1.引言
在CVPR 2026接收的论文《Conan: Progressive Learning to Reason Like a Detective over Multi-Scale Visual Evidence》中,我们提出了基于多尺度视觉证据的多步视频推理框架,解决多模态大语言模型(MLLMs)在视频理解中幻觉推理与证据定位不准的双重挑战。
论文链接:https://arxiv.org/abs/2510.20470
作者:Kun Ouyang, Yuanxin Liu, Linli Yao, Yishuo Cai, Hao Zhou, Jie Zhou, Fandong Meng, Xu Sun
机构:北京大学、腾讯微信AI
代码仓库:https://github.com/OuyangKun10/Conan
2.基于证据的侦探式推理(What)
2.1 核心框架
Conan模仿侦探破案过程,通过三个模块构建推理链条:
- 1.帧识别(Identification):区分证据帧(直接回答问题)、上下文帧(辅助推理)与无关帧(可忽略)
- 2.证据推理(Reasoning):基于已识别的帧进行跨帧线索关联与逻辑推断
- 3.动作决策(Action):自适应决定是随机采样更多帧、针对性检索特定片段,还是自信地给出最终答案
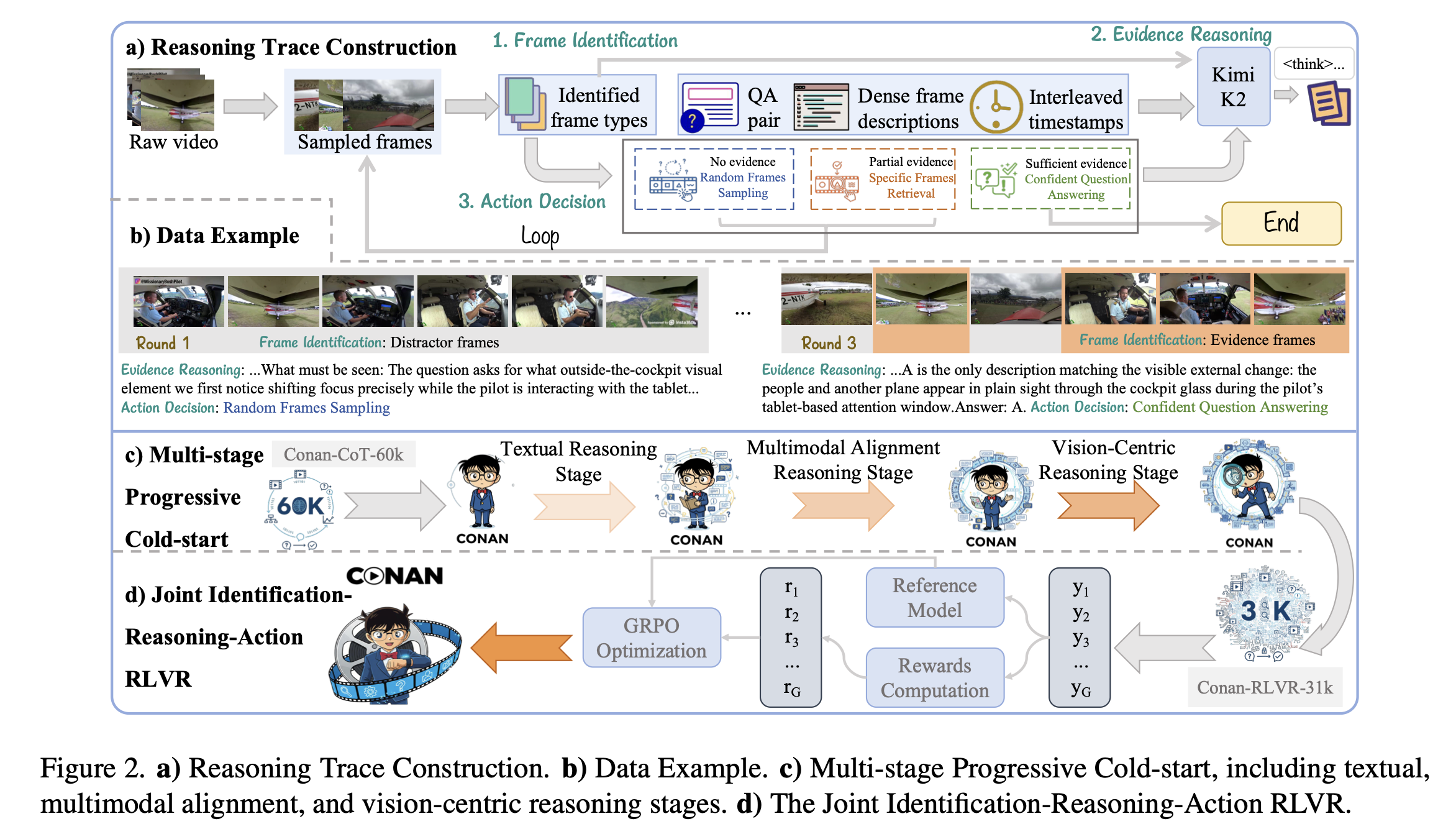
2.2 数据集与训练策略
Conan-91K数据集:基于GenS-Video-150K构建,使用Kimi K2自动生成91,000条推理轨迹,包含帧识别、证据推理和动作决策的完整标注。
