作者:小太阳
https://zhuanlan.zhihu.com/p/2038976197065963264
引言
笔者最近在阅读《LeWorldModel》论文和《第一性原理》一书时,偶然发现两者在方法论上有某种相通之处,于是想写下这篇博客,记录自己的一段学习与思考。
当前,大语言模型(LLM)仍处于高速发展之中。过去几年,AI 行业似乎形成了一种默认共识:更强的模型,往往意味着更多的数据、更大的参数规模,以及更多的 GPU 投入。当各家还在围绕算力规模展开竞逐时,AI 教父、图灵奖得主、前 Meta 首席科学家杨立昆(Yann LeCun)团队于 2026 年 03 月发布的论文 《LeWorldModel: Stable End-to-End Joint Embedding Predictive Architecture from Pixels》,却展示了另一种截然不同的可能。
论文提出的新型世界模型 LeWorldModel,仅用单张 GPU、数小时训练和约 1500 万参数即可完成。并且其规划速度比基于基础模型的世界模型快 48 倍,完整规划耗时不到 1 秒。这样的结果之所以引人注目,并不只是因为它更省,而是因为它似乎指向了一种不同的建模思路。
同时,这也引出了一个值得认真思考与讨论的问题:当整个行业都在沿着更大模型、更多算力的路径持续前进时,LeWorldModel 是否在提醒我们,AI 的发展未必只有规模扩张这一种答案?
论文:https://arxiv.org/pdf/2603.19312v1
仓库地址:https://github.com/lucas-maes/le-wm
一、大语言模型(Large Language Model,LLM)局限性
1.1 LLM的成就:读万卷书的通才
最近几年,LLM的成就有目共睹:
- 海量知识的压缩与生成:它学习了人类文本中的绝大部分公开知识,能够用流畅、多样的语言回答各种问题。
- 通用任务能力:无论是写邮件、总结文档、翻译语言,还是生成代码,LLM 都表现出超越常人的效率。
- 模式匹配与类比迁移:它能在不同领域之间建立表层类比,比如用莎士比亚风格解释量子力学。
LLM 可以视为"读万卷书"的终极形态。它接触过的文本规模远超任何个体人类,也因此能够在语言空间中展现出惊人的知识覆盖面和表达能力。然而,问题也恰恰出在这里:它读过无数关于世界的描述,却从未真正走出过书本。
1.2 LLM的天花板:没有脚的文字智能
尽管 LLM 令人惊叹,但它有几个不可忽视的本质缺陷:
- 缺乏真实世界的第一手经验:它知道火是热的,但不知道被烫的疼痛;它知道雨是湿的,但不理解淋雨后换衣服的麻烦。所有这些知识都来自文字的间接描述。换言之,LLM 掌握的是关于世界的语言表征,而不是世界本身的经验结构。
- 没有因果推理能力:LLM 的逻辑本质是词语的统计相关性,而不是因果关系。稍微改变问题中的数字或表述,答案就可能变得矛盾或荒谬。
- 没有稳定的内部世界模型:LLM 在处理每一个新问题时,不会在脑中构建一个持续的、可仿真的世界状态。它更像是在做高级的词语接龙——根据上文预测下文,而不是真正的理解与推演。
1.3 杨立昆核心观点:LLM 就是一条死路
- 思维链暴露的是模仿而非推理:当要求 GPT 解决一个需要 30 步推理的数学问题时,它通常会失败;但若提供思维链(Chain-of-Thought)提示,要求它逐步展示推理过程,成功率会显著提升。这一现象恰恰说明:模型本身并不具备真正的推理能力,它只是在模仿训练数据中见过的推理模式。
- 延长推理链只治标不治本:如果一个复杂问题需要生成 10000 个 token 来完成推理,其计算成本将高得不可行;更关键的是,tokens 越多,累积误差越大,最终结果的可靠性反而下降。当前通过增加 tokens 数量或强化思维链来提升推理能力的做法,只是在既有架构上打补丁,并未触及 LLM 缺乏深层世界理解与可靠推理机制这一根本局限。
- 走向世界模型:一种有潜力的替代方案是构建世界模型(World Model),一个能够理解物理世界运作规律、具备预测与规划能力的 AI 系统。
那么,究竟什么是世界模型?当前有哪些主流技术范式?杨立昆所主张的核心架构又是什么?围绕这些问题,下文将逐一展开。需要提前说明的是,世界模型的研究版图相当广阔,本文的讨论将主要聚焦于杨立昆所提出的核心架构及其基本原理。
二、世界模型(World Model , WM)
2.1 世界模型擅长行万里路
2.1.1 基本概念
世界模型通过学习环境动态,捕捉当前状态并预测未来演化,为 AI 提供内部的仿真、规划与决策能力。它如同一个内置的虚拟仿真系统,复刻了物理世界的空间结构、运动规律与因果关系,使 AI 无需在真实环境中反复试错,即可在虚拟空间中推演与优化动作,从而大幅提升决策效率与安全性。
换一种更直觉的说法,世界模型就是你心智中的沙盘。当你闭着眼睛走进自己的卧室,你不会撞到床角,因为你的大脑里有一个卧室的空间模型,你已经模拟出了路径。这就是一个简化的世界模型。
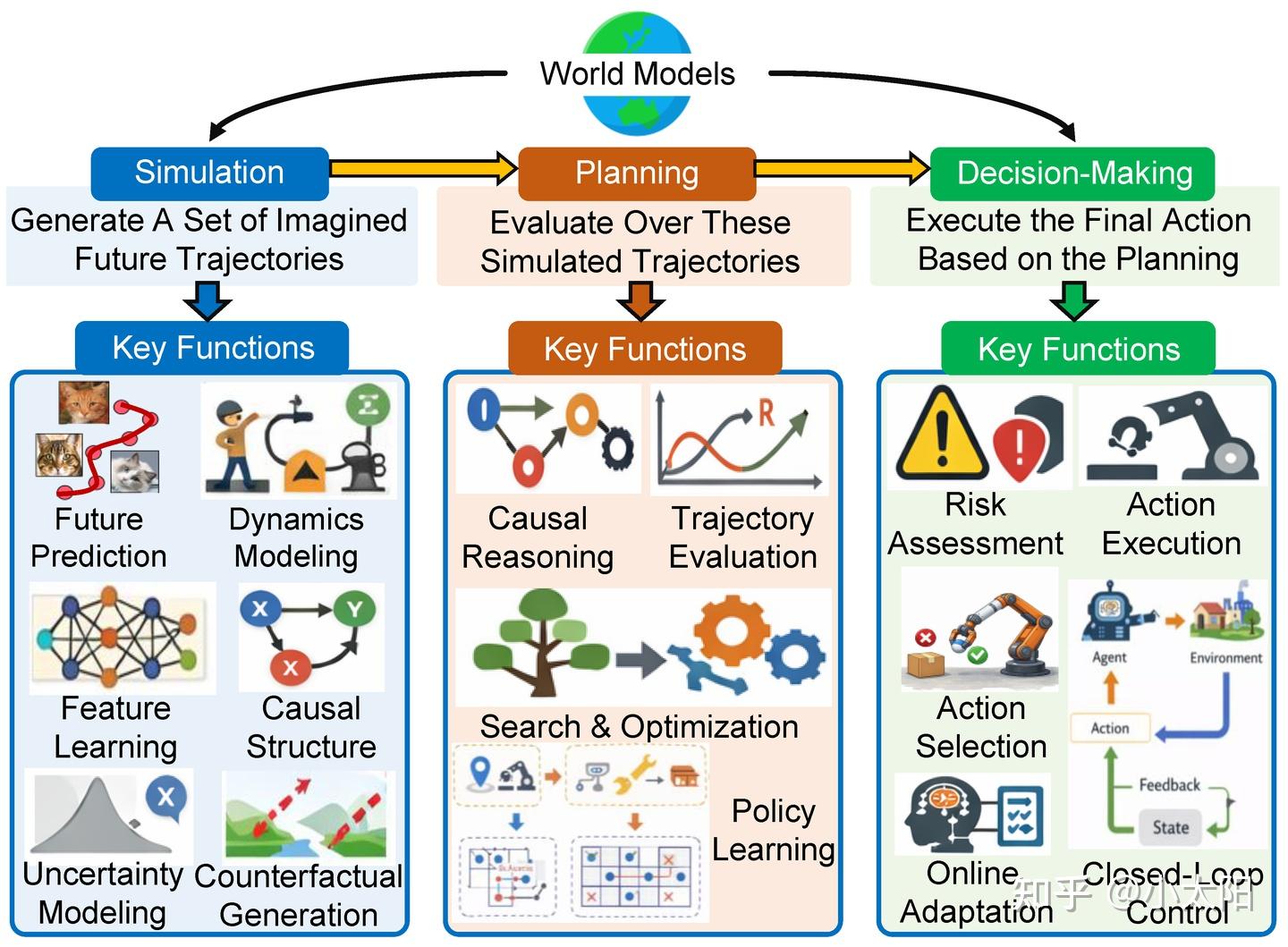
世界模型三大核心阶段可以概括为:仿真(Simulation)、规划(Planning)、决策(Decision-Making)。三者构成了一个从预测未来到选择方案再到执行行动的连续流程:
- 仿真(Simulation):仿真阶段主要负责根据已有环境状态生成一组想象中的未来轨迹,通过未来预测、动态建模、特征学习、因果结构建模、不确定性建模和反事实生成,帮助模型推演环境可能的发展方向。
- 规划(Planning):规划阶段在仿真生成的多条未来轨迹基础上进行评估和优化,通过因果推理、轨迹评估、搜索与优化以及策略学习,筛选出更符合目标的行动路径或策略。
- 决策(Decision-Making):决策阶段根据规划结果执行最终动作,并结合风险评估、动作选择、动作执行、在线适应和闭环控制,使智能体能够在真实环境中安全、有效地完成任务。
2.1.2 数学定义
一般来说,在时间步 t,世界模型可以被看作一个函数,它利用历史状态以及可选的动作来预测未来的潜在环境状态:
变量说明:
- \pi_{\theta}(\cdot):表示世界模型
- z_t:t 时刻潜在环境状态
- a_t:t 时刻智能体所选动作
- o_{t+1}:t+1 时刻的观测信息
这里有一点要注意,o_{t+1} 是环境直接返回的原始感知数据,是高维数据,而 z_{t+1} 是模型内部学习到的压缩、抽象表示。那为什么不能直接用 o_{t+1} 作为 z_{t+1}?因为原始观测维度太高、包含太多无关细枝末节的信息,直接用于规划会消耗巨大算力,而且难以抽象出因果规律。世界模型就是要学习一个简洁的 z 空间,在那里预测和规划既高效又鲁棒。
一个直观的类比:想象你是一个自动驾驶 AI
| 时间步 | 输入 | 输出 |
|---|---|---|
| t 时刻 | o_t:此刻摄像头拍到的 1080p 高清图像,包含天空、树木、路人、车辆、光影、阴影等全部细节 | z_t:从图像中提取的关键信息,比如自车位置(3 个坐标)、速度(3 个分量)、周围障碍物的位置和速度(若干个)、车道线曲率等。这是一个低维的"状态快照" |
| t+1 时刻 | o_{t+1}:新的一帧高清图像,反映了车辆移动后的真实画面 | z_{t+1}:通过 z_t、动作 a_t 和 o_{t+1} 更新后的新潜在状态 |
基于上面的预测机制,世界模型做如下三步:
- 利用已学习的动态模型生成多条想象未来轨迹 \{\zeta_i\}_{i=1}^{\phi}。其中第 i 条预测轨迹可表示为:\zeta_i = \{\eta_i^t\}_{t=1}^{T}。其中,每条轨迹由 T 个连续环境状态组成。
- 规划模块对候选轨迹进行评估优化,以确定期望轨迹及其对应的动作序列:{a_t}_{t=1}。
- 决策模块依据规划结果选择并执行最终动作。
由此,世界模型实现了从环境动态预测到轨迹仿真、动作规划和决策执行的完整闭环。
那么,这种"仿真→规划→决策"的闭环机制,与当前大语言模型所依赖的"输入→输出"模式,在底层逻辑上究竟有何本质不同?下面从几个关键维度进行对比。
2.2 LLM与世界模型的主要区别
| 维度 | LLM | 世界模型 |
|---|---|---|
| 知识来源 | 二手文本(读万卷书) | 一手交互(行万里路) |
| 内在表征 | 高维向量中的词语关联 | 可仿真的状态空间、因果图 |
| 核心能力 | 记忆、匹配、生成流畅文本 | 预测、想象、规划、因果推理 |
| 典型错误 | 产生"幻觉",逻辑不自洽却不自知 | 模型不精确时可能预测错误,但通常自洽 |
| 对世界的态度 | 旁观者,描述世界 | 参与者,模拟世界 |
有常言道:"读万卷书,不如行万里路"。LLM 像是熟读兵书的书生,纸上谈兵头头是道,但真上了战场,可能连粮草调度都算不清;而世界模型则像身经百战的将军,未必能背诵兵法原文,却能在心中推演山川地形、敌我态势。
笔者一直敬佩那些从男性主导领域中脱颖而出的女中豪杰,尤其觉得穆桂英挂帅时英姿飒爽、威武霸气!!而这种实战中的运筹帷幄,恰是世界模型的生动写照。下面,笔者将通过《穆桂英挂帅》中的沙盘推演,直观展示上述区别。
2.3 举例说明:《穆桂英挂帅》沙盘推演
场景还原:敌军压境,穆桂英没有立刻点兵出营。她走到沙盘前,上面有山川河流、城寨关隘、兵力标识。她开始在内心推演:
- 若我佯装败退,诱敌至葫芦谷……敌人会追多快?谷口能容纳多少人?
- 若此时我放火烧谷……风向如何?能烧掉多少敌兵?
- 若敌将识破,分兵两路……我哪一路伏兵会被反包?
她并不需要真的去葫芦谷打一仗,只需在沙盘上,也就是在她的世界模型中,预演多种方案,就能选出损失最小、战果最大的排兵布阵,然后才下达军令。这正是世界模型在现实中的威力:在行动之前,你就已经"真正地"走了一遍未来。
如果穆桂英只读过兵书,没有真实的作战经验,也没有在脑中建立动态的沙盘推演能力,那么她充其量只是一个"兵书 LLM"。背得再熟,也打不了胜仗。因为推演不等于检索。读万卷书(LLM)给了她兵法的文本知识,而行万里路(世界模型)给了她运筹帷幄、未卜先知的智慧。
三、世界模型四大主流技术范式
3.1 观测级生成式世界模型
观测类视觉世界模型主要通过视频生成模型、多模态 Transformer 以及 3D/4D 生成技术,直接在高维视觉空间中预测未来环境状态。其核心思路是将历史视觉观测、动作和文本等信息统一编码,并利用自回归预测、扩散生成或三维几何建模方法生成未来图像、视频或动态三维场景。
代表模型:Emu3
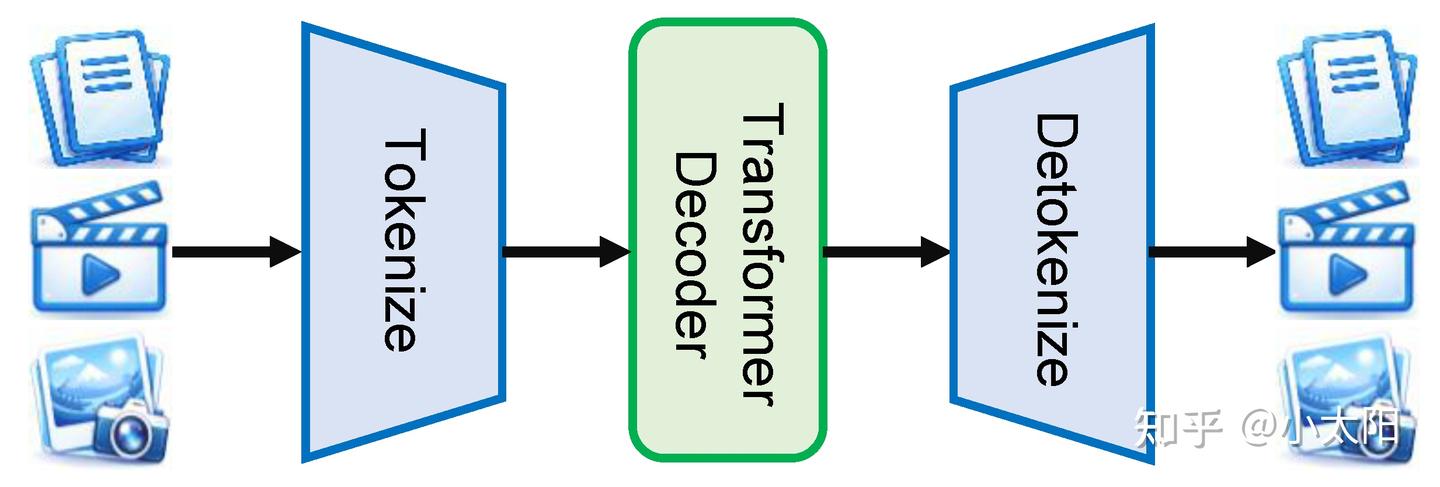
实现流程:将文本、图像和视频等不同模态统一建模。其关键在于把多模态数据全部转换为 tokens 序列,使 Transformer Decoder 能够像处理语言一样处理多模态信息,并最终生成多种形式的输出。
3.2 以对象为中心的世界模型
不再直接对整幅图像或像素进行建模,而是将场景分解为多个对象或视觉概念,并用一组可学习的 slots 来表示这些对象。模型通过预测未来时刻的对象 slots,学习对象级别的动态变化。
代表模型:SlotFormer
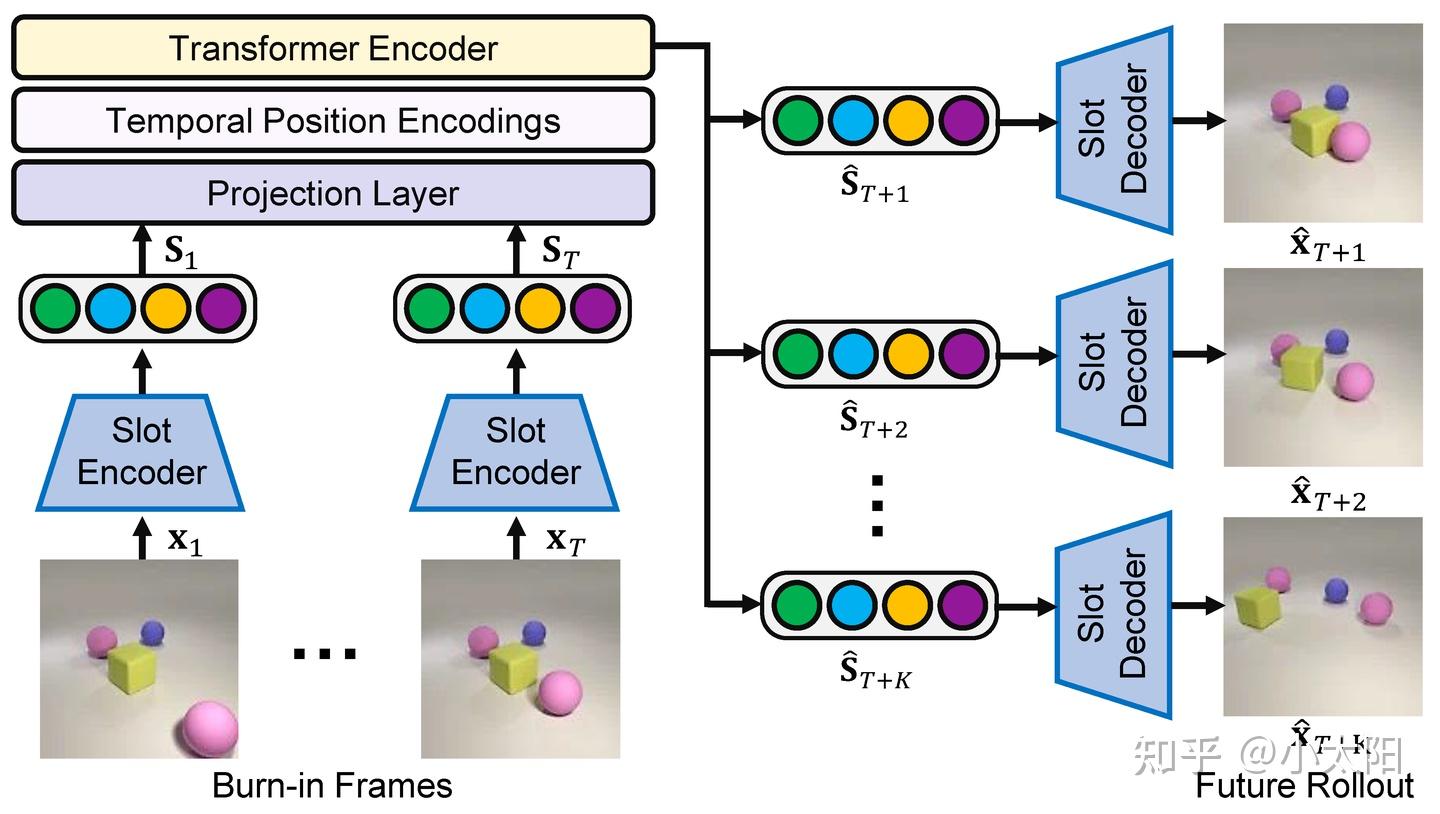
实现流程:
- 将历史观测帧 \{x_1, x_2, \ldots, x_T\} 通过 Slot Encoder 编码为对象级 slots。S_t = \{s_t^1, s_t^2, \ldots, s_t^N\} 代表第 t 帧中的一组 slots。
- Projection Layer、Temporal Position Encodings:将 slots 映射到 Transformer 输入空间并加入时间顺序信息。
- Transformer Encoder:建模对象之间、时间之间的动态关系并输出未来 K 个时间步的对象级预测结果 \hat{S}_{T+1}, \hat{S}_{T+2}, \ldots, \hat{S}_{T+K}。
- Slot Decoder:将未来 slots 解码为图像,即 \hat{S}_{T+k} \rightarrow \hat{x}_{T+k}。
3.3 RL-based 世界模型
智能体不直接依赖真实环境反复试错,而是学习一个环境动态模型,并在潜在空间中想象未来可能发生的状态和奖励,从而进行规划和策略学习。其中,**循环状态空间模型(Recurrent State-Space Model,RSSM)**是该方向的主流结构,Dreamer 系列是代表性方法。
代表模型:DreamerV3
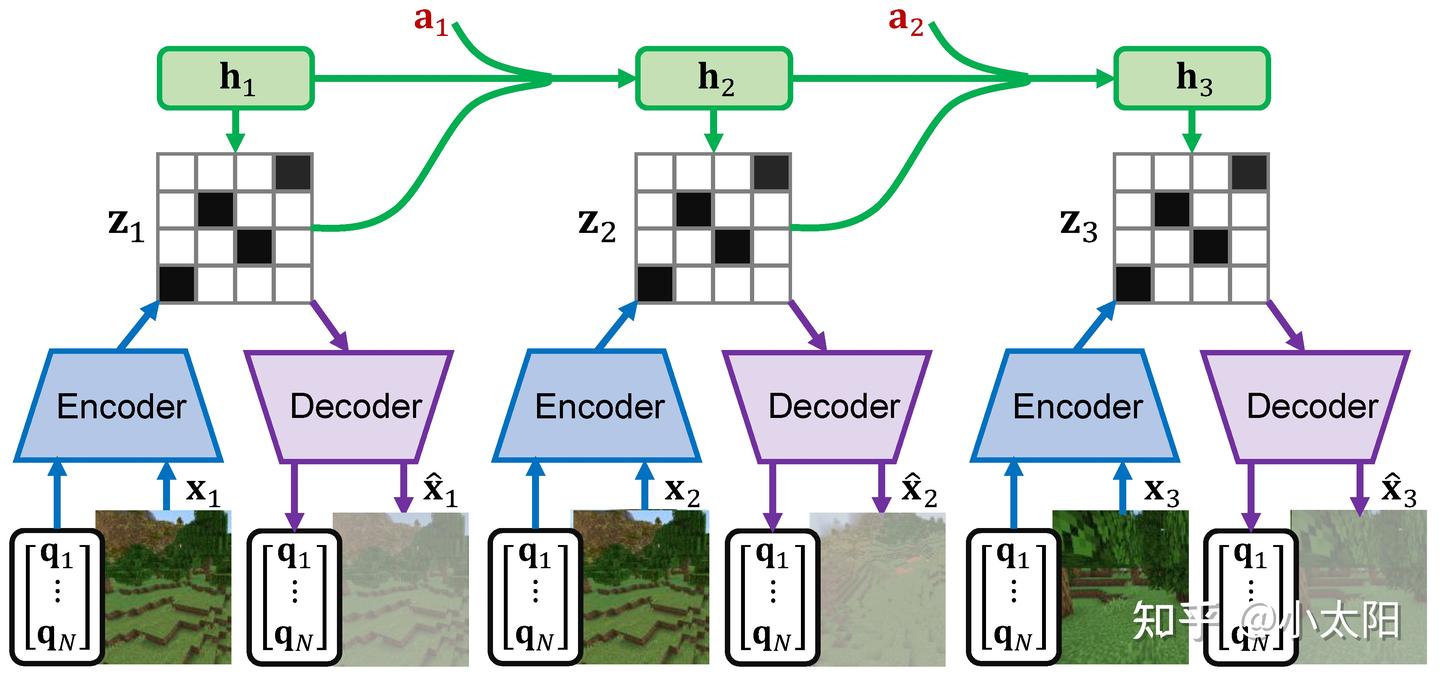
实现流程:
- Encoder:对于观测图像 x_t,Encoder 将其编码成潜在状态 z_t,更抽象、更低维的隐变量表示。
- RSSM 维护一个循环隐藏状态 h_t。其中 h_t 表示确定性隐藏状态,由上一时刻的隐藏状态 h_{t-1}、上一时刻的潜在状态 z_{t-1} 以及上一时刻执行的动作 a_{t-1} 决定:
- Decoder:根据潜在状态 z_t 和隐藏状态 h_t,生成观测图像 \hat{x}_t,即还原成可见图像。
3.4 隐空间世界模型
先将高维视觉观测编码为抽象的潜在表示,再在该潜在空间中预测未来状态变化,从而更高效地捕捉环境的语义结构、运动规律和动作影响,为仿真、规划和控制提供支持。
代表模型:V-JEPA 2
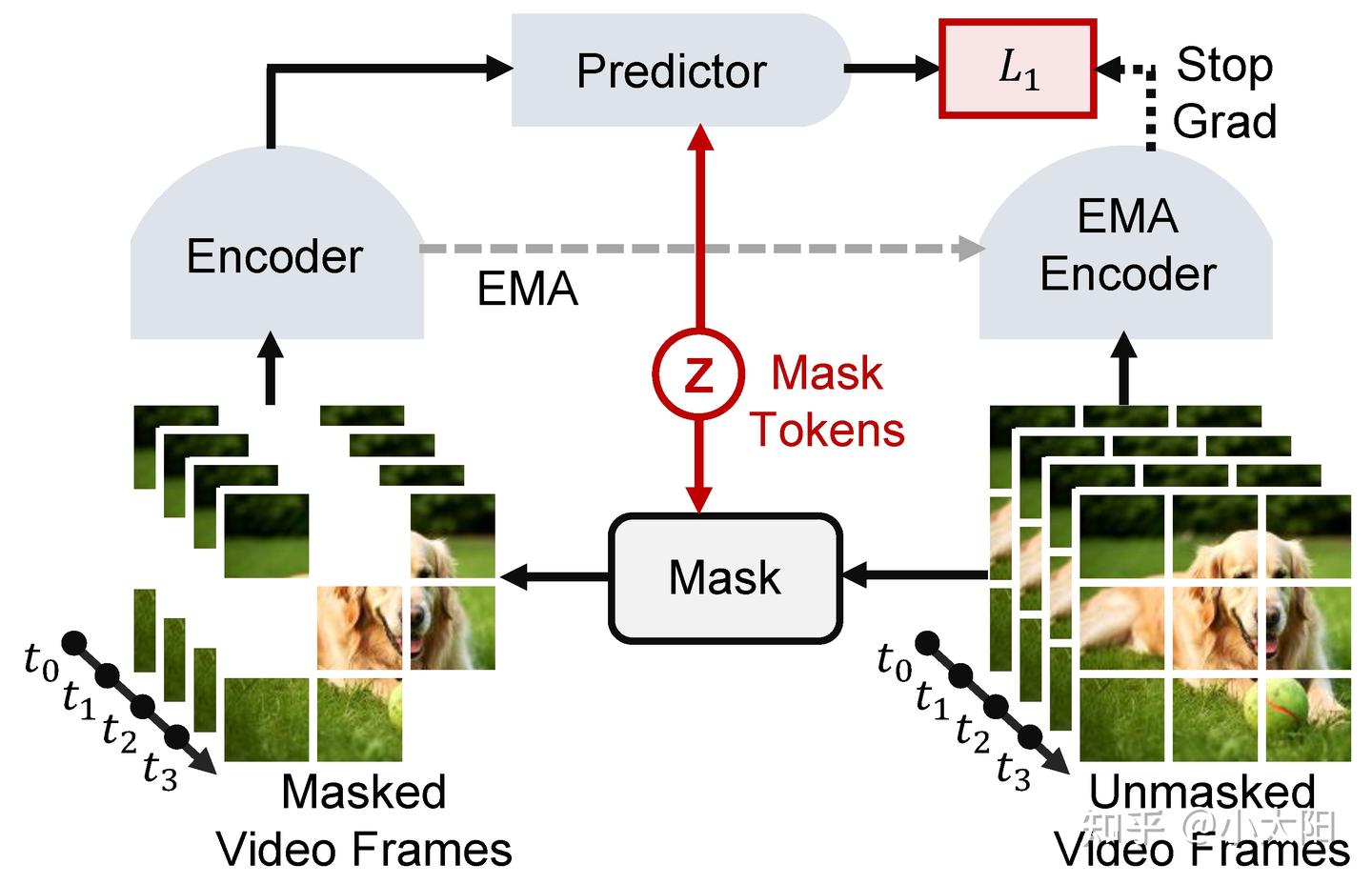
隐空间世界模型就是杨立昆一直所主张的核心架构 JEPA 所实现的模型,下面我们对其进行详细介绍。
四、杨立昆主张的核心架构:联合嵌入预测架构(Joint-Embedding Predictive Architecture,JEPA)
JEPA 本质上是一种自监督学习(Self-Supervised Learning, SSL)方法。而要真正理解 JEPA 的设计动机与独特之处,有必要先回顾自监督学习在计算机视觉领域的代表性流派。
4.1 自监督学习方法
4.1.1 SimCLR:基于对比学习的视觉自监督方法
- 核心思想:对同一张图片做两种不同的数据增强,得到两个视图,让模型学会把它们的表示拉近;同时把不同图片的表示推远。
- 训练目标:最大化同一图像不同增强视图之间的相似度,最小化不同图像之间的相似度。
- 缺点:依赖大量负样本,大 batch 和强数据增强。
4.1.2 MAE:基于重建的掩码自编码器
- 核心思想:随机遮住图像中的大部分 patch,只把少量可见 patch 输入 encoder,然后让 decoder 重建被遮住的图像内容。
- 训练目标:根据可见 patch 的信息,重建被 mask 掉的 patch 的像素值。
- 缺点:可能过度关注低层像素、纹理和细节,语义抽象性相对不足。
4.1.3 JEPA:基于联合嵌入预测的自监督方法
- 核心思想:在抽象表示空间中进行预测,而不是在原始像素空间中进行重建。
