过去一年,OPD 强势改写大模型后训练格局,消融蒸馏与强化学习的技术壁垒,驱动模型从静态对齐迈向自主进化,一众关乎 AI 自我迭代的前沿疑问应运而生。

在 5 月 30 日,#青稞AMA 第 3 期:On-Policy Distillation(OPD) 专题中,青稞社区邀请到了当前 OPD 方向最核心的一批青年科学家,一起深度解析了 OPD 技术的火爆成因,探讨了其作为一种高效率后训练手段在模型合板、持续学习及长文本任务中的核心优势。
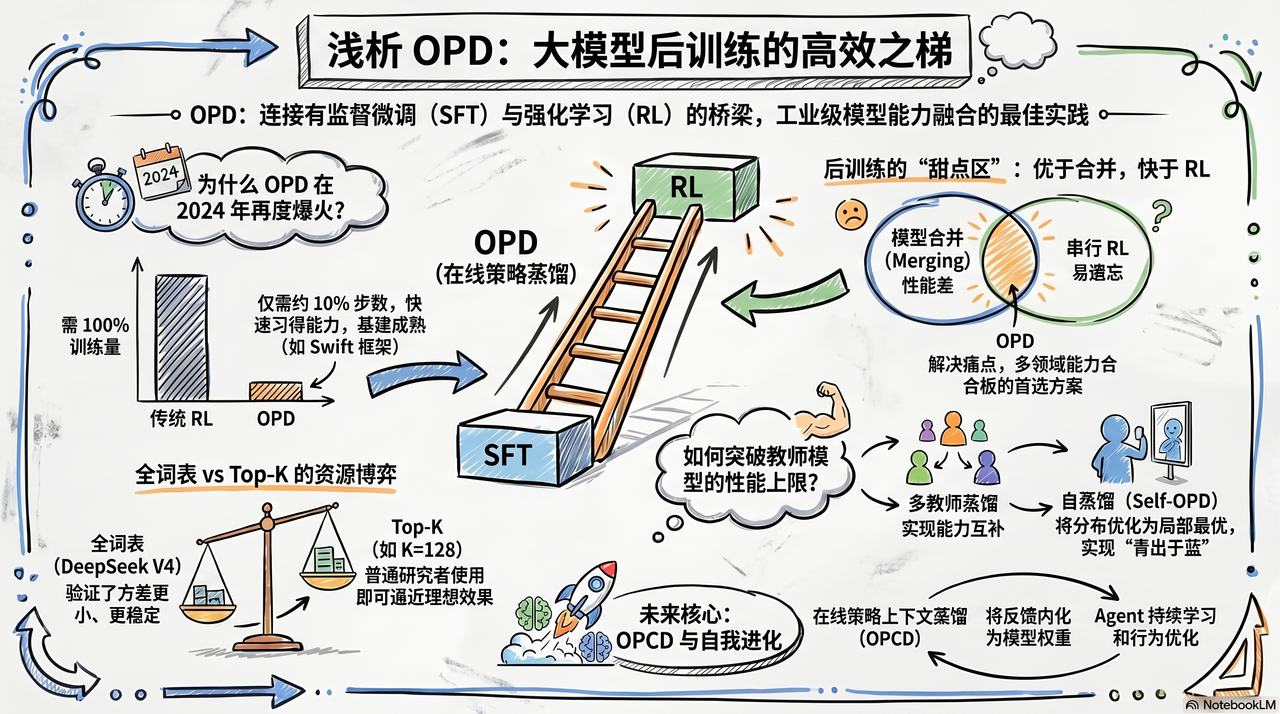
同时还详细对比了 OPD 与强化学习(RL)在优化目标与泛化能力上的本质区别,并对全词表监督、跨模型蒸馏以及黑盒蒸馏等工程痛点提出了前沿见解。
此外,讨论还展望了 Self-OPD 与上下文蒸馏在实现模型自我演进中的潜力,为理解大模型蒸馏技术的演进路径提供了重要参考。
参与嘉宾有:
- 傅宇千(主持人),中科院自动化所深度强化学习团队博士生
- Tianzhu,MSRA GenAI 组 researcher
- 顾煜贤,清华大学博士生 & MiniLLM 一作
- 杨晨旭,信息工程研究所六室自然语言处理小组博士生
- 何秉翔,清华 THUNLP 博士生 & Rethinking OPD 共一
- 黎亚轩,上科大本科生 & Rethinking OPD 共一
直播回放
On-Policy Distillation 专题视频回放已在【青稞AI】视频号上线,欢迎观看!
哔哩哔哩:https://www.bilibili.com/video/BV1qKVd6XEA3?t=594.2
浅识一下
傅宇千 (主持人):
大家好!我是傅宇千。首先感谢青稞社区的邀请,很荣幸作为主持人组织这场 OPD 专题讨论,很高兴与Tianzhu、煜贤、晨旭、秉翔、亚轩共同探讨 OPD。
我目前是自动化所四年级博士生,师从赵东斌研究员与朱圆恒副研究员,研究方向为强化学习与大模型后训练,近期我们对 OPD 的理论与实践展开分析,形成《Revisiting OPD》一文并开源代码。
正式讨论前,先请各位嘉宾分别做自我介绍,内容可包含当前研究方向、关注 OPD 的原因、代表性研究工作、研究中遇到的问题,以及核心认知转折点等。
Tianzhu:
大家好,我是Tianzhu,现任微软亚研院 General AI 组研究员。此前主要研究语言模型预训练,相关工作聚焦 Attention 机制。
大概去年开始关注一些 on-policy learning 的方向,当然其实去年开始做的时候,是因为我们组对于 distillation 有研究传统,之前最早就是煜贤学长 MiniLLM,我们这边对蒸馏的关注一直比较多,尤其是发现 on-policy 对于蒸馏也好、持续学习也好,都有不可或缺的重要作用。
所以去年看了一些 black-box on-policy distillation 的相关工作,今年则做了 on-policy context distillation 相关的工作,整体是围绕 OPD 这个课题。
其实个人体验的话,on-policy learning 这件事非常重要,我觉得包括大家后面说的 self-improve 以及 continual learning 这些所有 topic,可能都离不开 on-policy learning 以及它背后的一些 insight。
顾煜贤:
大家好,我是顾煜贤,清华大学五年级博士生,即将毕业。我的研究方向基本覆盖语言模型全链条,包括数据、后训练、OPD、模型架构等,近期重点关注模型架构。
我关注 OPD 的时间较早,2022 年冬天 ChatGPT 刚推出,大家对强化学习充满兴趣,导师建议我用强化学习做蒸馏,这是 OPD 最早的研究思路,后续逐步演化出 Reverse KL 形式,最终形成 MiniLLM。
MiniLLM 是 2023 年 6 月发布,是理论层面第一篇 OPD 论文,比谷歌同类工作早 9 天。当时我核心认知是 on-policy 的重要性,但那时候该观点未被广泛认可,行业普遍认为强化学习成本高,更倾向于 DPO 而非强化学习,后续大家才逐步意识到 on-policy 的价值。
当时也曾尝试 black-box 蒸馏,试图获取 GPT 的 Logits 但未成功,后来这个 Tianzhu 给实现了,非常厉害。
何秉翔:
大家好,我是何秉翔,清华大学计算机系二年级直博生,在自然语言处理实验室 THUNLP 读博,师从刘知远教授,主要研究方向为大模型对齐与强化学习。
2023 年我从数据层面开展研究,参与构建偏好对齐数据集,后续探索指令微调数据、偏好对齐数据,分析后训练阶段数据质量的影响因素。去年我主要研究强化学习,从有监督、无监督强化学习两个维度,验证极简强化学习的潜力,刻画伪信号的可扩展性边界,同时参与构建推理模型强化学习综述。
我关注 OPD 始于去年下半年,看到 Thinking Machine Lab 的博客,其中提到经过 RL 的模型可通过 OPD 快速恢复教师模型性能,当时我刚完成 JustRL 这个工作,将一个模型通过简单 RL recipe 的方式稳定训练了 4000 多步,希望借助 OPD 恢复模型性能,由此开启 OPD 研究,并开展 OPD 性质分析相关工作,先简要介绍这些。
黎亚轩:
大家好,我是黎亚轩,上海科技大学大三计算机专业本科生,目前在清华 NLP 实验室实习,和秉翔师兄合作,研究方向为大模型后训练与对齐,是《Rethinking OPD》一作,该工作与秉翔合作完成。很荣幸受青稞社区邀请,与各位优秀的老师、学长探讨 OPD,我资历尚浅,希望多向大家学习。
我 10 月从秉翔师兄处了解到 OPD,Thinking Machines Lab 发布的博客展示了 OPD 相较于 RL 的高效性、相较于 SFT 无遗忘的优势,效果极具吸引力,我们尝试复现并开展研究,过程中遇到诸多训练失败的情况,经大量分析与实验,最终形成《Rethinking OPD》工作,以上是我的介绍。
杨晨旭:
大家好,我是杨晨旭,信息工程研究所博士生,师从林政研究员,主要研究大模型后训练、强化学习,聚焦多模态大语言模型与视频理解方向。
我接触自蒸馏研究的时间较晚,2023 年二三月份自蒸馏相关研究集中涌现,我才开始跟进,觉得这类研究很有价值。研究过程中遇到诸多问题,自蒸馏生效的条件较为苛刻,不同领域数据适配的方法不同,很有意思。
此前资源受限条件,在研究推理相关工作,发表两篇相关论文,去年下半年至今年年初转向大模型后训练研究,还有诸多问题需要向各位请教。
OPD 爆火的真相
傅宇千 (主持人):
谢谢各位同学的自我介绍,接下来进入圆桌讨论环节。
第一个问题,煜贤老师提到 OPD 出现时间较早,无论是MiniLLM,还是谷歌 OPD 论文,其实在 2023 年 6 月就有首次发布。为何时隔三年,OPD 再次火爆,相关论文与下游应用快速兴起,各位老师有何看法?
