作者:Tunneling,本篇工作和 @黄ABC 一起完成
原文:https://zhuanlan.zhihu.com/p/2049190077922800057
一、为什么具身智能重新关注世界模型?
"世界模型"在具身智能领域似乎又变成了一个高频词,它为什么又回到了热门呢,和传统强化学习又有哪些区别?
首先,从 Model-Based RL 的视角看,世界模型并不是一个全新的概念,它可以理解为 Model-Based RL 中的 learned dynamics model,即智能体先学习"世界会如何随动作变化",再用这个模型 rollout 未来、进而评估动作后果,反哺当前决策。
大语言模型里的"世界知识",也不是单纯的视频生成模型并不属于这个范畴,本文讨论的世界模型是 Model-Based RL 中可用于决策的未来预测模型。
这条线的可以概括为:
压缩 → 动力学建模 → 控制
因此,具身智能重新关注世界模型,最重要的原因如下:
用对未来的预测和想象,辅助当前时刻的决策。
其次,真实交互成本、稀疏奖励、策略评估和生成式模型的进展,也都在把这个方向重新从角落推到前台。
1.1 决策依赖未来,而不是只依赖当前观测
对于一个具身智能体来说,当前动作的好坏不能只看眼前这一帧,对未来的预测也起到关键作用。比如,机械臂现在向左移动一点,可能会让夹爪更接近目标,也可能会把物体推到不可达的位置;移动底盘现在绕开障碍,可能会让后续路径更短,但可能会错过更好的观察角度。
因此,真正困难的问题不是"当前图像里有什么",而是:
如果我现在执行这个动作,接下来几步会发生什么?这些未来变化会不会让我的任务更容易完成?
这就是 world model / Model-Based RL 重新站起来的原因。它试图在智能体内部建立一个可 rollout 的未来模型,让策略不只是从当前观测直接反射出动作,而是能通过 imagination 比较不同动作可能带来的后果。
我们可以把这个逻辑写成:
这也是 imagination 对决策的直接意义。它不是为了替代真实世界,而是为了让智能体在真正行动前,先在内部展开几种可能的未来。
1.2 其他原因:真实成本高,预测能力也更成熟了
机器人真机实验和游戏环境不同。
游戏里失败了可以立刻 reset,仿真里可以并行采样。但真机任务中,失败可能意味着:
- 需要人工重置;
- 机械臂撞到物体;
- 任务耗时很长;
- 数据采集速度极低;
- 设备损耗和安全风险增加。
因此,纯 Model-Free RL 很难直接在真机上 scale。
更麻烦的是,很多机器人任务只有完成时才有奖励:
- 抓起物体:成功 / 失败
- 打开抽屉:成功 / 失败
- 叠好毛巾:成功 / 失败
中间大量动作没有明确奖励,样本复杂度非常高,继而如果完全依靠真实环境中的 trial-and-error,很难学习到合理的策略,我们也很难知道哪一个动作好,好动作会被坏动作拖累,即信用分配会非常困难。
具身智能中策略评估的昂贵性也是我们需要考虑的因素,比如我们常常会得到很多候选策略,诸如:
- 不同训练步数的 checkpoint;
- 不同数据版本训练出的策略;
- 不同 VLA / diffusion policy / flow policy;
- 不同后训练方法得到的策略。
如果每个策略都上真机进行 A/B 测试,成本极高。
因此,如果能用少量真实交互学到一个世界模型,再在模型中进行大量 imagined rollout,就有机会降低真实采样成本,且让稀疏奖励下的信用分配和策略筛选变得更可行。
过去,像素级未来预测很难,生成结果模糊、长期不稳定。
但近年来视频生成模型、latent diffusion、transformer world model 等方向发展很快,使得"动作条件的视频预测"重新变得有吸引力。这些进步使得世界模型从 Dreamer 系列中的 latent dynamics,逐渐走向更高维、更开放的 video world model。
二、Model-Based RL 与 Model-Free RL 有何不同?
上一节说,世界模型的关键作用是先想象未来,再辅助当前决策,此即 Model-Based RL 的基本思想。所以认识世界模型,我们得先了解 Model-Based RL 和 Model-Free RL 相比有哪些优势。
在强化学习里,所有策略要解决的都是同一个问题:
当前状态或观测下,应该选择什么动作,才能让未来回报最大?
