NUS、ZJU、UW、Stanford、CUHK联合提出「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。

仅用2.4万条数据微调7B统一模型,视觉推理平均提升34.74%,多项任务比肩甚至超越GPT-4o和Gemini 2.5 Flash。更重要的是,模型涌现出未被训练覆盖的视觉操作能力与自主模式切换,显示出多模态推理走向「原生智能」或许正在跨过第一道门槛。
论文标题:ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
论文(arXiv): https://arxiv.org/abs/2510.27492
代码:https://github.com/ThinkMorph/ThinkMorph
主页(全开源):https://thinkmorph.github.io/
为什么需要「原生」多模态推理?
人类解决复杂问题时,「视觉思维」和「逻辑思维」是无缝切换的:看到一道几何题,我们会在脑中构建空间图景,同时用逻辑推演约束条件;走迷宫时,我们一边在视觉上追踪路径,一边在语言层面排除死胡同。两种思维模态彼此交织、互相推进,这是人类认知的基本方式。

然而,当前主流的多模态大模型并非如此。图像只在输入阶段被“看见”一次,之后无论是思维链还是强化学习,提升的都是语言层面的推理。换言之,模型「看了一眼」之后就闭上了眼睛,纯靠文字完成后续所有思考。
一种思路是调用外部视觉工具来间接弥补,但天花板有限。ThinkMorph 走的是更彻底的路:「原生多模态推理」(Unified Multimodal Reasoning):模型可以在推理的任何阶段自主生成中间图像来辅助思考,再用文字分析图像、推进逻辑,形成交替演进的推理链。整个过程在同一个统一模型中完成,不依赖任何外部工具或多阶段流水线。
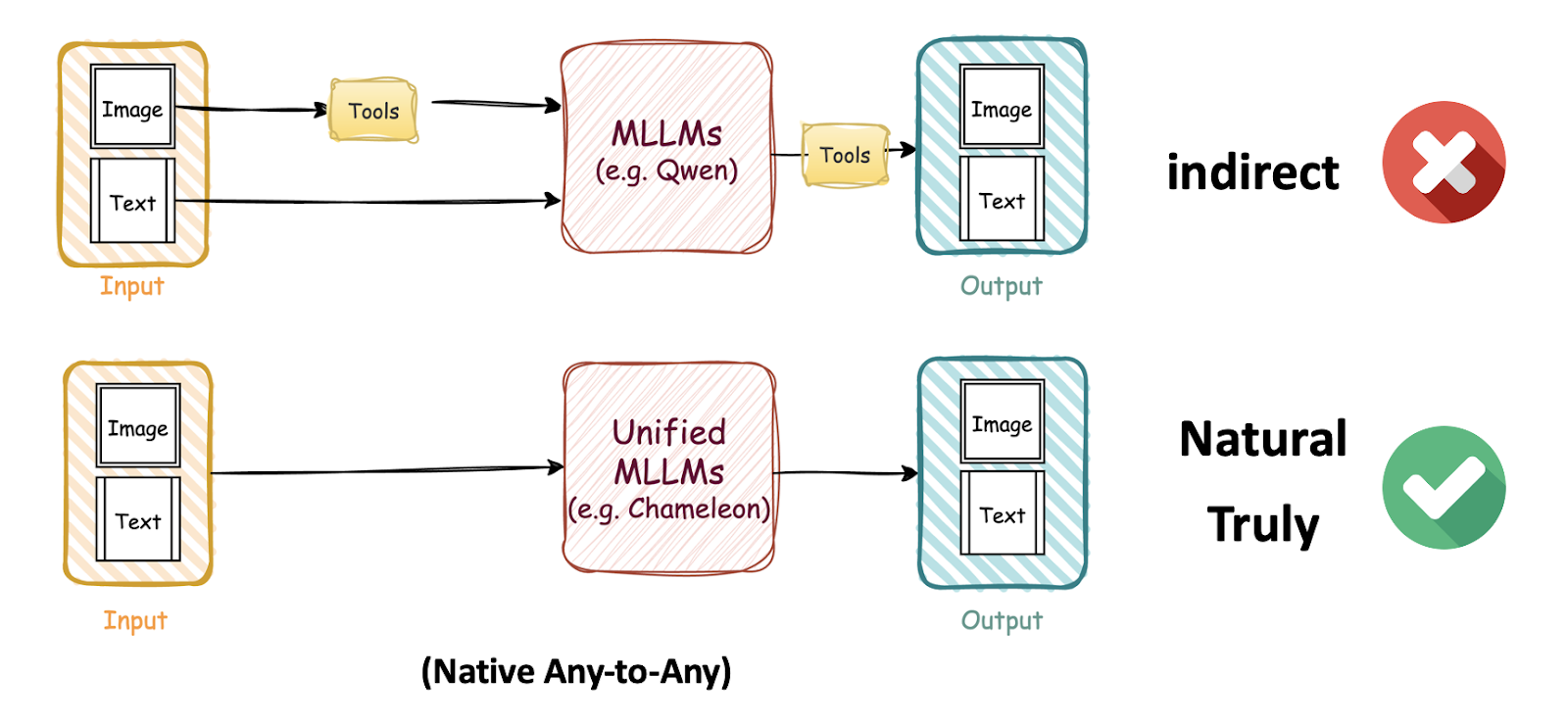