顾煜贤:
我也很惊讶 OPD 突然爆火了。对我而言,Thinking Machines Lab 这一波推广与大规模实践,对 OPD 这个话题起到了极大的推动作用。
时代背景是,现在后训练已经成为主流方向。2023 年时,大家对后训练的概念还不够清晰,也没有成熟的后训练流程,基本都在做 SFT,即便做后训练也主要是 DPO,很少有人做大规模的 RL。
当时的 RL 基本就是 RLHF,只做简单对齐。我认为 OPD 火起来主要有两个原因:一是时代背景,后训练本身火了;
二是 Thinking Machines Lab 做了一系列关键推动。我自己理解,他们是想做类似 continual learning 的方向。刚才Tianzhu也提到,OPD 及其衍生方向和 continual learning 有非常强的关联,我相信后面Tianzhu会展开讲。
第二点是业界普遍认为 Thinking Machines Lab 其实把 OpenAI 内部的一些技术开源出来了,包括 LoRA 的训练 API 等相关组件。其实很早就有说法,OpenAI 也在使用类似 Reverse KL 的方式做蒸馏,也可能正是因为他们开源,进一步带动了 OPD 的普及。
傅宇千 (主持人):
确实我也有听说,Tianzhu对此有何看法?
Tianzhu:
我觉得 Thinking Machines Lab 的做法非常巧妙。他们选择从 RL 的视角、尤其是从 dense reward 的角度去解读 OPD。在我个人看来,OPD 和 RL 在本质上其实差异非常大,无论是优化目标还是学习范式,都存在根本性的区别。
去年多篇探讨 RLVR 局限性的论文指出,传统强化学习依靠 sparse reward,不仅难以优化 Top-K 指标,训练效率也偏低。而 TML 巧妙地从 dense reward 的视角解读 OPD,将其与 RL 领域的问题结合,恰好击中了学界的痛点,让大家看到解决 RL 稀疏奖励瓶颈的全新思路。
所以我认为这其中有运气成分,再叠加行业发展趋势,刚好契合了当下热门的研究方向。OPD 走红存在一定偶然性,TML 最初大概率也没料到它会热度暴涨,不过他们在撰写博客时明显经过考量,特意关联了 continual learning 等热门课题。
傅宇千 (主持人):
确实如此。我认为 OPD 具备的 on-policy 特性,是它能够走红的重要原因。
另一方面,当前大模型发展也提出了新需求:一是模型需要具备持续学习能力,二是业界都在追求通用大模型。想要融合多领域能力,传统 SFT 的效果往往不及 on-policy 方法。
晨旭、秉翔、亚轩,有没有补充看法?
杨晨旭:
我觉得宇千、煜贤、Tianzhu几位说得都很有道理。
在我看来,OPD 能够走红,也和当下强化学习基础设施的发展密切相关。早期缺少相关工具与 Swift 这类强化学习框架的支撑,大家自行实现 on-policy 方法难度很高。如今有了完善的基建支持,相关的研究和实践也变得更加丰富。
结合宇千刚才提到的持续学习,在多领域场景中落地 OPD,也离不开 MiMo 团队提出的 MOPD 方案。该方案开源之后,很多企业团队都开始采用这套更优的方式做模型能力融合。可以说 OPD 在学术界和工业界都具备很好的落地价值,这也进一步推动了它的爆火。
何秉翔:
在我看来,OPD 其实并不是全新的技术。煜贤学长早年开展的 MiniLLM,在算法层面就已经具备了清晰的雏形。在业界实践中,通义千问去年 5 月发布的技术报告里,也简要提及了 on-policy distillation,能看出业界很早就已经在落地这套方案。
其次,OPD 如今走红也恰逢合适的时机。一方面,当下开源模型数量众多,整体能力也逐步追上闭源模型。依托开源模型可以获取 logits,不再局限于黑盒蒸馏,为蒸馏相关研究提供了良好条件。
另一方面,OPD 本身具备很高的发展潜力。正如Tianzhu刚才所说,它依托稠密奖励的思路,也契合了强化学习领域的研究趋势。2024 年下半年 OpenAI 推出 o1 之后,不少团队尝试复现其技术路线,涌现出大量过程奖励模型相关工作。
大家普遍认为超长思维链依赖过程奖励训练,但这条路线逐渐暴露出问题,模型容易出现投机行为,同时相关数据也难以采集。
到 2025 年年初,DeepSeek R1 证明仅依靠简单基于规则的结果奖励,就能让强化学习取得不错的效果,研究方向也随之转向结果奖励。
经过上半年的探索,结合 RLVR 局限性等相关研究,学界开始重新思考,无监督奖励、伪奖励是否也能用于模型训练。在这样的背景下,dense reward 这条技术路线出来,重新把大家的注意力吸引过来。
最后,正如之前几位提到的,如今相关技术基础设施已经成熟,模型能力也大幅提升,不少领域的表现甚至超越人类水平。行业也产生了新的需求,希望模型能够实现自我迭代,从零散的环境信号、竞赛数据与历史经验中学习反馈,而 OPD 恰好能够匹配这类需求。
多重因素叠加,也就让 OPD 获得了如今这么高的关注度。
傅宇千 (主持人):
谢谢各位的讨论。
OPD 如何超越教师模型?
傅宇千 (主持人):
既然谈到 OPD 火爆的原因,接下来探讨核心问题:OPD 本质是蒸馏,其性能上限受教师模型限制,难以超越教师模型,各位认为如何实现 OPD 超越教师模型的能力?
我个人认为 OPD 的价值,并不体现在单一教师模型的性能超越上,而是在多教师 OPD 场景中,不同教师模型之间能够形成能力互补。这个思路也来源于过往强化学习领域做多任务训练的相关经验,在开展多任务强化学习训练时,将多个不同任务联合训练,能够观察到明显的领域泛化效果。因此我认为,借助多教师 OPD 的方式,完全有机会让模型能力超越单个教师模型。
大家是怎么考虑的?
