作者:CyberSoma
https://zhuanlan.zhihu.com/p/2022391438546072926
JEPA的愿景框架与工作进展
提起世界模型& JEPA,JEPA就是不抠像素(细节),只学抽象规律,预测未来,确实的本质特征,相比生成式AI要省算力。要知道2022年Yann提出的JEPA的那篇论文《A Path Towards Autonomous Machine Intelligence》(2022),是一整个对自主机器智能愿景框架,把JEPA分成4层,分别是,
Level 0:基础 JEPA。单模态、潜空间预测,不重建像素以及Token。
Level 1:多模态 JEPA。图像 、视频、语言、音频、3D全覆盖。
Level 2:世界模型 JEPA。时序 + 物理 + 动作 + 因果,能预测未来。
Level 3:分层思考 JEPA。多层抽象 + 长期规划 + 类人思考。
Yann把整个JEPA又分为三个方向:I-JEPA(图像起点)、V-JEPA(视频、世界模型方向) 和 H-JEPA(层次化未来方向)。
这样一来,工作进展就很清晰了,那我们就从L0-L4一层一层来看,可以说版图基本完成大半,还差最后的临门一脚!
Level 0:基础JEPA,完成进度100%
这层的代表作是以图像代表作的I-JEPA(2023),潜在空间预测可行性的里程碑。它证明了非生成式、自监督学习的有效性,避免了像素重建的维度灾难。
参考:I-JEPA(图像)、DMT-JEPA(细粒度图像)、Point-JEPA(3D点云)等。
Level 1:多模态全覆盖,完成进度95%
这层走全面发展策略,整体比较综合,从图像、视频、3D到音频、语言、图文再到图数据、医疗全有,这层的成果和Yann的AMI LABs的产品线以及战略保持一致,医疗和图数据属于领域扩展,没到领域全覆盖,也是当前运用最为高频的方向。
参考:V-JEPA(视频)、A-JEPA(音频)、LLM-JEPA(语言)、VL-JEPA(图文)、Graph-JEPA(图数据)、EchoJEPA(医疗超声)等。
Level 2:世界模型 + 因果,完成进度80%
这层接近完全落地,主要涉及时序预测、动作条件、物理推理、因果推理,今年3月发的V-JEPA 2.1、LeWorldModel属于关键性突破,Yann在达沃斯论坛分享时就提到近期要发布V-JEPA 2.1,又一次强调对常识的理解。LeWorldModel,第一个从原始像素端到端稳定训练的JEPA,解决坍缩问题,像素级世界模型稳定性+1。
参考:V-JEPA 2(视频规划)、ACT-JEPA(动作条件)、Causal-JEPA(因果)等。
关键突破:V-JEPA 2.1(密集特征)、LeWorldModel(端到端像素世界模型)
Level 3:分层思考(ThinkJEPA),正在来的路上
目前暂时可以参考的是2022版愿景,属于是Yann 的终极 AGI 世界模型,可以先参考V-JEPA 2、ACT-JEPA,但还没到多层抽象 + 长期规划 + 类人思考程度。
JEPA家族成员介绍
社区里有很多种分类方法,有说10种,也有12种,14种,我们先按照有代表性的进行分析,挖坑先,待L3成果问世之时,我会再更一版,当前家族成员情况如下:
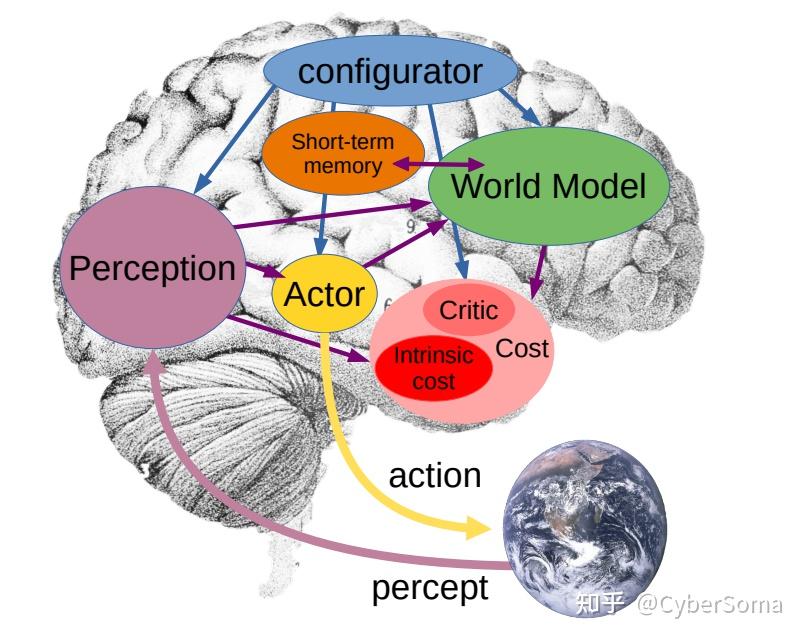
1. JEPA/ H-JEPA(L3)
论文: A Path Towards Autonomous Machine Intelligence
链接:https://openreview.net/pdf?id=BZ5a1r-kVsf
摘要: 机器如何能像人类和动物一样高效地学习?机器如何能学会推理和规划?机器如何能学习多个抽象层级上的感知与行动计划的表示,从而使它们能够在多个时间跨度内进行推理、预测和规划?
