

动态三维建模的统一框架旨在在时间维度上同时建模场景的几何结构与运动变化,实现对动态世界的完整理解与重建。
整体框架通常包括两个核心模块:
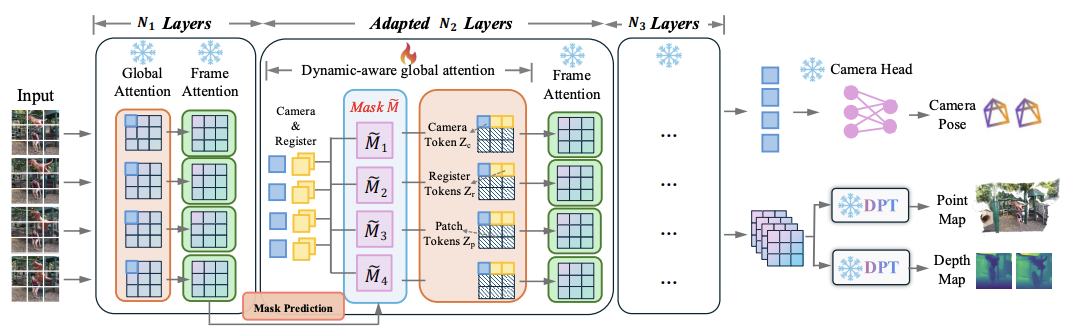
首先是感知与表示模块,从多视角图像或视频中提取空间与时间特征,并构建统一的动态场景表示,如隐式场、3D Gaussian 或体渲染表示;
其次是几何与运动建模模块,联合估计相机运动、场景几何以及物体或场景的动态变化,实现空间与时间的耦合建模。

通过统一表示、联合优化和时空建模,该框架能够在复杂动态场景中实现稳定、连续且可泛化的三维理解。
3月20日(周五)上午10点,青稞Talk 第114期,麻省理工学院(MIT)博士后研究员周恺辰,将直播分享《从 VGGT 到 PAGE-4D:动态世界中的 3D 感知统一框架》。
论文:PAGE-4D: Disentangled Pose and Geometry Estimation for VGGT-4D Perception
链接:https://arxiv.org/abs/2510.17568
项目主页:https://page4d.github.io/
分享嘉宾
周恺辰,麻省理工学院(MIT)博士后研究员,博士毕业于牛津大学。主要从事机器人与三维视觉方向研究,重点关注动态场景中的几何与运动理解、三维重建及智能操作。在 CVPR、ECCV、NeurIPS 等国际顶级会议发表多篇论文,相关研究成果在机器人感知与空间智能领域具有重要影响。
主题提纲
从 VGGT 到 PAGE-4D:动态世界中的 3D 感知统一框架
1、静态世界的幻觉:VGGT 为什么会“失效”?
2、3D 感知的“任务冲突”
3、PAGE-4D:动态感知的 VGGT 扩展
4、动态场景的实验验证
5、未来方向探讨 & AMA (Ask Me Anything)
直播时间
3月20日(周五)10:00 - 11:00