作者:Kiki Huang
http://xhslink.com/o/9vI0xkOqra3
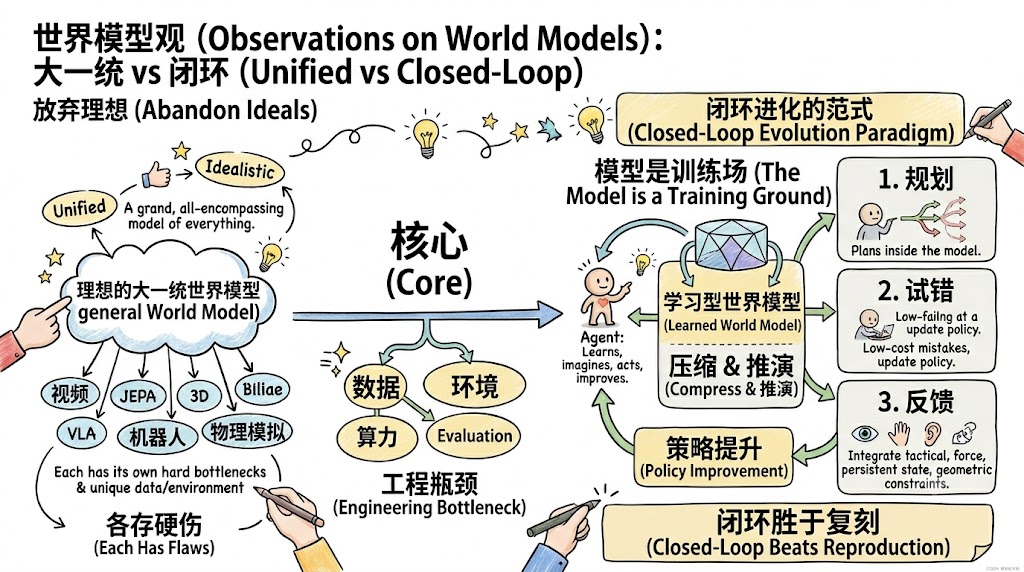
最近集中听了几场 world model 相关分享,听下来我最大的感受是:大家其实都在逐渐放弃一种过于理想化的大一统模型想象。
不是说没人想做 unified model,而是落到具体问题上,video、JEPA、3D、VLA、robotics、game world model 每条线都有自己的硬伤。很多路线最后卡住的地方,不一定是网络结构不够漂亮,而是没有足够好的数据闭环、没有可扩展的评估环境、没有稳定的训练 recipe,或者干脆没有足够的卡把想法真的跑起来。
这点也挺现实。world model 听起来像是算法问题,但做起来很快就会变成工程和资源问题。视频模型要长上下文、多视角、一致性,机器人要交互数据、仿真环境、真实机验证,3D 要几何监督和场景规模,Dreamer-style agent learning 又要大量 imagined rollout 和环境交互。最后大家聊着聊着,都会回到几个很朴素的问题:数据在哪里?闭环在哪里?算力在哪里?
video world model 这边,最现实的优势还是 scale。视频数据多、训练范式成熟,也最接近现有 diffusion / autoregressive video / multimodal foundation model 的放大路径。
但视频生成本身不是终点。现在很多工作都在往里面接 camera control、action conditioning、long-term memory、3D consistency 和 physical feedback,本质上是在承认:只靠像素视频模型最容易 scale,但长期一致性、空间回访、动作因果仍然不稳;
JEPA 的问题意识更接近状态预测,但 latent 怎么变成可规划、可控制的接口还没完全解决;
3D 路线能提供 persistent state 和几何约束,但数据、训练和交互闭环都比视频难 scale;
VLA 直接面对机器人动作,但 action space 稀疏、接触事件非平稳、物理反馈缺失,导致很多模型看起来懂任务,真正执行时还是脆。
simulation 路线看起来没那么像 foundation model 叙事,但它能提供可控交互、物理约束和系统评估,也是 robot learning 里很难绕开的基础设施。
所以我听下来的感觉不是哪条路线已经赢了,而是大家都意识到大一统很难,于是开始互相借鉴关键部件,然后各做各的。
还有一个很明显的变化是,很多人对单纯讨论模型架构已经没那么兴奋了。不是说架构不重要,而是当 infra、数据、训练规模、交互环境都还没稳定的时候,过早争论某个 backbone、某种 tokenization、某种 latent design,意义其实有限,很难预测一个可回访、可干预、可规划的世界状态。
这也是很多人会反复质疑的地方:现在的 video world model 到底是在学物理,还是只是在学视觉上合理的运动纹理?一个球滚得像不像、一个杯子倒得像不像,和模型是否真的理解接触、摩擦、支撑、碰撞、质量、约束,并不是一回事。很多生成结果在短时间内看起来很自然,但一旦需要长程一致性、重复交互、物体回访,或者要求动作结果严格可控,物理约束缺失的问题就会冒出来。
3D 这边也很有意思。很多人会说显式 3D 可能不再重要,latent 足够大就能自己学出空间结构。但从现在的 video world model 问题看,这个判断至少还站不稳。视角大幅运动、长视频、相机回访、多视角一致性,这些场景一上来,纯 latent 的结构遗忘和场景漂移就会暴露。Geometry Forcing、World-R1、Lyra 2.0、HY-World 2.0 这些路线用不同方式把 3D constraint、3D memory、3D reward 或 correspondence call back回来,说明显式结构不是旧时代包袱,而是模型走向交互系统时不得不补的一块骨架。
但我最看好的其实还是 Dreamer 路线。原因不是 Dreamer 的某个具体架构一定会原样成为终局,而是它抓住了 world model 更本质的问题设定:世界模型不只是用来生成一段未来,而是要让 agent 能在里面想象、试错、规划、更新策略,最后变得更强。
也就是说,world model 的价值不在于单独生成了一个多逼真的世界,而在于它能不能进入 agent learning loop,变成智能体获得经验、修正行为的训练场。
这一点和很多 video world model 的叙事很不一样。video 路线经常把重点放在未来能不能生成得更真实、更长、更稳定,但 Dreamer 路线从一开始关心的就是:模型学到的 dynamics 能不能被 policy 使用?imagined rollout 能不能变成有效训练信号?agent 能不能在模型内部低成本犯错,再把经验转化成更好的行为?这比单纯生成未来观测更接近我理解里的 world model。
有意思的是,我发现不少 LLM 背景的人会更容易看好 JEPA 路线。可能是因为 JEPA 的叙事和语言模型里的 representation / prediction / abstraction 更接近:重点不是还原每个像素,而是学到一个对未来、任务和状态变化有用的 latent。相比 video generation 对画面质量的执念,JEPA 更像是在问:模型内部到底应该预测什么?