本论文提出了一种用于构建自主智能代理的架构和训练范式。它结合了诸如可配置的预测世界模型、由内在动机驱动的行为,以及通过自监督学习训练的分层联合嵌入架构等概念。
创新点:
- 首次提出联合嵌入预测架构,核心从像素、原始数据预测转向抽象嵌入预测,避免生成不可预测的噪声细节。
- 分层设计(H-JEPA)实现多尺度预测,支持短期细节与长期规划,模拟人的认知过程。
- 完全自监督,无需任何标签或人工增强,奠定Yann LeCun的自主机器智能路线图基础。
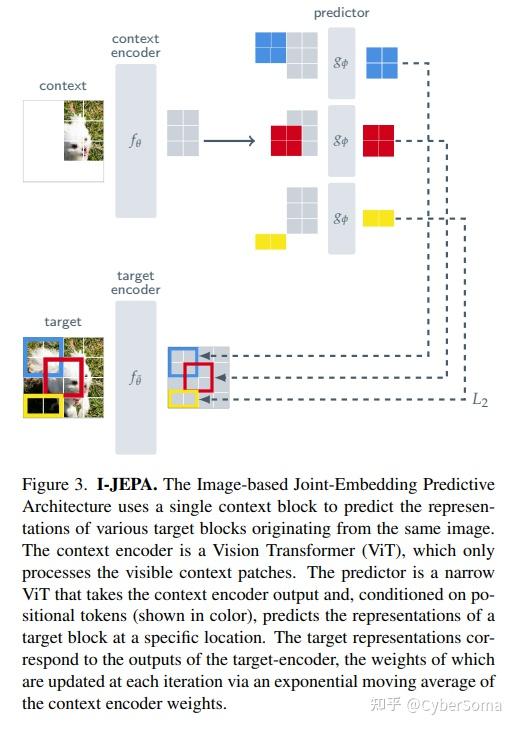
2. I-JEPA(L0)
论文: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
链接:https://arxiv.org/abs/2301.08243
摘要: 本文介绍了基于图像的联合嵌入预测架构 (I-JEPA),这是一种无需人工数据增强的自监督学习非生成方法。通过利用 Vision Transformers 并在 ImageNet 上使用少量 GPU 进行高效训练,I-JEPA 在多种下游任务(从线性分类到物体计数和深度预测)中均实现了强大的语义表示性能。
创新点:
- 首个真正非生成式JEPA实现,彻底抛弃像素重建,专注高层语义预测,计算效率大幅提升。
- 采用上下文块分散可见,目标块语义尺度的创新掩码策略,无需任何数据增强即可达到SOTA表示质量。
- 在ImageNet线性评估中以更少计算资源超越MAE/CAE等传统方法,训练快,抗噪,少标注,好用,成为视觉JEPA的标杆。
应用建议:图像分类、检测、分割、医学影像、卫星图分析等。
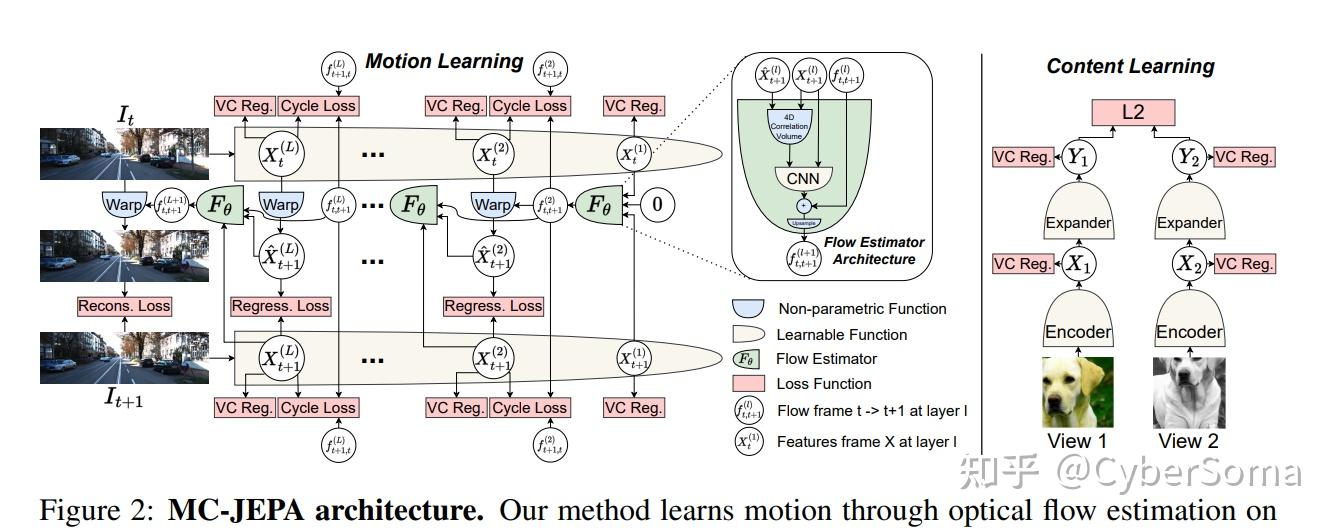
3. MC-JEPA(L1)
论文: MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features
链接:https://arxiv.org/abs/2307.12698
摘要: MC-JEPA是一种联合嵌入预测架构,通过在共享编码器中共同学习光流和内容特征,解决了传统自监督学习忽视运动信息、光流估计忽视内容理解的问题。该方法在无监督光流基准测试和下游语义分割任务中均达到了与现有技术相当的性能,证明了运动与内容特征的联合学习能相辅相成。
创新点:
- 首次将运动(Motion)和内容(Content)特征解耦学习,解决视频中动态与静态信息的纠缠问题。
- 共享编码器+联合预测,实现高效的多任务自监督,适用于视频理解的早期探索。
- 为后续V-JEPA系列奠定基础,在运动预测任务中表现出色。
应用建议:视频分类、动作识别、简单运动分析等。
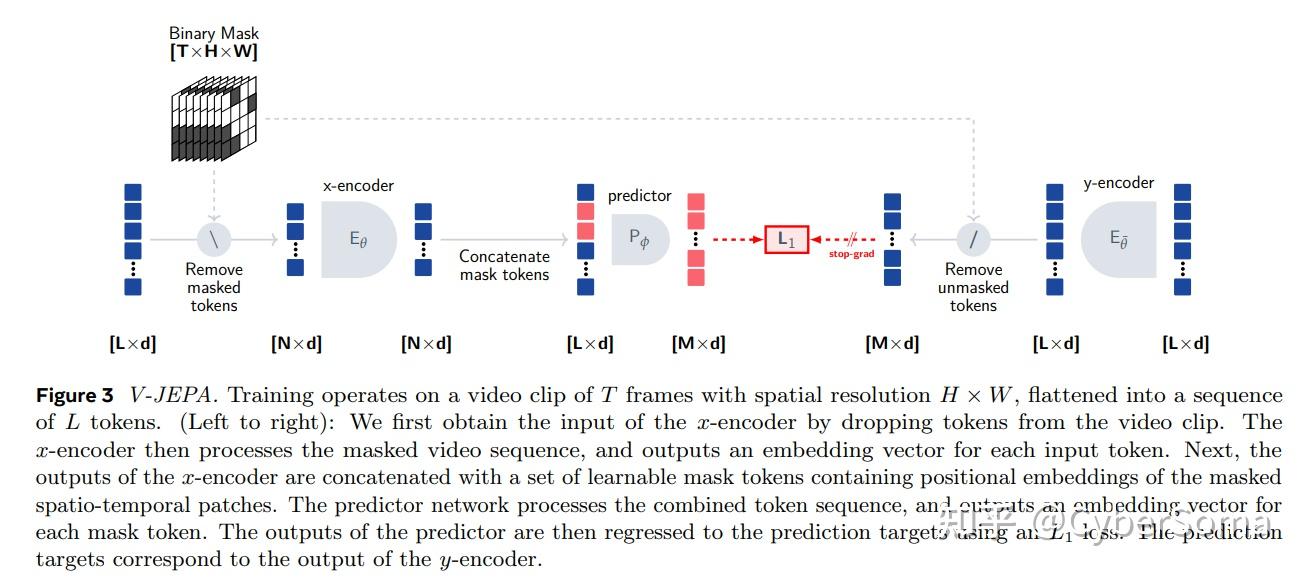
4. V-JEPA(L1)
论文: Revisiting Feature Prediction for Learning Visual Representations from Video
链接:https://arxiv.org/abs/2404.08471
摘要: 本文探讨了将特征预测作为视频无监督学习的独立目标,并引入了 V-JEPA,这是一系列仅使用特征预测目标进行训练的视觉模型,而不使用预训练的图像编码器、文本、负样本、重构或其他监督来源。