三阶段渐进式冷启动:
- 阶段一:文本推理——用帧的文本描述训练,建立结构化推理基础
- 阶段二:多模态对齐——结合视觉帧与文本描述,学习帧检索动作
- 阶段三:视觉中心推理——完全依赖视觉帧进行多步推理AIR RLVR强化学习:通过格式奖励、结果奖励、识别奖励和检索奖励的联合优化,使模型学会何时收集证据、何时推理、何时作答。
3. 动机与灵感(Why)
3.1 视频推理的双重困境
困境一:RL方法的幻觉陷阱
现有基于RL的推理(如Video-R1)依赖纯文本链,缺乏视觉证据显式关联,导致结论无视觉依据或产生幻觉。
困境二:帧检索的证据迷失
帧检索方法(如Video-MTR)难以精确定位关键帧,常将无关帧纳入证据集,无法应对多步逻辑推导。
3.2 侦探破案的启示
启示一:多尺度证据识别
侦探区分关键线索(证据帧)、辅助信息(上下文帧)和干扰项(无关帧),聚焦真正突破口。
启示二:渐进式能力培养
侦探从文字案卷分析→图文对照→现场勘查逐步成长,而非直接面对复杂现场。
Conan的核心逻辑:多尺度帧识别 + 三阶段渐进式冷启动,先掌握结构化推理,再逐步引入视觉证据,避免早期训练崩溃。
4.实践中的Conan(How)
4.1 自动化数据构建
基于GenS-Video-150K,利用Kimi K2生成推理轨迹:
- 均匀采样16帧并自动标注类型
- 根据证据充足度决定动作:随机采样 / 特定检索 / 自信回答
- 生成连贯的文本推理链
4.2 三阶段训练流程