- 训练目标:最小化预测表示与目标区域的真实表示之间的差异(真实表示通常由目标编码器对目标区域编码得到)。
从设计思路上看,JEPA 融合了 MAE 与 SimCLR 的优点:
- 它像 MAE 一样采用掩码预测的学习范式,通过上下文推断缺失内容;
- 但它不像 MAE 那样在像素层面重建,而是借鉴了 SimCLR 对表征空间的关注,在抽象的嵌入空间中进行预测,从而避免模型陷入纹理、亮度等低层细节,更专注于学习语义层面的不变性特征。
举个通俗的例子来说明:给你一张蒙娜丽莎的画,遮住她的眼睛周围。
| 方法 | 要求 |
|---|---|
| 像素重建 | 要求你精确画出被遮住的每一根睫毛、眼角的皱纹、瞳孔中的反光形状,稍有偏差就算错 |
| JEPA | 要求你在"面部特征语义空间"中回答:"这里应该是略带微笑的眼睛,眼神柔和"。模型学到的是"眼睛"和"微笑"这些抽象概念,而不是像素的精确排列 |
但是 JEPA 也有一个潜在问题:所有不使用负样本的自监督学习方法,都存在**表征坍塌(Representation Collapse)**问题。模型为了最小化训练损失,可能学到一种"投机取巧"的无效解。无论输入是什么,都输出相同或几乎相同的特征表示。
关于这一问题,我们暂且留到后文展开。在具体介绍 LeWorldModel 时,笔者将结合其方法设计,进一步分析表征坍塌产生的原因以及 LeWorldModel 是如何对此进行规避或缓解的。
4.2 I-JEPA(Image-based Joint-Embedding Predictive Architecture)
由 Meta AI 研究团队于 2023 年 06 月发布,是 JEPA 理论框架在图像领域的首次实践。
4.2.1 核心思想
在抽象的表征空间中对缺失信息进行预测,而非在像素空间内重建细节,这便是 I-JEPA 的核心思想。具体而言,给定一张图像,模型首先随机遮挡若干个目标区域(target blocks),然后仅利用剩余的上下文区域(context block),在表征空间中预测这些被遮挡区域所对应的特征表示。由于预测目标是抽象的语义表征而非具体的像素值,模型得以聚焦于图像的高层语义结构,并自然地忽略那些难以预测的低层细节。
4.2.2 架构设计
I-JEPA 的整体架构由三个核心组件协同构成:上下文编码器(context Encoder)、目标编码器(target Encoder)与预测器(predictor)。三者相互配合,共同形成一个完整的自监督学习系统。

- 上下文编码器(ViT):将输入图像划分为小块,随机采样一个覆盖 85%–100% 面积、1:1 比例的可见区域,将其编码为特征序列。
- 目标编码器(同上下文编码器):为被遮挡的目标区域生成真值表征。参数不通过梯度下降更新,而是采用上下文编码器参数的**指数移动平均(Exponential Moving Average, EMA)**进行动量更新。
- 预测器(轻量 Transformer):根据上下文编码器的输出预测目标区域的特征。输入包括上下文特征和一组可学习的掩码 token(携带目标区域的位置信息,通过位置嵌入编码),输出为预测的目标区域特征。
4.2.3 损失函数
I-JEPA 的损失函数:让模型预测的 target patch 表征尽可能接近 target encoder 产生的真实 patch 表征,使用的是 patch-level 的平方 L_2 距离,并对多个 target block 取平均:
变量说明:
- M:一张图像中采样的 target blocks 数量
- i:第 i 个 target block 的索引,其中 i = 1, 2, \ldots, M
- \hat{s}_y(i):第 i 个 target block 的预测表示
- s_y(i):第 i 个 target block 的真实目标表示
- D(\hat{s}_y(i),\, s_y(i)):第 i 个 target block 上预测表示 \hat{s}_y(i) 与真实表示 s_y(i) 之间的距离
- B_i:第 i 个 target block 中包含的 patch 索引集合
- j:第 i 个 target block 内某个 patch 的索引,满足 j \in B_i
- \hat{s}_{y_j}:第 j 个 target patch 的预测表示向量
- s_{y_j}:第 j 个 target patch 的真实目标表示向量
- \| \hat{s}_{y_j} - s_{y_j} \|_2^2:第 j 个 target patch 的预测表示与真实目标表示之间的平方欧氏距离
4.2.4 核心代码
import torch
import torch.nn as nn
from einops import rearrange
class IJEPA(nn.Module):
"""I-JEPA: 基于图像的联合嵌入预测架构"""
def __init__(
self,
image_size=224, # 输入图像边长
patch_size=16, # 图像块边长
encoder_dim=768, # 编码器输出维度
predictor_dim=384, # 预测器内部维度
encoder_depth=12, # 编码器 Transformer 层数
predictor_depth=6, # 预测器 Transformer 层数
num_heads=12, # 注意力头数
ema_momentum=0.996 # EMA 动量
):
super().__init__()
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) ** 2 # 224/16=14, 14^2=196
self.ema_momentum = ema_momentum
# 上下文编码器(ViT)
self.context_encoder = VisionTransformer(
image_size=image_size, patch_size=patch_size,
dim=encoder_dim, depth=encoder_depth, heads=num_heads
)
# 目标编码器(结构与上下文编码器相同,参数通过 EMA 更新)
self.target_encoder = VisionTransformer(
image_size=image_size, patch_size=patch_size,
dim=encoder_dim, depth=encoder_depth, heads=num_heads
)
self.target_encoder.load_state_dict(self.context_encoder.state_dict())
for param in self.target_encoder.parameters():
param.requires_grad = False
# 轻量预测器
self.predictor = Predictor(
encoder_dim=encoder_dim,
predictor_dim=predictor_dim,
depth=predictor_depth,
num_patches=self.num_patches
)
@torch.no_grad()
def update_target_encoder(self):
"""
使用EMA更新目标编码器的参数。
