
论文题目:Reason Only When Needed: Efficient Generative Reward Modeling via Model-Internal Uncertainty
arXiv 链接:https://arxiv.org/abs/2604.10072
作者单位:腾讯混元 & 新南威尔士大学(UNSW)
收录会议:ACL 2026
领域:LLM 高效推理 / 生成式奖励模型 / 推理优化
关键词:E-GRM,Dynamic CoT Trigger,Model-Internal Uncertainty,Discriminative Scoring,GRM,Efficiency, Reward Fidelity
摘要
在生成式奖励模型(GRM)的现有实践中,“思维链推理总是越多越好”这一信念正面临现实的挑战。
本文系统解析腾讯混元联合新南威尔士大学在ACL 2026上提出的E-GRM框架——它从根本上质疑了“无差别使用CoT推理”的合理性,并提出了基于模型内部不确定性的替代方案。
E-GRM通过并行解码的共识度判定问题复杂度,动态决定是否触发完整的思维链推理;当需要推理时,由混合损失训练的判别式评分器从多个候选路径中选出最优解。
本文将从问题背景、技术架构、训练机制、实验数据和消融分析等多个维度,完整呈现E-GRM的设计理念与实证效果。
1. 引言:为什么“一律推理”不是最优解?
生成式奖励模型(Generative Reward Model, GRM)通过思维链(Chain-of-Thought, CoT)提示技术,使大语言模型(LLM)能够生成逐步推理来评估响应质量,这已经成为提升LLM复杂推理能力的主流路线。
然而,现有GRM系统的设计存在一个根本性的前提问题:是否所有输入都需要完整的推理链?
1.1 两个被忽视的效率问题
1.同质化处理的代价:当前GRM系统对所有输入采用相同的推理流程——无论问题是“1+1等于几”还是“求这个微分方程的通解”,模型都被要求生成完整的逐步推理。这种设计忽略了输入固有的难度差异,将大量计算资源消耗在了本可快速回答的简单问题上。
2.投票机制的精度局限:在生成多条推理路径后,现有GRM多采用投票(如自洽性采样,Self-Consistency)来决定最终答案。这意味着每条推理链被赋予完全相同的权重——“深刻理解后得出的正确答案”和“碰巧猜对的正确答案”在投票中完全没有区别。
1.2 E-GRM的回应
针对上述瓶颈,腾讯混元与新南威尔士大学的研究团队在ACL 2026上提出了E-GRM(高效生成式奖励模型)。它的核心主张简洁而有力:模型应该“只在需要的时候推理”。
具体而言,E-GRM引入了两个关键技术组件:一是利用并行解码的答案共识度作为动态触发信号,判断问题是否需要完整CoT;二是设计混合损失驱动的判别式评分器,对推理路径质量进行0-1区间的精细评估,替代粗糙的投票聚合。
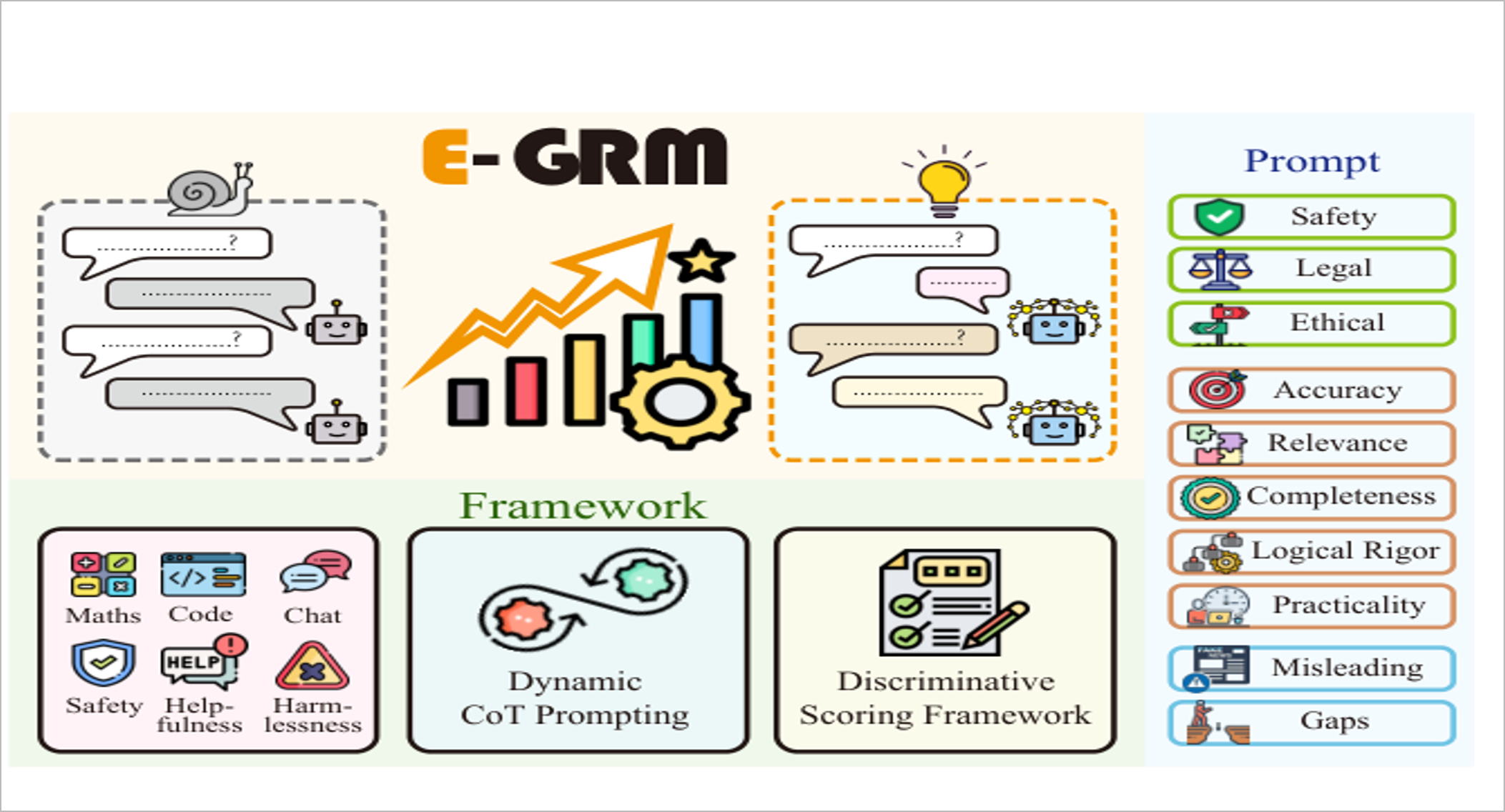
图1:E-GRM框架在多个领域的应用示意,展示了动态触发与判别式评分的协同工作模式。
2. 核心技术:动态CoT触发
2.1 基于共识度的不确定性估计
动态CoT触发的核心思想可以从一个简单现象出发理解:对同一个问题多次采样解码,如果模型的回答高度一致,说明模型对这个问题“很有把握”——此时复杂的推理链可有可无。反之,如果多次采样的回答分歧很大,说明问题复杂,需要更深的推理。
E-GRM将这一观察操作化为共识度度量:
[
\text{Consensus}(x) = \frac{\max_{y} \text{Count}(y)}{M}
]
