蒸馏 + RL 已经是 reasoning 模型后训练的标配:DeepSeek-R1、s1、OpenThinker 走的是“off-policy 蒸馏再 RL”,Qwen3、MiMo、GLM-5 则把 on-policy distillation(OPD)直接编进了后训练管线。
但有一个问题很少有人追问:为什么 off-policy 蒸馏长成了 SFT 的样子,而 OPD 长成了 RL 的样子?这两种形态是必然的吗?
来自东方理工、香港理工大学、上海交通大学、香港科技大学(广州)的研究团队给出了一个出人意料的答案:这两个范式各自隐式绑定了两个本可以独立选择的设计维度。
把它们解耦之后,SFT、DAgger、离线 RL、OPD 这四个看似分属不同领域的训练范式,恰好填满一张 2×2 表格的四个格子。更重要的是,这个统一视角直接带来了可落地的方法:Avg@k 提升 3.6 分、Pass@k 最高提升 5.8 分、响应长度砍掉 3 倍。
📄 论文链接:https://arxiv.org/abs/2605.16826
背景:两大范式,和它们各自的“出身”
先快速对齐一下两大范式在做什么。
Off-policy 蒸馏:教师生成轨迹,学生在这些轨迹上做监督学习。实践中通常实现为 SFT——把教师采样出的 token 当 hard label 做交叉熵。R1、s1、OpenThinker 的蒸馏阶段都是这个配方。它的问题是exposure bias:训练时学生永远条件在教师写的完美前缀上,推理时却要条件在自己生成的前缀上;一旦自己写错一个 token,后面就进入了训练时从未见过的状态,误差不断累积。
On-policy 蒸馏(OPD):让学生自己生成 rollout,教师对学生访问到的每个状态给出 token 级反馈。监督发生在学生真实会到达的状态上,exposure bias 被天然缓解,而且 token 级的稠密反馈比 outcome RL 的稀疏奖励信息量大得多。
一个是 SFT 式的监督学习,一个被普遍理解为 RL 式的策略优化。两者看起来是完全不同的方法论。但论文指出:它们的差别其实可以被精确分解为两个独立的选择。
