作者:硅基趣玩喵
原文链接:https://zhuanlan.zhihu.com/p/2016080986690041206
一、背景
LLM强化学习训练面临一个核心架构选择:是使用在线RL(Online RL)——在训练中实时采样当前策略的rollout,还是使用离线RL(Offline RL)——利用预先收集好的固定数据集进行优化?这两种方法在数据效率、计算成本、训练稳定性和最终性能之间存在根本性的权衡,理解这一权衡是设计LLM训练系统的核心决策。
DPO(Direct-Preference Optimization)是最成功的离线RL代表,PPO/GRPO是在线RL的主流实现,而最新趋势是将两者结合,形成迭代式在线-离线混合方法(如Online DPO、Iterative RLHF)。
二、在线RL与离线RL的本质区别
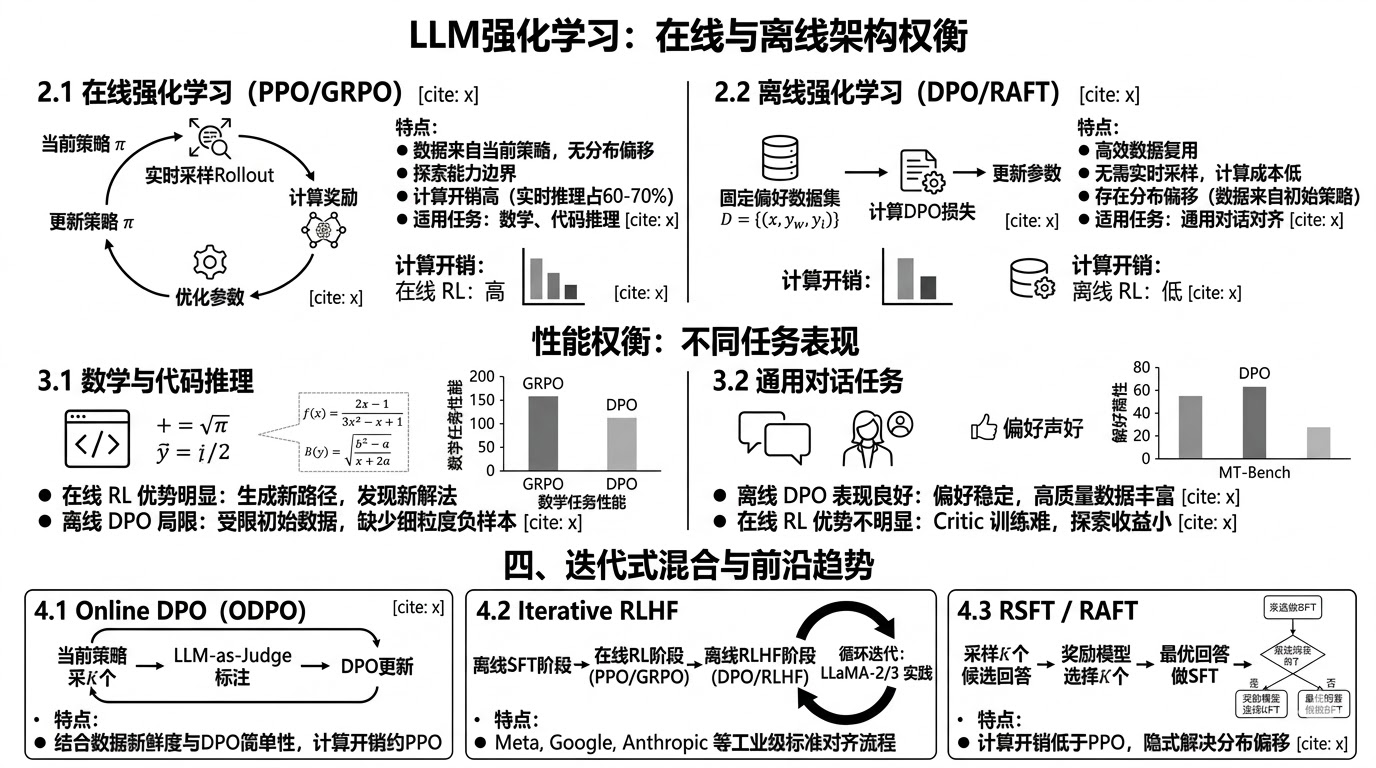
2.1 在线RL(PPO/GRPO)
在每个训练步骤,使用当前策略生成新的rollout,然后立即用这些新数据进行参数更新:
数据流:当前策略\pi_\theta→生成rollout→计算奖励→更新参数→新策略\pi_{\theta'}→生成新rollout→ …
核心特性:
- 训练数据始终来自当前策略,无分布偏移问题
- 每次策略更新都能探索当前策略能力边界附近的新区域
- 计算开销高:每步需要完整的推理前向传播(通常占总计算的60-70%)
- 需要实时奖励模型或验证器(无法使用批量预标注数据)
2.2 离线RL(DPO/RAFT)
使用预先收集好的固定数据集(通常是偏好数据对)进行优化,无需实时采样:
数据流:固定偏好数据集D = \{(x, y_w, y_l)\}→计算DPO/SFT损失→更新参数
核心特性:
- 数据复用效率高:一份数据集可以多轮训练
- 无需实时推理,GPU利用率高(无生成开销)
- 存在分布偏移:数据由初始策略生成,随训练进行数据越来越不代表当前策略分布
- 无法探索训练集之外的新解法(被数据集限制)
三、关键性能权衡
3.1 数学推理任务
在线RL(GRPO)的优势明显:
- 每轮训练生成新的推理路径,不受初始数据集中推理风格的束缚
- 可以自主发现数据集中不存在的推理策略(如不寻常但有效的解题路径)
- DeepSeek-R1实验显示,GRPO在MATH数据集上比相同数据量的DPO高约5-10%
离线DPO的局限:
- DPO数据集中的正确推理路径由某个特定模型生成,当前训练模型可能”无法理解”该路径(超出当前能力范围),导致监督信号无效
- 缺少对”接近正确但有缺陷”的推理路径的细粒度对比,负样本质量有限
3.2 通用对话任务
离线DPO表现良好:
- 对话质量的偏好较稳定(礼貌性、格式、完整性),不随策略能力强烈变化
- 高质量人工偏好数据集(如HH-RLHF、UltraFeedback)包含了大量多样化场景
- 计算成本远低于在线RL,适合资源有限场景
在线RL的优势不明显:
- 通用对话任务的”最优回答”不那么唯一(创意性更强),在线探索的收益较小
- PPO在对话任务中的Critic训练难度高(难以精确估计对话价值)
四、迭代式在线-离线混合方法
4.1 Online DPO(ODPO)
结合了在线RL的数据新鲜度和DPO的简单性:
流程:
1.从当前策略\pi_\theta对每个prompt采样2个候选回答
2.用奖励模型/LLM-as-Judge判断哪个更好,生成新的偏好对
3.用新偏好对做一步DPO更新
4.循环
