型可以在不输出显式推理步骤的情况下,通过隐式推理完成生成任务 。
2.知识迁移
逆转诅咒与架构差异 在知识注入实验中,我们发现 CoT 虽然能显著改善正向检索(根据名字生成人物)的表现,但在逆向搜索(根据描述生成人物)中改善有限,验证了多模态模型中存在与大语言模型类似的“逆转诅咒”现象 。
此外,架构分析显示,基于 Query 的模型(如 BLIP-3o)表现出优于纯自回归模型的特性。可视化结果表明,其不同位置的 Query 能够分步关注属性与实体信息,这种机制具有类似思维链的潜在属性(Latent CoT),更利于知识的提取与迁移 。

推理生成

在推理生成任务中,我们发现若不显式地使用思维链(Chain-of-Thought, CoT),模型的生成过程会退化为浅层的“词袋(Bag-of-Words)”映射——它能画出“苹果”,但无法处理“3+2”后的数量逻辑。然而,一旦引入 CoT,让模型先在文本域“想清楚”,性能便会发生质的飞跃(从 0.02 暴涨至 0.51)。
为了进一步探索这种能力是否可以内化,UniSandbox 提出了 STARS(Self-Training with Rejection Sampling) 框架。

STARS 通过让模型自己生成 CoT 推理数据,并利用其强大的理解模块进行“自我审查(Rejection Sampling)”,筛选出高质量数据微调生成器。实验证明,这种方法能在数学推理上成功将显式的推理过程“蒸馏”进模型的参数中,实现隐式推理,并且这种推理能力可以有效泛化到其他难度的测试中。
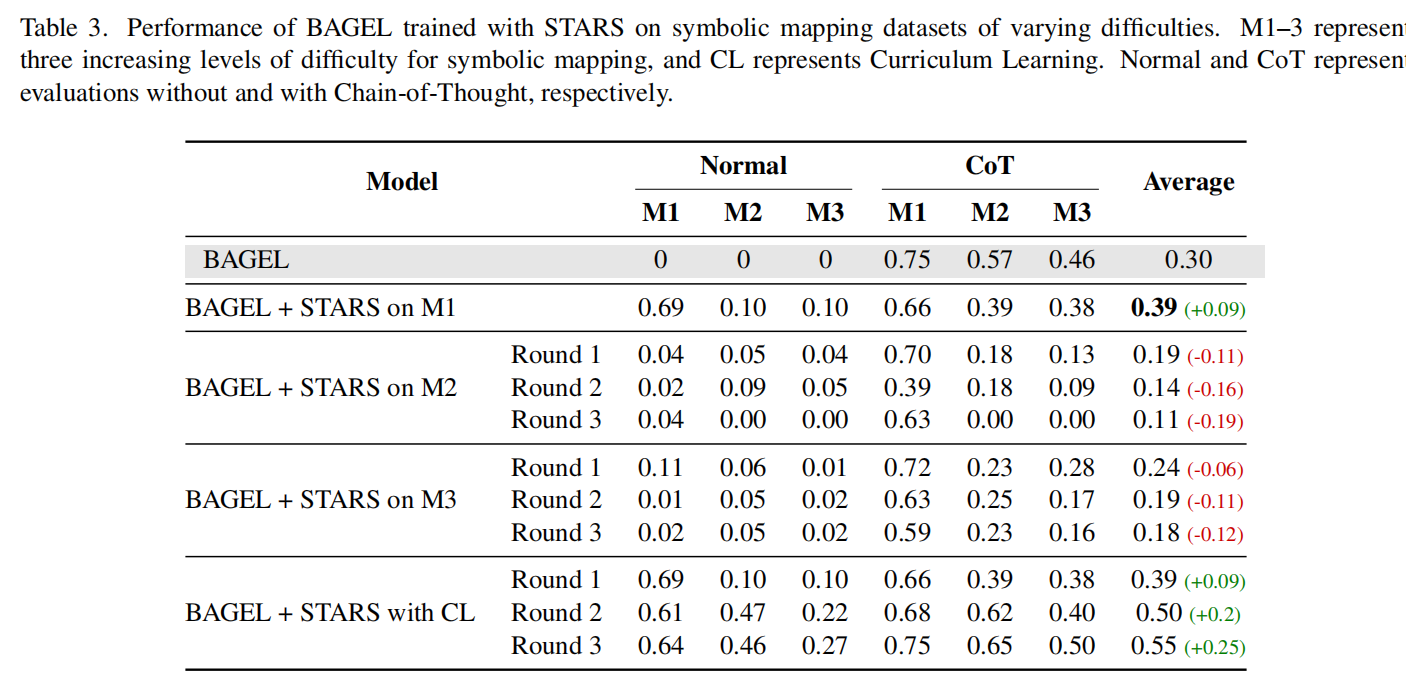
然而,在面对高难度的符号映射任务(Symbolic Mapping)时,我们遭遇了滑铁卢。 当我们试图直接用高难度数据(如三跳逻辑推理:A代表1,1代表猫,生成A代表的动物)训练模型时,模型的性能不升反降,甚至趋近于零。
我们发现,面对复杂的逻辑链,模型并没有学会推理规则,而是开始“摆烂”。在只有两个选项(如生成苹果或橘子)的任务中,模型发现只要始终生成同一种物体,就能在 loss 上获得一个相对不错的结果(50%的概率蒙对)。
UniSandbox 发现,引入课程学习(Curriculum Learning) 是破局的关键。通过从易到难逐步训练,模型不仅掌握了复杂推理,甚至在原始 CoT 模式下的表现也得到了进一步增强。
知识迁移
如果说“推理生成”考察的是模型处理内部逻辑规则的能力,那么一个更本质的问题随之而来:模型是否也难以调用其新学到的“内部记忆”?