更新公式(逐参数):
θ_target_new = momentum * θ_target_old + (1 - momentum) * θ_context_current
其中:
- θ_target_old 是目标编码器当前的参数
- θ_context_current 是上下文编码器当前的参数(通过梯度下降更新)
- momentum (self.ema_momentum) 是平滑系数,通常设为一个接近 1 的值(如 0.996)
"""
for p_ctx, p_tgt in zip(self.context_encoder.parameters(), self.target_encoder.parameters()):
p_tgt.data = self.ema_momentum * p_tgt.data + (1 - self.ema_momentum) * p_ctx.data
def forward(self, images, context_masks, target_masks):
"""
前向传播:计算预测损失
images: [1, 3, 224, 224] 单张图像
context_masks: [1, 196] 上下文掩码,True 表示可见块
target_masks: list of [1, 196] 每个元素是目标区域掩码
"""
# 1. 上下文编码器:提取可见区域特征
context_tokens = self.context_encoder(images, mask=context_masks)
# 2. 目标编码器:生成全图特征(无梯度)
with torch.no_grad():
target_features = self.target_encoder(images)
# 3. 对每个目标区域计算预测损失
total_loss = 0.0
for target_mask in target_masks:
# 提取目标区域真值特征
target_tokens = self.apply_mask(target_features, target_mask)
# 预测目标区域特征
pred_tokens = self.predictor(context_tokens, target_positions=target_mask)
# L2 损失
total_loss += torch.mean((pred_tokens - target_tokens) ** 2)
return total_loss / len(target_masks)
def apply_mask(self, features, mask):
"""根据布尔掩码提取特征"""
return features[mask.unsqueeze(-1).expand_as(features)].view(features.size(0), -1, features.size(-1))
class Predictor(nn.Module):
"""轻量预测器:用上下文特征预测目标区域特征"""
def __init__(self, encoder_dim=768, predictor_dim=384, depth=6, num_patches=196):
super().__init__()
# 投影层:编码器维度 -> 预测器维度
self.input_proj = nn.Linear(encoder_dim, predictor_dim)
# 可学习掩码 token
self.mask_token = nn.Parameter(torch.zeros(1, 1, predictor_dim))
nn.init.normal_(self.mask_token, std=0.02)
# 位置嵌入
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, predictor_dim))
nn.init.normal_(self.pos_embed, std=0.02)
# Transformer 块
self.blocks = nn.ModuleList([TransformerBlock(dim=predictor_dim, heads=6) for _ in range(depth)])
# 输出投影:预测器维度 -> 编码器维度
self.output_proj = nn.Linear(predictor_dim, encoder_dim)
def forward(self, context_tokens, target_positions):
"""
context_tokens: [1, num_context, 768] 上下文编码器输出
target_positions: [1, 196] 目标区域布尔掩码
返回: [1, num_target, 768] 预测的目标特征
"""
B = context_tokens.shape[0] # B=1
# 1. 上下文特征降维
ctx = self.input_proj(context_tokens)
# 2. 为目标位置生成带位置编码的掩码 token
num_target = target_positions.sum().item()
# mask_token 扩展
pred = self.mask_token.expand(B, num_target, -1)
# 提取目标位置的位置嵌入
pos = self.pos_embed.expand(B, -1, -1)[target_positions].view(B, num_target, -1)
pred = pred + pos
# 3. 拼接上下文和预测 token
tokens = torch.cat([ctx, pred], dim=1)
# 4. Transformer 处理
for blk in self.blocks:
tokens = blk(tokens)
# 5. 提取预测部分并升维
pred_out = tokens[:, -num_target:]
return self.output_proj(pred_out)
上面的核心代码已经给出了 I-JEPA 的主要实现,并附带了详细的注释与维度说明,这里不再重复。唯一值得特别说明的是参数更新函数这里:
def update_target_encoder(self):
"""
使用指数移动平均更新目标编码器的参数。
更新公式(逐参数):
θ_target_new = momentum * θ_target_old + (1 - momentum) * θ_context_current
其中:
- θ_target_old 是目标编码器当前的参数
- θ_context_current 是上下文编码器当前的参数(通过梯度下降更新)
- momentum (self.ema_momentum) 是平滑系数,通常设为一个接近1的值(如 0.996)
"""
for p_ctx, p_tgt in zip(self.context_encoder.parameters(), self.target_encoder.parameters()):
p_tgt.data = self.ema_momentum * p_tgt.data + (1 - self.ema_momentum) * p_ctx.data