黎亚轩:
我们此前关注过 EXOPD 相关研究,不少工作在基准测试中已经实现学生模型超越教师模型,其中一篇跟进过的 EXOPD 论文让我印象很深。
想要让学生模型超越教师模型,关键在于 OPD 要给出合理的优化方向。打个比方,如果教师模型传递给学生的优化方向正确,但更新幅度不足,我们就可以人为放大这个幅度,进而提升模型效果,这是我比较浅显的理解。
目前对于 OPD 为何能让学生模型超越教师模型,业界还没有形成清晰、统一的理论解释,相关论文也大多只是提出一些猜想。
傅宇千 (主持人):
我也看过 EXOPD 这项工作。它主要在模型差值上做了优化,借助差值外推或是不同模型参数外推的方式,让模型能力超越原本的教师模型。目前我也还没能理清背后的原理,但确实观测到了这样的现象。
Tianzhu:
结合实验经验来看,如果训练全程固定教师模型,最终学生模型收敛后,能力会和教师模型趋于一致。即便采用离线策略训练,最终的收敛效果也大致相近。
但训练过程中会出现特殊状态:例如初始阶段的学生模型,会在部分维度优于教师模型,同时在另一些维度存在短板,在线策略学习的过程中也会呈现出这样的特点。
学生可能稍微保留自身优势,同时学到教师模型的相关能力。但在我看来,这种效果并没有稳定保障,大多是实验调参时碰巧达到相应状态,不过这类现象确实能够观测到。
再来说 self distillation,还有 context distill 这类方向,它的实现思路更接近模型自我迭代。模型可以依托各类环境带来的 context,比如 coding environment、人类 feedback 等内容进行学习。
此时教师模型掌握着专属信息或是人类反馈上下文,学生模型以此为学习目标进行训练,训练完成的新学生模型又会成为新的教师模型,形成自我提升的过程。
这种模式下不存在固定的教师模型,所以我认为它在一定程度上,已经超出了大家最初所定义的OPD范畴。
傅宇千 (主持人):
对,感觉还是需要一些外部的信息,无论是环境的反馈还是人类的一些 feedback。关于Tianzhu刚刚提到的 self distillation,以及它和 RL 的结合,我们后续也会展开讨论。
杨晨旭:
我也这么认为,单纯依靠最初版本的 OPD,想要超越 teacher 其实并不现实。后续业界探索出了不少算法,其中自蒸馏的思路很有价值,引入额外信息确实能让模型习得新能力。
将 RL 与 OPD 相结合,也能进一步拓展模型的能力边界。实际训练过程中,把 RL 和 OPD 交替串联使用,最终效果会优于单独使用 RL。RL 有时会让模型的探索空间收窄,搭配 OPD 则可以重新拓宽探索范围。
多教师方案也是一个具备研究潜力的方向。我们前段时间发表了一篇名为 COPD 的论文,主要研究学生与教师共同进化。处于不同领域的师生模型可以互相指导,配合合理的 OPD 训练节奏,能够有效提升模型在全领域的综合平均性能。
何秉翔:
我认为不管是 OPD,还是更广义的知识蒸馏方法,其终极目标都是让学生模型逼近甚至超越 teacher。
但目前来看,无论是 SFT 还是 OPD,在多数通用场景下都很难做到这一点,甚至连追平 teacher 五成的性能都不容易。其中影响因素繁多,也难以量化,模型自身能力、监督密度、数据质量等都会产生作用。
目前在 OPD 的相关实验中,若将学生模型经过 RL 迭代后的版本作为 teacher,效果基本可以实现百分之百还原。而在部分领域的 multi-teacher OPD 场景下,不同能力之间基本不会出现冲突,部分领域还能形成相互增益,甚至出现小幅超越 teacher 的情况。
这也是知识蒸馏领域大家最关注的方向。至于性能差距究竟有多大、如何进一步逼近性能上限,还有大量问题有待探索。同时目前也无法确定,单纯对齐模型输出端的 logits 分布,是否属于高效的学习信号。毕竟 OPD 本质上只是依托 log p difference,也就是概率差值来完成学习。
顾煜贤:
我分享一下之前实验中的观察。我曾用模型 A 自身作为 teacher,再对模型 A 做蒸馏,最终指标实现了上涨,这种情况显然已经超越了原有的 teacher。
由此我认为,on-policy 本身就能够带来性能提升,具体效果取决于实验设定。当时使用的模型 A 并未经过 RL 训练,也没有执行过任何 on-policy 相关操作,分布还未收敛到局部最优,只是完成了 SFT,整体分布仍有优化空间。在这种前提下,经过 on-policy 训练的学生模型,性能大概率会优于未做 on-policy 处理的 teacher。
我认为这也正是在部分实验设定、部分基准测试中,能观测到学生模型表现优于 teacher 的原因。
傅宇千 (主持人):
针对煜贤刚才提到的,模型自蒸馏实现指标上涨的现象,我猜想这或许和无奖励强化学习的原理相近?整个过程并没有引入真实标注数据,模型只是不断提升自身输出的置信度,最终就带来了性能提升。
顾煜贤:
对,相当于你原来 Pass@k 它其实都是不变的,只不过你通过 on-policy 把 Pass@k 变成 Pass@1 了。
全词表 vs Top-K 怎么选?
傅宇千 (主持人):
刚刚讨论这个问题时,秉翔提到,现阶段的 OPD 向 学生模型传递的信息量偏少,我们一般基于 logits 做估计。针对这一点,目前也出现了新方法与实践。
近期 DeepSeek V4 采用了全词表的 OPD 方案。我们查阅它的 technical report 可以发现,其中关于 OPD 的内容,主要介绍了底层架构上的多项大幅优化。
这里就产生一个顾虑:普通研究者开展全词表相关实验,对硬件资源要求很高。是否存在替代方案,能够逼近全词表的效果?比如采用 Top-k 或是 Top-p 这类选取方式。
大家是否做过类似尝试。
何秉翔:
我们目前的研究范围相对有限,仅在数学和代码场景下对比了 sample token 与 Top-k 的差异。针对 Top-k,我们也开展了相应的消融实验,k 值最高设置到 128。
这套方案在实现上还有不少细节,目前可能暂时没法讲解得十分透彻。比如最终优化目标,究竟采用 teacher 的 log p 加权,还是 student 的 log p 加权,不同选择会让优化方向出现偏差。
总结来看,在数学任务中我们发现,sample token 能达到接近 Top-128 的效果。同时在我们测试的 16k 序列长度下,调整 Top-k 的 k 值,整体效果并没有明显变化。
对此我们也有一些思考:使用 Top-k 乃至全词表做蒸馏,正如 DeepSeek V4 中提到的,能够覆盖更全面、学习信号也更完整。
但是从某种程度上,选取 Top-k 词表中排位靠后的 token 进行监督,是不是也偏离了 OPD 的本意?
对大量不同 token 做监督时,teacher 本身对此也会存在判断不确定的情况,这类位置输出的信号会带有噪声,这就形成了 trade off。
另外,我们当前实现的 OPD 优化目标,其 advantage 与 log p 加权值大致成正比。词表中概率偏低的 token,对应的 advantage 本身就偏弱。
从实验结果来看,二者差距可达一个甚至两个数量级,因此这部分 token 并不会左右整体的优化过程。
黎亚轩:
那我接着秉翔的内容继续说。我们在 rethinking OPD 中做了消融实验,发现全词表方案并没有带来明显提升。
我也很好奇 DeepSeek 为何选择采用全词表。标准 KL 散度会以 student 的概率做加权,再结合 log p 的对数差值进行计算。当 token 概率 P 极低时,对应数值会变得很小,advantage 趋近于零,几乎无法产生有效梯度更新。基于这一点,我认为 Top-k 其实可以满足使用需求。
另外在我看来,Top-p 还有一处实现难点:Top-k 的张量维度是固定的,而 Top-p 选出的候选数量不固定,有时是 10 个、有时是 20 个,动态维度会增加工程实现难度。
我们还观察到,当 k 值设置得过小时,容易引发训练不稳定。我猜测在 agentic 这类长程任务中,训练不稳定带来的负面影响会被进一步放大。DeepSeek 选择全词表,大概率是为了保障训练稳定性,再依托自身成熟的 infra,顺利解决了全词表带来的算力与存储问题。
傅宇千 (主持人):
我们在 revisiting opd 的实验中也发现,教师模型对 student 采样得到的轨迹存在分布层面的约束。在 agent 这类长程任务,或是容易和教师模型产生分布偏移的场景中,训练不稳定的问题会进一步加剧。
结合相关实验来看,在这类不稳定场景下,适当调高 Top-k 的 k 值,能有效改善训练状态。不过当 k 值提升到一定水平后,继续调大带来的收益就会变得十分有限。
顾煜贤:
关于全词表,我之前推导过它的使用原因。全词表在优化目标上的期望是严格等同于 TML 公式的,这一点可以证明,并且它的方差严格更小,所以使用全词表是一个不会有损失的选择。
至于具体实现方式,DeepSeek 他们直接存储的是 hidden state,hidden state 相比于把整个词表都计算出来,存储量肯定更小,大概是几千这样的量级。他们还做了 Offload,具体就看需求了。