这与人类的认知方式高度一致:我们解决视觉问题时,也是在「看」和「想」之间自然切换,而不是看一眼就闭上眼睛纯靠语言推演。ThinkMorph让模型第一次具备了这种能力。
核心设计:互补而非同构
ThinkMorph的核心理念:文字与图像在推理中应提供互补信息,共同演化,而非同构复制。
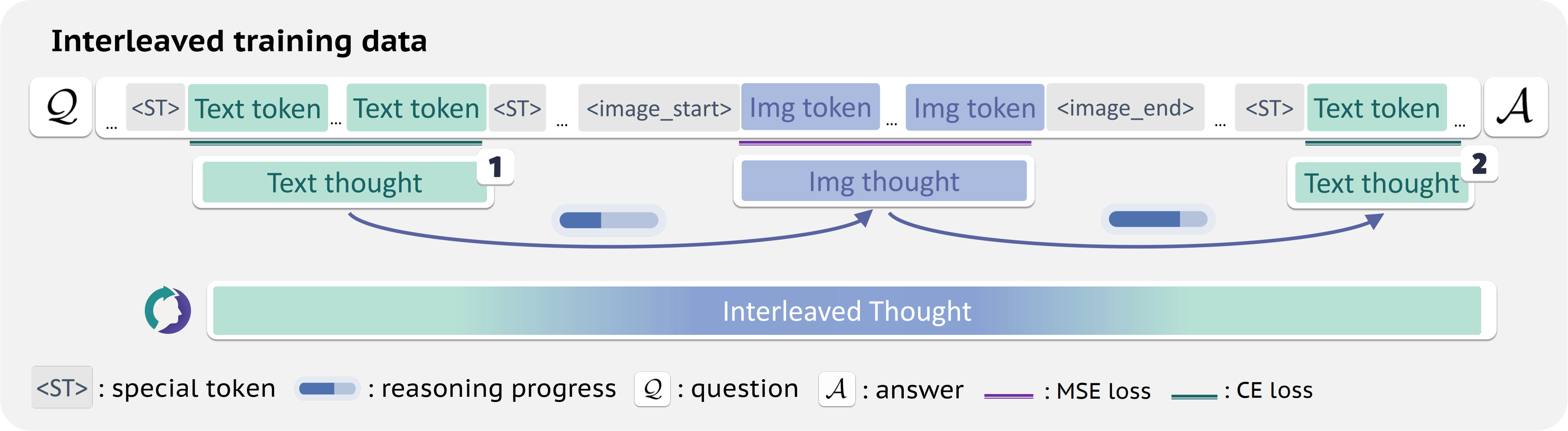
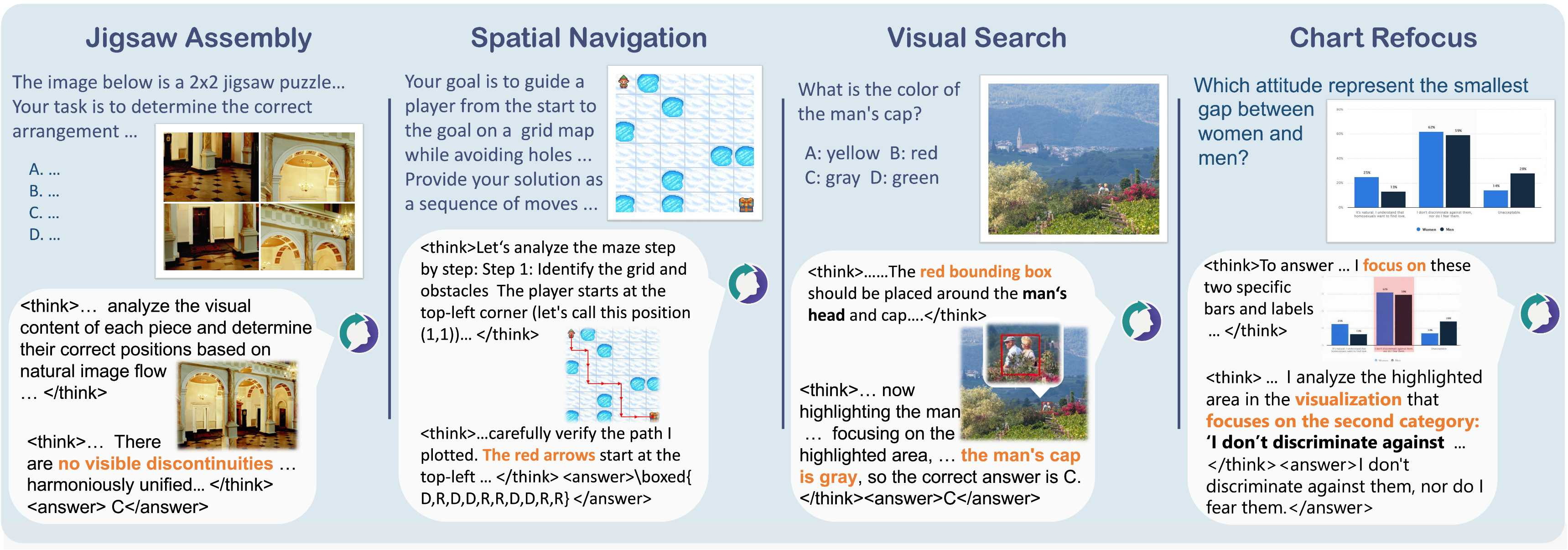
文字负责抽象分析和逻辑验证(「这块碎片左侧有棕色纹理,应在第三行第一列」),图像负责空间可视化和细节呈现(生成重排后的拼图效果图、标注边界框、绘制路径),两者互相推动,逐步逼近答案。
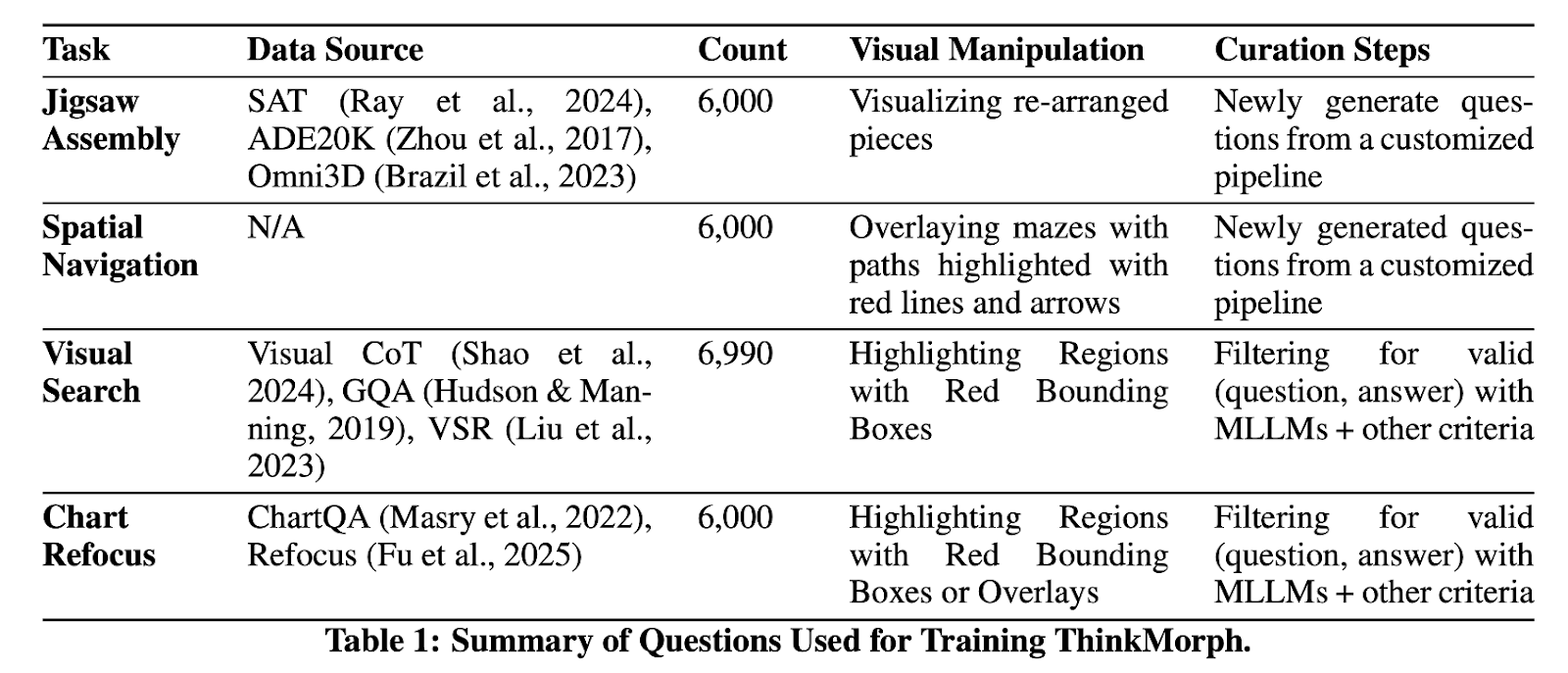
基于统一多模态模型Bagel-7B,研究团队构建了约24K条高质量交错推理训练数据,覆盖四类视觉推理任务
原生多模态推理有多强,又能走多远?