从这段代码可以看出:上下文编码器的参数通过梯度下降进行常规更新,而目标编码器的参数并不直接由梯度下降优化,而是通过指数移动平均(EMA)从上下文编码器继承而来。也就是说,目标编码器的参数本质上是上下文编码器历史状态的加权平均,变化极为平滑(动量系数通常设为 0.996 或更高)。
这背后的原因是什么?
不妨设想另一种情况:如果目标编码器的参数也采用梯度下降来更新,会发生什么?此时,预测器所面对的"正确答案"(即目标编码器的输出)每一步都会剧烈变化,导致训练过程极不稳定。模型很容易走向一条"捷径":预测器只学会复制上下文特征,两个编码器则共同坍缩为常数值输出。虽然损失很小,但学习到的表示毫无意义(表征坍缩)。
采用 EMA 更新后,目标编码器的变化大幅平滑,为预测器提供了一个稳定的回归目标。预测器无法"复制粘贴"上下文特征,而必须真正学习从可见块预测缺失块的语义,从而迫使模型学到有意义的表示。这种设计本质上是一种自蒸馏:上下文编码器(学生)从数据中学习,目标编码器(老师)通过 EMA 集成学生的历史知识。老师提供稳定的软目标,学生努力逼近,从而朝正确方向收敛。
因此,I-JEPA 正是通过 EMA 机制来有效缓解表示坍缩问题,这是其成功的关键设计之一。
4.3 V-JEPA(Video Joint-Embedding Predictive Architecture)
V-JEPA 于 2024 年 02 月由 Meta AI 发布,是 JEPA 框架从静态图像向动态视频的自然延伸。
4.3.1 本质思想
与 I-JEPA 相比,V-JEPA 的核心挑战在于如何有效建模视频中的时空动态。这是因为视频不仅包含空间维度的外观信息,还引入了时间维度的运动线索和因果关系。为应对这一挑战,V-JEPA 在时空表征空间中进行预测,从而学习到能够同时捕捉外观特征与运动信息的通用视觉表征。
4.3.2 整体架构
V-JEPA 的整体框架仍由三个核心组件构成:上下文编码器(x-encoder)、目标编码器(y-encoder)和预测器(predictor)。x-encoder 和 y-encoder 均采用标准的 Vision Transformer 架构,但仅处理各自对应的 tokens 子集。
- 上下文编码器(x-encoder):首先,将一个包含 T 帧、分辨率为 H \times W 的视频片段划分为若干个三维时空小块(3D patch),每个小块经线性映射得到一个 token,从而形成总长度为 L 的 tokens 序列。随后,随机采样一个连续的上下文块作为唯一可见区域,其余小块对应的 token 均被遮盖。最后,移除所有被遮盖的 tokens,编码器将长度为 N 的 tokens 序列编码为特征序列。
- 目标编码器(y-encoder):y-encoder 输入的是完整的 tokens 序列(无掩码,长度为 L)。y-encoder 编码完整序列后,移除可见 tokens,保留被遮盖 tokens 的特征,得到长度为 M 的 tokens 序列(其中 M = L - N)。
注意:这一设计区别于 I-JEPA 中目标编码器仅处理被遮盖目标区域的做法。差异的根本原因在于图像与视频的信息密度不同:静态图像的信息密度较低,若目标编码器也看完整图像,预测器容易"作弊",导致表征坍缩;而视频作为连续动态信号,本身蕴含丰富的时空信息。若将视频的目标编码器也切碎,就会丢失这种动态连续性优势。因此,V-JEPA 让目标编码器直接处理完整视频,本质上是为预测任务提供了一个高密度、高信息量的"标准答案"。
- 预测器(predictor):预测器是一个轻量级 Transformer 架构,接收 x-encoder 的输出和一组可学习的 mask tokens 作为输入。
4.3.3 损失函数
变量说明:
- x:输入视频中的上下文部分,即模型可见的那部分视频内容
- y:输入视频中的目标部分,即模型需要预测其表示的那部分视频内容
- E_{\theta}(\cdot):上下文编码器,参数为 \theta,用于将输入视频片段编码为特征表示
- \bar{E}_{\theta}(\cdot):目标编码器,通常是 E_{\theta}(\cdot) 的指数滑动平均版本
- P_{\phi}(\cdot):预测器,参数为 \phi
- \mathrm{sg}(\cdot):stop-gradient 操作,表示其内部变量不回传梯度
4.4 V-JEPA 2
V-JEPA 2 是 Meta 在 2025 年 06 月推出的开源 AI 世界模型。
4.4.1 本质思想
V-JEPA 2 是通过视频自监督学习,在潜在表示空间中预测世界状态变化,形成可用于理解和规划的世界模型。相比 V-JEPA 主要学习视频表示和物理常识,V-JEPA 2 进一步加入动作条件预测,使模型能预测行动结果并支持机器人规划。
4.4.2 整体两阶段规划
- 通用表征预训练阶段:利用 100 万小时的互联网规模视频和 100 万张图像,采用视觉掩码去噪目标对 V-JEPA 2 进行自监督预训练,使模型学习物体运动、场景变化和物理规律等高层视觉表征。随后,将其与 LLM 主干对齐,以支持动作分类、目标识别、动作预测和视频问答等下游任务。
- 动作条件规划阶段:冻结预训练视频编码器,仅利用少量机器人交互数据,在已学习表征之上训练动作条件预测器,即 V-JEPA 2-AC。该模型用于预测不同动作导致的未来状态变化,并在模型预测控制(MPC)循环中评估候选动作序列,选择最有利于达成目标的动作,从而实现机器人操作规划。
4.4.3 架构设计
V-JEPA 2 视觉预训练:模型首先将视频划分为时空 tokens,并随机遮挡其中一部分 tokens。被遮挡后的视频输入 encoder,得到可见区域的表征。随后,模型引入 mask tokens,并通过 predictor 预测被遮挡区域的高层表征。这里的监督目标不是原始像素,而是由 EMA encoder 对完整视频生成的目标表征。ema encoder 通过 encoder 参数的指数滑动平均进行更新,并通过 stop-gradient 阻止梯度反传,因此能够提供更加稳定的预测目标。最终,模型使用 L1 loss 约束 predictor 输出与 EMA encoder 目标表征之间的距离。
V-JEPA 2-AC 的动作条件预测训练:训练好的视频 encoder 被冻结,模型不再更新视觉表征,而是在固定的表征空间中训练一个新的 action-conditioned predictor。该 predictor 接收过去视频帧的视觉表征,同时融合机器人动作和末端执行器位姿信息,预测未来视频帧的表征。真实的未来帧同样经过 frozen encoder 得到目标表征,并通过 L1 loss 对预测结果进行监督。
4.5 V-JEPA 2-AC
以一个桌面机械臂控制场景为例,说明该框架的具体实现。该系统由一台配备固定外部视角相机的 7 自由度 Franka Emika Panda 机械臂组成,机械臂末端带有双指夹爪,控制动作对应于末端执行器命令。
4.5.1 训练数据
模型训练使用了原始 Droid 数据集中约 62 小时的未标注视频数据。该数据集由大量 3–4 秒的短视频组成,记录了机械臂执行不同操作过程。
未标注视频:指的是训练过程中不使用奖励信号、任务类别、任务成功与否等额外语义标注信息。模型仅利用原始视频帧以及与每帧对应的末端执行器状态信息进行学习,其中状态信息包括三维位置、三维姿态和一维夹爪状态。
核心思想是学习一个类似这样的关系:当前图像 + 当前机器人状态 + 动作 → 下一时刻图像表征
