作者:小泥鳅
https://zhuanlan.zhihu.com/p/2004633029096776871
TL;DR:推导公式拆解RL训练中Entropy变化流程、基于判别式S_k=p_k(H+\log p_k)分四类讨论Token的Entropy-Dynamic性质、统一解释主流RL-Entropy控制Trick。
本篇Blog将介绍我们的论文中的主要分析,同时根据我们的Entropy Dynamics分析,对现有各种的算法Trick(e.g. DAPO, 80/20 rule, Reward the unlikey, NSR, ...)做解释。
论文:On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models
论文链接:https://huggingface.co/papers/2602.03392
开头的碎碎念:
去年上半年开始,有关于RL entropy的工作特别火,在ICLR 2026我们也投稿了一篇Entropy相关的工作,用类似Learning Dynamics[1]的logits分析方法,讨论不同token logit对整体entropy变化情况的一阶影响,给出了一个直接分析entropy变化的公式。
这篇工作从理论角度和机制分析出发,可以对很多现有的RL算法设计做出解释,也为更精细的RL Entropy控制方法在理论和实践层面给出了Insight,算是(自认为)idea还不错的工作。
结果论文投稿ICLR初始均分5.5(按理说这个均分是前15%吧)却惨遭AC reject.不过anyway吧,AC的decision不影响我认为我们这篇工作做的分析挺有意思的。因此没中稿也还是把paper挂出来,在这里把insight分享(宣传)出来。
同时,这个Blog也是整理分析一下Entropy相关的工作,从Entropy Dynamics的角度出发去整理和分析一些Famous RL算法的设计。
基于Token logits的Entropy Dynamics推导
我们的主要motivation是理解不同token对于策略熵变化的贡献情况(以便更精细化的控制和clipping),那么对应的分析目标就回答如下问题:如果模型增强或减少了某个特定token-logit,整体分布的多样性(entropy)会发生什么变化?
Prelimiary:Learning Dynamics of LLM
