近年来,视觉语言模型(Vision-Language Models, VLMs)已经成为多模态理解与推理任务中的主流范式。当前大多数 VLM 采用 “视觉编码器(通常为 Vision Transformer, ViT)+轻量投影层(projector)+大语言模型(Large Language Model, LLM)”的架构,将图像编码为视觉特征后,直接映射并输入LLM。
然而,这一简洁架构背后存在一个容易被低估的问题:经过投影层后的视觉特征,并不天然处于LLM熟悉的文本表示空间中。
针对这一关键挑战,团队提出了一种全新的视觉语言模型架构 Deep Pre-Alignment(DPA)。
DPA不再让大语言模型边理解边对齐,而是引入一个小型视觉语言模型(perceiver VLM),在视觉特征进入目标LLM之前,先将视觉特征对齐到更接近目标LLM文本表示空间的状态。
由此,目标LLM能够在更加贴近文本的表示空间上开展理解与推理。

论文地址:https://arxiv.org/abs/2605.15300
GitHub 仓库:https://github.com/THUMAI-Lab/Deep-Pre-Alignment
为什么需要 DPA?多模态模型中的“隐性对齐成本”
传统 VLM 架构隐含地假设:经过预训练的 ViT 视觉特征已经足够接近语言模型的文本空间,因此只需一个线性层或 MLP 投影器即可完成跨模态连接。
但论文指出,视觉特征与目标 LLM 的文本空间之间仍存在显著的模态差距。这意味着:
- 目标 LLM 的浅层结构需要花费大量容量进行视觉到文本的粗粒度对齐;
- 原本应用于深层理解和复杂推理的模型深度被提前消耗;
- 多模态训练可能对原有语言能力造成更强的破坏,诱发文本能力遗忘。
DPA 的核心思想正是:将模态对齐从目标 LLM 内部前移到视觉特征进入 LLM 之前完成。这样,大语言模型不必再承担过重的浅层对齐压力,而能够更充分地发挥其语言预训练中获得的理解与推理能力。
DPA 核心特点
从“ViT 直接连接 LLM”到“先深度预对齐,再进入 LLM”
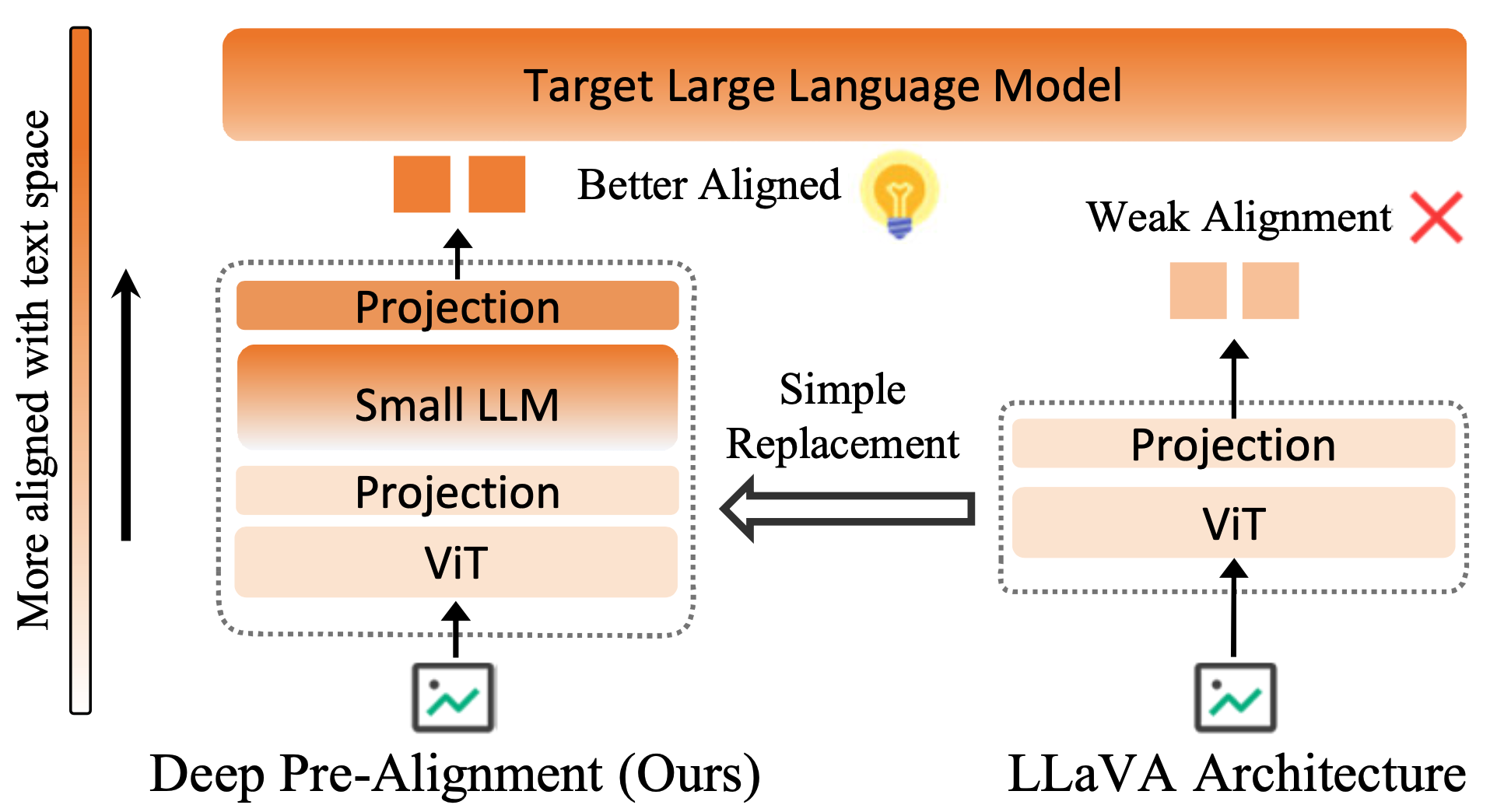
传统 VLM 通常将 ViT 提取到的视觉特征,通过一个轻量投影层直接送入目标 LLM。这样做虽然结构简单,但也意味着:视觉特征是否真正适合 LLM 处理,很大程度上要依赖目标 LLM 的前几层自行适配。
[
v \xrightarrow{E} H_v \xrightarrow{\phi} H'_v \rightarrow M_t,
]
DPA 的核心变化在于,它不再让目标 LLM 直接接收浅层视觉特征,而是在前端引入一个小型 perceiver VLM。这个 perceiver VLM 不只包含 ViT 和投影层,还包含一定深度的语言模型模块,能够在视觉特征进入目标 LLM 之前,先将其推进到更接近文本空间的表示状态。
[
v \xrightarrow{E} H_v
\xrightarrow{\phi_p} H'_v
\xrightarrow{M^{\text{LLM}}p,\ \phi} H{\text{aligned}}