具体步骤如下:
- 4 秒视频变成 16 帧图像(4 fps):x_1, x_2, \ldots, x_{16}
- 每帧图像都有一个机器人状态:s_1, s_2, \ldots, s_{16}
- 每个 s_k 是一个 7 维向量,表示第 k 帧时机械臂末端的位置、姿态和夹爪状态:
- 动作不直接给出,而是表示从当前帧状态变化到下一帧状态的变化量:
4.5.2 损失函数
V-JEPA 2-AC 以自回归方式进行训练,将单步预测误差(Teacher Forcing Loss)和多步滚动预测误差(Rollout Loss)相加作为总损失:
Teacher Forcing Loss:训练模型的单步预测能力
Rollout Loss:多步自回归预测能力
自回归预测过程:
4.5.3 下游任务规划控制
对于训练好的 V-JEPA 2-AC 世界模型,机器人如何进行决策呢?
核心思想:给定当前状态和目标图像,搜索一串机器人动作,使得机器人执行这串动作之后,世界模型预测出的未来状态和目标状态最接近。
目标导向的能量函数:
其中:
- \hat{a}_{1:T}:表示从第 1 步到第 T 步的候选动作序列
- z_k = E_\theta(x_k):当前帧图像表征
- z_g = E_\theta(x_g):目标图像特征
4.5.4 V-JEPA 2-AC:零样本机器人控制能力
训练完成后,V-JEPA 2-AC 迎来了真正的考验:在真实机器人上完成具身控制任务。
研究者将 V-JEPA 2-AC 与**模型预测控制(Model Predictive Control,MPC)**结合,用于完成到达、抓取、拾取放置等基础机器人任务。任务目标由图像指定,模型需要根据当前图像和目标图像,自主规划动作序列。
MPC 的过程类似下象棋:AI 会先模拟多种可能的动作方案,选择最可能接近目标的一条路径,并只执行其中的第一步。随后,它会观察实际结果,更新当前状态,再重新规划,如此循环直到完成任务。
这些实验均在真实的 Franka Panda 机械臂上完成,并采用零样本部署方式。测试环境从未出现在训练数据中。此外,模型仅依赖一台未标定的低分辨率单目 RGB 相机作为视觉输入,没有使用深度相机或复杂标定信息。这表明 V-JEPA 2-AC 具备较强的真实场景泛化能力。
从 V-JEPA 到 V-JEPA 2-AC,模型的发展路径也愈发清晰。**从理解世界,到作用于世界。从被动观察,到主动交互。**一个能够感知、预测并改变物理世界的通用智能体,正在逐渐走向现实。
五、LeWorldModel:极简主义哲学
5.1 什么是 LeWorldModel?
2026 年 03 月,由 Mila 实验室、纽约大学、三星 SAIL 和布朗大学联合撰写,杨立昆亲自参与指导的论文发表,提出 LeWorldModel:首个能从原始像素端到端稳定训练的 JEPA 世界模型。
该模型的核心目标是从观测数据中学习通用的、与任务无关的世界模型。与传统的任务驱动方法不同,LeWorldModel 并非针对某一特定任务优化行为,而是致力于学习能够捕捉环境动态的通用表征,使其能够在后续被灵活地用于多种任务的控制或适配。
其核心特性堪称"极简主义"的典范:
| 特性 | 说明 |
|---|---|
| 参数极小 | 仅约 1500 万参数 |
| 训练极简 | 无需两阶段预训练,不使用任何启发式训练技巧(如停梯度、指数移动平均或预训练编码器),仅通过最直接的端到端联合优化即可完成训练。单张 GPU、数小时即可收敛 |
| 损失函数极简 | 无需为表征学习设计多个复杂的损失项(如重建损失、对比损失、奖励预测等)。LeWorldModel 仅需两项损失:MSE 预测损失 + SIGReg 正则项。其中,SIGReg 仅含一个超参数,并具有可证明的抗表征坍塌保证 |
5.2 架构设计
LeWorldModel 的核心思想:将复杂的世界建模问题压缩到紧凑的潜在空间中,仅保留本质组件进行处理。
仅由两个核心模块构成:
- 编码器(Encoder):将原始像素观测 o_t 映射为紧凑的低维潜在表示 z_t。编码器采用 ViT-Tiny 架构(约 500 万参数),参数为 \theta。
- 预测器(Predictor):基于当前潜在表示 z_t 和动作 a_t,预测下一时刻的潜在隐状态 z_{t+1},在潜在空间中建模环境动态。预测器采用 Transformer 架构(约 1000 万参数),参数为 \phi。
5.3 极简主义损失函数
LeWorldModel 秉持极简主义设计哲学。其训练目标高度凝练,仅包含两项核心损失函数,从而彻底摆脱了传统方法中的各类复杂技巧。
那么,如此极致精简的两个损失函数究竟是什么?让我们从数学的第一性原理出发,重新审视训练目标。概括而言,模型需要具备两项核心能力:第一,能够准确预测未来;第二,拥有足够强大的表征能力,绝不能将千差万别的输入图像坍缩为同一个潜在表示。
基于这两条原则,LeWorldModel 的完整训练目标定义为两项损失之和:
其中,\mathcal{L}_{\text{pred}} 为未来预测损失,\text{SIGReg}(\mathbf{Z}) 为抗坍缩正则化项,\lambda 为正则化项的权重系数。论文默认取 \lambda = 0.1,是模型唯一需要实际调节的超参数!!!
5.3.1 未来预测损失 \mathcal{L}_{\text{pred}}
该损失强制模型从当前观测与动作中预测下一时刻的潜在表示:
变量说明:
- z_t = \text{enc}_\theta(o_t):编码器将原始像素 o_t 映射为潜在嵌入表示
- a_t:t 时刻采取的动作
- \hat{z}_{t+1} = \text{pred}_\phi(z_t, a_t):预测器根据当前嵌入表示 z_t 和动作 a_t 给出的下一时刻预测嵌入表示
- z_{t+1} = \text{enc}_\theta(o_{t+1}):真实下一帧的编码潜入表示
5.3.2 表征坍塌(Representation Collapse)本质原因
在正式介绍抗坍缩正则化项之前,我们来思考一个问题:为什么只有预测损失会导致表征坍缩?
重新看下预测损失这个公式:
首先,如果令编码器输出恒为常数向量 \mathbf{c} \in \mathbb{R}^d,与输入 o_t 无关,即对所有时刻 t 有 \mathbf{z}_t \equiv \mathbf{c};
其次,如果令预测器也输出同一常数,即 \text{pred}_{\phi}(c, a_t) \equiv c。
则会产生如下结果:
该解使损失降至一个全局最小值 0(平凡解)。然而,编码器彻底丢失了输入信息,无论输入图像差异多大,均被映射为同一常数向量 c。换言之,只要编码器与预测器联合学习到这一常数映射,预测损失即可被完美最小化。
形象的例子:
场景设定:老师给每个学生一张图片,要求完成两个任务:
- 编码任务:用一句话抽象概括一张图片内容(相当于编码器输出 z)
- 预测任务:根据当前图片的概括句和动作(比如翻页),预测下一张图片的概括句(相当于预测器输出 \hat{z})
学生偷懒绝招:
- 不管老师给他看什么图片(猫、汽车、星空、人脸),他都直接写一句话:"这是一张图片"
- 然后预测下一张图片时,他又写:"这还是一张图片"
这样一来:
- 当前概括:z = "这是一张图片"
- 预测下一张:\hat{z} = "这还是一张图片"
- 真实下一张概括:也是"这是一张图片"(因为学生永远这么写)
- 预测误差等于 0!