核心发现:一个被序列级推导“焊死”的耦合
蒸馏的目标是让学生 q_\theta 的响应分布匹配教师 p_T。序列级上有两个选择:
Forward KL 在教师的响应上取期望,reverse KL 在学生的响应上取期望。利用自回归分解 p(y|x) = \prod_t p(y_t \mid s_t),其中 s_t = (x, y_{<t}) 是第 t 步的 prefix(也可以理解为生成过程中的“状态”),两个序列级目标分别展开为:
其中 d_T^t 和 d_S^t 分别是教师轨迹和学生轨迹诱导的 prefix 分布。
看出问题了吗:forward KL 自动绑定了教师 prefix,reverse KL 自动绑定了学生 prefix。“在哪监督”(prefix 来源)和“怎么比较”(KL 方向)这两件事,被序列级推导焊死在了一起。现有实践完全继承了这个绑定:off-policy 蒸馏 = 教师轨迹 + token 级 forward KL,OPD = 学生轨迹 + token 级 reverse KL。
论文的核心论点是:这个耦合只是序列级推导的副产品。在 token 级上,这两个维度完全正交——prefix 可以从 d_T^t 或 d_S^t 采,每个 prefix 上的 token 级 KL 可以取 forward 或 reverse。做 Cartesian product,得到四个合法的目标,其中两个 off-diagonal 组合(教师 prefix + reverse KL、学生 prefix + forward KL)此前从未被系统研究过。
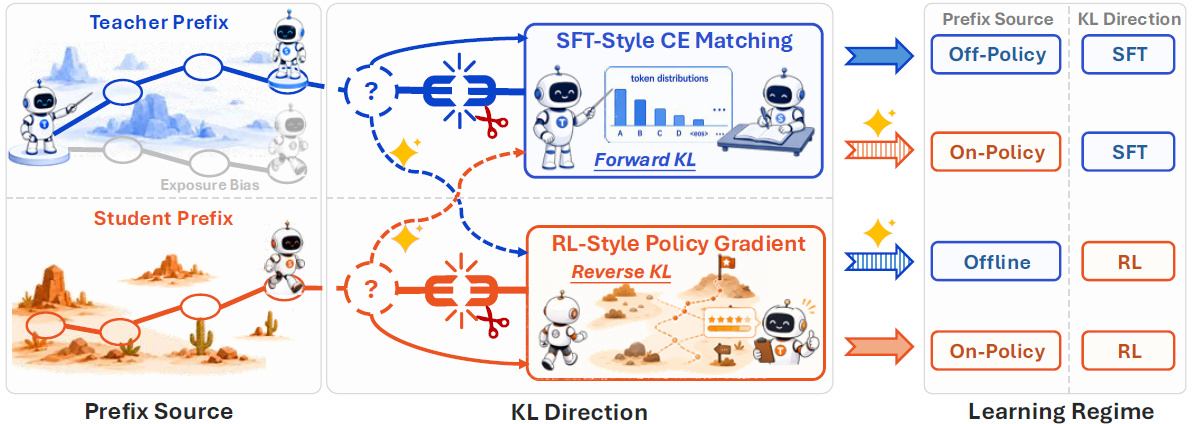
图 1:解耦蒸馏框架总览。左:prefix 来源(教师轨迹 vs 学生轨迹,后者天然规避 exposure bias);中:KL 方向决定监督形态(SFT 式交叉熵 vs RL 式 policy gradient);右:两个开关的四种组合,对应四种学习范式,其中带 ✨ 的两条 off-diagonal 路径此前从未被系统研究。
两条梯度恒等式:forward KL 是 SFT,reverse KL 是 RL