这些模型在从公开数据集收集的 200 万个视频上进行训练,并在下游图像和视频任务上进行评估。本文的结果表明,通过预测视频特征进行学习可以产生通用的视觉表示,在无需调整模型参数的情况下,在基于运动和外观的任务中均表现良好。
本文最大的模型,一个仅在视频上训练的 ViT-H/16,在 Kinetics-400 上获得 81.9%,在 Something-Something-v2 上获得 72.2%,在 ImageNet1K 上获得 77.9%。
创新点:
- 首个大规模视频JEPA,纯特征预测目标,无需预训练图像编码器、文本或负样本。
- 从海量互联网视频学习世界动态,为世界模型提供强大基础。
- Meta官方开源,标志JEPA从图像向视频、多模态的重大扩展。
应用参考:视频理解、动作预测、视频检索、短视频内容分析等。
5. A-JEPA(L1,Audio-JEPA)
论文: A-JEPA: Joint-Embedding Predictive Architecture Can Listen(2023)
链接:https://arxiv.org/abs/2311.15830
论文:Audio-JEPA: Joint-Embedding Predictive Architecture for Audio Representation Learning(2025)
链接:https://arxiv.org/abs/2507.02915
摘要(2023): 本文展示了驱动大型基础视觉模型成功的掩码建模原理,可以通过在潜空间中进行预测,有效地应用于音频领域。我们引入了基于音频的联合嵌入预测架构(A-JEPA),这是一种用于音频频谱自监督学习的简单扩展方法。
遵循 I-JEPA 的设计,我们的 A-JEPA 通过上下文编码器,利用课程掩码策略对可见的音频语谱图块进行编码,并预测在精心设计的位置处采样的区域表示。这些区域的目标表示是通过上下文编码器的指数移动平均(即目标编码器)在整个语谱图上提取的。
考虑到音频语谱图中局部时间和频率高度相关的复杂性,我们发现以课程学习的方式将随机块掩码转变为时频感知掩码是有益的。为了增强上下文语义理解和鲁棒性,我们在目标数据集上使用正则化掩码对编码器进行微调,而不是采用输入丢弃或置零的方式。
在实验中,当基于 Vision Transformer 结构构建时,我们发现 A-JEPA 具有高度的可扩展性,并在多个音频和语音分类任务上创下了新的最先进性能,超越了其他使用外部监督预训练的最新模型。
创新点:
- 将JEPA首次成功扩展到音频领域,抛弃传统波形、谱图重建,专注抽象音频表示。
- 简单ViT(Vision Transformer)主干即可实现高效自监督,跨模态通用性强。
- 为音视频联合等多模态世界模型铺路。
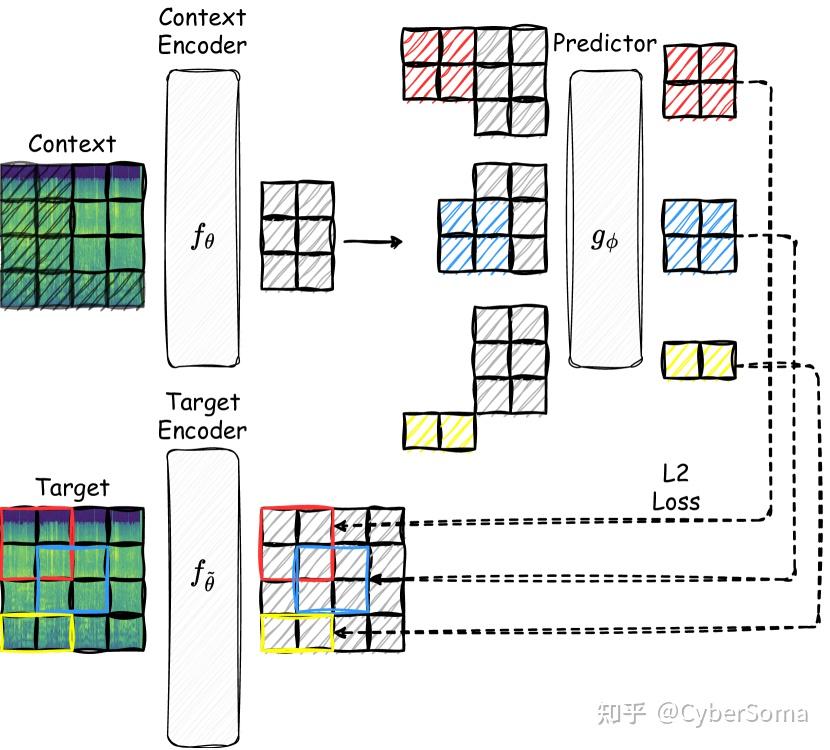
6. Point-JEPA(L1)
论文: Point-JEPA: A Joint Embedding Predictive Architecture for Self-Supervised Learning on Point Cloud
链接:https://arxiv.org/abs/2404.16432
摘要: 最近,点云领域的自监督学习取得了显著进展,展现出巨大潜力。然而,这些方法通常存在预训练时间长、需要在输入空间进行重构以及依赖额外模态等缺点。