差别在于,它们如何利用"未来"。Model-Free 方法通常不显式学习世界如何变化,而是把未来回报压进非常直接的价值函数或策略里。Model-Based 方法则先学习一个环境模型,再用这个模型预测未来、生成轨迹或辅助规划。
2.1 Model-Free:直接学策略或价值
Model-Free RL 不显式学习环境的转移模型,而是直接学习:
- 动作价值函数:Q(s,a)
- 状态价值函数:V(s)
- 策略函数:\pi(a \mid s) 或 \pi(a \mid o)
典型方法包括 DQN、PPO、SAC、TD3 等。
它的核心特点是:不显式回答"世界下一步会怎么变",而是直接学习"我现在应该怎么做"。
在高维视觉任务里,这一点有时反而是优势。因为直接从图像学一个策略 \pi(a \mid o),往往比预测下一帧图像 \hat{P}(o' \mid o,a) 更容易先训到可用。
但代价也很明显:
- 样本效率通常较低;
- 稀疏奖励下信用分配困难;
- 对未来的建模是隐式压进 Q 或 \pi 里的;
- 很难显式问"如果我这样做,后面会发生什么"。
也就是说,Model-Free 方法工程成熟,但它对未来的利用方式比较"黑箱"。
2.2 Model-Based:先学世界如何变化,再决策
Model-Based RL 则显式学习一个环境模型,例如:
或者在确定性形式下写成:
在高维观测设定中,也可以是:
同时,模型通常还会预测奖励和终止信号:
其中 \hat{d}_t 表示 termination / done signal,也就是模型预测当前 transition 是否会导致 episode 终止。
学到模型之后,可以有如下几种用法:
第一种是规划,也就是 MPC。 在模型里搜索未来一段动作序列 a_{t:t+H},选择预测回报最高的动作。
第二种是 Dyna 式虚拟数据增广。 真实环境采少量数据,再用模型生成额外 transition,辅助训练策略或价值函数。
第三种是 Dreamer 系列代表的 imagined learning。 先用世界模型 rollout 出 latent 轨迹,然后在这些想象轨迹上训练 actor-critic。
Model-Based RL 的优势在于,它可以在模型里反复 rollout,从而提升样本效率;但它的天然风险也不可忽视,比如:
- 模型误差会在长 rollout 中复合;
- 策略可能 exploit 模型漏洞;
- 图像动力学难学;
- 规划或搜索的推理成本可能很高。
所以 Model-Based RL 的核心矛盾一直是:
模型越准,agent 越能在想象中学习;模型越偏,策略越容易学到"欺骗模型"的动作。
换句话说,模型的好坏极大程度影响策略,一个错误的模型不可能带来正确的决策。
2.3 一个简明对比
| 角度 | Model-Free RL | Model-Based RL |
|---|---|---|
| 是否学习转移模型 | 否 | 是 |
| 学习对象 | Q, V, \pi | \hat{P}, \hat{r}, \hat{d}(终止信号) |
| 对未来的利用 | 隐式压进价值/策略 | 显式 rollout |
| 样本效率 | 通常较低 | 潜力更高 |
| 图像观测 | 策略学习较自然 | 像素预测困难 |
| 主要风险 | 样本需求大 | 模型误差、模型被 exploit |
三、经典范式:压缩 → 动力学建模 → 控制
世界模型这条线最经典的范式可以概括为三步:
更具体地说:
| 环节 | 目标 | 解决什么问题 |
|---|---|---|
| 压缩 | o_t \to z_t | 把高维图像压到可建模的 latent space |
| 动力学建模 | z_t, a_t \to z_{t+1} | 让模型可以在内部 rollout 未来 |
| 控制 | z_t \to a_t,或学习 V, Q, \pi | 让 agent 不只是预测未来,而是能做决策 |
这三个环节缺一不可:
- 如果没有压缩,就要直接在像素空间预测未来,难度极高。
- 如果没有动力学建模,就无法在内部想象未来。
- 如果没有控制,模型只会预测,不会决策。
这里尤其要注意,controller 不是某一篇论文里的偶然模块名,而是世界模型范式中的第三环。前两环回答的是"世界如何被表示"和"世界会如何变化",而 controller 回答的是:
在模型已经给出内部状态和未来演化的前提下,动作到底由谁来选、按什么目标来选?