根据我自己的实验来看,全词表的效果要比单点好很多,不论是收敛速度还是最终性能。我认为还有一个原因,单点相当于只能给一个 token 传递梯度,而全词表相当于每个 token 对应的 head vector 都会参与最终目标的计算,至少每个 head vector 都被训练到了,这也会带来一定的帮助。
Tianzhu:
实际上 TML 采用的是 K2 loss的形式,K2 loss求导之后得到的 advantage 和blog是一致的,梯度上是对reverse KL的无偏估计。全词表方案的方差更低,所以理论上效果不会变差。如果表现不佳,大概率是实现问题,比如尾部 token 的数值精度不足。
从研究角度出发,可以考虑使用 JSD,它融合了 forward 与 reverse 两种形式,具备均衡性。部分任务中 reverse 形式未必能带来增益,比如 student 模型本身能力较弱的场景。另外 JSD 是有界的,整体训练过程会更加稳定。因此做研究时,JSD 会是更优选择,也可以将 JSD 搭配 Top-k 使用。
Top-k 存在固有缺陷是,训练步数增多后容易出现崩溃,因为它在前向计算和梯度层面都存在偏差。综合来看,如果配套的工业级 infra 足够完善,全词表方案会更合理,例如采用全词表 reverse KL 或是全词表 JSD。
傅宇千 (主持人):
确实就相当于全词表的话在效果上是有保障,但是就看性能与资源的权衡了。
Token-level 与 Sequence-level 损失差异
傅宇千 (主持人):
我们之前讨论的是单个 token 选用全词表还是单点估计,除此之外,Thinking Machine Lab 也提到其 loss 形式为折扣因子置零的实现形式。
loss 分为 token-level 与 sequence-level 两类,本质问题是当前 token 与对应梯度是否会影响后续 reward 和轨迹,以及是否需要考量该影响。
针对这部分内容,大家可以发表看法。
顾煜贤:
我试过将折扣因子设成不为零,明确来说没有效果。我之前也看过知乎上的相关文章,其他人做过同样的实验,结论也是无效。我认为原因可能在于,长程轨迹下 token 的奖励估计存在问题。
一方面,长程轨迹建模的方差过大。首先,长程依赖无法推导出等价的全词表形式,只有临近的第一个 token 才能适配全词表计算。而长程轨迹本身方差极大,方差会在一定程度上抵消其带来的收益。
我后来在代码中也做过实验,将衰减系数设为非零时,观察到 reverse KL 散度下降,我监测了 student 和 teacher 模型估计出的 reverse KL 数值,确实是降低的,但 benchmark 指标没有提升,最终结论也是没有实际作用。
傅宇千 (主持人):
我们也做过推导,其方差上界会持续增大,相较单 token 方案劣势明显。该方案存在一处优势:倘若 teacher 模型存在缺陷,在某个 token 之后输出错误 feedback,采用 sequence-level 能够在一定程度上缓解该问题。不过该结论仅为现象观测,模型性能并未得到明显提升。
何秉翔:
我十分认同煜贤学长的观测结论,token-level 与 sequence-level 的核心区别在于是否拆分 future reward。相较于 sequence-level,token-level 属于有偏估计,但其最坏情形的方差边界更紧凑,不会出现 sequence-level 方差大幅走高的问题。
在文本长度仅数 K、十几 K 的场景下,二者效果差距不大;但面向上百 K 量级的 agent 场景时,方差问题直接决定方案可用性,偏差与方差的取舍需要纳入权衡。
另外我们在有效的 OPD 实验配置中观测到,advantage 主要集中在 student 与 teacher 重合的高概率 token 区间,该过程等价于隐式的 token 权重重分配,落在重合区间之外的 token 贡献已通过 KL 约束得到抑制,因此显式增设 discount factor 带来的收益远低于预期。
黑盒 OPD 怎么做?
傅宇千 (主持人):
感谢各位老师的分享。
接下来,我们继续围绕 OPD 原理展开讨论,此前 Tianzhu 学长也提及针对 black-box 的 OPD 相关研究。
当前大家较为关注,针对闭源模型落地 OPD,有哪些可行方案实现 black-box OPD,请Tianzhu学长分享下这方面的相关实操经验。
Tianzhu:
我们去年开展过相关探索,此前落地 black-box OPD 一直缺少效果可靠的方案,该方向实现难度较高。
我们选用简易思路:在训练完 student 模型后额外训练一个 discriminator,用来区分 student 与 teacher 的 response,再依托 discriminator 输出打分充当 student 的 reward。
实验结果显示,该方案在偏向 chat 和 math 的实验配置中能够带来指标提升,但同时出现了 GAN 训练里的经典缺陷。
第一是训练稳定性不足,训练阶段 student 生成 response 的长度会频繁震荡。这也比较好理解,discriminator 容易依据文本长度区分两类回复,模型生成文本过长时会被约束缩短,文本过短时又被引导加长,最终造成长度震荡,该问题本质和 GAN 的训练不稳定特性同源。
第二,当前采用 sequence-level 稀疏 reward,依托整段序列完成判别;若改为按 token 训练 discriminator、逐 token 为 student 赋值 reward,模型极易训练崩溃。该现象合乎逻辑,很难依托单个 token 学习精准的奖励信号。
black-box OPD 相关尝试仍有待优化,算不上最终可行方案。从实现逻辑来看,该思路具备合理性,和 GAIL 相近,但想要更落地的 black-box OPD,后续仍存在大量研究探索空间。
顾煜贤:
我感觉或许可以借助 context distribution 实现该方案:调用目标模型本身,配合 Gemini 生成的 prompt,再引入 OPD 完成优化,以此实现 black-box 落地,该思路目前还没有落地验证。
黎亚轩:
我近期查阅了一些 black-box OPD 相关工作,其中包含此前热度较高的tianzhu学长的GAD,以及新近的 Rubric OPD。
黑盒场景的核心难点是,缺少直接手段量化 teacher 与 student 的分布差异。
Rubric OPD 的实现思路为:以 teacher 充当评判主体,逐条甄别 teacher 和 student 生成 response 的具体差异并赋予权重,再由 teacher 担任校验模型完成打分,最终加权汇总结果。
该方案持续迭代后,很容易演化成和 RL 中奖励模型相近的形态。
傅宇千 (主持人):
不管参照煜贤还是亚轩的思路,高质量构造 rubrics 十分关键。依托合理的 rubrics,或者说搭建完备的 context 空间,让教师能把他的能力传给学生也很重要。
Tianzhu:
这类方案大多是将 black-box 的 teacher 等效为 reward model 使用,但想要充分复用同一个 prompt 下 teacher 原生输出的 response,难度比较高。
何秉翔:
我自己其实对黑盒了解并不是特别多,可能像 SFT 是一个比较经典的一个,就我只利用 teacher 的 response,能不能做一个比较好的知识蒸馏,然后像去年年底也是像 Tianzhu 师兄这边的一个 GAD,我感觉也是走黑盒这条路一个很有意思的一个尝试。
就在这个之前,我对黑盒的认知是,探索如何能够利用充分利用轨迹来把 teacher 的知识去传给学生,如果黑盒没法获得模型内部的一些东西,甚至输出的 logits 都没有的话,那似乎怎么去利用这个 teacher 输出的 response 就是一个比较好的点。
就像刚刚亚轩提到,就是有没有可能我去用 rubric,我去让这个 teacher 去通过他的一些 test time scaling 把能力去诱导出来,或者去充当一个 reward model,甚至直接简单输出一个 response 也好。核心在于怎么把这个知识给传递给学生。
另外刚刚咱们也提到用 TOP K 或者是全词表,就其实是对于怎么利用这个监督信号的探讨。其实有没有可能更激进一些,就是像不同的 Family 之间不同的词表,如果都有 logits,我怎么去利用,这个时候就会需要碰到很多种跨词表、跨 tokenizer 的这种问题。
那进一步的假设,我之前也看到过有一些那种我去利用 teacher 的内部的 attention 的一些激活信号来去做某种蒸馏,那么这个时候如果 teacher 和 student 他的内部的 block 的 hidden size,或者说 depth 都不太一样,这件事又怎么去利用,其实我了解的这方面工作并没有很多,所以我感觉其实还有很多东西可能是可以研究的,核心的目标就还是我怎么让这个学生就无限的接近这个 teacher 甚至超越。
跨模型 / 跨词表 OPD
傅宇千 (主持人):