| 阶段 | 数据 | 核心目标 |
|---|---|---|
| 文本推理 | 10K样本 | 建立逻辑推理结构 |
| 多模态对齐 | 35K样本 | 学习视觉-语言关联,引入检索 |
| 视觉中心 | 60K样本 | 掌握纯视觉多步推理 |
| AIR RLVR | 31K高难度样本 | 强化证据识别与检索效率 |
四维奖励函数:格式规范+答案正确+证据识别精准+检索高效
5.实验效果
在六个多步推理基准(MMR-V、Video-Holmes、VRBench、VCRBench、LongVideoReason、Human-P&C)上:
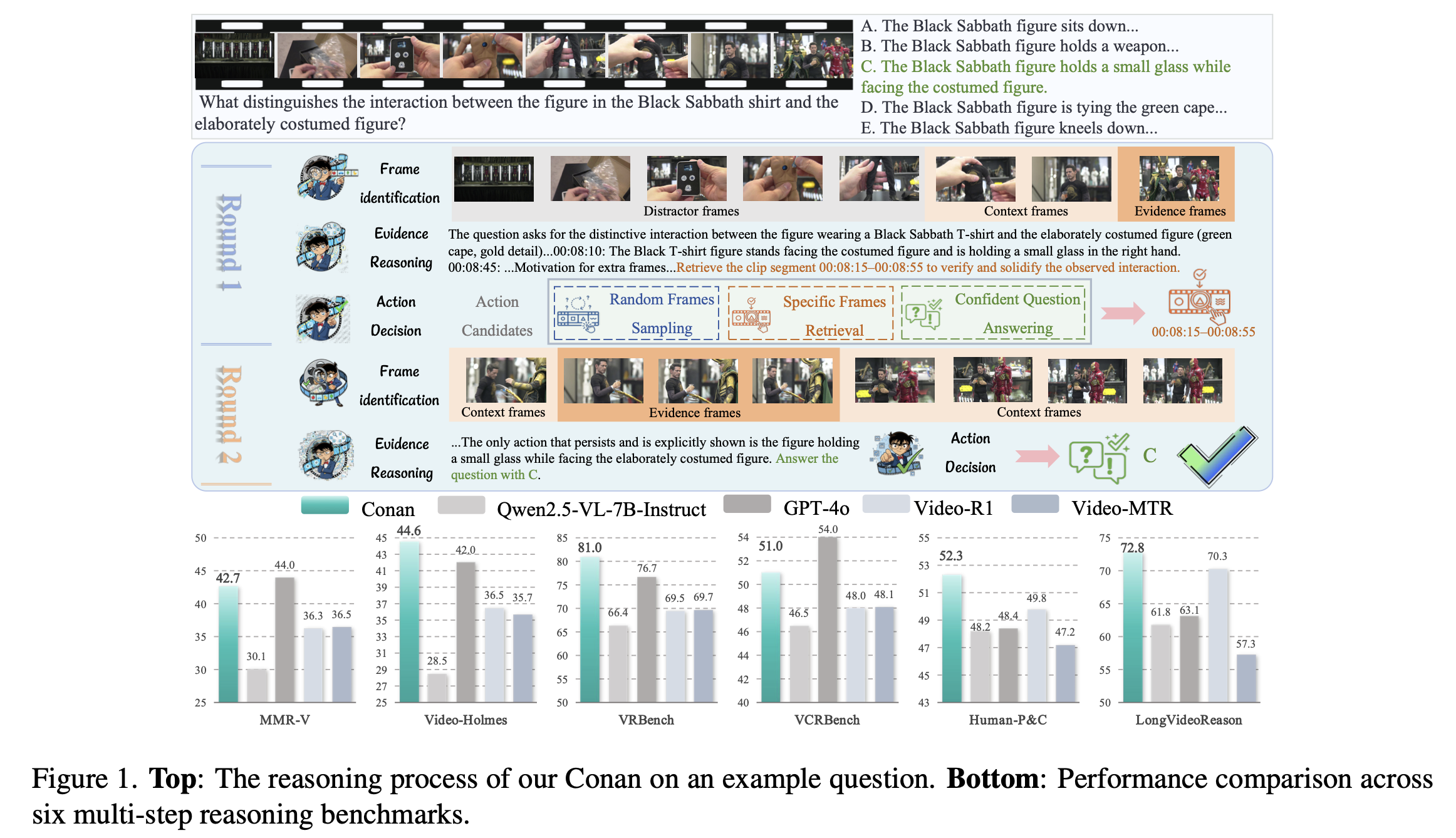
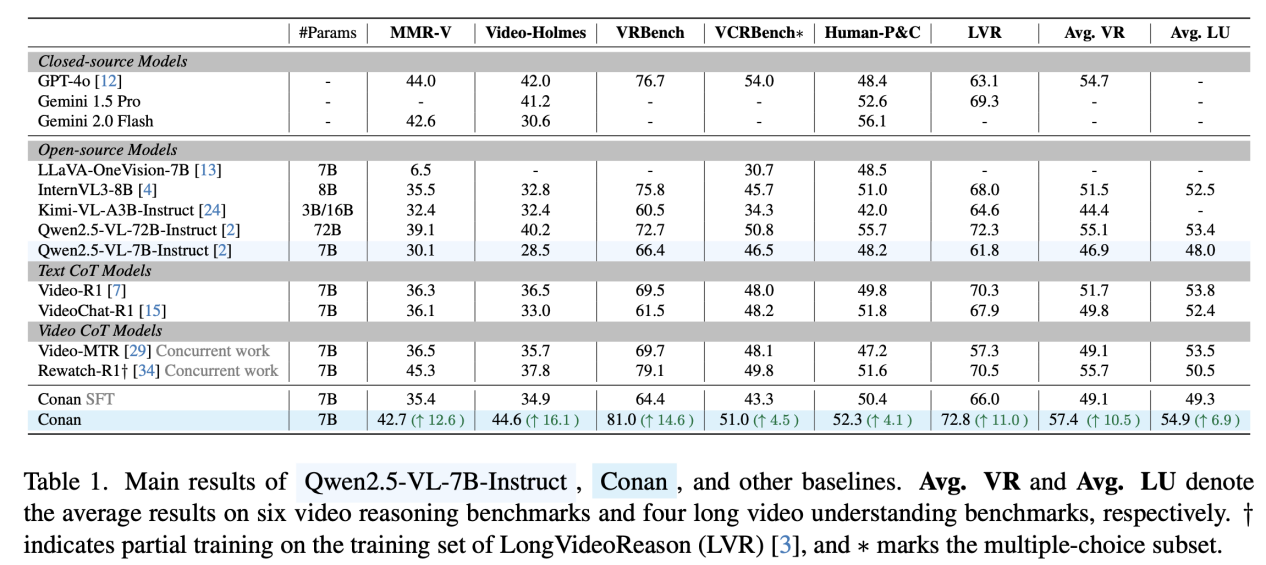
6. 总结
Conan通过多尺度帧识别和三阶段渐进式冷启动,为视频推理中的幻觉与稀疏奖励问题提供了有效方案。
核心贡献:
- 侦探式三阶段推理框架(识别-推理-决策)
- Conan-91K大规模数据集与自动化构建管道
- 三阶段渐进冷启动 + AIR强化学习- 六个基准平均10.5%准确率提升
未来方向:探索动态帧生成(Chain-of-Frame),让模型在推理中生成超出原视频范围的视觉证据。
论文:https://arxiv.org/abs/2510.20470
模型:huggingface.co/RUBBISHLIKE/Conan-7B
代码:https://github.com/OuyangKun10/Conan