作者:陈坤 史鹏
https://zhuanlan.zhihu.com/p/2017276876004017170
本文介绍我们近期在 RLVR 训练动态方面的一项研究。我们从梯度保留裁剪(Gradient-Preserving Clipping)的理论视角出发,提出了一套灵活的熵调节机制,并基于熵增熵减的调节机制,实验了包括先熵增再熵减,熵减-熵增-熵减和动态衰减的三种熵控制策略,通过实验证明,该策略有效缓解了 GRPO 训练中的策略熵崩溃问题。
论文:Flexible Entropy Control in RLVR with Gradient-Preserving Perspective
论文链接:http://arxiv.org/abs/2602.09782
一、背景:当大模型学会”过早自信”
近年来,以DeepSeek-R1为代表的大语言模型在通过 RLVR 在数学推理、代码生成等任务上取得了惊人进展。作为RLVR的代表算法,GRPO 因其无需单独训练Critic网络、实现简单高效而被广泛采用。然而,一个普遍困扰研究者的现象是:随着训练进行,模型的策略熵会迅速衰减至接近零,也就是熵崩溃。
什么是策略熵崩溃?
策略熵衡量的是模型输出的”不确定性”或”多样性”。高熵意味着模型会探索多种可能的解题路径,低熵则意味着模型变得”过于自信”,倾向于重复少数几种固定模式。