在同一个基座模型上,研究团队分别微调了纯文字、纯视觉和交错「三种推理模式」进行对比。结果很清晰:交错推理在视觉密集型任务上全面领先。文字与图像在推理中确实能互补协作,而非简单相加。
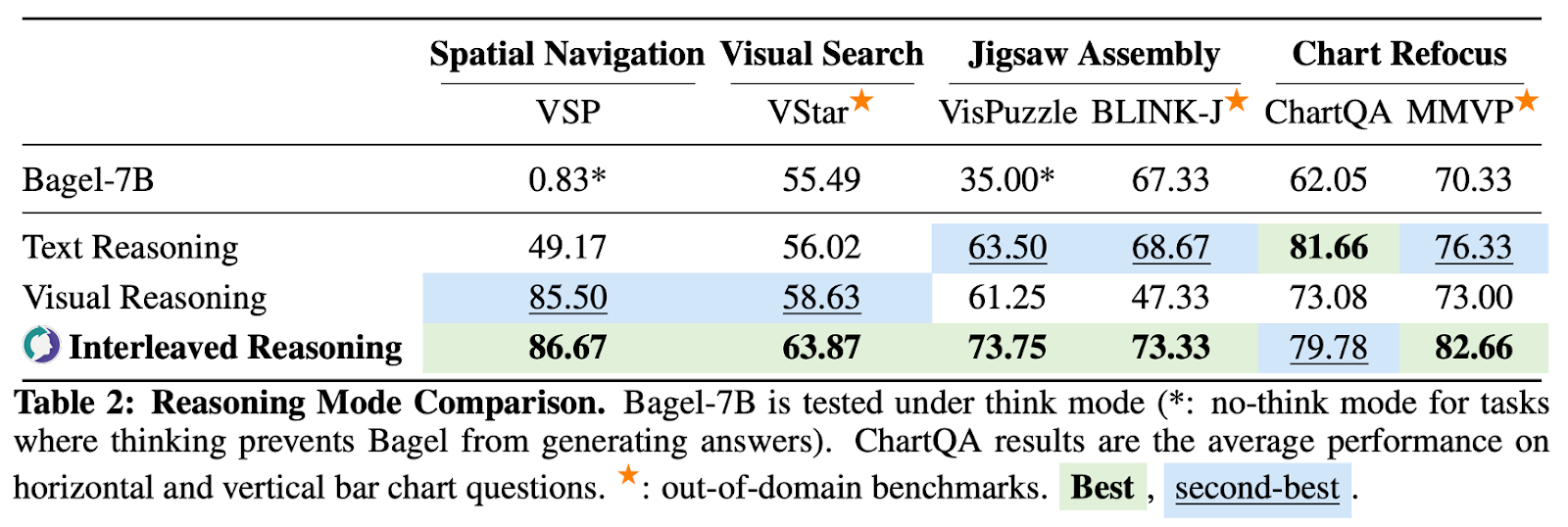
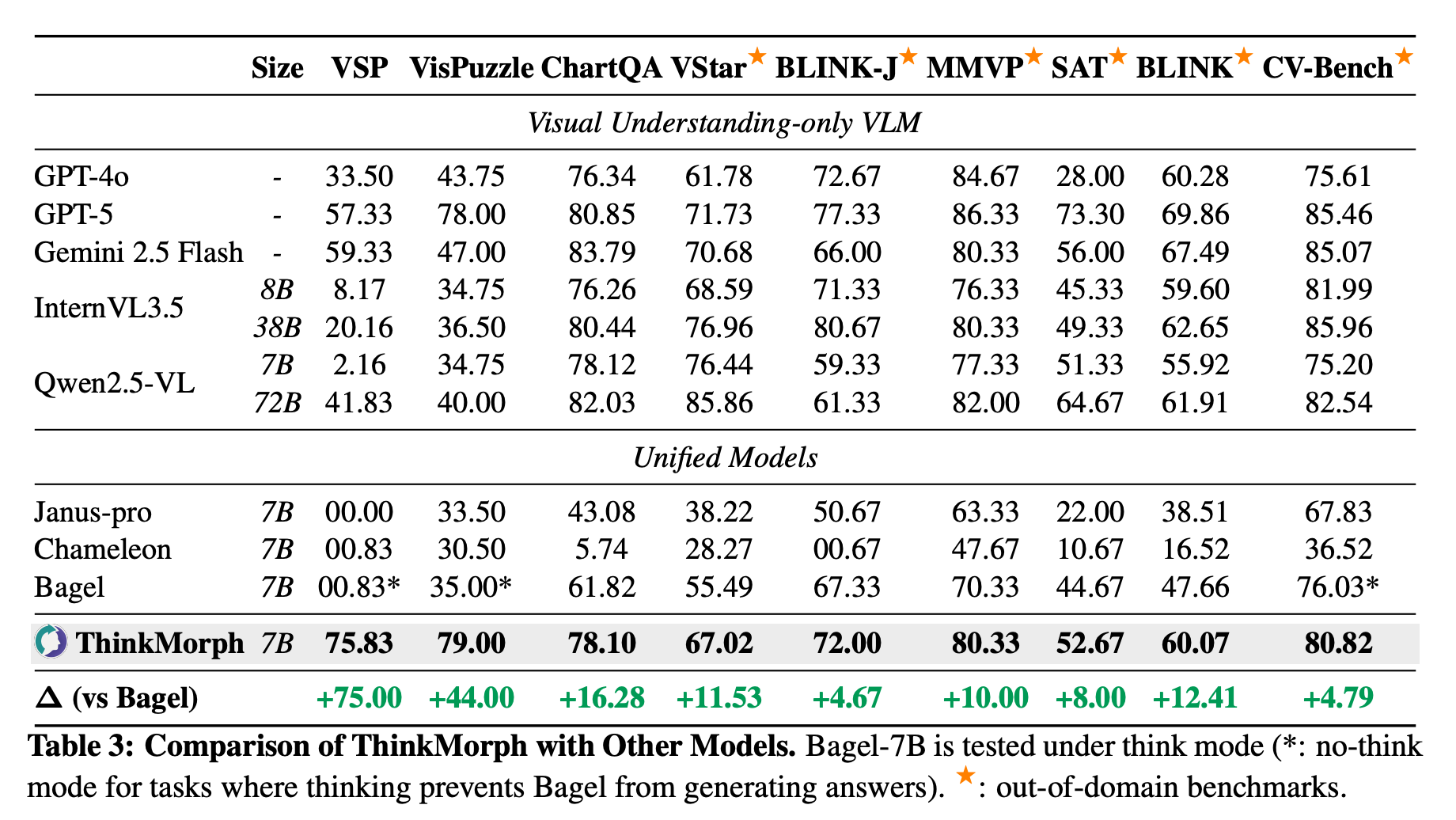
更关键的是「泛化能力」。在全部24K数据联合训练后,ThinkMorph在9 个基准上相比基础模型平均提升20.74%,其中包括多个从未见过的域外任务。尽管只有7B参数,它已可以与大规模模型比肩:在BLINK-J上超越 Qwen2.5-VL-72B超过10个百分点,在SAT空间推理上领先GPT-4o 24.67个百分点,在MMVP上匹配Gemini 2.5 Flash。
这不只是规模的胜利,而是训练策略的胜利:交错推理让生成与理解相互强化,用更少的数据撬动了更强的视觉推理能力。
