论文: Why Supervised Fine-Tuning Fails to Learn: A Systematic Study of Incomplete Learning in Large Language Models
会议: ACL 2026 |单位: 腾讯混元 × UNSW
arXiv: https://arxiv.org/abs/2604.10079
核心命题:SFT学不会的问题,不能靠「加epoch」解决。有些问题加epoch只提升1%,但换个策略能提升12.5%。本文聚焦于「用什么策略治什么病」——一个完整的SFT失败修复方案库。
一、从「一个笼子装所有病」到「五把手术刀」
做SFT的人面对模型学不会时的本能反应是:加epoch。
本文通过实验证明,这种「盲目加epoch」的效率极低。对于知识缺失型未学习样本(根因I),加epoch仅提升1-2%。但改用CPT(Continual Pre-Training,持续预训练)知识增强方案,效果是 +8-17% ——差了一个数量级。
作者的核心论点是:不完全学习现象(ILP,Incomplete Learning Phenomenon)不是单一疾病,而是五种病因的综合征。每种病因需要不同的「手术刀」。在10个标准SFT(Supervised Fine-Tuning,监督微调)数据集上,平均15.3%±2.1% 的训练样本处于未学习状态,这个数字在Qwen、LLaMA、OLMo2上稳定存在。

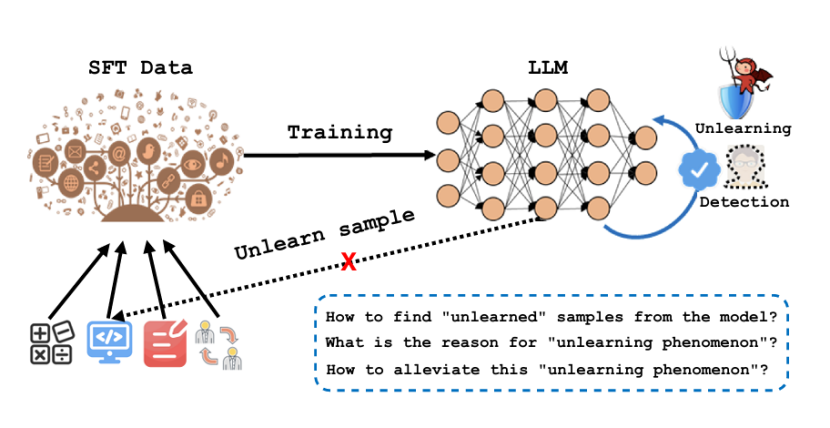
在进行策略拆解之前,先理解这个问题的基本框架。作者提出了一个三段式诊断流程:

而让检测成为可能的关键技术是MC转换(Multiple-Choice Conversion,多项选择转换)——将SFT的监督响应转化为多项选择题格式,用pass@5 < 0.2判定「未学习样本」。

二、手术刀1:CPT知识增强——当SFT遇上知识真空
治疗的敌人
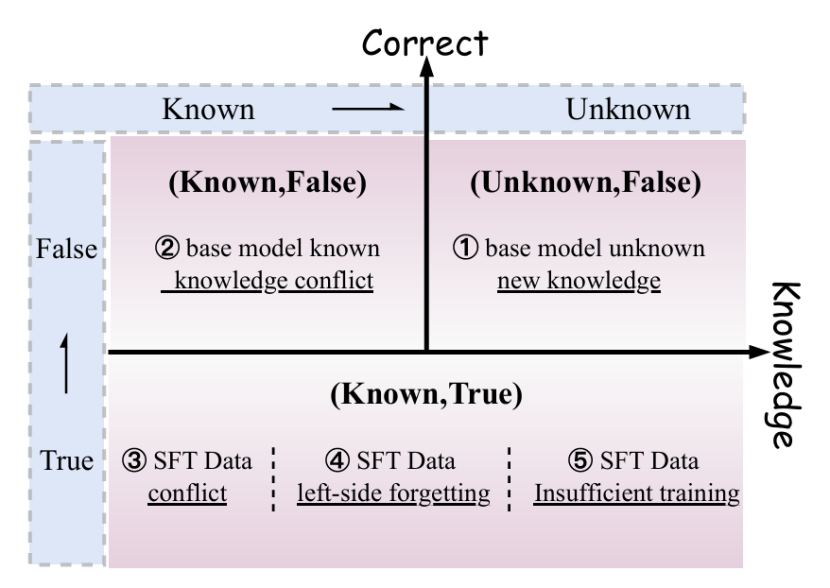
根因I:预训练知识缺失。 基模型从未在预训练语料中见过相关知识——罕见疾病的诊断标准、特定法条编号、低频金融产品名。SFT无法「无中生有」。
为什么加epoch没用
SFT的优化信号强度有限——几个epoch的梯度更新无法在模型参数中凭空构造出从未有过的知识表征。你可以让没见过斑马的人做一万道「斑马vs马」的选择题,他依然没有「条纹」的概念。
治疗流程
Step 1: 从未学习样本中用OpenIE提取知识三元组 (h,r,t)
Step 2: 基模型BoN-10探测,pass@10 < 0.2 → 标记「盲知识」
Step 3: 多源检索 → WikiData + Google Search + OpenAI-o1 API
Step 4: 构建增强语料(领域:通用 = 0.8:0.2 混合)
Step 5: 基模型CPT(持续预训练)
Step 6: 标准SFT
治疗效果

| 数据集 | 模型 | CPT前 | CPT后 | 提升 |
|---|---|---|---|---|
| MedQA | 7B | 42.1% | 54.6% | +12.5% |
| LegalBench | 7B | 51.3% | 60.7% | +9.4% |
| LegalBench | 14B | 53.8% | 67.9% | +14.1% |
| FinanceBench | 7B | 38.5% | 44.2% | +5.7% |