JEPA 路线我觉得也值得继续看,JEPA 的价值在于它把问题从 pixel reconstruction 拉回到 latent prediction:模型到底应该预测什么状态?什么表示对未来、任务、动作后果有用?这比追求像素级清晰度更接近行动系统需要的东西。但如果 JEPA 学到的 latent 没有进入 planning loop、policy learning loop 或 closed-loop control,它仍然只是一个更好的表征模型。
更值得关注的,可能是 JEPA-style predictive latent 和 Dreamer-style closed-loop agent learning 的结合:前者负责学一个更抽象、更可预测的状态空间,后者负责让 agent 在这个状态空间里演化。
DreamZero 作者展示的循环 agent 路线也让我印象比较深。表面看 DreamZero 是 video / WAM 路线,用 video foundation model 做 future prediction,再和 action 结合;但更有意思的不是生成未来视频再出动作这个叙事,而是它开始接近一种 Dreamer-like loop:agent 利用世界模型生成经验、评估动作后果,再反过来改进自身。底座从 RSSM / latent dynamics 换成了大规模 video prior,但系统目标仍然是闭环学习。
VLA / robotics 这边的讨论则更贴近真实执行问题。很多时候视觉模型能给出看似合理的动作,但机器人真正失败的地方往往不在语义理解,而在接触瞬间:夹爪有没有夹稳,物体有没有滑,力是不是过大,软物体有没有形变,工具和表面之间的摩擦状态有没有变化。这些信息很难只靠 RGB 视频补出来。也因此,触觉、力反馈、本体感知和接触状态估计的重要性反而越来越高。对机器人来说,如果 world model 没有 tactile / force / proprioception,只靠视觉预测,就很容易看起来懂世界,但真正一接触就露馅。
从控制和优化视角看,大家对现有 VLA world model 的不满也在这里。他们并不是反对 learning,而是会追问:你的状态变量是什么?约束在哪里?动力学误差怎么处理?安全边界怎么保证?模型预测错了以后如何在线修正?
现在很多 VLA world model 更像是从大模型侧往机器人上接接口,能展示 impressive demo,但对控制里最核心的稳定性、鲁棒性、约束满足、可解释代价函数和 real-time feedback 还交代得不够。尤其在接触丰富的任务里,单纯靠离线数据学一个动作分布,很难替代可验证、可闭环修正的控制系统。
这里还不能忽略 simulator 的作用。现在很多 world model 讨论容易把 simulator 放在一个有点过时的位置,好像大模型起来以后,显式仿真环境就只是数据生成工具。但我觉得这个判断也太早了。对机器人和 embodied agent 来说,simulator 仍然提供了现实世界很难直接给的东西:可控的初始状态、可重复的失败案例、可系统扫描的物理参数、可量化的 reward / constraint,以及足够密集的交互数据。
更重要的是,未来的 simulator 也未必还是传统意义上完全手工建模的 physics engine。它很可能会和 learned world model 混在一起:一部分靠显式物理保证约束和可验证性,一部分靠生成模型补足复杂场景、多样物体和真实世界分布。这样看,simulator 不是被 foundation model 淘汰的旧工具,而可能是 world model 真正落到 robot learning 里绕不开的基础设施。
这也是我觉得未来几条线会互相靠近的地方。video 路线提供 scale 和真实世界先验,JEPA 路线提供 predictive representation,3D 路线提供 persistent state 和空间一致性,VLA / robotics 路线提供 action interface、触觉、力反馈和真实失败案例,simulator 路线提供可控交互、物理约束和系统评估,而 Dreamer 路线提供一个最完整的系统范式:模型不是为了复刻世界,而是为了让 agent 在世界模型里持续变强。
所以现在 world model 的关键问题已经不是要不要 latent,也不是要不要生成视频,而是 latent 里面有没有稳定的空间结构、物理约束、动作因果、长期记忆和多模态反馈;更进一步,这些东西能不能进入一个闭环,让 agent 在模型中规划、试错、学习、自我更新,并在真实世界反馈里不断校正自己。
大一统模型可能还很远,但闭环进化这条线已经越来越清楚了。 world model 真正值得期待的地方,不是它能把世界画得多像,而是它能不能让 agent 在一次次想象、试错和真实反馈里变强。