为了解决这些问题,本文引入了 Point-JEPA,这是一种专门为点云数据设计的联合嵌入预测架构。 为此,本文引入了一个排序器 (Sequencer),对点云补丁嵌入进行排序,以便在目标和上下文选择期间,根据索引高效地计算并利用它们的邻近性。该排序器还允许在上下文和目标选择之间共享补丁嵌入邻近性的计算,从而进一步提高效率。
实验表明,本文的方法在避免输入空间重构或额外模态的同时,实现了最先进的性能。特别是在 ModelNet40 数据集的线性 SVM 分类任务中,Point-JEPA 达到了 93.7±0.2% 的准确率,超越了所有其他自监督模型。
此外,Point-JEPA 在所有四种少样本学习(Few-shot learning)评估框架下也创下了新的性能纪录。
创新点:
- 针对3D点云的专用JEPA,处理非结构化稀疏数据,实现高效自监督表示学习。
- 多块采样策略生成信息丰富的上下文与目标块,提升3D语义理解。
应用场景:自动驾驶点云、机器人 3D 感知、3D 建模等。
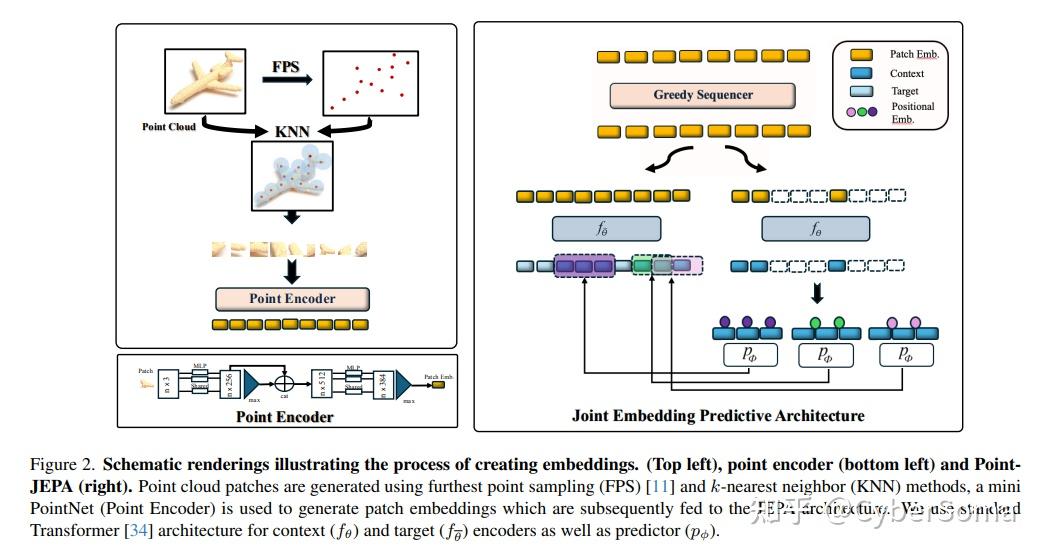
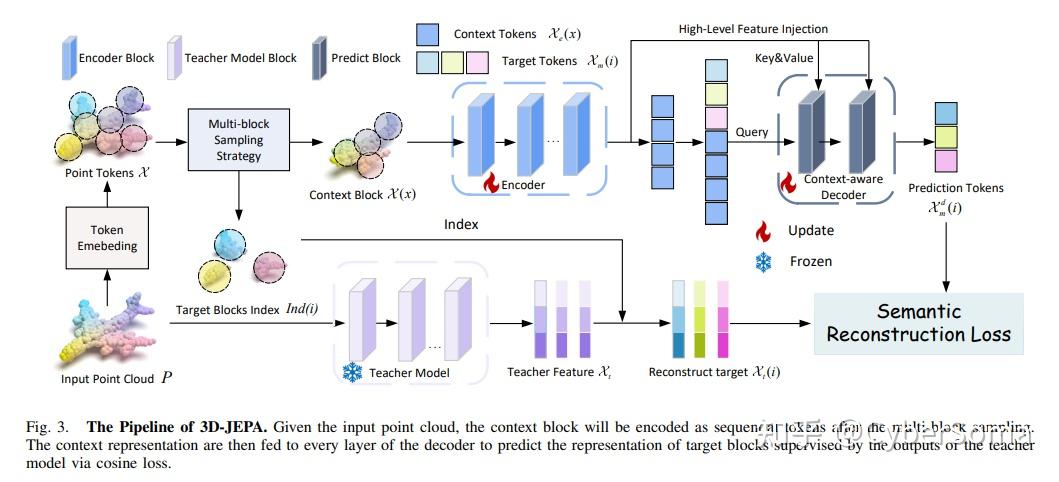
7. 3D-JEPA(L1)
论文: 3D-JEPA: A Joint Embedding Predictive Architecture for 3D Self-Supervised Representation Learning
链接:https://arxiv.org/abs/2409.15803
摘要: 基于不变性的方法和生成式方法在 3D 自监督表示学习(SSRL)中表现出了显著的性能。
然而,前者依赖于人工设计的数据增强,这会引入并不普遍适用于所有下游任务的偏置;而后者则不加区分地重构掩码区域,导致表示空间中保存了无关的细节。为了解决上述问题,本文引入了 3D-JEPA,一种新型的非生成式 3D SSRL 框架。
具体而言,本文提出了一种多块采样策略,用于生成具有足够信息量的上下文块(Context block)和若干具有代表性的目标块(Target blocks),并提出了上下文感知解码器来增强目标块的重构。
具体来说,上下文信息被持续输入到解码器中,从而促进编码器学习语义建模,而不是记忆与目标块相关的上下文信息。总体而言,3D-JEPA 利用编码器和上下文感知解码器架构,从上下文块中预测目标块的表示。
在不同数据集上的各种下游任务证明了 3D-JEPA 的有效性和高效性,能够以更少的预训练轮数实现更高的准确率,比如在 PB T50 RS 上仅通过 150 轮预训练就达到了 88.65% 的准确率。
创新点:
- 首个专为3D数据的JEPA框架,支持真实世界3D传感器数据。
- 非生成式设计避免点云重建的计算开销,专注抽象空间预测。
- 在物体定位与3D理解任务中展现强大泛化能力。
应用场景:3D 理解和定位,机器人的物体抓取预测、导航与交互,真实世界 3D 传感器数据处理等。
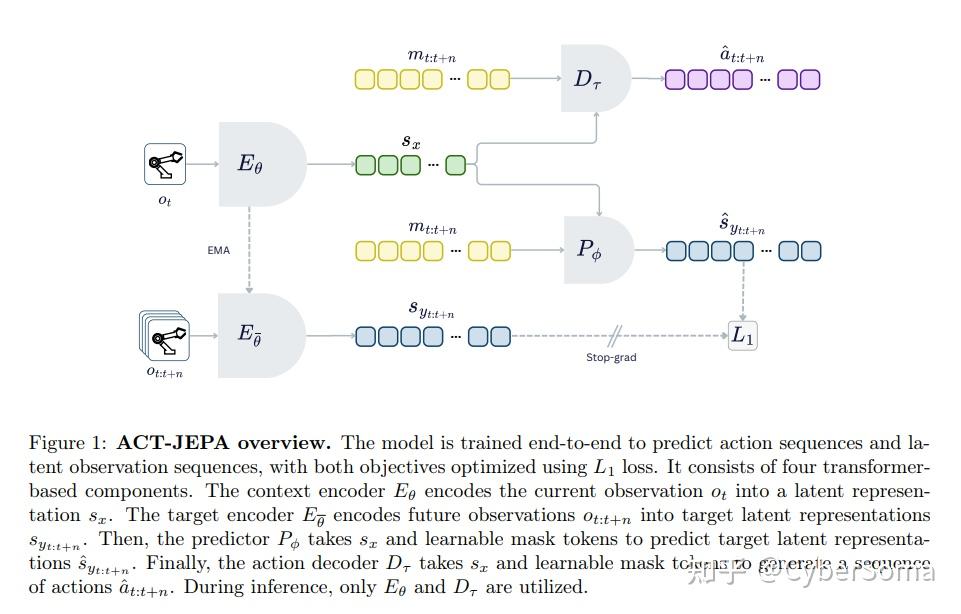
8. ACT-JEPA(L2)
论文: ACT-JEPA: Novel Joint-Embedding Predictive Architecture for Efficient Policy Representation Learning
链接:https://arxiv.org/abs/2501.14622
摘要: 为决策策略学习高效的表示是模仿学习(IL)中的一项挑战。目前的模仿学习方法需要专家演示,而这些演示的收集成本很高。此外,这些方法并未经过显式训练来理解环境,因此它们的世界模型发育不足。