其中(M)是并行解码次数(如5次),Count(y)是答案y在M次中出现的次数。共识度取值范围为[0,1]:1.0表示所有解码完全一致,接近0表示答案高度分散。
2.2 路由决策
基于共识度,E-GRM执行简单的二元路由:
[
\text{Route}(x) =
\begin{cases}
\text{Short-path(短推理)}, & \text{Consensus}(x) \ge \tau
\text{Long-path(长推理)}, & \text{Consensus}(x) < \tau
\end{cases}
]
论文设置阈值(tau = 0.8)。当M=5时,这意味着至少4/5的解码结果一致才走短路径。短路径下模型直接输出最高频的答案,完全省去CoT生成;长路径下触发完整的逐步推理。
2.3 阈值的工程意义
τ=0.8的选择有多层考量。过高(如1.0)会导致大量本可快速回答的问题进入长路径,效率提升有限;过低(如0.6)则会让模型在不确定性较高时仍不启动推理,精度受损。
0.8恰好在MATH数据集上对应了一个自然的“断点”——约58%的样本共识度高于0.8,42%的样本低于此阈值。这个分布本身也说明:即便在数学竞赛级别的数据集中,仍有超过一半的问题模型可以“一眼看穿”。
表1:不同触发策略在MATH上的表现
| 策略 | 准确率 (%) | 平均延迟 (s) | 是否依赖人工规则 |
|---|---|---|---|
| Forced-CoT(一律推理) | 75.1 | 3.8 | 否 |
| Rule-based(规则路由) | 70.5 | 2.1 | 是 |
| AdaCoT(特征路由) | 76.8 | 2.9 | 是 |
| E-GRM(共识度路由) | 78.4 | 2.2 | 否 |
表注:E-GRM在准确率和延迟上均占优,且不依赖任何人工设计的路由规则。
3. 判别式评分器:混合损失下的精细评估
动态触发解决了“是否推理”的问题,但一旦进入长路径,模型仍然需要从多条候选推理链中选出最优的一条。传统投票机制在这里的缺陷已经分析过——它无法区分不同质量的推理。
3.1 评分器的设计
E-GRM引入了一个轻量级的判别式评分模块(S_\phi)。它以输入x和推理路径r为输入,输出标量质量分数(\hat{q} = S_\phi(x, r) \in [0,1])。这个分数的核心价值在于:它为每条推理路径提供了一个可比的、连续的质量估计,而不是投票中“是/否”的二元判断。
3.2 混合损失函数
评分器训练采用混合损失:
[
L_{\text{scorer}} = \alpha \cdot \ell_{\text{Huber}}(q, \hat{q}) + (1 - \alpha) \cdot \ell_{\text{Hinge}}(r^+, r^-)
]
其中:
- Huber损失处理回归任务:它使预测分数(\hat{q})尽可能贴近真实质量标签(q)。相比MSE,Huber对异常值(如错误标注的样本)不敏感,提供更鲁棒的梯度。
- 铰链损失处理排序任务:给定正例推理路径(r^+)和负例(r^-),铰链损失确保评分器为正例分配足够高的分数,使两者的差值至少超过一个预设间隔(\epsilon)。
- (\alpha)在(0,1)之间平衡两个目标的权重。
这一设计确保了评分器同时具备校准性(分数能够反映真实的正确率)和区分度(能可靠地将好推理和差推理排序)。
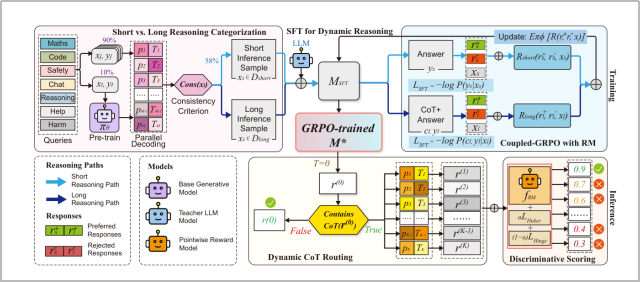
图2:E-GRM的全流程框架,上方为训练阶段(SFT+偏好优化),下方为推理阶段的动态路由与判别式评分。
4. 两阶段训练机制