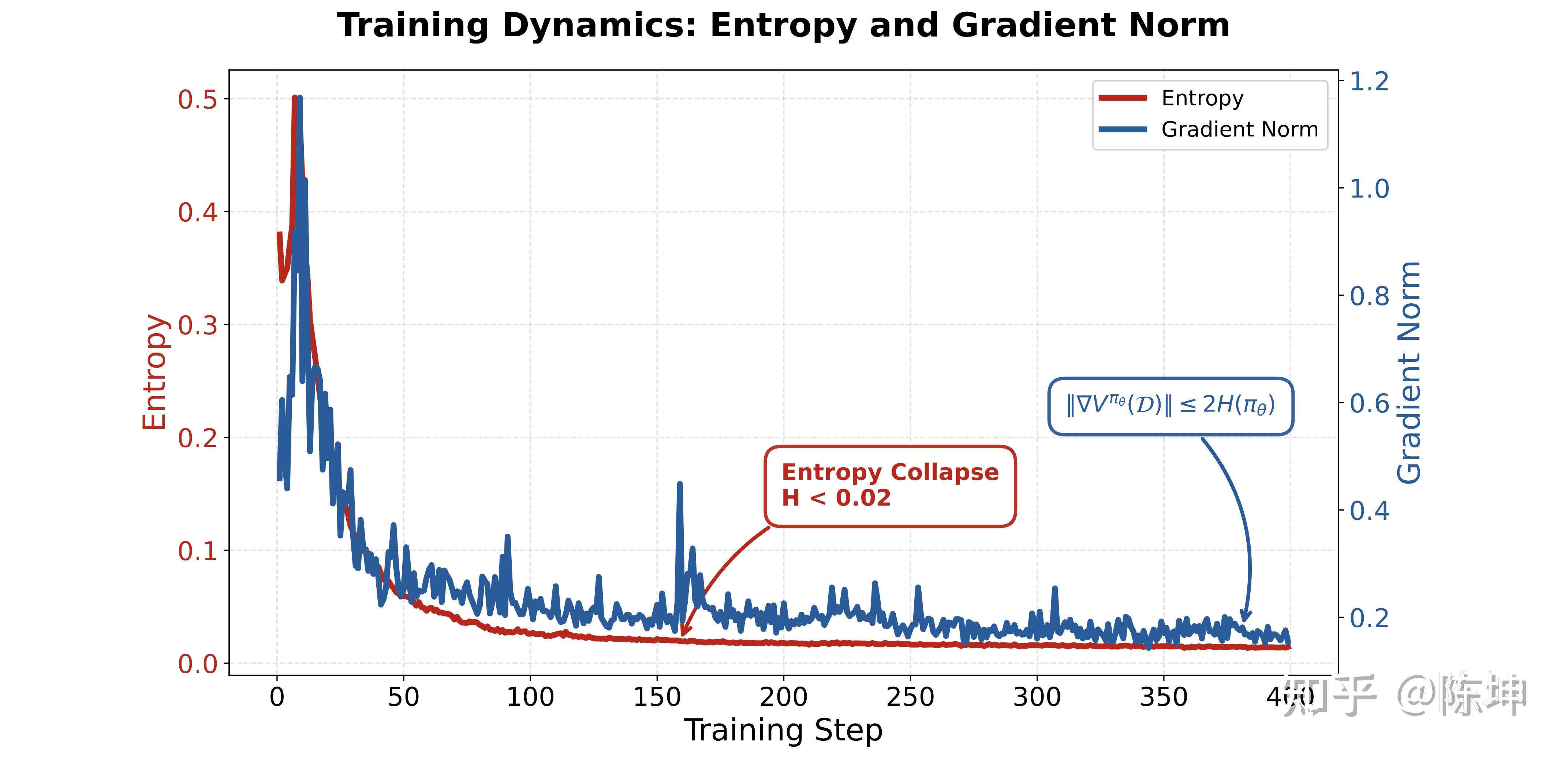
然后GRPO训练往往会出现熵的迅速衰减,也就是熵崩溃,熵崩溃带来两个严重后果:
1.过早收敛:模型在训练早期就锁定少数”看似有效”的解题策略,丧失探索能力,陷入局部最优
2.梯度消失:Shen等人的理论分析表明,策略梯度范数受熵的上界约束,熵崩溃直接导致后续训练梯度微弱,模型难以继续改进
二、问题的根源:梯度裁剪
要理解熵崩溃,我们需要回到RLVR的核心机制——PPO-Clip的梯度裁剪。
PPO-Clip 回顾
PPO(Proximal Policy Optimization)通过限制新旧策略之间的偏离程度来稳定训练:
其中r_t(\theta)是重要性采样比率。PPO-Clip 的目标函数为:
通过将r_t(\theta)裁剪在[1-\epsilon, 1+\epsilon]区间内,PPO确保策略更新不会过于激进。
裁剪阈值与熵的微妙关系
现有研究(如 DAPO)发现,过于严格的裁剪阈值会抑制低概率token的探索,导致熵持续下降。DAPO 提出的Clip-Higher策略通过提高上界阈值 \epsilon_{high}来缓解这一问题。
然而,究竟梯度裁剪与熵控制之间存在什么关系,能否通过梯度裁剪来准确灵活控制熵增熵减,以及我们究竟在训练中应该如何有效地控制熵仍然是需要解决的问题。我们的核心贡献就在回答上面这三个问题。