不止于性能:原生多模态推理的潜力远超想象
如果 ThinkMorph 只是「性能更好」,它可能只是又一篇刷榜论文。但比数字更重要的,是这个初步探索中涌现出的一系列积极信号。它们暗示:原生多模态推理的潜力,我们才刚刚触及冰山一角。
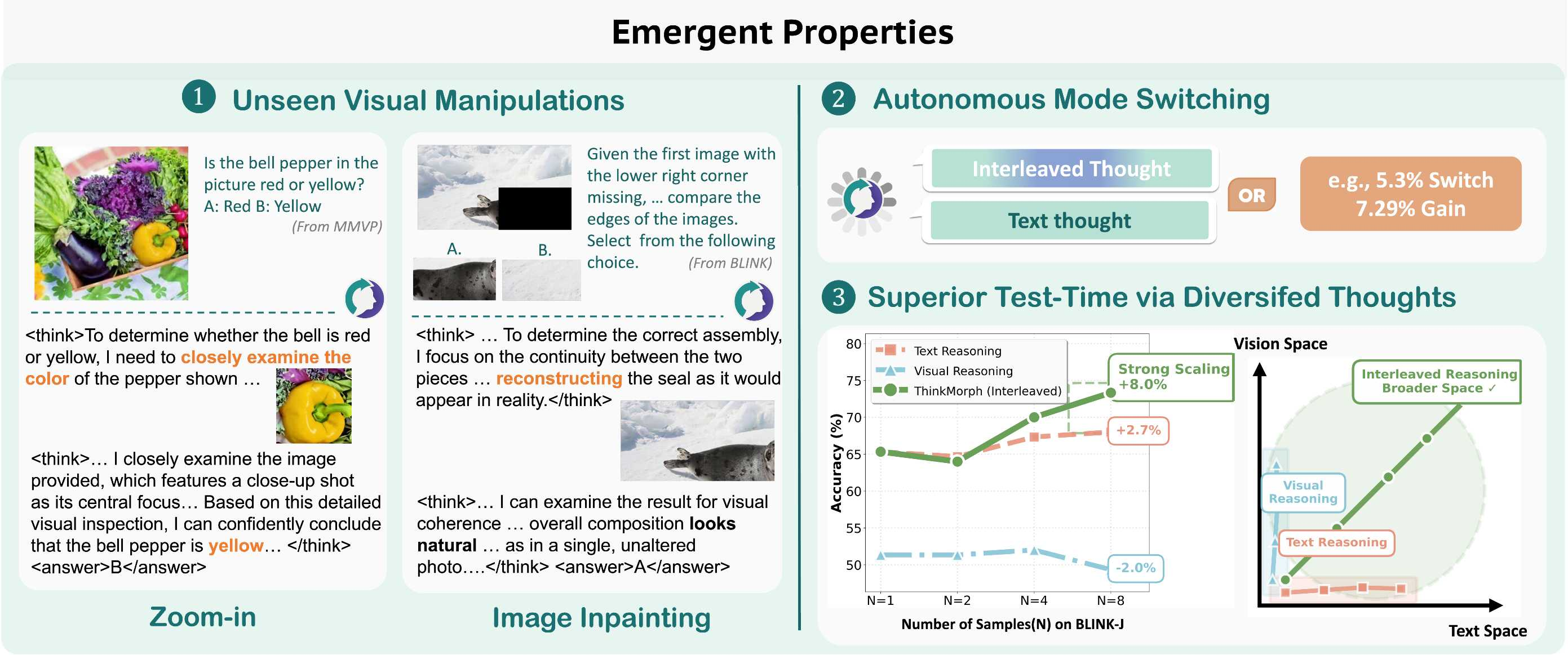
信号一:未见视觉操作——模型自主习得了 8 种新技能
训练数据中只包含四类基础视觉操作(拼图可视化、路径绘制、边界框标注、区域高亮),但测试时模型自发展现了8种从未见过的操作如放大(zoom-in)、图像修复(inpainting)等。

最典型的例子:面对「这个灯笼椒是红色还是黄色?」这个问题,模型自动生成了一张放大图来辨认颜色的细微差异,完全模仿了人类凑近观察的认知策略,而这种操作在训练数据中从未出现。在某些基准上,这类涌现操作占到了所有视觉生成的10% 以上。