这一环可以有不同做法。在早期 World Models 里,controller 往往是一个相对独立、结构很小的控制器,直接根据当前 latent state 输出动作;而在 Dreamer 里,controller 不再是单独的一层小网络,而是变成了在 imagined rollout 上训练的 actor-critic。
因此,世界模型真正想做的不是单纯的视频预测,而是:
把高维观测压缩到 latent space,在 latent space 中学习动力学,再基于 imagined trajectory 训练或选择动作。
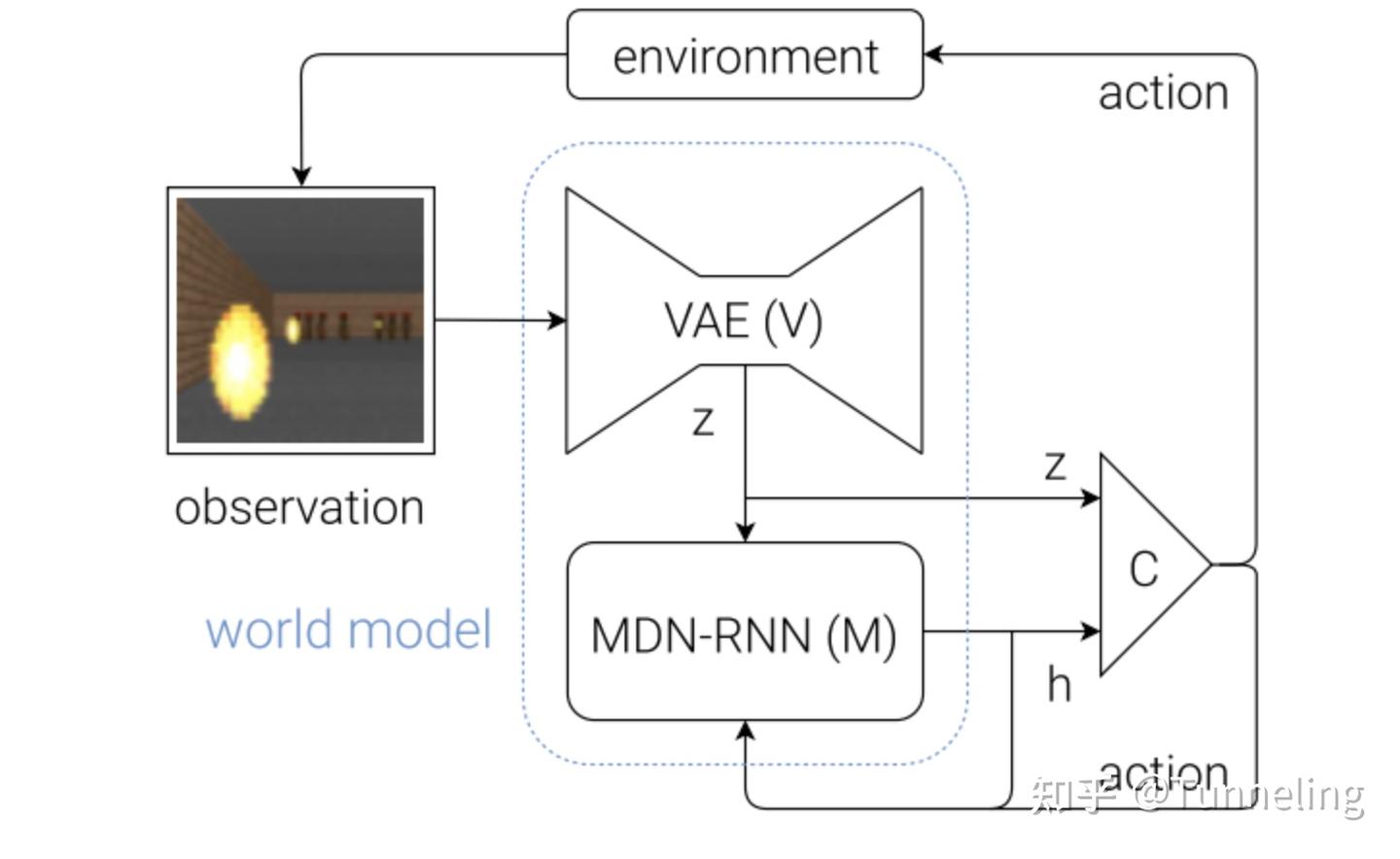
World Models 由 Ha 和 Schmidhuber 在 2018 年提出,可以看成这个范式最清晰的早期版本。它把系统拆成三个模块:
- V 模块:视觉压缩
- M 模块:潜空间动力学建模
- C 模块:控制器
其中,World Models 里的 controller 做法相对直接:先用 VAE 得到 latent code z_t,再用 MDN-RNN 得到 hidden state h_t,最后让 controller 根据 (z_t, h_t) 输出动作:
也就是说,这里的控制环节表示:给定当前内部状态,直接输出一个动作。
它说明对于高维视觉控制任务,agent 不一定要直接在像素空间中学习策略,可以先学习一个内部世界模型,再基于这个模型的 latent state 进行控制。
但 World Models 还没有建立后来 Dreamer 那种"在 imagined trajectory 上系统训练 actor-critic"的 RL 闭环。换句话说,它更像是把 world model 作为控制器的前端和内部模拟器;直到 Dreamer 的出现,world model 才真正变成了策略学习的训练场。
下面两篇代表作描述了上述范式的继续发展。
四、Dreamer:让策略在想象中学习
Dreamer 由 Hafner 等人在 2020 年提出。如果从世界模型的经典范式看,Dreamer 并不是推翻 World Models,而是在同一条链路上把三个环节都接进了一个更完整的 RL 闭环:
| 环节 | World Models | Dreamer |
|---|---|---|
| 压缩 | VAE | RSSM encoder |
| 动力学 | MDN-RNN | RSSM latent dynamics |
| 控制 | 独立 Controller | actor-critic on imagined rollout |