\rightarrow M_t.
]
因此,输入目标 LLM 的不再是简单投影后的视觉 token,而是已经经过深度预对齐的多模态表示。目标 LLM 可以将更多容量用于理解、推理和生成,而不是在浅层承担过多模态转换工作。
无需重写训练流程,可无缝接入现有 VLM 框架
DPA 并不依赖复杂的辅助损失、特殊优化目标或额外的推理流程。论文中,研究团队仍然沿用当前 VLM 中广泛采用的两阶段训练范式:
1.Stage-1:使用图文对数据训练投影层,完成 perceiver VLM 与目标 LLM 的维度对齐;
2.Stage-2:使用高质量视觉指令数据,对整个系统进行端到端训练微调。
也就是说,DPA 的引入更接近一种模块化替换,只需将原有的 ViT 编码器替换为 perceiver VLM,训练目标与推理策略均可保持不变。这使其能够无缝嵌入现有的主流多模态大模型开发流程中。
多模态性能显著提升
研究团队在 11 个基准上系统评估了 DPA,包括:
- 8 个多模态任务:覆盖通用视觉理解、多模态推理与细粒度感知;
- 3 个文本任务:衡量多模态训练后语言能力的保持情况。
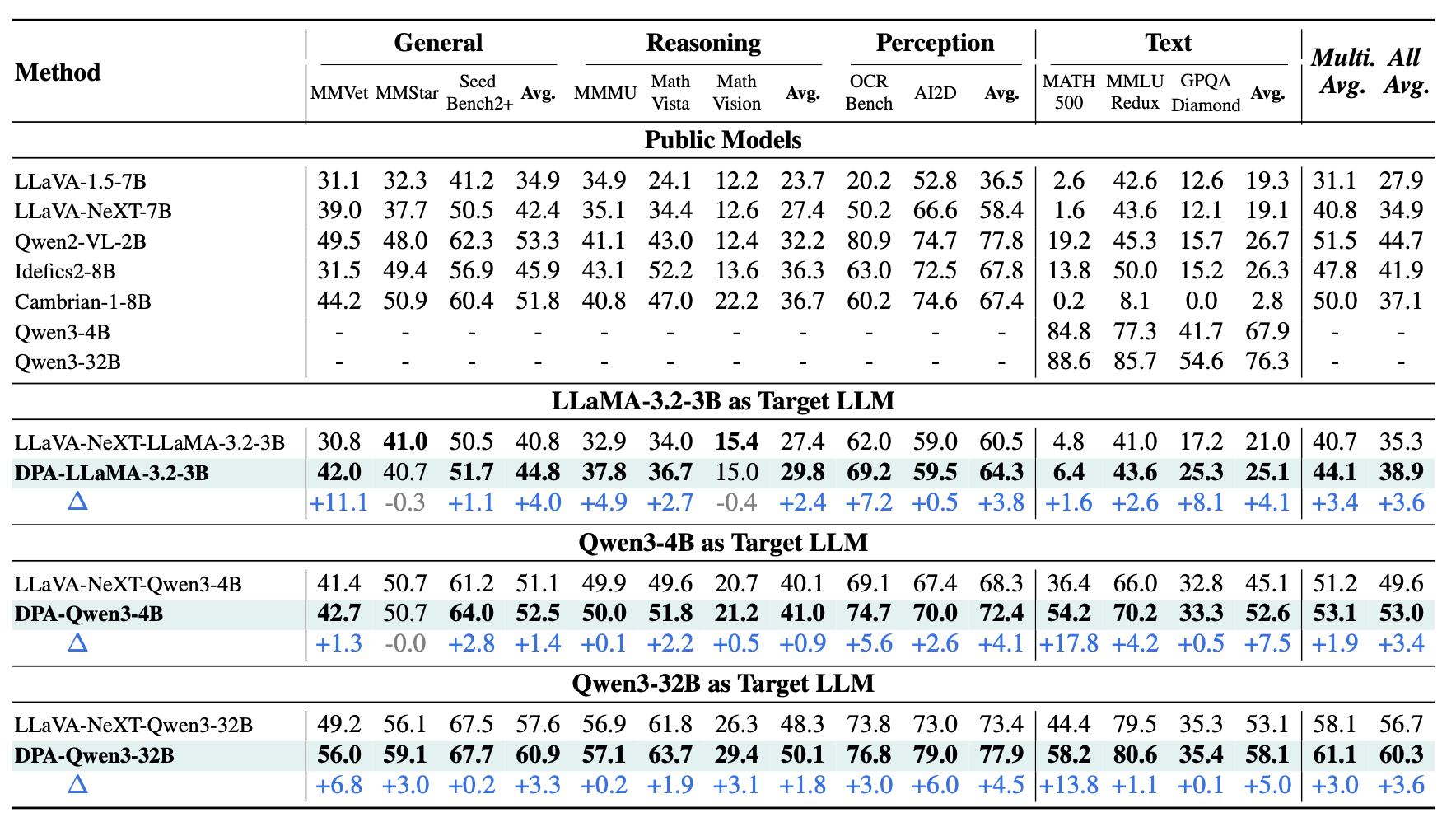
实验结果表明,DPA 在不同规模和不同模型家族上均带来了稳定收益:
- 在 Qwen3-4B 设定下,DPA 在 8 个多模态基准上的平均性能提升 +1.9 分;
- 在 Qwen3-32B 设定下,提升进一步扩大到 +3.0 分;