刚刚秉翔也提到了不同模型族教师的蒸馏问题,这也是当下研究的关注点。实际开展 OPD 时,学生与教师往往分属不同模型家族,会出现词表不统一、分布差异大等各类难题,想请教各位有什么可行的优化解决思路。
此前 Lightning OPD、Rethinking OPD 相关工作都给出一个思路,在师生分布差距较大时,先通过一轮热身 SFT,让学生模型初步贴近教师分布后再执行 OPD;但针对词表无法对齐的痛点,目前还缺少成熟的解决方案。
Tianzhu:
词表对齐同样是很有探索价值的研究方向。
早前 Hugging Face 有一篇paper,但实测落地效果不理想,痛点在于跨模型词表重合度过低。我记得中科院自动化所前段时间也出过一篇相关论文。整体来看,异构词表对齐和黑盒蒸馏一样,目前仍属于尚未被充分探索完善的研究方向。
傅宇千 (主持人):
Tianzhu提到的自动化所相关工作就是我们的《Revisiting OPD》。我们的处理方案比较简易,直接将无法对齐的 token 做 mask 屏蔽处理,想听听各位有没有别的看法。
黎亚轩:
我比较好奇跨词表、跨模型家族蒸馏的问题,不同家族模型容易出现推理范式不一致的问题。倘若师生模型的思考逻辑相差过大,OPD 最终效果或许还比不上单纯 SFT,这点我暂时没有定论,想和各位学长探讨交流。
何秉翔:
我还有一个思考方向,结合我们目前的实验结果来看:即便师生共用一套词表、不存在词表不匹配问题,在模型参数量规格差距较大时,OPD 效果依旧不理想。
也就是说同词表场景的适配问题尚且没能妥善解决,跨词表蒸馏的难度自然更高。而面对部分闭源模型,我们甚至无法获取其词表信息,当下最稳妥的主流方案,似乎就是采用黑盒思路,依托 SFT 完成蒸馏。
傅宇千 (主持人):
可以再详细说一下尺寸不一样,带来的性能的损失。
何秉翔:
那我具体展开聊聊模型尺寸差异引发的性能损耗,这也是我们课题最初的研究动机。
我们原本没计划系统性剖析 OPD 内在特性,最初只是想要复现 Thinking Machine Lab 博客里的实验效果。实验里先用同规格 1.5B 模型,自行经过 RL 训练得到 Teacher,再用 OPD 蒸馏同尺寸 1.5B 学生模型,能够高效恢复 Teacher 八成以上性能。
后续我们更换同源 7B 强 Teacher,该模型综合能力远优于 1.5B 版本,可在用它蒸馏 1.5B 小模型时,OPD 训练全程收敛停滞,学生很难吸收高性能 Teacher 的知识。我们的论文正是围绕该现象展开,探究大跨度参数量差距下,强教师无法通过 OPD 有效赋能小模型的底层原因。
杨晨旭:
秉翔我有个问题,你们有没有试过用 30B、上百 B 量级的大模型去蒸馏,效果会不会优于 7B 蒸馏 1.5B?模型尺寸差距和性能恢复效率之间是否存在某种关联?
何秉翔:
这个问题提得很好。我们在观测两组实验效果差异后补充了对照实验:一组是 7B 规格的 Skywork 经过 RL 之后作为 Teacher,蒸馏同尺寸 7B 学生,OPD 训练效果正常;换成 14B 大模型蒸馏 7B 学生,又复现了之前的失效问题。
不过 30B 及以上档位的对照实验我们还没开展,现有结论存在局限。另外还有一个值得留意的地方,qwen3 的技术报告里提到,它的小参数版本基本依靠 SFT 叠加 OPD 训练而来,在跨尺寸蒸馏上落地效果出色,这点也让我比较感兴趣。
多教师 / 多领域 OPD
傅宇千 (主持人):
好,那跨尺寸相关内容先到此。
接下来咱们聊一下 OPD 原理另一个相关问题:OPD 优势是可做多领域知识融合。我们落地的多 Teacher OPD 方案是一个领域对应一位 Teacher,完成多领域联合蒸馏;还有另一种多 Teacher 范式是单个领域同时接入多位 Teacher。
那在做 multi-teacher opd 时,对于单个领域,我用多个 teacher 同时去学,这两种不同的 multi-teacher opd,它是不是会发生一些,或者是不是会观察到一些专家冲突的问题,然后冲突怎么去解决?大家有没有在实际的 multi-teacher opd 当中观测到类似的问题?
我这边先来分享一下吧,我们之前有做过,不管是多任务 RL,还是多 Teacher OPD,现阶段都缺少一套可量化、能在训练前预判 Teacher 间知识冲突程度的指标。
我们实验发现,不管是多任务场景还是 OPD 多教师蒸馏,各个 Teacher 之间是出现知识冲突、还是互相增益提升泛化能力,事前都难以预判,这也是我们当下的难点。
杨晨旭:
我感觉是 multi-task 那种,多个 domain 的冲突还稍微弱一些,直接部署多个 teacher,对于不同的任务就直接去 call 一下它相应的 teacher,直接 mix 在一个 batch 里去训。可能任务之间差异比较大,然后他们本身冲突也会比较小。
我感觉,multi-task 上 mopd 它一定程度上为了解决直接去 mix 的 RLVR 效果不好的一个问题提出的。至于单个 task 上用不同的 teacher 可能是会有一些问题,我个人觉得是可能冲突会更严重一些,毕竟在同一个问题上,甚至相似的一些问题上,可能各个 teacher 他的一个 Pattern 不太一样,反而会在同一个轨迹上有一些互相冲突的一些情况存在。
我觉得它的实际的一个意义没有在多个 task 上去做 opd 意义更大一些。就假如是单个 task 的话,为什么不直接用最好的去做 opd 就可以了。
OPD 与 RL 的关系与区别
傅宇千 (主持人):
我刚刚有关注到,你说我们做 multi-teacher opd 的时候它其实是会比 MIX-RL 要好,这一块不知道有没有可以更深入去讲。
因为我了解到在做 mult-teacher opd 之前,大家去融合能力的方式其实是去做 MIX-RL,这两者之间有什么联系,不知道你能不能讲一下。之前Tianzhu学长也有提到说 rl 和 opd 还是认为是不太一样的两个方法,可以再去深入的讨论一下。
杨晨旭:
这是我们在自身工作中发现的一些现象,前段时间我们做了 COPD,在同一批多领域数据上分别进行混合 RLVR 与 MOPD 实验,MOPD 效果确实更优。
MIMO 的报告中也提及 MIX-RL 存在冲突问题,我认为 OPD 会更适配持续学习。前段时间还有一篇 SDFT 相关工作,思路和 MOPD 相近,分步逐个任务训练,模型遗忘程度更低。
傅宇千 (主持人):
没有,其实就是想讨论一下 MIX-RL 和我们所说的 MIX- OPD 二者之间的区别。后续 Tianzhu 学长也可以补充,谈谈您认为二者存在哪些本质区别,以及为什么这些区别使得现在大家更多选用 OPD。
Tianzhu:
我认为融合方案的核心在于 OPD 收敛速度快。单独 RL 训练单个任务耗时漫长,且训练轮次越多灾难性遗忘越严重;OPD 仅需很少的训练步数,就能快速习得 RL 任务的能力,依靠少步数训练来降低遗忘,这是关键优势。
MIX-RL 和 MOPD 实验设定相近,TML 博客里也验证过先对模型做 RL、再用 OPD 回灌知识的方案,核心亮点就是凭借快速收敛,低成本获取 RL 增益。除去算力与训练时长,遗忘问题是另一关键,SDFT 等相关论文也佐证了这点。
从训练目标与落地实现来看,RL 和 OPD 本身存在本质差异。TML 博文把 OPD 类比 RL、套用奖励概念,更多是便于理解或是贴合行业热点,深究底层逻辑,OPD 本质更像是拟合目标分布,二者优化目标并不相同。
我想听听各位实操经验,比如 RL 串联 OPD 后,域外泛化、模型遗忘等实际表现,我近期也在跟进相关研究,借此交流参考。
傅宇千 (主持人):
这里我可以分享一下,我最近在做一些实验,我们发现 RL 的泛化性会比 OPD 更强,实验现象是这样。
我的分析是信号来源不一样,OPD 正如刚才 Tianzhu 所说,目标是拟合教师,而教师并不是任务环境动力学的完美表征,只是当前任务的一种映射。
OPD 的泛化能力取决于教师和环境真实反馈的贴近程度。但 RL 使用的奖励是真实基准真值,本质在学习环境动力学,不同环境的动力学存在共性,因此 RL 泛化效果更好,这是我的观点。
顾煜贤:
我很认同宇千的观点。据我的实验观察,即便教师输出可以当作稠密奖励,但这份奖励并不完善。
我在小模型实验里发现学生很容易出现投机拟合的问题:OPD 依托反向 KL 优化,是把教师视作奖励信号,让学生生成教师偏好的内容;而语言模型本身偏爱重复文本,重复段落输入后模型 PPL 偏低。
日常经过 SFT 与对齐的大模型采样很难暴露该缺陷,但用偏弱的小模型做 OPD 蒸馏时,小模型就容易放大教师本身的短板、刻意投机适配不完美的教师输出,这也是 OPD 泛化表现比不上 RL 的一大原因。
傅宇千 (主持人):
非常认同刚才的观点,我们实验里也观测到了这种投机拟合现象,查看样本后确实就是内容重复的问题,即便文本重复,教师模型依旧会给出很高的概率。
何秉翔:
煜贤学长、宇千提到的问题我们实验里也完整复现了,用基座模型做学生开展 OPD 训练时,小模型极易投机拟合、生成重复文本。
另外我们近期基于 MiniCPM5,在代码、数学、指令三四个领域开展多 Teacher OPD 实验,学生可以完整追平 Teacher 效果,工业落地收益突出。