4.1 监督微调(SFT):双轨学习
E-GRM的SFT阶段直接利用了动态触发的划分能力。对训练集中的每个样本(x_i)执行M次并行解码并计算共识度。共识度≥τ的归入短路径集(\mathcal{D}{\text{short}}),否则归入长路径集(\mathcal{D}{\text{long}})。
- 短路径训练:模型直接学习输入到答案的映射(\mathcal{L} = -\log P_\theta(y | x))。
- 长路径训练:模型学习生成完整推理链(\mathcal{L} = -\log P_\theta(r, y | x)),其中r为推理链的token序列。
这种区分性的训练至关重要——它确保了模型在推理阶段能根据共识度信号灵活切换“快速模式”和“深思模式”。
4.2 扩展GRPO:引入配对奖励信号
E-GRM在标准GRPO(生成式奖励策略优化)的基础上进行了扩展。其核心创新在于奖励函数的设计:
[
R_{\text{pair}}(x, r^+, r^-) = \beta \cdot \mathbb{I}[\text{Ans}(r^+) = y] + (1-\beta) \cdot (S_\phi(x, r^+) - S_\phi(x, r^-))
]
这个奖励函数包含两项:第一项是答案正确性的硬约束(正样本答案必须正确),第二项是判别式评分器给出的质量差异。(\beta)在0到1之间控制两者的权重。
优化目标为:
[
J(\theta) = \mathbb{E}{(x,r^+,r^-)\sim D{\text{pref}}}[R_{\text{pair}}(x, r^+, r^-)] - \lambda \cdot D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}]
]
其中KL散度项约束策略不偏离SFT参考模型太远,保证训练稳定性。

图3:Coupled-GRPO的成对奖励信号机制,通过评分器差值驱动策略向高质量推理方向优化。
4.3 推理流程
完整的推理管道为:
- 1.对输入x执行M次并行解码,计算共识度。
- 2.若共识度≥τ,直接输出最高频答案,流程结束。
- 3.若共识度<τ,生成K条候选CoT推理路径。
- 4.用判别式评分器(S_\phi)对K条候选分别打分。
- 5.选择分数最高的一条作为最终输出。
5. 实验与结果
5.1 基准测试全景
表2:RM-Bench跨领域评估(32B模型)
| 领域 | Chat | Math | Code | Safety | Easy | Normal | Hard | Avg. |
|---|---|---|---|---|---|---|---|---|
| E-GRM 32B | 75.6 | 80.0 | 66.5 | 94.2 | 86.0 | 80.8 | 70.7 | 79.2 |
32B模型在RM-Bench四个领域中均达到或接近最优,尤其在安全领域(94.2%)表现突出。
表3:RMB帮助性与无害性评估
| 模型 | Helpfulness (Pairwise) | Harmlessness (Pairwise) | Overall |
|---|---|---|---|
| 7B | 0.756 | 0.775 | 0.677 |
| 14B | 0.791 | 0.793 | 0.706 |
| 32B | 0.807 | 0.823 | 0.743 |
| GPT-4o | — | — | 0.738 |
E-GRM 32B以0.743的总体得分超越了GPT-4o(0.738),在无害性上达到0.823的突出水平。