老师欣喜若狂,觉得学生太牛了,预测得完全准确。
问题暴露:老师仔细一想:这个学生其实什么都没学会。问他"猫和狗有什么区别?"他答不上来。问他"下一张如果是星空,会是什么?"他仍然说"这还是一张图片"。他根本没有理解任何图片的内容差异,只是用一个恒定不变的输出蒙混过关。
这就是表征坍缩:所有的输入(无论千差万别)都被映射成了同一个潜在表示 c,而预测器也学会了输出同一个 c。损失函数完美最小化,但模型没有学到任何有意义的世界知识。
那么问题来了,老师如何纠正?
老师发现了这个问题,于是补充了两条新规则:
-
要求1:拒绝模板化,追求均匀散开
- 你们的概括句必须有区分度。如果两张不同图片的句子完全一样,扣分
- 我真正想要的是:大家的句子要像操场上散开玩耍的小朋友——到处都有,不挤成一团,也不排成一条线(各向同性高斯分布)
-
要求2:随机抽查,用模糊属性检验均匀性
- 老师会每次随机挑一个"模糊属性",比如可爱程度、亮度、动感,然后给每个句子在这个属性上打分
- 如果不管换什么属性,你们所有句子在这些维度上的得分都像标准正态分布一样,就说明句子确实散得均匀。否则,扣分(Epps–Pulley 正态性检验统计量来定量判断)
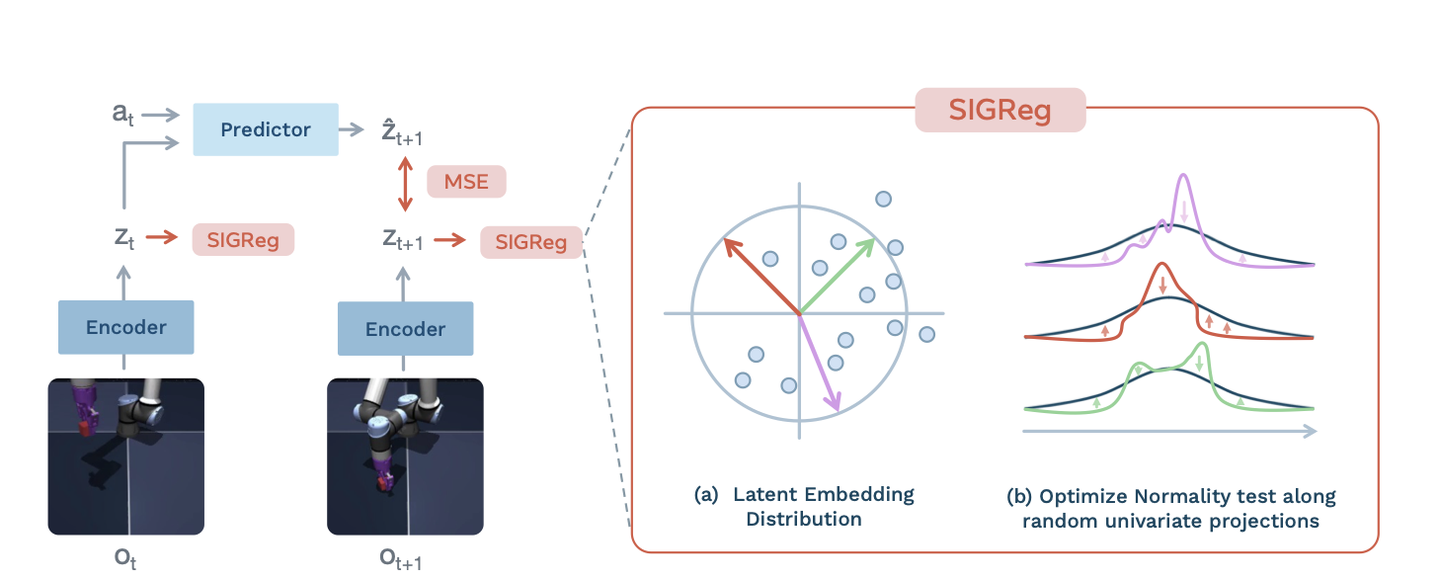
5.3.3 抗坍缩正则化 SIGReg(Sketched-Isotropic-Gaussian Regularizer)
各向同性高斯分布数学定义:
一个 d 维高斯分布 z \sim \mathcal{N}(\mu, \Sigma) 称为各向同性的,如果其协方差矩阵 \Sigma = \sigma^2 I,其中 \sigma^2 > 0 是标量,I 是 d \times d 单位矩阵。此时密度函数为:
当 \mu = 0, \sigma = 1 时称为标准各向同性高斯分布 \mathcal{N}(0, I)。这个分布具有旋转不变性(球对称)、各维度独立且同方差,是最均匀的高维球形分布。
Epps–Pulley 正态性检验统计量数学定义:
计算样本经验特征函数 \phi_N(t) 与理论特征函数 \phi_0(t) 之间平方差的积分,并用 w(t) 进行加权。因此,T 值越小,说明样本分布与目标正态分布越接近;反之,则偏差越大。
SIGReg 核心思想:使嵌入向量 \mathbf{Z} 的分布逼近各向同性的高斯分布 \mathcal{N}(0, I)。论文巧妙地结合了两个统计工具来实现高维分布匹配:
- Cramér–Wold 定理:将高维问题降为一维分布问题
- 单变量 Epps–Pulley 检验统计量:定量评估一维投影是否服从标准正态分布
数学公式:
其中:
- M:随机投影个数
- \mathbf{Z} \in \mathbb{R}^{N \times B \times d}:潜在嵌入表示向量,其中 N 为历史长度(时间步数),B 为批次大小,d 为嵌入向量维度
- \mathbf{u}^{(m)} \in \mathbb{S}^{d-1}:每个方向向量都是 d 维单位向量
- \mathbf{h}^{(m)} = \mathbf{Z} \mathbf{u}^{(m)} \in \mathbb{R}^{NB}:将整个嵌入表示向量 \mathbf{Z} 投影到方向 m 后得到的一维向量
- T(\cdot):Epps–Pulley 正态性检验统计量
对于投影向量 \mathbf{h}^{(m)} 定义:
其中:
- \phi_{NB}(t; \mathbf{h}) = \frac{1}{NB} \sum_{n=1}^{NB} e^{i t h_n}:经验特征函数
- e^{-\frac{t^2}{2}}:标准正态分布的特征函数
- w(t) = e^{-t^2 / (2\lambda^2)}:权重特征函数,\lambda 为高斯核带宽
SIGReg 作用总结:
| 效果 | 说明 |
|---|---|
| 防止坍塌 | 当所有嵌入坍缩为同一个点时,每个投影方向上的样本方差为零,投影分布与\mathcal{N}(0, 1) 差异极大,导致 T 值很大,因此正则化项会惩罚这种坍缩 |
| 高维友好 | 无需直接在高维空间做密度估计,而是通过随机投影降为一维,计算简单、可扩展 |
| 理论保证 | 由 Cramér–Wold 定理,当\text{SIGReg}(\mathbf{Z}) \rightarrow 0 当且仅当嵌入分布收敛到 \mathcal{N}(0, I) |
5.4 极简主义代码
5.4.1 主架构
def lejepa_forward(self, batch, stage, cfg):
"""编码观测,预测下一时刻的隐状态,计算 LeWM 预测损失 + SigReg 正则损失"""
ctx_len = cfg.history_size # 历史上下文长度
n_preds = cfg.num_preds # 预测步数
lambd = cfg.loss.sigreg.weight # 正则项权重
# 将序列边界处的 NaN 动作替换为 0
batch["action"] = torch.nan_to_num(batch["action"], 0.0)
# 编码:观测 -> 隐状态,动作 -> 动作嵌入
output = self.model.encode(batch)
emb = output["emb"] # (B, T, D) 隐状态序列
act_emb = output["act_emb"] # (B, T, D_a) 动作嵌入序列
# 上下文部分:前 ctx_len 步
ctx_emb = emb[:, :ctx_len]
ctx_act = act_emb[:, :ctx_len]
# 目标部分:向后偏移 n_preds 步(未来隐状态)
tgt_emb = emb[:, n_preds:]
# 用上下文预测未来隐状态
pred_emb = self.model.predict(ctx_emb, ctx_act)
# LeWM 预测损失:均方误差
output["pred_loss"] = (pred_emb - tgt_emb).pow(2).mean()
# SigReg 正则:防止表征坍缩(保持方差-协方差结构)
output["sigreg_loss"] = self.sigreg(emb.transpose(0, 1))
# 总损失 = 预测损失 + λ × 正则项
output["loss"] = output["pred_loss"] + lambd * output["sigreg_loss"]
# 日志记录
losses_dict = {f"{stage}/{k}": v.detach() for k, v in output.items() if "loss" in k}
self.log_dict(losses_dict, on_step=True, sync_dist=True)
return output
5.4.2 SIGReg 损失函数
class SIGReg(torch.nn.Module):
"""各向同性高斯正则化器(单 GPU 版)——通过检验隐变量的高斯性来防止表征坍缩"""
def __init__(self, knots=17, num_proj=1024):
"""
knots: 特征函数求值点数(在 [0,3] 区间上)
num_proj: 随机投影的数量
"""
super().__init__()
self.num_proj = num_proj
# 在 [0,3] 上生成等间距点,用于计算经验特征函数
t = torch.linspace(0, 3, knots, dtype=torch.float32)
dt = 3 / (knots - 1)
# 梯形积分权重(首尾减半)
weights = torch.full((knots,), 2 * dt, dtype=torch.float32)
weights[[0, -1]] = dt
# 标准正态的特征函数 φ(t) = exp(-t²/2)
window = torch.exp(-t.square() / 2.0)