我们从Learning Dynamics of LLM Finetuning(ICLR2025-Best Paper)的分析出发。
我们假设词表大小为V。对于某个位置,模型的输出Logits为\mathbf{z}=[z_1,z_2,\dots,z_V]。通过Softmax 函数得到概率分布 p:
该分布的Shannon Entropy定义为:
下面我们做Learning Dynamics的推导:
假设我们对第k个Token的Logit进行了微小的更新\epsilon(例如在 RL 过程中,该词得到了正奖励,\epsilon > 0)。更新后的Logit为
(其中
\mathbf{e}_k
是单位向量)。
利用Softmax的雅可比矩阵(Jacobian)
(\delta_{ij}=1if i = j),我们可以得到概率的一阶变化\delta p_i:
1.对于被扰动的词k:
2.对于其他词i \neq k:
直观理解:增加/减少一个token的 Logit,会导致该词概率增加/减少,而其他所有词的概率按其原有比例“等比例缩小/放大”。这部分也是Learning Dynamics的核心结论。
From Learning Dynamics to Entropy Dynamics
现在可以通过logit变换来推导熵的变化\Delta H。
根据泰勒展开:
已知熵对概率的偏导数为:
带入\Delta H公式:
由于概率之和始终为1,所以\sum\delta p_i =0。第一项消失,剩下:
将之前得到的\delta p_i带入:
提取公因子-\epsilon p_k:
注意,由于H = - \sum_{all}p_i\log p_i,可以观察到括号内的项:
于是得到最终简洁的线性动态公式:
其中 S_k即为我们推导得出的Entropy Change Discriminator:
Entropy Change Discriminator告诉了我们什么
设s = \mathrm{sign}(\epsilon)为更新方向(正样本为+1,负样本为-1),则熵的变化符号为:
其中e^{-H}即为阈值点。根据正负样本方向以及对应token prob是大于还是小于这个阈值,我们可以分四类Case讨论:
对于正样本,如果对应logit的p_i大则熵增,小则熵降:
- p_i > e^{-H}\Rightarrow \Delta H<0;此时分布变得更尖,熵降(Case1)
- p_i < e^{-H}\Rightarrow \Delta H>0;此时分布变得更平,熵增(Case2)