关键发现:模型越大(14B vs 7B),CPT收益越大(+14.1% vs +9.4%)——大模型的知识吸收能力更强。
三、手术刀2:CPT校准——纠正模型的「错误信念」
治疗的敌人
根因II:SFT监督与预训练知识冲突。 基模型在预训练阶段形成了强烈的错误信念。比如「法国总统」这个知识点——模型在预训练语料中看到了大量「奥朗德总统」的表述,SFT虽然标注了正确答案「马克龙」,但预训练先验太强。
与手术刀1的关键区别
| CPT知识增强(根因I) | CPT校准(根因II) | |
|---|---|---|
| 目标 | 从零构建知识 | 覆盖错误先验 |
| 数据量 | 大(需构建完整知识体系) | 中等(纠偏性数据) |
| CPT步数 | 较多 | 较少 |
| 核心挑战 | 信息量充足 | 强信号压倒旧先验 |
治疗流程
1.检测基模型高置信度错误(对错误选项概率 > 0.9)
2.检索权威外部知识作为纠偏数据
3.CPT重新对齐内部表征
4.重新SFT
治疗效果
ARC +2.8%,CommonQA +2.4%。冲突率(基模型高置信度错误的比例)显著下降。
四、手术刀3:动态分桶——让矛盾数据「井水不犯河水」
治疗的敌人
根因III:SFT数据内部矛盾。 同一个训练集中存在语义相似但标签矛盾的样本对。比如两个样本都问某疾病的潜伏期——一个标注「3-7天」,另一个「1-14天」。当它们共现于同一batch时,梯度方向相反,净梯度接近零——两个都学不会。
为什么不能简单删除
| 方案 | 效果 | 问题 |
|---|---|---|
| 直接删除冲突样本 | +1.5% | 信息损失、删除标准模糊 |
| 动态分桶 | +2.8% | 保留全部信息,只隔离冲突 |
治疗流程
1. Sentence-BERT编码所有训练样本
2. 构建冲突图:Sim(i,j) > 0.85 且标签矛盾 → 添加边
3. 图着色分配桶:相邻节点(冲突样本)不同色(桶)
4. 训练:每个mini-batch只从一个桶采样
5. 每K步重新评估,动态更新分桶
核心思想是保留信息总量,只改变信息的呈现方式——确保任何两个可能矛盾的知识点不会同时出现在一个batch的梯度计算中。
五、手术刀4:全局打乱+动态重采样——对抗训练遗忘
治疗的敌人
根因IV:左侧遗忘。 当SFT数据按来源顺序排列时(先所有MedQA,再所有LegalBench),后期的训练会「覆盖」早期的学习成果。前10%数据的ROUGE-L最严重时下降29%。
全局打乱
# 不好(顺序排列→遗忘)
dataloader = [medqa_all, legal_all, finance_all]
# 好(全局随机混合→抗遗忘)
dataloader = RandomSampler(medqa + legal + finance, shuffle=True)
动态重采样
每K步监测各数据子集的验证准确率。如果某子集下降超过阈值,从该子集额外采样加入当前batch——「谁被遗忘了就多给谁训练机会」。
治疗效果
| 数据位置 | 原ROUGE-L | 策略后 | 提升 |
|---|---|---|---|
| 前10%(最早) | 0.41 | 0.53 | +29% |
| 中间50% | 0.48 | 0.55 | +14.6% |
| 最后10% | 0.57 | 0.56 | -1.6% |
前10%数据提升29%,而最后10%仅微降1.6%。代价极小,收益极大。
六、手术刀5:渐进Epoch——不是不想学,是没学够
治疗的敌人
根因V:优化不足。 固定epoch下,简单样本数量多(约占80%),虽然单个梯度小但累积后主导了平均梯度方向。难样本(5%)的梯度大但被平均掉了——模型参数更新方向由简单样本定义。
治疗流程
# 传统做法(固定epoch)
for epoch in range(fixed_epochs):
train()
# 渐进Epoch(自适应停止)
while val_performance_improving():
train_one_epoch()
治疗效果

| 模型 | 提升 |
|---|---|
| Qwen2.5-7B | +1.9% |
| LLaMA3-8B | +1.8% |
| OLMo2-7B | +1.8% |
七、治疗方案的选择逻辑
决策流程
未学习样本检测通过(pass@5 < 0.2)
↓
基模型zero-shot准确率如何?
├── < 25%(近乎随机)→ 根因I → 手术刀1(CPT知识增强)
├── 低但高置信度错误 → 根因II → 手术刀2(CPT校准)
└── 尚可或正常 →
├── 语义相似样本标签矛盾?→ 根因III → 手术刀3(动态分桶)
├── 数据在训练序列前段?→ 根因IV → 手术刀4(打乱+重采样)
└── 难样本loss仍在下行?→ 根因V → 手术刀5(渐进Epoch)
实施优先级建议
1.先做零成本策略:全局打乱(手术刀4)+ 渐进Epoch(手术刀5)——改dataloader和停止条件,不花额外算力。
2.再做低成本策略:动态分桶(手术刀3)——仅需Sentence-BERT编码和图着色,算力开销极小。
3.最后启动高杠杆策略:CPT(手术刀1和2)——需要外部数据检索和额外预训练,成本高但收益也最大。
论文信息
标题: Why Supervised Fine-Tuning Fails to Learn
arXiv: https://arxiv.org/abs/2604.10079
会议: ACL 2026
单位: 腾讯混元 & UNSW
本文以五类解决方案为主线,完整讲解每种「手术刀」的适用病因、操作流程、关键数据和实施成本。