- 在 LLaMA-3.2-3B 作为 LLM 时,DPA 也取得了 +3.6 的整体平均提升,说明其效果并不依赖于单一模型家族。
显著缓解文本能力遗忘,兼顾多模态性能提升与语言能力保持
多模态训练常常会损害原本强大的文本能力。论文指出,在 Qwen3-4B 设置下,标准 LLaVA-NeXT 风格模型在 MATH-500 上的成绩会从纯文本模型的 84.8 大幅下降到 36.4。
引入 DPA 后,该分数恢复到 54.2。进一步统计显示:
- 在 4B 模型上,DPA 将文本能力遗忘减少了 32.9%;
- 在 32B 模型上,减少了 21.6%。
这说明,DPA 并非只是提升视觉任务分数,而是在模型结构层面缓解了“为了学会看图而牺牲语言能力”的矛盾。
几乎不增加推理负担,32B 模型吞吐下降仅约 2%
尽管 DPA 在视觉端引入了一个小型 perceiver VLM,但相对于目标大语言模型的整体规模,其额外开销非常有限。论文报告,在 32B 模型设置下,DPA 相比基线仅带来约 2% 的吞吐下降,却获得了更强的多模态表现和更好的语言能力保持。
这意味着,DPA 并不是以显著牺牲效率为代价换取性能提升,而是提供了一种高性价比的架构升级方案。
DPA 为什么有效?来自消融实验的证据
提升并不只是因为 perceiver VLM 更强,而是架构本身更合理
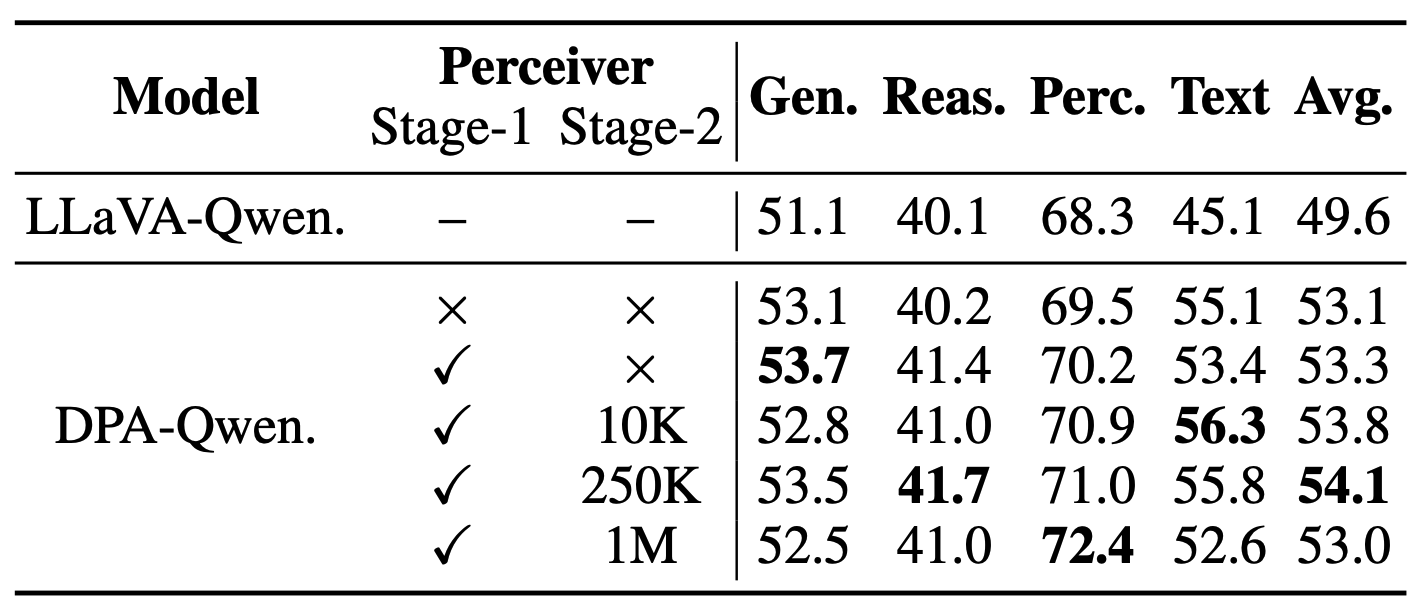
一个自然的问题是:DPA 的提升,是否仅仅来自于换了一个更强的视觉模块?