研究团队分析了其来源机制:预训练赋予了原始的视觉操作能力,而交错推理微调激活了这些能力在推理场景中的目的性运用。
信号二:自主模式切换——「这道题不需要视觉辅助」
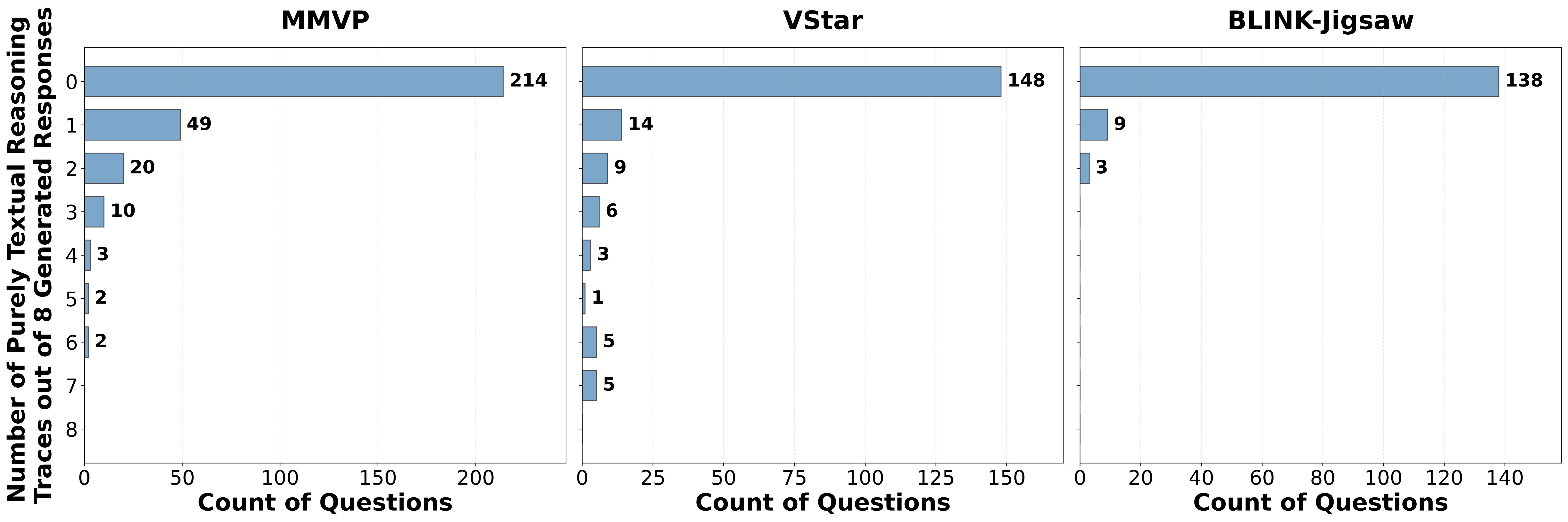
尽管只用交错推理数据训练,模型在**5.3%**的测试案例中 「自主切换」为纯文字推理。这不是随机行为:在切换的样本上准确率达到 81.25%,比坚持交错推理高出 7.29 个百分点。
模型学会了判断「这道题需不需要视觉辅助」,像人类一样灵活协调语言和视觉,而非机械执行固定流程。

信号三:协同解空间探索——多样性驱动更好的测试时扩展
在Best-of-N采样下,交错推理一致优于单模态推理,且分布偏移越大优势越明显。在最具挑战的BLINK-J上,交错推理从65.33%提升到73.33%(+8.0%),而纯视觉推理反而下降2.0%。