对于负样本,如果对应logit的 p_i 大则熵降,小则熵增:
- p_i > e^{-H}\Rightarrow \Delta H>0;此时分布变得更平,熵增(Case3)
- p_i < e^{-H}\Rightarrow \Delta H<0;此时分布变得更尖,熵降(Case4)
从直观上讲,这四类中可能只有第(Case4)类别对RL学习可能没有太大的帮助。其他的三种对应都可以想到对应起到正向帮助的有效case。而很多RL算法Trick可以被认为是通过对四类Case的不平等对待,来达成对应的算法效果。
对现有方法的解释与理解
比较有意思的一点是,从我们的分析结果出发,可以套入现有的很多RL算法工作,得到一个对应的合理解释。在此也对entropy相关的各种工作做一个整理 and 带入。
DAPO
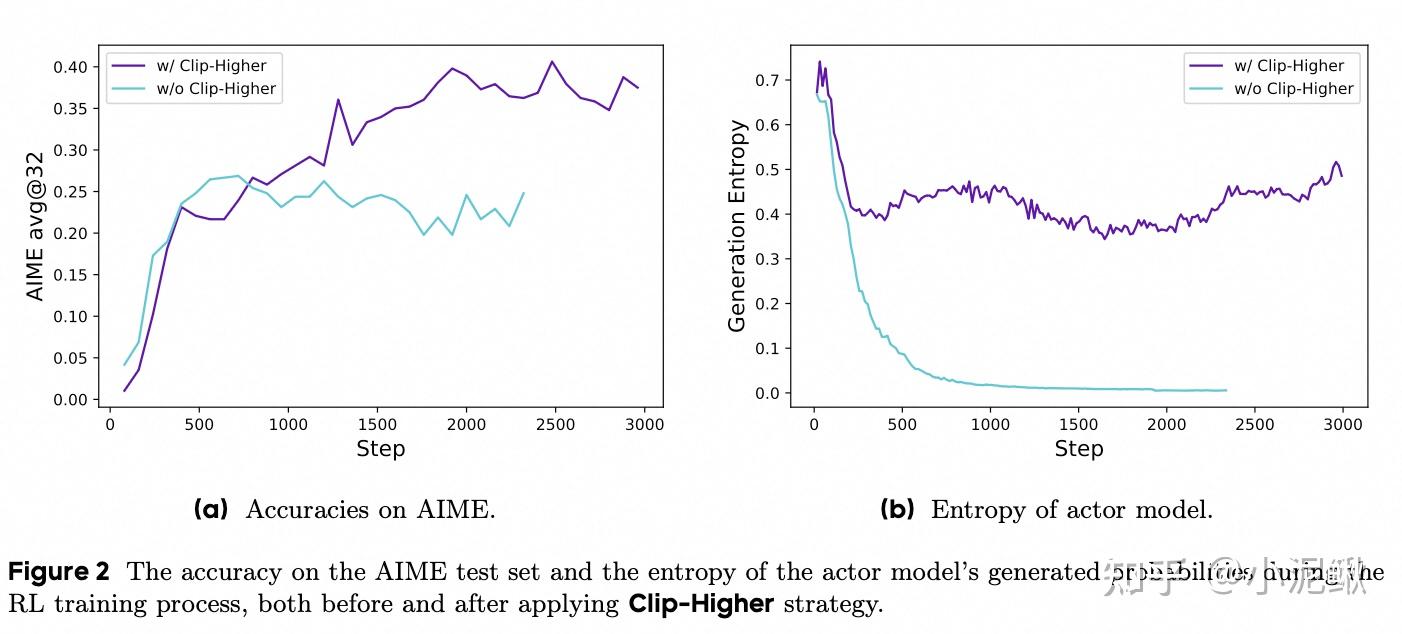
DAPO[2]的Clip Higher方法是放松clipping上界的取值范围,会同时放松对应(Case2)和(Case4)部分的off-policy更新条件。由于Clipping上界被触发意味着该PPO-epochs内已经提升过对应的p_i概率,(Case4)应该更少被触发,(Case2)的部分影响都要大于(Case4)的部分。因此通过对(Case2)部分进行促进可以有效提升policy的探索,提升Entropy。
Beyond 80⁄20 rules

80/20论文[3]的方法是只对Forking token(High Entropy Token,即对应entropy高e^{-H}小的部分)进行更新。那么在实际更新的token中,对应(Case1)和(Case3)的占比为主要。
这样的设置就是让正样本exploit降低entropy,负样本explore提升entropy,虽然没有什么entropy上的保障,算是比较符合我们RL本身的直觉。
Reward the Unlikely
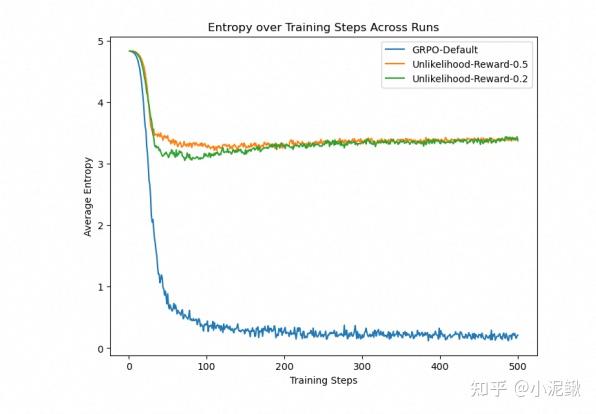
[3]相当于用reward提升(Case2)部分的更新幅度,来达成维持entropy不剧烈下降的目的。
Do Not Let Low-Probability Tokens Over-Dominate