研究团队通过控制变量实验发现,答案是否定的。即便使用尚未经过完整多模态训练的 perceiver VLM,DPA 依然能够比传统 ViT 架构取得约 +3.5 的整体平均提升。此外,不同 perceiver VLM 的独立性能差异较大,但最终 DPA 模型的收益仍然保持在相对稳定的区间内。
这说明,DPA 的关键价值并不只是使用了一个更强的小模型,而是其提出的深度语言空间预对齐架构本身。
真正关键的是语言对齐模块
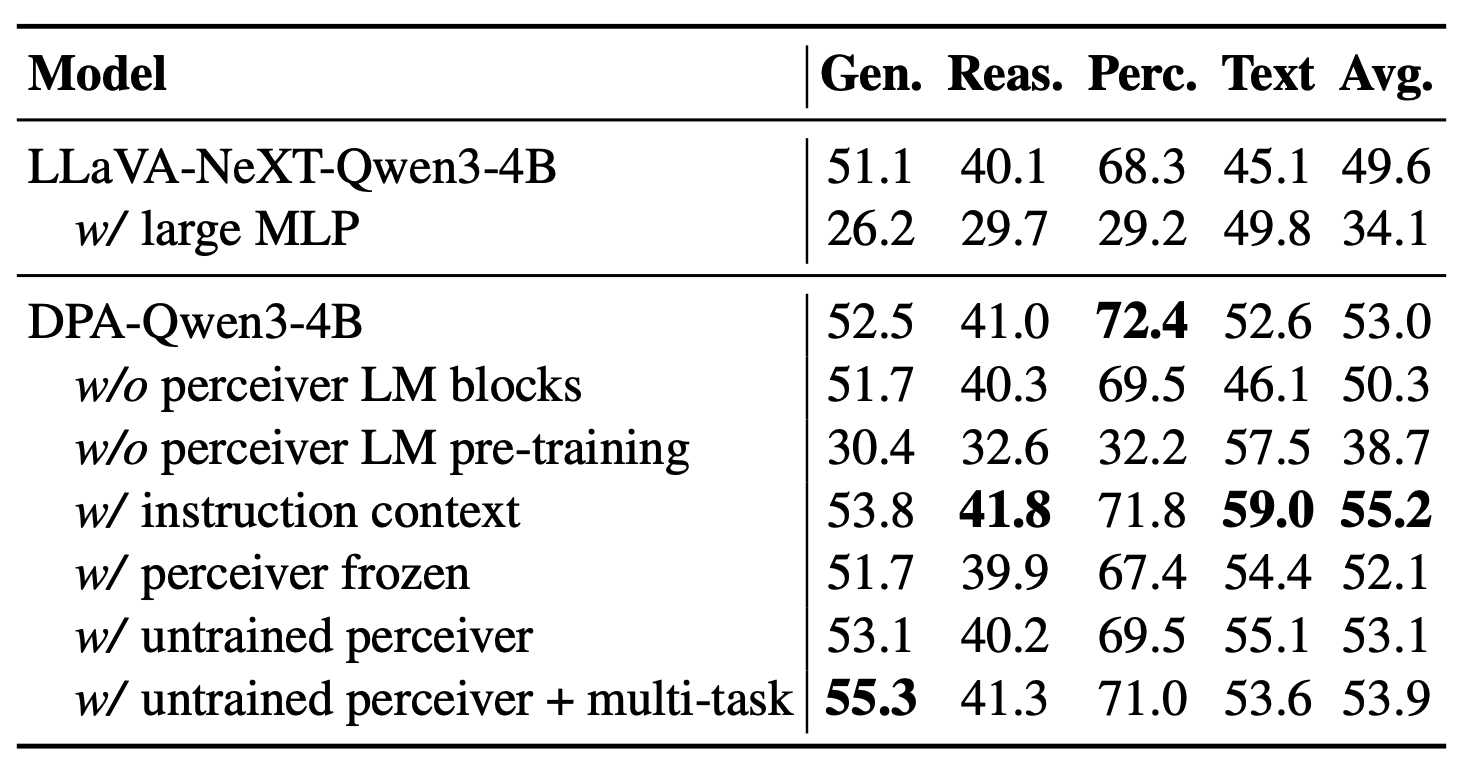
论文进一步表明,DPA 的有效性高度依赖 perceiver VLM 中的语言模型:
- 若去除 perceiver VLM 的语言模型,整体平均分仅从基线 49.6 提升到 50.3;完整 DPA 则可达到 53.0;
- 若去掉 perceiver VLM 语言模型的预训练,其表现会显著下降到 38.7。
这表明,DPA 并非简单地加深视觉编码器,而是利用具备语言先验的模型,将视觉特征主动对齐至适合目标 LLM 使用的文本表示空间。
总结
DPA 提出了一种新的 VLM 架构思路:多模态模型不应把视觉到语言的对齐负担全部交给目标 LLM,而应在视觉特征进入 LLM 之前,通过具备语言能力的 perceiver VLM 完成更深层次的预对齐。
在几乎不改变主流训练与推理流程的前提下,DPA 同时带来了更强的多模态理解能力、更好的语言能力保持,以及极低的额外推理开销。
这表明,构建高性能 VLM 的关键,不仅在于获得更强的视觉表示,还在于让视觉特征以更接近文本空间的形式进入目标 LLM,从而真正释放大语言模型的理解与推理能力。