三、理论分析:四个熵敏感区域
我们的贡献之一是从理论上精确刻画了重要性采样比率空间中,哪些区域会促进熵增长,哪些区域会导致熵下降。我们发现,关于这一讨论,我们和 通义团队近期的工作 On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models 不谋而合。在他们的知乎介绍中 RL训练中的 Entropy Dynamics 也有对这一理论和其他工作的介绍。
核心推导
对于单步更新的surrogate objective:
我们计算目标函数梯度与全局熵梯度的内积:
式子中的两项分别为Token-specific项和Global baseline项,而这一内积的符号主要由相对于基线的词特定token项决定。聚焦于特定 token的成分,我们得到以下关系:
由此得到关键洞察:熵的变化方向取决于 token 的”惊奇度”(Surprisal)与当前熵的相对关系。
四个熵敏感区域
基于理论分析,我们识别出四个关键区域:
- 区域 E1:-\ln \pi(a|s) < H(低惊奇度/高概率)andA>0熵变化: 下降
- 区域 E2: -\ln \pi(a|s)>H(高惊奇度/低概率)andA>0熵变化: 上升
- 区域 E3: -\ln \pi(a|s)<H(低惊奇度/高概率)andA<0熵变化: 上升
- 区域 E4: -\ln \pi(a|s)>H(高惊奇度/低概率)andA<0熵变化: 下降
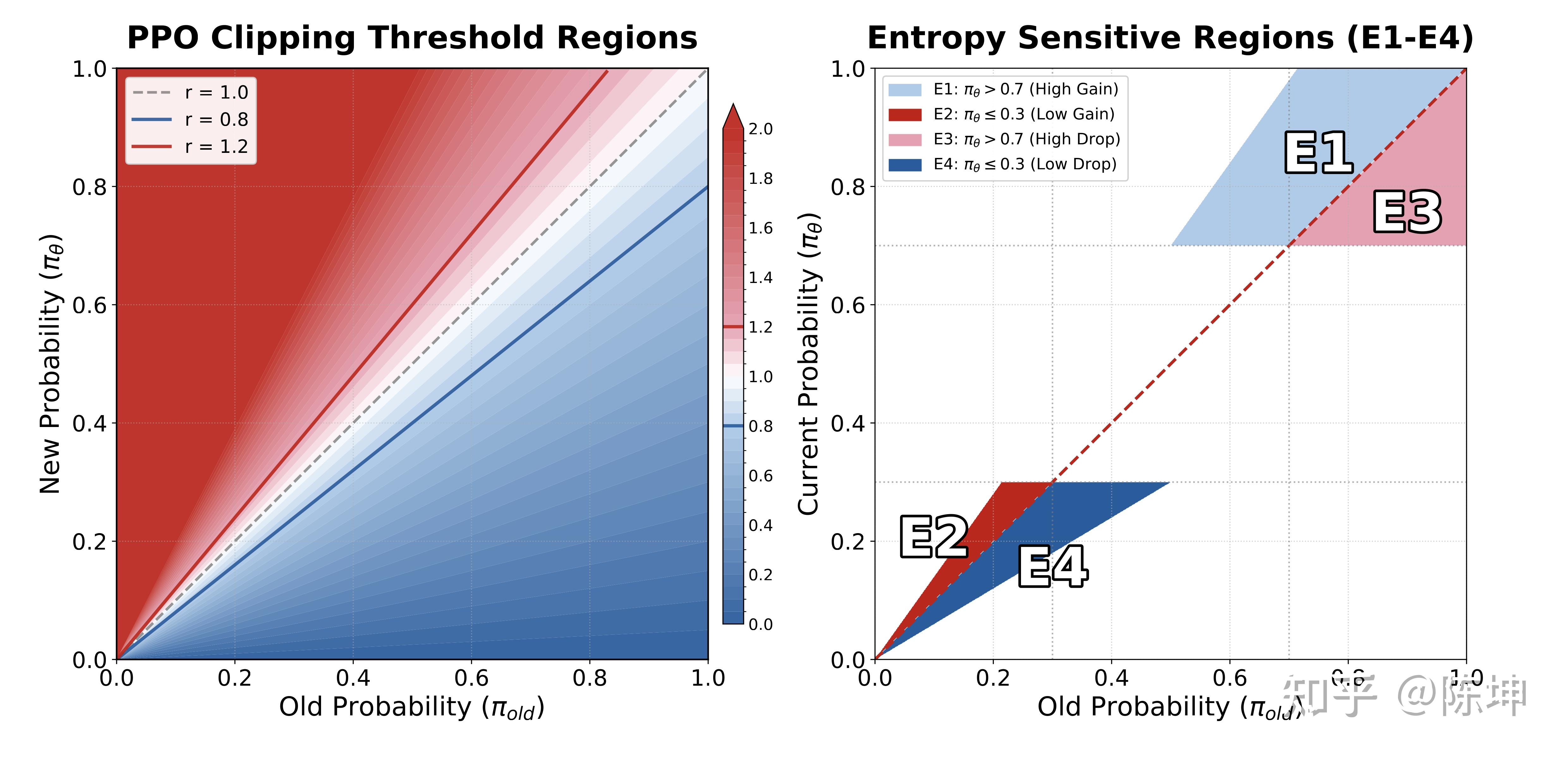
直观理解:
- E1/E4:强化”意料之中”的token→ 分布更尖锐→熵下降
- E2/E3:强化”出乎意料”的token→ 分布更平坦→熵上升
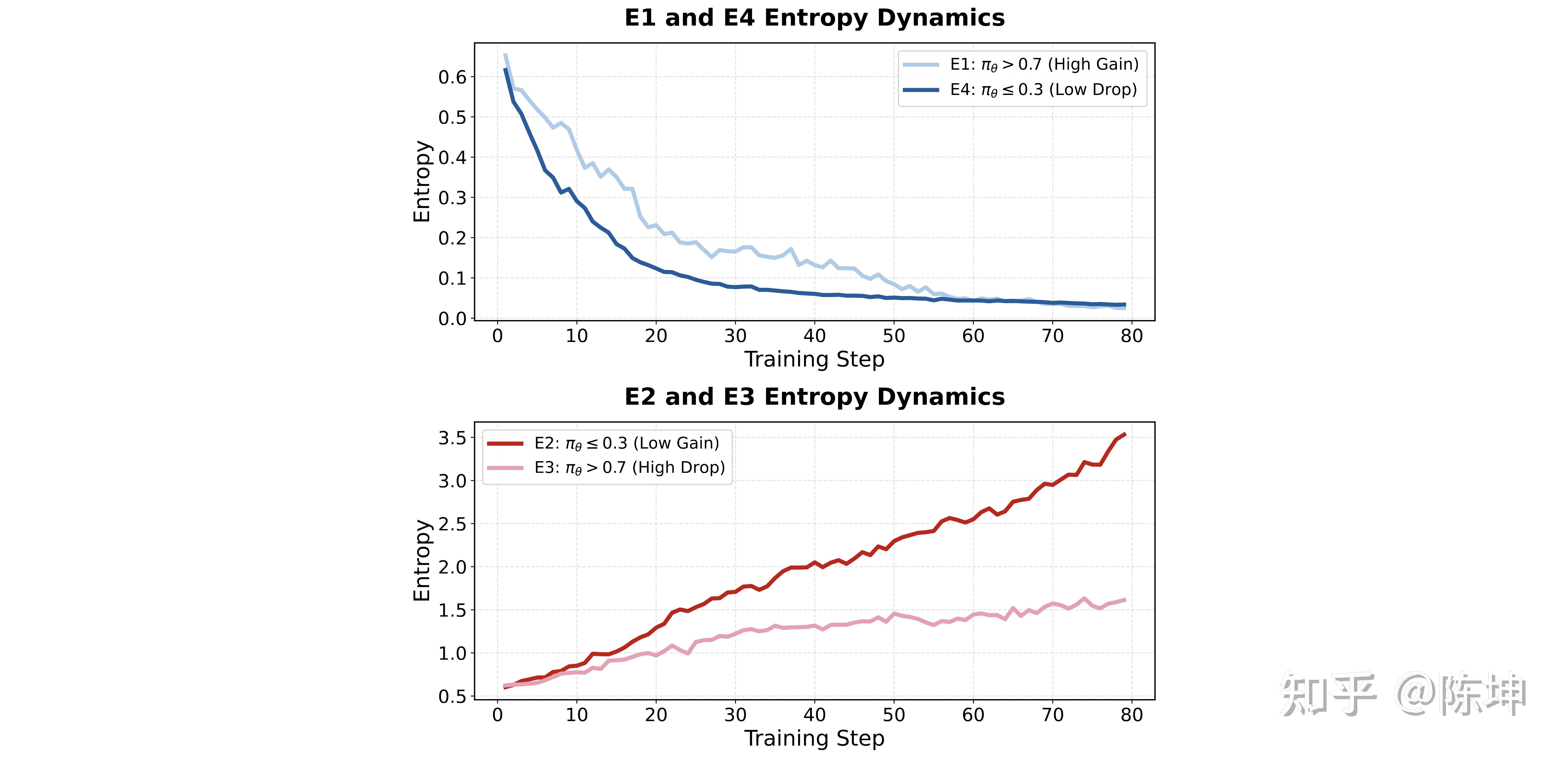
我们通过受控实验验证了这一理论:仅对特定区域应用梯度裁剪,观察到与理论预测完全一致的熵动态变化。
四、熵的调节机制:动态裁剪阈值
基于上述理论洞察,我们设计了动态裁剪阈值机制,通过非线性调制特定比率区域来精确控制熵。
动态上界裁剪阈值(控制熵增)
当A > 0时,上界阈值主要影响E1(高概率)和E2(低概率)区域。
固定的高阈值(例如DAPO的clip-higher)虽然能促进E2区域的探索,但同时也会引入E1区域的过优化,导致熵下降。我们为了避免这种情况出现,将上界阈值\epsilon设计为当前概率的函数:
其中f与\pi_\theta呈负相关:
- 低概率 token:放宽阈值,促进探索(增强 E2)
- 高概率 token:收紧阈值,防止过优化(抑制 E1)
采用线性负相关形式
得到动态约束:
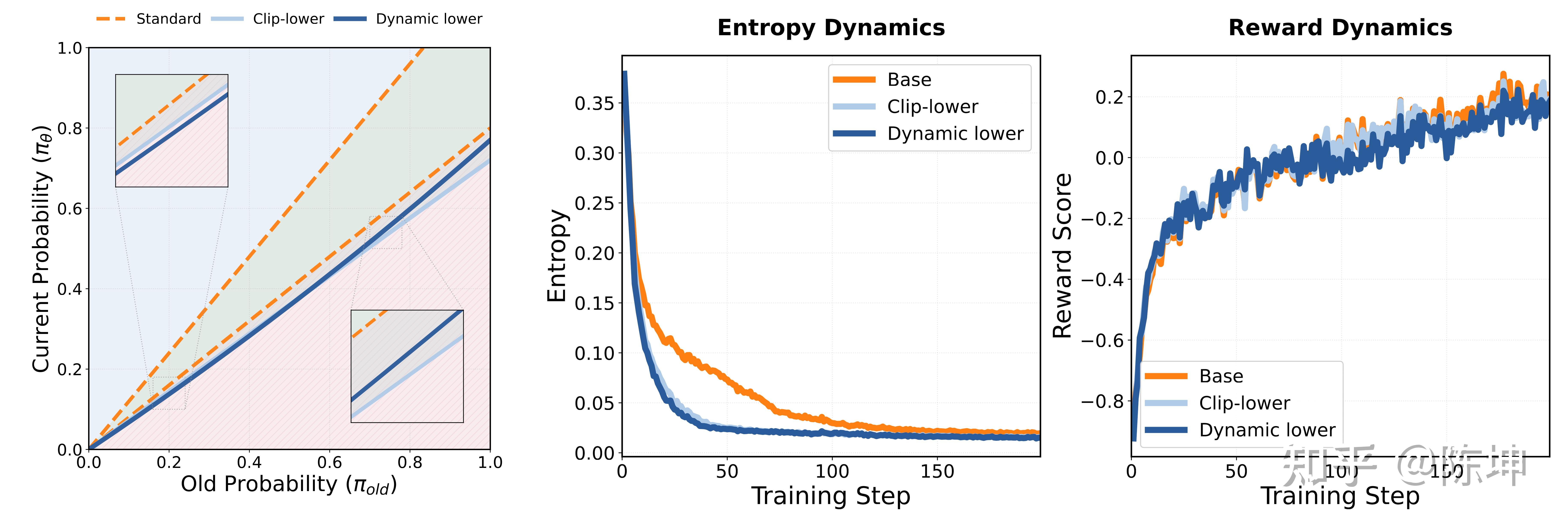