| RL 闭环 | 较弱 | 明确建立 |
更具体地说:
- 在 World Models 里,world model 的主要作用是先把高维观测压缩好、把 latent dynamics 建模好,然后把这些内部表示交给一个相对独立的 controller 去选动作。也就是说,模型是控制器的输入来源和内部模拟器,但策略本身并不是主要在 imagined trajectory 上端到端训练出来的。
- 在 Dreamer 里,world model 不再只是给 controller 提供状态表示,而是直接生成 imagined rollout,actor 和 critic 就在这些 imagined trajectory 上更新。也就是说,模型不只是"帮助控制",而是直接构成了策略学习发生的地方。
简单来讲:
- World Models:先学模型,再让控制器利用这个模型
- Dreamer:先学模型,再让策略直接在模型里学习
如果专门看 controller 这一环,两者的差别尤其关键:
- 在 World Models 里,controller 是一个独立模块,输入 (z_t, h_t),直接输出动作 a_t;
- 在 Dreamer 里,controller 不再被单独实现成一个"小控制器",而是改写成 actor-critic 机制:actor 在 imagined latent trajectory 上输出动作,critic 评估这些动作带来的未来回报,再反过来更新 actor。
这一步非常关键。因为它不只是"多用了一个模型",而是把 world model 接进了强化学习闭环,将强化学习加入具体控制:策略不再只是利用模型提供的状态表示,而是直接通过模型内部展开的未来轨迹来完成价值估计与策略更新。
4.1 RSSM:适合部分可观测任务的 latent dynamics
Dreamer 使用的是 RSSM,也就是 Recurrent State-Space Model。
直观地说,RSSM 同时维护两类状态:
- deterministic state:由 RNN 维护历史信息;
- stochastic state:表示当前 latent state 中的不确定性。
在部分可观测场景下,仅靠当前图像 o_t 往往不能还原完整环境状态。因此,Dreamer 不只编码当前观测,还通过 recurrent dynamics 利用历史信息。
RSSM 大致包含三类过程:
- 从观测中推断当前 latent state;