表4:RewardBench评估
| 模型 | Chat | Chat_Hard | Safety | Reasoning | Overall |
|---|---|---|---|---|---|
| 7B | 94.2 | 74.8 | 85.3 | 87.0 | 85.3 |
| 14B | 93.8 | 80.6 | 87.2 | 92.1 | 88.4 |
| 32B | 95.4 | 83.3 | 92.0 | 95.4 | 91.5 |
在RewardBench上,32B模型取得了91.5%的领先成绩,尤其在推理(95.4%)和安全(92.0%)子集上达成最佳。
5.2 效率数据
在MATH数据集上,E-GRM的效率表现:
- 58%的样本进入短路径,完全跳过CoT生成。
- 推理延迟从3.8秒降至2.2秒,相对降低62%。
- FLOPs从23.7T降至15.7T,相对降低49%。
- 准确率从75.1%提升至78.4%,未降反升。
5.3 消融实验
表5:组件消融(MATH数据集)
| 变体 | 准确率 (%) | FLOPs (T) | 延迟 (s) |
|---|---|---|---|
| 完整E-GRM | 78.4 | 15.7 | 2.2 |
| 移除动态触发 | 75.2 | 23.4 | 3.4 |
| 移除判别式评分 | 72.8 | 15.9 | 2.2 |
| 基础CoT-GRM | 69.1 | 23.7 | 3.6 |
移除动态触发导致FLOPs增加49%、延迟增加55%。移除评分器导致准确率最大降幅5.6%——这说明动态触发主控效率,判别式评主控精度,两者缺一不可。
表6:偏好优化消融
| 变体 | MATH | HelpSteer2 | RMB Harmlessness |
|---|---|---|---|
| 标准GRPO | 76.9 | 81.5 | 0.765 |
| 扩展GRPO | 78.4 | 82.3 | 0.775 |
引入配对奖励信号带来了一致性提升,尤其在MATH上提升1.5个百分点。
6. 贡献与讨论
6.1 核心贡献
1.不确定性驱动的动态路由:首次将模型内部不确定性从“置信度评估工具”转变为“计算资源调度信号”,实现了与任务无关的按需推理。
2.混合损失评分器:Huber+铰链的联合训练设计,使评分器兼具校准性和区分度,在奖励信号的保真度上显著超越投票机制。
3.统一的端到端框架:将动态触发、评分和策略优化纳入一个整体,实现了效率与精度的双重突破。
6.2 局限性
1.并行解码开销:M=5次的初始解码带来约5%的额外延迟。
2.阈值依赖性:当前τ=0.8在多个领域效果稳定,但在分布外领域或对抗性场景中可能需要校准。
3.评分器泛化边界:评分器对训练数据中未覆盖的新型推理模式的评估可靠性有待检验。
7. 结论
E-GRM从根本上挑战了“更多推理总是更好”的行业假设。它在MATH数据集上将58%的问题识别为可以快速回答,在复杂问题上通过精细评分确保质量,最终实现了延迟降低62%同时精度提升的成果。
对于正在探索大模型推理效率优化的学者和工程师而言,E-GRM的核心启示在于:智能不仅体现在“能够进行深度推理”,更体现在“知道何时不需要深度推理”。
图表附录:
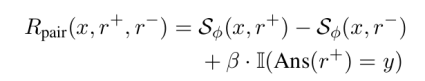
附图1:扩展GRPO的奖励函数与优化目标公式。
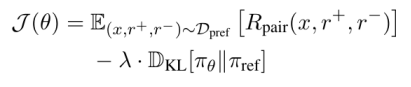
附图2:Coupled-GRPO中奖励函数的具体构造方式。
版权说明:本文为对上述ACL 2026论文的解析,旨在促进学术交流与传播。版权归原作者所有。