自监督学习(SSL)提供了一种替代方案,因为它可以从多样化的未标记数据中学习世界模型。然而,大多数自监督学习方法效率低下,因为它们在原始输入空间中运行。
在这项工作中,本文提出了 ACT-JEPA,这是一种统一了模仿学习和自监督学习以增强策略表示的新型架构。它经过端到端的训练,共同预测:1)动作序列和 2)潜空间观测序列。
为了在潜空间中进行学习,本文利用了联合嵌入预测架构(JEPA),这使得模型能够过滤掉无关细节并学习稳健的世界模型。
本文在不同环境和多项任务中对 ACT-JEPA 进行了评估。我们的结果显示,它在所有环境中都优于最强的基准模型。ACT-JEPA 在世界模型理解方面实现了高达 40% 的提升,任务成功率提高了 10%。
最后,本文证明了预测潜空间观测序列可以有效地泛化到预测动作序列。这项工作展示了整合模仿学习和自监督学习如何实现高效的策略表示学习、改进的世界模型以及更高的任务成功率。
创新点:
- 专为机器人策略设计的JEPA,首次将IL与SSL端到端结合,提升世界模型与动作预测。
- 在潜在空间预测动作序列和观测序列,数据效率高、泛化强。
- 直接支持具身智能规划,是JEPA在机器人领域的实战落地代表。
应用场景:机器人操纵,具身智能规划与长时序决策等。
9. V-JEPA 2(L2)
论文: V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
链接:https://arxiv.org/abs/2506.09985
摘要: 现代人工智能的一个重大挑战是学习理解世界,并主要通过观察来学习行动(LeCun, 2022)。本文探索了一种自监督方法,该方法将互联网规模的视频数据与少量交互数据(机器人轨迹)相结合,以开发能够在物理世界中进行理解、预测和规划的模型。 本文首先在一个包含超过 100 万小时互联网视频的视频和图像数据集上,预训练了一个无动作(Action-Free)的联合嵌入预测架构 V-JEPA 2。
V-JEPA 2 在运动理解方面表现强劲(在 Something-Something v2 上达到 77.3% 的 Top-1 准确率),并在人类动作预测方面达到了最先进的水平(在 Epic-Kitchens-100 上的 Recall@5 为 39.7%),超越了以往的特定任务模型。
此外,在将 V-JEPA 2 与大语言模型对齐后,本文证明了其在 80 亿参数规模下的多项视频问答任务中达到了最先进性能(PerceptionTest 为 84.0,TempCompass 为 76.9)。
最后,本文展示了如何通过使用来自 Droid 数据集的不足 62 小时的无标注机器人视频,对一个潜空间动作条件世界模型(Latent Action-Conditioned World Model)V-JEPA 2-AC 进行后训练,从而将自监督学习应用于机器人规划任务。
本文在两个不同的实验室中对 Franka 机械臂进行了 V-JEPA 2-AC 的零样本(Zero-Shot)部署,并实现了利用图像目标进行规划来完成物体的拾取和投放。值得注意的是,这是在没有从这些环境中的机器人收集任何数据,且没有任何特定任务训练或奖励的情况下实现的。这项工作证明了通过对网络规模数据和少量机器人交互数据进行自监督学习,可以产生一个能够在物理世界中进行规划的世界模型。
创新点:
- 首个结合海量视频+少量机器人数据的世界模型,支持理解、预测与规划。
- 动作条件化版本实现零样本机器人部署。
- 数据效率极高,仅需几十小时机器人数据即可泛化到新环境。
应用场景:零样本(Zero-Shot)机器人规划与控制,机器人导航,视频理解与预测场景等。
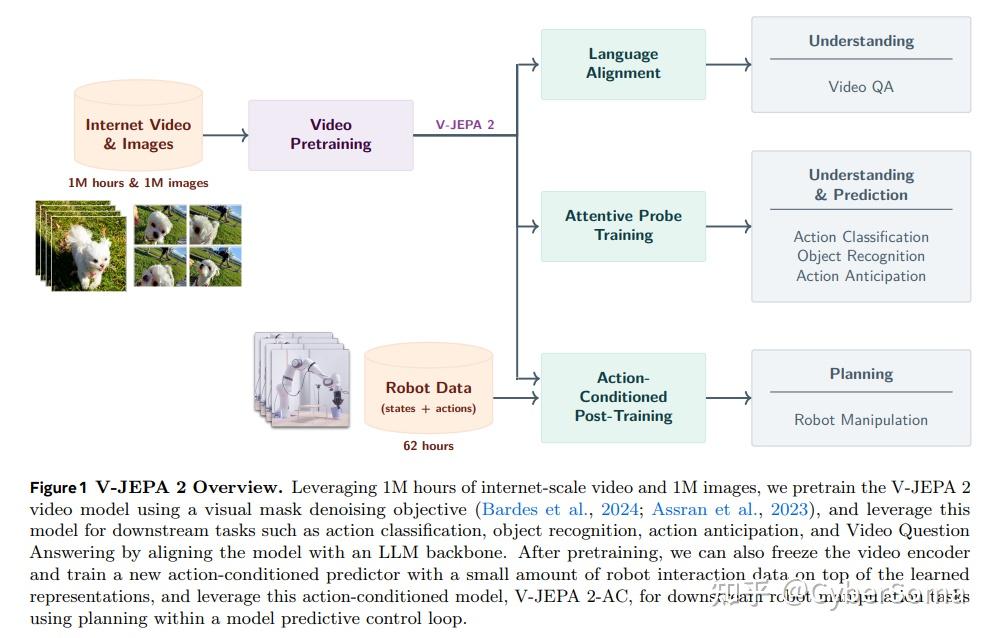
10. LeJEPA(L0,JEPA简化版)
论文: LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
链接:https://arxiv.org/abs/2511.08544
摘要: 学习世界及其动态的可操作表示是人工智能的核心。联合嵌入预测架构(JEPAs)提供了一个充满前景的蓝图,但由于缺乏实践指导和理论支持,导致了零散的研发。我们提出了关于 JEPAs 的全面理论,并将其具现化为 LeJEPA,一个精简、可扩展且具有理论依据的训练目标。
首先,本文确定各向同性高斯分布是 JEPAs 嵌入为最小化下游预测风险应遵循的最优分布。其次,本文引入了一种新颖的目标函数,草图化各向同性高斯正则化(SIGReg),以约束嵌入达到该理想分布。将 JEPA 的预测损失与 SIGReg 结合,产生的 LeJEPA 具有诸多理论和实践优势:
- (i) 单个权衡超参数;
- (ii) 线性时间与内存复杂度;
- (iii) 在不同超参数、ResNets, ViTs, ConvNets架构和领域中保持稳定;
- (iv) 无需启发式方法,比如无需梯度停止(Stop-Gradient)、无需师生模型(Teacher-Student)、无需超参数调度器;
- (v) 分布式训练友好,实现仅需约 50 行代码。
本文的实证验证涵盖了 10 多个数据集、60 多种架构,且具有不同的规模和领域。比如,使用 ImageNet-1K 进行预训练并在冻结主干网络下进行线性评估,LeJEPA 使用 ViT-H/14 达到了 79% 的准确率。本文希望 LeJEPA 提供的简洁性及理论友好型生态系统将重新确立自监督预训练作为 AI 研究核心支柱的地位。
创新点:
- 引入SIGReg正则化,彻底消除传统JEPA的启发式,如EMA、Stop-Gradient,仅需一个超参数。
- 训练稳定、线性复杂度,支持ViT-g(18亿参数)等巨型模型,线性探针(State-of-the-art linear)性能领先。
- 提供首个与下游任务强相关的训练损失,可直接用于模型选择。
应用场景:计算机视觉基础预训练与迁移学习,标签稀缺或标注成本高的领域等。
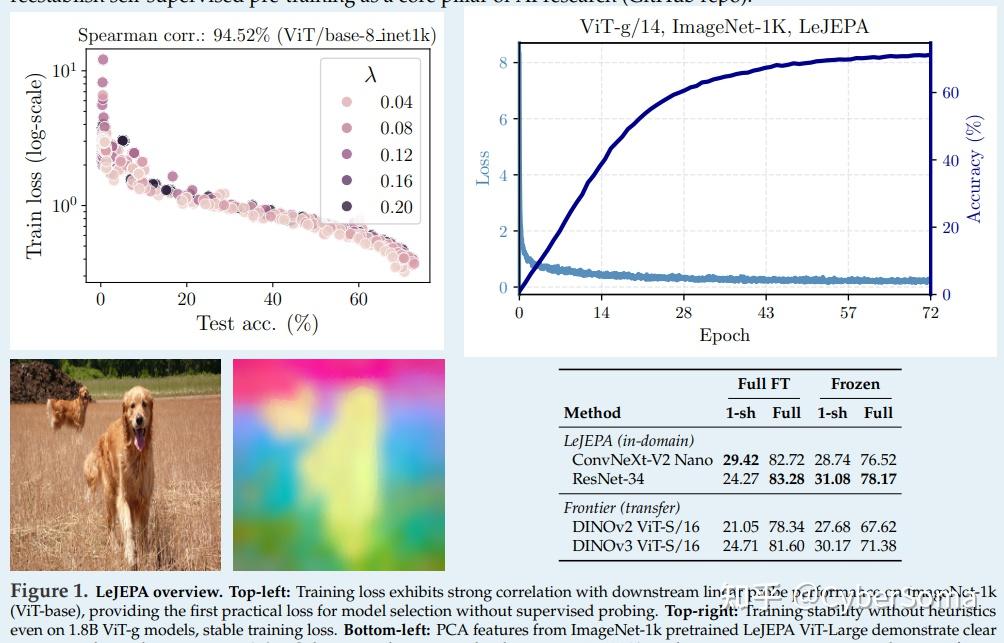
11. Causal-JEPA(L2)
论文: Causal-JEPA: Learning World Models through Object-Level Latent Interventions
链接:https://arxiv.org/abs/2602.11389
摘要: 世界模型需要强大的关系理解能力来支持预测、推理和控制。虽然以物体为中心的表示(Object-Centric Representations)提供了一种有用的抽象,但它们不足以捕捉依赖于交互的动态过程。因此,我们提出了 C-JEPA,一种简单且灵活的以物体为中心的世界模型,它将掩码联合嵌入预测从图像补丁(Image Patches)扩展到了以物体为中心的表示。