- 根据当前 latent state 和动作预测下一 latent state;
- 从 latent state 重建观测、奖励和终止。
也就是说,它既是 representation model,也是 dynamics model。
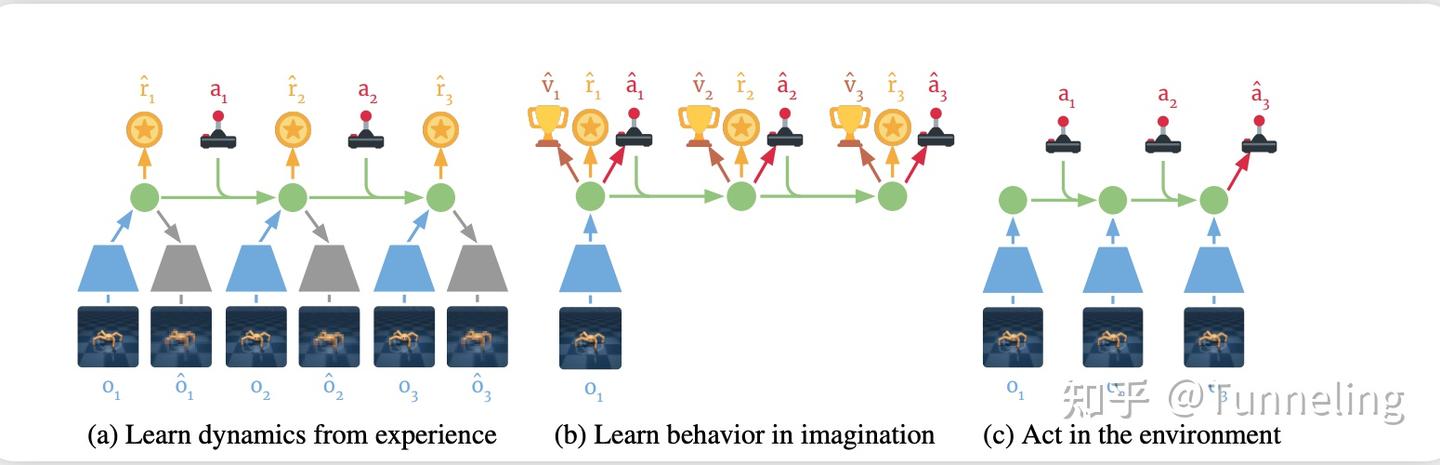
4.2 Imagined rollout:未来来自模型,而不是真环境
学好 RSSM 后,Dreamer 不再只依赖真实环境轨迹训练策略。
它会从真实数据中的某个 latent state 出发,在模型内部执行当前 actor 给出的动作,然后递推未来 latent state:
同时预测奖励:
这样就得到一段 imagined trajectory:
这条轨迹不是从真实环境采样来的,而是从世界模型中想象出来的。
4.3 Actor-Critic:在 imagined trajectory 上更新策略和价值
Dreamer 在 imagined trajectory 上训练 actor 和 critic。
critic 学习预测 imagined trajectory 上的 return;actor 则学习选择能够带来更高 predicted return 的动作。
这里常用 \lambda-return 或类似的多步回报估计方式。需要注意的是:
- V_R 表示纯 imagined reward 的累计回报
- V_N^k 表示带 bootstrap 的 k 步回报
- V_\lambda 则是对不同步长回报的加权组合
它的作用是把 imagined rollout 中预测到的奖励和 critic 的 bootstrap value 结合起来,作为 critic 和 actor 的学习信号。
imagined trajectory 是世界模型生成的未来序列;\lambda-return 是控制侧用于估计回报的工具。两者不是一回事。
这一点很容易混淆。
Dreamer 的关键不是"用了 \lambda-return",而是:
它让 actor-critic 的主要学习信号来自 latent imagination。
这正是 Dreamer 相对 World Models 的本质升级。
五、DreamerV3:范式不变,稳定性 scale
DreamerV3 由 Hafner 等人在 2023 年提出。
它要解决的问题不是"要不要换一个世界模型范式",而是一个更工程、更关键的问题:
能不能用同一套 world model + actor-critic recipe,在很多不同任务上都稳定工作,而不是每换一个环境就大调参?