解耦之后,凭什么说这四个格子对应四个经典范式?论文在梯度层面给出了精确的答案。固定 prefix s_t,把教师 p_T 视为与 \theta 无关的常数。
(i) Forward KL 的梯度是 SFT 式交叉熵。 由于 p_T 不依赖 \theta:
这正是以教师分布为 soft target 的交叉熵梯度。在教师采样出的 token 上做单样本 Monte Carlo 近似,就退化成大家熟悉的 hard-label SFT。
(ii) Reverse KL 的梯度是 REINFORCE。 这里期望是对 q_\theta 自己取的,求导要小心。展开:
对乘积求导得到两项。一项是 \sum_y \nabla_\theta q_\theta(y|s_t) 乘以 1(来自 \log q_\theta 自身的导数),由于概率归一化 \sum_y q_\theta = 1,这一项恒为零。剩下的一项用 score function 技巧 \nabla_\theta q_\theta = q_\theta \nabla_\theta \log q_\theta 改写:
把符号翻过来(最小化 KL = 最大化负 KL),这就是标准的 REINFORCE 上升方向,每个 token 的稠密奖励恰好是师生 log-ratio:
教师概率比学生高,奖励为正,推高该 token;反之为负,压低它。Forward KL 给出监督学习的梯度,reverse KL 给出强化学习的梯度——KL 方向这一个开关,直接决定了你在做 SFT 还是 RL。
四个格子,逐个对号入座
现在两个轴都清楚了:prefix 来源决定 policy regime(教师 prefix 对学生而言是 off-policy 的,学生 prefix 是 on-policy 的),KL 方向决定梯度形态(SFT 式 vs RL 式)。四个格子逐个看:
| Forward KL(SFT 式梯度) | Reverse KL(RL 式梯度) | |
|---|---|---|
| 教师 prefix(off-policy) | Off-policy SFT | 离线 RL 式蒸馏 |