通过应用物体级掩码(要求从其他物体推断出某个物体的状态),C-JEPA 诱发了具有类似反事实效果的潜空间干预,并防止了捷径解(Shortcut Solutions),使得交互推理变得至关重要。
实证表明,C-JEPA 在视觉问答方面带来了持续的提升,与没有物体级掩码的相同架构相比,在反事实推理方面的绝对提升约 20%。在智能体控制任务中,C-JEPA 仅使用补丁化世界模型所需总潜空间输入特征的 1%,即可实现更高效的规划,并达到相当的性能。
最后,我们提供了一项正式分析,证明了物体级掩码通过潜空间干预引入了因果归纳偏置(Causal Inductive Bias)。
创新点:
- 引入对象级潜在干预,实现显式因果推理,超越纯相关性预测。
- 以对象为中心的世界模型,适合复杂场景的结构化理解。
- 为物理AI和规划任务提供更强的因果建模能力。
应用场景:反事实推理,机器人/智能体控制,因果关系分析等。
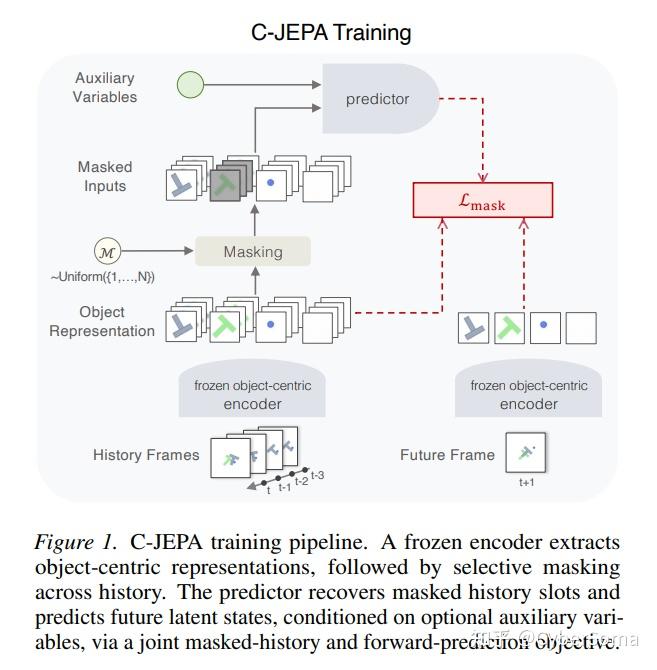
12. V-JEPA 2.1(L2)
论文: V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
链接:https://arxiv.org/abs/2603.14482
摘要: 本文推出了 V-JEPA 2.1,这是个自监督模型系列,它在保持强大的全局场景理解能力的同时,能为图像和视频中的视觉场景学习密集(dense)且高质量的表示。 V-JEPA 2.1 结合了四个关键要素:
- (i) 密集预测损失 (Dense Predictive Loss):一种基于掩码的目标函数,其中所有标记(包括可见上下文和被掩码的标记)都对训练损失有贡献,从而鼓励显式的空间和时间定位(grounding);
- (ii) 深度自监督 (Deep Self-Supervision):在编码器的多个中间层分层应用自监督目标,以提高表示质量;
- (iii) 多模态分词器 (Multi-Modal Tokenizers):支持对图像和视频进行统一训练;
- (iv) 有效的模型与数据扩展。 这些设计选择显著提升了密集特征的质量,产生的表示在空间上有结构、语义上连贯且时间上一致。
在实证方面,V-JEPA 2.1 在一系列基准测试中达到了最先进(state-of-the-art)的结果:在 Ego4D 短期物体交互预测上达到 7.71 mAP;在 EPIC-KITCHENS 高层动作预测上达到 40.8 Recall@5;并且在真实机器人抓取成功率上比 V-JEPA 2 AC 提升了 20%。
该模型还在机器人导航(Tartan Drive 上的 ATE 为 5.687)、深度估计(NYUv2 线性探针下 RMSE 为 0.307)以及全局识别(Something-Something-V2 上为 77.7%)中展现了最先进的性能。 本文的结果表明,V-JEPA 2.1 推动了密集视觉理解和世界建模领域的最前沿技术。
创新点:
- 引入深层自监督与多层层次特征,解锁分割、跟踪等密集预测能力。
- 多模态分词器支持图像+视频统一训练,空间/时间一致性更强。
- 在机器人导航与动作预测中规划速度与精度显著提升。
应用场景:具身智能,精细操作,视频理解与精细语义分割,三维感知与深度估算。
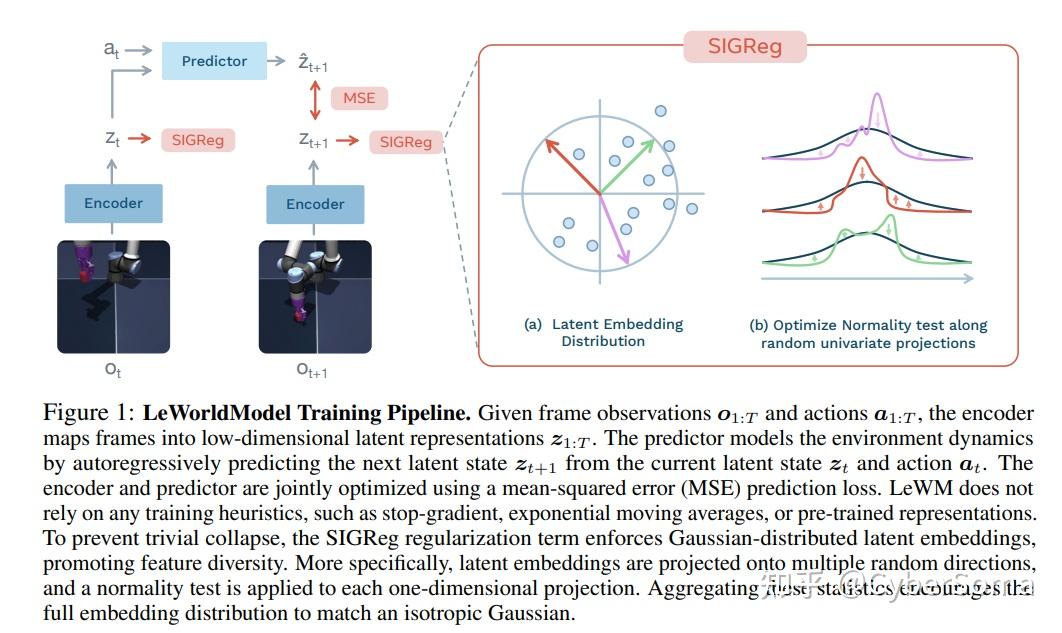
13. LeWorldModel(L2)