[4]相当于抑制了所有(Case2)和(Case4)的更新。论文没有给出entropy曲线而是给出了accuracy收敛速度。我个人猜测这篇论文对应的方法实际上是更快的用entropy的下降去换RL accuracy的加速提升,即更多的exploit。
以及这篇工作,他的方法理论上是和Beyond 80⁄20 rules这篇正好相反的。我认为两篇工作结论不一致的原因一方面由于实验时使用本身模型的强弱:对于更弱的模型(Qwen2.5),需要更多的提升模型解题的基础能力(解题的原子能力),即更多的在持续exploit;80/20用的是更强的模型(Qwen3),其实原子的解题能力不错,因此更多是要diverse的reasoning pattern。
NSR
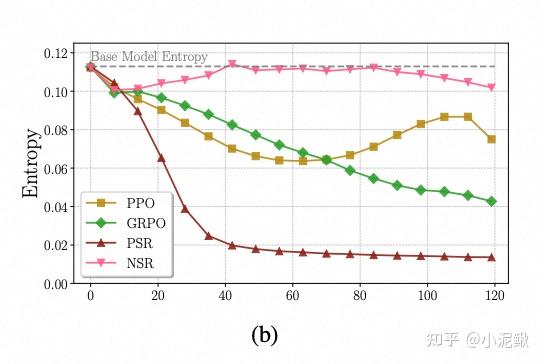
[5]NSR只训练负样本,相当于只训练(Case3)和(4)。而大部分情况下(Case3)的作用是大于(Case4)的,hence熵增。
负样本控制

现在很多算法(SAPO[6]、Deepseek-V3.2中对GRPO的改进[7])都是将正负样本分开处理。对负样本额外操作,降低low prob负样本权重或者直接过滤掉对应负样本,这其实也可以认为就不想要(4)即p_i < e^{-H}的负样本部分,这个部分导致的熵降其实是相对不健康,undesirable的。所以去掉了能提升Performance也很合理。
The Entropy Mechanism of RL
他们通过分析得出的公式为:
[7]这篇工作同样是分析Entropy,不过他们是从RL batch出发,用协方差形式来分析entropy变化情况做推导,而最后得出了有些类似的结论。
对应的
其实也是看当前logit是否是超过了一个阈值,而
也可以被看为是正负样本方向。
CE-GPRO
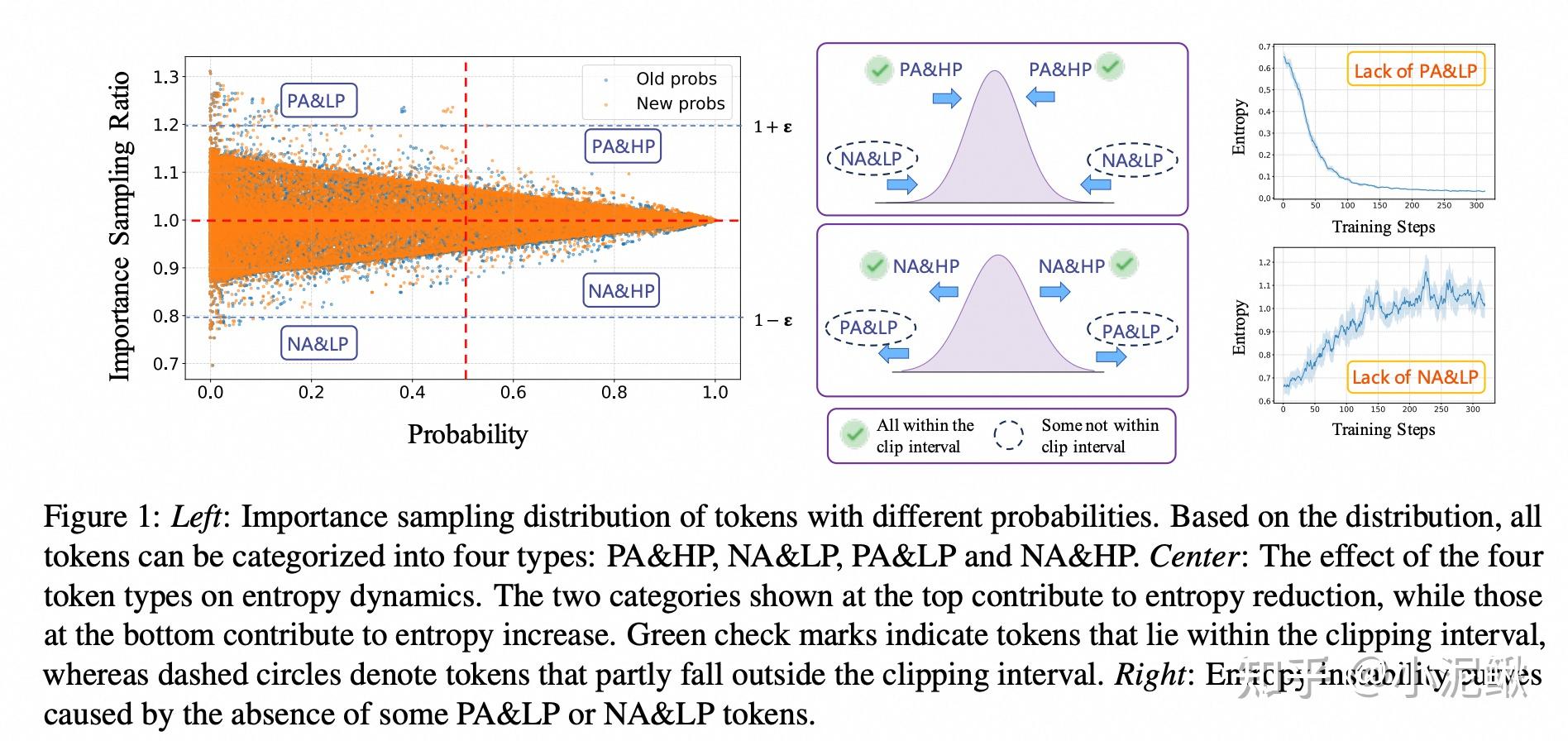
[8]快手的CE-GRPO算是同期工作,他们是从Empirical的实验角度出发,得出了类似的4种case的分类结论,可以说是很巧了。他们的实验结果更是很好的验证了我们的Entropy Dynamics分析结论。
Adaptive Entropy loss
Entropy-loss是最简单粗暴的提升entropy的方法,可能有些case下会有效。个人觉得这种方法好处是最直观,坏处是大水漫灌的方式效果肯定不会特别好,而且要额外的算一个loss,会有一些cost。 稍微好一点的方式是entorpy-loss的系数可以adaptive的去算[9],不过也没有解决根本问题。