动态下界裁剪阈值(控制熵减)
当A<0时,情况更为微妙。负优势信号存在一个不稳定性问题:由于Softmax的归一化特性,惩罚某个token会间接提升其他所有token的概率。对于 高概率负样本,固定的高\epsilon_{low}允许过度更新,导致分布剧烈偏移 而对于 低概率负样本:进一步压低其概率有助于排除次优区域,且对整体分布影响有限。
因此,我们采用相反的动态策略:
- 高概率 token:收紧阈值,保持稳定性(抑制 E3 的过度熵增)
- 低概率 token:放宽阈值,强化排除(增强 E4 的熵减效果)
五、熵的控制策略:探索与收敛的平衡
有了动态裁剪机制,我们可以设计灵活的熵控制策略。核心思想是:训练早期保持高熵以促进探索,后期逐渐降低熵以实现收敛。
我们将PPO裁剪目标函数推广为时间依赖形式:
其中\mathcal{E}^+_k和\mathcal{E}^-_k是随训练步数k动态变化的阈值函数。
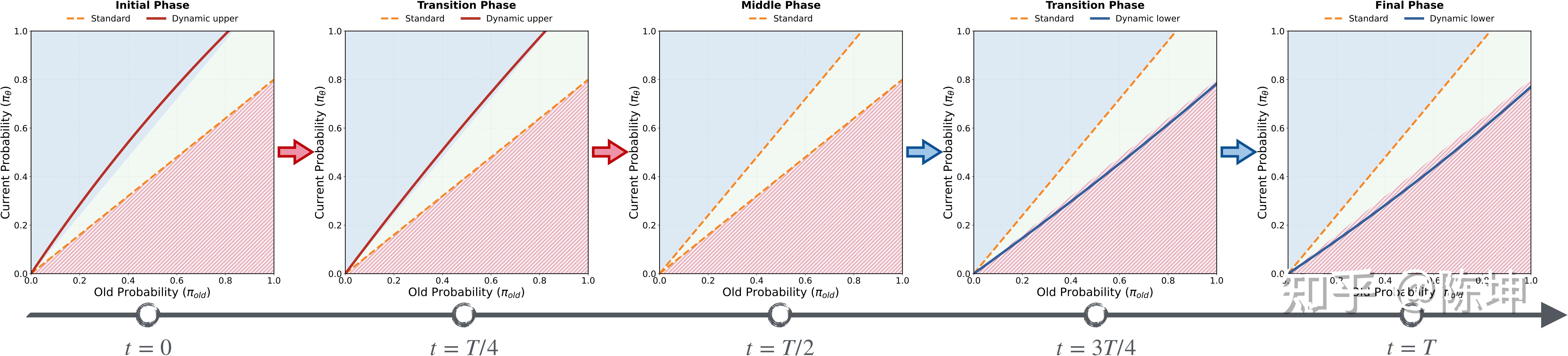
策略一:Increase-then-Decrease(ID)
以训练总步数T的中点为界,分为两个阶段:
其中\lambda(k) = 1 - \frac{2k}{T},\mathcal{H}(p)是动态上界函数,\mathcal{M}(p)是动态下界函数。
- 第一阶段:使用动态上界促进熵增长,下界保持标准值