DreamerV3 的回答是:可以,但前提是把训练中最容易不稳定的地方都标准化。
因此,DreamerV3 的贡献不在于推翻 Dreamer,而在于让 Dreamer 的范式更稳定、更通用、更能 scale。
5.1 数值尺度稳定:symlog / symexp 与 two-hot
不同任务的 reward 和 value 尺度可能差异极大。有的任务 reward 很小,有的任务回报很大;如果直接用普通 MSE 预测 value,梯度尺度很容易失控。
DreamerV3 使用 symlog / symexp 处理大范围数值:
它的作用是压缩大数值,同时保留正负号。
此外,DreamerV3 对 reward / value 使用 two-hot 表示,而不是简单做标量回归。这可以让价值学习在大尺度回报下更加稳定。
这部分主要解决的是:reward 和 value 的数值尺度问题。
5.2 潜动力学稳定:KL balancing、free bits、uniform mix
世界模型训练中,latent state 很容易出现两类问题:
- posterior collapse:模型忽略 stochastic latent,只靠 deterministic hidden state 或 decoder 也能重建。
- KL spike:KL 项突然变大,导致训练不稳定。
DreamerV3 延续并强化了 Dreamer 系列中的一些稳定性技巧,例如:
- KL balancing
- free bits
- uniform mix
这些技巧的共同目标是:
让 latent dynamics 既真的携带信息,又不要被 KL 正则压死或训炸。
也就是说,这部分主要服务于第二环:动力学建模。它保证世界模型内部的 latent transition 是可训练、可 rollout、可被 actor-critic 使用的。
5.3 控制稳定:return normalization 与 target critic
即使世界模型训练稳定,控制侧也可能不稳定。因为 actor-critic 对 reward scale、value target、bootstrap 误差都很敏感。
DreamerV3 使用了 return normalization、EMA target critic 等技巧,使 critic target 更平滑,也让 actor 更新不容易被极端回报尺度带偏。
这部分解决的是第三环:控制。它让 imagined rollout 上的 actor-critic 更新更加稳定。
5.4 DreamerV3 的范式地位
DreamerV3 的重要性在于,它证明了 latent world model 这条路线并不是只能在少数任务上工作。
它在 Atari、ProcGen、DMLab、Minecraft 等大量任务上使用较统一的超参数取得了强结果,说明:
RSSM + imagined rollout + actor-critic 这套范式,在通用 RL / 视觉控制任务上已经具有相当强的可扩展性。
所以 DreamerV3 不是范式革命,而是范式成熟。
可以把三篇工作的关系总结为:
| 工作 | 主要贡献 | 一句话总结 |
|---|---|---|
| World Models | 拆分 VAE、MDN-RNN、Controller | 把世界模型三环节拆清楚 |
| Dreamer | RSSM + imagined actor-critic | 让策略在想象轨迹上学习 |
| DreamerV3 | 稳定训练 recipe | 不改范式,但让范式跨任务 scale |
可以把演进线写成:
六、总结:latent 世界模型范式已经成立,但边界仍然明显
本文从 Model-Based RL 的角度梳理了世界模型主线:先压缩观测,再建模动力学,最后用想象轨迹驱动控制。World Models 拆清了三环,Dreamer 接通了闭环,DreamerV3 则把这套范式稳定地扩展到了更多任务。
压缩 → 动力学建模 → 控制
三篇代表作分别推动了这个范式的不同环节:
| 工作 | 主要贡献 | 一句话总结 |
|---|---|---|
| World Models | 拆分 VAE、MDN-RNN、Controller | 把世界模型三环节拆清楚 |
| Dreamer | RSSM + imagined actor-critic | 让策略在想象轨迹上学习 |
| DreamerV3 | 稳定训练 recipe | 不改范式,但让范式跨任务 scale |
至此,在通用 RL / 视觉控制任务上,latent 世界模型这套范式已经被反复验证。真正的问题开始转向:
这套 latent world model 能否继续扩展到更复杂、更开放、更高维的具身场景?
在机器人中,状态更难观测,接触动力学更复杂,长程任务更稀疏,策略评估更昂贵。因此,世界模型重新回到舞台中央。
但它面临的问题也更实际和尖锐:
- latent 是否足够表达物理交互?
- video world model 能否真正服务控制,而不是只生成好看的视频?
- 世界模型如何避免被策略 exploit?
- 想象 rollout 的误差如何随时间控制?
- 世界模型如何与 VLA、diffusion policy、flow policy 结合?
这些问题,将是下篇的主线。
参考文献
[1] David Ha, Jürgen Schmidhuber. World Models. arXiv:1803.10122, 2018. https://arxiv.org/abs/1803.10122
[2] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, Mohammad Norouzi. Dream to Control: Learning Behaviors by Latent Imagination. arXiv:1912.01603, 2020. https://arxiv.org/abs/1912.01603
[3] Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, Timothy Lillicrap. Mastering Diverse Domains through World Models. arXiv:2301.04104, 2023. https://arxiv.org/abs/2301.04104