| 学生 prefix(on-policy) | DAgger 式 on-policy SFT | OPD |
教师 prefix + forward KL = off-policy SFT。
在教师轨迹上做交叉熵匹配,R1 式蒸馏的精确刻画,没有悬念。
学生 prefix + forward KL = DAgger。
DAgger(Dataset Aggregation)是模仿学习的经典算法,要解决的正是 behavior cloning 的 covariate shift 问题:learner 在 expert 数据上训练,部署时自己执行,小错误把它带进 expert 数据没覆盖的状态,策略随即失效。
DAgger 的解法是反过来:让 learner 自己跑,expert 在 learner 实际访问到的状态上给出标注,再用监督学习更新。
对照一下这个格子:prefix 由学生采样(learner 的状态分布),每个 prefix 上用教师的完整分布做交叉熵监督(expert 的标注,只不过是 soft 分布而非单个动作)。结构严丝合缝,这就是 LLM 蒸馏里的 DAgger,此前没人系统跑过。
教师 prefix + reverse KL = 离线 RL 式蒸馏。
离线 RL 的设定是:数据由行为策略(behavior policy)预先采好,学习的目标策略不与环境交互,只在固定数据集上做 RL 式更新。
对照这个格子:轨迹由教师(行为策略)生成,学生(目标策略)在这些自己从未生成过的 prefix 上,接受 log-ratio 奖励驱动的 policy gradient 更新。数据分布与被优化策略分离,这正是离线 RL 的核心结构。同样,此前没人系统研究过。
学生 prefix + reverse KL = OPD。
学生自己 rollout,自己的状态分布上做 policy gradient,奖励是稠密的师生 log-ratio——OPD 的本质就是 dense-reward on-policy RL。
你以为是四个领域的四种方法,其实是同两个开关的四种拨法。
实验:把四个格子全部拉出来遛一遍