- 第二阶段:上界恢复标准值,使用动态下界促进熵下降
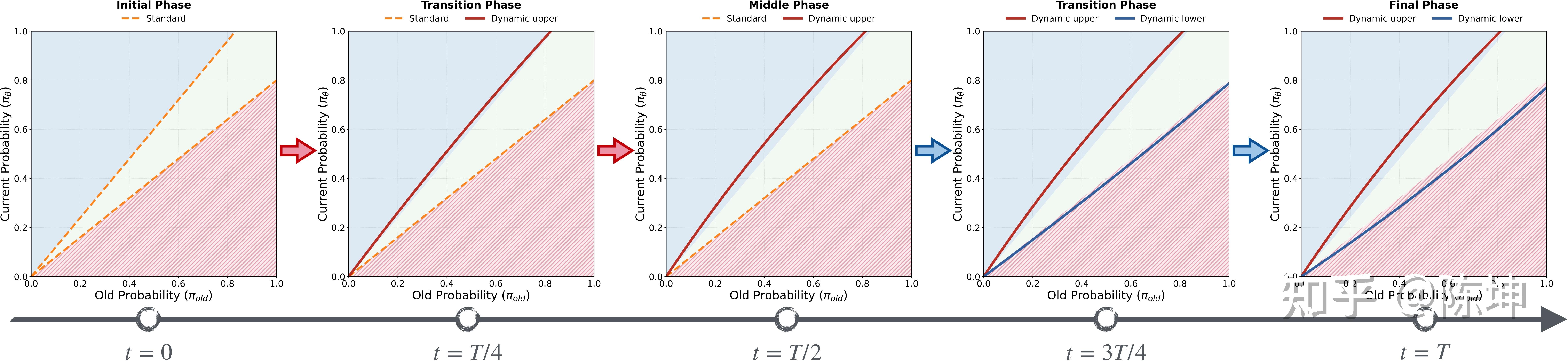
策略二:Decrease-Increase-Decrease(DID)
DID策略允许熵在第一阶段先下降,在熵崩溃前通过梯度裁剪控制熵的回升,然后在第二阶段收敛:
策略三:Oscillatory Decay(OD)
ID 和 DID 都将训练过程划分为离散阶段。OD 策略则让模型在整个训练过程中自主进行振荡衰减:
定义随时间变化的熵阈值:
其中H_{min} = 0.2 H_{init}是目标熵下界。
引入离散状态变量s_k \in \{0, 1\}(1表示熵增模式,0表示熵减模式),通过滞环逻辑控制状态转移:
根据当前状态动态选择裁剪阈值:
六、实验结果
我们在Qwen2.5-Math-7B和Qwen2.5-7B上进行了全面实验,使用DAPO-MATH数据集,在AIME24、AIME25、AMC、MATH-500、GSM8K、Olympiad等基准上评估。
我们的三种策略在多个基准上均优于GRPO , Clip-Higher和其他基线方法,其中ID策略在AIME24、AMC、MATH-500、GSM8K、Olympiad上取得最佳性能。具体的实验结果大家可以见论文。
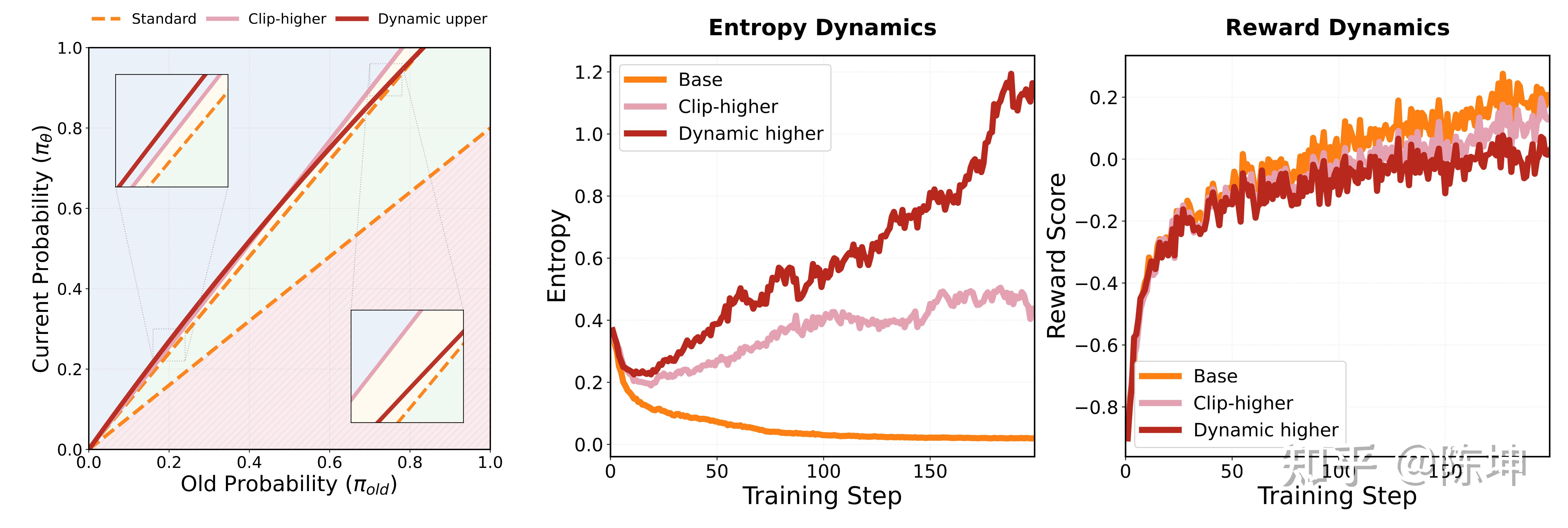