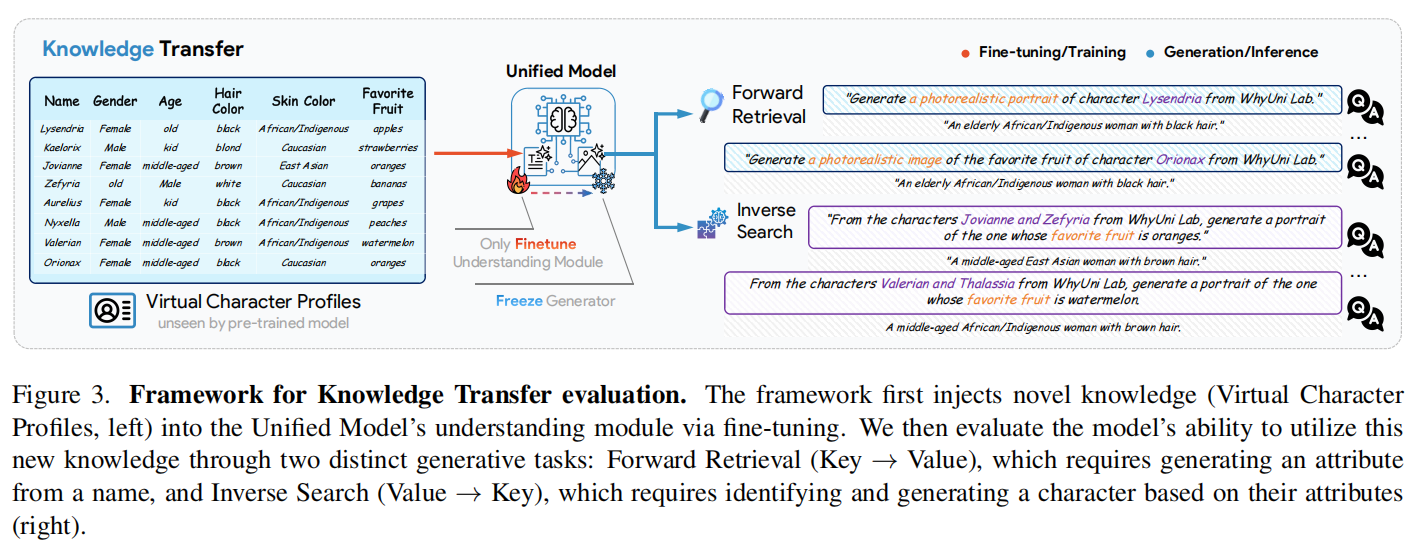
我们将“知识迁移”定义为:当向模型的理解模块注入全新的、训练集中不存在的知识后,生成模块能否直接调用这些知识进行视觉创作。这是验证“理解”是否真正反哺“生成”的试金石。
为了杜绝数据泄露,UniSandbox 构建了一个完全虚构的“虚拟人物档案库”(包含姓名、外貌特征等)。我们通过微调(Fine-tuning)将这些知识注入模型的理解模块,确保模型“知道”这些人是谁,但在预训练阶段从未“见过”他们。
我们设计了两个维度的测试任务:
1.正向检索(Forward Retrieval): 给定名字(Key),要求模型画出对应的人物形象(Value)。
2.逆向搜索(Inverse Search): 给定外貌描述(Value),要求模型识别出是谁,并画出其形象(Key)。
遗憾的是,UniSandbox 的实验表明,这种“理解-生成”的阻断是全方位的
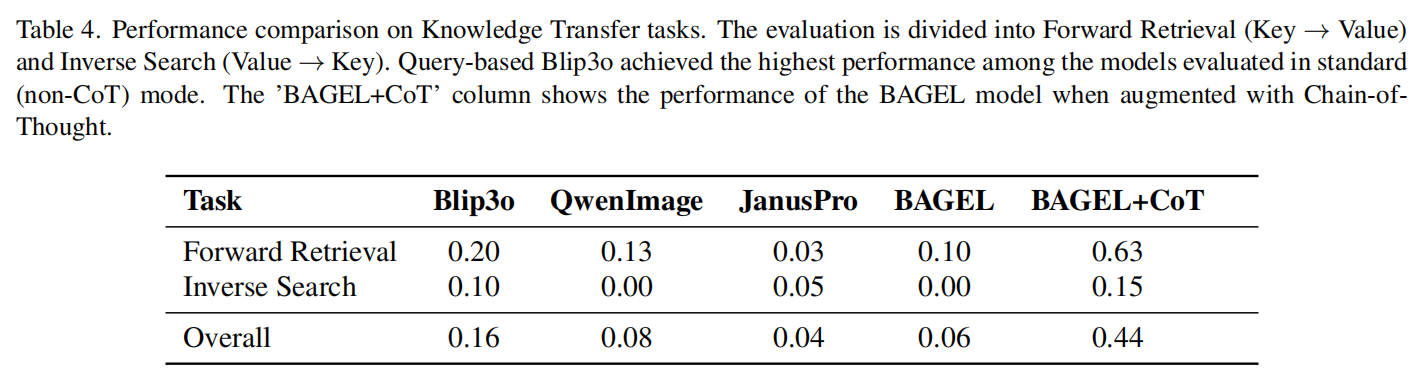
引入思维链(CoT)后,情况发生了两极分化:
- 正向检索被“激活”: CoT 充当了“桥梁”,显式地将沉睡的知识提取出来,使得 Bagel 在该任务上的得分从 0.10 暴涨至 0.63。
- 逆向搜索依然“崩塌”: 即便开启 CoT,模型在“根据描述反推人物”的任务上依然表现不佳(仅 0.15)。这证实了多模态模型中同样存在类似于大语言模型的“逆转诅咒(Reversal Curse)”——模型难以反向利用学到的知识链条。

架构分析:Query-based 模型的“隐式思维链”
在知识迁移的横向评测中,我们观察到基于 Query 的 Blip3o 在标准模式下取得了最高的性能 。为了探究其架构优势,我们对其隐层状态进行了可视化分析 。
具体而言,我们提取并解码了不同位置 Query 对应的隐层状态,计算了与注入知识相关的词汇概率 。以“Kaelorix 最喜欢的水果”为例,我们将相关词汇分为“目标知识”(Target Knowledge,如 strawberries)和“相关属性”(Related Attribute,如 kid, male) 。