理论统一只是上半场。下半场,团队把四个目标放进同一个严格受控的实验台:Qwen3-4B/8B 做教师、Qwen3-0.6B 做学生(同家族避免 tokenizer 错位),DeepScaleR 上训练,AIME24、AMC23、MATH500、GSM8K 上评测。
两种训练长度(128 / 4096 token)、两种评估模式(standalone 蒸馏、蒸馏后接 GRPO 继续训练),训练全程追踪准确率、预测熵、响应长度三条曲线。
注意这里的巧思:熵和长度不是凑数的指标,它们分别是“探索能力”和“生成行为”的实时仪表盘,后面所有的故事都藏在这三条曲线的交互里。
权衡一:KL 方向,精度与熵的对赌
先看最直接的问题:reverse KL 和 forward KL 谁强?
Standalone 蒸馏下,reverse KL 几乎全面胜出。 匹配设置下 Avg@k 平均高出 +2.45 分,短序列设置下拉大到 +3.68 分。最典型的一组:MATH500、学生 prefix、128-token 训练,reverse KL 把 Avg@k 从 34.31% 直接拉到 42.65%(4B 教师),从 34.43% 拉到 43.23%(8B 教师)——8 个多点的差距,任何人看了都会直接选 reverse KL。
但训练曲线讲了另一个故事。4096-token 设置下,reverse KL 一边涨精度,一边把预测熵推向崩塌,响应长度则一路顶到评测时的生成上限。 这是 reverse KL mode-seeking 几何的必然结果:它把概率质量不断集中到教师高概率的少数延续上,分布越削越尖。
尖到什么程度?反映到指标上,Pass@k 开始背叛 Avg@k:128-token 设置下 reverse KL 的 Pass@k 只是勉强打平 forward KL,4096-token 设置下平均反而更低。也就是说,reverse KL 训出来的学生,单次答对率高了,但 k 次尝试的覆盖面反而缩了——多样性被精度换走了。
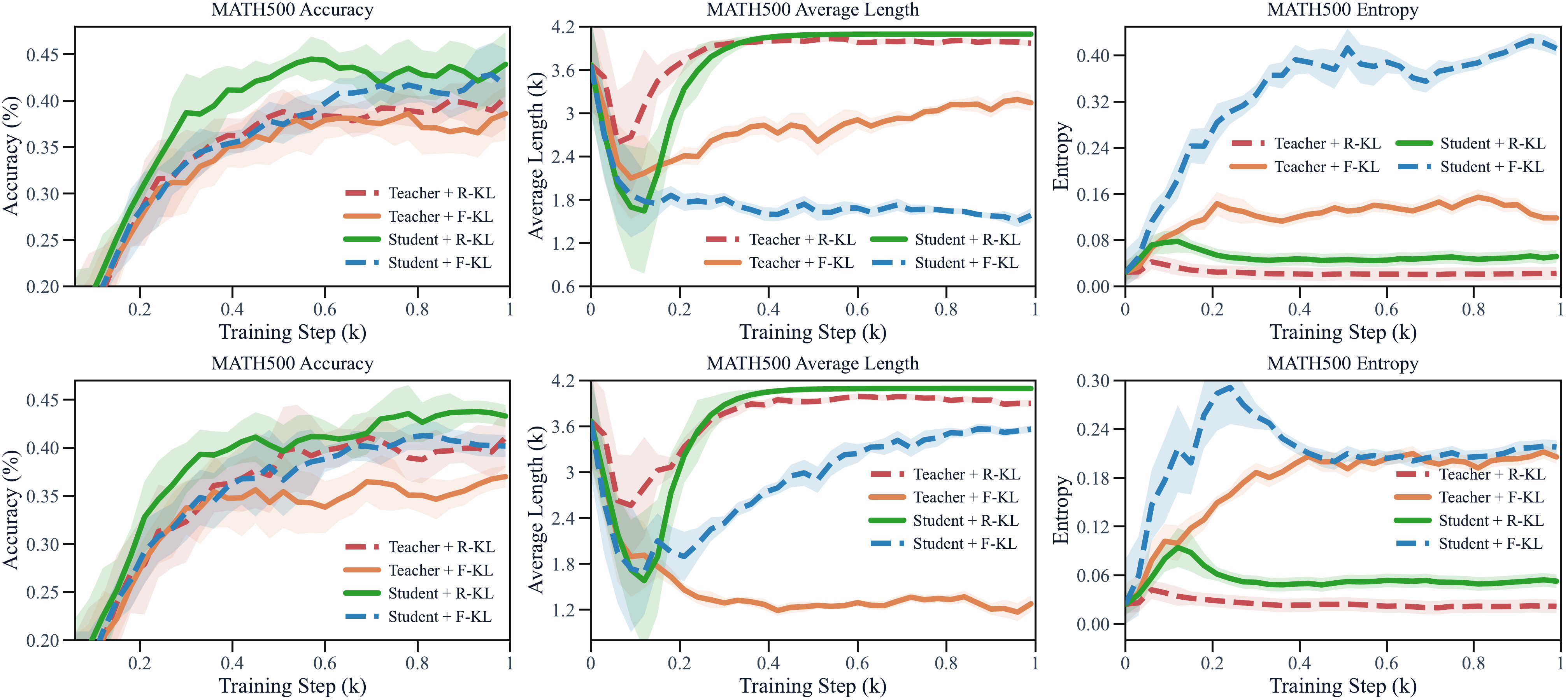