一方面归功于Tianzhu学长所说 OPD 训练高效;从工程落地流程来看,传统方案要么混合 RL、要么串行分步 RL,串行 RL 存在链路瓶颈,前序任务训练出错会连锁拖累后续任务,跨团队协作落地成本高。而采用 OPD 合板方案后,各领域团队可以独立迭代优化自身数据与Teacher,各司其职。
我们猜想多 Teacher OPD 能够有效缓解灾难性遗忘。我同样认同 OPD 与 RL 的环境动力学存在本质区别:各领域经过 RL 产出 Teacher 后,OPD 学习的是稠密化的中间思维范式信号,并非 RL 那种基于最终结果的稀疏奖惩。
在多目标优化场景下,对齐思维范式更容易收敛至帕累托最优。对比 GRPO 依靠多条采样轨迹的正误做0-1离散奖励,梯度波动剧烈、混合训练稳定性差,OPD 优化过程平缓很多,GRPO 一旦采样全错或个别样本异常就会产生大幅梯度扰动,造成Mix-RL训练震荡。
我们还有一组对照实验佐证 OPD 优化逻辑:以大能力强模型为Teacher、小参数弱模型为学生时,OPD 训练反而会造成学生性能大幅下滑。
这也说明 OPD 优化目标只复刻教师的思维范式,不直接优化下游最终效果;思维范式优质则学生能力提升,范式存在缺陷就会被模型钻空子投机拟合。
黎亚轩:
我记得晨旭学长在 COPD 里提到过一个现象:模型先 RL 训练数学任务,再串行 RL 训练代码任务,最终效果不佳,因此依靠 OPD 完成多任务合板。
另外我们做 OPD 后发现,稠密监督并不是没有弊端。原因在于回复文本只有前面一部分内容有效,后文大多是噪声内容,容易干扰训练效果。
像 Agentic 任务,我怀疑 OPD 的适配效果有限。千问近期发文也提到, Agentic OPD 实测表现一般,业内也衍生出各类优化手段改良 OPD;而Agentic RL 训练方案发展成熟。
整体来看 RL 在这类任务上效果会更出色。
杨晨旭:
我觉得刚才大家提到的效率这个点很有意思。除了混合 RL、OPD 之外,过去还有 Model Merging 这类免训练的模型合并方案,但这类方案效果普遍最差。
OPD 相当于处在中间的折中位置:混合 RL 需要海量训练数据,串行训练容易出现遗忘;OPD 训练效率高、收敛速度快,模型还没发生明显旧知识遗忘就能习得新领域能力,综合表现远优于免训练的 Model Merging,所以现在业界落地使用更加普遍,刚好卡在实用性最优的区间。
傅宇千 (主持人):
谢谢各位精彩的讨论。
既然聊到 OPD 和 RL,我们前面说了二者的区别,另外 MIMO 提出的 MOPD 已经把 OPD 的稠密监督信号和 RLVR 的稀疏奖励信号做了融合,这套方案在他们的报告里实现思路相对简洁。
那不知道后续会不会出现更优的改进方案,让两种信号融合更稳定、进一步提升模型性能。大家有没有相关落地尝试或者研究成果,可以分享一下。
何秉翔:
这块我们之前也试过相关实验:一开始用基座模型作为学生开展 OPD,实验效果不理想。
我和亚轩当时猜测,缺少无法被投机拟合的真值奖励来校正模型是关键问题,于是做了简易尝试,直接叠加0-1离散奖励,没有额外权重调参,最终提升有限。
相关内容我了解不算深入,可能晨旭这边的自蒸馏 RLVR 会更熟悉。我顺带聊聊个人对 OPD+RL 类算法的看法,现在行业都聚焦后训练流水线:早年主流是 SFT+RL、RLHF,25年流行 RLVR,如今 OPD 被嵌入后训练流程,但各团队落地位置不同,比如有的把 OPD 放在中间,不少方案则将 OPD 作为最终合版步骤,流水线选型是当下热点,小型实验室很难完整遍历各类对比实验。
在我看来,SFT、RL 以及各类黑白盒蒸馏,本质都是对策略模型的输出分布进行调整。学生模型原生在词表具备固定分布空间,不同 Prompt 会催生差异化概率分布,各类算法就是对 token 概率做差异化调控:SFT 偏向覆盖长尾 token,补齐低频样本概率,属于 Mode Covering;OPD 依托策略梯度、反向 KL,还有 RL 优化逻辑偏向 Mode Seeking,侧重拉高高频主流 token 的概率。
各类算法本质等价于奖励塑形,按系数缩放单个 token 的优势值,核心都是驱动模型从原始分布向目标分布偏移,只是优化路径与训练动力学存在区别;只要模型参数量充足、训练数据足够,不同算法最终能够收敛至相近最优解。
杨晨旭:
感谢秉翔刚才提到我的工作,我做的 OPD 与 RL 结合主要落地在自蒸馏场景,传统 OPD 融合方案我没有深入尝试。
我发现 OPSD 类方法的效果高度依赖数据与任务类型,做多模态实验时直接套用 OPSD 容易出现信息泄露:生成后半段模型反复依赖训练阶段的特权信息,但实际线上推理拿不到这类信息,这也是我研发 OPD+RL 融合方案的出发点。
OPD 提供稠密监督信号,我们拆分两路优化逻辑:依靠 RLVR 真实标准答案做结果约束把关,OPD 仅用来调控参数更新幅度。这套思路只在自蒸馏场景验证,和 MIMO 多专家架构的 OPD+RL 不一样。
直接加权融合两种信号效果很差,根源是两类梯度量级不一致、超参调试难度高;换成 LSD 方案,把相加融合改成相乘融合,利用证据比值缩放优势值,能够有效缓解稠密 OPD 信号和稀疏 RL 信号之间的优化冲突。
Self-OPD / In-context OPD
傅宇千 (主持人):
既然秉翔刚提到 self OPD,我们就顺着这个话题往下聊,相信直播间不少朋友和 OPD 领域研究者都很关注。当下很多人的研究方向就是 self OPD 以及 in‑context OPD。
我想请教大家相关看法,同时我有个疑问:晨旭刚才提到 self OPD 训练时,学生容易复述特权信息,这块有没有稳妥的解决思路?一是从 OPD 算法层面怎么优化,二是落地细节怎么处理。
杨晨旭:
我们最开始试过不少办法处理该问题,但效果始终不理想。SDPO 在附录里给出过方案,大概是掩码掉生成开头部分 token 用来规避特权信息泄露,我们实测、调整 top-k 等各类参数后,在多模态场景下泄露问题依旧存在。
正因如此,我们选择把优化方向和更新幅度做解耦,让 OPD 不再直接改动学生模型分布,转而间接调控梯度更新幅度,充当 RLVR 的辅助约束,这是我们现阶段的探索思路。
顾煜贤:
我目前刚起步研究,也碰到不少难点。如果把 in‑context OPD 视作一种持续学习方案,我还是倾向持续学习需要将知识固化进模型参数。
当下持续学习大致分成两大路线:参数更新派、免参数更新派。
近期免参数路线热度很高,像 Claude Code 依靠外部技能库调度,不靠微调参数就能落地一部分持续学习能力;而对于参数更新路线,Self-OPD、OPCD 是落地潜力很高的方向,核心难点在于怎么用好模糊的奖励信号。
传统 RLVR 需要和环境交互、依靠量化数值奖励才能完成优化,而 OPCD 依托上下文,借助模型把模糊反馈转化为稠密监督信号。这也是它适配持续学习的关键。
Tianzhu:
我很认同煜贤的看法,OPCD 也就是 On-Policy Context Distribution,更适配难以获取 0-1 离散奖励的场景:任务结果无法核验、反馈多以文本形式给出时,把反馈放进上下文做蒸馏会更合适。
另外顺带一提,多篇冠以 Self 开头的自蒸馏论文,命名和实际落地内容存在偏差。自蒸馏定义宽泛,像 STAR、先 RL 微调模型再 OPD 回灌参数这类方案都能算作自蒸馏,却没有用到上下文学习;但实际上他们的核心是吸收上下文信息,所以相关论文的命名并不严谨。
结合之前讨论,上下文范式极易出现模型投机拟合的根源在于:学生复刻教师分布,但教师依托上下文生成的输出分布本身没有可靠性保障,不能默认带入上下文后教师效果就一定提升。我自己的实操经验来看,将上下文提炼成高层抽象条目能更好改善这个问题。
如果直接堆砌学生过往完整的采样轨迹,模型很容易投机重复原有内容;先对原始轨迹提炼总结,转化为高阶指导性经验知识是可行思路。模型经过预训练后,能够遵照高层指令规范输出,但杂乱无章的原始答案不在模型的有效学习分布内,会导致教师生成的分布偏移失真。
《Self Distillation Zero》这类文章给出优化思路:收集教师纠错类样本、针对性微调教师模型,以此保障上下文搭配教师后的输出分布有效。这也是上下文蒸馏和常规 OPD 的关键差异。
标准 OPD 使用规范 Prompt,教师整体输出稳定可控;但随意拼接上下文时,被上下文触发的教师分布质量无法保证。
傅宇千 (主持人):
我补充一点看法,很认同Tianzhu的观点。这类问题根源往往不在 OPD 算法本身,而是 Prompt 设计。自动提示优化(Automated Prompt Optimization)正是对应的研究方向,今年 ICLR 收录的 GEPA 就是代表工作,核心思路是通过优化 Prompt 来提升模型表现。
我们复现 GEPA 相关实验时发现,优化后的 Prompt 不能过于细碎、不能逐条适配单样本;相较定制化 Prompt,Tianzhu刚才提到的高度抽象、条目式的种子 Prompt 效果反而更好,这个结论也合乎逻辑。
顾煜贤:
我再提一个问题,OPCD 是落地持续学习的一类算法,但我科研目前卡在缺少适配的实验环境、标准基准与数据集。想请教各位,研究这类持续学习该选用什么评测环境?