原因在于:单模态推理链局限于单一表示空间,而交错推理同时在文字和图像空间中探索,天然产生更 「多样化」 的推理轨迹,覆盖更广的解空间。
涌现属性的进一步验证
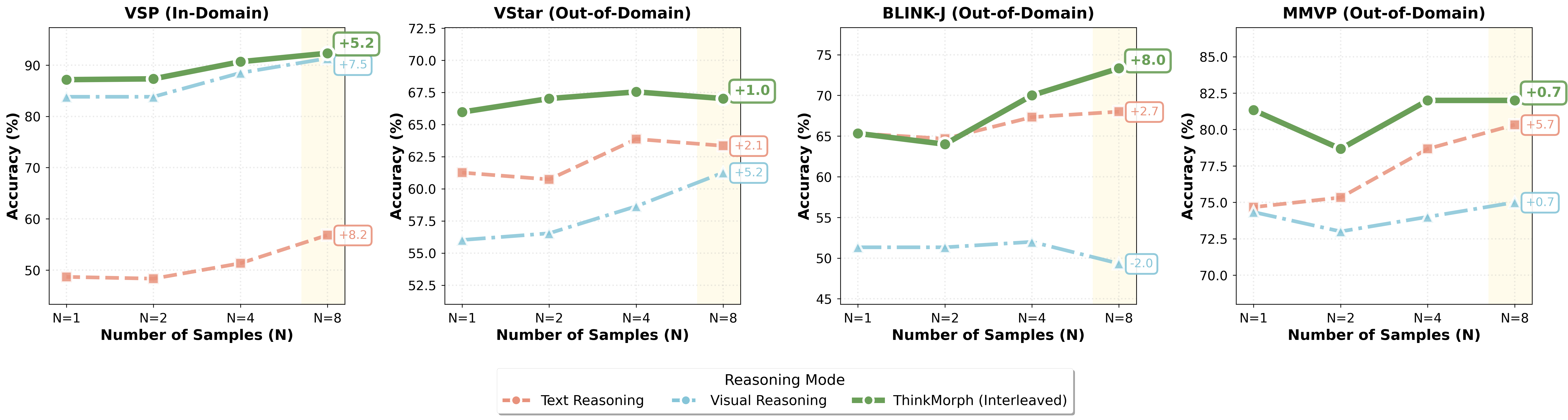
上述三个涌现信号是否只是个别任务上的偶然?在更广泛的域外基准上,研究团队进一步验证了它们的稳健性。
测试时扩展的表现因任务类型而异:在推理密集型任务(如 VStar)上,性能随采样数 N单调提升(+5.89%@N=8);而在感知主导型任务(如 BLINK-J)上呈现 U 形曲线,需要更大的采样量才能逃离局部最优。
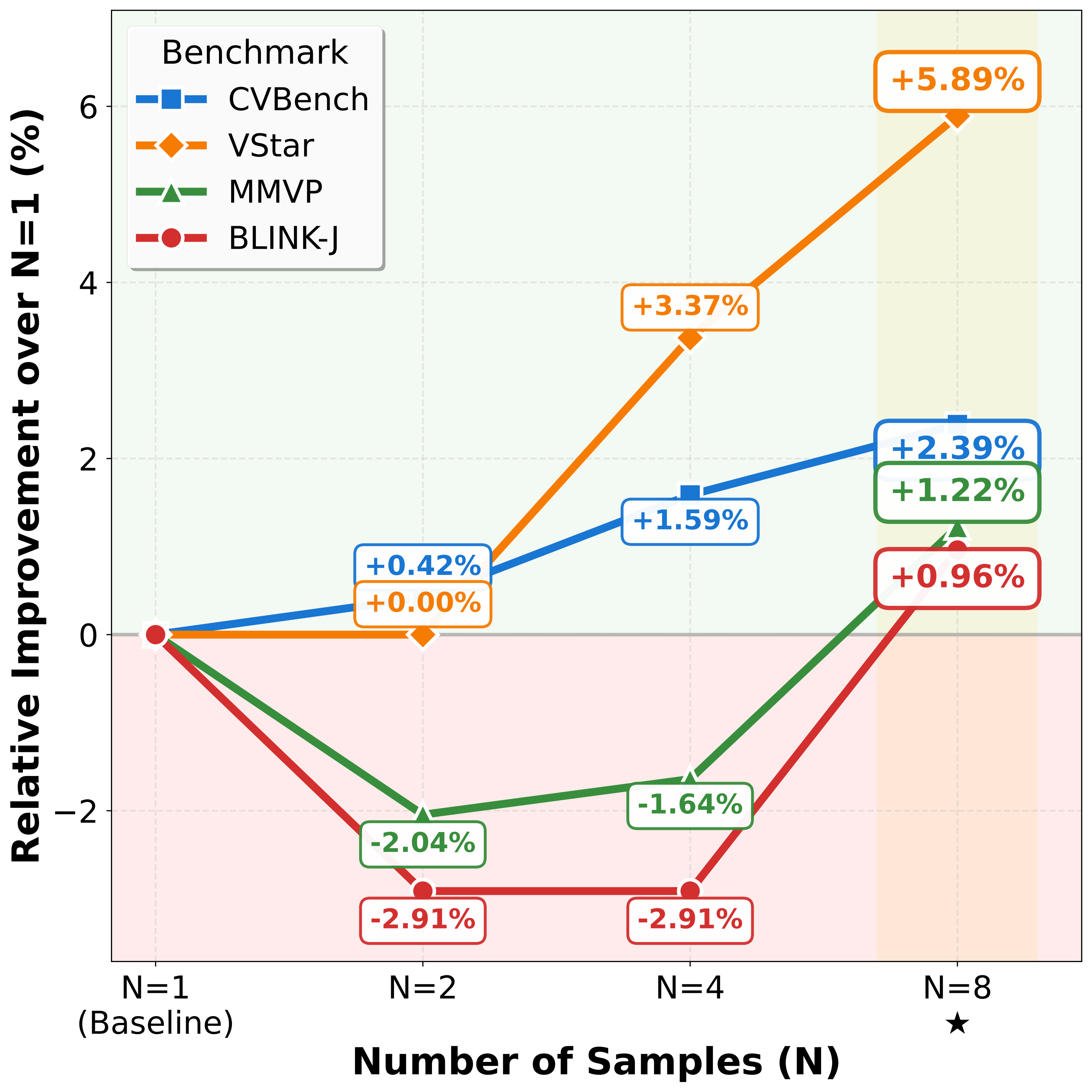
此外,当模型被允许在不同推理模式间灵活切换时,模式多样性本身进一步放大了测试时扩展的收益,为未来更高效的多模态扩展提供了方向。
边界在哪里?
ThinkMorph 同时讨论了这种推理方式的边界条件。 在图表分析中,关键信息本身就是文字(标签、数值),纯文字推理反而略优(+1.88%);但在需要精确视觉定位的任务上(如 MMVP),交错推理优势明显(+6.33%)。简单说:需要持续「看」的任务,交错推理最优;一眼就能提取关键信息的任务,文字推理更高效。

总结:原生多模态推理的未来
ThinkMorph仍是「原生多模态推理」的一场初步探索,但它已经证明,文字与图像一旦在统一架构中共同演化,就会涌现出训练数据从未覆盖的新能力,并学会自主判断何时该看、何时该想。
如果说当下的推理增强是在语言空间里把推理拧到极致,而ThinkMorph暗示下一次范式级突破可能不在更长的文本链条里,而在视觉与语言「交错协作」的原生推理里。跨过第一道门槛之后,等待被释放的是一种构建智能的全新默认方式。让多模态成为默认的思考方式,而这才刚刚开始。