self.register_buffer("t", t)
self.register_buffer("phi", window)
# 预乘积分权重(用于后续加权求和)
self.register_buffer("weights", weights * window)
def forward(self, proj):
"""
proj: (T, B, D) 时间步数, 批量大小, 隐变量维度
返回: 标量损失,值越小表示隐变量分布越接近各向同性高斯
"""
# 1. 采样随机投影方向(归一化到单位长度)
A = torch.randn(proj.size(-1), self.num_proj, device=proj.device)
A = A.div_(A.norm(p=2, dim=0)) # (D, num_proj)
# 2. 计算 Epps-Pulley 统计量(检验分布是否为高斯)
# 将隐变量投影到随机方向,并乘以 t 轴(升维以便广播)
x_t = (proj @ A).unsqueeze(-1) * self.t # (T, B, num_proj, knots)
# 经验特征函数:平均 cos 和 sin
cos_mean = x_t.cos().mean(dim=-3) # (B, num_proj, knots)
sin_mean = x_t.sin().mean(dim=-3)
# 与理论特征函数 φ(t) 的平方误差
err = (cos_mean - self.phi).square() + sin_mean.square() # (B, num_proj, knots)
# 3. 沿 t 轴积分(使用梯形权重),再乘以时间步数(标准化)
statistic = (err @ self.weights) * proj.size(-2) # (B, num_proj)
# 4. 返回所有投影和批次的均值
return statistic.mean() # 标量
5.5 潜在规划
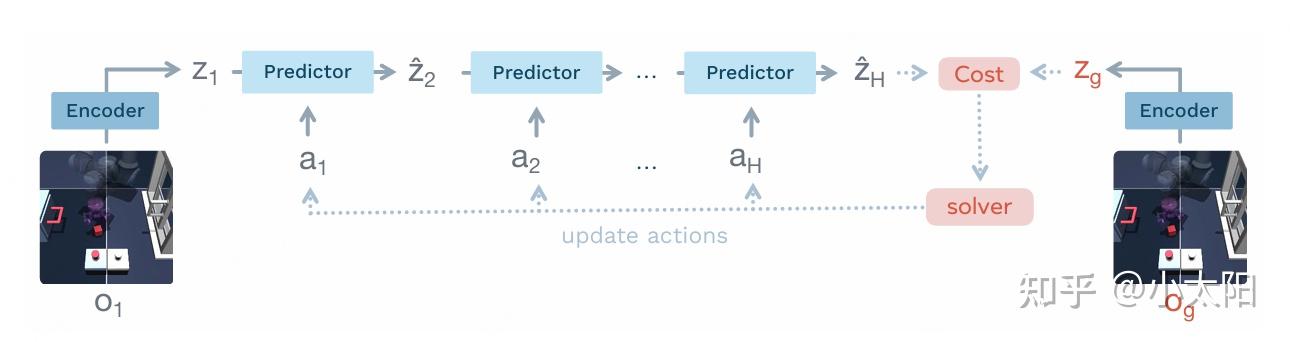
训练完成后,LeWorldModel 并不用潜在表示做分类或重建,而是直接用它进行动作规划。在推理时,我们在世界模型的潜在空间中进行轨迹优化。
做法非常直观:
- 给定起始观察 o_1,随机初始化一个候选动作序列,并迭代地展开预测潜在状态,得到 \hat{z}_2, \hat{z}_3, \dots, \hat{z}_H,直到规划到视野 H。模型根据下式预测潜在转移:
- 规划通过优化动作序列 a_{1:H} 来最小化一个终端潜在目标来匹配目标:
- 这个优化过程对应于一个有限时域最优控制问题,使用**交叉熵方法(CEM)**来求解:
但这个过程中是存在问题的:
LeWorldModel 的预测器采用自回归结构。在规划推演中,每一步的预测潜在状态 z_{t+1} 都会作为下一步的输入。由于训练数据覆盖有限且环境动态常呈现非线性,预测器必然存在近似误差。随着规划视野 H 增大,误差逐级累积,使得长时域下的 \hat{z}_H 与真实潜在状态 z_H 之间产生显著偏离。而 CEM 正是基于这些有偏的 \hat{z}_H 来评估动作序列的优劣,因此所优化出的动作序列在真实环境中往往表现不佳。
那要怎么解决呢?此时**模型预测控制(Model Predictive Control, MPC)**出场了!!
MPC 核心原理:
- 不追求单次规划完整的长时动作序列。MPC 在每个时间步仅执行当前最优动作,之后利用真实观测对潜在状态进行重估与重置,并基于新状态重新进行短视野规划。
- 滚动时域控制天然限制了开环规划的长度。MPC 只执行前 K 步动作(通常 K < H,H 为原始规划视野),随后利用新的真实观测 o_{t+K} 重新编码得到潜在状态 z_{t+K},以此作为起点再次规划。
- 每次规划均从真实潜在状态出发进行有限步预测。这显著减少了自回归误差的累积范围,提升了控制的鲁棒性与准确性。
六、从 LLM 的局限到世界模型:LeWorldModel 为何更接近 AI 的第一性原理?
我们不难感叹:最聪明的解决方案,往往正是最简单的那个。LeWorldModel 直击问题本质,将极简主义践行到底,这恰恰是第一性原理思维的生动体现。
6.1 第一性原理:回到问题的本源
第一性原理要求我们剥开表象,回到最本源的问题,不被现有方法和技术路径所束缚,直接从问题的物理定律出发去思考。马斯克曾说:"与其站在别人的肩膀上,不如回到物理定律,从原点开始推导。"
6.2 对照第一性原理,重新审视 AI
**智能的本质是什么?是预测下一个词吗?显然不是。**正如杨立昆所言:"智能的本质是学会预测"。婴儿通过扔东西理解重力,而非通过阅读物理课本。智能的根本来源,是对世界运作方式的预测能力。
用第一性原理推导:AI 应优先学习世界的运行规律,而非文字的统计模式。杨立昆倡导的正是这一理念:系统要学习的是现实世界的潜在结构与动态演化,而非单纯的文本统计关联。
6.3 LeWorldModel 对第一性原理的三层回归
第一层:回归数据源头——从零开始,不走捷径
LeWorldModel 从最原始的像素输入出发,不依赖任何预训练的 DINO 或 CLIP 特征,也不需要额外的辅助监督信号。它回到了问题的原点:当一个智能体初次睁开眼观察世界时,应该从哪些最基本的观测开始学习?
第二层:回归架构本质——简化到不能再简
LeWorldModel 的架构只有两个核心组件:一个编码器和一个预测器。它没有 EMA(指数移动平均),没有 stop-grad,也没有复杂的掩码策略。每一个曾被用来修补模型的技巧,都被彻底剥离。所有模块以端到端的方式联合训练,让数据自己说话。这种"少即是多"的思路,正是第一性原理的精髓:剥离一切浮华,直抵问题的核心。
第三层:回归问题本原——用最朴素的方式解决最难的问题
LeWorldModel 的训练目标仅由两项损失构成:预测损失用于学习世界动态,SIGReg 用于防止表征坍塌。相比现有唯一的端到端替代方案,它将可调的损失超参数从六个压缩到一个。杨立昆团队没有堆砌技巧去"修补"模型,而是找到了表征坍塌的根源,并用最直接的方式加以解决。
七、总结
写到这里,相信大家已经对世界模型有了一定的认知。本文没有过多展开模型效果的横向对比,也没有把重点放在某个指标是否领先。因为我更想讨论的,并不是 LeWorldModel 走到了哪一步,而是它背后的思考方式——一条更接近 AI 本质的路径。
当大模型架构逐渐成为行业共识时,我们反而更应该停下来追问:这一定就是最好的方法吗?共识并不等于真理,经验也不等于本质。人类曾经看到一只天鹅是白色的,十只天鹅是白色的,甚至一万只天鹅都是白色的,于是很自然地归纳出"所有天鹅都是白色的"。但只要一只黑天鹅出现,这个看似稳固的结论便会被瞬间推翻。
**这正是归纳法的局限。**它高效、直接,也符合大多数时候的经验直觉,但终究只是基于有限样本形成的低成本假设,而不是事实本身。
真正接近本质的方式,不是在既有经验上不断叠加经验,而是回到第一性原理,重新追问那些被默认接受的前提:
- 智能究竟如何形成?
- 模型是否只是学习语言表面的统计规律?
- AI 是否需要具备对世界的内部表征、预测能力和行动规划能力?
从这个角度看,杨立昆所倡导的 LeWorldModel 模型,其特性恰恰更直击智能的底层逻辑。它并不是简单地在已有大模型范式中继续做加法,而是提醒我们,技术的演进不应只是在既有共识中寻找局部最优,更应敢于回到问题本身,重新定义问题、拆解问题、构建可能性。
**个人成长亦是如此。**很多时候,我们以为自己被能力限制,其实是被假设限制。我们以为走不出去,其实是早已接受了别人划下的边界。外界的评价、行业的路径、过去的经历,也许都只是基于有限样本得出的归纳判断,而不是人生的最终答案。
不要轻易被外界定义,也不要过早为自己设限。经验可以参考,但不应成为牢笼。共识值得尊重,但不必盲从。真正的破界,始于重新追问本质。凡事从第一性原理出发,拆掉旧假设,重建新可能,我们才有机会跳出既定路径,走向更大的世界。