图 2:4096-token 蒸馏阶段的训练动态(MATH500;上排 Qwen3-4B 教师,下排 Qwen3-8B 教师;左:精度,中:响应长度,右:预测熵)。两条 reverse KL 曲线(红、绿)精度领先,但长度迅速顶到 4k 上限、熵被压到贴地;两条 forward KL 曲线(橙、蓝)保住了熵。
真正的代价在 RL 阶段才暴露。把四个 checkpoint 分别交给 GRPO 继续训练:forward KL 的 checkpoint 熵保得好,RL 一路稳定爬升;reverse KL 的 checkpoint 起点虽高,但熵已接近枯竭,RL 想探索却无路可走——精度非但不涨,反而一路回吐,被 forward KL 的 checkpoint 反超。于是出现了这篇论文最反直觉的结论之一:
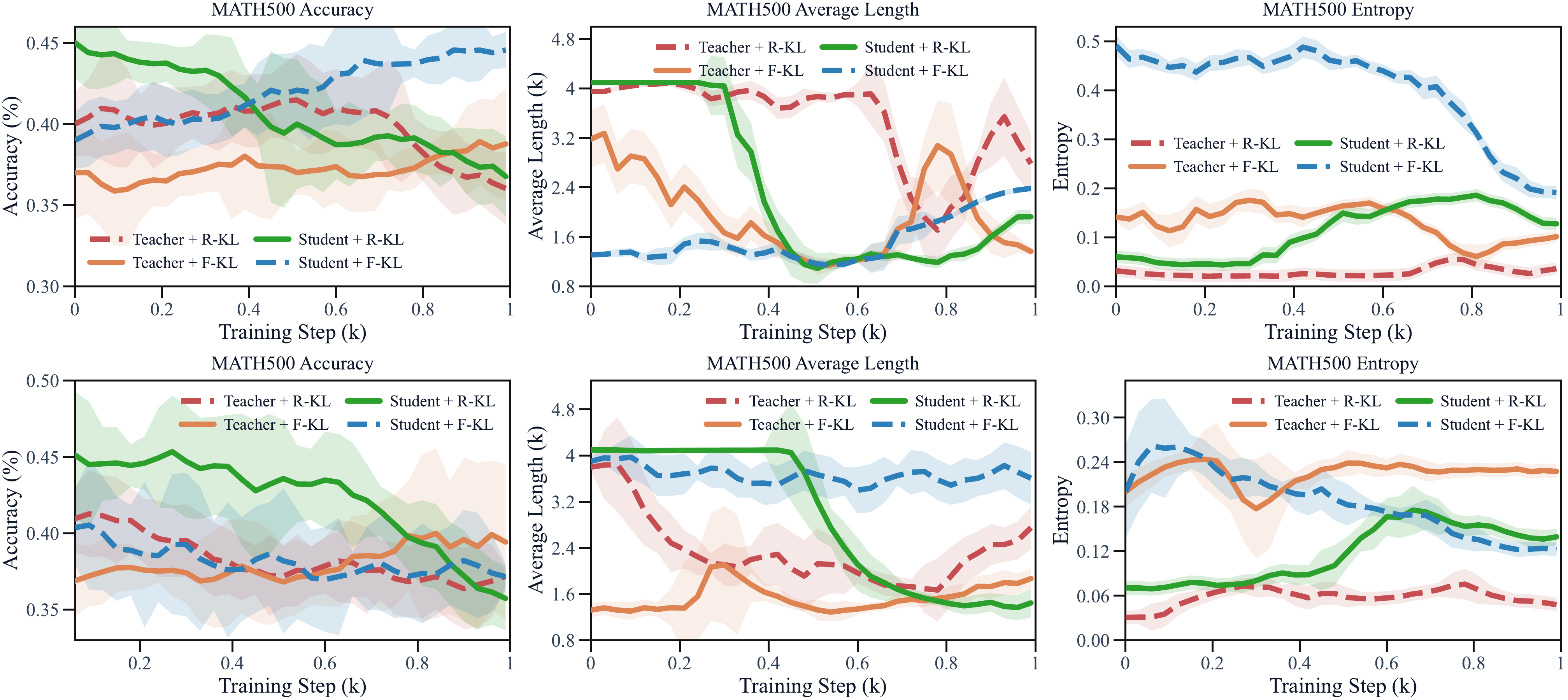
图 3:四个蒸馏 checkpoint 接 GRPO 后的 RL 动态(上排 4B 教师 warmup,下排 8B)。最戏剧化的对比:OPD warmup(绿)起点最高,RL 中精度却一路下滑;DAgger 式 warmup(蓝)起点更低,凭着保住的熵稳定爬升,最终反超。standalone 的赢家,成了 RL 的输家。
Standalone 最强的蒸馏目标,不一定是“蒸馏 + RL”管线的最佳起点。你在蒸馏阶段赢下的每一分,可能都在透支 RL 阶段的探索空间。
这一条对所有在跑“蒸馏 → RL”管线的团队都是直接警告:只盯着蒸馏阶段的 Avg@k 选 checkpoint,很可能选到一个 RL 起跑就熄火的模型。
权衡二:Prefix 来源,质量与算力的对赌
同等训练步数下,学生 prefix 系统性更好——监督发生在学生真正会访问的状态上,这正是 DAgger 思想在 LLM 蒸馏里的胜利,也再次确认了 OPD 路线的核心价值。
但把对比口径换成同等 FLOPs,天平就翻了:教师 prefix 的轨迹可以离线生成、反复复用,教师 logits 可以一次计算、永久缓存;学生 prefix 则要求每一步都在线 rollout、在线打分,教师必须常驻显存。预算紧张、或者手里已经有现成教师轨迹的团队,教师 prefix 反而是更高性价比的选择。 质量和算力,取决于你缺哪个。