熵与奖励曲线分析
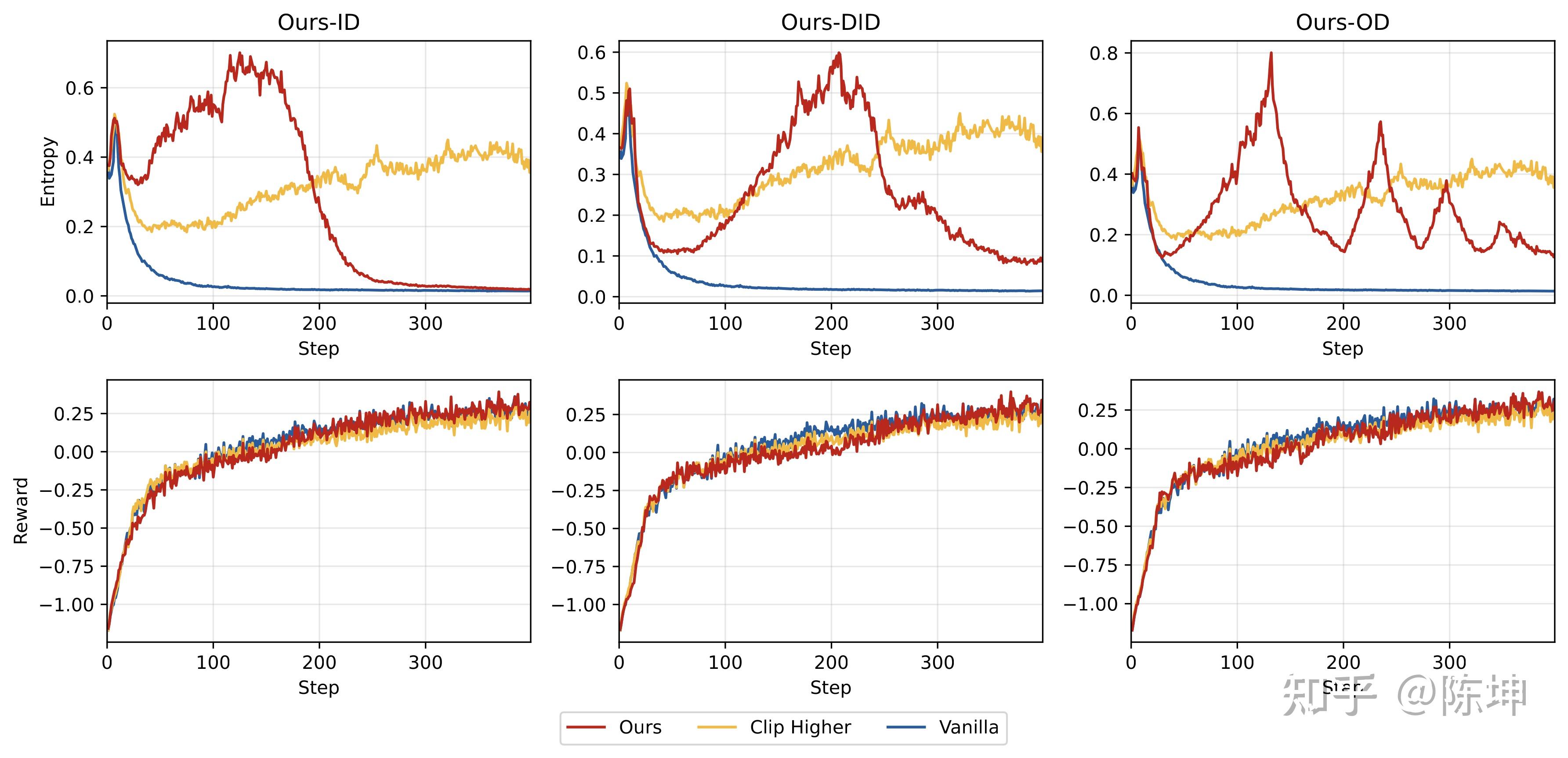
从训练曲线可以观察到:
- 熵调控有效:三种策略都实现了预期的熵变化模式
- 后期性能超越:虽然早期奖励较低,但我们的方法在后期显著超越基线
探索能力评估
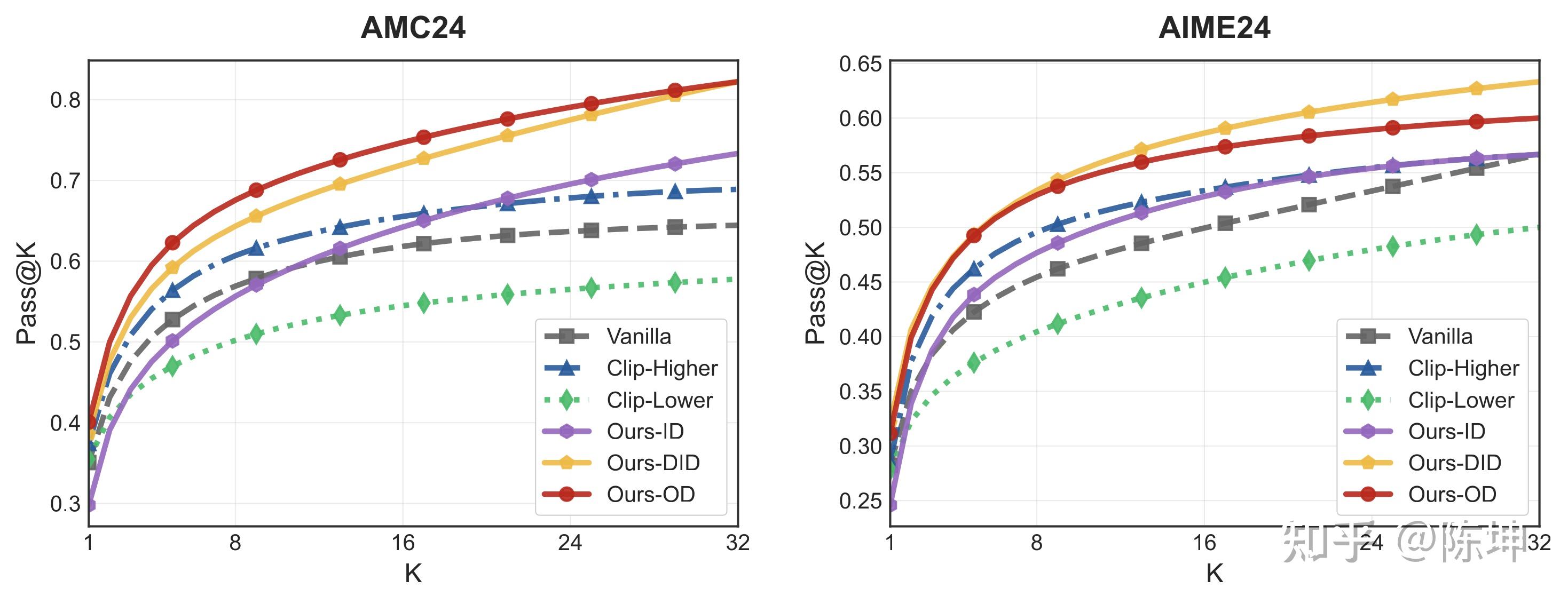
我们使用Pass@K指标评估模型的探索能力,在模型训练熵较高的120 step。结果显示,虽然各方法在Pass@1上表现相近,但增加采样数后,我们的方法展现出显著更好的Pass@K性能,说明模型保留了更丰富的解题策略。
阶段比例分析
对于ID和DID策略,我们分析了不同阶段比例的影响:
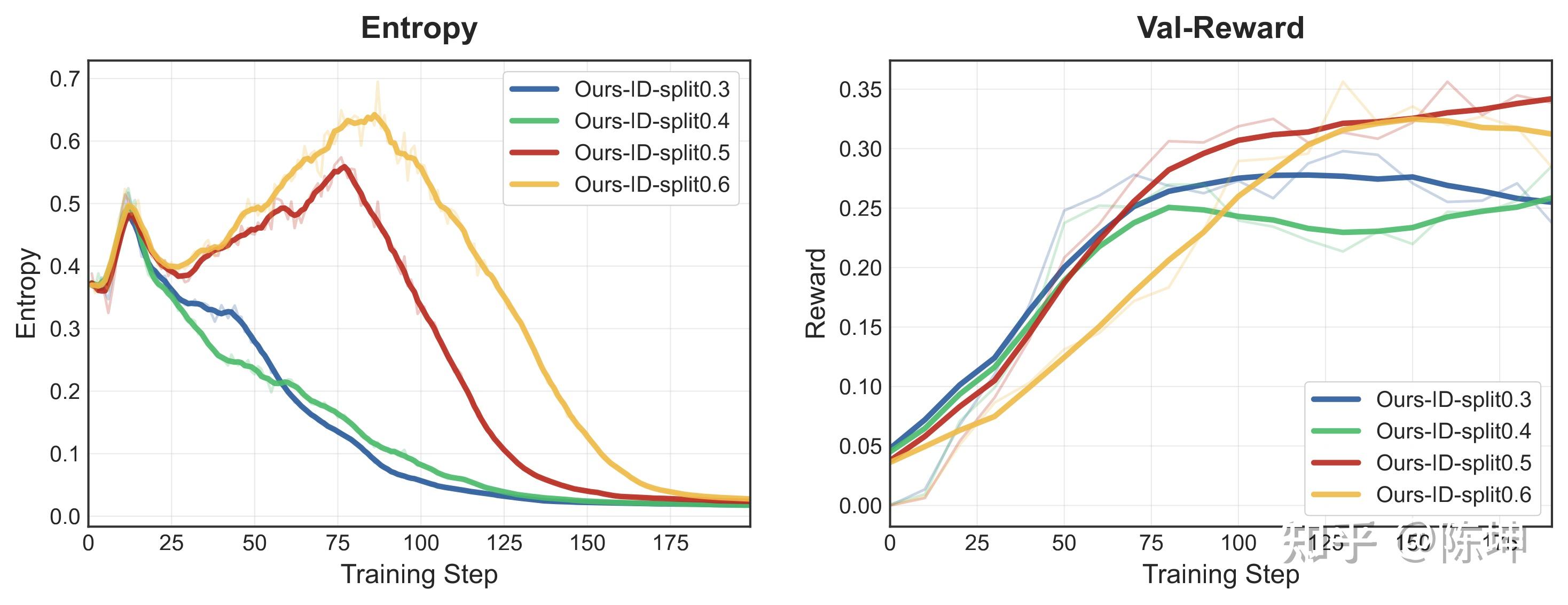
结果表明,0.5的均衡比例取得最优性能:
- 比例过小(0.3/0.4):熵尚未达到足够峰值就开始下降
- 比例过大(0.6):第二阶段收敛过快,影响最终性能
七、总结、其余实验分析与展望
本文从梯度保留裁剪的理论视角出发,系统研究了 RLVR 中的策略熵控制问题。我们的主要贡献包括:
1.理论洞察:精确刻画了重要性采样比率空间中四个熵敏感区域的作用机制
2.调控机制:设计了基于动态裁剪阈值的熵调控方法,可独立控制熵增和熵减
3.控制策略:提出了ID、DID、OD三种熵控制策略,有效缓解熵崩溃并提升模型性能
此外,其余深入的实验分析(裁剪阈值关联、Token裁剪概率、与固定阈值方法的对比)欢迎从我们在Arxiv上发布的论文继续了解,我们验证了动态裁剪机制的有效性和必要性。
这项工作为理解和控制大模型强化学习中的训练动态提供了新的理论工具和实用方法。未来,我们计划探索更精细的自适应熵控制机制,以及将这一框架扩展到更广泛的RLVR应用场景。
参考文献
[1] Shen et al. “On Entropy Control in LLM-RL Algorithms.” https://arxiv.org/abs/2509.03493
[2] Schulman et al. “Proximal Policy Optimization Algorithms.” https://arxiv.org/abs/1707.06347
[3] Yu et al. “DAPO: An Open-Source LLM Reinforcement Learning System at Scale. https://arxiv.org/abs/2503.14476
[4] Wang et al. “On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models”. https://arxiv.org/abs/2602.03392