感觉现在大家用这种entropy loss的情况少了,提升exploration的方法更多是clip-higher(简单有效,没有overhead)。不过clip-higher相比之下没有那么方便的adaptive的调整,因为没有一个合适的中间指标作为参看。而adaptive调整这件事感觉本身是很有意义的。
通过Temperature控制Entropy
还有一类工作是Temperature来控制Entropy/探索情况。
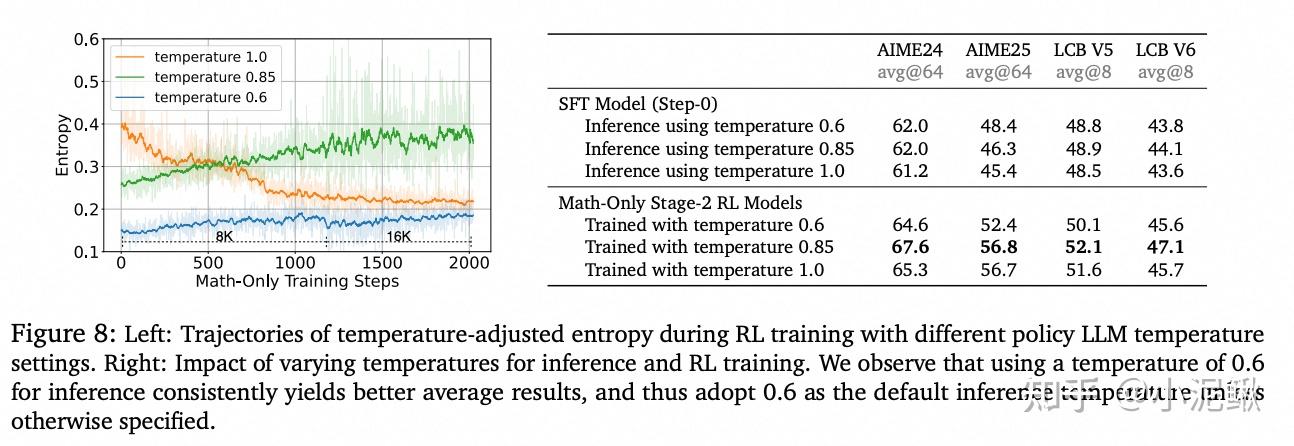
NvidiaAce1.1[10]提出合理的 temperate设置可以促进entropy稳步上升,对应也得到了更好的Performance。
比如Polaris[11]通过动态调整不同阶段的最优Temperature来控制探索:
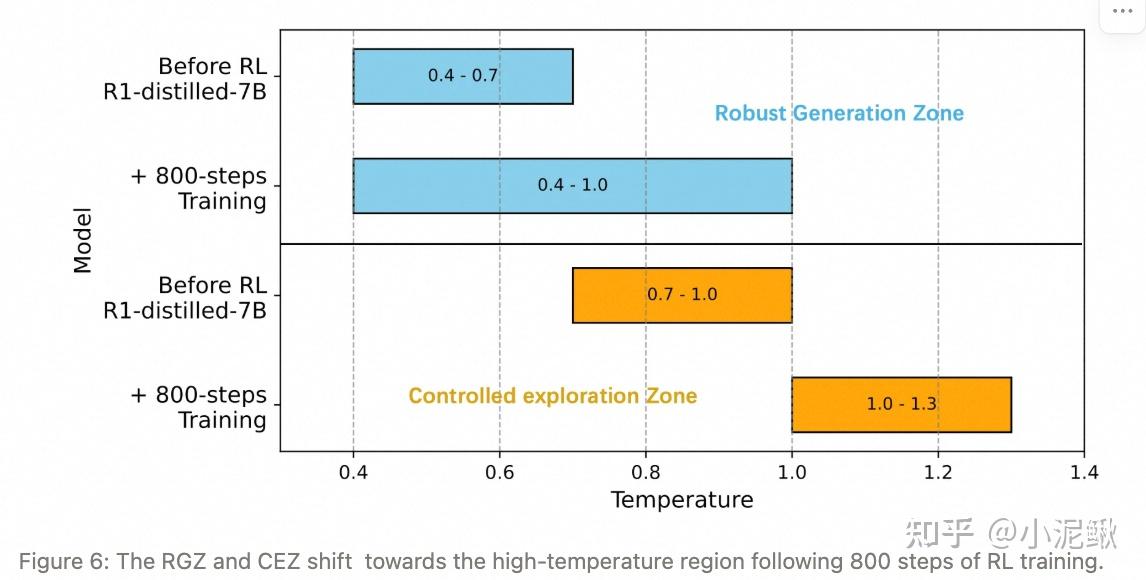
当然,temperature这个用token prob也不是很好解释。Polaris这篇的temperature调整更多是从rollout diversity得角度出发,这么说来其实这个操作还更本质些。
关于RL Entropy的碎碎念
RL-Entropy最大的尴尬在于:Entropy作为一个指标和其实和最后Performance不挂钩,Entropy始终是一个间接的指标。它更像是一个“生命体征”,心跳停了(熵崩了)人肯定没救,但心跳正常不代表你能跑马拉松。
现在的RL算法已经能让我们很轻易地把熵控制在一个漂亮的范围,但实际上也没有特别大的意义。如何让LLM在巨大的解空间里做有意义的探索,这才是Exploration的关键。而不同于传统RL(有限的action space甚至直接用Epsilon Greedy或者加Noise就好),RL for LLM的本身logits的词表就大,叠加Long-CoT之后更是有了夸张的action space大小。
如何让LLM做有效的持续探索是RL能否长期训练的关键。如果能很好的解决这个问题,相信叠加了Scaling Law的威力后,the Era of Experience就会到来。
最后,都看到这里了,在Huggingface Daily Papers上给我们点个赞吧,给被AC拒掉的我们一点小小的安慰。 如果你对LLM策略演化或者大规模 RL 训练感兴趣,欢迎关注我们的项目Trinity-RFT,也欢迎讨论分享观点~
Refs:
[1] Learning Dynamics of LLM Finetuning
https://arxiv.org/abs/2407.10490
[2] DAPO: An Open-Source LLM Reinforcement Learning System at Scale
https://arxiv.org/abs/2503.14476
[3] Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening
https://arxiv.org/abs/2506.02355
[4] Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
https://arxiv.org/abs/2505.12929
[5] The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning
https://arxiv.org/abs/2506.01347
[6] Soft Adaptive Policy Optimization
https://arxiv.org/abs/2511.20347
[7] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
https://arxiv.org/abs/2512.02556
[8] CE-GPPO: Coordinating Entropy via Gradient-Preserving Clipping Policy Optimization in Reinforcement Learning
https://arxiv.org/abs/2509.20712
[9] Skywork Open Reasoner 1 Technical Report
https://arxiv.org/abs/2505.22312
[10] AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy
https://arxiv.org/abs/2506.13284
[11] POLARIS: A POst-training recipe for scaling reinforcement Learning on Advanced ReasonIng modelS
https://arxiv.org/html/2507.07451v1