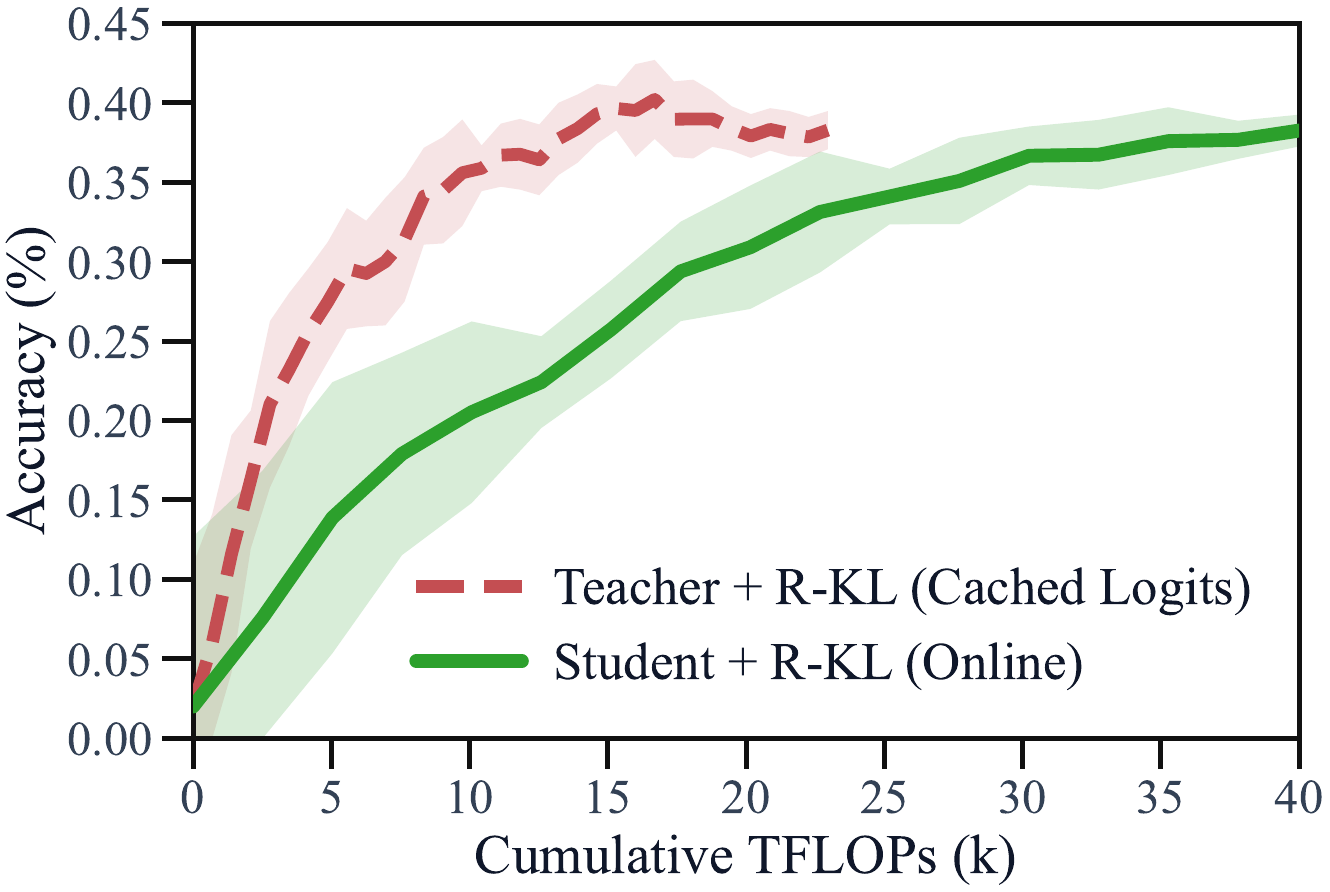
图 4:同等累计 FLOPs 下的精度对比。教师 prefix + 缓存 logits(蓝)因为省掉了在线 rollout 和在线打分,在算力受限的前期显著领先于在线 OPD(橙)。
权衡三:训练长度,精度与稳定性的对赌
长序列蒸馏(4096)推理精度更高——长链条推理本来就需要长上下文的监督。但在 reverse KL 下,长序列正是熵崩塌和长度膨胀的放大器:序列越长,mode-seeking 的压缩效应累积越狠。短序列(128)训练稳定得多,三条曲线都温和,但精度天花板有限。直接二选一,两头都不讨好。
两个方法:把三个权衡逐个拆掉
诊断清楚了,药方也就清晰了。论文给出两个直接可用的方法,分别瞄准 KL 方向和训练长度两个权衡。
KL mixing:给 reverse KL 上一道熵保险
既然 forward KL 保熵、reverse KL 提分,自然的想法是 token 级加权混合两者。但实验给出的结论是不对称的,而且这个不对称正是方法的精髓:
长序列蒸馏必须配足量的 forward KL 权重。 高 forward 配比的混合,在几乎不损失 reverse KL 精度优势的前提下,同时压住了熵崩塌和长度膨胀——三条训练曲线全部回到健康区间。反过来,高 reverse 配比的混合依然不稳,熵照崩、长度照炸。
换句话说,forward KL 在混合中不是配角,而是那道不可省略的保险;很多团队习惯性地“以 reverse 为主、加一点 forward 调味”,方向恰好反了。
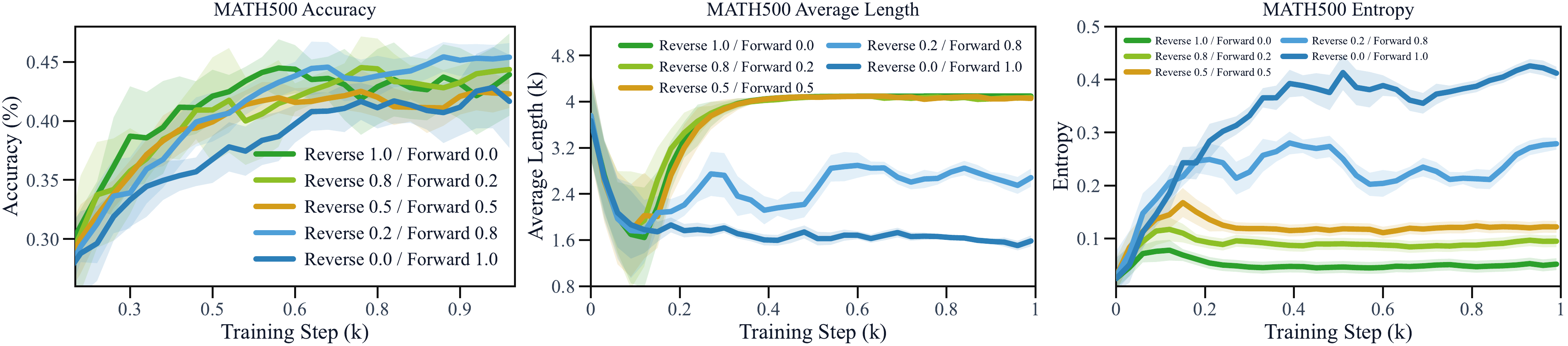
图 5:五种 KL 混合配比下的训练动态(左:精度,中:长度,右:熵)。精度上五种配比最终几乎打平,但长度和熵泾渭分明:reverse 权重 ≥ 0.5 的配比(绿、橙)长度全部顶死 4k 上限、熵贴地;只有 forward 权重 ≥ 0.8 的配比(蓝)同时压住了长度和熵崩塌。精度不掉、稳定性全保,这就是“足量 forward”的含义。