Online DPO的数据始终来自当前策略,避免了离线DPO的分布偏移问题,同时保留了DPO的简单性(无需Critic)。实验表明,Online DPO比离线DPO在MT-Bench上高约5-8%,且计算成本仅为PPO的30-40%。
4.2 Iterative RLHF(迭代式强化学习)
3阶段迭代循环:
- 阶段1(离线SFT):使用高质量示例数据进行监督微调,建立基础能力
- 阶段2(在线RL):使用PPO/GRPO强化关键能力(数学推理、安全性),探索当前数据分布边界
- 阶段3(离线DPO/RLHF):收集在线RL产生的新数据,经人工/AI标注后更新偏好模型,为下一轮迭代准备
LLaMA-2、LLaMA-3的训练均采用多轮Iterative RLHF,每轮5000-20000条新偏好标注,已进行3-5轮迭代。
4.3 Rejection Sampling Fine-tuning(RSFT/RAFT)
离线RL的一种特殊形式,利用在线采样但以SFT方式训练:
1.从当前策略对每个prompt采样K(如64)个候选回答
2.用奖励模型选择得分最高的候选作为”最优回答”
3.对这些”最优回答”做SFT(而非RL)
4.循环
优点:
- 无需Critic,无PPO的训练不稳定性
- SFT训练稳定且高效
- 每轮使用当前策略采样,隐式解决了分布偏移
缺点:
- 无法直接利用”负样本”信息(与DPO相比)
- 每次需要采样K个候选,推理成本高
五、选择方法的决策树
任务有可验证奖励(数学、代码)?
├── 是 → 在线RL(GRPO/PPO)效果最好,计算预算允许则首选
└── 否(主观任务)
├── 有高质量偏好数据?
│ ├── 是 → 离线DPO(简单高效)
│ └── 否 → Online DPO(自动生成在线偏好数据)
└── 计算预算充足?
├── 是 → Iterative RLHF(最佳效果)
└── 否 → RSFT(RAFT,平衡性价比)
六、工程实践建议
- 资源有限的团队优先离线DPO:实现简单,无需推理基础设施,一块A100可以训练7B模型
- 高性能推理任务(数学/代码)必须使用在线RL:离线数据的分布局限会严重限制推理能力上限
- Iterative RLHF是工业级对齐的标准:Meta、Google、Anthropic均采用多轮迭代,每轮更新数据和奖励模型
- Online DPO是在线RL和离线DPO之间的最优折衷:比DPO效果好5-8%,比PPO计算成本低50-70%
七、参考文献
1.Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model, NeurIPS 2023
https://arxiv.org/abs/2305.18290
2.Dong et al., RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment*, TMLR 2023
https://arxiv.org/abs/2304.06767
3.Guo et al., Direct Language Model Alignment from Online AI Feedback, arXiv 2024
https://arxiv.org/abs/2402.04792
4.Touvron et al., LLaMA 2: Open Foundation and Fine-Tuned Chat Models, 2023
https://arxiv.org/abs/2307.09288