
在最近的大模型后训练中,On-Policy Distillation已经成为默认选项之一。
但研究者们在分析训练日志、实验曲线和对比不同 OPD 方法实现时,反复碰到同一个问题:理论上很自然的 sampled-token OPD,实际运行起来并不稳定,甚至会把模型往一些局部上“看起来合理”、整体上却越来越差的方向推。
重探 On-Policy Distillation(OPD):三类典型失败以及修复路径
5月16日上午10点,青稞Talk 125期,青稞社区邀请到自动化所深度强化学习团队博士生傅宇千,来直播分享《重探 On-Policy Distillation(OPD):三类典型失败以及修复路径》。
在这次分享中,傅宇千博士将集中回答三个更具体的问题:OPD方法到底在优化什么;其常见实现为什么容易出问题;以及是否存在一个代价不高、但更稳定的实现路径。
主题提纲
重探 On-Policy Distillation(OPD):三类典型失败以及修复路径
1、On-Policy Distillation算法概述
2、OPD到底在优化什么?
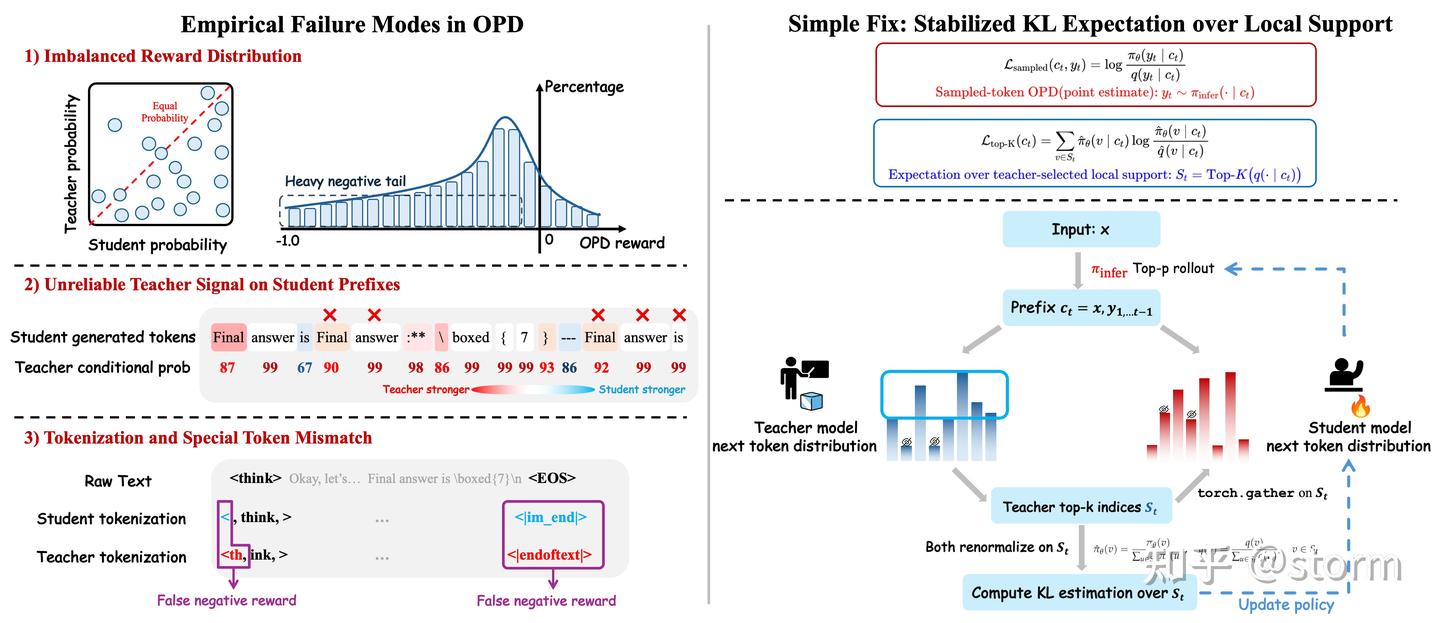
3、实践中的三大陷阱:Sampled-tokenOPD为什么失效?
4、TeacherTop-K,一种更稳定的实现路径
5、后训练流程中的两层Gap与未来路径探讨
6、AMA (Ask Me Anything)环节
直播时间
5月16日(周六)10:00 - 11:00