可视化结果揭示了令人惊喜的机制:
正如原文图 4 所示,Query-based 架构展现出了一种分步处理的动态过程:
1.中间 Query 负责“定位”: 在生成的中间阶段,与“相关属性”(如 kid, child)相关的词汇概率显著升高 (5)。这表明,中间的 Queries 正在首先尝试通过属性来“锁定”或“定位”这个角色。
2.末端 Query 负责“提取”: 与最终“目标知识”(如 strawberries)相关的词汇概率,则是在最后的 Query 成功被检索到,达到峰值。
这表明,Query-based 架构它利用多个Queries 执行了一个“隐式的思维链(Implicit CoT-like process)”:先利用中间 Queries 消化上下文并定位实体(属性检索),再利用末端 Queries 精准提取目标信息(知识检索) 。
这种天然的分步检索机制,正是其在知识迁移任务上表现优异的深层原因,也为未来设计更高效的统一模型架构提供了关键的设计参考。
结论
本文探究了一个根本性问题:在统一多模态模型中,理解能力是否真的能指导生成?
为了回答这一问题,我们提出了 UniSandbox,这是一个利用可控合成数据的全新解耦评估框架 。
我们的研究揭示了一个显著的 “理解-生成鸿沟”(Understanding-Generation Gap):目前的模型在很大程度上无法将其理解能力转化为生成能力,这主要体现在推理生成和知识迁移这两个关键维度上 。
对于推理生成
我们证明了显式的思维链(CoT)能够激活模型的推理生成能力,并且这种能力可以通过自训练(Self-training)成功内化 。
对于知识迁移
我们展示了 CoT 同样是一个有效的激活剂 。此外,我们的分析还揭示了基于 Query 的架构天然具备隐式的类 CoT 属性,这为未来的架构设计提供了关键洞察 。
总而言之,UniSandbox 揭示了当前模型的局限性,并为设计真正实现理解与生成协同(Synergy)的统一架构指明了前进的道路