论文: LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
链接:https://arxiv.org/abs/2603.19312
摘要: 联合嵌入预测架构(JEPAs)为在紧凑的潜空间中学习世界模型提供了一个极具吸引力的框架,然而现有方法依然脆弱,依赖于复杂的多项损失函数、指数移动平均(EMA)、预训练编码器或辅助监督来避免表示崩溃。
在这项工作中,本文引入了 LeWorldModel (LeWM),这是第一个能够仅使用两项损失(下一嵌入预测损失和强制潜空间嵌入呈高斯分布的正则化项),从原始像素开始稳定地进行端到端训练的 JEPA。与目前唯一的端到端替代方案相比,它将可调的损失超参数从 6 个减少到了 1 个。
LeWM 仅拥有 1500 万参数,在单个 GPU 上几小时内即可完成训练;其规划速度比基于基础模型的世界模型快达 48 倍,同时在多种 2D 和 3D 控制任务中保持了竞争力。除了控制任务外,我们通过对物理量的探测(probing)证明了 LeWM 的潜空间编码了有意义的物理结构。惊讶度(Surprise)评估证实,该模型能够可靠地检测到不符合物理规律的事件。
创新点:
- 首个像素级端到端稳定JEPA,无需复杂多损失或预训练编码器。
- SIGReg正则化确保嵌入分布稳定,训练简单且可扩展。
- 在世界模型规划与控制任务中超越PLDM等基线,是Yann终极AGI愿景的最新实战化。
应用场景:小型机器人,高频实时动作规划等。
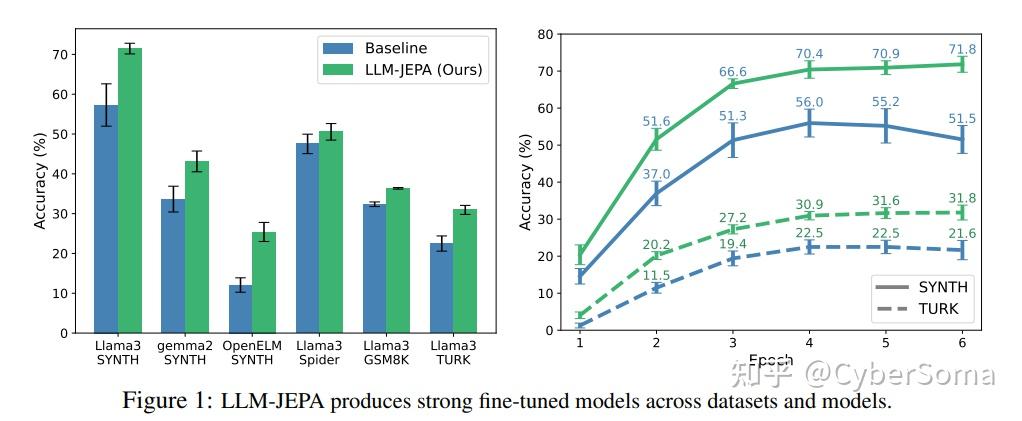
14. LLM-JEPA(L1)
论文: LLM-JEPA: LARGE LANGUAGE MODELS MEET JOINT EMBEDDING PREDICTIVE ARCHITECTURES
链接:https://arxiv.org/abs/2509.14252
摘要: 大语言模型(LLM)的预训练、微调和评估依赖于输入空间的重构和生成能力。然而,在视觉领域已经观察到,嵌入空间(Embedding-Space)的训练目标,例如使用联合嵌入预测架构(JEPAs),远优于其在输入空间对应的训练目标。
语言与视觉之间训练方式的这种脱节引发了一个自然的问题:语言训练方法能否从视觉方法中学习一些技巧?JEPA 风格的 LLM 的缺失,证明了为语言设计此类目标的挑战。
在这项工作中,本文朝着这个方向迈出了第一步,开发了 LLM-JEPA,这是一种适用于微调和预训练的基于 JEPA 的 LLM 解决方案。到目前为止,LLM-JEPA 能够在多种模型上以显著优势超越标准的 LLM 训练目标,同时对过拟合具有鲁棒性。这些发现在NL-RX, GSM8K, Spider, RottenTomatoes众多数据集以及 Llama3、OpenELM、Gemma2 和 Olmo 等各种模型系列中均得到了验证。
创新点:
- 打破了自 GPT 诞生以来大语言模型一直遵循的预测下一个 Token(单词)的固有模式。
- 从像素、单词重构转向潜空间预测,使模型能更专注于逻辑和含义,而不是表面的文本重复。
- 第一次成功将 JEPA 架构跨界应用到纯文本 LLM 上。
应用场景:文本摘要、问答、长文本理解、逻辑推理。
还有一些JEPA,更多像Graph-JEPA,EchoJEPA这种行业应用,又或者是L2领域的全面落地方向,期待L3的成果发布后,届时JEPA家族将呈现百花齐放状态,全面覆盖行业应用。