何秉翔:
顺着煜贤的问题、结合刚才 Self-OPD 的话题,我也比较认同 Tianzhu的观点,上下文是关键本质,各类先验信息都可以塞入上下文,既能放入待内化的知识点,也能填入历史错误轨迹、环境反馈、工具报错等内容,依托上下文开展蒸馏逻辑合理。
不过我们实操发现,小模型落地该方案短板突出:小模型上下文理解能力有限,堆砌详细日志、完整工具轨迹等海量上下文信息非但没法提效,反而分散注意力、拖累下游效果,部分场景空上下文表现反而更优。
反观我们用 Gemini3-Pro 仅推理阶段拼接上下文,实测效果出色。这就引出选题困惑:OPCD 相关持续学习研究,该选用小模型还是大模型?
小型实验室、高校受算力限制只能基于小模型开展实验,但小模型上得到的训练规律与动力学特征,往往很难直接迁移到大参数量前沿模型。
傅宇千 (主持人):
我插一句题外话,想请教煜贤师兄:现在业界同名的 Continual Learning 实际分成两条完全不同的技术路线,我对此一直存有疑问。
第一种就是依托 In-Context Learning 的上下文式持续学习,典型代表是混元 CL-Bench:预训练数据不含任务相关知识,推理阶段把整套完备规则、自洽说明全部塞进输入上下文,模型仅凭即时上下文里的新增信息完成决策、落地新知识。
第二种就是咱们当下围绕 OPCD、Self-OPD 讨论的参数迭代式持续学习:按顺序串行学习多领域、多任务,完成一个 Domain 再迭代学习下一个 Domain,或是面向用户做个性化增量学习、随用户数据流迭代优化模型参数。
我想确认下这两种同名 CL 的本质区分边界。
顾煜贤:
目前行业本身没有严格统一的界定,我认同你的划分,大体就两类。一类好比直接给到一整本资料,模型仅凭上下文当场读取使用新知识。另一类就是分批依次接收任务,循序渐进迭代优化、持续精进。
我理解 OPD 更适配第二种持续学习范式:模型和环境持续交互、不断接收新增反馈,循序渐进迭代更新参数、把新知识内化进权重。在我看来,OPD 更适配持续交互、持续接收环境反馈的场景;其余在线学习、别的持续学习落地场景,则需要搭配其他算法方案。
Tianzhu:
虽说都叫 continue-learning,但最终想要达成的目标差异很大。拿 TML 相关工作来看,它们更偏向做 personalize,用到 LoRA,相关后续讨论也和 Tinker 的实现方式挂钩。
这类方向相关工作不少,像后续 OpenClaw-RL,核心逻辑都是基于用户与模型交互产生的 preference,再把信息回写到模型权重里,比如为单个用户单独训练一份小 LoRA。
但在我看来,这类个性化任务依靠 context 方案基本就能落地。比如 OpenAI 的 memory 能力,个性化记忆究竟有没有必要写入模型权重,目前还存疑。
另一方面,continue-learning 还有一类是持续适配时效性增量数据,也就是给模型注入近期新知识、迭代存量知识库,这也是很主流的持续学习路线。
第三种则是持续接入全新任务,新增任务的数据分布和原有数据偏差明显,coding 任务就是典型。模型离线基于 Training data 完成训练上线后,现实落地会碰到大量 OOD 数据与陌生新任务。
研究难点就是在不破坏原有分布的前提下,持续把新任务、新环境、用户全新交互习惯等信息融入模型,我认为这条研究路线最有价值。 产品(例如 CC)正式上线后会产生海量 OOD 用户数据,数据体量与分布跨度已经超出 context 承载上限,没法只靠上下文实现知识内化。
这也是当下缺少公认 continue-learning bench 的关键原因:coding 评测任务长、难度高,学术界很难批量跑分,大厂内部落地方案又不对外披露。但 coding 场景十分适合开展持续学习研究。
黎亚轩:
我比较好奇一点:即便有 continue-learning bench,不同模型跑出来的结果也很难横向对标。现在 self distill 大多基于小模型实现,普遍存在投机拟合、特权信息泄露的问题。
如果换成 DeepSeek-V2 这类能力拔尖的开源大模型做推演,bench 指标大概率会明显走高。
Tianzhu:
我觉得原因可能在于,目前开源和闭源模型在 follow instruction 的能力上差距明显。使用 CC 就能发现,它的 instruct 遵循能力要强很多。因此在 continue-learning bench 中,直接把内容放入上下文实现持续学习的效果,和模型对 context 的 Utilization 利用能力高度相关。
OPD 未来发展方向与落地场景
傅宇千 (主持人):
接下来我们简单聊聊 OPD 后续发展方向。
Tianzhu:
在我看来,OPD 往后大概率会成为训练 pipeline 里的配套工具。当下主流训练都围绕 RL、RLVR 展开,RLVR 很难突破 oracle reward 的上限,现阶段 OPD 更多起到辅助补齐的作用,未来能不能在通用 reward 场景做出突破还不好下定论。
落地层面,像千问借助它做小模型蒸馏,也是大厂早期落地 OPD 的核心诉求,小模型蒸馏会是 pipeline 里关键一环。
从持续学习维度来看,Self OPD、OPCD 是重点方向:模型上线后和真实用户持续交互,源源不断产出轨迹与 OOD 数据,这批数据经由上下文蒸馏回灌迭代模型。
我们之前 OEL 论文重点讨论过该痛点:用户交互数据很难完成完整全量 rollout,大多只能依靠 partial rollout 拟合 reward,而这正是 OPD 的优势场景。
Self OPD、OPCD 不用完整推演至末尾获取最终 0/1 reward,依托上下文约束的 Teacher 就能在推演中途提供学习信号。因此我很看好 OPD 在线学习场景,能够实现优于传统 RL 的效果。
另外我近期也在调研非 RLVR 的通用任务,探索 Self OPD / OPCD 在陌生场景的差异化效果,目前行业还没有统一结论。
黎亚轩:
我对 OPD 发展感触很深。OPD 已是成熟的算法框架,早在 2023 年煜贤学长就在 MiniLLM 相关大模型工作里落地了 OPD 思路,加上千问 3 依托 OPD 完成小模型蒸馏的成熟工业落地,现在每周差不多新增六到七篇 OPD 相关论文,基础改动的创新空间已经不大。
在我看来值得深挖的有两条路线:第一是 RL 与 OPD 融合,像晨旭学长团队的 RLSD 工作就做得很出色,这个落地前景很好;
第二是多教师蒸馏融合,目前业界常用 OPD 做模型合版,但把多个 teacher 的能力高效凝练到单个 student 里难度很高,同团队的 COPD 就是该方向代表,多师协同蒸馏还有充足的研究余地。
顾煜贤:
我个人更看好 OPCD 在 continue-learning 方向的落地价值。我本身偏向全参数训练路线,后续打算依托该方案搭建具备持续学习能力的模型或是 Agent。
单从 OPD 算法本体来说,不管是稳定性优化、各类任务指标刷点,可挖掘的改进空间已经比较有限。未来的重点不在算法迭代,而是拓展落地场景,像前面提到的模型合版、continue-learning 这两个领域,仍留有充足的研究空间。
杨晨旭:
在我看来,当下学界围绕 OPD 更适合深耕自蒸馏相关内容,未来前景大致分成两条路线:第一种偏向易落地,大多是算法层面的微调优化,思路精巧、叙事完整,很受学术论文青睐,但实际性能提升有限。
真正贴合工业、基座模型团队攻坚的是高难度方向,比如黑盒 OPD、跨词表 OPD,落地门槛很高,一旦实现突破,行业影响力和模型增益都会十分可观。
何秉翔:
在我看来,想要研判 OPD 后续发展,要先梳理现有方案的局限。OPD 最初凭借密集 token 级 dense-reward 实现高效训练、收敛速度优于 RLVR,看似是无成本的优质优化,但这套密集监督并非免费午餐。
结合 Revisiting OPD 相关结论,我们同样观测到长上下文场景的明显缺陷:随着学生自主生成的前缀不断变长、轨迹持续偏离教师分布,教师输出的监督信号噪声显著抬升、熵值偏高;若强行让学生拟合可信度不足的 token 监督,极易造成梯度崩坏。
针对长上下文 OPD 痛点,Agent 落地场景需要针对性算法优化,Cursor2.5 就采用局部 Self-OPD 方案,通过截断生成区间规避超长轨迹带来的 reward drift 问题。
在 OPD 落地前景上,我和 Tianzhu 观点保持一致:OPD 本质属于知识蒸馏技术,核心价值聚焦已有知识迁移,很难突破模型原有能力边界。
落地主要划分两大场景:第一,工业后训练流水线,依托 OPD 做模型合版,对比 Mix RL 相关方案训练效率更高,同时在性能修复、缓解灾难性遗忘上表现突出;
第二,大模型蒸馏小模型、端侧轻量化落地,SFT+OPD 大概率会成为行业标准化训练范式。
不过工业端后续是否长期沿用 OPD 合版路线仍存变数:RLVR 依托结果式稀疏奖励,更有机会拓展模型原有能力边界、提升泛化能力,实际效果还需要持续验证。
除此之外,OPD 相关工作开拓了全新研究思路:数学、代码任务可依托任务专属离散奖励,但通用域缺少定制化稀疏奖励,业界普遍依赖生成式奖励模型做打分。
由此衍生新思路:借助 Context Distillation,将参考答案、环境交互反馈全部拼接进上下文,让模型依托上下文的内隐信息完成自监督学习,这条路径也为 Self-Evolving 开辟了全新研究维度。
傅宇千 (主持人):
我主要有两点看法。第一,文本反馈是 OPD 很关键的落地场景,Tianzhu 和秉翔刚才都提到了。在 Cursor2.5 落地之前,工业界很少能拿出 self-distillation 落地见效的实例,Cursor 借助该思路基于用户交互优化模型行为模式,落地价值很高。
参考它过往针对 Tab 功能,采集用户操作决策做 on-policy 训练的方案,后续它很有可能把用户使用过程中的行为数据,通过 self-distillation 蒸馏进自家 Composer 模型。
第二是效率与 partial rollout 方向,和 Tianzhu 的观点一致。我们近期实验发现,仅针对一段回复靠前 10% 内容做 OPD,最终效果就接近全量文本做 OPD。
背后两点启示:一是轨迹开头 10% 基本锁定后续生成规律;二是长周期 Agent RL 训练不必完整 rollout,只推演前段部分内容、依靠 OPD 获取监督奖励即可训练,这个方向前景很好。
精选问答
怎么看待 PG style OPD 和 GKD style OPD?KL 放进 loss 传梯度,还是放进 reward 不走梯度回传?
顾煜贤:
KL 放进 reward、依靠 policy gradient 优化等价于 top-1 采样形式;如果采用全词表 KL 计算,就转化为标准损失 loss 形式,两种范式在数学期望层面等价。
不管选用哪种方案,样本全都由 student 模型在线 rollout 采样得到,因此天然和 policy gradient 挂钩,不能简单看作额外附加 loss。
从推导来看,GKD 在期望上等价于把 KL 作为 reward 的 PG 路线,但 GKD 存在多种变体:
- Reverse KL:和 reward 形式严格等价;
- Forward KL、GSD:不存在上述等价关系,只能依托全词表设计经验化优化策略。
模型自蒸馏时自己和自己KL为0该怎么理解?
傅宇千 (主持人):
自 KL 仅在数学期望上等于 0,单次实际采样得到的样本分布和原分布存在偏差。
Think Machine Lab 相关实验:模型用自身生成数据做 SFT,模型性能逐步下滑。他的解释就是自采样样本带有分布偏移信号,反复在自生成样本上训练会逐步偏离原始分布,沦为 off-policy 训练。
OPD做完Student rollout后,是否需要拒绝采样、丢弃低分样本,只优化正向reward轨迹?
黎亚轩:
我们在 Strong-to-Weak distillation 实验里有相关副结论:选用 DeepMath 数据集,单独筛选高难度题目子集做 OPD,模型提升幅度很差;改用简易 Prompt、偏简单的样本训练,OPD 增益更突出。该规律目前仅在本组实验得到验证,暂无法确认可以全场景泛化。
训练前有没有量化指标,预判当前场景适不适合OPD、预估Student能补齐和Teacher之间多少性能差距?
何秉翔:
目前没有能精准定量预测性能补齐幅度的指标。
我们 Rethinking OPD 提出两个参考度量:overlap ratio(师生 TOP-K 候选 token 重合率)、重合 token 的概率加权总和。
指标逻辑:依托两处数值判断师生输出分布、思考模式的相似度;师生分布越贴近,OPD 带来的性能提升通常越可观。但暂时无法依靠指标量化具体涨幅,相关定量研究仍待补充。
多专家OPD,采用mini-batch多领域混合训练,还是分领域顺序训练?
傅宇千 (主持人):
业界主流为同一个 mini-batch 内混入多领域数据混合训练,不采用分Domain串行训练。
VLM场景下OPD有什么落地实践、相关论文/开源项目推荐?
杨晨旭:
RLSD 公开仓库可直接复用脚本复现 OPD;代码领域参考 SDPO,通用数学、纯文本场景可参考 EXOPD 开源工程。
OPD训练所用Query,和师生基座模型预训练/SFT数据的Query需要保持一致吗?
傅宇千 (主持人):
英伟达 Lightning OPD 论文方案:OPD 蒸馏阶段和师生 SFT 使用同一套 query。
黎亚轩:
在 Rethink OPD 的 recycle 相关实验中,采用与 SFT 完全相同的一套 query 做 OPD,训练效果更优,但会出现模型生成熵偏低的问题;熵值不足会影响后续 boost positive 优化任务的效果,因此实操建议在原有数据基础上混入部分额外 OPD 数据联合训练。
VLM的OPD和纯文本LLM的OPD相比,有哪些差异化结论?
杨晨旭:
我没有观测到 VLM 与纯文本 LM 在 OPD 上存在本质区别,核心差异集中在生成序列长度:VLM 普遍生成文本更短,纯文本模型生成长度更长。
依托上下文拼入 Prompt 的 OPD 方案容易受超长上下文拖累、性能衰减,因此这类算法在短生成的 VLM 任务里适配效果更佳。
另外我在 VLM 上做 RLSD 实验有个特殊结论:依托完整交互轨迹训练、直接使用标准答案训练两种方案效果接近;但在纯文本场景下二者性能差距明显。
整体来看二者区别主要来源于生成长度。