Entropy-gated 长度课程:让熵来决定什么时候加长度
针对训练长度的权衡,论文的方案是把“长度该多长”从超参变成由熵实时驱动的决策:从短窗口(128)起步,持续监控预测熵,只在熵仍高于稳定阈值时才放宽长度上限;一旦熵逼近危险区,长度就地冻结。逻辑非常直白——熵是探索能力的油表,油表正常才允许踩油门。
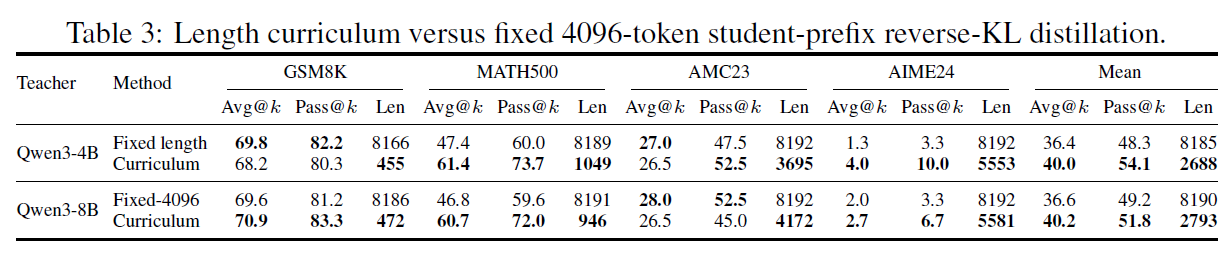
效果是三赢:相比固定 4096-token 训练,Avg@k 提升 3.6 分,Pass@k 最高提升 5.8 分——注意 Pass@k 也涨了,说明多样性被真正保住而非牺牲——平均响应长度同时缩短约 3 倍。更高的精度、更好的覆盖、三分之一的生成开销,一个课程调度同时拿下。
给实践者的速查表
把全文的发现压缩成一张决策表:
| 你的场景 | 推荐配置 |
|---|---|
| 只做蒸馏,不接 RL,追求 Avg@k | 学生 prefix + reverse KL(即 OPD) |
| 蒸馏后要接 RL | 保熵优先:forward KL,或高 forward 权重的 KL mixing |
| 算力紧张 / 已有现成教师轨迹 | 教师 prefix,复用轨迹和缓存 logits |
| 要做长序列蒸馏 | KL mixing(足量 forward)+ entropy-gated 长度课程 |
另外一个工程细节值得单独点赞:精确的全词表 KL 需要在每个 token 位置物化词表大小的中间张量,显存压力巨大,这也是很多实现退而求采样近似的原因。
团队实现了一个 fused kernel,把投影、softmax、KL 累加融合成流式的单遍词表扫描,单 token 中间显存从 O(|V|) 降到 O(1),让所有实验跑的都是精确 KL 而非近似——对比实验的可信度由此而来。
一句话 takeaway
蒸馏的设计空间其实只有两个旋钮:在哪监督(prefix 来源)、怎么比较(KL 方向)。拨法不同,就得到 SFT、DAgger、离线 RL 或 OPD;理解了旋钮背后的三大权衡,才能为“蒸馏 + RL”管线选对起点,而不是沿用范式的默认绑定。